

树分治
树分治
参考资料:
点分治详解 - Ying xue Cat:最适合入门的一篇,详细地展示了从暴力优化到点分治核心思想的过程。一针见血地,“使用点分治的前提条件是我们不那么关心树的具体形态,比如 路径、连通块 相关的问题”。
点分治学习笔记 - Menci:这人头像是库公:)
树分治小记 - command_block:无需多言。
https://www.luogu.com.cn/blog/221955/shu-fen-zhi-zong-jie-dian-bian-fen-zhi-dian-bian-fen-shu-post
前言:
- 以下提到的所有例题,若未经特殊说明,树的大小均为 \(10^5\) 级别。
- 知识点并不全面,比如链分治没有在本篇文章中单独讨论。
点分治入门1
由于 点分治详解 - Ying xue Cat 已经讲得足够清晰了,因此此处只摘抄其中的一些重点:
-
点分治是一个快速处理树上问题的好方法。
这里的「树上问题」,指使用点分治的前提条件是我们 不那么关心树的具体形态,比如 路径、连通块 相关的问题。
-
对于路径类问题,对于每个点 \(u\),我们统计 所有以点 \(u\) 为 LCA 的点对 对答案的贡献。
-
枚举 LCA 后,直接暴力的时间复杂度与 \(O(\sum{dep_i})\) 有关。
想最小化 \(\sum{dep_i}\),我们要做的就是在这个做法的基础上想办法降低树的高度,而这就是点分治要做的事。
-
定义:对于树上的每一个点,计算其所有子树中最大的子树节点数,这个值最小的点就是这棵树的重心。
由此,我们可以得出重心的性质:以树的重心为根时,所有子树的大小都不超过整棵树大小的一半。
至于怎么找重心,上述定义和性质看起来等价,似乎根据哪个来判断对结果并没有影响。
但在点分治的过程中,我们钦定使用定义来判断;这样做的原因会在后文提到。
-
如果选择子树的重心继续递归,这棵子树的树高一定不超过 \(\frac{sz_{u}}{2}\)。
那么每次的树高都减半的话,递归层数不会超过 \(\log_{2}{n}\),点分治 \(O(n\log{n})\) 的复杂度就得到了保证。
(其实点分治没有改变原树的树高,但通过改变递归顺序减少了递归层数,其实也就等同于降低了树的高度。)
-
换了根节点之后需要保证不会走到子树外面,这需要开一个标记数组判断是否以某个点作为根进行计算。
-
calc里面可以使用双指针、容斥等技巧,这些是实现能力的问题,与算法本身无关,故不赘述。 -
梳理大体步骤:
- 找当前子树的重心 (find)
- 统计 以重心为根时 以重心为 LCA 的点对 的贡献 (calc)
- 以重心为根,递归处理它的子树 (solve)
-
一种错误的点分治写法:
void solve(int now) { vis[now]=1,calc(now); for(int i=head[now];i;i=e[i].nxt) { int v=e[i].to; if(vis[v]) continue; // find(v,now); S=siz[v],rt=0,mx[0]=1e9; find(v,now); solve(rt); } }如果没有写注释里的语句,那么
siz[v]传的就不是当前操作子树的实际大小。可以证明,如果
find(找根)函数内以定义判断重心,则时间复杂度仍然正确;但如果以 \(\frac{sz}{2}\) 判断重心,则时间复杂度错误。所以最好用定义来判断重心。
好像也没有很省流。
P4178 Tree
Problem
给定一棵 \(n\) 个节点的树,每条边有边权,求出树上两点距离小于等于 \(k\) 的点对数量。
Solution
洛谷上模板题的多测有点太憨了,感觉这个题更有价值。
只考虑 calc 的部分:把子树内所有点到当前根节点 \(root\) 的距离存下来,然后做双指针。
由于这样可能计入源于 \(root\) 的同一棵子树内的两个点所拼成的折返路径,因此需要将这部分的数量减掉。
作为模板题给出一个完整代码。
// Sea, You & Me
const int N = 4e4 + 5;
const int INF = 1e9 + 7;
int n, K, ans;
vector<PII> G[N];
int sz[N];
struct Shiroha
{
int root, nowsz;
int vis[N];
int maxp[N];
int depth[N];
int g[N], gcnt;
void get_root(int u, int fa)
{
sz[u] = 1, maxp[u] = 0;
for(auto nxt : G[u])
{
int v = nxt.fi;
if(v == fa || vis[v])
continue;
get_root(v, u);
sz[u] += sz[v];
chkmx(maxp[u], sz[v]); // not chkmx(maxp[u], maxp[v]) !!!
}
chkmx(maxp[u], nowsz - sz[u]);
if(maxp[u] < maxp[root]) root = u;
}
void get_dist(int u, int fa)
{
g[++gcnt] = depth[u];
for(auto nxt : G[u])
{
int v = nxt.fi;
if(v == fa || vis[v])
continue;
depth[v] = depth[u] + nxt.se;
get_dist(v, u);
}
}
int calc(int u, int v)
{
int res = 0;
gcnt = 0;
depth[u] = v;
get_dist(u, 0);
sort(g + 1, g + gcnt + 1);
for(int r = gcnt, l = 0; r >= 1; --r)
{
while(l + 1 < r && g[l + 1] + g[r] <= K) ++l;
res += min(l, r - 1);
}
return res;
}
void PDC(int u)
{
vis[u] = 1, ans += calc(u, 0);
for(auto nxt : G[u])
{
int v = nxt.fi;
if(vis[v]) continue;
ans -= calc(v, nxt.se); // from the same subtree
get_root(v, 0); // just to get sz
nowsz = sz[v];
maxp[root = 0] = INF;
get_root(v, 0);
PDC(root);
}
}
}umi;
int main()
{
read(n);
for(int i = 1; i < n; ++i)
{
int x, y, z;
read(x), read(y), read(z);
G[x].EB(MP(y, z));
G[y].EB(MP(x, z));
}
read(K);
umi.PDC(1);
printf("%d\n", ans);
return 0;
}
P4149 [IOI2011] Race
Problem
给一棵树,每条边有权。求一条简单路径,权值和等于 \(k\),且边的数量最小。
Solution
维护 \(f_{d}\) 表示到根的距离为 \(d\) 时边数的最小值,然后直接更新即可,时间复杂度 \(O(n\log{n})\)。
P6626 [省选联考 2020 B 卷] 消息传递
Problem
给定一棵树,\(m\) 组询问 \(x, k\),查询与点 \(x\) 相距长度为 \(k\) 的点数。
Solution
把询问挂在点上,然后 calc 时前缀算一遍,后缀算一遍。
点分治过程本身是 \(O(n\log{n})\) 的;每个询问对应的点的深度在分治之后是 \(O(\log{n})\) 级别的,因此处理询问部分的时间复杂度是 \(O(m\log{n})\) 的。
P5351 Ruri Loves Maschera
Problem
给定一棵边带边权的树,定义有向路径的权值为经过边权最大值,求路径边数 \(\in [L, R]\) 的所有路径的权值和。
Solution
维护每种链长的 \(\max(v_i)\) 的总和,然后发现拼接算贡献时需要快速查询前缀和,写一个树状数组即可,时间复杂度 \(O(n\log^{2}{n})\)。
CF293E Close Vertices
Problem
给定一棵边带边权的树和参数 \(l, w\),求简单路径边数 \(\le l\)、边权和 \(\le w\) 的点对数量。
Solution
相当于 P4178 Tree 的二维版本,乍一眼看上去要三维数点,有点吓人。
但其实还是可以仿照那个题的思路,在 calc 里面排序后双指针,只是由于多了一维的限制,需要求前缀和。
那么上树状数组就可以了,时间复杂度 \(O(n\log^{2}{n})\)。
点分治入门2
接下来要动点脑子了。
P5306 [COCI2018-2019#5] Transport
Problem
Solution
P3060 [USACO12NOV] Balanced Trees G
Problem
给出一棵树,每个结点上有一个括号。问在所有括号平衡的路径中,最大嵌套层数为多少。
Solution
当前分治中心为 \(root\)。
首先把括号表示转成数字表示,可以发现一个括号序列可以用 \(\pm x\) 表示,代表它的左括号比右括号多多少。
对于一条经过 \(root\) 的路径,把它看成一条 \(+x\) 路径与一条 \(-x\) 路径的拼接,
P7215 [JOISC2020] 首都
Problem
给定一棵点带颜色的树,定义一次合并 \((x, y)\) 可以将所有颜色为 \(y\) 的节点的颜色染成 \(x\)。
求最少合并多少次使得存在一个连通块使得其中包含的颜色不在连通块外部出现。
Solution
这也能点分治!
