Wind Simulation in 'God of War'(GDC2019 战神4风力场模拟)
Wind Simulation in 'God of War'(GDC2019)

战神4中的风力场模拟
这次带来的分享的主题是,圣莫妮卡工作室他们在战神4中关于GPU模拟风力场。
演讲者Rupert Renard 12年游戏行业开发经验,参与过战神4,塞尔达传说,质量效益3等大作。
0.What Wind is Used For
风在游戏中能带来什么?

通常情况线下,风可以是一个简单的正弦波,影响物体的摆动,但是为了创造一个更生动的世界,战神4写了一套完善的风力系统,可以作用的对象包括
- 粒子
- 头发
- 树叶
- 皮毛
- 声音系统
- 布料
这里的头发,树叶,皮毛,被集成在另一个系统中,子系统中处理局部空间的扰动。
风的强弱可以烘托环境氛围,营造气氛。
1.CPU Origins

CPU上流体模拟的传统方法,03年GDC上有一篇经典文章 “Real-Time Fluid Dynamics for Games”,主要是在不影响流体表现的前提线下,通过简化流体表达方程提高计算速度。
那篇论文提到了方法,计算过程主要是 通过密度(density)添加力(add force),结合流体本身的扩散(diffuse),达到流体的效果(move),解决 boundary issues(边界问题),会在bound box 外面再包一层,论文地址
但是战神他们觉得现在都9012了,为啥不用一些更先进的其他方法去尝试呢
2.Wind Tiers
风的类型和级别

三种风的类型:
- Static Wind
- Dynamic Wind
- Counter Wind
静态风:静态风是一个全局的风,均匀地应用于场景中的所有物体。它可以随着时间的推移而改变,也可以随着玩家在世界各地的移动而改变。有时会用scrolling noise texture 来做静态风。
动态风:动态风是他们的重点,作用范围是在玩家周围形成一个3D立体的空间,并随着玩家的移动而移动的。
逆风:逆风是其实是一个机制,用来模拟在风中移动的物体,是否受到风的影响。
如果一个物体的运动速度和方向与静态风或动态风大致相同,就会抵消风的作用,并给出物体不受风影响的表现。
SampleWind(object) := StaticWind + DynamicWind[object.position] - object.velocity
公式也比较好理解。
风的影响的采样公式 = 全局静态风一个vector3 + 动态风场中物体位置的风采样 - 物体的移动速度vector3
3.Dynamic Wind Details
动态风详解

用32x16x32 的三维纹理来存, 每立方米 一个纹理单位。 为了在GPU上快速方便的模拟风的计算,选择了标准的三维纹理volume,而没有使用层次化的volume。
战神的动态风场在玩家周围也足够大,能包含斧头扔出去的距离。所以他们的动态风场xz是比y大一倍的。
使用每帧5次的迭代,没有什么特别愿意,只是刚好找到了一个比较balance的值。
风的产生设计了不同类型的“发动机”,用来给风场注入速度。
战神里面的Advection 对流提供了,正向和反向的2种,他们强烈建议别图便宜只搞一种,后面会说原因。
他们尝试过用压强来模拟风场,但是他们的美术不喜欢,而且压强有个弊端,就是不能是负的。但是压强他们也做了,把压强做为一个额外的使用参数
4.Storage

每个属性都有单独的三维纹理,x的速度,y的速度,z的速度

关于三维纹理的切片方向也有讲究,他们选择的是xz轴的切片。(据说,这样做在计算的更高效,因为很多时候风的流向都是水平运动)
5.Diffusion
风的扩散。

随时间推移,某个cell会对周围的cell产生影响。可以理解成是使流体模拟达到平衡的一种机制。它被用来在相邻的cell之间传递能量。
这来的扩散就用到了 double的buffer,2个buffer交替存数据。
验证之后发现将速度属性分成三个单独的三维纹理,计算的时候尤其高效。
是因为如果不分离的话,在计算风的迭代的时候,xyz三个方向全部计算完成之后,才能进行下次的迭代。但其实这三个方向的计算,发生在不同迭代轴上,是互不影响的
看着2张图就能看出来。

