
python网络-静态Web服务器案例(29)
一、静态Web服务器案例代码static_web_server.py
# coding:utf-8 # 导入socket模块 import socket # 导入正则表达式模块 import re # 导入多进程模块 from multiprocessing import Process # 设置静态文件根目录 HTML_ROOT_DIR = "./html" # 定义个一个HTTPServer的类 class HTTPServer(object): """""" # 初始化方法 def __init__(self): # 创建一个服务器socket套接字 self.server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # socket地址重用配置 self.server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # HTTPServer开启的方法 def start(self): # 设置监听字节长度为128 self.server_socket.listen(128) # 不间断的监听是否有人链接服务器 while True: # 解析请求链接服务器的客户端信息 client_socket, client_address = self.server_socket.accept() print("[%s:%s]用户连接上了" % client_address) # 创建多进程handle_client处理客户端的请求 handle_client_process = Process(target=self.handle_client, args=(client_socket,)) # 开启多进程 handle_client_process.start() # 关闭客户端socket套接字 client_socket.close() # 多进程handle_client def handle_client(self, client_socket): """处理客户端请求""" # 获取客户端数据 request_data = client_socket.recv(1024) print("request data:", request_data) # 多请求数据用空格做分割处理 request_headers_lines = request_data.splitlines() for line in request_headers_lines: print(line) # 解析请求报文 request_start_line = request_headers_lines[0] # 利用正则表达式提取用户请求的文件名 file_name = re.match(r"\w+ +(/[^ ]*) ", request_start_line.decode("utf-8")).group(1) print(file_name) if "/" == file_name: file_name = "/index.html" # 打开文件 ,读取内容 try: file = open(HTML_ROOT_DIR + file_name, "rb") except IOError: # 设置打开文件失败时返回的响应起始行\r\n是换行 response_start_line = "HTTP/1.1 404 Not Found\r\n" # 设置打开文件失败时返回的响应头 response_headers = "Server:My server\r\n" # 设置打开文件失败时返回的响应体 response_body = "The File is not found" else: # 打开成功时读取的客户端要请求的文件数据 file_data = file.read() # 关闭文件 file.close() # 构造响应数据 response_start_line = "HTTP/1.1 200 OK\r\n" # 构造响应头 response_headers = "Server:My server\r\n" # 构造响应体 response_body = file_data.decode("utf-8") response = response_start_line + response_headers + "\r\n" + response_body print("response data:", response) # 向客户端返回响应数据 client_socket.send(bytes(response, "utf-8")) # 关闭客户端连接 client_socket.close() # 绑定端口 def bind(self, port): self.server_socket.bind(("", port)) def main(): # 创建HTTPServer对象 http_server = HTTPServer() # 绑定端口 http_server.bind(8000) # 开启服务 http_server.start() if __name__ == "__main__": main()
二、index.html代码
说明:index.html在html文件夹中,html文件夹和static_web_server.py在同目录
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>My web</title> </head> <body> <h1>Se7eN_HOU</h1> </body> </html>
三、浏览器运行效果
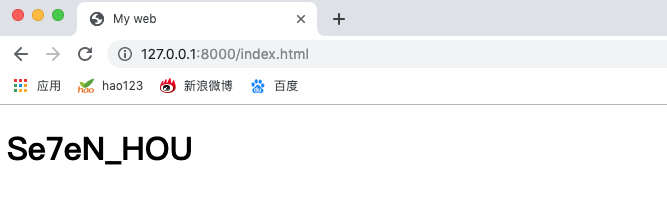
四、说明
在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来。而浏览器和服务器之间的传输协议是HTTP,所以:
-
HTML是一种用来定义网页的文本,会HTML,就可以编写网页;
-
HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信
侯哥语录:我曾经是一个职业教育者,现在是一个自由开发者。我希望我的分享可以和更多人一起进步。分享一段我喜欢的话给大家:"我所理解的自由不是想干什么就干什么,而是想不干什么就不干什么。当你还没有能力说不得时候,就努力让自己变得强大,拥有说不得权利。"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号