
记录lucene.net的使用过程
之前公司要做一个信息展示的网站,领导说要用lucene.net来实现全文检索,类似百度的搜索功能,但是本人技术有限,只是基本实现搜索和高亮功能,特此记录;
先看下页面效果,首先我搜索“为什么APP消息没有推送”,出来的结果如下图:
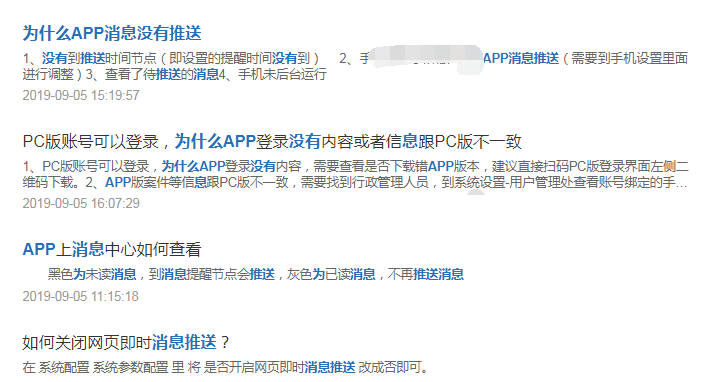
然后我再搜索“醒 消息 推”,出来结果如下图:
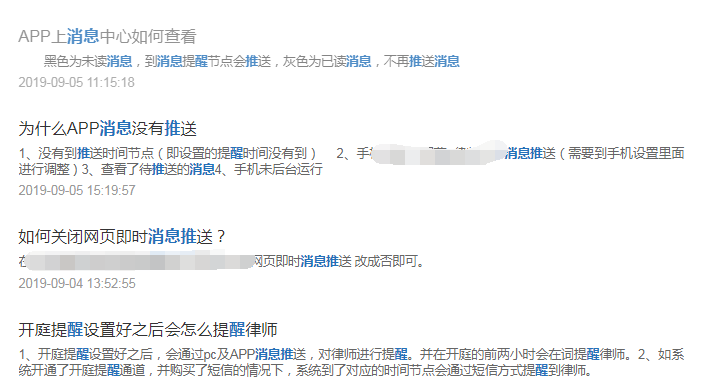
然后说下,我使用的是Lucene.net版本是2.9.22,盘古分词的版本是2.3.1,注意,版本lucene.net和盘古分词的版本一定要对上,之前我用Lucene.net3.0的版本,就一直有错误,后来换到低版本才没问题的;
接着是关键的类LuceneHelper,如下所示:
1 public class LuceneHelper 2 { 3 readonly LogHelper _logHelper = new LogHelper(MethodBase.GetCurrentMethod()); 4 private LuceneHelper() { } 5 6 #region 单例 7 private static LuceneHelper _instance = null; 8 private static readonly object Lock = new object(); 9 /// <summary> 10 /// 单例 11 /// </summary> 12 public static LuceneHelper instance 13 { 14 get 15 { 16 lock (Lock) 17 { 18 if (_instance == null) 19 { 20 _instance = new LuceneHelper(); 21 PanGu.Segment.Init(PanGuXmlPath);//使用盘古分词,一定要记得初始化 22 } 23 return _instance; 24 } 25 } 26 } 27 #endregion 28 29 #region 分词测试 30 31 32 /// <summary> 33 /// 处理关键字为索引格式 34 /// </summary> 35 /// <param name="keywords"></param> 36 /// <returns></returns> 37 private string GetKeyWordsSplitBySpace(string keywords) 38 { 39 PanGuTokenizer ktTokenizer = new PanGuTokenizer();//使用盘古分词器来吧关键字分词 40 StringBuilder result = new StringBuilder(); 41 ICollection<WordInfo> words = ktTokenizer.SegmentToWordInfos(keywords); 42 foreach (WordInfo word in words) 43 { 44 if (word == null) 45 { 46 continue; 47 } 48 //result.AppendFormat("{0}^{1}.0 ", word.Word, (int)Math.Pow(3, word.Rank)); 49 result.AppendFormat("{0} ", word.Word); 50 } 51 return result.ToString().Trim(); 52 } 53 #endregion 54 55 #region 创建索引 56 /// <summary> 57 /// 创建索引 58 /// </summary> 59 /// <param name="datalist"></param> 60 /// <returns></returns> 61 public bool CreateIndex<T>(IList<T> datalist) 62 { 63 IndexWriter writer = null; 64 try 65 { 66 writer = new IndexWriter(directory_luce, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入) 67 //writer = new IndexWriter(directory_luce, null, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入) 68 } 69 catch 70 { 71 writer = new IndexWriter(directory_luce, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入) 72 //writer = new IndexWriter(directory_luce, null, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入) 73 } 74 foreach (var data in datalist) 75 { 76 CreateIndex<T>(writer, data); 77 } 78 writer.Optimize(); 79 writer.Close(); 80 return true; 81 } 82 83 public bool CreateIndex<T>(IndexWriter writer, T data) 84 { 85 try 86 { 87 88 if (data == null) return false; 89 Document doc = new Document(); 90 Type type = data.GetType(); 91 92 //创建类的实例 93 //object obj = Activator.CreateInstance(type, true); 94 //获取公共属性 95 PropertyInfo[] Propertys = type.GetProperties(); 96 for (int i = 0; i < Propertys.Length; i++) 97 { 98 //Propertys[i].SetValue(Propertys[i], i, null); //设置值 99 PropertyInfo pi = Propertys[i]; 100 string name = pi.Name; 101 object objval = pi.GetValue(data, null); 102 string value = objval == null ? "" : objval.ToString(); //值 