先解释下VGPR。
AMD GCN 计算单元中, 一个GCN计算单元(CU),包含四个SIMDs(单指令流多数据流),每一个包含一个包含32位的VGPRs(矢量通用寄存器)的64KB寄存器文件
着色器最终处理每个线程的带宽更少,这是因为每个线程的数据更少,这意味着每个线程的VGPR更少,这意味着更好的占用潜力。
对于希望异步运行的着色器,更少的VGPRs也是非常好的选择
好处是,GPU在计算迭代的时候,更少的等待时间。
对于希望异步运行的shader,更少的VGPRs也是非常好的选择
6.Motors
风力发动机

6种不同类型的Motors
- Directional 平行风 (类似unity WindZone里的Directional)
- Omni 全向风 (类似unity里的Spherial)
- Vortex 旋涡,沿某个轴产生风
- Moving 运动发动机,锥形,可以理解成发动机在运动,产生风场是锥形扩散的
- Cylinder 圆柱的上下面可以大小不一样
- Pressure 直接就是压强
当时面临的一个挑战就是不同类型的Motor混合时候,互相作用
// 平行风,out返回float3的velocity
void ApplyMotorDirectional(in float3 cellPosWS, uniform MatorDirectional motorDirectional, in out float3 velocityWS)
{
// 计算cell到motor的距离
float distanceSq = lengthSq(cellPosWS - motorDirectional.posWS);
// 距离的平方小于motor的作用范围,加上速度
// force = direction * strength * deltaTime
if(distanceSq < motorDirectional.force)
velocityWS += motorDirectional.force;
}
// 全向风,作用朝四面八方,辐射出去,存在作用半径radius
void ApplyMotorOmni(in float3 cellPosWS, uniform MotorOmni motorOmni, in out float3 velocityWS)
{
// force = strength * deltaTime
float3 differenceWs = cellPosWS - motorOmni.posWS;
float distanceSq = lengthSq(differenceWs);
// 速度受到作用半径和距离的影响
if(distanceSq < motorOmni.radiusSq)
velocityWS += motorOmni.force * rsqrt(distanceSq) * differenceWs
}
// 螺旋风
void ApplyMotorVortex(in float3 cellPosWS, uniform MotorVortex motorVortex, in out float3 velocityWS)
{
// force = strength * deltaTime
float3 differenceWs = cellPosWS - motorVortex.posWS;
float distanceSq = lengthSq(differenceWs);
// 速度受到作用半径和螺旋风轴向叉乘的影响
if(distanceSq < motorVortex.radiusSq)
velocityWS += motorVortex.force * cross(motorVortex.axis, rsqrt(distanceSq) * differenceWs)
}
和unity里的WindZone做一个简单对比,
unity中3D 在 Game Object > 3D Object > Wind Zone,提供了wind zone,但是类型较为单一,只提供了Direction和Spherical两种,差不多等价于战神里的 Directional 和 Omni。
unity主要还是用压强来实现的,暴露的参数,Main(强度)近似战神Motor类型中的force。
7.Advection
平流(或者叫水平对流)
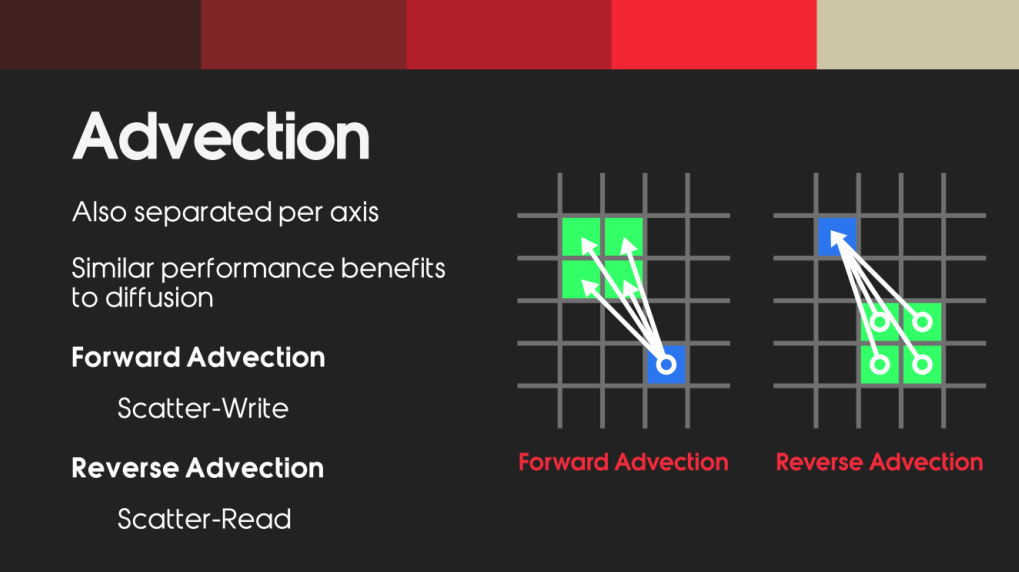
是基于速度传递能量的过程,发生在纹理和纹理之间,可以用来传播速度属性。
通过平流 来传播速度,模拟能量的流动。
处理平流可以处理diffusion扩散一样,按轴进行分离,减少等待时间。
但是会存在一个问题,在做迭代的时候, 正向和反向的会同时对数据读写,写入数据的时候发生数据争抢。多线程的时候可能同时有不同的线程在往texel纹理中写数据。
8.Spin Compare & Exchange
交换比较

