

mysql 锁,和加锁机制
背景
间隙锁是MySQL在RR可重复读隔离级别下用来修复幻读才引入的一种锁,间隙锁也只有在RR可重复读隔离级别下才会存在,如果是在RC读已提交隔离级别下,是没有间隙锁的存在的。另外,我们也知道,幻读这种现象也只有在当前读的时候才会发生,在一致性快照读的情况下是没有幻读现象的。
那么间隙锁到底是怎么样工作的?它是如何保证在当前读的时候,不会出现幻读现象的呢?接下来让我们一起剖解分享一下间隙的加锁的机制是怎么样的。
实验环境的准备
前置条件
接下来的实验是在如下的环境下开始的:
MySQL的版本:5.7.24
事务的隔离级别:RR可重复读
测试使用存储引擎为innodb存储引擎
准备建表语句
下面的实验使用的userinfo表结果如下表格所示:其中用户的年龄age字段是可能存在多个用户的年龄相同的情况,所以这个age列上有非唯一索引;而所有用户的手机号码不会重复,所以这个phone列上面有一个唯一索引;姓名name列和备注remark列上面没有任何索引就是两个普通的字段。
序号 字段名称 字段类型 字段注释 索引类型
| 序号 | 字段名称 | 字段类型 | 字段注释 | 索引类型 |
|---|---|---|---|---|
| 1 | id | int | 表的主键 | 聚簇索引 |
| 2 | name | varchar | 姓名 | N/A |
| 3 | age | int | 年龄 | 非唯一索引 |
| 4 | phone | varchar | 手机号 | 唯一索引 |
| 5 | remark | varchar | 备注信息 | N/A |
建表语句如下:
CREATE TABLE `userinfo` ( `id` int(11) NOT NULL COMMENT '主键', `name` varchar(255) DEFAULT NULL COMMENT '姓名', `age` int(11) DEFAULT NULL COMMENT '年龄,普通索引列', `phone` varchar(255) DEFAULT NULL COMMENT '手机,唯一索引列', `remark` varchar(255) DEFAULT NULL COMMENT '备注', PRIMARY KEY (`id`), UNIQUE KEY `idx_userinfo_phone` (`phone`) USING BTREE COMMENT '手机号码,唯一索引', KEY `idx_user_info_age` (`age`) USING BTREE COMMENT '年龄,普通索引' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
准备初始化数据
下面实验中使用到的测试数据如下:
T INTO `userinfo`(`id`, `name`, `age`, `phone`, `remark`) VALUES (0, 'mayun', 20, '0000', '马云'); INSERT INTO `userinfo`(`id`, `name`, `age`, `phone`, `remark`) VALUES (5, 'liuqiangdong', 23, '5555', '刘强东'); INSERT INTO `userinfo`(`id`, `name`, `age`, `phone`, `remark`) VALUES (10, 'mahuateng', 18, '1010', '马化腾'); INSERT INTO `userinfo`(`id`, `name`, `age`, `phone`, `remark`) VALUES (15, 'liyanhong', 