
中小企业如何有效应对计算资源的弹性变化需求?
作者:程序员大阳(独立开发者)
来源:本文选自 Serverless 函数计算评测活动 征文
1. 计算舞台的发展史
1.1 上古时代
long long ago,很久很久以前,计算机是一种极其稀缺的资源。我曾跟某大学教授沟通,他说最开始的时候,一个大学的计算机系可能只有一台计算机。计算机是如此稀缺,那时候的计算资源可以说就算你有钱,也未必能轻易得到。
这个时代,我愿称之为计算资源的上古时代,其特点就是稀缺!
1.2 中古时代
我刚毕业那会,进入一家国有大型商业银行从事信息科技工作。第一次走进机房,就被那一排排的服务器电脑震撼了。看着那些服务器时不时闪烁的灯光,我能想象到,它们支撑的是数百亿、千亿、万亿的资金流动。
它们体格巨大、性能强悍、运行稳定,但是——额——非常昂贵。不光购买贵,要想让这些大型服务器正常运行,配套的机房、运维人员成本也不低。大型企业能承受,中小公司就有心无力了。
这个时代,我愿称之为计算资源的中古时代,其特点就是昂贵!
1.3 近现代
2018年,我进入一家民企企业,我发现企业使用的基本都是云服务器。使用云服务器的好处是,如果部署的程序访问量大、并发量高、数据量大,那就买配置高的、贵一点的。如果部署的程序比较简单,访问人数也不多,那就买配置低的、便宜一点的。