多线程运作的时候,纹理写入,因为内存可见性的原因,不是原子运算,可能最后返回的结果有偏差。
举个简单的例子开多线程 执行i++ 1000次,最后返回的结果不一定是1000,是一样的原因。
简单解释下,多线程线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。
这里用到的解决方法是多线程里面常见的CompareExchange,函数差不多是这样的
CompareExchange(Double, Double, Double)
void SpinCompareExchange(uniform RWTexture3D<float> rwTex, uniform unit3 rwTexSize, in unit3 coord, in float value)
{
if(all(coord < rwTexSize))
{
float curVal = 0;
for(;;)
{
float oldVal, newVal = curVal + value;
InterlockedCompareExchange(rwTex[coord], curVal, newVal, oldVal);
if (curVal == oldVal)
break;
curVal = oldVal
}
}
}
把目标操作数(第1参数所指向的内存中的数)与一个值(第3参数)比较,如果相等,则用另一个值(第2参数)与目标操作数(第1参数所指向的内存中的数)交换
整个操作过程是锁定内存的,其它处理器不会同时访问内存,从而实现多处理器环境下的线程互斥。
这个地方可以直接参考MSDN compareExchange函数的api
9.Atomic Add

定长操作。上一页提交浮点型在比较的时候,硬件没法对浮点型进行原子运算。所以战神换了个思路,损失一定精度,转化成定长的浮点(或者说是定点),16.16,上下都保证一定的精度。
也叫fixed-point number,定点数的计算效率是比浮点数更高的
wiki上解释是:
定点数类型的值其实就是个整数,需要额外做比例进位,进多少位需要根据具体的定点数类型决定。例如 1.23 使用 1/1000 比例的定点数表示时是 1230;1,230,000 使用 1000 比例的定点数表示也是 1230。与浮点数不同,相同类型的定点数中所有值的缩放系数都是一致的,在计算过程中也保持不变。
缩放系数通常是 10 或 2的幂,前者方便人类读写,后者易于高效计算。不过有时也会使用其它比例,例如可以用 1/3600 的比例的定点数来表示以小时为单位的时间值,可以精确到秒。
定点数的最大值,可以通过将其内部所使用的整数的最大值乘以缩放系数求得,最小值同理。
浮点数的精度是有尾数位决定的,正常单精度float,双精度double的小数位如下:
float:
1bit(符号位) 8bits(指数位) 23bits(尾数位)
double:
1bit(符号位) 11bits(指数位) 52bits(尾数位)
他们把小数位按16位算精度,转换成int,在做原子加的操作。
// float转int要乘的宏
# define FXDPT_SIZE(1<<16)
void AtomicAdd(uniform RWTexture3D<int> rwTex, uniform unit3 twTexSize, in unit3 coord, in float value)
{
if(all(coord < rwTexSize))
{
InterlockedAdd(rwTex[coord], (int)(value * FXDPT_SIZE));
}
}
10.Scheduling
调度算法以及耗时。

