20189217 2018-2019-2 《密码与安全新技术专题》论文学习与报告总结
课程:《密码与安全新技术专题》
班级: 1892
姓名: 李熹桥
学号:20189214
上课教师:王志强
上课日期:2019年5月21日
必修/选修: 选修
1.论文总结
论文题目:With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning
论文作者:Bolun Wang, UC Santa Barbara; Yuanshun Yao, University of Chicago; Bimal Viswanath, Virginia Tech; Haitao Zheng and Ben Y. Zhao, University of Chicago
1.1 背景
现在很多企业都在做深度学习,但是监督学习训练需要非常大的标记数据集,比如在视觉领域ImageNet模型的训练集包含了1400万个标记图像,但是小型公司没有条件训练这么大的数据集或者无法得到这么大的数据集。
论文中提到对于这个问题,当前一个普遍的解决方案就是迁移学习:一个小型公司借用大公司预训练好的模型来完成自己的任务。我们称大公司的模型为“教师模型“,小公司迁移教师模型并加入自己的小数据集进行训练,得到属于自己的高质量模型”学生模型”。
总结来看迁移学习主要解决了目前机器学习中存在的两个问题:
第一,是数据量不足的问题。虽然互联网和移动互联网催生了数据量的爆炸式增长,但在一些非互联网领域仍然存在数据量小的困境。医疗领域就是一个典型,有一些发病率较低的疾病样本数量很少,但会存在与它相关联的疾病和治疗方法,我们就可以通过已有的模型进行迁移,从而对疑难杂志进行大数据分析从而得出有效的诊疗方案。
第二,是个性化推荐的问题。每个人的喜好兴趣都不相同,通过数据可以分析出一个人的用户画像,对他进行内容的精准推荐。但如何给一个没有书籍浏览信息的人进行阅读推荐呢?这可以通过迁移学习,对他的音乐、艺术作品兴趣,包括学习经历等一系列信息,与他的阅读兴趣进行关联,从而实现在没有该领域数据积累下的个性化推荐。