而且随着时间的发展,访问量大增时,也可以花钱升级配置。同时采用云服务器的话,不用单独建设机房,也不用买硬件路由器、防火墙啥的,从成本上讲也不高。
简直是太香了,所以中小企业开始积极拥抱云服务器。我记得在公司工作的时候,管理的云服务器有几十台,而且每年都稳定新增若干台。
这个时代,我愿称之为计算资源的近现代,其特点嘛,就是性价比高。
1.4 当代
其实我在工作中,老早就发现了一些问题,就是我们对计算资源的需求,具有时空的不均衡性。
比如我们开发一套学校的缴费系统,这个系统平时无人问津,到了学校发缴费通知那几天,系统访问人数爆棚。但是我们购买服务器的时候,总得按照支撑最大访问量的情形去购买,那平时剩余的计算能力不就大大的浪费了吗?
如果能有一种方式,可以根据需要,弹性的拓展或收缩计算能力,用户只需要按实际计算量付费,那会是一个相当大的进步吧。
另外从社会发展、从人类命运共同体的角度去看,这也是极大节约了社会资源、提高了生产效率啊。哎,恕我孤陋寡闻,虽然我一直有这样的想法,却不知这在云计算领域是早就实现了的技术。而Serverless就是其中一种代表性的计算技术,它早已经来到我们身边了。
这个时代,我愿称之为计算资源的当代,其特点嘛,就是精细、和谐。
