HIT Software Construction Lab 5_经验总结
前言:
终于写完lab5了,这次lab5是基于lab3的一次实验,主要是王忠杰老师提供了4个大约有50w行的大文件让我们根据自己所选应用读取其中两个并且创建轨道系统。
这次lab5优化的我很崩溃,因为我lab3虽然设计模式都用了,但是是冲着“能跑就行”去做的,完全没有考虑性能的问题,而且lab 3已经过去将近一个月了,我完全想不起来我之前lab3是怎么写的,而且之前为了赶进度没有写注释,写lab5的时候就各种猜自己之前是怎么想的……
这次lab 5的内容很杂,有利用strategy模式实现三种读写策略,有利用各种命令、工具分析程序性能,有针对性能的优化等等,我这次总结经验主要是性能优化的经验。
优化过程
TrackGame性能优化
一开始TrackGame我全都是用List实现的,List是O(n)复杂度,这就意味着如果要在List中用contains()方法的话计算机要从第一个元素一直check到要找的那个元素,对于50w这个量级的数据量来说,实在是太吃性能了。于是我做出了一个疯狂的决定——重构我的代码,把所有List存的并且需要查找操作的东西全部换成Set和Map,同时要做一个开关,将我的checkRep和checkException都关闭,不然这样check一下我连读文件都要12分钟。
最核心的部分就是重构生成比赛规则的代码了
public interface GameStrategy<L,E> {
public List<List<E>> generateGame(List<E> PhysicalObjects, List<Track> tracks);
}
生成比赛规则我使用的是strategy模式,最上层有一个接口GameStrategy,我比赛的方案是使用一个双层List来存储,外层List代表的是这个文件生成的所有的比赛方案,内层List代表的是单场比赛生成的比赛方案。这对于性能来说就很恐怖了,两个List套在一起简直就是灾难。我跑那个大文件根本跑不出来……
于是我把内层的List换成了Map,将轨道和运动员映射起来,这样我往里面装的时候就是Hash映射,是O(k)的复杂度,对于50w这个量级的数据来说,简直是天壤之别。
A Thousand Years Later
经过漫长的debug,我的程序的第一版重构出现了,大概要跑15分钟,我觉得还是太慢,肯定还有地方可以优化
在安排比赛策略的时候首先要对运动员的最好的成绩进行排序按照成绩从好到坏进行排序,然后选择最中间的轨道,依次向两边扩展地安排运动员比如:
假设有五名运动员和五个轨道,对运动员根据成绩进行排序
首先安排第一个运动员到第三条轨道上,第二个运动员安排到第二条轨道上,第三个运动员安排的第四个轨道上等等,以此类推。
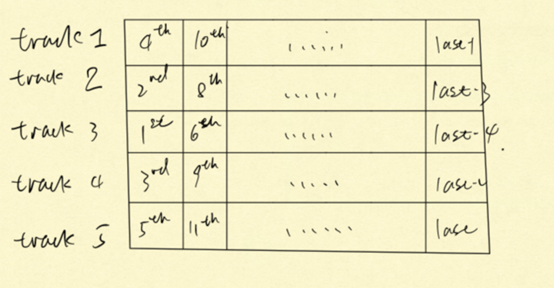
如图所示。
然后分组的时候将每一个list中位于同一位置的人划分到一个组
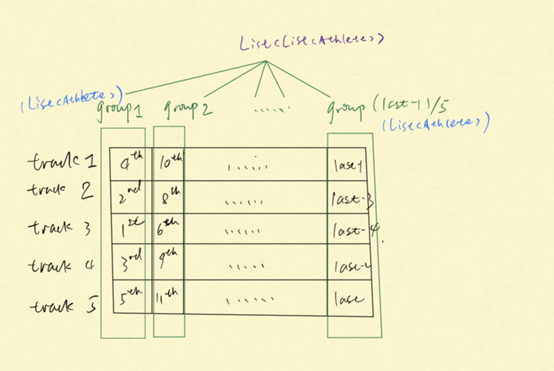
我直接把实验三我的报告的图给贴过来了,把内层的list换成Map就行了
这样就有一个很大的问题,对于50w的数据量来说,我把这么大的数据先存储到一个数据结构中(List<Map<>>),然后再从这个数据结构往外搬到其他的数据结构中(一个个Map<>),会导致我做了太多的无用功,我完全可以直接就在每个小的Map中为每个运动员找到一个位置,反正我之前将运动员安排到这个List<Map<>>中也是按照轨道中的顺序一个个安排的,一步到位,省去中间的步骤
A Thousand Years Later
经过漫长的debug之后,我的程序重构来到了第二版,我的程序时间来到了8分钟,相比于之前一个小时都跑不出来,已经是很大的进步了
然后我听到了一个令人窒息的消息,隔壁寝室大佬构造TrackGame居然只有3秒??