首先考虑暴力:假设答案连通块内包含点 \(u\),那么以 \(u\) 为根,将 \(u\) 的颜色入队,然后不断取出一种颜色,遍历该种颜色的所有节点,并对这些节点向父节点跳一步,如果碰到新的颜色就将新的颜色入队,直到队列为空。这样就得到了包含 \(u\) 的极小合法连通块,对一个初始扩展点进行扩展的时间复杂度为 \(O(n)\)。
可以想到以初始扩展点为点分治的分治中心 \(root\)。如果在扩展过程中遍历到了分治子树之外的某个点 \(x\),则以 \(root\) 为初始点扩展的队列中包含以 \(x\) 作为初始点扩展队列的初始形态,那么以 \(root\) 扩展得到的连通块一定不小于以 \(x\) 扩展得到的连通块,所以以 \(root\) 扩展得到的连通块一定不优,可以直接终止扩展。换句话说,我们 只关心完全包含在当前分治子树内的合法连通块。
时间复杂度 \(O(n\log{n})\)。
最后一提的是,曾经有一个错误的想法,以为原树可以拆成若干个互不相交的极小合法连通块,则对于同一个极小合法连通块 \(S\) 内的点 \(u, v\) 分别扩展,会得到同样的结果。这显然可以用 2 - 1 - 1 - 2 一条链给否决掉。
实在是一道漂亮的点分治题。
点分治入门3
接下来要废点脑子了。
P2664 树上游戏
Problem
给定一棵树,树的每个节点有个颜色。
给一个长度为 \(n\) 的颜色序列,定义 \(s(i,j)\) 为 \(i\) 到 \(j\) 的颜色数量,以及 \(sum_i=\sum_{j=1}^n s(i, j)\)。请求出所有的 \(sum_i\)。
Solution
省流,这个题的重点就是拆贡献。
对于当前的分治中心 \(root\),先把以 \(root\) 为端点到子树内的路径对 \(root\) 的贡献做了,这是容易的。
然后考虑子树内的点 \(x\) 经过 \(root\) 对 \(x\) 产生的贡献,这个贡献拆到每一种颜色上进行统计。
我们发现对 \(x\) 产生贡献的颜色分为两类:
-
第一类颜色:是在 \(x \to root\) 的路径上出现过的、必然会被计入答案的,记为 \(S_{1}\)。
该类颜色对 \(x\) 的贡献为 \((sz_{root} - sz_{u}) \times |S_{1}|\),其中 \(u\) 是 \(x\) 方向上 \(root\) 的子节点。
-
第二类颜色:没有出现在 \(x \to root\) 的路径上的,记为 \(S_{2}\)。
记 \(cnt_{c}\) 表示以 \(root\) 和子树内一点为端点且包含颜色 \(c\) 的路径数,则该类颜色对 \(x\) 的贡献为 \(\sum\limits_{c \in S_{2}}cnt_{c}\)。
这些信息的处理都是容易的。具体地,先预处理出 \(sz\) 和所有颜色的 \(cnt\) 之和,然后对于一棵子树先把子树内对 \(cnt\) 的贡献清掉,再递归到每一个 \(x\) 更新答案,不断增加第一类颜色的贡献,减去第二类颜色的贡献。
CF566C Logistical Questions
洛谷:CF566C Logistical Questions
Codeforces:CF566C Logistical Questions
Problem
一棵 \(n\) 个节点的树,点有点权,边有边权。两点间的距离定义为两点间边权和的 \(\frac 32\) 次方。求这棵树的带权重心。
(重心必须在点上,权值也是根据答案重心来算的)
Solution
神。
假设重心为 \(u\)。直接写出以 \(u\) 为重心的权值表达式:
考察将 \(u\) 在路径 \(path(s, t)\) 上移动(我们先允许 \(u\) 可以在边上)。
注意到 \(d(u, i)\) 均为下凸函数,且 \(a_{i} \ge 0\),因此 \(a_{i}\times d(u, i)\) 均为下凸函数 ,下凸函数之和为下凸函数。
这说明,从带权重心向四处扩散,\(f\) 的大小是单调不降的。
先考虑一个暴力算法,随便拎一个点作为初始重心 \(u\),此时这个点把树分成了若干连通块。
则可以断言,只有一条出边 \(u \to v\) 使得 \(u\) 向 \(v\) 移动时 \(f\) 值呈下降趋势。
这个趋势是没法直观地用 \(f\) 来表示的,但是你已经是一个成熟的 高中生 OIer 了!你直接想到利用导数!