1.2 迁移学习
迁移学习过程
“学生模型”通过复制教师模型的前N-1层来初始化,并增加了一层全连接层用于分类,之后使用自己的数据集对学生模型进行训练,训练过程中,前K层是被冻结的,即它们的权重是固定的,只有最后N-K层的权重才会被更新。前K层之所以在训练期间要被冻结,是因为这些层的输出已经代表了学生任务中的有意义的特征,学生模型可以直接使用这些特征,冻结它们可以降低训练成本和减少所需的训练数据集。
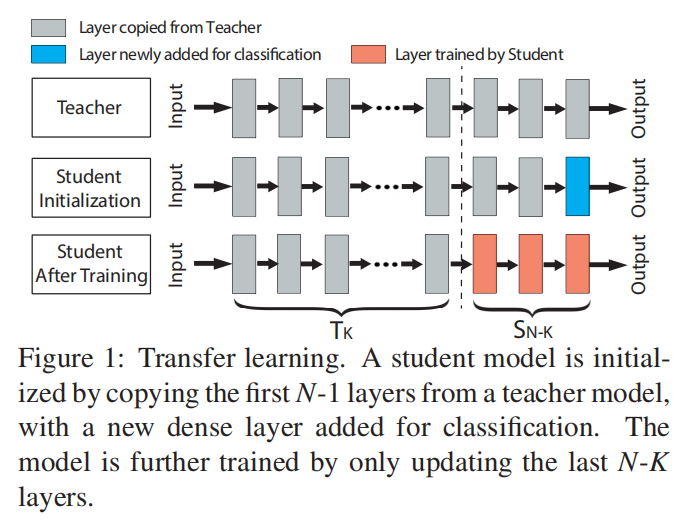
迁移学习方法
根据训练过程中被冻结的层数K,可以把迁移学习分为以下3种方法:深层特征提取器(Deep-layer Feature Extractor)、中层特征提取器(Mid-layer Feature Extractor)、全模型微调(Full Model Fine-tuning)。
- Deep-layer Feature Extractor:K=N-1,学生任务与教师任务非常相似,需要的训练成本最小
- Mid-layer Feature Extractor:K<N-1,允许更新更多的层,有助于学生为自己的任务进行更多的优化
- Full Model Fine-tuning:K=0,学生任务和教师任务存在显著差异,所有层都需要微调
迁移学习安全性
人工智能的应用不断多元化,不断深入日常的生活之中,迁移学习的安全性已经成了当前人工智能学科必须要面对的问题。由于迁移学习要选择“教师模型”有限缺乏多样性,用户只能从很少的教师模型中进行选择,同一个教师模型可能被很多个公司迁移,所以攻击者如果知道了教师模型就可以攻击它的所有学生模型。这就是这篇论文主要攻击的方法
1.3 对抗性攻击
常用术语
- 对抗图像/对抗样本(Adversarial example/image):对抗样本是对干净图像进行处理后的样本,被故意扰乱(如加噪声等)以达到迷惑或者愚弄机器学习技术的目的,包括深度神经网络。
- 对抗扰动(Adversarial perturbation):对抗扰动是添加到干净图像中的噪声,使其成为一个对抗样本。
- 对抗性训练(Adversarial training):对抗性训练使用除了干净的图像之外的对抗样本来训练机器学习模型。
- 对手(Adversary):对手通常指创建一个对抗样本的代理。但是在某些情况下,我们也称对抗样本本身为对手。
- 黑盒攻击(Black-box attacks):黑盒攻击是在不了解一个目标模型的具体情况下,针对该模型,生成了对抗样本(测试阶段)。在某些情况下,假设对手对模型的了解有限(例如,它的训练过程或者架构),但绝对不知道模型参数。在其他情况下,使用任何关于目标模型的信息称为半黑盒攻击。这篇文献使用前一种约定。
- 白盒攻击(White-box attacks):白盒攻击假设具备了目标模型的完整知识,包括其参数值、体系结构、训练方法,在某些情况下还包括训练数据。它允许攻击者对模型进行无限制的查询,直至找到一个成功地对抗性样本。这种攻击常常在最小的扰动下获得接近100%的成功,因为攻击者可以访问深度神经网络的内部结构,所以他们可以找到误分类所需的最小扰动量。然而白盒攻击一般被认为是不切实际的,因为很少会有系统公开其模型的内部结构。
- 检测器(Detector):检测器是一种(仅)检测图像是否为对抗样本的机制。
- 欺骗率(Fooling ratio/rate):欺骗率表示在图像被扰动后,经过训练的模型改变其预测标签的百分比。
- 一次性/单步方法(One-shot/one-step methods):一次性/单步法通过执行单步计算产生对抗性扰动,例如计算一次模型的损失梯度。与之相反的是迭代方法( iterative methods),它多次执行相同的计算以得到一个单独的扰动。后者的计算成本通常很高。
- 近似无法察觉(Quasi-imperceptible):近似无法察觉扰动从人类感知而言对图像影响很小。(本文提出的DSSIM距离)
- 修正器(Rectifier):修正器修改一个对抗样本来恢复这个目标模型的预测结果同该样本未扰动前的预测。
- 针对性攻击(Targeted attacks):有针对性的攻击欺骗了一个模型,使对抗性图像错误地预测成特定标签。它们与非目标攻击相反,在非目标攻击中,被预测的对抗图像的标签是无关的,只要它不是正确的标签。
- 威胁模型(Threat model):威胁模型指的是一种方法所考虑的潜在攻击类型,例如黑盒攻击。
- 可转移性(Transferability):可转移性指的是一个对抗样本具有可转移能力,即使是除了用来产生它的模型以外,它仍然有效。
- 通用扰动(Universal perturbation):通用扰动能够在任何图像上扰动并高概率欺骗一个给定模型。值得注意的是,通用性指的是一种与图像无关的扰动性质,区别于有很好的可转移性。
- 目标攻击:将source image 𝑥_𝑠 误分类成target image 𝑥_𝑡 所属标签
- 非目标攻击:将source image 𝑥_𝑠 误分类成任意其他的source image 所属标签
对抗性攻击思路
由于机器学习算法的输入形式是一种数值型向量(numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。
和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,之后该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。如给一个输入图像加入不易察觉的扰动,使模型将输入图像误分类成其他类别。
1.4具体攻击策略##
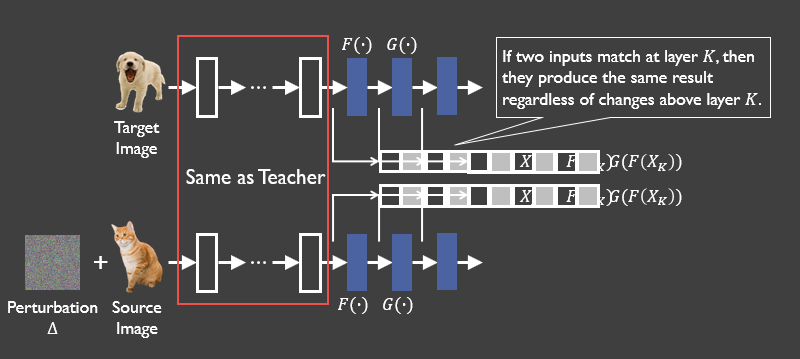
如果攻击目标是把source图猫误识别为target图狗,本文的攻击思路是:首先将target图狗输入到“教师模型”中,捕获target图在“教师模型”第K层的输出向量。之后对source图加入扰动,使得加过扰动的source图(即对抗样本)在输入“教师模型”后,在第K层在数值上产生非常相似的输出向量。由于前馈网络每一层只观察它的前一层,所以如果我们的对抗样本在第K层的输出向量可以完美匹配到target图的相应的输出向量,那么无论第K层之后的层的权值如何变化,它都会被误分类到和target图相同的标签。
1.4.1 如何选择攻击层
- 攻击者首先要判断学生模型是否使用了Deep-layer Feature Extractor,因为它是最易被攻击的方法。
- 如果学生模型的迁移学习方法是Deep-layer Feature Extractor ,攻击者需要攻击第N-1层以获得最佳的攻击性能;
- 如果学生模型的迁移学习方法不是Deep-layer Feature Extractor ,攻击者可以尝试通过迭代瞄准不同的层,从最深层开始,找到最优的攻击层。
1.4.2 给定学生模型如何确定教师模型
前面我们的误分类攻击是假设了攻击者知道教师模型是哪个的,接下来我们放宽这个条件,考虑攻击者不知道教师模型是哪个的情况。

