寒假作业(2/2)
作业基本信息
| 这个作业属于哪个课程 | 2021春软件工程实践 | W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业(2/2) |
| 这个作业的目标 | 1. 深入思考并提出5-10个问题 2. 学习使用github 3. 制定代码规范 4. 学会使用单元测试 5. PSP表格记录 |
| 作业正文 | part1:阅读《构建之法》并提问 part2:WordCount编程 |
| 其他参考文献 | CSDN、博客园、简书、git |
part1. 阅读《构建之法》并提问
Q1: 面对用户评价褒贬不一的BUG应该怎么办?
什么是BUG呢?简单地说,软件的行为和用户的期望值不一样,就叫BUG。是否是BUG,取决于用户、开发者的不同角度。
例如,某聊天软件不支持视频聊天,用户期望这个聊天软件支持视频聊天。但是该软件的开发人员说,这个软件根本没打算支持视频聊天。这还是一个BUG么?用户下载了一个公司的软件,结果第二天发现电脑上突然多了好几个新软件,但用户从来也没有同意安装。这是BUG,还是用户应该感激的福利?
第一章中提到了BUG这个概念,依作者这么说,不同用户眼中的BUG很有可能是不一样的,而且很多软件的BUG大多是由用户反馈的,特别是开发游戏的软件BUG会出奇的多。这里我因为自己的假设和书中的不同而提问,但是根据我的经验,很多游戏玩家会以游戏中的某些BUG为乐趣(前提是BUG没有打破游戏的公平性),一段时间BUG被修复了以后,都会抱怨BUG怎么没了……
- 于是我就产生了一个问题,这样用户评价褒贬不一的BUG的出现,我们到底是修复还是不修复它呢?
我的见解是,其实开发人员很大程度上并不了解玩家的想法,我认为可以向玩家收集调查问卷,如果这个娱乐性的BUG被大部分玩家接受的话,其实这个BUG是可以永久存在的因为他并没有打破游戏本身的公平性。但对于那些已经影响到游戏公平性的BUG,开发人员应该立即做出反馈并在第一时间修复它。
Q2: 走进思维误区该怎么办?
分析麻痹:一种极端情况是下弄清楚所有细节、所有依赖关系之后再动手,心理上过于悲观,不想修复问题,出了问题都赖在相关问题上。分析太多,腿都麻了,没法起步前进,故得名“分析麻痹”(Analysis Paralysis)。
第三章中提到的思维误区分析麻痹的问题,我在平时的编程中偶尔也会碰到,特别要解决一个无从入手的功能的时候,我会从网上找源代码进行测试,测试期间肯定会有一系列的问题和我看不懂的代码,而我的强迫症让我一定要把这个问题解决掉。
- 于是我就产生了一个问题,遇到这样令人无从入手只能找百度将代码一步一步挖掘下去的时候(很多时候最后还是得推倒重来但我也不知道还有什么别的方法),这样算是误区吗?还是有什么其它更好的解决办法呢?
Q3: 结对编程有必要吗?
结对编程让两个人所写的代码不断地从处于“复审”的过程,程序员们能够不断地审核,提高设计和编码质量,可以及时发现并解决问题,避免把问题拖到后面的阶段去。
第四章中提到了结对编程这个概念,作者提到结对编程能使代码始终处于复审的状态,这里书中的描述和我的间接经验有些许的矛盾,根据我的经验,两个人一起思考,若其中一个人提出一个算法,会出现两种极端的情况:
- 另一个人没有get到这个人的思路就容易被这个人带着跑,思维也会跟着走偏(直到最后的测试才发现思路不对);
- 另一个人对这个逻辑提出质疑并认为自己的算法才是解决之道,而这个人坚持己见,于是两个人就陷入了僵持……
- 于是我就产生了一个问题,出现这种情况的时候再继续结对编程是不是一种低效率的选择?或者说还是各自编程负责各自需要完成的功能更好呢?因为这样可以有自己的逻辑,不用跟着对方走。以我自己平时的实践经验,我自己独自思考的效率比多人一起思考的效率更高。
我的见解是,要不要结对编程还是因人而异,看自己适不适合和人结对编程,也看结对编程的那个伙伴与自己是否有默契。
Q4: 在理解敏捷流程上的困惑
敏捷方法能够帮助你更早地知道你是否能如期完成任务,仅此而已。敏捷的方法(迭代的方式)能帮你尽快让用户看到项目的部分价值。当你尽早交付部分价值时,也许用户对你目前交付的东西已经很满意了,这样你就不用再花时间来实现其他需求。另一种可能是,用户看到了部分系统,他们有新的需求,这样你就可以实现新的需求,而不用再浪费时间实现过时的需求了。
第六章中介绍了敏捷流程,并将它和瀑布流程进行了一个对比,从我的理解来看,瀑布流程就是先整体布局,最后再按照设计好的流程进行开发。但是这里我还是不太懂书中提到的敏捷流程。
- 那敏捷流程是不是意味着直接着手开发,做好一个功能后再去思考下一功能做什么呢?如果是这样的话会不会带了些盲目性?会不会出现推翻重来的情况呢?
