从CK+库提取标记点信息
1.CK+动态表情库介绍
The Extended Cohn-Kanade Dataset(CK+)
这个数据库是在 Cohn-Kanade Dataset 的基础上扩展来的,发布于2010年。这个数据库比起JAFFE 要大的多。而且也可以免费获取,包含表情的label和Action Units 的label。
这个数据库包括123个subjects, 593 个 image sequence,每个image sequence的最后一张 Frame 都有action units 的label,而在这593个image sequence中,有327个sequence 有 emotion的 label。这个数据库是人脸表情识别中比较流行的一个数据库,很多文章都会用到这个数据做测试。
In this Phase there are 4 zipped up files. They relate to:
下载数据库后有以下四个文件
1) The Images (cohn-kanade-images.zip) - there are 593 sequences across 123 subjects which are FACS coded at the peak frame. All sequences are from the neutral face to the peak expression.
2) The Landmarks (Landmarks.zip) - All sequences are AAM tracked with 68points landmarks for each image.
3) The FACS coded files (FACS_labels.zip) - for each sequence (593) there is only 1 FACS file, which is the last frame (the peak frame). Each line of the file corresponds to a specific AU and then the intensity. An example is given below.
4) The Emotion coded files (Emotion_labels.zip) - ONLY 327 of the 593 sequences have emotion sequences. This is because these are the only ones the fit the prototypic definition. Like the FACS files, there is only 1 Emotion file for each sequence which is the last frame (the peak frame). There should be only one entry and the number will range from 0-7 (i.e. 0=neutral, 1=anger, 2=contempt, 3=disgust, 4=fear, 5=happy, 6=sadness, 7=surprise). N.B there is only 327 files- IF THERE IS NO FILE IT MEANS THAT THERE IS NO EMOTION LABEL (sorry to be explicit but this will avoid confusion).
The Images (cohn-kanade-images.zip)图片库中包含了从平静到表情表现峰值的图片,实际使用中建议使用比较明显的图片,并进行相应的预处理。
Emotion_labels.zip标签压缩包中
0-中性
1-愤怒
2-蔑视
3-厌恶
4-恐惧
5-高兴
6-悲伤
7-惊讶
2.特征点分析
因为我们自己建立的表情库是用RealSense摄像头采集的,我们想验证我们的识别方法在在CK+库上的识别效果,所以需要做的是对CK库进行特征点提取。
在提取之前我们先要分析CK库中特征点的ID,这样方便我们找到RealSense中对应的点。
选择CK库中的一张图片,读数据,将标记点在图片中画出来。
1 def drawLandmarkPoint(img,color): 2 draw = ImageDraw.Draw(img) 3 myfont = ImageFont.truetype("C:\\WINDOWS\\Fonts\\SIMYOU.TTF", 10) 4 5 file_txt = open("S035_003_00000001_landmarks.txt", "a+") 6 lines = file_txt.readlines() 7 t=1 #特征点标号 8 for line in lines: 9 line_object=line.split(" ") 10 x=float(line_object[3]) #原始数据是科学记数法,这里转换成浮点型 11 y=float(line_object[-1]) 12 print x,y 13 #draw.ellipse((0, 0, 200, 200), fill="red", outline="red") 14 draw.text((x,y), bytes(t), font=myfont, fill=color) 15 t+=1 16 file_txt.close()
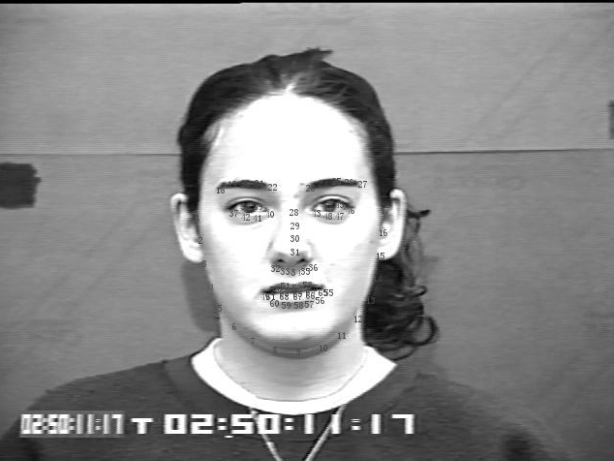
CK库中的标记点共有68个。
3.特征点转换CK_to_RealSense
可以看出特征点的顺序和RealSense是不一样的。相比RealSense的78个标记点,CK+中只有68个,且CK库中有几个点RealSense中没有,所以,我们最后存下来的点在66个。