103 if (name.ToLower() == "id" || name.ToLower() == "type")//id在写入索引时必是不分词,否则是模糊搜索和删除,会出现混乱 104 { 105 doc.Add(new Field(name, value, Field.Store.YES, Field.Index.NOT_ANALYZED));//id不分词 106 } 107 else if (name.ToLower() == "IsNewest".ToLower()) 108 { 109 //doc.Add(new Field(name, value, Field.Store.NO, Field.Index.ANALYZED_NO_NORMS));//分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间 110 doc.Add(new Field(name, value, Field.Store.YES, Field.Index.NOT_ANALYZED));//IsNewest不分词 111 } 112 else if (name.ToLower() == "IsReqular".ToLower()) 113 { 114 //doc.Add(new Field(name, value, Field.Store.NO, Field.Index.ANALYZED_NO_NORMS));//分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间 115 doc.Add(new Field(name, value, Field.Store.YES, Field.Index.NOT_ANALYZED));//IsReqular不分词 116 } 117 else 118 { 119 if (name.ToLower() == "Contents".ToLower()) 120 { 121 value = GetNoHtml(value);//去除正文的html标签 122 } 123 doc.Add(new Field(name, value, Field.Store.YES, Field.Index.ANALYZED));//其他字段分词 124 } 125 } 126 writer.AddDocument(doc); 127 } 128 catch (System.IO.FileNotFoundException fnfe) 129 { 130 throw fnfe; 131 } 132 return true; 133 } 134 #endregion 135 136 #region 在title和content字段中查询数据,该方法未使用,可能有错漏,我使用的是下面的分页查询的; 137 /// <summary> 138 /// 在title和content字段中查询数据 139 /// </summary> 140 /// <param name="keyword"></param> 141 /// <returns></returns> 142 public List<Questions> Search(string keyword) 143 { 144 145 string[] fileds = { "Title", "Contents" };//查询字段 146 //Stopwatch st = new Stopwatch(); 147 //st.Start(); 148 QueryParser parser = null;// new QueryParser(Lucene.Net.Util.Version.LUCENE_30, field, analyzer);//一个字段查询 149 parser = new MultiFieldQueryParser(version, fileds, analyzer);//多个字段查询 150 Query query = parser.Parse(keyword); 151 int n = 1000; 152 IndexSearcher searcher = new IndexSearcher(directory_luce, true);//true-表示只读 153 TopDocs docs = searcher.Search(query, (Filter)null, n); 154 if (docs == null || docs.totalHits == 0) 155 { 156 return null; 157 } 158 else 159 { 160 List<Questions> list = new List<Questions>(); 161 int counter = 1; 162 foreach (ScoreDoc sd in docs.scoreDocs)//遍历搜索到的结果 163 { 164 try 165 { 166 Document doc = searcher.Doc(sd.doc); 167 168 169 170 string id = doc.Get("ID"); 171 string title = doc.Get("Title"); 172 string content = doc.Get("Contents"); 173 174 string createdate = doc.Get("AddTime"); 175 PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"red\">", "</font>"); 176 PanGu.HighLight.Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new PanGu.Segment()); 177 highlighter.FragmentSize = Int32.MaxValue; 178 content = highlighter.GetBestFragment(keyword, content); 179 string titlehighlight = highlighter.GetBestFragment(keyword, title); 180 if (titlehighlight != "") title = titlehighlight; 181 182 Questions model = new Questions 183 { 184 ID = int.Parse(id), 185 Title = title, 186 Contents = content, 187 AddTime = DateTime.Parse(createdate) 188 }; 189 190 list.Add(model); 191 } 192 catch (Exception ex) 193 { 194 