27, '1515', '李彦宏'); INSERT INTO `userinfo`(`id`, `name`, `age`, `phone`, `remark`) VALUES (20, 'wangxing', 23, '2020', '王兴'); INSERT INTO `userinfo`(`id`, `name`, `age`, `phone`, `remark`) VALUES (25, 'zhangyiming', 38, '2525', '张一鸣');
最后的测试环境
准备好表和初始化数据之后,我们的测试环境就准备好了,最后的测试环境如下:

间隙锁的结构
针对上面我们准备表结构和插入的测试数据,目前userinfo表中有三个间隙锁,分别在主键id列上,非唯一索引age列,唯一索引phone列。它们的间隙锁的分布情况分别如下。根据各个索引列上面的值,把索引切分为不同的区间段。
主键索引id列上的间隙锁结构如下图所示:

非唯一索引age列上的间隙锁结构如下所示:因为是非因为索引,所以索引中的值可以重复出现,所以在图中没有标记每一个间隙可能出现的值,用三个点代替显示。
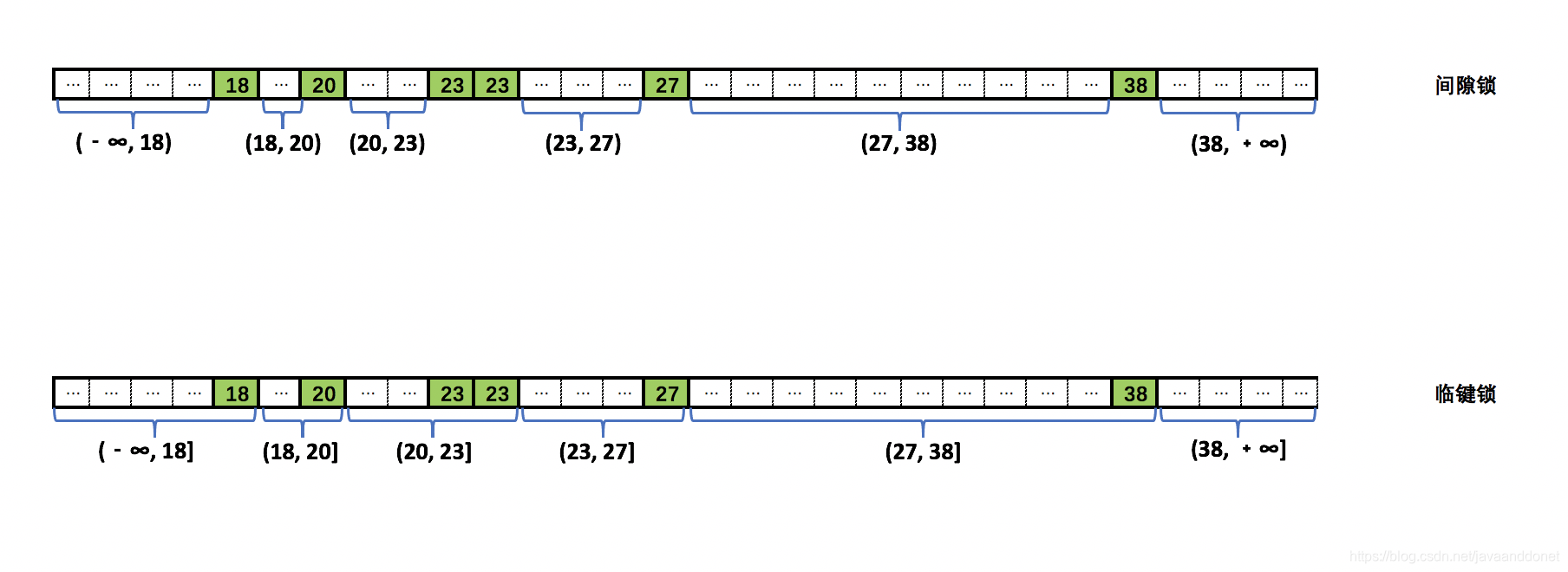
唯一索引phone列上的间隙锁如下所示:
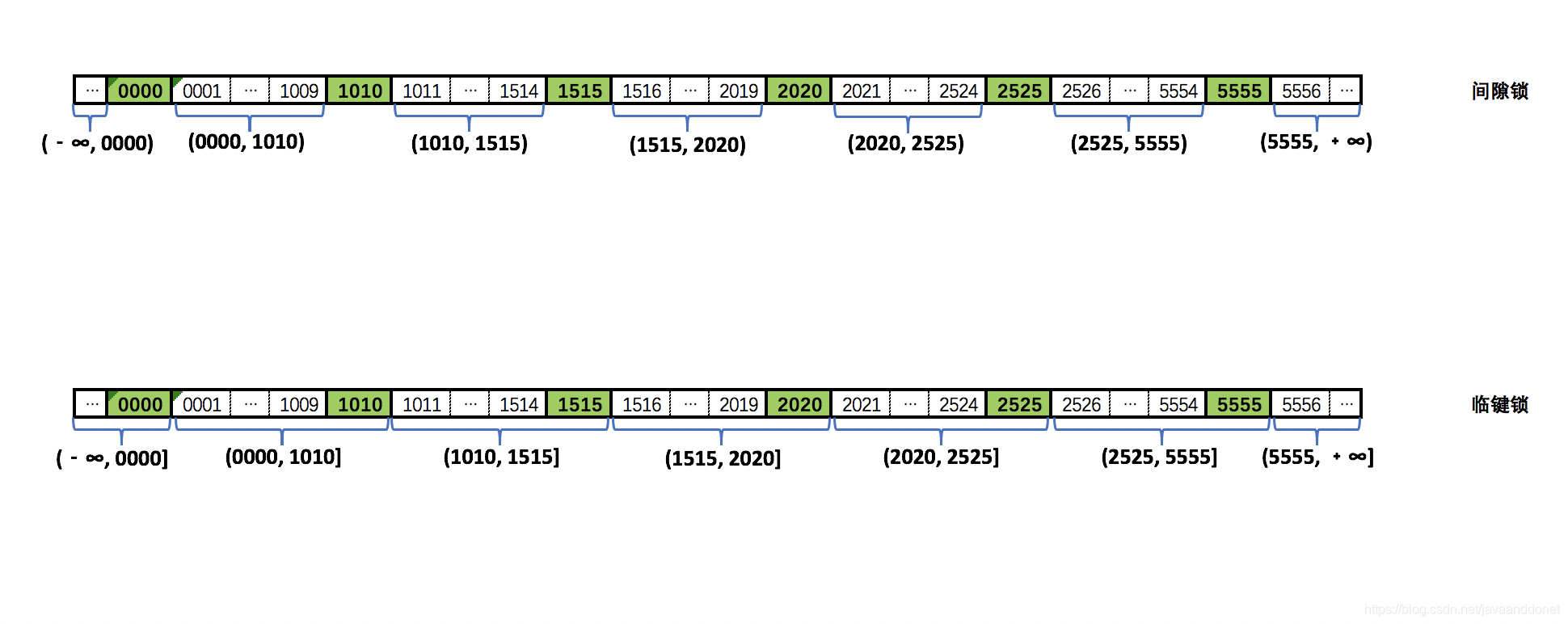
根据主键查询,给行增加X锁
我们要知道,MySQL中的行锁和间隙锁是锁定就是对应的索引。行锁锁定的行所在的主键索引,非主键索引列上面的锁也是锁定对应的非主键索引。间隙锁也是锁定索引,他们不是锁定行,也不是锁定某个列,是锁定对应的索引。
索引的结构
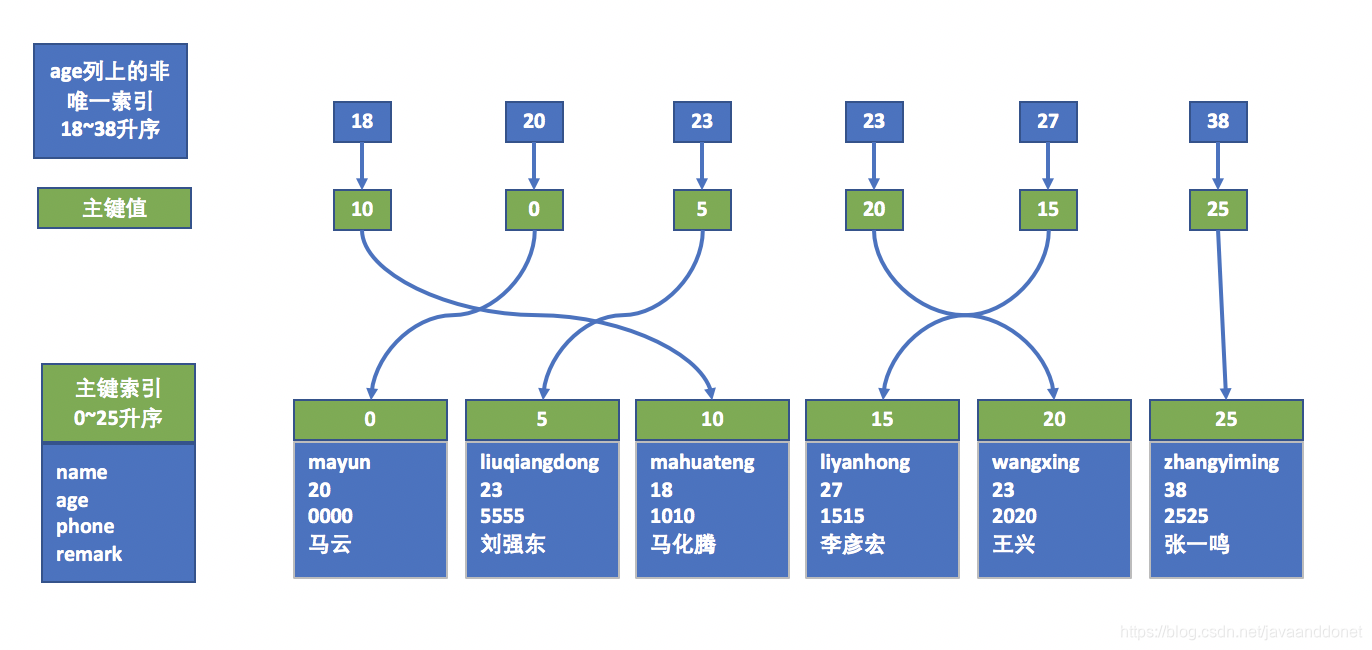
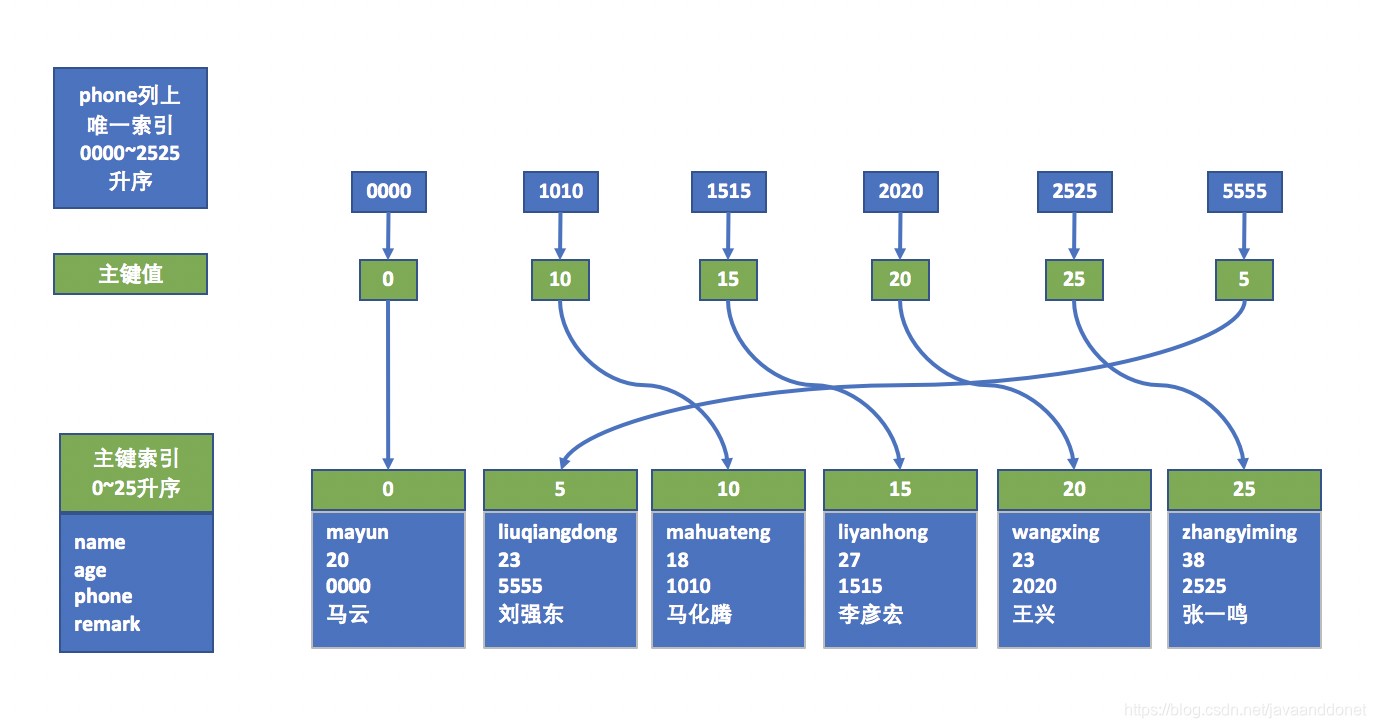
