

一、场景介绍
假设某次搜索结果中有 100_0000 篇文章,而你的个人收藏中有 10000 篇,如何在短时间内快速识别 100_0000 中哪些是 “已收藏”, 哪些是 “未收藏” ?
二、正常逻辑(双层for 循环)
public class ForEachTest { public static void main(String[] args) { // user book list List<String> ubList = new ArrayList<>(); // book list List<String> bList = new ArrayList<>(); // 收藏的数据条数 int collectionNum = 10000; // 总条数 int total = 100_0000; // 预计要存储的结果,也可以定义在要返回到页面实体的状态中 Map<String, Integer> resMap = new HashMap<>(total); // 初始化 个人中心收藏的数据 Random r = new Random(); for (int i = 0; i < collectionNum; i++) { ubList.add(String.valueOf(r.nextInt(total))); } // 初始化 搜索结果中返回的数据,同时维护一个 个人与文章 相关的状态map // 状态初始结果为 0:“未收藏”, 1:“已收藏” for (int i = 0; i < total; i++) { bList.add(String.valueOf(i)); //如果这个 bList 中存储的是 实体对象,则可以在存入数据的时候,就初始化一个未收藏的状态 resMap.put(String.valueOf(i), 0); } // 记录开始时间 long start = System.currentTimeMillis(); System.out.println("开始..."); //for 双层循环 // 这个是 外大内小 /*for (String b : bList) { for (String ub : ubList) { if (b.equals(ub)) { resMap.put(b, 1); break; } } }*/ // 这个是 外小内大 for (String ub : ubList) { for (String b : bList) { if (b.equals(ub)) { resMap.put(b, 1); break; // 如果这里没有添加 break,则时长为 62秒左右 } } } // 结束时间 long end = System.currentTimeMillis(); // 用时时长 ms System.out.println("耗时 ms: " + (end - start)); } }
注: 在这几次的测试中,都没有涉及内存的消耗与数据准备的时间!
测试数据:
collectionNum: 10000
total : 100 0000
消耗时间:
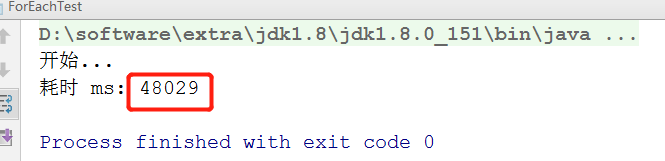
结论:双层 for 循环,遍历了 100亿次,用时 48秒 左右,虽然有随机的成分在内,但是多次测试后,影响并不大!
三、利用 HashMap 底层,减少无效的遍历
public class ForAndMapTest { public static void main(String[] args) { // user book list List<String> ubList = new ArrayList<>(); // book list List<String> bList = new ArrayList<>(); // 收藏的数据条数 int collectionNum = 10000; // 总条数 int total = 100_0000; // 预计要存储的结果,也可以定义在要返回到页面实体的状态中 Map<String, Integer> resMap = new HashMap<>(total); // 初始化 个人中心收藏的数据 for (int i = 0; i < collectionNum; i++) { ubList.add(String.valueOf(i)); } // 初始化 搜索结果中返回的数据,同时维护一个 个人与文章 相关的状态map // 状态初始结果为 0:“未收藏”, 1:“已收藏” for (int i = 0; i < total; i++) { bList.add(String.valueOf(i)); //如果这个 bList 中存储的是 实体对象,则可以在存入数据的时候,就初始化一个未收藏的状态 resMap.put(String.valueOf(i), 0); } // 记录开始时间 long start = System.currentTimeMillis(); System.out.println("开始..."); // 将 个人中心收藏的数据,转化存储到 map 中, // 注意 收藏的文章的id 作为key,value 随意,这里使用同样使用了 id Map<String, String> ubMap = new HashMap<>(); for (String ubId : ubList) { ubMap.put(ubId, ubId); } // 开始遍历 搜索结果中的 100万条数据,是否有被个人收藏过的,有就改变返回的状态。 for (String bId : bList) { // 直接使用 ubMap 的查找key 值是否存在的方式,判断该文章是否已经收藏。 if (ubMap.containsKey(bId)){ resMap.put(bId, 1); } } // 结束时间 long end = System.currentTimeMillis(); // 用时时长 ms System.out.println("耗时 ms: " + (end - start)); } }
测试数据:
collectionNum: 10000
total : 100 0000
消耗时间:
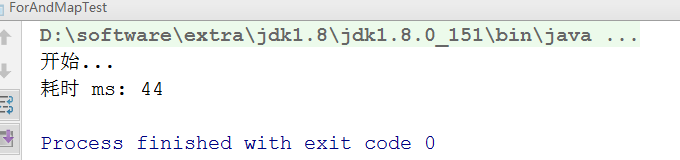
结论:一层循环,加上内部的 hash 计算,用时 44ms
四、总结
条件: 两组数据分别没有重复的数据(id 或者 根据对比的字段不重复,也可以根据业务琢磨,即放在 map 中的 key 值不重复)
需求:对比一组数据中的数据,是否在另一组中有对应的匹配数据
结论:使用 hashmap 的 key值 进行查找,明显快于双层 for 循环,for 循环消耗的时间是 key 值查找的 1000多倍!!!
五、原理解析
1. 双层 for 循环就不需要多解释,纯粹的 10000 x 100 00000 - (break 跳出的累计次数)=< 100 亿 的遍历次数,按平均来算,每次都在 50_0000 的地方跳出,则需要 10000 x 50_0000 = 50亿次 遍历
2. HashMap 快的原因在于将 id 值作为 map 的key存储在map中,而 map 底层是 数组在存储数据,此处不对链表和树结构进行说明。通过计算 id 的 hashcode 值,再与 map 的容量 size 求余数,直接获取到该条数据在 hashMap 中的下标,而不是逐一的去查找数据。故 使用 hashmap 只循环了一次 (10000 + 少量运算),速度明显有所突破。
3. 根据需要控制内存消耗大小,你可以自定义将 数据多的放在 map 或者将数据少的放在 map 中,也就是在控制外层循环的次数,外层大,则占用内存就小,时间上可能会有所增加。
六、缺陷与不足说明
1. 当没有 break 语句的时候,双层 for 循环的循环次数 外层用 w 表示,内层用 n 表示,w > n (外层大于内层循环次数)时,产生了 更长的执行时间,看到了分支优化和 CPU 缓存大小什么的,看不懂。。。
2. 使用HashMap 明显是利用了空间换时间,可能需要考虑业务及设备的问题。
如果有大佬知道有关分支优化,CPU 缓存或者其他见解的,都可以在评论区留言,非常感谢!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号