Yolov5环境报错解决:No labels found in 与 Could not run 'torchvision::nms' with arguments from the 'CUDA' backend 。
问题记录
yolov5环境
1 No labels found in (Done)
报错内容
F:\WorkSpace\GitSpace\yolov5>python train-self.py
train-self: weights=weights/yolov5s.pt, cfg=models/yolov5s-new.yaml, data=data\coconew.yaml, hyp=data\hyps\hyp.scratch-low.yaml, epochs=100, batch_size=4, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs\train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
fatal: unable to access 'https://github.com/ultralytics/yolov5.git/': Failed to connect to github.com port 443 after 21110 ms: Timed out
Command 'git fetch origin' timed out after 5 seconds
YOLOv5 v7.0-114-g3c0a6e66 Python-3.9.0 torch-1.13.1+cu116 CUDA:0 (NVIDIA GeForce GTX 1050, 4096MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
ClearML: run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 in ClearML
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5s-new summary: 214 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs
Transferred 229/349 items from weights\yolov5s.pt
AMP: checks passed
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
train: Scanning F:\WorkSpace\GitSpace\yolov5\data\ImageSets\train.cache... 0 images, 4456 backgrounds, 0 corrupt: 100%|
Traceback (most recent call last):
File "F:\WorkSpace\GitSpace\yolov5\train-self.py", line 640, in <module>
main(opt)
File "F:\WorkSpace\GitSpace\yolov5\train-self.py", line 529, in main
train(opt.hyp, opt, device, callbacks)
File "F:\WorkSpace\GitSpace\yolov5\train-self.py", line 188, in train
train_loader, dataset = create_dataloader(train_path,
File "F:\WorkSpace\GitSpace\yolov5\utils\dataloaders.py", line 124, in create_dataloader
dataset = LoadImagesAndLabels(
File "F:\WorkSpace\GitSpace\yolov5\utils\dataloaders.py", line 504, in __init__
assert nf > 0 or not augment, f'{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}'
AssertionError: train: No labels found in F:\WorkSpace\GitSpace\yolov5\data\ImageSets\train.cache, can not start training. See https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
思路&解决
目录结构:
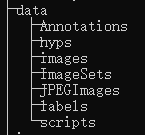
我看了许多博客都说 Annotations 文件夹与 image 要在 data 中, labels 文件夹也要在同级目录下,但是无论是将 ImageSets 中的 txt 文件以及 utils 里的 dataloaders.py 中文件路径改为绝对路径还是更换目录结构都无法解决。
直至看到一篇博客提到文件名被改了,与实际不符,修改代码之后解决问题,考虑到可能是源码中的思路与本机目录结构不符,决定去查看源码,由于处理数据文件的代码处于 dataloaders.py 中,从该文的报错信息处开始查看。
# Display cache
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
if exists and LOCAL_RANK in {-1, 0}:
d = f'Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt'
tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT) # display cache results
if cache['msgs']:
LOGGER.info('\n'.join(cache['msgs'])) # display warnings
assert nf > 0 or not augment, f'{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}'
报错处处于以上代码的第8行,但是显然这附近没有我们想要的,于是想到查看代码中处理后的 labels 文件目录,找到生成 labels 目录的函数 img2label_paths :
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
根据注释也可以明白该函数用于生成默认的 labels 目录,我们在其中添加输出语句,分析判断该函数的结构。
[sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
#其中一个目录为 F:\\WorkSpace\\GitSpace\\yolov5\\data\\JPEGImages\\009963.txt
其中 sa = /images/ , sb = /labels/ , x 的值为 img 的目录,这里的路径确实是 images 文件夹的绝对路径,语句中以第一次出现的字符串 images 作为分割点,但是我提供的目录中并未出现 images 字符串,所以分割失败,修改一下我提供的目录即可。
2 Could not run 'torchvision::nms' with arguments from the 'CUDA' backend (Done)
报错内容
F:\WorkSpace\GitSpace\yolov5>python train-self.py
train-self: weights=weights/yolov5s.pt, cfg=models/yolov5s-new.yaml, data=data\coconew.yaml, hyp=data\hyps\hyp.scratch-low.yaml, epochs=100, batch_size=4, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs\train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
remote: Enumerating objects: 13, done.
remote: Counting objects: 100% (13/13), done.
remote: Compressing objects: 100% (13/13), done.
remote: Total 13 (delta 5), reused 1 (delta 0), pack-reused 0
Unpacking objects: 100% (13/13), 14.11 KiB | 29.00 KiB/s, done.
From https://github.com/ultralytics/yolov5
3c0a6e66..5c91daea master -> origin/master
6ac4c48c..8e0c488e benchmarks -> origin/benchmarks
github: YOLOv5 is out of date by 2 commits. Use 'git pull' or 'git clone https://github.com/ultralytics/yolov5' to update.
YOLOv5 v7.0-114-g3c0a6e66 Python-3.9.0 torch-1.13.1+cu116 CUDA:0 (NVIDIA GeForce GTX 1050, 4096MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
ClearML: run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 in ClearML
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5s-new summary: 214 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs
Transferred 229/349 items from weights\yolov5s.pt
AMP: checks passed
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
train: Scanning F:\WorkSpace\GitSpace\yolov5\data\ImageSets\train... 4456 images, 494 backgrounds, 0 corrupt: 100%|████
train: WARNING Cache directory F:\WorkSpace\GitSpace\yolov5\data\ImageSets is not writeable: [WinError 183] : 'F:\\WorkSpace\\GitSpace\\yolov5\\data\\ImageSets\\train.cache.npy' -> 'F:\\WorkSpace\\GitSpace\\yolov5\\data\\ImageSets\\train.cache'
val: Scanning F:\WorkSpace\GitSpace\yolov5\data\ImageSets\val.cache... 496 images, 51 backgrounds, 0 corrupt: 100%|█████
AutoAnchor: 4.10 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset
Plotting labels to runs\train\exp38\labels.jpg...
