【数据挖掘】学术文献信息抽取
1、需求
a>先下载一篇病原微生物相关的论文,分析出其中的属性
b>读取论文,定位关键词
c>NLP识别句子的意义,进行信息获取,尝试理解信息,整理相关属性资料 https://blog.csdn.net/sdu_hao/article/details/105292176
2、流程梳理、csdn
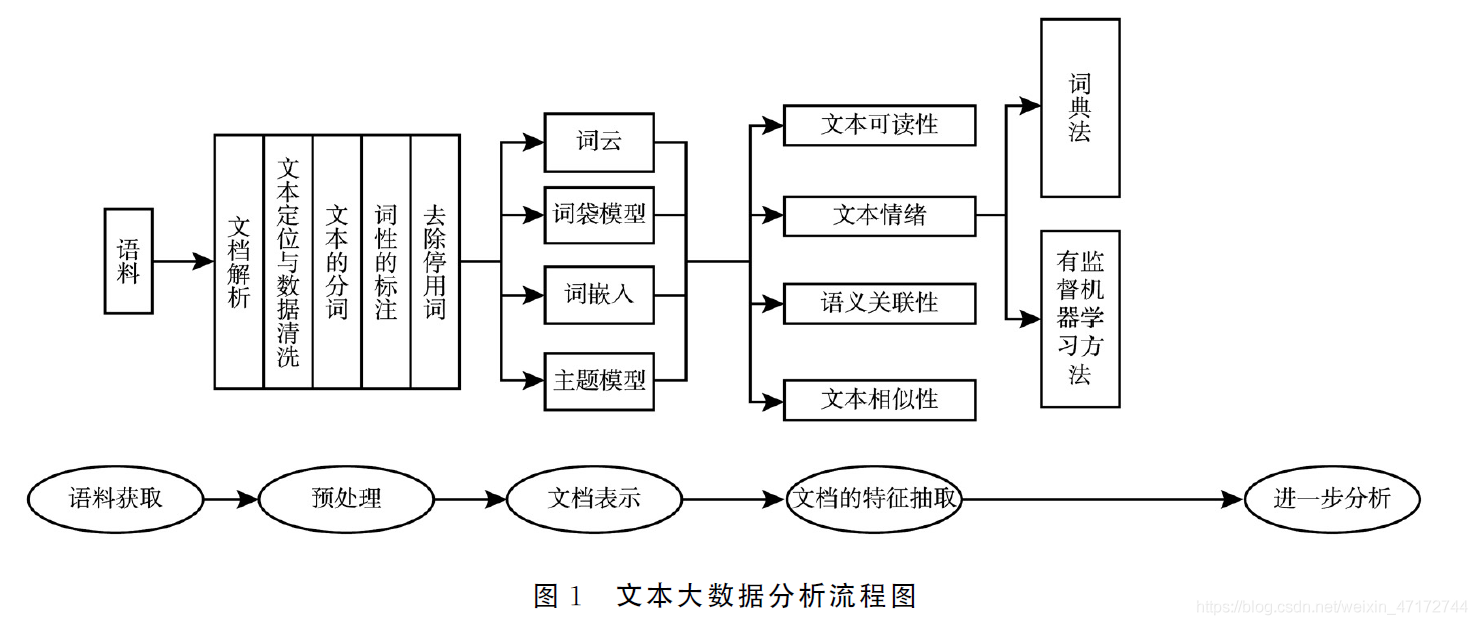
1/搜索相关论文,获得对应的pdf文档
2/读取PDF内容,转为TXT文件
pip install pdfplumber
>>读取其中的表格,转为csv输出--camelot
python库camelot安装及使用中的一些注意事项
3/确定关键字,获取当前的句子
把txt按照句子划分行
正则表达式定位满足几个关键词/https://www.jianshu.com/p/41d06a4ed896
(python挖掘关键词几个都符合)/信息抽取 https://www.jianshu.com/p/a1994336af2d
生物信息文献数据库构建与软件Web自动发布 何莹
https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD2009&filename=2009038794.nh&uniplatform=NZKPT&v=792rwfvbxQgmWx5jLiluhcXFs_df2XzhmTr_OytiMAJFeidjeP6CRcNKdzjhWIba
即可存入此数据
4/数据统计
文本分词
数据清理
转变成普通的txt格式型
再进行词频统计
3、论文搜集
KeyWord:论文、挖掘、论文挖掘、语义解析、信息抽取
1、基于Python语言的学术论文数据挖掘与分析——以医疗人工智能相关学术论文为例 https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2021&filename=XMTJ202105010&uniplatform=NZKPT&v=3ewPG-u9tc0Pr_olRzUs4QBOb1NagD8jZc13DOAn1nLcVG03J4RIA_4fz24A7jLl
2、期刊编辑发表论文情况的文本挖掘与分析https://kns.cnki.net/kcms/detail/detail.aspx?filename=BJXB201904019&dbcode=CJFQ&dbname=CJFDTEMP&v=t2BCYR_QG_w56Jpi43GoOHom_hyW6VKlqBmLEiSISLke5ZbVtu2LCAKI15eE1S3g

3、基于文本语义的篇章结构分析方法
https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=SCPD&dbname=SCPD2020&filename=CN107145479B&uniplatform=NZKPT&v=JaDWgEoeRHvux5PHmfn2X1fjDAfziwIYJROFMAmwycBXl3DOylet80gok8kZqY_E
“步骤1,数据获取;101获取纯文本数据,使用开源工具将待处理机器不可读格式文档转为机器可读的TXT格式;
步骤2,正文抽取;102噪声内容过滤,过滤对结构抽取任务而言的噪音内容,包括:空行、页眉页脚、表格内容;103目录和正文分割,对于有目录的文本,进行目录和正文的分割;目录部分识别出来后将其所有行以及之前行的内容剔除,仅保留其后的正文内容;
步骤3,标题识别和抽取;
步骤4,层级结构构建。”
4、基于文本挖掘的中文期刊数据分析系统的设计与实现 https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD202101&filename=1021534093.nh&uniplatform=NZKPT&v=vLKrbSZ6pC4BtFiHZKakVQlUHQz6sqFDfaE4IhJeABKJt5c1UUqyl3bQDkGJUTla

https://www.cnblogs.com/ljrj/p/6595076.html
“目前,关键词自动提取方法分为两类:
1)关键词分配,预先定义一个关键词词库,对于一篇文章,从词库中选取若干词语作为文章的关键词;
2)关键词抽取,从文章的内容中抽取一些词语作为关键词。”
6、基于词频统计分析国内外文本挖掘的研究热点 https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CPFD&dbname=CPFDLAST2018&filename=ZGUH201710001060&uniplatform=NZKPT&v=VKhW5uI-vAkTnUE3CU04Za5wgKoiE_vCCzP-serlihtF1tkXVgrR5QsAImG2ijN0fgW33H4FwZs%3d

7、中文期刊论文数据治理工作实践——以挖掘中国知网题录及PDF文档为例
https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CPFD&dbname=CPFDLAST2018&filename=ZGUH201710001060&uniplatform=NZKPT&v=VKhW5uI-vAkTnUE3CU04Za5wgKoiE_vCCzP-serlihtF1tkXVgrR5QsAImG2ijN0fgW33H4FwZs%3d pdf处理方法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· Apache Tomcat RCE漏洞复现(CVE-2025-24813)