转化之后主要缺失的点是眉毛下眉的2x3=6个点,左右眼睛2x2=4个点。
多出的2个点是鼻子2侧,CK有5个,RealSense只有3个。所以最后保存了66个点。
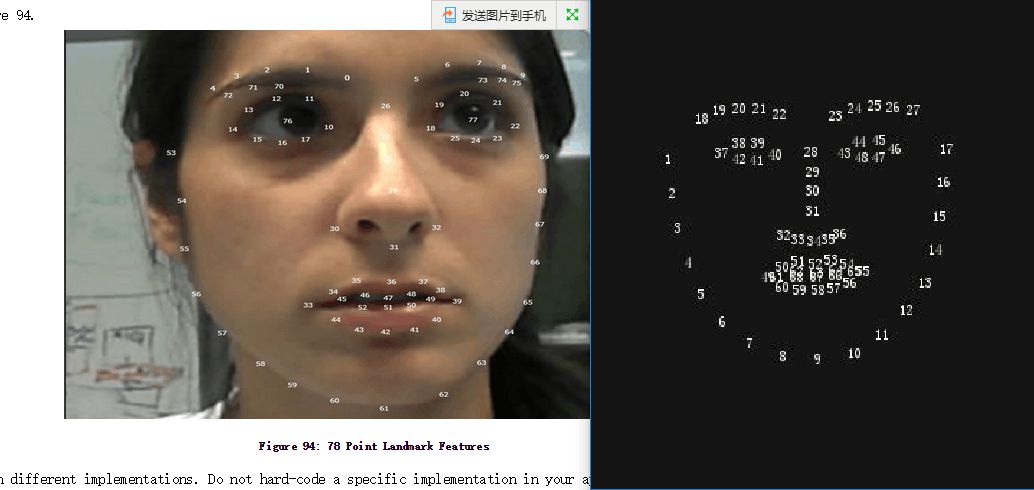
在程序里面建立元祖,标注转化的对应关系。
依次是,左眉,右眉,左眼,右眼,鼻子,外嘴唇,内嘴唇,脸轮廓
1 #将ck点转换成realsense的点 r:ck 共66个点。 2 CK_to_RealSense={0:22,1:21,2:20,3:19,4:18, 3 5:23,6:24,7:25,8:26,9:27, 4 10:10,11:39,12:38,14:37,16:42,17:41, 5 18:43,19:44,20:45,22:46,24:47,25:48, 6 26:28,27:29,28:30,29:31,30:32,31:34,32:36, 7 33:49,34:50,35:51,36:52,37:53,38:54,39:55,40:56,41:57,42:58,43:59,44:60, 8 45:61,46:62,47:63,48:64,49:65,50:66,51:67,52:68, 9 53:1,54:2,55:3,56:4,57:5,58:6,59:7,60:8,61:9,62:10,63:11,64:12,65:13,66:14,67:15,68:16,69:17 10 } 11 RealSenseID=[0,1,2,3,4, 12 5,6,7,8,9, 13 10,11,12,14,16,17, 14 18,19,20,22,24,25, 15 26,27,28,29,30,31,32, 16 33,34,35,36,37,38,39,40,41,42,43,44, 17 45,46,47,48,49,50,51,52, 18 53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69 19 ]
4.进行处理
CK+库中的动态表情是通过动态序列来展示的,所以一个表情会有多张图片,需要的是将一个表情的多张图片进行处理,提取特征点信息,然后存到一个txt中,表现出动态的变化。
所以open操作的模式要写成
fCK_image = open(CKDataDir, "a"),可以多次写入,这样对同一个目录下多个图片的数据写入一个文件。
1 def readFile(filepath): 2 f1 = open(filepath, "r") 3 nowDir = os.path.split(filepath)[0] #获取路径中的父文件夹路径 4 fileName = os.path.split(filepath)[1] #获取路径中文件名 5 #对新生成的文件进行命名的过程 6 CKDataDir = os.path.join(nowDir, "CKData.txt") 7 8 fCK_image = open(CKDataDir, "a") 9 fCK_image.write(os.path.splitext(fileName)[0]+"\t") 10 11 lines = f1.readlines() 12 for n in range(0,66): 13 #for n in range(1, lines_count+1): 14 line = lines[CK_to_RealSense[RealSenseID[n]]-1] 15 line_object = line.split(' ') 16 17 id=RealSenseID[n] 18 if n==63: 19 time=4 20 image_x = float(line_object[3]) 21 image_y = float(line_object[-1]) 22 pointData = bytes(id) + "\t" + bytes(image_x) + "\t" + bytes(image_y) +"\t" 23 fCK_image.write(pointData) 24 print pointData 25 26 fCK_image.write("\n") 27 f1.close() 28 fCK_image.close() 29 30 global picturecount 31 picturecount+=1
5.递归批量处理数据
对CK库中,标记点的文件夹进行递归操作。
需要注意的是,打开文件操作的时候,需要在路径前面加上字符r。
eachFile(r"E:\RealSense\CK+\Landmarks_track")
因为在过程中存在这样的路径,里面有\0,程序会认为是这个字符串结束了,然后运行不下去。
E:\RealSense\CK+\Landmarks\S010\001\S010_001_00000001_landmarks.txt
1 def eachFile(filepath): 2 global emotioncount 3 4 pathDir = os.listdir(filepath) #获取当前路径下的文件名,返回List 5 for s in pathDir: 6 newDir=os.path.join(filepath,s) #将文件命加入到当前文件路径后面 7 if os.path.isfile(newDir) : #如果是文件 8 if os.path.splitext(newDir)[1]==".txt": #判断是否是txt 9 readFile(newDir) #读文件 10 pass 11 else: 12 eachFile(newDir) #如果不是文件,递归这个文件夹的路径 13 emotioncount += 1
最后的将处理的图片数量和表情个数打印输出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号