为了能够更好地展现这个变化趋势,我们以重心从 \(u\) 向 \(v\) 移动的距离 \(x\) 作为自变量,重新写出 \(f\) 的表达式:
求导可得:
我们只需判断 \(u \to v\) 时 \(f^{'}(0)\) 是否 \(< 0\) 即可。
如果没有一条出边使得 \(f^{'}(0) < 0\),则可断言 \(u\) 就是最终的答案重心。
对当前重心 \(u\),子树内 \(\frac{3}{2}a_{i}\times (d(u, i) + x)^{\frac{1}{2}}\) 的和是可以 \(O(n)\) 处理的,因此判断移动方向可以在 \(O(n)\) 时间内完成。
由于我们只关心移动方向,换句话说,我们只关心答案重心在哪个连通块,因此并不关心树的具体形态,可以直接用点分治进行优化。
与大部分点分治题目不同的是,此题的 calc 过程中将对整棵树进行遍历,而分治中心最多只会枚举 \(O(\log{n})\) 个。
此题开门见山,起笔壮阔,而后挑灯看剑,波澜不惊,实乃神作。
P4183 [USACO18JAN] Cow at Large P
Problem
贝茜被农民们逼进了一个偏僻的农场。农场可视为一棵有 \(N\) 个结点的树,结点分别编号为 \(1,2,\ldots, N\) 。每个叶子结点(度数为 \(1\) 的点)都是出入口。开始时,每个出入口都可以放一个农民(也可以不放)。每个时刻,贝茜和农民都可以移动到相邻的一个结点。如果某一时刻农民与贝茜相遇了(在边上或点上均算),则贝茜将被抓住。抓捕过程中,农民们与贝茜均知道对方在哪个结点。
请问:对于结点 \(i\,(1\le i\le N)\) ,如果开始时贝茜在该结点,最少有多少农民,她才会被抓住。
Solution
首先考虑 Bessie 起始点固定的情况,即整棵树的根确定。
农民在从叶节点往上移动,相当于在扩大 封锁子树 的范围,而这些范围的并集必须包含所有叶节点。考察一个农民封锁子树的范围,只需考察该子树的根,我们记其为 封锁点。
记 \(w_{u}\) 表示 \(u\) 与叶节点的最近距离,\(d(u, v)\) 表示点 \(u, v\) 间的距离,则点 \(u\) 可以成为封锁点的条件是:\(w_{u} \le d(u, root)\)。
贪心地考虑:如果 \(u\) 的父亲 \(fa\) 是封锁点,那么 \(u\) 一定是封锁点,但选取 \(fa\) 一定比选取 \(u\) 更优。
我们称这样的点为 决策点:不仅它是封锁点,而且其父亲不是封锁点,即:\(w_{u} \le d(u, root) \land w_{fa_{u}} > d(fa_{u}, root)\)。
统计上述节点的数量,即能得到一个答案。统计出所有答案的时间复杂度为 \(O(n^{2})\),无法通过。
接下来有两种优化思路。
-
无脑上点分治,对于分治子树内的所有点对 \((u, v)\)(\(u, v\) 不在同一棵子树内),向 \(v\) 贡献 \([w_{u} \le d(u, v) \land w_{fa_{u}} > d(fa_{u}, v)]\)。
上述贡献条件是二位偏序的形式,直接上数据结构数点即可。
-
神。思想是,由于变化的 \(fa_{u}\) 不方便处理,于是先用某个恒定的量替换掉 \(fa_{u}\)。这里即为度数。
Observation:\(\sum\limits_{v \in subtree(u)}deg_{v} = 2 \times sz_{u} - 1 \iff \sum\limits_{v \in subtree (u)}(2 - deg_{v}) = 1\)。
结合上文的贪心策略,我们知道:
- 决策点与封锁子树构成双射,这暗示以某种适当的方式统计子树可以不重不漏地表示出决策点的信息;
- 封锁子树内的所有点都是封锁点。
由此导出一个重要结论:封锁点的 \(2 - deg_{u}\) 之和等于决策点个数,即为答案。
具体地,\(ans_{u} = \sum\limits_{i = 1}^{n}[w_{i} \le d(u, i)](2 - deg_{i})\)。
注意,如果根节点本身就是一个封锁点——这只可能存在于根节点是一个度数为 \(1\) 的节点——即叶节点,那么上述等式不成立,需要特判。
时间复杂度 \(O(n\log^{2}{n})\)。可能也可以做到 \(O(n\log{n})\),但我不是很在意这只老哥。
P9678 [ICPC2022 Jinan R] Tree Distance
Problem
给你一棵 \(n\) 个点的树。记 \(\operatorname{dist}(i,j)\) 为树上 \(i,j\) 之间唯一简单路径的长度。
你要回答 \(q\) 次询问:给定 \(l,r\),求 \(\min\limits_{l\leq i<j\leq r}(\operatorname{dist}(i,j))\)。\(1\leq n\le 2 \times 10^5\),\(1\leq q\le 10^6\)。
CF786D Rap God
Problem
给定 \(n\) 个点的树,每条边有小写字母,定义 \(str(a,b)\) 是 \(a\) 到 \(b\) 的最短路径上将每条边的字符拼接起来所得的字符串。
\(q\) 次询问点对 \(x,y\),求有多少个点 \(z\) 满足 \(z\ne x,y\) 且 \(str(x,y)>str(x,z)\)。\(n,q\le 2\cdot 10^4\),\(1\le x,y\le n\),\(x\ne y\)。
Solution
Rap God (Codeforces Round 406 Div 1 problem D)
点分治。把询问 \((x, y)\) 挂在 \(x\) 上,一个询问只会被处理 \(\log{n}\) 次。
记当前分治中心为 \(root\)。
考察子树内的一个路径起点 \(x\) 及其某个询问 \((x, y)\) 能对应多少个点 \(z\),使得 \(x, z\) 的最近公共祖先为 \(root\) 并且 \(str(x, y) > str(x, z)\)。
由于 \(x \to z\) 的路径必然经过 \(root\),所以可以把 \(x \to z\) 拆分为 \(x \to a\) 和 \(root \to z\),其中 \(a\) 是 \(root\) 在 \(x\) 方向上的子节点。
我们可以先判定 \(str(x, a)\) 与 \(str(x, y)\) 的等长前缀 \(str(x, b)\) 的关系:
- 若 \(str(x, a) > str(x, b)\):则没有能对当前询问产生贡献的 \(z\)。
- 若 \(str(x, a) < str(x, b)\):则有 \(sz_{root} - sz_{a}\) 个点 \(z\) 能对当前询问产生贡献。
- 若 \(str(x, a) = str(x, b)\):则需要比较 \(str(root, z)\) 与 \(str(x, y)\) 的后缀 \(str(c, y)\)。
前两种情况是容易的,难点在第三种情况。
考虑将以 \(root\) 作为起点、子树内的任意点作为终点的所有路径拉出来建一棵字典树,同时对每个节点记录以该节点结束的路径条数,并假设子节点按照入边字母大小从左到右排列。
则有一个很好想的暴力,在字典树上沿 \(str(c, y)\) 走,并不断加上小于当前字母的所有左侧子树的点权和。
你发现一步一步跳实在是太憨了,于是考虑预处理出字典树的根到每一个节点的跳跃过程中所累加的左子树点权和。
在具体考虑有多少个 \(str(root, z) < str(c, y)\) 时,可以直接二分出 \(str(c, y)\) 能在字典树上能匹配到的最深的节点,只需在最后一步没有出边能与 \(str(c, y)\) 时枚举出边累计子树点权和。
前缀相等后的二分算贡献是算法的瓶颈,二分有一只老哥,由于是树上求字符串哈希值所以还要倍增一下,又上一只老哥。外层再套一只点分治的老哥,总时间复杂度为 \(O((n + Q)\log^{3}{n})\)。
有必要说明一些实现上的问题。
-
预处理每个节点到根的正反哈希值,然后倍增实现快速查询 \(x \to y\) 的前 \(len\) 条边组成的字符串的哈希值。类似地还需要实现快速查询 \(x \to y\) 经过 \(len\) 条边后到达的点、第 \(len\) 条边的字符以及两条路径的最长公共前缀等函数。
-
有一个很烦的事情是,你要消除询问点所在子树对字典树的贡献。
一个好写的做法是,先不消除贡献地整体算一遍,再对每棵子树分别建字典树消除贡献,显然这样复杂度仍然是正确的。
-
为了方便查错,可以把子树内的所有查询存到一个
vector里面统一查询,而不是在递归过程查询。 -
被卡哈希了,我最后还是选择写双模数哈希。
点分治与单调队列按秩合并
CF150E Freezing with Style
