代码实战之AdaBoost
尝试用sklearn进行adaboost实战 & SAMME.R算法流程,博客地址
- 初试AdaBoost
- SAMME.R算法流程
- sklearn之AdaBoostClassifier类
- 完整实战demo
初试AdaBoost
一个简单的例子,来介绍AdaBoostClassifier。
例子放在Github上,可以直接fork。
#coding=utf-8 #python 3.5 ''' Created on 2017年11月24日 @author: Scorpio.Lu ''' ''' 在scikit-learn库中,有AdaBoostRegression(回归)和AdaBoostClassifier(分类)两个。 在对和AdaBoostClassifier进行调参时,主要是对两部分进行调参:1) AdaBoost框架调参;2)弱分类器调参 ''' #导包 from sklearn.model_selection import cross_val_score from sklearn.datasets import load_iris from sklearn.ensemble import AdaBoostClassifier #载入数据,sklearn中自带的iris数据集 iris=load_iris() ''' AdaBoostClassifier参数解释 base_estimator:弱分类器,默认是CART分类树:DecisionTressClassifier algorithm:在scikit-learn实现了两种AdaBoost分类算法,即SAMME和SAMME.R, SAMME就是原理篇介绍到的AdaBoost算法,指Discrete AdaBoost SAMME.R指Real AdaBoost,返回值不再是离散的类型,而是一个表示概率的实数值,算法流程见后文 两者的主要区别是弱分类器权重的度量,SAMME使用了分类效果作为弱分类器权重,SAMME.R使用了预测概率作为弱分类器权重。 SAMME.R的迭代一般比SAMME快,默认算法是SAMME.R。因此,base_estimator必须使用支持概率预测的分类器。 loss:这个只在回归中用到,不解释了 n_estimator:最大迭代次数,默认50。在实际调参过程中,常常将n_estimator和学习率learning_rate一起考虑 learning_rate:每个弱分类器的权重缩减系数v。f_k(x)=f_{k-1}*a_k*G_k(x)。较小的v意味着更多的迭代次数,默认是1,也就是v不发挥作用。 另外的弱分类器的调参,弱分类器不同则参数不同,这里不详细叙述 ''' #构建模型 clf=AdaBoostClassifier(n_estimators=100) #弱分类器个数设为100 scores=cross_val_score(clf,iris.data,iris.target) print(scores.mean())
SAMME.R算法流程
- 初始化样本权值:$ w_i=1/N,i=1,2,…,N $
- Repeat for $ m=1,2,…,M $:
- 训练一个弱分类器,得到样本的类别预测概率分布 $ p_m(x)=P(y=1|x)∈[0,1] $
- $f_m(x)=\frac{1}{2}log\frac{p_m(x)}{1-p_m(x)}$
- $w_i=w_iexp[-y_if_m(x_i)]$,同时,要进行归一化使得权重和为1
- 得到强分类模型:$sign{\sum_{m=1}^{M}f_m(x)}$
AdaBoostClassifier类
现在我们来说点理论的东西。关于AdaBoostClassifier。
sklearn.ensemble.AdaBoostClassifier的构造函数如下:
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’, random_state=None)
各个参数已经在代码里介绍过了,这里不再叙述。有一点要注意,理论上可以选择任何一个弱分类器,不过需要有样本权重。
另外有方法:
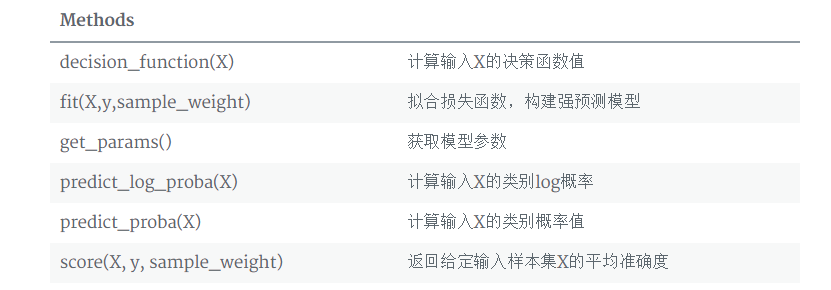
另外一些方法请见官网sklearn-AdaBoost
完整实战demo
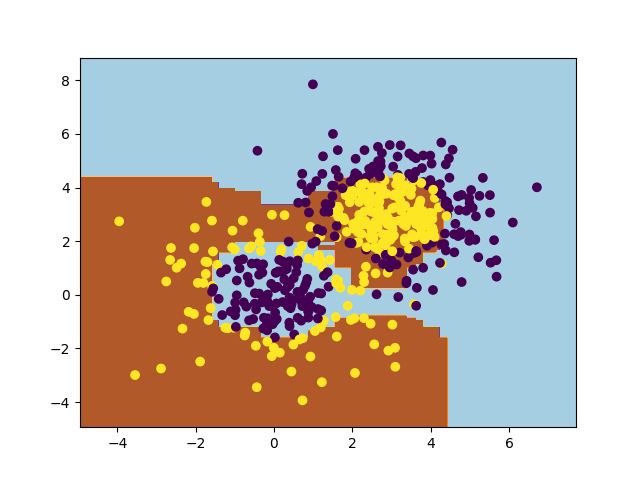
现在再来一个完整的demo,来看看AdaBoost的分类效果
#coding=utf-8 #python 3.5 ''' Created on 2017年11月27日 @author: Scorpio.Lu ''' import numpy as np import matplotlib.pyplot as plt from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import make_gaussian_quantiles #用make_gaussian_quantiles生成多组多维正态分布的数据 #这里生成2维正态分布,设定样本数1000,协方差2 x1,y1=make_gaussian_quantiles(cov=2., n_samples=200, n_features=2, n_classes=2, shuffle=True, random_state=1) #为了增加样本分布的复杂度,再生成一个数据分布 x2,y2=make_gaussian_quantiles(mean=(3,3), cov=1.5, n_samples=300, n_features=2, n_classes=2, shuffle=True, random_state=1) #合并 X=np.vstack((x1,x2)) y=np.hstack((y1,1-y2)) #plt.scatter(X[:,0],X[:,1],c=Y) #plt.show() #设定弱分类器CART weakClassifier=DecisionTreeClassifier(max_depth=1) #构建模型。 clf=AdaBoostClassifier(base_estimator=weakClassifier,algorithm='SAMME',n_estimators=300,learning_rate=0.8) clf.fit(X, y) #绘制分类效果 x1_min=X[:,0].min()-1 x1_max=X[:,0].max()+1 x2_min=X[:,1].min()-1 x2_max=X[:,1].max()+1 x1_,x2_=np.meshgrid(np.arange(x1_min,x1_max,0.02),np.arange(x2_min,x2_max,0.02)) y_=clf.predict(np.c_[x1_.ravel(),x2_.ravel()]) y_=y_.reshape(x1_.shape) plt.contourf(x1_,x2_,y_,cmap=plt.cm.Paired) plt.scatter(X[:,0],X[:,1],c=y) plt.show()
训练完成后的错误率大概是0.116。分类效果图如下:
作者 Scorpio.Lu
转载请注明出处!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号