

SVM理论之线性分类
离上次发博文差不多有一年的时间了,因为一直在准备考研直到4月份才有时间,无奈考研后进入空白期,对专业、技术甚至生活失去了兴趣,部分原因也是没有什么好写
的,现在刚做完毕设,有点积累,就从这里开始吧!希望能尽快找回节奏!
我将从svm理论到应用,分享一下学习经历,文章有很多内容来自文献和网络牛人,后面给出链接。我自己也阅读了好几遍(写得真的很不错),思考后加入了自己的理解,
且作为一系列的学习笔记吧。
相关学科、领域的关系
1、数据挖掘和机器学习:
数据挖掘受到很多学科领域的影响,其中数据库、机器学习、统计学无疑影响最大。简言之,对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析
技术。由于统计学往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据
挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。
从数据分析的角度来看,绝大多数数据挖掘技术都来自机器学习领域,但机器学习研究往往并不把海量数据作为处理对象,因此,数据挖掘要对算法进行改造,使得算法性能
和空间占用达到实用的地步。同时,数据挖掘还有自身独特的内容,即关联分析。
2、模式识别和机器学习:
传统的模式识别的方法一般分为两种:统计方法和句法方法。句法分析一般是不可学习的,而统计分析则是发展了不少机器学习的方法。也就是说,机器学习同样是给模式识别
提供了数据分析技术。机器学习是方法,模式识别是目的。
3、数据挖掘和模式识别:
从其概念上来区分吧,数据挖掘重在发现知识,模式识别重在认识事物。
什么是SVM
SVM是一种分类算法,所以先从分类开始。分类作为数据挖掘领域中一项非常重要的任务,目前在商业上应用最多(比如分析型CRM里面的客户分类模型,客户流失模型,客户
盈利等等,其本质上都属于分类问题)。而分类的目的则是学会一个分类函数或分类模型(或者叫做分类器),该模型能吧数据库中的数据项映射到给定类别中的某一个,从而可以用
于预测未知类别。
下面是一个心脏病的例子:现代医学里可以利用一些比较容易获得的临床指标推断某人是否得了心脏病,假定是否患有心脏病与病人的年龄和胆固醇水平密切相关。比如说医生
可以根据以往病人的临床资料(年龄,胆固醇等),对后来新来的病人通过检测年龄、胆固醇等指标,以此来推断或者判定病人是否有心脏病。而这就是分类(classification)技
术。下表对应10个病人的临床数据(年龄用[x1]表示,胆固醇水平用[x2]表示):

这样,问题就变成了一个在二维空间上的分类问题,可以在平面直角坐标系中描述如下:根据病人的两项指标和有无心脏病,把每个病人用一个样本点来表示,有心脏病者用
“+”形点表示,无心脏病者用圆形点,如下图所示:

很明显的看到,可以在该平面上用一条直线把圆点和“+”分开来的。
svm应用
SVM是由Vanpik领导的AT&TBell实验室研究小组在1963年提出的一种新的非常有潜力的分类技术。它是一种基于统计学习理论的模式识别方法,在解决小样本、非线性及
高维模式识别问题中表现出许多独特的优势,SVM不同于很多只限于实验室研究使用的算法,SVM不仅是学术界非常有力的研究方法,并且广泛运用于商业应用,在文本分类和
手写识别、生物信息学等领域都取得了成功的应用。
线性分类
(1)分类问题定义
一般使用X表示输入空间,Y表示输出域。通常X∈Rn,对于两类问题,Y = {-1, 1};对于多类问题,Y = {1,2,…,m}; 训练集是训练数据(样本)的集合,通常S=((x1,y1),..(xn, yn))
此时也等价于给函数g(x)附加一个符号函数sgn(),即f(x)=sgn [g(x)]是我们真正的判别函数。如果 g(x)=0,则很难办了,分到哪一类都不是。事实上,对于 g(x)的绝对值很小的
(1)分类问题定义
一般使用X表示输入空间,Y表示输出域。通常X∈Rn,对于两类问题,Y = {-1, 1};对于多类问题,Y = {1,2,…,m}; 训练集是训练数据(样本)的集合,通常S=((x1,y1),..(xn, yn))
∈(X×Y)n,其中n是样本数目,xi是样本(向量),yi是它们的标记。
(2)线性判别函数
线性函数:在一维空间里就是一个点,在二维空间里就是一条直线,三维空间里就是一个平面,如果不关注空间的维数,这种线性函数还有一个统一的名称——超平面(Hyper Plane)。
(2)线性判别函数
线性函数:在一维空间里就是一个点,在二维空间里就是一条直线,三维空间里就是一个平面,如果不关注空间的维数,这种线性函数还有一个统一的名称——超平面(Hyper Plane)。
由x的各个分量的线性组合而成的线性函数 :
g(x) = wT•x + b (参数w是权重向量、b是偏置向量;w、x都为n维向量,b为实数). (1)
方程g(x)=0 (2)
定义了一个判定面(分类面),它把归类于C1的点与归类于C2的点分开来。当x1和x2都在判定面上时,有g(x1)=g(x2)即w T •x 1 + b = w T •x2 + b ,故 w T •(x 1– x2 )=0 ,这表明w和超平面上任意向量正交,并称w为超平面的法向量。
两类情况:对于两类问题的决策规则为
• 如果g(x)>0,则判定x属于C1,
• 如果g(x)<0,则判定x属于C2;
两类情况:对于两类问题的决策规则为
• 如果g(x)>0,则判定x属于C1,
• 如果g(x)<0,则判定x属于C2;
此时也等价于给函数g(x)附加一个符号函数sgn(),即f(x)=sgn [g(x)]是我们真正的判别函数。如果 g(x)=0,则很难办了,分到哪一类都不是。事实上,对于 g(x)的绝对值很小的
情况(即接近超平面的点),我们都很难处理,因为细微的变动(比如超平面稍微转一个小角度)就有可能导致结果类别的改变。理想情况下,我们希望 g(x) 的值都是很大的正数
或者很小的负数,这样我们就能更加确信它是属于其中某一类别的。
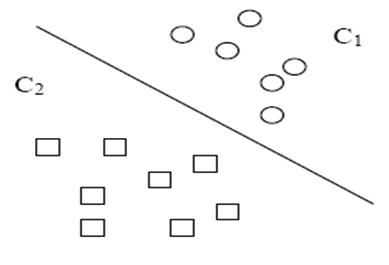 图1
图1
线性不可分:本属于某一类的点跑到另一类(分类面的另一侧),即存在离群点。
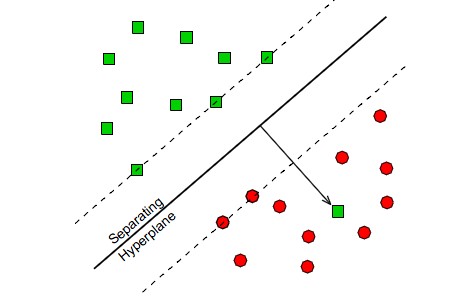 图3
图3