Problem
给定一颗带边权的树和参数 \(L, R\),求一条边数在 \(L, R\) 之间的路径,并使得路径上边权的中位数最大。输出一条可行路径的两个端点。
注意这里的中位数定义为第 \(\lfloor \frac{cnt}{2} \rfloor + 1\) 小的数,其中 \(cnt\) 表示数列长度。
Solution
采用中位数的经典套路,二分中位数 \(mid\),然后把 \(< mid\) 的边权设为 \(-1\),\(\ge mid\) 的边权设为 \(1\),则判断答案是否 \(\ge mid\) 只需看新赋权的树上是否存在一条长度在 \([L, R]\) 的路径的边权和 \(\ge 0\)。
上点分治,对于当前分治中心 \(root\),记 \(f_{i}\) 表示到 \(root\) 距离为 \(i\) 的路径的边权和最大值,显然有一个用线段树维护 \(f\) 的做法,但是时间复杂度是三只老哥,难以通过。
考虑遍历当前子树时,按节点深度从小到大进行遍历,发现更新答案时相当于对 \(f\) 做下标值域上从大到小的滑动窗口。
为了保证时间复杂度,这个过程不必也不能将子树内的点全部拿出来排序,使用 BFS 即可做到按深度从小到大的线性遍历。对于本题,更简单地实现方法是直接 DFS,用一个桶记录一下每种深度对应的最大值,然后做一个简单的单调队列。
但是 考虑到初始化单调队列的时间消耗,假设一开始遍历的就是深度最大的那个子树,那么之后的初始化时间消耗会非常巨大,可以直接卡成 \(O(n^2)\)。
所以想到将子树按照深度从小到大排序,容易发现,排序后再做单调队列的初始化时间复杂度与以 \(root\) 为根的子树大小同级。
另一方面指出,对子树排序操作的总时间复杂度是 \(O(n\log{n})\) 的,而不是在点分治的老哥上再套一只老哥。说明一下这个操作的时间复杂度:假设每次与 \(root\) 相连的边数为 \(s_{i}\),则时间为 \(O(\sum{s_i}\log{s_{i}})\)。由于每次分治下去后,与 \(root\) 相连的边就 "断" 了,因此每条边只会被排序一次,即 \(\sum{s_i} = O(n)\),所以 \(O(\sum{s_i}\log{s_{i}}) \sim O(n\log{n})\)(由多元均值不等式可知)。
输出方案是容易的,把路径端点和权值绑定在一起。
故最终算法的时间复杂度为 \(O(n\log^{2}{n})\)(离散化)。code CF150E
P3714 [BJOI2017] 树的难题
Problem
给定一棵树,树上的每个边有一个颜色,每种颜色对应一个权值。
对于一条树上的简单路径,路径上经过的所有边按顺序组成一个颜色序列,序列可以划分成若干个相同颜色段。定义路径权值为颜色序列上每个同颜色段的颜色权值之和。
给定 \(L, R\),计算边数 \(\in [L, R]\) 的所有简单路径中路径权值的最大值。
Solution
对于当前的分治中心 \(root\),对其子树内的每个点计算 \(sum_{u}\) 表示点 \(u\) 到 \(root\) 的路径的权值,这是容易的。
然后考虑拼接路径 \(i \to root\) 和 \(j \to root\),这分为两种情况。记 \(col_{u}\) 表示 \(root \to u\) 的路径上靠近 \(root\) 一端的第一条边的颜色:
-
一种是 \(col_{i} = col_{j} = c\),则权值为 \(sum_{i} + sum_{j} - w_{c}\)。
-
另一种 \(col_{i} \neq col_{j}\),则权值即为 \(sum_{i} + sum_{j}\)。
不管哪一类,都需要保证 \(d_{i} + d_{j} \in [l, r]\),其中 \(d_{x}\) 表示 \(x\) 到 \(root\) 的距离。
然后将子树按照 \(col\) 的大小进行排序,使得 \(col\) 相同的子树是连续的,这样方便我们维护一棵与当前子树 \(col\) 相同的线段树 \(T_{1}\) 和一棵与当前子树 \(col\) 不同的线段树 \(T_{2}\),然后按照上面的分类讨论更新答案。当子树的 \(col\) 值改变时,将 \(T_{1}\) 的信息合并到 \(T_{2}\) 上并将 \(T_{1}\) 清空。
时间复杂度是 \(O(n\log^{2}{n})\),其实还是挺好写的。code P3714 - \(O(n\log^{2}{n})\)
但是我们并不满足于此,是时候让单调队列上场了。
维护 \(f_{i}, g_{i}\) 分别表示与当前子树 \(col\) 相同 / 不同的长度为 \(i\) 的路径中 \(sum\) 的最大值,它们的更新都是容易的。
对同一棵子树内的点,按照它们的 \(d\) 从小到大去更新答案,这相当于对 \(f, g\) 做下标值域从大到小的滑动窗口。
为了保证时间复杂度,对于同一颜色的子树,保证它们是相邻的,按子树深度从小到大排序;对于不同颜色的子树,以该种颜色的所有子树的最大深度从小到大排序。
对于 \(col\) 相同的答案更新,需要对每一棵子树都做一遍 \(f\) 的单调队列,这部分的时间复杂度显然是与 \(root\) 子树大小同级。
对于 \(col\) 不同的答案更新,就不能对每一棵子树都做 \(g\) 的单调队列,而应该等同种颜色的子树都遍历完后,对这种颜色的子树整体做一遍 \(g\) 的单调队列,使得复杂度也与 \(root\) 子树大小同级。
时间复杂度 \(O(n\log{n})\)。如果采用一只老哥的做法的话,感觉这题比上面那道 *3000 困难。
P4292 [WC2010] 重建计划
Problem
点分治与字符串
点分治优化最小生成树
Tree MST
Problem
给定一棵 \(n\) 个节点的树,现有有一张完全图,两点 \(x,y\) 之间的边长为 \(w_x+w_y+dis_{x,y}\),其中 \(dis\) 表示树上两点的距离。求完全图的最小生成树。
Solution
*点分治与古河渚
渚「你好,西瓜冰棒同学」
白羽「你好,红豆沙包同学」
准备囤到 12.24 再做。
2023.12.05 被作为作业题分配给我了。
CF434E Furukawa Nagisa's Tree
洛谷:CF434E Furukawa Nagisa's Tree
Codeforces:CF434E Furukawa Nagisa's Tree
Problem
冈崎朋也要送古河渚一棵点带点权的树。给定常数 \(k, x, y\),其中保证 \(y \le 10^9\),\(y\) 是质数,\(0 \le x < y\),\(1 \le k < y\)。
记\(S(s, e)\) 表示从 \(s\) 出发到 \(e\) 的简单路径,并定义 \(G(S(s, e)) = \sum\limits_{i = 0}^{|S(s, e)| - 1}k^{i}v_{i}\)。
如果 \(G(S(s, e)) \equiv x \pmod{y}\),则路径 \(S(s, e)\) 属于小渚,否则属于朋也。
由于小渚旷了一学期的课,她以为如果路径 \(S(p_1, p_2)\) 和 \(S(p_2, p_3)\) 都属于某个人,则 \(S(p_1, p_3)\) 也属于那个人。
很显然这是不一定正确的。请你求出有多少个三元组 \((p_1, p_2, p_3)\) 满足小渚的预测。
Solution
记 \(f(s, t)\) 表示 \([G(S(s, t)) \equiv x \pmod{y}]\),则答案可以直接写成:
令 \(a_{u} = \sum\limits_{v = 1}^{n}f(v, u)\),\(b_{u} = \sum\limits_{v = 1}^{n}f(u, v)\)(实际上有 \(\sum\limits_{u = 1}^{n}a_{u} = \sum\limits_{u = 1}^{n}b_{u}\))。则答案可以表示为:
于是现在只需要求出所有 \(a_{u}, b_{u}\)。
这是容易用点分治解决的,用 map 存一下即可。
时间复杂度 \(O(n\log^{2}{n})\)。
点分树 & 动态点分治
[ABC291Ex] Balanced Tree
Problem
建立一棵点分树:|
Solution
ABC 史上最简单 EX:|
考虑将点分治的过程具象成一棵树,这棵树就是点分树。
这个题没什么好说的,这里主要讲一下点分树的性质:
-
树高为 \(O(\log{n})\)。
-
所有点的子树大小之和为 \(O(n\log{n})\)。
-
\(u, v\) 在点分树上的最近公共祖先 \(lca\) 一定在 \(u \to v\) 的路径上,即 \(dis(u, v) = dis(u, lca) + dis(lca, v)\)。
注意等式中的 \(dis\) 均定义在原树上!
