

索引概念
索引是与视图关联的磁盘或内存中结构,可以加快从表或视图中的检索速度。索引包含由表或视图中的一列或多列生成的键。
索引特点
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引不足
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
应该建立索引的特点
- 在经常需要搜索的列上,可以加快搜索的速度;
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 在经常使用在 WHERE 子句中的列上面创建索引,加快条件的判断速度。
不应该建立索引的特点
- 对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很 少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降 低了系统的维护速度和增大了空间需求。
- 对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少, 例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需 要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
- 对于那些定义为 blob 数据类型的列不应该增加索引。这是因为,这些列的数据量要 么相当大,要么取值很少。
- 当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能 是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会 提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
聚集索引和非聚集索引
聚集索引和非聚集索引都可以是唯一的。 这意味着任何两行都不能有相同的索引键值。
聚集索引:聚集索引根据数据行的键值在表或视图中排序和存储这些数据行。 索引定义中包含聚集索引列。 每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
非聚集索引:
非聚集索引具有独立于数据行的结构。 非聚集索引包含非聚集索引键值,并且每个键值项都有指向包含该键值的数据行的指针。
从非聚集索引中的索引行指向数据行的指针称为行定位器。 行定位器的结构取决于数据页是存储在堆中还是聚集表中。
在表中创建主键约束和唯一约束会自动创建索引,创建主键约束时会自动创建聚集索引;创建唯一约束索引会自动创建非聚集索引。
--创建表时添加约束
CREATE TABLE Production.TransactionHistoryArchive1 (
TransactionID int IDENTITY (1,1) PRIMARY KEY NOT NULL
);
CREATE TABLE Production.TransactionHistoryArchive1 (
TransactionID int IDENTITY (1,1) NOT NULL,
CONSTRAINT PK_TransactionHistoryArchive_TransactionID PRIMARY KEY CLUSTERED (TransactionID)
);
--主键
alter table abo.tableName Add constraint pk_name primary key
--唯一约束
alter table Account add constraint AK_AccountName unique (Account_Name)
--删除约束
alter table AdItem drop constraint AdOrder_AdItem_FK1
聚集索引
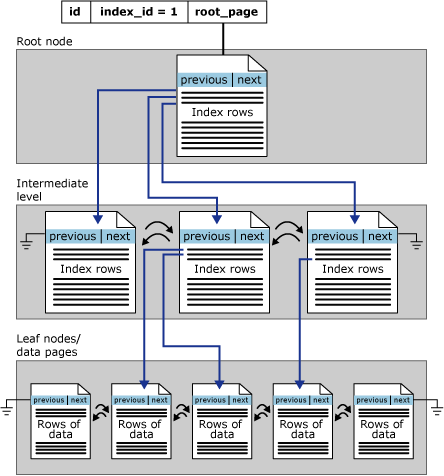
在 SQL Server 中,索引是按 B 树结构组织的。 索引 B 树中的每一页称为一个索引节点。 B 树的顶端节点称为根节点。 索引中的底层节点称为叶节点。 根节点与叶节点之间的任何索引级别统称为中间级。 在聚集索引中,叶节点包含基础表的数据页。 根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向 B 树上的某一中间级页或叶级索引中的某个数据行。 每级索引中的页均被链接在双向链接列表中。
聚集索引在 sys.partitions中有一行,其中,索引使用的每个分区的 index_id = 1。 默认情况下,聚集索引有单个分区。 当聚集索引有多个分区时,每个分区都有一个包含该特定分区相关数据的 B 树结构。 例如,如果聚集索引有四个分区,就有四个 B 树结构,每个分区中有一个 B 树结构。
根据聚集索引中的数据类型,每个聚集索引结构将有一个或多个分配单元,将在这些单元中存储和管理特定分区的相关数据。 每个聚集索引的每个分区中至少有一个 IN_ROW_DATA 分配单元。 如果聚集索引包含大型对象 (LOB) 列,则它的每个分区中还会有一个 LOB_DATA 分配单元。 如果聚集索引包含的变量长度列超过 8,060 字节的行大小限制,则它的每个分区中还会有一个 ROW_OVERFLOW_DATA 分配单元。
数据链内的页和行将按聚集索引键值进行排序。 所有插入操作都在所插入行中的键值与现有行中的排序顺序相匹配时执行。
下图显式了聚集索引单个分区中的结构。
建议使用聚集索引事项
- 使用运算符(如
BETWEEN、>、>=、< 和 <=)返回一系列值 - 返回大型结果集
- 使用
JOIN子句;一般情况下,使用该子句的是外键列。 - 使用
ORDER BY或GROUP BY子句
注:定义聚集索引键时使用的列越少越好
什么情况下不适合创建聚集索引
频繁更改的列
宽键(组合聚集索引,选择的列太多)
非聚集索引
非聚集索引包含索引键值和指向表数据存储位置的行定位器。 可以对表或索引视图创建多个非聚集索引。 通常,设计非聚集索引是为改善经常使用的、没有建立聚集索引的查询的性能。