基尼系数是经济学中的概念,在本文中如果基尼系数非常大,说明该学生模型对应的教师模型不在候选池中,或者该学生模型选择的不是Deep-layer Feature Extractor的迁移学习方法。
1.4.3目标函数
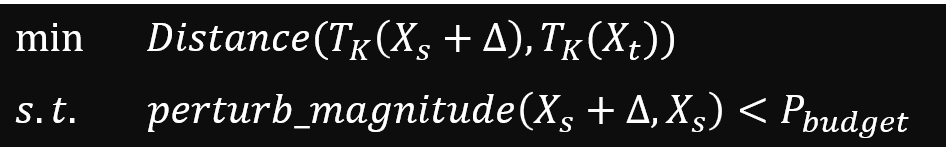
公式含义为在扰动程度perturb_magnitude小于一定约束值(扰动一般经验值P)的前提下,最小化对抗样本(扰动后的source image)第K层的输出向量与target image 第K层的输出向量的欧式距离。之前计算扰动程度都是使用L2范数,但是它无法衡量人眼对于图像失真程度的感知。本文利用一种图像结构相似性DSSIM来度量图像加扰动前后的相似程度。
这意味着在实现的时候需要最优化两个loss,一个为DSSIM,一个为在k层两种不同输入的输出的欧式距离。

1.5影响攻击效果的因素##
- 扰动预算P的选择直接关系到攻击的隐蔽性。P越小攻击成功率越低,通过使用DSSIM度量方法测量图像失真,我们发现P=0.003是人脸图像的一个安全阈值。其对应的L2范数值明显小于前人的结果。
- 距离度量方法也会影响攻击效果,使用DSSIM产生的扰动不易察觉,使用L2的扰动更明显。DSSIM能考虑到图像的潜在结构,而L2平等对待每一个像素,并经常在脸部产生明显的“纹身样” 图案。
- 迁移学习方法也非常影响攻击效果,本文的攻击对于深层特征提取器是非常有效的,但对于全模型微调无效。
1.6本文攻击的防御方法
论文还提出了3种针对本文攻击的防御方法,其中最可行的是修改学生模型,更新层权值,确定一个新的局部最优值,在提供相当的或者更好的分类效果的前提下扩大它和教师模型之间的差异。换句话说在教师模型第K层的输出向量和学生模型第K层的输出向量之间的欧氏距离大于一个阈值前提下,让预测结果和真实结果的交叉熵损失最小。
1.7复现结果##

下图为实验结果示意图:

1.8生成扰动的其他方法##

借用Gan的结构,可得到一个合理的扰动图像。
复现得到的demo如下:

可以发现如果不加相关约束的话,加扰动的图像可见明显的水印,这更加证明了引用DSSIM的重要性。
2.学习中遇到的问题及解决
- 问题1:教师模型上白盒攻击能否转移到学生模型身上?
- 问题1解决方案:不行,从实验结果来看仅有0.3%的对抗样本在学生模型上被错分。从网络结构上看,学生模型与教师模型的分类层不同,对教师模型的对抗性样本经过学生模型的分类器时不会被分类到某一指定类。
3.学习感想和体会
以前认为安全问题存在在硬件,软件编译器,网站等传统载体上,经过学习我发现ML、DL方面也存在着不可忽视的安全问题。比如帮助医生诊断的神经网络如果遭受到攻击,那医生的判断将会受到很大的影响。再比如自动驾驶中对路标信号灯的识别网络受到攻击将可能会出现安全事故。这次的论文学习让我产生了更自觉的安全意识。
参考资料
posted on 2019-06-03 22:19 20189214李熹桥 阅读(267) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号