P6329 【模板】点分树 & 震波
Problem
非常好模板。动态修改点权,对询问 \((x, k)\) 求 \(\sum\limits_{dis(x, y) \le k}a_{y}\)。
Solution
由点分树的上述性质,将 \(dis(x, y) \le k\) 转为 \(dis(x, lca) + dis(lca, y) \le k \iff dis(lca, y) \le k - dis(x, lca)\)。
考虑枚举 \(lca\)(你发现这就是点分治的最初思想),则右式为定值,需查询所有与 \(lca\) 距离 \(\le k - dis(x, lca)\) 且 \(LCA(x, y) = lca\) 的所有点 \(y\) 的点权和。
显然这是不重不漏的,不知道为什么一年前的我好像对此思索了很久。
如果您也有疑虑可以参考我一年前写的笔记,但相比之下不如再好好想想点分治思想的本质是什么,再回来看待点分树。
回归正题,我们发现对于枚举的 \(lca\),记其在 \(x\) 方向上的子节点为 \(s\),则合法的 \(y\) 的集合相当于 \(lca\) 子树中与 \(lca\) 相距 \(\le k - dis(x, lca)\) 的点集 去掉 \(s\) 子树中与 \(lca\) 相距 \(\le k - dis(x, lca)\) 的点集。
这里就会出现一个喜闻乐见的误区:以为后者相当于 \(s\) 子树中与 \(s\) 相距 \(\le k - dis(x, lca) - 1\) 的点集。
我们需要时刻记住,原树上两点间距离不等于点分树上对应两点间的距离。也就是说,这里的 \(dis(lca, s)\) 虽然在点分树上的距离显然为 \(1\),但在原树上可就不一定了。
那么我们需要怎么办呢?记 \(fa_{x}\) 表示 \(x\) 的父节点,则对每个点分别开两棵线段树,\(T_{1u}\) 存储 \(u\) 子树内与 \(u\) 相距为 \(w \in [0, n]\) 的点权和,\(T_{2u}\) 存储 \(u\) 子树内与 \(fa_{u}\) 相距为 \(w \in [0, n]\) 的点权和,然后查询和修改都直接暴力向上跳,由点分树的另一个性质可知,由于树高是 \(O(\log{n})\) 的,最多只会跳 \(O(\log{n})\) 次,因此算上线段树的一只老哥,总时间复杂度为 \(O(n\log^{2}{n})\)。
由于点分树上所有点的子树深度和是 \(O(n\log{n})\) 的,因此动态开点的空间复杂度是 \(O(n\log{n})\) 的。当然也可以对每个点开一个树状数组直接做。
贴一个板子吧。
void PDC(int u)
{
vis[u] = 1;
for(auto v : OG[u])
{
if(vis[v])
continue;
get_root(v, u);
nowsz = sz[v];
maxsz = N;
get_root(v, u);
add(u, root);
fath[root] = u;
PDC(root);
}
}
vector<int> vec[N];
void preprocess()
{
PDC(1);
for(int u = 1; u <= n; ++u)
{
int cur = u;
while(cur)
{
vec[u].EB(get_dist(u, cur));
cur = fath[cur];
}
}
}
void modify(int u, int v)
{
int cur = u, id = 0;
while(cur)
{
T1.modify(T1.rt[cur], 0, n, vec[u][id++], v);
if(fath[cur]) T2.modify(T2.rt[cur], 0, n, vec[u][id], v);
cur = fath[cur];
}
}
int query(int u, int K)
{
int res = 0;
int cur = u, pre = 0, id = 0;
while(cur)
{
int d = vec[u][id++];
if(pre) res -= T2.query(T2.rt[pre], 0, n, 0, K - d);
res += T1.query(T1.rt[cur], 0, n, 0, K - d);
pre = cur, cur = fath[cur];
}
return res;
}
P2056 [ZJOI2007] 捉迷藏
Problem
Solution
P3241 [HNOI2015] 开店
Problem
给定一棵点带点权的三度化树。
多组询问 \(u, L, R\),强制在线查询树上点 \(u\) 到所有点权 \(\in [L, R]\) 的点的距离和。
Solution
先上一棵点分树。
如果对一个点 \(u\) 查询所有点到它的距离怎么做?
记 \(f_{u}\) 表示点分树上 \(u\) 子树内所有点到 \(u\) 的距离和,\(g_{u}\) 表示点分树上 \(u\) 子树内所有点到 \(fa_{u}\) 的距离和。
套路地枚举最近公共祖先,即不断向上跳,则对于一个 \(lca\),其贡献为 \(f_{lca} - g_{s} + dis(u, lca)\times (sz_{lca} - sz_{s})\),其中 \(s\) 是 \(lca\) 沿 \(u\) 方向上的子节点。
如果对一个点 \(u\) 查询权值在 \([L, R]\) 内的点怎么做?