上面的表插入数据之后,在id主键索引上会有一个B+Tree的索引结构。在age非唯一索引和phone唯一索引两列上,会有两个B+Tree索引结构。他们的结构如下图所示:
id主键索引结构

age非唯一索引结
phone唯一索引
间隙锁加锁规则
这里先简单总结一下间隙锁加锁的一些规则,然后我们根据规则去逐步验证这些规则。
- 查询过程中访问到的对象才会加锁。
- 加锁的基本单位是next-key lock(前开后闭)。
- 等值查询上MySQL的优化:索引上的等值查询,如果是唯一索引,next-key lock会退化为行锁,如果不是唯一索引,需要访问到第一个不满足条件的值,此时next-key lock会退化为间隙锁。
- 范围查询:无论是否是唯一索引,范围查询都需要访问到不满足条件的第一个值为止。
实验部分
我们针对以下几个SQL语句来分析一下具体间隙锁的加锁的范围是什么。这几个SQL分别使用不同的列来作为where条件来筛选表中第2条数据。
根据where条件中各个列的类型,我们可以分为如下4类SQL。下面的四个语句都会自动给表增加上对应的行锁之外,如果有必要增加对应的间隙锁,也会增加上间隙锁来避免幻读的发生,而如果不需要间隙锁就可以避免幻读的发生,那么MySQL就不会自动增加上对应的间隙锁只要对应的行锁就可以了。
/*根据主键查询,给行增加X锁*/ select * from userinfo where id = 5 for update; /*根据唯一索引列查询,给行增加X锁*/ select * from userinfo where phone = '5555' for update; /*根据非唯一索引列查询,给行增加X锁*/ select * from userinfo where age = 23; /*根据普通列查询,给行增加X锁*/ select * from userinfo where name = 'liuqiangdong';
