第一次个人编程作业
一、论文查重个人编程作业
| 作业所属班级 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024 |
|---|---|
| 作业要求 | 个人项目——论文查重 |
| 作业目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率 |
| github仓库地址 | https://github.com/wenhuilan/RuanGong/tree/master |
二、开发环境
编译环境:Windows11,x64
IDE:Visual Studio
语言:C++
三、总体设计
- 实现的功能:
文件管理类:文件的读取和写入
文本分析类:分词处理->计算逆文本频率并用向量表示->计算文本相似度
单元测试类:测试文件管理类和文本分析类的功能是否正常
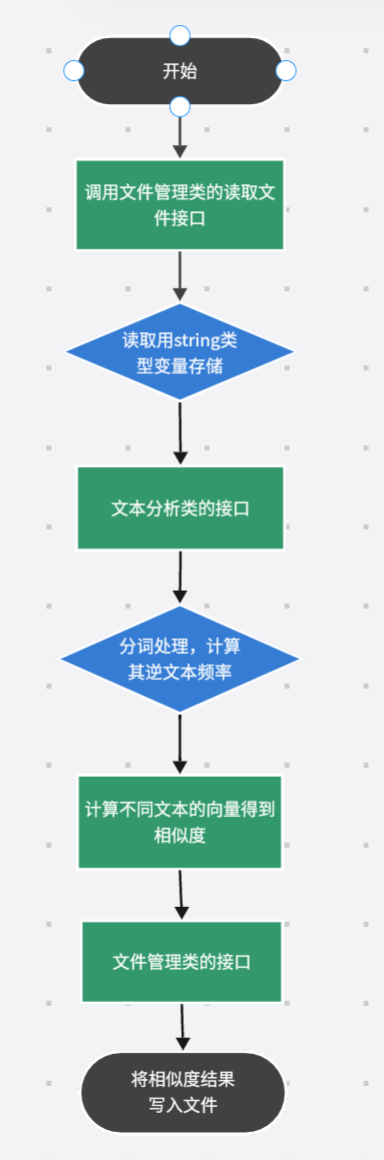
主程序:调用文件管理类读取待对比文本->调用文本分析类处理文本信息并获得向量,并计算文本相似度->将相似度计算结果写入文件 - 具体设计
-
文件读取类的设计:
使用C++标准库的文件读写接口实现 -
文本分析类的设计
文本分析类的设计思路:
文本分析类要实现的功能可以概括为以下三个方面: -
文本分词处理
对于文本处理部分,我使用cppjieba等分词库来实现文本的分词处理。
分词处理是将输入的文本切割成一个个词语的过程。
我调用分词库提供的接口,将文本作为输入,然后获取到分词后的词语列表
逆文本频率计算是针对文本中每个词语的频率进行统计和计算。我使用C++ STL容器map来存储每个词语及其对应的出现次数。通过遍历分词处理后的词语列表,统计每个词语的出现次数,并计算出词频向量(TF)。接着,可以利用公式计算逆文档频率(IDF)来衡量词语的重要性。
在计算文本相似度方面,常用的方法包括欧氏距离、曼哈顿距离和余弦相似度等。欧氏距离和曼哈顿距离可以用来衡量两个向量之间的距离,从而判断它们的相似度。而余弦相似度则是通过计算两个向量之间的夹角来衡量它们的相似度,值越接近1表示相似度越高。
由于随着文本量的增大,构造的IDF向量维度会不断增大,导致使用欧氏距离计算的结果会极其不合理,故采用余弦相似度进行计算
-
接口测试类的设计
-
主程序的设计
- 性能测试
处理:使用static关键字将设计的类设为静态类避免内存管理出现问题
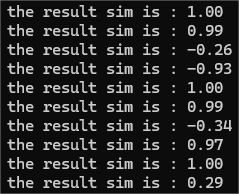
3.单元测试
//样例1
string TestOrig1 = "今天是星期天,天气晴,今天晚上我要去看电影。";
string TestCopy1 = "今天是周天,天气晴朗,我晚上要去看电影。";
//样例2
//样例3
//样例4
//样例5
......
Tester::TestForEssayAnalysist(TestOrig1, TestCopy1);
return 0;
-
测试结果:
-
错误处理--路径为空
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate* | 估计这个任务需要多长时间 | 100 | 80 |
| Development | 开发 | 300 | 300 |
| Analysis | 需求分析(包括学习新技术) | 30 | 40 |
| Design Spec | 生成设计文档 | 10 | 25 |
| Design Review | 设计复审 | 10 | 15 |
| Coding Standard | 代码规范 | 10 | 15 |
| Design | 具体设计 | 50 | 70 |
| Coding | 具体编码 | 200 | 150 |
| Code Review | 代码复审 | 20 | 15 |
| Test | 测试 | 10 | 20 |
| Reporting | 报告 | 30 | 30 |
| Test Report | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem & Process Improvment Plan | 事后总结,并提出过程的改进计划 | 20 | 20 |
| 合计 | 860 | 850 |