2. Serverless的概念
先从字面意思理解,Server是服务器,less是缺少,合起来就是无服务器。无服务器的运算,就是咱们的程序不用部署到各类服务器,而是直接交给云(例如阿里云),云帮我们来协调计算资源、进行弹性的计算。
接下来我们就使用阿里云Serverless函数计算,来真正体验一下吧。
3. 快速体验
3.1 产品入口
阿里云产品众多,先给大家说下函数计算 FC 的位置。
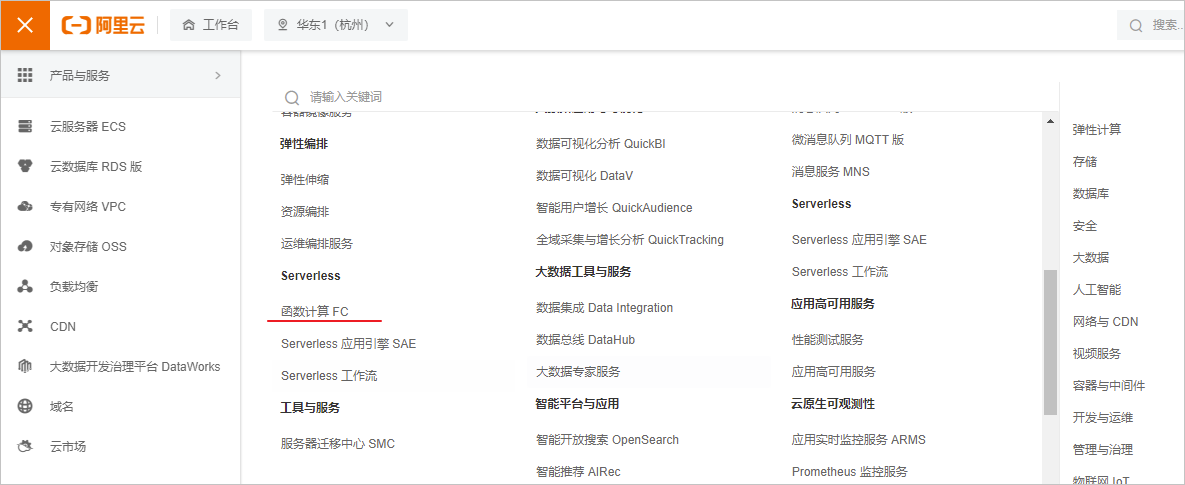
3.2 创建应用
进入函数计算产品后,我们首先要创建一个应用。应用可以理解为一个后台服务、后台项目之类的东西。
阿里云内置了很多应用模板,例如常见的SpringBoot、Django、Flask等等,很好很强大,此处我选择了比较熟悉的SpringBoot。
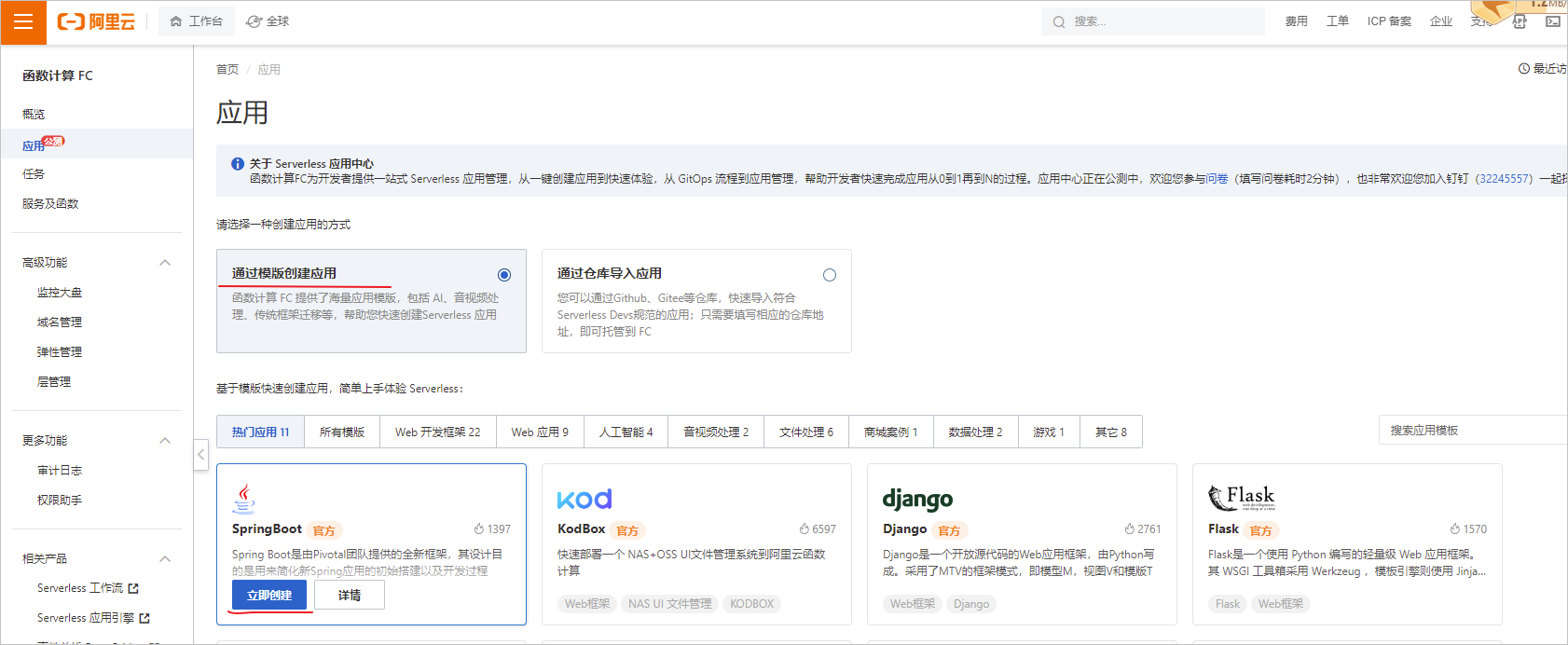
3.3 应用部署设置
如下图,设置为通过Gitgee代码仓库部署应用代码。这个很好理解,我们的应用直接关联一个Gitee的代码仓库,如果我们想部署应用,就先将代码提交到Gitee。
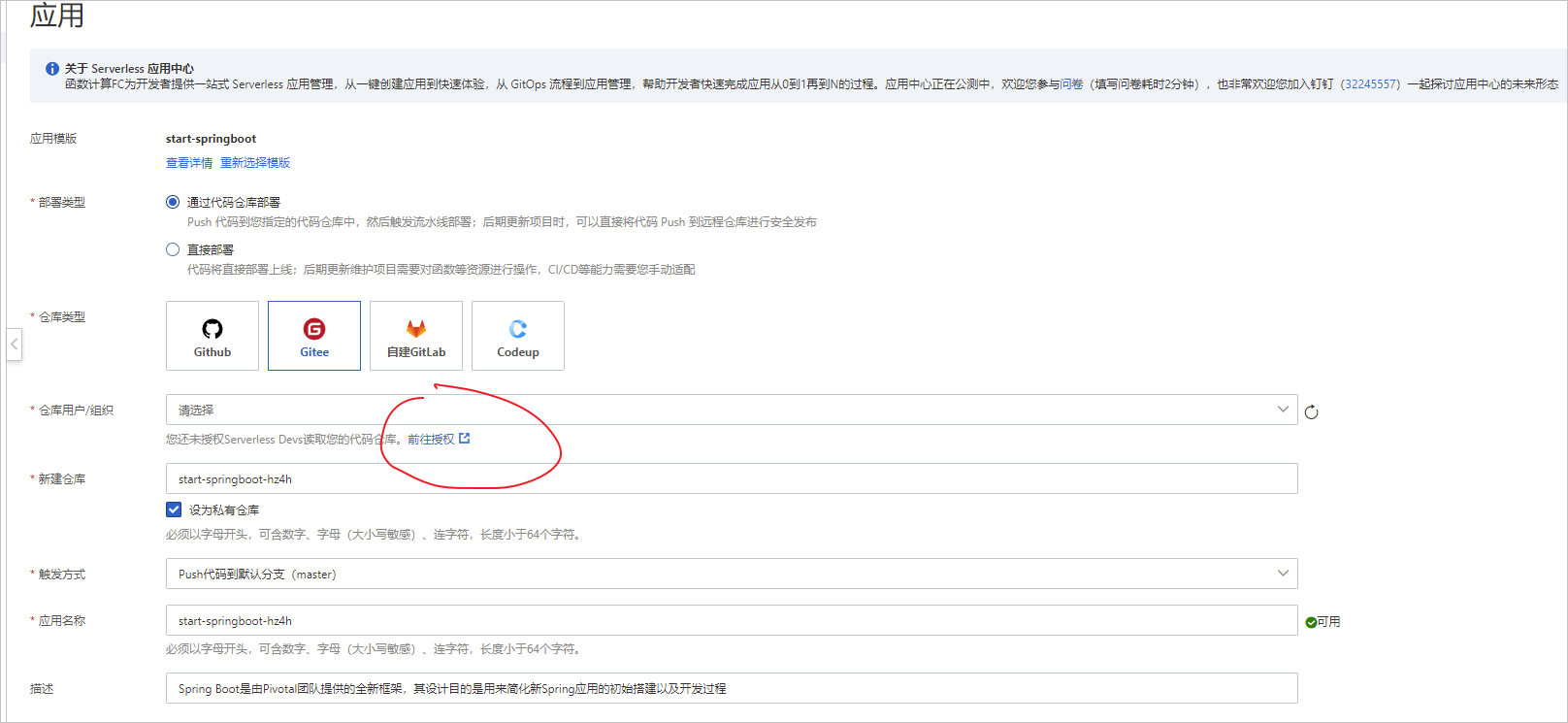