实验的过程中,还需要密切观察下面三个表中的内容,这里记录的MySQL在执行期间正在允许的事务、锁、锁等待等信息。从这里三张表中,可以看到每一个阻塞是因为什么阻塞的,被哪些锁阻塞的。
/*查看正在运行的事务*/ select * from information_schema.innodb_trx; /*查看当前的锁信息*/ select * from information_schema.innodb_locks; /*查看锁等待的信息*/ select * from information_schema.innodb_lock_waits;
RR级别+主键索引列
在可重复读隔离级别下,通过主键索引去查询数据尝试增加X锁的时候,使用如下的SQL语句
/*根据主键查询,给行增加X锁*/ select * from userinfo where id = 5 for update;
此时会在主键索引上索引值为5的记录上增加X锁,此时不需要使用其他间隙锁就可以避免幻读的发生。因为主键索引是唯一索引,当锁住这一行数据后,其他事务将不能做如下操作:
- 不能删除id=5的这一行数据。id=5的行已经被当前事务给增加了X锁,所以其他事务将不能查询、修改、删除这一行数据。
- 不能新插入一个id=5的行。表中已经存在主键id=5的行了,所以其他事务不能再次增加一个id=5的行。所以就可以避免在id=5这个条件下再次查询的时候出现多行数据而产生幻读的现象。
- 不能修改id=5的这一行数据。id=5的行已经被当前事务给增加了X锁,所以其他事务将不能查询、修改、删除这一行数据。
- 不能把其他行的id值改为5。这一行是主键索引,也是唯一所以,它的值不能重复。所以其他事务不能把一个id!=5的行改为id=5的行。所以就可以避免在id=5这个条件下再次查询的时候出现多行数据而出现幻读的现象。
