48 容器(七)——HashMap底层:哈希表结构与哈希算法
哈希表结构
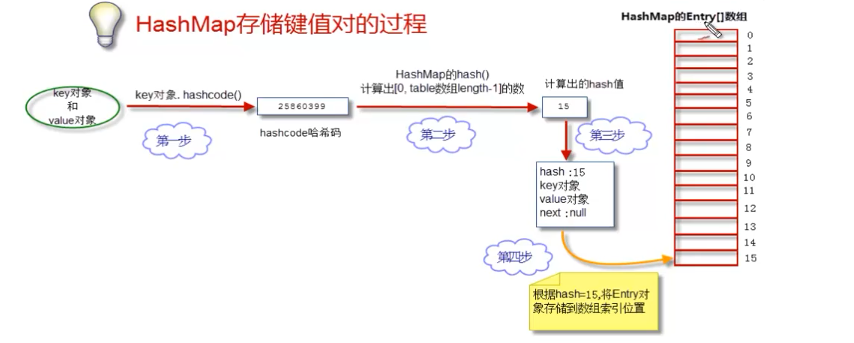
哈希表是由数组+链表组成的,首先有一个数组,数组的每一个位置都用来存储一个链表,链表的基本节点为:【hash值,key值,value值,next】,当存入一个键值对时,首先调用hashcode()方法获得key的hashcode,然后通过算法计算出hash值,当不同的key取到相同的hash值时,后面的key作为一个节点连接到前一个相同hash值的key的节点。
hash值的算法
最差的算法:hashcode/hashcode 会将所有的元素存储在数组的下标1位,实际上已经退化为一个数组
常用的算法是:hashcode%数组长度
通过这个算法将得到[0,数组长度-1]的值,即hash值。这种算法可以使各key尽可能均匀的分布在数组中。这种表也称作“散列(hash的翻译)表”。
优化算法:同样是取余数,但是进行了优化。首先约定数组的长度为2的整数幂,然后通过位运算快速得道hash值:hashcode&(数组长度-1)
下面验算一下算法:
public class Test {
public static void main(String[] args) {
Test t = new Test();
//算法:hashcode%数组长度,假设数组长度为16(2的4次方)
System.out.println(t.hashCode()%16);
System.out.println(t.hashCode()&(16-1));
}
}
结果:
2
2
后面又优化了一次,是目前使用的hash值算法(我看不懂):

get方法底层
调用get方法时,会通过传入的key值,调用hashCode()方法获得key对象相应的hashCode值,然后通过计算获得hash值,与位桶数组(就是hash表的数组)的对应位置的链表中的各节点逐个进行比较,如相同,则返回该value。
equals方法比较的就是hashCode值,如果a.equals(b)为true,那么a与b的hashCode值一直相等。
get方法调用了getNode方法,一下为getNode源码:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
拆开分析:

哈希表的扩容
HashMap的位桶数组,初始大小为16。当位桶数组中的元素到达(0.75*数组length),就重新调整数组大小为原来的2倍。
但扩容很耗时。
当位桶数组的列表长度大于8时,链表会转换为红黑树,这将大大提高查找效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号