注意,点击上图中红线处的链接,然后登陆Gitee,即可完成Gitee代码对阿里云Serveless的绑定授权。
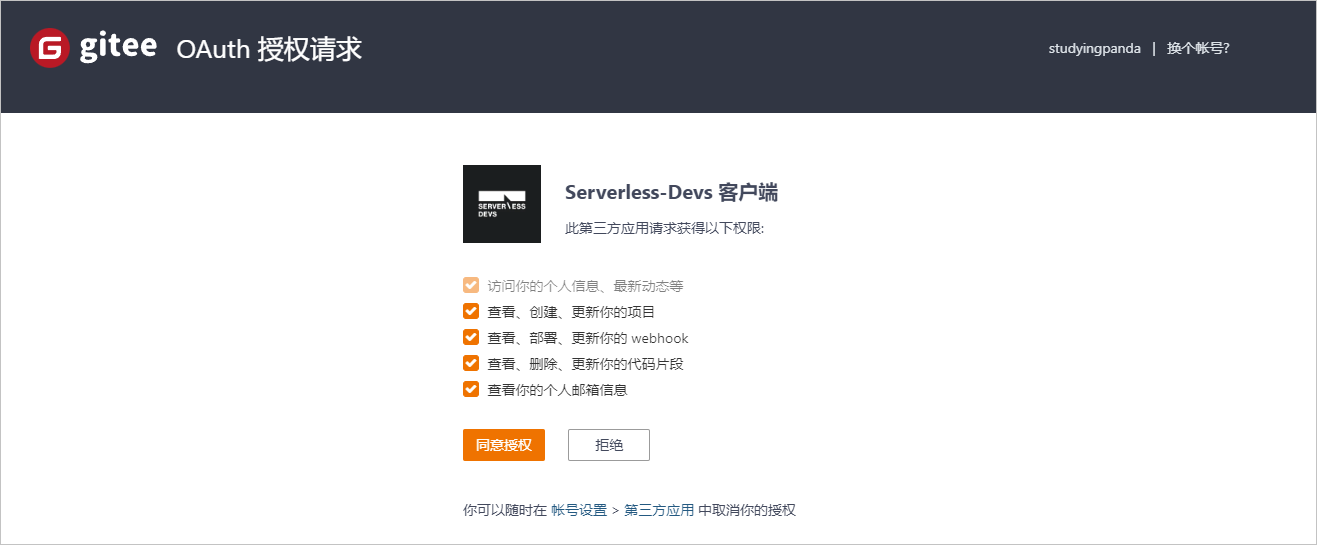
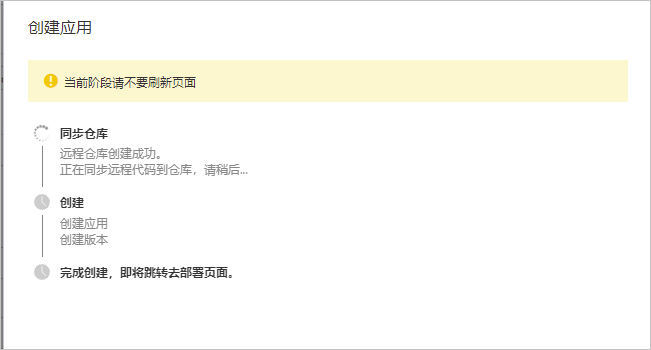
点击创建后,会弹出如下窗口,等待创建完成即可。
3.4 编写代码
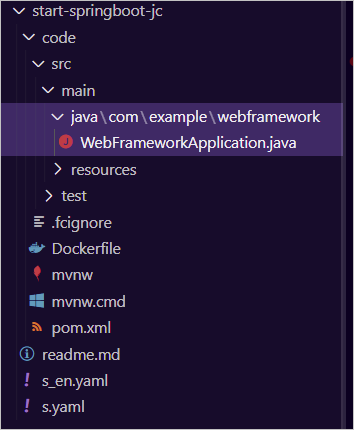
在上面创建项目时,我们指定了Gitee代码仓库名为【start-springboot-jc】,我们将该仓库克隆到本地,查看项目代码结构如下:
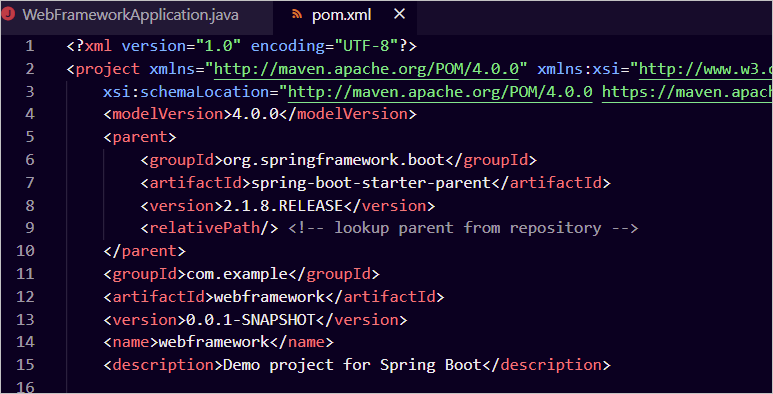
打开pom.xml配置文件,熟悉的感觉,这是一个纯正的SpringBoot项目,版本为2.1.8。阿里云开发人员既然选择了该版本,它应该是非常稳定优秀的吧。
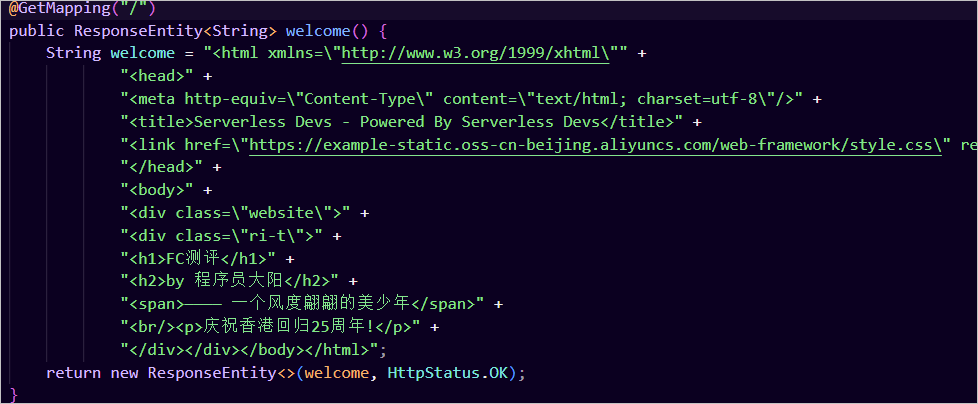
接下来看下启动类,我们可以轻易的猜出,welcome就是我们应用默认的入口。
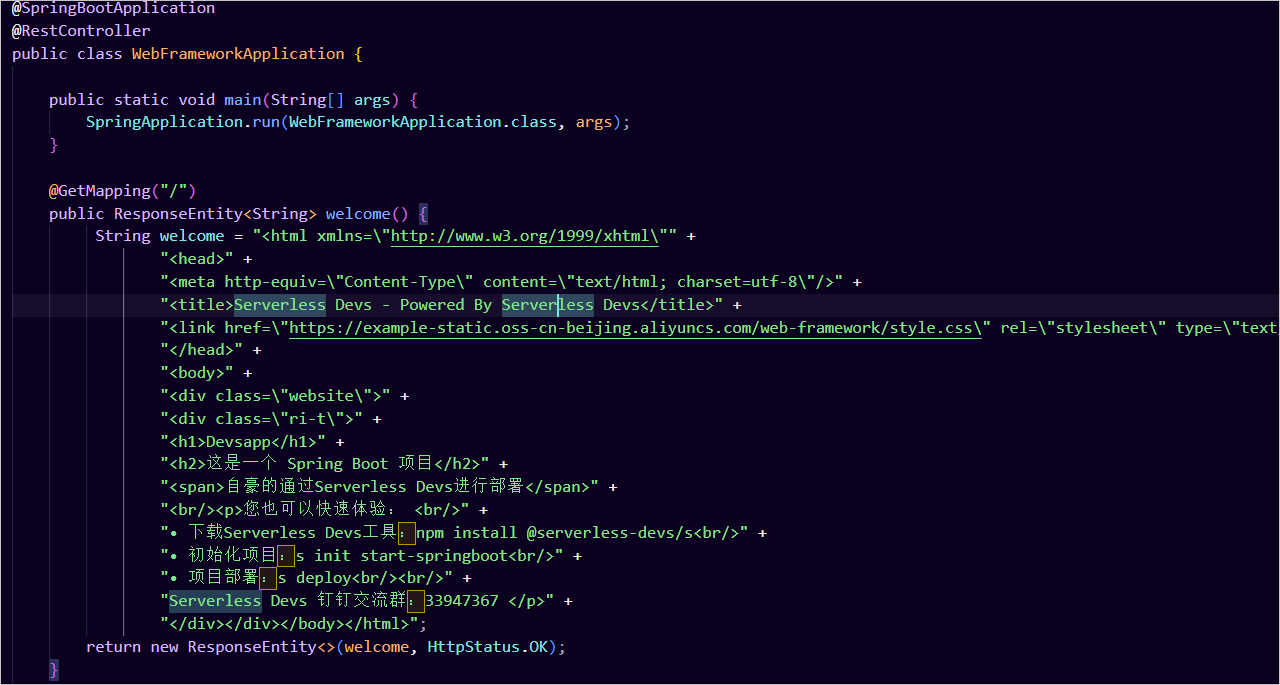
来吧,不修改一番,怎能见证我这一代Java全栈程序员的风采!