此时增加的锁也只有主键索引id=5这一个行锁,锁结构如下:

综上几点可以确定,当使用主键索引进行查询数据增加X锁的时候,是可以避免幻读的发生,此时不需要间隙锁的参与就可以避免幻读。其他事务可以正常的对userinfo表进行除id=5之外增删改查操作。比如插入一个id=6的数据行,删除id=0的数据行,修改id=20的行等操作。
实验截图:
通过如下的实验,可以看出,在左侧的事务给表userinfo增加了id=5的行锁之后,右侧的事务仍然可以对表中其他数据行和间隙进行增删改查。说明左侧的事务只增加了id=5的行锁,没有间隙锁的存在。

下面我们再来看一个因为索引失效而走全表扫描的例子,与此同时下面的这个例子也能从一定程度上说明左侧的事务只对id=5这一行增加了一个X锁,没有其他间隙锁或行锁的存在。
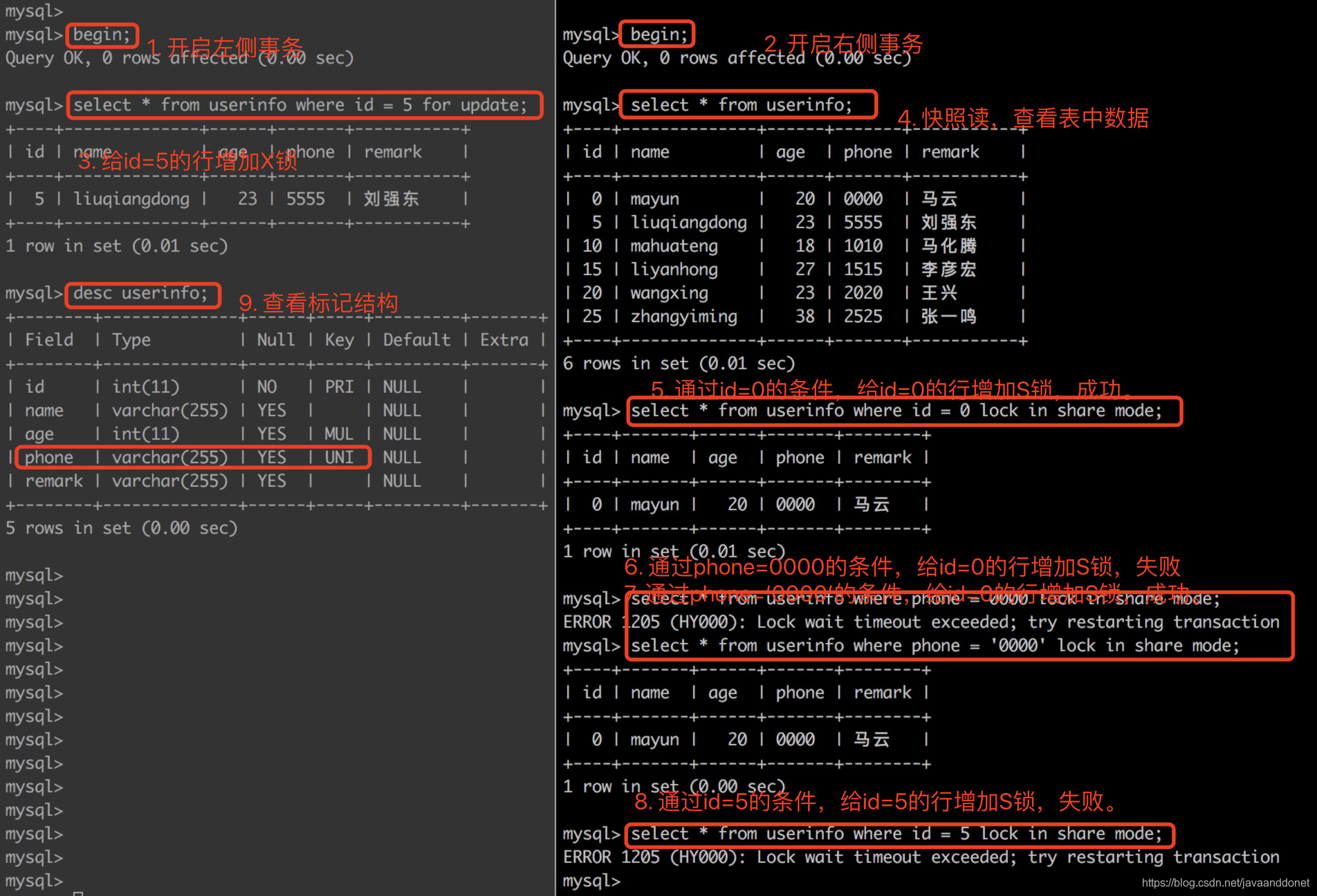
上面截图中的第5,6,7,8在尝试加S锁的时候,这里解释一下为什么成功,为什么失败。
- 第5步中,是通过id=0这个条件去给id=0的这一行数据增加S共享锁,where条件中的id是主键列,也是一个唯一索引列,所以在查询的时候,可以直接通过主键索引定位到对应的行。所以直接找到了id=0的这一行,同时发现这一行上面没有其他X所存在,所以增加S锁成功。
- 第6步中,是通过phone=0000这个条件去给id=0的行增加S锁,这里之所以失败的原因如下:
- phone是一个varchar类型的唯一索引,在给它赋值的时候,如果我们赋值不是varchar类型的数据,MySQL为了避免SQL直接出现错误,会尝试进行隐式转换,把数据库中的phone列使用函数转换为和你赋值的类型一致的数据再进行等值判断。