风力模拟,在GPU管线上是第一次做的事,模拟差不多耗时0.1ms。
模拟的过程本身也是异步的,和渲染物体,渲染粒子,并行。

蓝色表示扩散,红色是Motor相关,橘色是正向对流初始化的一些过程,黄色开始计算正向对流,后面是反向平流,最后紫色导出,方便gpu和cpu访问。
整个过程VGPR和SGPR都很低,适合并行运算。
diffuse进行了5次,耗时43.2ms,平均一次8ms,这是因为使用了分离轴的技巧(3个轴互不影响分离计算)。这种方法,如果使用更大的Volume,性能的提高会更加明显。
后面他们觉得forward平流和reverse评论在setup的阶段,可以用buffer来记录之前的数据,空间换时间,差不多又节约了10ms左右。
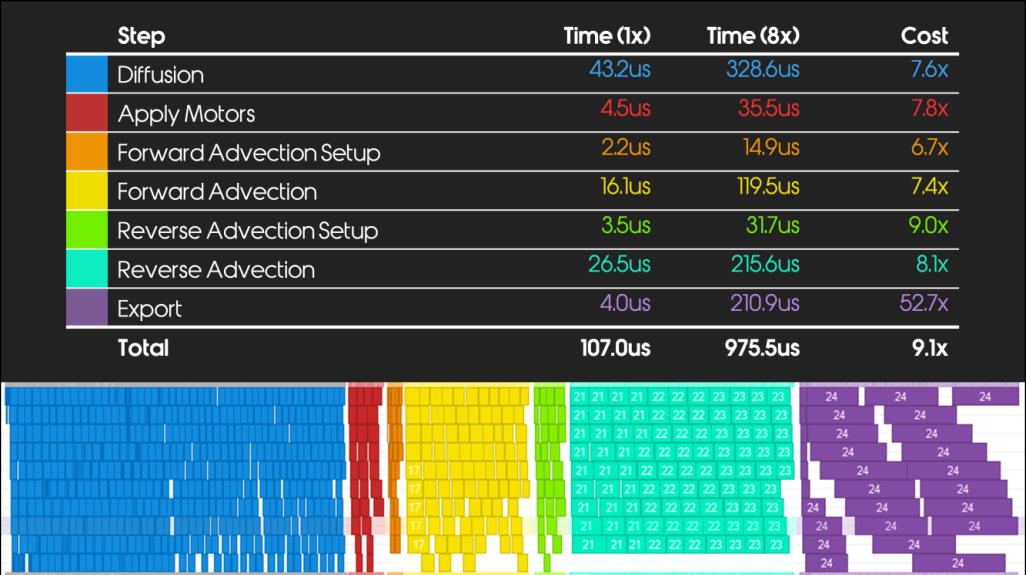
他们还做了一个实验,把每个轴的size扩大一倍,等于整体体积扩大了8倍。
实验结果可以看出来,最后一列是耗时,可以看出差不多都是7,8倍的样子,说明耗时和数据量基本线性相关,只有export导出的部分耗时增多,演讲者说可能是纹理寻址的问题。
11.Timing-Full Frame
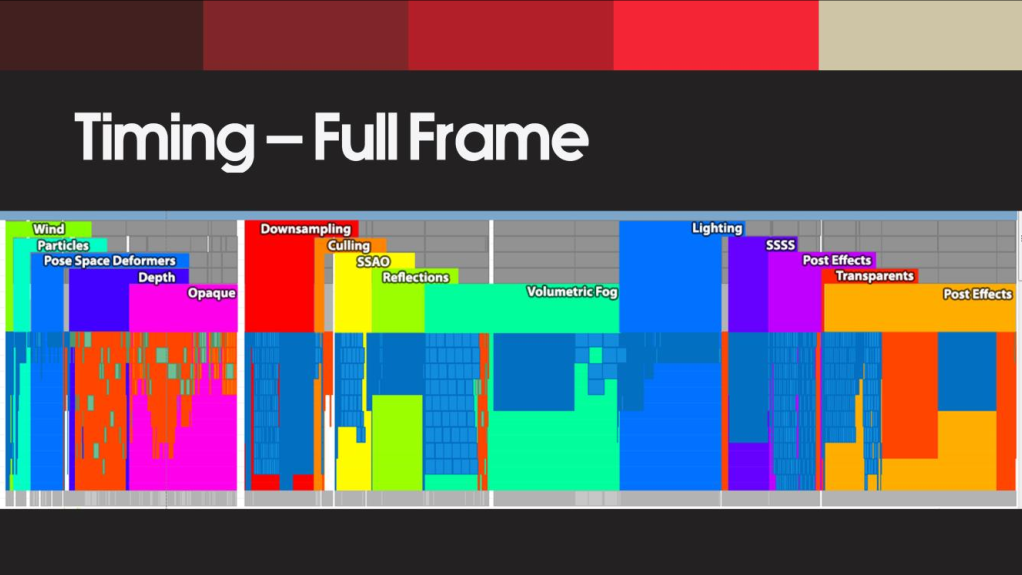
这张图展示了战神 一帧绘制各部分的耗时,其实wind的耗时所占的比重很小,上面下那是的是异步并行的耗时,
12.Debugging
战神他们团队的debug工具真是完善,