Q5: 关于开发者和测试者之间的矛盾处理
有些团队把开发和测试有意无意对立起来,好像二者是矛盾是。一个典型的例子是,有时开发人员不想给测试人员提供足够的信息,好像不想“帮”测试人员找到缺陷;与此同时,测试人员一旦找到缺陷,会有些得意,“看,你写的代码那么臭,我又发现了N个Bug”。这种对立情绪,也许在短期内能刺激成员的工作热情,而从长远来看是有害的。很少人会希望在这种充满对立情绪的环境中工作。
下面文字让我产生了共鸣,可是即便我们心里懂得这个道理,但现实中难免会遇到这种情况:
- 于是我就产生了这个问题,如果遇到了开发者不配合,总是不提供全面的信息有所隐藏的时候,我作为测试者该如何劝说他呢?(鉴于本人交际能力有限)反之我作为开发者提供给测试者详细的信息,结果却遭到测试者的嘲笑,打击了我的自信心,我又该怎么让他减少这种现象的发生呢?
冷知识: 程序中bug的名称源自“虫子”
在程序中bug一词用于技术错误。这一术语最初由爱迪生在1878年提出的,但当时并没有流行起来。在这的几年之后,美国上将Grace Hopper在她的日志本中,写下了她在Mark II电脑上发现的一项bug。不过实际上,她说的真的是“虫子”问题,因为一只蛾子被困在电脑的继电器中,导致电脑的操作无法正常运行。如图片所见,她写道“这是我在电脑上发现的第一个bug”。结果被政府拒绝,因为当时荷兰没有这个职业。
参考来源

part2:WordCount编程
1. Github项目地址
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 150 |
| • Design Spec | • 生成设计文档 | 60 | 20 |
| • Design Review | • 设计复审 | 30 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 60 | 40 |
| • Coding | • 具体编码 | 200 | 150 |
| • Code Review | • 代码复审 | 50 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 60 | 30 |
| • Size Measurement | • 计算工作量 | 60 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 870 | 640 |
3. 解题思路描述
- 首先编程语言选择的问题,最后选择使用C/c++来编写程序;
- 考虑到这次编程作业需要用到大量字符串处理的相关知识,于是在网上找了许多这类的资料;
- 统计字符数这个指标,直接对得到的字符串进行一个length就能得出结果;
- 统计单词数量这个指标,需要对字符串进行分割,这边需要一个分割函数来实现,再对单词进行判断和存储;
- 统计有效行数这个指标,可以截取每一行的字符串进行判断;
- 单词出现的频率这个数据,可以使用map容器来存储,再通过vector容器与sort函数的结合来对数据进行排序和输出。
4. 代码规范制定链接
5. 设计与实现过程
首先我创建一个名为WordFile的类,在类中使用功能函数,这个类中有3个私有数据成员:输入文件instream和输出文件ofstream,以及存储单词出现频率的map容器。