不行,我不甘心,我继续找我的程序的漏洞~
然后我又找到了一个很吃性能的东西,叫做defensive copy。我读文件是专门的用一个类Reader来实现,然后这个类中有很多数据结构,比如List<athleteName>, List<athleteAge>,然后我构建的时候从这个Reader获取这些数据结构来构建,这里我返回的是defensive copy,50w的数据量拷贝那么多次,这简直就是黑洞。我很想就直接返回引用,但是我又害怕rep exposure,不能为了性能连安全性都不要吧,这太不elegant了。然后我突然想到了老师上课好像讲了一个可以把Collections的实现类转换成不可变的一个方法,那是在mutable/immutable讲的,距离现在大概有1万年了,找了500年的ppt之后,我终于找到了这个东西:
Collections.unmodifiableList/Map/Set
这简直就是性能救星,反正我都是observer类型的方法,对于这些数据我不需要mutator方法,所以我就将defensive copy改成了unmodifiableList/Map/Set
我的trackGame重构第三版诞生了,现在它也只需要3秒就能构建出来了~
sociaNetworkCircle重构
本来我是不想重构这个东西的,但是老师在群里说了,三个应用都要优化,第二个应用因为没什么好优化的可以不用管。我昨天晚上连晚饭都没吃把它优化出来了。
优化构建socialNetworkCircle时筛选relation的算法
我是用lab2的graph和friendshipGraph作为跳板来实现的,因为我觉得getDistance()简直为这个应用量身定做,每个人位于socialNetworkCircle的第几层直接一个getDistance()就可以得到了,但是同时,getDistance()也是一个性能黑洞,因为他做了太多不必要的广搜,其实每次我只需要得到距离为1的两个人作为一个relation添加到数据结构中就可以了。在询问了英才zwh大佬之后,决定用targets()方法,得到每个人的相距为1的朋友,然后只做一个广搜,从中心点添加距离为1的关系,同时记录他的层数,然后对每个已经添加的人不断添加跟他距离为1的人,这样一次广搜下来就可以得到所有的relation而且能够得到他的层数。
A Thousand Years Later
我的socialNetworkCircle的重构来到了第一版,但是它跑大文件居然我去步道乐跑了一次还没跑完??然后我继续找漏洞。
优化P2
我的目光锁定在了P2(Lab2),这个ConcreteVerticeGraph居然是用List实现的。然后我仔细分析了一下,觉得把这个List改成Set没什么用,因为addEdge()的时候是要先得到所有的Vertex内部的rep,这需要我对所有的Vertex进行遍历,那List和Set没区别了呀,所以应该设计一个Set存Vertex里面的那个rep,然后再设计一个Map将Vertex内部的rep和Vertex映射起来,这样我找rep找Vertex都可以做到常数时间内完成,应该会快不少。
Ten Thousand Years Later
做这么大改动实在是令人崩溃,我debug了一万年,最后把所有的defensive copy跟trackGame一样换成unmodifiableList/Set/Map,我的程序终于可以10s之内跑出来了。
结语
这次我得到了许多的教训,比如:
- 永远记得写注释!!不然回过头来看自己的代码简直灾难
- 写程序的时候一定要把所有的功能分的开开的,这样优化某个部分的时候会很省力,我的trackGame因为写的时候时间还挺充裕的所以就设计的挺好,重构花在调节各个ADT之间的关系上的时间也不是很久,主要时间用来改算法了,但是socialNetworkCircle已经是在赶ddl了所以就写得比较的emmm这也为我重构和debug带来了许许多多的麻烦。
- 永远不要甩锅给java和eclipse,只有可能是自己的代码有bug。写程序的时候总是太年轻,总觉得自己的程序肯定没问题,一定会是jdk或者eclipse出问题了,我的算法这么优秀怎么可能有bug呢,但是仔细看下来就会发现,在某个犄角旮旯里面总会有一些导致自己找了一个小时的智障bug))))
- List虽然方便但是还是Set和Map性能高一点,存在即合理,每个看上去更加优越的数据结构一定存在他的致命弱点需要别的数据结构来补足。之前觉得List那么方便还有哪个弱智用Set啊,现在被打脸了555

 浙公网安备 33010602011771号
浙公网安备 33010602011771号