- 可视化2D的切面
- 可以用向量更改wind的属性
- 粒子发射器
- 锁定volume位置
- volume中风力的采样和显示
可视化3D volume风场和2D的风 切面是最直接有效的。可以很方便美术去布风,看效果,也方便程序去debug。图中绿色的是一个directional motor(定向风发动机)。
奎爷的斧头也是一个Moving Motor,扔出去之后也会产生风影响周围的环境。


采样方法也分了2种:一种是均匀时间间隔,在固定距离间隔的位置采样,然后绘制矢量图标,表示风力;另一种是直接用矢量图标表示风力,越密集表示风强度越大。
13.Wind Customers

因为模拟的结果,不仅仅是GPU用,CPU布料和声音的系统也会用到,CPU和GPU通信又不叫耗,战神用了一个比较能接受的方法,把速度属性xyz,存成RGB16的 double buffer texture。保证流畅性,CPU上布料和声音系统读取的是上一帧GPU返回的结果。
14.Beaufort scale
蒲福風級,Beaufort风力等级。就是几级风力等级。

可以参考wiki Beaufort风力等级
0到12的等级,0代表没有风,12代表飓风的力量。比如能听到树叶的嗦嗦的声音,差不多是风力2级,地面差不多2m/s。
小树摇摆,差不多5级风,地面9m/s。 这等于把游戏中的风和现实世界关联上了,这样更具有真实性。
15.Conclusion

- 风的模拟使游戏更加生动
- 高性能和低消耗也是可以实现的
- 正向平流和反向一定要同事使用
- 好的debug工具可以事半功倍

相比2003的方法,战神把流体风的模拟放到了GPU上,更好的发挥了硬件GPU并行计算的性能,有更高的质量。
后面就是他安利大家去听他同事Sean的 Interactive Wind and Vegetation in God of War,讲植被和风交互,会详细介绍客户端表现,包括在Vertex Shader上风是怎么影响物体的,还有双高度场的草场交互。
个人总结
最后谈一下,自己的一点点小感想。
战神他们的对风力场的创新,是相当于把原来一直CPU上做的一件事件,放到了GPU上,做到了并行高效的效果。
多线程部分,并行的一些思想,原子操作等等。
计算的时候用定点数,相比浮点数,提交运算效率
最后他们的debug工具真是完善呀,开发效率高,调试效率高。实名羡慕...
参考文献
1.Wind Simulation in God of War
2.Introduction to Fixed Point Number Representation(berkeley.cs61c)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号