发现贡献具有可减性,即权值和可以拆成 \([1, R]\) 内的点对 \(u\) 的贡献减去 \([1, L - 1]\) 内的点对 \(u\) 的贡献。
好了!你发现对于任意一个节点而言,本质不同的前缀信息(包括 \(f, g, sz\))都只有子树大小个,由点分树的性质可知,存下这些信息只需 \(O(n\log{n})\) 的空间。
于是暴力预处理每个子树的前缀信息,查询时二分出需要的信息计算权值即可。
时间复杂度 \(O((n + Q)\log^{2}{n})\)。
P3345 [ZJOI2015] 幻想乡战略游戏
Problem
Solution
为什么又是这个叫幽香的啊:|
P5311 [Ynoi2011] 成都七中
Problem
给你一棵 \(n\) 个节点的树,每个节点有一种颜色,有 \(m\) 次独立的查询操作。
查询操作给定参数 \(l\ r\ x\),需输出:将树中编号在 \([l,r]\) 内的所有节点保留,\(x\) 所在连通块中颜色种类数。
Solution
返璞归真,最暴力的想法是什么?从 \(x\) 向外 dfs,只要 \(x \to y\) 路径上节点编号均在 \([l, r]\) 内,就能到达 \(y\)。
事实上,只要与 \(x\) 在同一连通块内,不管从哪个点出发进行遍历结果都是一样的,我们 钦定从与 \(x\) 在同一连通块内深度最浅的节点 \(u\) 开始遍历,这样连通块一定在 \(u\) 的子树内。
在点分树上,上述结论是否成立呢?不妨使用反证法,记连通块在点分树上深度最浅的节点为 \(u\),假设点 \(y\) 不在 \(u\) 的子树中,则 \(y\) 必须跨过 \(u\) 的父亲与连通块内的节点相连,这就表明 \(u\) 的父亲也在连通块内,与 \(u\) 作为最浅节点的条件矛盾,因此上述结论成立。
如何对每个询问找到连通块最浅节点:对每个点作为分治中心遍历原树结构,并维护路径上节点权值的上下界,这个上下界是可以存下来的(\(O(n\log{n})\)),之后有用。如果一个询问满足上下界限制,用当前分治中心更新该询问的最浅节点。
现在我们把询问挂在了连通块的最浅节点,因此只需考虑分治子树即可。
问题简化为:有若干个三元组 \((x, y, c)(x \le y)\),对于每个询问 \((l, r)(l \le r)\),求 \(l \le x \le y \le r\) 的三元组的颜色数量。
将二元组和询问均按下界从大到小排序,对于一个询问 \((l, r)\),将 \(x \ge l\) 的三元组 \((x, y, c)\) 用 \(y\) 更新颜色 \(c\) 对应的最小上界,并用树状数组维护一个上界对应多少颜色,询问 \((l, r)\) 的答案即为树状数组上 \(\le r\) 的权值和。总时间复杂度 \(O(n\log^{2}{n})\)。
你发现点分树好像很鸡肋。确实没必要写点分树,一次点分治就搞定了。
居然跑得飞快?这可不像 Ynoi 啊。
边分治入门
点分治是每次找到一个 “重心”,使得分开的所有子树大小的最大值最小。
边分治类似地找到一个中心边,使得两侧的子树大小最大值最小。
边分治有什么好处呢?每次分治的时候,子问题只会被切成 两半,这会带来一些好的性质。
但对于一个没有特殊性质的树,做边分治的最坏时间复杂度可以达到 \(O(n^2)\)。
所以需要引入一个重要的优化——三度化。
三度化
搬了 [学习笔记]边分治 - Miracle 的图。
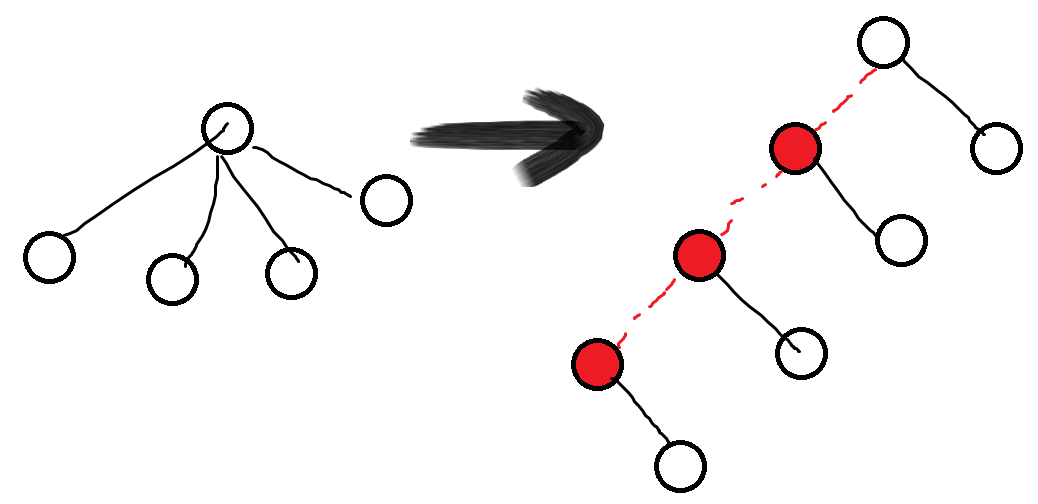
法一
把所有儿子依次加一个点串起来。
虚点和虚边按照具体情况赋上相应的权值。
struct Lexington
{
int e, ne, w1, w2;
};
struct Sakawa
{
int h[N << 1], idx = 1;
Lexington lxt[N << 2];
void clear()
{
memset(h, 0, sizeof(h));
}
void add(int a, int b, int c1, int c2)
{
lxt[++idx] = (Lexington){b, h[a], c1, c2};
h[a] = idx;
}
void adds(int a, int b, int c1, int c2)
{
add(a, b, c1, c2);
add(b, a, c1, c2);
}
}skw;
struct Shiroha
{
// ...
int tot;
Sakawa G;
void rebuild(int u, int fa)
{
int tmp = 0;
for(int i = skw.h[u]; i; i = skw.lxt[i].ne)
{
int v = skw.lxt[i].e;
if(v == fa) continue;
if(!tmp)
{
G.adds(u, v, skw.lxt[i].w1, 1);
tmp = u;
}
else
{
int vir = ++tot;
G.adds(tmp, vir, 0, 0);
G.adds(v, vir, skw.lxt[i].w1, 1);
tmp = vir;
}
rebuild(v, u);
}
}
// ...
}umi;
法二

不太喜欢这种写法,摆了。
由于三度化和虚边虚点处理,边分治一般要比点分治难写。
边分治
我们要清楚,三度化的作用是使得重构树上存在一条边使得能够相对均匀地将树分治成两个部分。
事实上,恰好有如下结论:
如果一棵树中每个点的度数都不超过 \(d\),则一定存在一条一定存在一条边分出两个子树大小均属于 \([\frac{n}{d + 1}, \frac{nd}{d + 1}]\)。
证明可见 这篇博客。所以同点分治类似地分析,边分治的时间复杂度也是 \(O(n\log{n})\) 的。
具体来说是以 \(\frac{3}{2}\) 为底,对于 \(n = 10^5\) 的数据范围,这个值约为 \(31\),开数组时开 \(33\) 差不多就够了。
贴一个边分治的 get_cent 和 EDC(Edge Divide and Conquer?) 过程的代码。
注:写法仅供参考。后文边分树一节中会给出可能更好的实现。
struct Shiroha
{
int tot;
int cent;
int nowsz;
int sz[N << 1];
int maxsz;
int vis[N << 1];
Sakawa G;
void rebuild(int u, int fa)
{
// ...
}
void get_cent(int u, int fa)
{
sz[u] = 1;
for(int i = G.h[u]; i; i = G.lxt[i].ne)
{
int v = G.lxt[i].e;
if(v == fa || vis[i])
continue;
get_cent(v, u);
sz[u] += sz[v];
int val = max(sz[v], nowsz - sz[v]);
if(val < maxsz) maxsz = val, cent = i;
}
}
void calc(int u1, int u2, Lexington lxt)
{
// ...
}
void EDC(int e)
{
int u1 = G.lxt[e].e, u2 = G.lxt[e ^ 1].e;
vis[e] = vis[e ^ 1] = 1;
calc(u1, u2, G.lxt[e]);
if(sz[u1] > 1)
{
nowsz = sz[u1];
maxsz = nowsz;
get_cent(u1, u2);
EDC(cent);
}
if(sz[u2] > 1)
{
nowsz = sz[u2];
maxsz = nowsz;
get_cent(u2, u1);
EDC(cent);
}
}
}umi;
-
注意边分治不会考虑到以一个点作为一条路径的情况。
-
注意三度化后点数变为了原来的两倍!