ifstream infile;
ofstream outfile;
map<string, int> mword;
WordFile中还有8个功能函数,其中打开输入输出文件各划分一个函数来实现。注意,输入文件需要对文件是否存在进行一个判断否则会出现异常。打开文件后,调用getWordFile()函数从输入文件中获取到文本字符串,存储在主函数里,接着就开始依次获取需要的四个指标。
int getCharacters(string str);
int getWords(string str);
int getLines(string str);
void getWordsNum();
- getCharacters()用来获取字符总数,这个函数调用一个str.length()就能得到结果。
- getWords()用来获取单词总数,由于先前得到的字符串是连续的,需要对字符串进行一个分割处理,而C没有自带的split函数,我自己写了一个split函数对字符串进行分割,对字符串进行分割是本程序的关键之一。
vector<string> split(const std::string &s) {
vector<string> vec_ret;
typedef string::size_type string_size;
string_size i = 0;
while (i != s.size()) {
while (i != s.size() && isspace(s[i]))
++i;
string_size j = i;
// 获取空白字符之间连续的非空白字符串的位置
while (j != s.size() && !isspace(s[j]))
++j;
//截取字符串
if (i != j) {
vec_ret.push_back(s.substr(i, j - i));
i = j;
}
}
return vec_ret;
}
然后先对字符串进行大小写转换(都转换为小写),再对每个分割出来的字符串进行单词判断,这个也独立出来一个isWord()函数对单词进行一个判断。我将存储单词的出现频率也放在了这个功能函数里,先使用map自带的find()函数判断单词是否已经存储在map中,若已存储则value++,若还未存储,则value=1。
-
getLines()用来获取有效行数,我的逻辑是循环搜索换行符出现的位置,再对每一个分离出来的字符串,去除掉空白字符后,判断是否为空,若不为空则有效行数加一。注意还要对最后一个换行符后面的字符串进行判断,在测试的时候我才发现了这个问题。
-
getWordsNum()用来输出出现频率最高的十个单词,这里用到C自带的sort函数,与vector容器结合,并通过自己写的cmp函数实现map容器value的排序以及key的排序。
vector< pair<string, int> > vec(mword.begin(), mword.end());
sort(vec.begin(), vec.end(), cmp);
bool cmp(const pair<string, int>& a, const pair<string, int>& b) {
if (a.second != b.second)
return a.second > b.second;