Console.WriteLine(ex.Message); 195 } 196 counter++; 197 } 198 return list; 199 } 200 //st.Stop(); 201 //Response.Write("查询时间:" + st.ElapsedMilliseconds + " 毫秒<br/>"); 202 203 } 204 #endregion 205 206 #region 在不同的分类下再根据title和content字段中查询数据(分页) 207 /// <summary> 208 /// 在不同的类型下再根据title和content字段中查询数据(分页) 209 /// </summary> 210 /// <param name="_type">分类,传空值查询全部</param> 211 /// <param name="keyword"></param> 212 /// <param name="PageIndex"></param> 213 /// <param name="PageSize"></param> 214 /// <param name="TotalCount"></param> 215 /// <returns></returns> 216 public List<Questions> Search(string _type,bool? _isnew,bool? _isreq ,string keyword, int PageIndex, int PageSize, out int TotalCount) 217 { 218 try 219 { 220 if (PageIndex < 1) PageIndex = 1; 221 //Stopwatch st = new Stopwatch(); 222 //st.Start(); 223 BooleanQuery bq = new BooleanQuery(); 224 if (_type != "" && _type != "-100") 225 { 226 QueryParser qpflag = new QueryParser(version, "Type", analyzer);//一个字段查询 227 Query qflag = qpflag.Parse(_type); 228 bq.Add(qflag, Lucene.Net.Search.BooleanClause.Occur.MUST);//与运算 229 } 230 if (_isnew.HasValue) 231 { 232 QueryParser qpnew = new QueryParser(version, "IsNewest", analyzer); 233 Query qnew = qpnew.Parse(_isnew.Value.ToString()); 234 bq.Add(qnew, Lucene.Net.Search.BooleanClause.Occur.MUST); 235 } 236 if (_isreq.HasValue) 237 { 238 QueryParser qpreq = new QueryParser(version, "IsReqular", analyzer); 239 Query qreq = qpreq.Parse(_isnew.Value.ToString()); 240 bq.Add(qreq, Lucene.Net.Search.BooleanClause.Occur.MUST); 241 } 242 243 string keyword2 = keyword; 244 if (keyword != "") 245 { 246 247 keyword = GetKeyWordsSplitBySpace(keyword); 248 249 string[] fileds = { "Title", "Contents" };//查询字段 250 QueryParser parser = null;// new QueryParser(version, field, analyzer);//一个字段查询 251 parser = new MultiFieldQueryParser(version, fileds, analyzer);//多个字段查询 252 //parser.DefaultOperator = QueryParser.Operator.OR; 253 parser.SetDefaultOperator(QueryParser.Operator.OR);//这里QueryParser.Operator.OR表示并行结果,相当于模糊搜索,QueryParser.Operator.AND相当于精准搜索 254 Query queryKeyword = parser.Parse(keyword); 255 256 bq.Add(queryKeyword, Lucene.Net.Search.BooleanClause.Occur.MUST);//与运算 257 } 258 259 //TopScoreDocCollector collector = TopScoreDocCollector.Create(PageIndex * PageSize, false); 260 IndexSearcher searcher = new IndexSearcher(directory_luce, true);//true-表示只读 261 262 //Sort sort = new Sort(new SortField("AddTime", SortField.DOC, false)); //此处为结果排序功能,但是使用排序会影响搜索权重(类似百度搜索排名机制) 263 //TopDocs topDocs = searcher.Search(bq, null, PageIndex * PageSize, sort); 264 TopDocs topDocs = searcher.Search(bq, null, PageIndex * PageSize); 265 //searcher.Search(bq, collector); 266 if (topDocs == null || topDocs.totalHits == 0) 267 { 268 TotalCount = 0; 269 return null; 270 } 271 else 272 { 273 int start = PageSize * (PageIndex - 1); 274 //结束数 275 int limit = PageSize; 276 ScoreDoc[] hits = topDocs.scoreDocs; 277 List<Questions> list = new List<Questions>(); 278 int counter = 1; 279 