- 对索引列使用函数操作,会导致查询的时候不走索引,索引对当前查询SQL语句失效了,此时的phone的索引就不会被使用,所以此时在查询数据的时候就是走全表扫描。
- 在全表扫描的时候,扫描到第一个phone=0000的行并不会停止,因为此时phone列的唯一索引没有使用,所以要继续扫描,判断表中每一行的phone列的值是否为0000。根据前面说的加锁规则,在尝试加锁的时候,会对所有扫描过的对象增加对应的锁。所以在扫描到id=5的行的时候,尝试给这一行增加S锁。
- 然而,id=5的这一行的索引记录,已经被左侧的事务给增加了一个X锁,因为S锁和X锁不能共存,所以此时给id=5的索引记录加S锁失败。
- 所以步骤6就被阻塞住了,等超过事务默认的最大等待阈值就会退出。
- 第7步中,执行成功了的原因正式因为我们在给phone列赋值的时候,使用了正确的varchar类型的'0000',所以在查询表中数据的时候,可以使用到唯一索引,直接定位到对应的主键索引上面的值,从而可以对id=0的索引记录加锁成功。不需要走全表扫描就可以找到对应的行。
- 第8步中,被阻塞的原因是因为它要给id=5的索引记录增加S锁,它可以通过主键索引直接定位到要加S锁的索引记录行,不需要走全表扫描。找到id=5的行后尝试给它加S锁,但是发现这个行已经被左侧的事务给增加了X锁。S锁和X锁不能共存,所以右侧的事务给id=5的行增加S锁失败。
所以:在我们平时开发的时候,写SQL语句的时候,一定要格外的注意给where条件后面的字段赋值的时候,一定要根据对应的字段类型进行赋值。切不要让MySQL使用隐式转换的功能导致索引失效而走全表扫描。这样我们会有一种错觉:为啥我加了索引了,查询还是很慢。你要保证:增加了索引,并且SQL语句查询的时候真正使用到了索引,这样才会对你的SQL性能有提升。
RR级别+唯一索引列
当我们尝试通过一个唯一索引列去给表增加X锁的时候,会使用如下的SQL,它会给表增加那些锁呢?