3.5 代码部署
将代码提交到仓库,然后点击红线处进入应用详情:
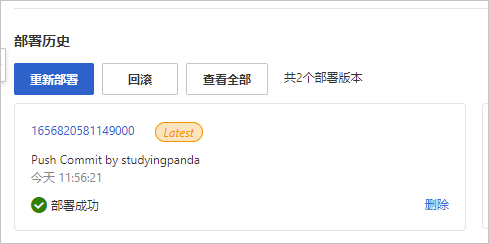
在部署历史中惊奇的发现已经自动部署了,要问我咋发现的,看下时间就是了。此处说明阿里云做的挺好啊,自动发现代码更新然后自动触发部署,此处一个值得点赞!
3.6 访问测试
在应用详情页面的上方,点击访问域名:
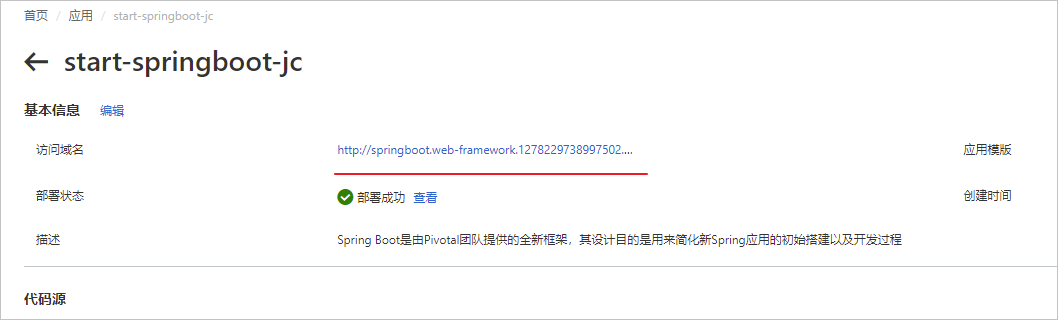
弹出网页界面如下,大功告成。

4. 常见使用问题解析
4.1 如何开发自己的业务逻辑
如果对SpringBoot很熟悉的话,这个问题应该是很简单的。
可以在pom.xml中配置依赖项,然后编写服务类,最后在welcome方法中调用封装的服务类即可。运行结果可以通过网页显示,当然一些后台计算也可以不用网页显示。
4.2 如何配置正式域名