TotalCount = topDocs.totalHits;//获取Lucene索引里的记录总数 280 281 //Lucene.Net.Highlight.SimpleHTMLFormatter simpleHTMLFormatter = new Lucene.Net.Highlight.SimpleHTMLFormatter("<em class=\"hl-l-t-main\">", "</em>"); 282 //Lucene.Net.Highlight.Highlighter highlighter = new Lucene.Net.Highlight.Highlighter(simpleHTMLFormatter,new Lucene.Net.Highlight.QueryScorer(bq)); 283 284 foreach (ScoreDoc sd in hits)//遍历搜索到的结果 285 { 286 try 287 { 288 Document doc = searcher.Doc(sd.doc); 289 string id = doc.Get("ID"); 290 string title = doc.Get("Title"); 291 string content = doc.Get("Contents"); 292 string updatetime = doc.Get("AddTime"); 293 294 PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<em class=\"hl-l-t-main\">", "</em>"); 295 PanGu.HighLight.Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new Segment());//搜索关键字高亮显示,上面的高亮样式自己写 296 highlighter.FragmentSize = Int32.MaxValue; //这里如果值小于搜索内容的长度的话,会导致搜索结果被截断,因此设置最大,根据需求来吧 297 string contentHighlight = highlighter.GetBestFragment(keyword2, content); 298 string titleHighlight = highlighter.GetBestFragment(keyword2, title); 299 300 301 //string titleHighlight = highlighter.GetBestFragment(analyzer, "Title", title); 302 303 //string contentHighlight = highlighter.GetBestFragment(analyzer, "Contents", content); 304 305 title = string.IsNullOrEmpty(titleHighlight) ? title : titleHighlight; 306 content = string.IsNullOrEmpty(contentHighlight) ? content : contentHighlight; 307 308 var model = new Questions 309 { 310 ID = int.Parse(id), 311 Title = title, 312 Contents = content, 313 AddTime = DateTime.Parse(updatetime) 314 }; 315 list.Add(model); 316 } 317 catch (Exception ex) 318 { 319 //这里可以写错误日志 320 } 321 counter++; 322 } 323 return list; 324 } 325 //st.Stop(); 326 } 327 catch (Exception e) 328 { 329 TotalCount = 0; 330 return null; 331 } 332 333 } 334 335 /// <summary> 336 /// 去除html标签 337 /// </summary> 338 /// <param name="StrHtml"></param> 339 /// <returns></returns> 340 public string GetNoHtml(string StrHtml) 341 { 342 string strText=""; 343 if (!string.IsNullOrEmpty(StrHtml)) 344 { 345 strText = System.Text.RegularExpressions.Regex.Replace(StrHtml, @"<[^>]+>", ""); 346 strText = System.Text.RegularExpressions.Regex.Replace(strText, @"&[^;]+;", ""); 347 strText = System.Text.RegularExpressions.Regex.Replace(strText, @"\\s*|\t|\r|\n", ""); 348 349 350 } 351 return strText; 352 353 } 354 #endregion 355 356 #region 删除索引数据(根据id) 357 /// <summary> 358 /// 删除索引数据(根据id) 359 /// </summary> 360 /// <param name="id"></param> 361 /// <returns></returns> 362 public bool Delete(string id) 363 { 364 bool IsSuccess = false; 365 Term term = new Term("id", id); 366 //Analyzer analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30); 367 //Version version = new Version(); 368 //MultiFieldQueryParser parser = new MultiFieldQueryParser(version, new string[] { "name", "job" }, analyzer);//多个字段查询 369 //Query query = parser.Parse("小王"); 370 371 //IndexReader reader = IndexReader.Open(directory_luce, false); 372 //reader.DeleteDocuments(term); 373 //Response.Write("删除记录结果: " + reader.HasDeletions + "<br/>"); 374 //reader.Dispose(); 375 376 IndexWriter writer = new IndexWriter(directory_luce, analyzer, false, IndexWriter.MaxFieldLength.LIMITED); 377 writer.DeleteDocuments(term); // writer.DeleteDocuments(term)或者writer.DeleteDocuments(query); 378 ////writer.DeleteAll(); 379 writer.Commit(); 380 //writer.Optimize();// 381 IsSuccess = writer.HasDeletions(); 382 writer.Close(); 383 return IsSuccess; 384 } 385 #endregion 386 387 #region 删除全部索引数据 388 /// <summary> 389 /// 删除全部索引数据 390 /// </summary> 391 /// <returns></returns> 392 public bool DeleteAll() 393 { 394 bool IsSuccess = true; 395 try 396 { 397 IndexWriter writer = new IndexWriter(directory_luce, analyzer, false, IndexWriter.MaxFieldLength.LIMITED); 398 writer.DeleteAll(); 399 writer.Commit(); 400 writer.Optimize();// 401 IsSuccess = writer.HasDeletions(); 402 writer.Close(); 403 } 404 catch 405 { 406 IsSuccess = false; 407 } 408 return IsSuccess; 409 } 410 #endregion 411 412 #region directory_luce 413 private Lucene.Net.Store.Directory _directory_luce = null; 414 /// <summary> 415 /// Lucene.Net的目录-参数 416 /// </summary> 417 public Lucene.Net.Store.Directory directory_luce 418 { 419 get 420 { 421 if (_directory_luce == null) _directory_luce = Lucene.Net.Store.FSDirectory.Open(directory); 422 return _directory_luce; 423 } 424 } 425 #endregion 426 427 #region directory 428 private System.IO.DirectoryInfo _directory = null; 429 /// <summary> 430 /// 索引在硬盘上的目录 431 /// </summary> 432 public System.IO.DirectoryInfo directory 433 { 434 get 435 { 436 if (_directory == null) 437 { 438 string dirPath = HttpContext.Current.Server.MapPath("/LuceneDic"); 439 if (System.IO.Directory.Exists(dirPath) == false) 440 _directory = System.IO.Directory.CreateDirectory(dirPath); 441 else 442 _directory = new System.IO.DirectoryInfo(dirPath); 443 } 444 return _directory; 445 } 446 } 447 #endregion 448 449 #region analyzer 450 private Analyzer _analyzer = null; 451 /// <summary> 452 /// 分析器 453 /// </summary> 454 public Analyzer analyzer 455 { 456 get 457 { 458 //if (_analyzer == null) 459 { 460 // _analyzer = new Lucene.Net.Analysis.PanGu.PanGuAnalyzer();//弃用盘古分词,感觉有点问题,测试下来没有自带分词好用,也有可能是好用的,但是之前用的高版本lucene.net,导致分词失效 461 _analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_29); 462 } 463 return _analyzer; 464 } 465 } 466 #endregion 467 468 #region version 469 private static Lucene.Net.Util.Version _version = Lucene.Net.Util.Version.LUCENE_29; 470 /// <summary> 471 /// 版本号枚举类 472 /// </summary> 473 public Lucene.Net.Util.Version version 474 { 475 get 476 { 477 return _version; 478 } 479 } 480 #endregion 481 /// <summary> 482 /// 盘古分词的配置文件 483 /// </summary> 484 protected static string PanGuXmlPath 485 { 486 get 487 { 488 return HttpContext.Current.Server.MapPath("/PanGu/PanGu.xml"); 489 } 490 } 491 }
然后是一些需要引用的DLL和盘古分词的字典文件等,如下所示:
至此Lucene.net的简单应用到此结束,谢谢!
不积跬步无以至千里,不积小流无以成江海。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号