墨者学院-WEB站点访问者身份识别
网络爬虫
之前用python做过一些爬虫,爬取电影信息,学校管理系统个人信息之类的,在墨者上看到搜索引擎也有爬虫?想想也是,理解起来很简单,一款搜索引擎,要收录的信息太多了,肯定不会靠人工收录,那就会有爬虫脚本,去收录信息,放到搜索引擎的数据库里,之后搜索才会出来东西。
直接上靶场地址:https://www.mozhe.cn/bug/detail/M3FwbkhWc3pkSkxLaE1KckwyMFVpQT09bW96aGUmozhe
正文
先看一下靶场的背景

原来是网站不想被搜索引擎收录,对特定的爬虫进行了屏蔽,打开环境之后
目标里提示了查看robots.txt
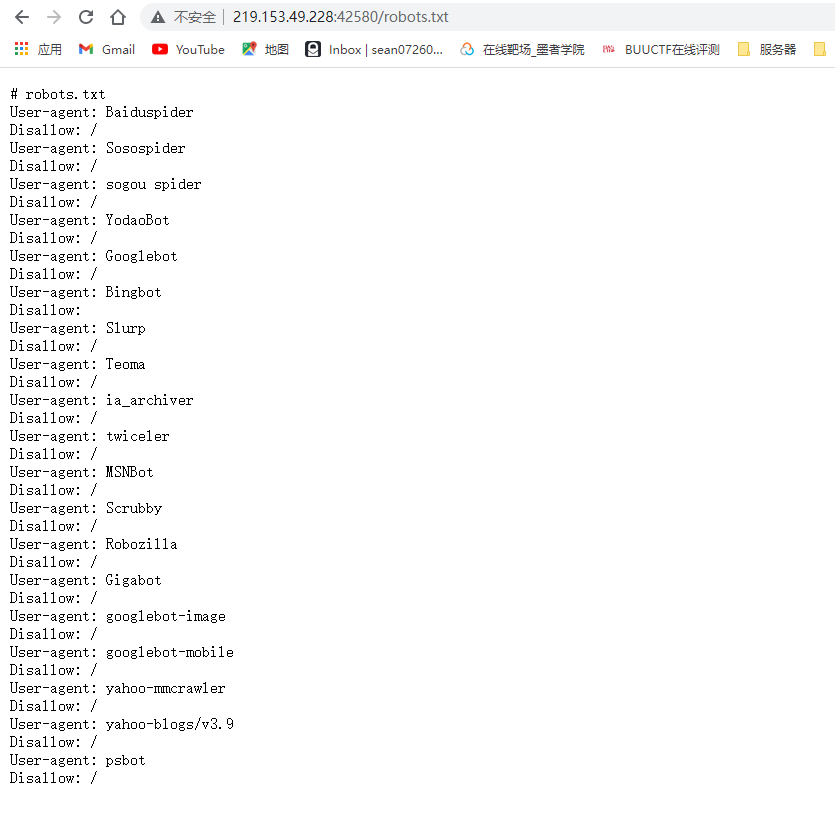
打开后发现,果然是被屏蔽了,百度,搜狗,谷歌的爬虫都被屏蔽了。
User-agent代表了浏览器标识,当时用对应的搜索引擎访问时,Disallow为 / 表示不允许访问网站根目录,那就等于是所有的都不可以访问了。
心灰意冷的时候,发现 Bingbot 的 Disallow 为空,说明网站没有对Bing做屏蔽,于是解题思路就大概在这里了,需要伪装成 Bing 的搜索引擎去访问网站,就可以成功访问了!
burp抓包,修改User-agent,进行伪装
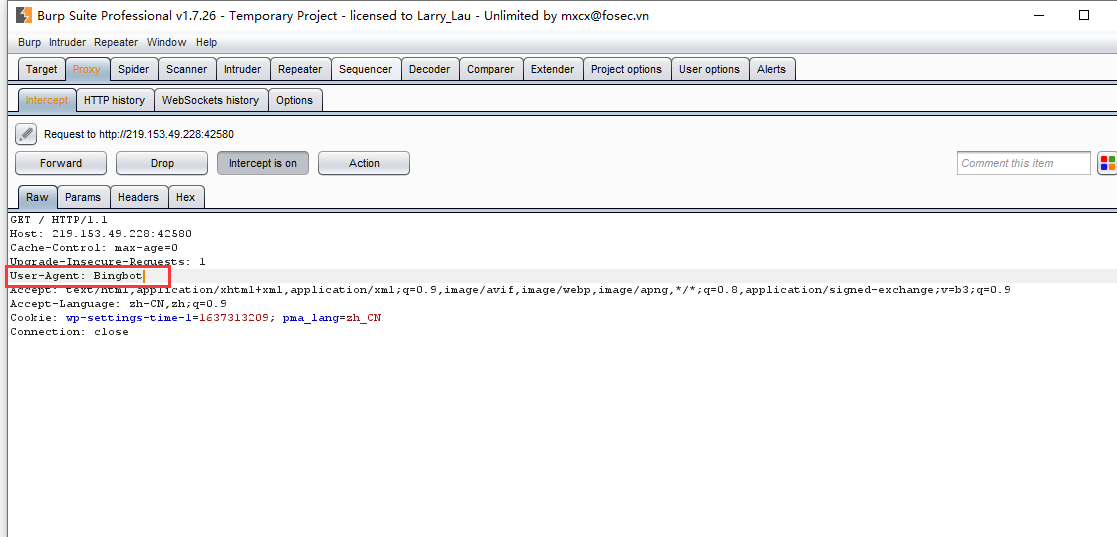
放包

果然没有被网站屏蔽,成功访问站点,key在页面最下面
END
接下来打算深入学一下搜索引擎爬虫的原理,等下一篇再更。