项目正式上线时,我们往往希望使用正式域名。可以进入函数计算首页,点击【域名管理菜单】,然后点击【添加自定义域名】:
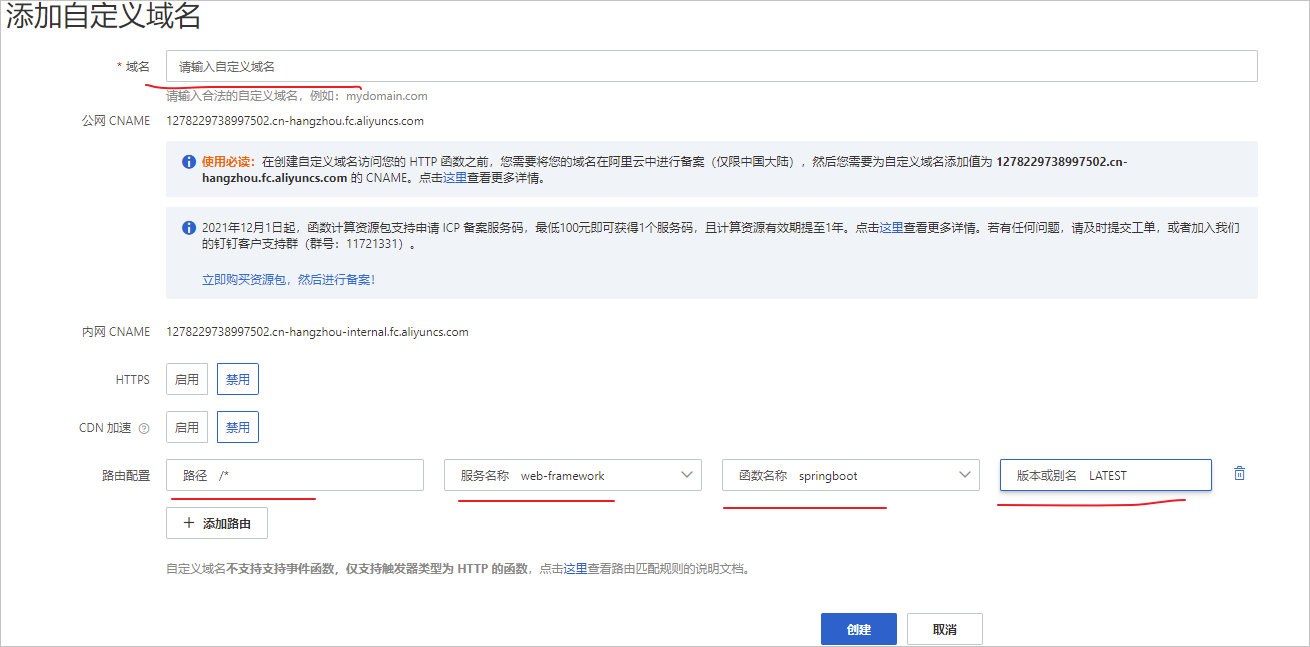
如下图,就可以将我们的域名和应用里面的函数关联起来了。
4.3 实例规格及环境配置
在【服务管理】-【函数管理】中点击红圈中的【配置】按钮。

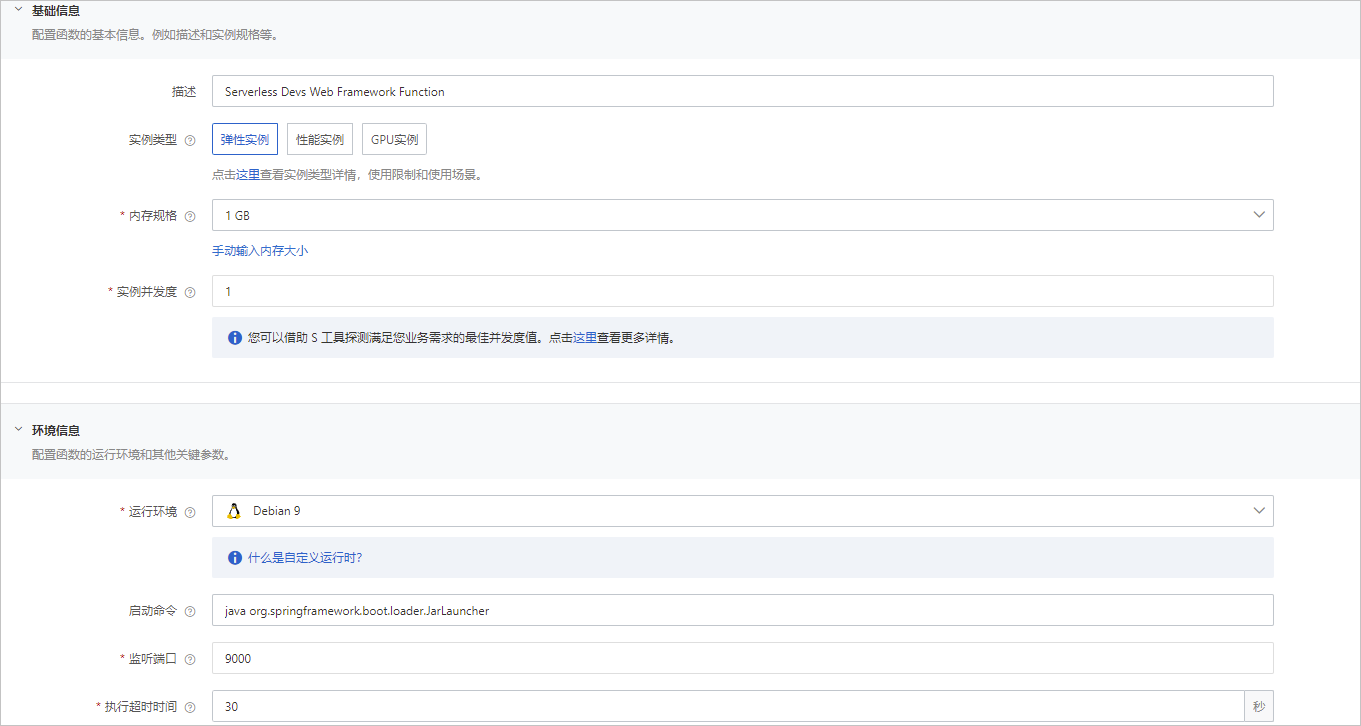
如下图,可以对实例规格、环境信息进行配置,例如内存、并发度、实例类型。
注意内存指的是函数执行的最大内存、并发度指的是函数可以同时处理多少个请求。
4.4 如何选择实例类型
实例类型分为三大类,下面是阿里云官方说明,我感觉写得挺好,就不再过多解释了。
- 弹性实例:函数计算基本实例,主要适用于突发流量场景,例如活动、大型促销和红包等。
- 性能实例:大规格实例,资源上限更高,主要适用于计算密集型场景,例如音视频处理、AI建模和企业级Java应用等场景。当您选择性能实例时,您的函数将运行在计算能力更高的实例中。