return a.first < b.first;
}
程序的独到之处:
- 代码精简,整个程序不过200行,没有特别复杂的算法,逻辑较为简单;
- 在排序上使用sort函数与cmp函数通过vector容器排序一步到位,减少了许多的工程;
- 代码不多,却有十个函数,实现了主测试函数与功能函数的分离,并将文件分离为一个用来声明函数的头文件,一个用来实现所有函数功能的源文件,以及一个包含主测试函数的源文件。
6. 性能改进
- 在性能测试方面,我生成了一个由100万个“abcd \n"字符串组成的输入文件,下面是性能测试结果截图:
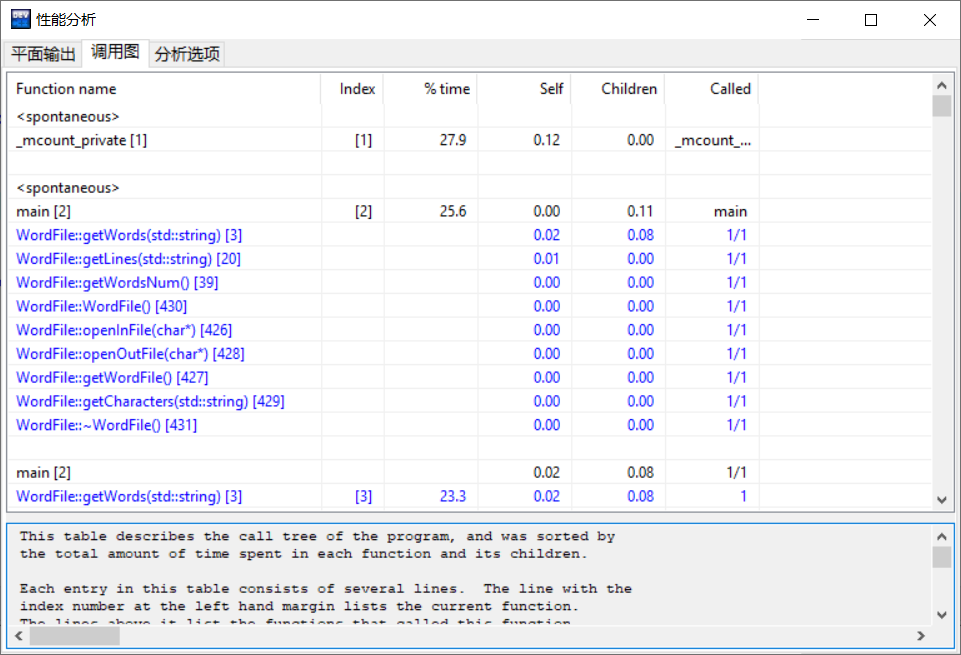
- 为了更显著地看到结果,我将测试文件改成1000万个字符,结果还是可观的:
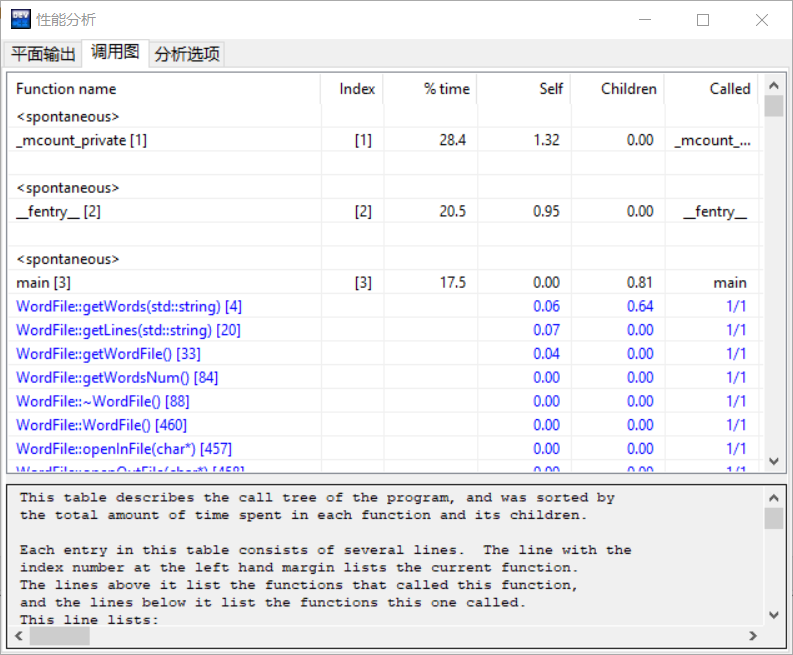
- 我又生成了长度为4~10的50万个随机字符串的输入文件,结果如下:

- 在缓存优化上,对于多次使用的计算结果及时缓存,避免重复计算,特别修改循环中需要用到的数据;
- 整个程序较为复杂的部分就是map排序的部分,我使用C++自带的sort函数,是我所了解到的较为便捷也不太复杂的方法;
7. 单元测试
- 打开输入文件函数测试:测试是否能正确打开已存在的文件;
TEST_METHOD(OpenInFile)
{
Assert::AreEqual(true, wf1.openInFile("input.txt"));
Assert::AreEqual(false, wf2.openInFile("input"));
Assert::AreEqual(false, wf3.openInFile("input3.txt"));
Assert::AreEqual(false, wf4.openInFile("input1"));
}
- 统计字符数函数测试:测试是否能统计空格、制表符、换行符等空白字符;测试能否正确统计字符数;
TEST_METHOD(GetCharacters)
{
Assert::AreEqual(0, wf.getCharacters(""));
Assert::AreEqual(3, wf.getCharacters(" "));
Assert::AreEqual(8, wf.getCharacters(" aa\nb\n "));
Assert::AreEqual(2,wf.getCharacters(" \n"));
Assert::AreEqual(9, wf.getCharacters("abc*65m. "));
}
- 判断是否为单词函数测试:测试能否正确判断单词;
TEST_METHOD(IsWords)
{
Assert::AreEqual(false, wf.isWord("abc123b"));
Assert::AreEqual(false, wf.isWord("a"));
Assert::AreEqual(false, wf.isWord("1235"));
Assert::AreEqual(false, wf.isWord("ab3ff"));
Assert::AreEqual(true, wf.isWord("abff"));
}
- 统计单词数函数测试:测试是否能正确分割字符串,并输出正确的单词数;