与使用书中索引的方式相似,查询优化器在搜索数据值时,先搜索非聚集索引以找到数据值在表中的位置,然后直接从该位置检索数据。 这使非聚集索引成为完全匹配查询的最佳选择,因为索引包含说明查询所搜索的数据值在表中的精确位置的项。 例如,为了从 HumanResources. Employee 表中查询向特定经理负责的所有雇员,查询优化器可能使用非聚集索引 IX_Employee_ManagerID;它以 ManagerID 作为其键列。 查询优化器能快速找出索引中与指定 ManagerID匹配的所有项。 每个索引项都指向表或聚集索引中准确的页和行,其中可以找到相应的数据。 在查询优化器在索引中找到所有项之后,它可以直接转到准确的页和行进行数据检索。
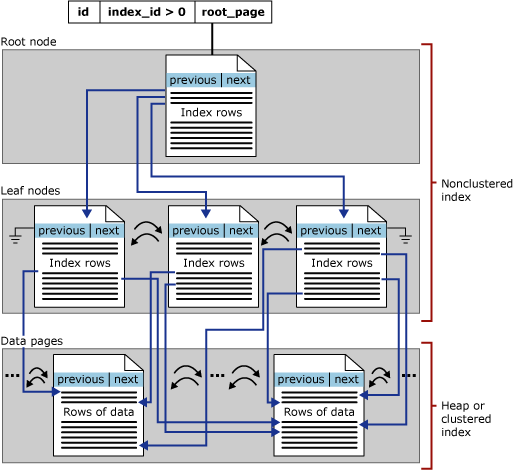
非聚集索引体系结构
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点:
- 基础表的数据行不按非聚集键的顺序排序和存储。
- 非聚集索引的叶级别是由索引页而不是由数据页组成。
非聚集索引行中的行定位器或是指向行的指针,或是行的聚集索引键,如下所述:
- 如果表是堆(意味着该表没有聚集索引),则行定位器是指向行的指针。 该指针由文件标识符 (ID)、页码和页上的行数生成。 整个指针称为行 ID (RID)。
- 如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。
对于索引使用的每个分区,非聚集索引在 index_id >1 的 sys.partitions 中都有对应的一行。 默认情况下,一个非聚集索引有单个分区。 如果一个非聚集索引有多个分区,则每个分区都有一个包含该特定分区的索引行的 B 树结构。 例如,如果一个非聚集索引有四个分区,那么就有四个 B 树结构,每个分区中一个。
根据非聚集索引中数据类型的不同,每个非聚集索引结构会有一个或多个分配单元,在其中存储和管理特定分区的数据。 每个非聚集索引至少有一个针对每个分区的 IN_ROW_DATA 分配单元(存储索引 B 树页)。 如果非聚集索引包含大型对象 (LOB) 列,则还有一个针对每个分区的 LOB_DATA 分配单元。 此外,如果非聚集索引包含的可变长度列超过 8,060 字节的行大小限制,则还有一个针对每个分区的 ROW_OVERFLOW_DATA 分配单元。
下图说明了单个分区中的非聚集索引结构。
建议使用非聚集索引事项
- 使用
JOIN或GROUP BY子句 - 不返回大型结果集的查询
- 包含经常包含在查询的搜索条件(例如返回完全匹配的 WHERE 子句)中的列
- 覆盖查询 (当索引包含查询中的所有列时,性能可以提升。)
- 大量非重复值,如姓氏和名字的组合(前提是聚集索引被用于其他列)
带有包含列的索引准则
- 在 CREATE INDEX 语句的 INCLUDE 子句中定义非键列
- 只能对表或索引视图的非聚集索引定义非键列
- 允许除 text、 ntext和 image之外的所有数据类型
- 精确或不精确的确定性计算列都可以是包含列
- 与键列一样,只要允许将计算列数据类型作为非键索引列,从 image、 ntext和 text 数据类型派生的计算列就可以作为非键(包含性)列。
- 不能同时在 INCLUDE 列表和键列列表中指定列名。
- INCLUDE 列表中的列名不能重复
唯一索引和筛选索引
唯一索引能够保证索引键中不包含重复的值,从而使表中的每一行从某种方式上具有唯一性。
筛选索引是一种经过优化的非聚集索引,尤其适用于涵盖从定义完善的数据子集中选择数据的查询。筛选索引使用筛选谓词对表中的部分行进行索引。用于重复性比较高的列
索引创建
CREATE [UNIQUE] [CLUSTERED| NONCLUSTERED ]
INDEX index_name ON { table | view } ( column [ ASC | DESC ] [ ,...n ] )
[with[PAD_INDEX][[,]FILLFACTOR=fillfactor]
[[,]IGNORE_DUP_KEY]
[[,]DROP_EXISTING]
[[,]STATISTICS_NORECOMPUTE]
[[,]SORT_IN_TEMPDB]
]
[ ON filegroup ]
--ag:
CREATE TABLE dbo.TestTable
(TestCol1 int NOT NULL,
TestCol2 nchar(10) NULL,
TestCol3 nvarchar(50) NULL);
GO
CREATE CLUSTERED INDEX IX_TestTable_TestCol1
ON dbo.TestTable (TestCol1);
索引的限制
1、使用不等于操作符(<>、 !=)
select cust_Id,cust_name from customers where cust_rating <> 'aa';
--正确写法
select cust_Id,cust_name from customers where cust_rating < 'aa' or cust_rating > 'aa';
2、使用 IS NULL 或 IS NOT NULL
使用 IS NULL 或 IS NOT NULL 同样会限制索引的使用。因为 NULL 值并没有被定义。
在 SQL 语句中使用 NULL 会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成 NOT NULL。
如果被索引的列在某些行中存在 NULL 值,就不会使用这个索引
3、使用函数
--account_number 是字符类型
select bank_name,address,city,state,zip from banks where account_number = 990354;
--正确写法
select bank_name,address,city,state,zip from banks where account_number ='990354';
资料: 索引体系结构和设计 聚集索引和非聚集索引