- GPU实例(公测中):基于Turing架构的GPU实例,主要适用于音视频、AI人工智能和图像处理等场景。在不同的场景中,将不同的业务负载下沉至GPU硬件加速,从而极大地提升了业务处理的效率。
4.5 如何进行监控和日志查看
注意在应用详情里面,会显示应用相关的底层服务和函数,如下图:
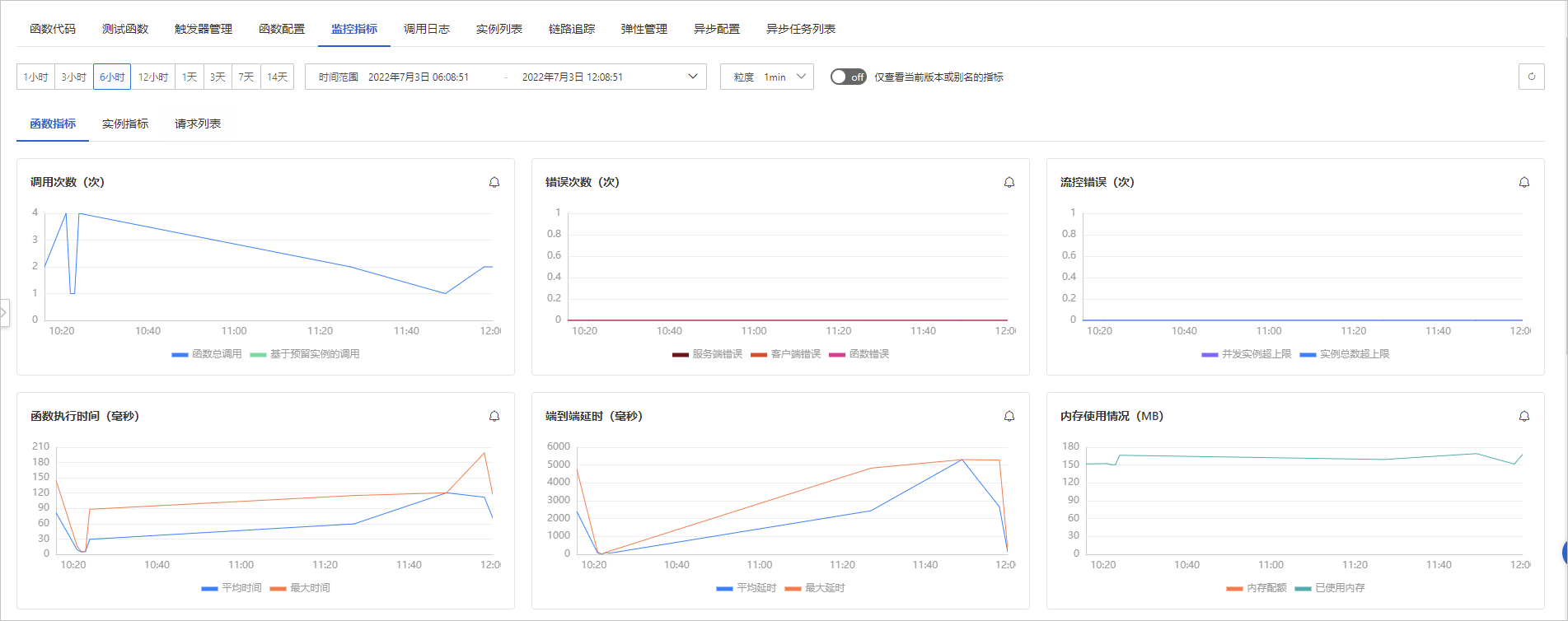
点击函数,可以看到很多信息,如下图可以很轻松的看到监控指标。
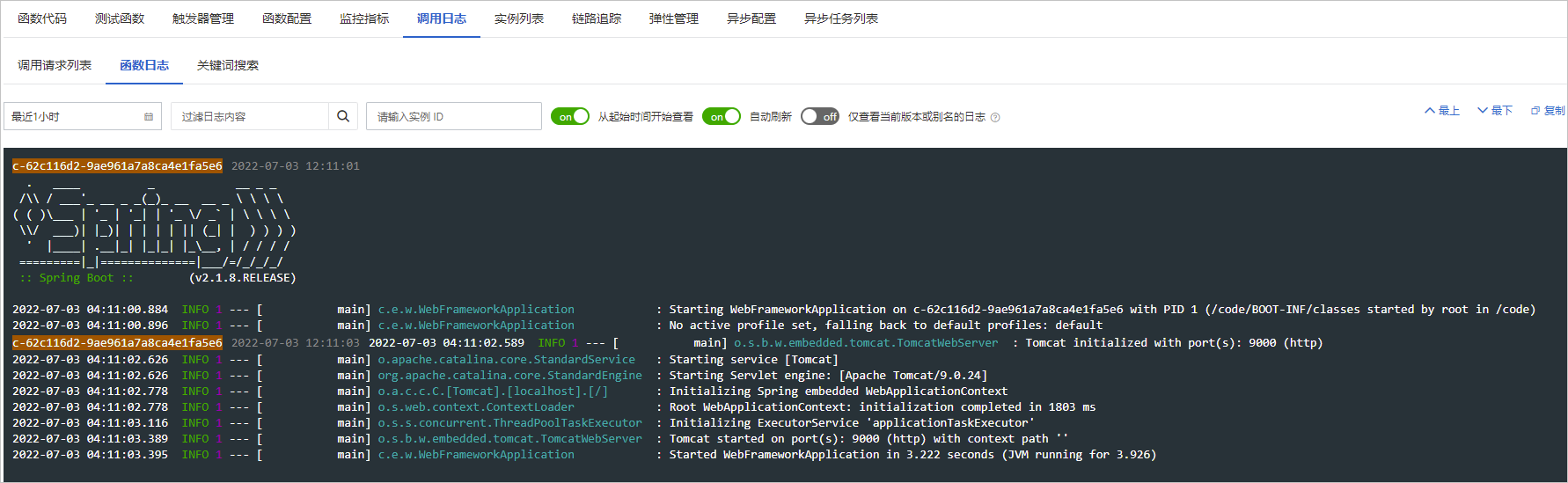
下图是日志信息:
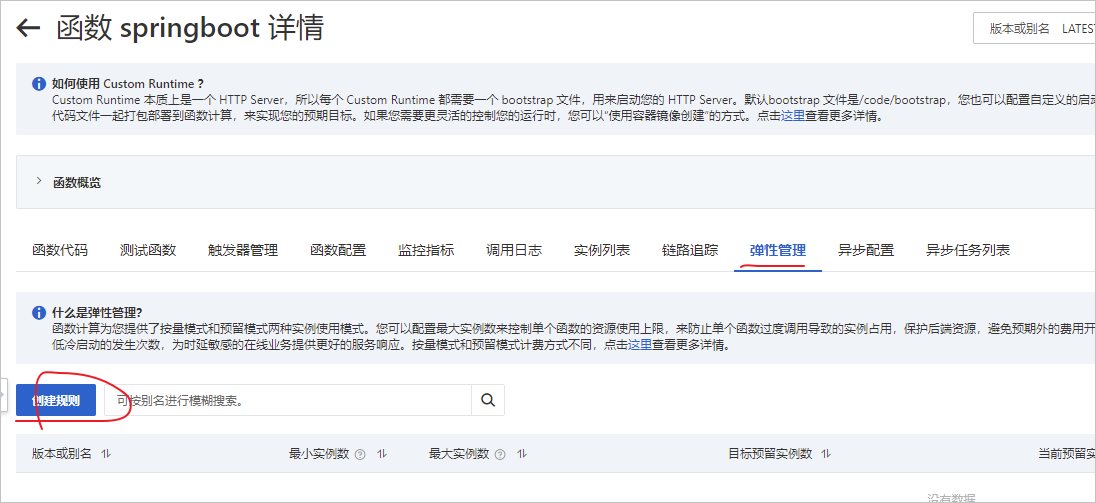
4.6 如何进行弹性管理
在函数详情页面,点击【弹性管理】-【创建规则】,可以通过设定规则,对函数进行弹性管理。
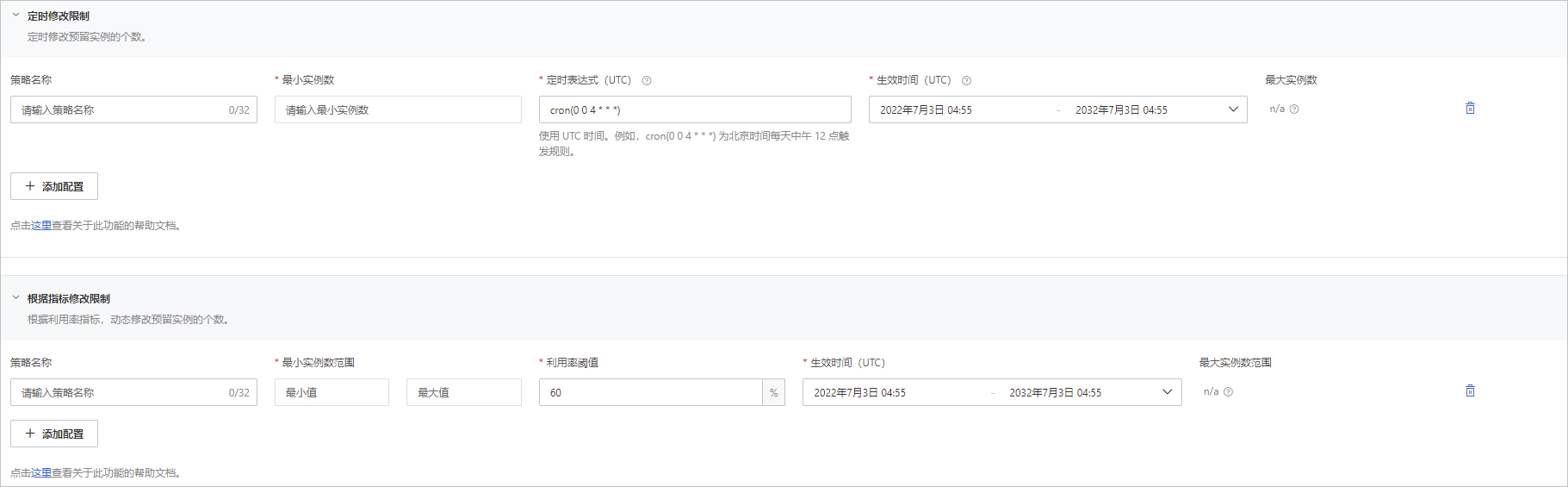
如下图,可以按时间、或者按指标,动态的调整实例数。
5. 小结
经过上面的讲述可以发现,Serverless函数计算作为一种新形式的计算方式,可以更好的应对计算资源弹性变化的场景。
从宏观上看,不同企业、不同服务对计算资源的需求存在时空不均衡的特点。云计算厂商可以通过动态的调度资源,实现计算能力的合理调配,节省大量的闲置资源,从而降低成本。
再宏观一点,当人类命运共同体的思想发展到一定程度,全球各个云计算厂商之间可以共享基础计算能力。当某个国家、地区计算资源在某个突然事件下不够用时,就可以临时调用其他国家、地区云厂商的计算资源——当然需要合理付费。
Serverless这种产品的研发,利国利民。前途是光明的,对于现今的技术,我们总会满怀希冀——愿云端起舞翩翩,伴人间璀璨华年。
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号