TEST_METHOD(GetWords)
{
Assert::AreEqual(2,wf.getWords("abc123b abbb 23sa\n\nAsshb"));
Assert::AreEqual(1, wf.getWords(" absad123\nbbb\n "));
Assert::AreEqual(0, wf.getWords(" \n"));
Assert::AreEqual(1, wf.getWords("abcr*65m."));
}
- 统计有效行数的测试:测试空行是否被忽略计算;测试有效行的判断是否正确;
TEST_METHOD(GetLines)
{
Assert::AreEqual(2, wf.getLines("abc123b abbb 23sa\n\nAsshb"));
Assert::AreEqual(2, wf.getLines(" absad123\nbbb\n "));
Assert::AreEqual(1, wf.getLines(" \n \nf hhdsa\n \n"));
Assert::AreEqual(0, wf.getLines(""));
Assert::AreEqual(0, wf.getLines(" \n \n "));
Assert::AreEqual(1, wf.getLines("ab*65m\n"));
}
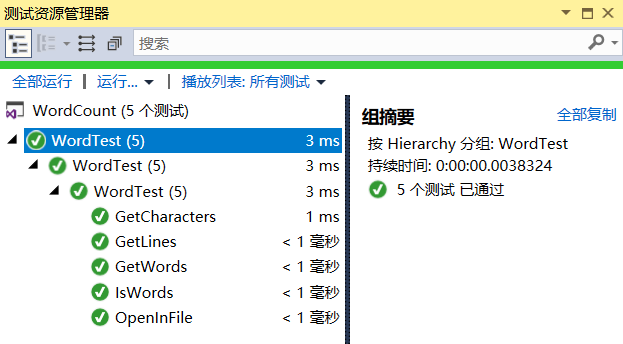
- 单元测试结果截图:
- 代码覆盖率截图:
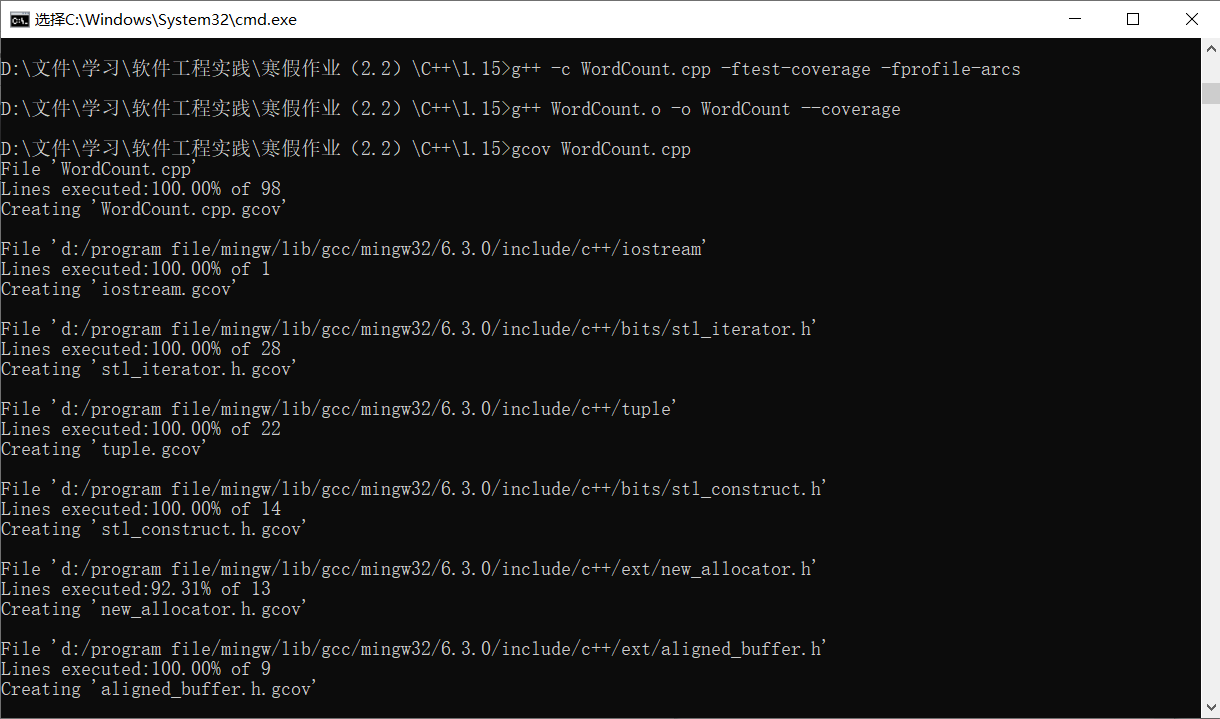
在获取代码覆盖率结果这一步上,我卡了很久。本来是使用VS来做的,但下载了各个版本的VS,运行代码覆盖率的时候都报告错误“无法生成覆盖率”,网上查了很多也都没有找到和我出现类似情况的资料。网上也极少关于C++代码覆盖率的获取途径,最后只能使用GCC自带的GCOV来获取代码覆盖率,虽然结果不太直观,但还是可行的。 - 在优化覆盖率上,重点检查带有分支的语句,减少不必要的判断和重复的代码,增加特殊的测试例子。
8. 异常处理说明
- 异常处理命令行参数无输入/输出文件的情况:
if (agrs< 3) {
cout << "Please input and output files!";
return 0;
}
- 异常处理输入文件不存在的情况:
if (!wf.openInFile(arg[1])) {
cout << "Could not find the file!";
return 0;
}
9. 心路历程与收获
在这次的作业中,我接触了许多之前没有接触过的知识:
- 我初步学习使用了github,在对代码的管理上确实很方便;
- 刚开始我根本不知道什么是单元测试,通过《构建之法》的阅读以及网上对单元测试的操作,学会了如何使用单元测试,在对代码的测试上便捷了许多,一次性能测试许多数据;
- 之前没有使用过对性能的查看,以及对代码覆盖率的测试,现在对这两个指标有了初步的认识;
- 其次就是PSP表格,对自己整个工程工作量的记录,刚开始还使用的不太习惯,对整个工作量的计算还不太上手,不过我相信在之后的项目中多使用PSP表格我能更好估计任务量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号