(3)线性可分与不可分
线性可分:若存在一线性函数能够把两类点完全分开。称此训练集为线性可分的。
定义一个点到某个超平面的函数间隔(functional margin):γf=yi(w T •xi+b) 。由两分类问题可知,γf总大于0. 考虑w和b,如果同时加大w和b,比如在 前面乘个系数比如2,
定义一个点到某个超平面的函数间隔(functional margin):γf=yi(w T •xi+b) 。由两分类问题可知,γf总大于0. 考虑w和b,如果同时加大w和b,比如在 前面乘个系数比如2,
那么所有点的函数间隔都会增大二倍,这个对求解问题来说不应该有影响,因为我们要求解的是 ,同时扩大w和b对结果是无影响的。这样,我们为了限制w和b,可能需要加入
归一化条件,毕竟求解的目标是确定唯一一个w和b,而不是多组线性相关的向量。现在把w和b进行一下归一化,即用 与
与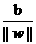 分别代替原来的w和b,那么间隔就可以写成
分别代替原来的w和b,那么间隔就可以写成
 与
与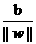 分别代替原来的w和b,那么间隔就可以写成
分别代替原来的w和b,那么间隔就可以写成γg =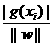 ,此时称γg为几何间隔(geometrical margin),它就是解析几何中点xi 到直线g(x)=0的距离公式(推广则是到超平面g(x)=0的距离, g(x)=0就是上面提到的分类
,此时称γg为几何间隔(geometrical margin),它就是解析几何中点xi 到直线g(x)=0的距离公式(推广则是到超平面g(x)=0的距离, g(x)=0就是上面提到的分类
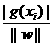 ,此时称γg为几何间隔(geometrical margin),它就是解析几何中点xi 到直线g(x)=0的距离公式(推广则是到超平面g(x)=0的距离, g(x)=0就是上面提到的分类
,此时称γg为几何间隔(geometrical margin),它就是解析几何中点xi 到直线g(x)=0的距离公式(推广则是到超平面g(x)=0的距离, g(x)=0就是上面提到的分类超平面)。
注:|w||叫做向量w的范数,范数是对向量长度的一种度量。向量w=(w1, w2, w3,…… wn),它的p-范数为||w||p = (w1p+w2p+…+wnp)
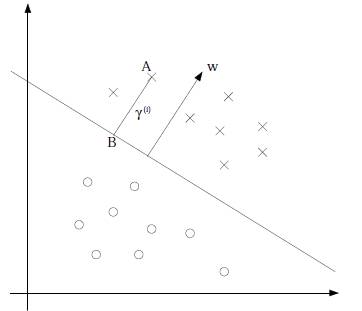

图2
归一化的几何意义:
如图所示,假设我们有了B点所在的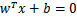 分割面。任何其他一点,比如A到该面的距离以γ表示,假设B就是A在分割面上的投影。我们知道向量BA的方向是 w
分割面。任何其他一点,比如A到该面的距离以γ表示,假设B就是A在分割面上的投影。我们知道向量BA的方向是 w
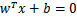 分割面。任何其他一点,比如A到该面的距离以γ表示,假设B就是A在分割面上的投影。我们知道向量BA的方向是 w
分割面。任何其他一点,比如A到该面的距离以γ表示,假设B就是A在分割面上的投影。我们知道向量BA的方向是 w(分割面的梯度),单位向量是 。设A为x,B为x0(x、x0都是向量),向量BA = x-x0 = γ . 又由于 x0 是超平面上的点,满足 f(x0)=0 ,代入超平面的方程,
。设A为x,B为x0(x、x0都是向量),向量BA = x-x0 = γ . 又由于 x0 是超平面上的点,满足 f(x0)=0 ,代入超平面的方程,两边同乘||w||,又wTw=||w||2,即可算出γ= =
=  。这里的 γ 是带符号的,我们需要的只是它的绝对值,类似地,也乘上对应的类别 y
。这里的 γ 是带符号的,我们需要的只是它的绝对值,类似地,也乘上对应的类别 y
 =
=  。这里的 γ 是带符号的,我们需要的只是它的绝对值,类似地,也乘上对应的类别 y
。这里的 γ 是带符号的,我们需要的只是它的绝对值,类似地,也乘上对应的类别 y
γg = yγ = 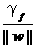 . (3)
. (3)
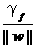 . (3)
. (3)即函数间隔归一化结果就是几何间隔。
线性不可分:本属于某一类的点跑到另一类(分类面的另一侧),即存在离群点。

参考:《支持向量机导论》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号