P4149 [IOI2011] Race
Problem
给一棵树,每条边有权。求一条简单路径,权值和等于\(k\),且边的数量最小。
Solution
command_block:“建议先使用边分治写点分治的题来熟练。”
JZP:“其实随便挑个点分治题几乎都能作为边分治的例题。”
我写出来的边分治比点分治快了整整 1s,效率还是不错的。
主要贴一下关于 calc 部分的实现:
struct Shiroha
{
int tot;
int cent;
int nowsz;
int sz[N << 1];
int maxsz;
int vis[N << 1];
int f[M];
int d1[N << 1], d2[N << 1], dcnt;
int g[N << 1], gcnt;
Sakawa G;
void rebuild(int u, int fa)
{
// ...
}
void get_cent(int u, int fa)
{
// ...
}
void get_dist(int u, int fa, int w1, int w2)
{
if(w1 > K) return;
if(u <= n) // !!!
{
++dcnt;
d1[dcnt] = w1, d2[dcnt] = w2;
}
for(int i = G.h[u]; i; i = G.lxt[i].ne)
{
int v = G.lxt[i].e;
if(v == fa || vis[i])
continue;
get_dist(v, u, w1 + G.lxt[i].w1, w2 + G.lxt[i].w2);
}
}
void calc(int u1, int u2, Lexington lxt)
{
gcnt = dcnt = 0;
get_dist(u1, u2, 0, 0);
for(int i = 1; i <= dcnt; ++i)
{
chkmn(f[d1[i]], d2[i]);
g[++gcnt] = d1[i];
}
dcnt = 0;
get_dist(u2, u1, lxt.w1, lxt.w2);
for(int i = 1; i <= dcnt; ++i)
chkmn(ans, f[K - d1[i]] + d2[i]);
for(int i = 1; i <= gcnt; ++i)
f[g[i]] = N;
}
void EDC(int e)
{
// ...
}
void work()
{
tot = n;
G.clear();
rebuild(1, 0);
// G = skw;
nowsz = tot;
maxsz = nowsz;
get_cent(1, 0);
for(int i = 0; i < M; ++i)
f[i] = N;
EDC(cent);
}
}umi;
边分治与合并凸包
省流:边分治的二叉结构保证了合并凸包时间复杂度的正确性。
听说用点分治每次选最小的两棵子树合并复杂度也是对的,但效率远不如边分治,且不如边分治一次合并就解决来得方便。
因此边分治在这件事情上做得更好。
树分治与虚树
这个小节出现的位置有点尴尬,主要是因为暴力写挂和通道这两个大火题不太好用点分治做,只能接在边分治之后。
算是点分治与边分治的一个综合提升吧。
P4565 [CTSC2018] 暴力写挂
Problem
给定两棵大小均为 \(n\) 的边带边权的树。 定义两点 \(x, y\) 间的距离 \(D(x, y)\) 为:
求 \(\max\limits_{1 \le x \le y \le n}D(x, y)\)。
Solution
点分治也能做,但听说会被对着卡。
为了方便边分治时可以把贡献拆到两个点上,首先把式子中的深度化成距离:
对第一棵树进行边分治,并记当前分治中心边为 \(cent\)。
记 \(d_{x}, d_{y}\) 分别表示 \(x, y\) 到 \(cent\) 的距离(方便实现,可以把中心边的权值任意赋给其中一方),此时 \(dis(x, y) = d_{x} + d_{y}\)。
以 \(\mathrm{depth}(x) + d_{x}\) 作为第二棵树中 \(x\) 的点权 \(w_{x}\),用第一棵树当前分治块内的所有点在第二棵树上建立虚树,并考虑在第二棵树的虚树上更新答案。
具体考虑如何更新答案:对所有在第一棵树的分治块内不属于同一棵子树的点对 \((x, y)\),\(ans \xleftarrow{\max} w_{x} + w_{y} - 2{\mathrm{depth'}(\mathrm{LCA'}(x,y))})\)。
这个可以看成将 \(cent\) 两侧的点分别染成黑色和白色,然后直接在虚树上做个树形 DP 即可。
注意三度化产生的虚拟节点和虚树上的非关键点不能影响到答案更新。
时间复杂度为 \(O(n\log^{2}{n})\),如果 \(O(n)\) 建虚树可以做到 \(O(n\log{n})\)。
P4220 [WC2018] 通道
Problem
给定三棵大小均为 \(n\) 的树,求一个点对 \((x, y)\) 以最大化 \(x, y\) 在三棵树上的距离之和。
Solution
思路大致与 P4565 [CTSC2018] 暴力写挂 相同,所以就写简洁点了。
对 \(T1\) 进行边分治,并记当前分治中心边为 \(cent\)。记 \(w_{x}, w_{y}\) 分别表示 \(x, y\) 到 \(cent\) 的距离,此时 \(dis1(x, y) = w_{x} + w_{y}\)。将 \(cent\) 两侧的点分别染成黑白两色。
对 \(T2\) 建立虚树。枚举虚树上的 LCA(即下式中的 \(lca2(x, y)\)),求子树内异色点对 \((x, y)\) 的下式最大值:
发现最棘手的就是这个 \(dis3(x, y)\)。
然后疯狂给 \(T3\) 叠 buff,将 \(w_{x} + d2_{x}\) 视作在 \(T3\) 上的 \(x\) 点上接一个虚点 \(x^{'}\)(不用真的实现),然后询问第三棵树上异色关键点的距离最大值。
由于边权非负,因此有一个经典结论是:取得距离最大值的异色关键点一定在白点直径端点和黑点直径端点之中。
所以维护 \(f_{u, 0 / 1}\) 表示考虑 \(T2\) 中 \(u\) 子树内,在 \(T3\) 上的黑/白直径端点,在 \(T2\) 上 DP 时暴力枚举所有组合方式进行转移并更新答案即可。
时间复杂度 \(O(n\log^{2}{n})\)。同样可以稍加优化成 \(O(n\log{n})\)。
P6668 [清华集训2016] 连通子树
Problem
给定一棵点带颜色的树,最多会有 \(5\) 个点有相同的颜色。
\(Q\) 次询问,每次会关心三种不同的颜色 \(a,b,c\),求树上有多少个不同的非空联通子图满足里面颜色为 \(a,b,c\) 的点的个数分别为 \(na,nb,nc\)。取模。
保证 \((na + 1)(nb + 1)(nc + 1)\) 的和不超过 \(8 \times 10^6\)。
Solution
边分树入门
边分树是什么样的结构呢?
类比点分治将每次的分治重心进行连边,边分治是将分治中心边视作虚点,然后将当层分治中心边连向下一层分治的中心边。
当递归到底时,当前分治块内没有边,只有一个点,把这个点与上一层的中心边相连。
把所有点作为边分树的叶子节点,所有边作为非叶子节点,形成了一棵二叉树。
叶子节点寄存着最原始的信息,而非叶子节点寄存着分治块内的信息并。
以下是一个构建的例子。

边分树具有如下性质:
- 两个不同的叶子节点对应的两个原树节点 \(u, v\) 必过 \(LCA(u, v)\) 对应的分治中心边。
- 边分树的结构基本等同于线段树。这意味着边分树也能支持某些线段树能做的事情。
P3241 [HNOI2015] 开店
Problem
给定一棵点带点权的三度化树。
多组询问 \(u, L, R\),强制在线查询树上点 \(u\) 到所有点权 \(\in [L, R]\) 的点的距离和。
Solution
如果是点分治,你需要考虑去除在同一子树内的路径贡献;但在边分治中,你只需要查询对面子树的信息,则不需要考虑这个麻烦的问题。这已经体现出了边分治在解题思路上的优越性。
由于写得太难看了,所以这里就不放代码段了。之后会给出更好的实现。
同样是两只老哥,我的边分树效率居然是点分树的两倍多!