Image sizes 640 train, 640 val
Using 4 dataloader workers
Logging results to runs\train\exp38
Starting training for 100 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/99 0.958G 0.08311 0.04302 0.07115 23 640: 100%|██████████| 1114/1114 [06:55<00:00,
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/62 [00:00<?
Traceback (most recent call last):
File "F:\WorkSpace\GitSpace\yolov5\train-self.py", line 640, in <module>
main(opt)
File "F:\WorkSpace\GitSpace\yolov5\train-self.py", line 529, in main
train(opt.hyp, opt, device, callbacks)
File "F:\WorkSpace\GitSpace\yolov5\train-self.py", line 352, in train
results, maps, _ = validate.run(data_dict,
File "C:\Users\wan\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "F:\WorkSpace\GitSpace\yolov5\val.py", line 220, in run
preds = non_max_suppression(preds,
File "F:\WorkSpace\GitSpace\yolov5\utils\general.py", line 982, in non_max_suppression
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
File "C:\Users\wan\AppData\Local\Programs\Python\Python39\lib\site-packages\torchvision\ops\boxes.py", line 41, in nms
return torch.ops.torchvision.nms(boxes, scores, iou_threshold)
File "C:\Users\wan\AppData\Local\Programs\Python\Python39\lib\site-packages\torch\_ops.py", line 442, in __call__
return self._op(*args, **kwargs or {})
NotImplementedError: Could not run 'torchvision::nms' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'torchvision::nms' is only available for these backends: [CPU, QuantizedCPU, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradMPS, AutogradXPU, AutogradHPU, AutogradLazy, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
CPU: registered at C:\Users\circleci\project\torchvision\csrc\ops\cpu\nms_kernel.cpp:112 [kernel]
QuantizedCPU: registered at C:\Users\circleci\project\torchvision\csrc\ops\quantized\cpu\qnms_kernel.cpp:124 [kernel]
BackendSelect: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\BackendSelectFallbackKernel.cpp:3 [backend fallback]
Python: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\PythonFallbackKernel.cpp:140 [backend fallback]
FuncTorchDynamicLayerBackMode: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\functorch\DynamicLayer.cpp:488 [backend fallback]
Functionalize: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\FunctionalizeFallbackKernel.cpp:291 [backend fallback]
Named: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\NamedRegistrations.cpp:7 [backend fallback]
Conjugate: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\ConjugateFallback.cpp:18 [backend fallback]
Negative: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\NegateFallback.cpp:18 [backend fallback]
ZeroTensor: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\ZeroTensorFallback.cpp:86 [backend fallback]
ADInplaceOrView: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:64 [backend fallback]
AutogradOther: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:35 [backend fallback]
AutogradCPU: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:39 [backend fallback]
AutogradCUDA: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:47 [backend fallback]
AutogradXLA: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:51 [backend fallback]
AutogradMPS: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:59 [backend fallback]
AutogradXPU: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:43 [backend fallback]
AutogradHPU: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:68 [backend fallback]
AutogradLazy: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:55 [backend fallback]
Tracer: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\autograd\TraceTypeManual.cpp:296 [backend fallback]
AutocastCPU: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\autocast_mode.cpp:482 [backend fallback]
AutocastCUDA: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\autocast_mode.cpp:324 [backend fallback]
FuncTorchBatched: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\functorch\LegacyBatchingRegistrations.cpp:743 [backend fallback]
FuncTorchVmapMode: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\functorch\VmapModeRegistrations.cpp:28 [backend fallback]
Batched: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\BatchingRegistrations.cpp:1064 [backend fallback]
VmapMode: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\VmapModeRegistrations.cpp:33 [backend fallback]
FuncTorchGradWrapper: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\functorch\TensorWrapper.cpp:189 [backend fallback]
PythonTLSSnapshot: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\PythonFallbackKernel.cpp:148 [backend fallback]
FuncTorchDynamicLayerFrontMode: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\functorch\DynamicLayer.cpp:484 [backend fallback]
PythonDispatcher: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\PythonFallbackKernel.cpp:144 [backend fallback]
思路&解决
看了不少博客和文章,总结一下大概是因为CUDA与torch版本不匹配造成的,当前版本:
| 环境、工具 | 版本 |
|---|---|
| CUDA | 11.3 |
| torch | 1.13.1+cu116 |
| torchvision | 0.14.1 |
原先看到说torch可以接受低版本CUDA,由于实在找不到对应版本,先下着凑合用,现在解决不掉,根据文章所述可以通过降低torch版本解决。
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.douban.com/simple
更换版本后的各个环境工具版本:
| 环境、工具 | 版本 |
|---|---|
| CUDA | 11.3 |
| torch | 1.9.0+cu111 |
| torchvision | 0.10.0+cu111 |
成功训练,问题解决,总结一下,torch版本可以低于CUDA环境。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号