可持久化边分树
前文提到,边分树的结构非常类似线段树。于是可持久化边分树这个科技诞生了。
P3241 [HNOI2015] 开店
Problem
给定一棵点带点权的三度化树。
多组询问 \(u, L, R\),强制在线查询树上点 \(u\) 到所有点权 \(\in [L, R]\) 的点的距离和。
Solution
梅开 “三度”!此题还可以做得更优。
考虑先建一棵空的边分树,然后按点权从小到大加入信息,每加入一个点就新建一个版本的边分树。
这个过程只会影响到某个叶子节点往上的一条链,因此一次新建的节点数是 \(O(\log{n})\) 的。
查询时在外层二分出边分树的版本,在边分树上只需要 \(O(\log{n})\) 地跳即可。
因此时空复杂度均为 \(O((n + Q)\log{n})\)。
由于之前写的边分树实在是太难看了,所以换用了 tyl 的写法改了一下。
具体地,为了更加逼近线段树的风格,对每个叶节点记录从根节点跳到它的过程中每一层走的方向,这样就可以像线段树那样自根向叶进行修改和查询。
修改了建树过程(EDC),使得代码更具对称性的美感。
这种写法树上的所有节点都表示中心边。
由于该题为下一题的严格弱化版,我们在下一个典题放出代码段。
code P3241 我交的时候是洛谷上最优解。
CF757G Can Bash Save the Day?
Problem
一棵 \(n\) 个点的树和一个排列 \(p_i\),边有边权,支持两种操作:
l r x,询问 \(\sum\limits _{i=l}^{r} dis(p_i,x)\)。x,交换 \(p_x,p_{x+1}\)。
\(n,q\leq 2\times 10^5\),强制在线。
Solution
把 \(p_i\) 视作表示点权为 \(i\) 对应的节点编号,发现这个题相当于开店的基础上支持修改的完全加强版。
考虑第 \(i\) 个版本的边分树维护插入了点权为 \(1 \sim i\) 的节点后的信息。
发现交换操作只会影响到第 \(x\) 个版本的边分树,操作后第 \(x\) 个版本的边分树变为第 \(x - 1\) 个版本的边分树插入点权为 \(x + 1\) 的节点。
所以其实思路就这样非常简单。
下面给出一个非常优雅的实现。
// Sea, You & Me
// ...
const int MOD = 1 << 30;
const int N = 2e5 + 5;
const int F = 33;
const int INF = 1e9 + 7;
int n, Q, p[N];
LL lastans;
struct Lexington
{
int to, ne, w;
};
struct Sakawa
{
int h[N << 1], idx = 1;
Lexington lxt[N << 2];
void clear()
{
idx = 1;
memset(h, 0, sizeof(h));
}
void add(int x, int y, int z)
{
lxt[++idx] = (Lexington){y, h[x], z};
h[x] = idx;
}
void adds(int x, int y, int z)
{
add(x, y, z), add(y, x, z);
}
}skw;
int rt[N];
struct Shiroha
{
int tot;
int cent;
int nowsz;
int maxsz;
int sz[N << 1];
int vis[N << 1];
int umi = 0;
LL dis[N << 1][F];
int dir[N << 1][F];
Sakawa T;
struct Nanami
{
int son[2];
int cnt[2];
LL sum[2];
}tr[N * F * 2];
void clear()
{
for(int p = 1; p <= umi; ++p)
for(int i = 0; i < 2; ++i)
tr[p].cnt[i] = tr[p].sum[i] = tr[p].son[i] = 0;
for(int i = 1; i <= tot; ++i)
vis[i] = 0;
tot = umi = 0;
}
void rebuild(int u, int fa)
{
// ...
}
void get_cent(int u, int fa)
{
for(int i = T.h[u]; i; i = T.lxt[i].ne)
{
int v = T.lxt[i].to;
if(v == fa || vis[i / 2])
continue;
get_cent(v, u);
int val = max(sz[v], nowsz - sz[v]);
if(val < maxsz)
{
maxsz = val;
cent = i;
}
}
}
void dfs(int u, int fa, int dep, LL w, int op)
{
sz[u] = 1;
if(u <= n)
{
dis[u][dep] = w;
dir[u][dep] = op;
}
for(int i = T.h[u]; i; i = T.lxt[i].ne)
{
int v = T.lxt[i].to;
if(v == fa || vis[i / 2])
continue;
dfs(v, u, dep, w + T.lxt[i].w, op);
sz[u] += sz[v];
}
}
void EDC(int &p, int u, int dep)
{
if(sz[u] == 1) return;
p = ++umi;
nowsz = sz[u], maxsz = INF;
get_cent(u, 0), vis[cent / 2] = 1;
int x = T.lxt[cent].to;
int y = T.lxt[cent ^ 1].to;
dfs(x, 0, dep, 0, 0);
dfs(y, 0, dep, T.lxt[cent].w, 1);
EDC(tr[p].son[0], x, dep + 1);
EDC(tr[p].son[1], y, dep + 1);
}
void modify(int &p, int q, int x, int dep)
{
if(!q) return;
p = ++umi;
tr[p] = tr[q];
int op = dir[x][dep];
tr[p].cnt[op] += 1;
tr[p].sum[op] += dis[x][dep];
modify(tr[p].son[op], tr[q].son[op], x, dep + 1);
}
LL query(int p, int x, int dep)
{
if(!p) return 0;
int op = dir[x][dep];
LL res = tr[p].sum[op ^ 1] + 1LL * dis[x][dep] * tr[p].cnt[op ^ 1];
return res + query(tr[p].son[op], x, dep + 1);
}
void preprocess()
{
clear();
T.clear();
tot = n;
rebuild(1, 0);
// T = skw;
umi = 0;
dfs(1, 0, 0, 0, 0);
EDC(rt[0], 1, 0);
for(int i = 1; i <= n; ++i)
modify(rt[i], rt[i - 1], p[i], 0);
}
}Hairi;
int main()
{
read(n), read(Q);
for(int i = 1; i <= n; ++i)
read(p[i]);
skw.clear();
for(int i = 1; i < n; ++i)
{
int x, y, z;
read(x), read(y), read(z);
skw.adds(x, y, z);
}
Hairi.preprocess();
for(int cas = 1; cas <= Q; ++cas)
{
int op; read(op);
if(op == 1)
{
int l, r, x;
read(l), read(r), read(x);
l ^= lastans, r ^= lastans, x ^= lastans;
lastans = Hairi.query(rt[r], x, 0) - Hairi.query(rt[l - 1], x, 0);
printf("%lld\n", lastans); lastans %= MOD;
}
else
{
int x; read(x); x ^= lastans;
Hairi.modify(rt[x], rt[x - 1], p[x + 1], 0);
swap(p[x], p[x + 1]);
}
}
return 0;
}
边分树合并
前文提到,边分树的结构非常类似线段树。于是边分树合并这个科技诞生了。
P4565 [CTSC2018] 暴力写挂
Problem
给定两棵大小均为 \(n\) 的边带边权的树。 定义两点 \(x, y\) 间的距离 \(D(x, y)\) 为:
求 \(\max\limits_{1 \le x \le y \le n}D(x, y)\)。
Solution
CTSC2018 Baoli Xiegua - Mickey-snow's Blog