/*根据唯一索引列查询,给行增加X锁*/ select * from userinfo where phone = '5555' for update;
此时查询数据的过程是这样的:先查唯一索引,然后再回表查询主键索引,然后从主键索引上返回查询的结果。具体流执行流程如下:
先根据phone列上面的唯一索引找到索引值为’5555’索引记录,因为是唯一索引,所以找到5555的索引记录后就停止搜索了,索引树上只有一条5555的记录。
然后再根据这个索引记录上面存储的主键索引的值5去主键索引上面查找需要查询的行记录。
根据加锁规则中提到的:只会在扫描到的对象上增加锁。所以会在主键索引id=5的索引记录上增加X锁,也会在唯一索引phone='5555’的索引记录上增加一个X锁。
此时加锁的情况如下所示:

疑问1:如何证明通过select * from userinfo where phone='5555' for update增加X锁的时候,在索引列phone='5555’的索引记录上增加了X锁了?通过如下实验可以证明这个结论:

针对上图中的各个实验步骤,简单做如下说明。
- 在第3步执行完成的之后,在非主键索引(非聚簇索引、二级索引)phone中的phone='5555’索引记录行增加了X锁,同时在主键索引(聚簇索引)id中id=5的索引记录行增加了X锁。
- 第4步中查询语句使用了覆盖索引的功能,我们只查询的phone这一列的值,在非主键索引上就包含了我们要查询的结果,所以这个查询不会去查询主键索引,只会在非主键索引上搜索查找。但是它增加S锁和X锁都失败了,说明这个phone='5555’索引记录上已经被增加了X锁。
- 在第5不执行完成后,左侧的事务就回滚了,所以在第3步中增加的两把X锁都被释放掉了。
- 所以在第6步和第7步中,再次尝试给phone='5555’的非主键索引记录行增加S锁或X锁的时候,都加锁成功了。
- 此时就已经说明了在通过非主键索引且是唯一索引列,在给表增加X锁的时候,除了会对主键索引对应的记录行增加X锁之外,还会在非聚簇索引的索引记录上增加X锁。
- 在第11步中,我们做了和第3不类似的操作,但是和第3步的区别在于:此时我们给表增加的是S锁而不是第3步中的X锁。
- 因为S锁和S锁是共享的,所以在右侧事务中的第12步中,给phone='5555’的索引记录增加S锁,成功。
- 因为S锁和X锁不能共存,所以在右侧事务中的第13步中,给phone='5555’的索引记录增X锁,加锁失败。而当左侧事务执行完第14步回滚事务的操作之后,此时phone列上面的phone值为’5555’的索引记录的S锁已经被释放,所以做右侧事务中,再次尝试给phone='5555’的索引记录增加X锁,此时才成功。
疑问2:为什么要在主键索引id=5这个记录上也增加X锁?如果并发的一个SQL,是通过主键索引来删除数据,SQL语句为:delete from userinfo where id = 5;。 此时,如果update语句没有将主键索引上的记录加锁,那么并发的delete就会感知不到前面的update语句的存在,违背了同一记录上的更新/删除需要串行执行的原则。
疑问3:通过疑问2,我们知道在唯一索引phone上面增加了X锁,那么我们前面的实验一中,通过select * from userinfo where id = 5 for update增加X锁的时候,有没有在索引列phone='5555’的索引记录上增X锁呢?
我们的实验截图如下:

注意:目前我只能确定phone='5555’的索引记录上一定是没有X锁,但是有没有S锁目前还不能确定,因为如果通过id=5 for update加X锁后,如果在phone='5555’的非主键索引的索引记录上增加一个S锁,在右侧的事务中,也是可以获得S锁的,因为S锁和S锁是可以共存的。事实上,我们也确实在右侧的事务中获得了phone='5555’索引记录上的S锁。索引我不确定在左侧的事务中,是否给phone='5555’的索引记录上增加了S锁。
如果大家有办法可以证明这一点,也希望大家给我留言你的证明方式。
RR级别+非唯一索引列
通过非唯一索引列age来增加X锁的SQL语句如下,当执行完成如下语句之后,表userinfo会有哪些锁产生呢?
select * from userinfo where age = 23 for update;
加锁情况如下图所示:
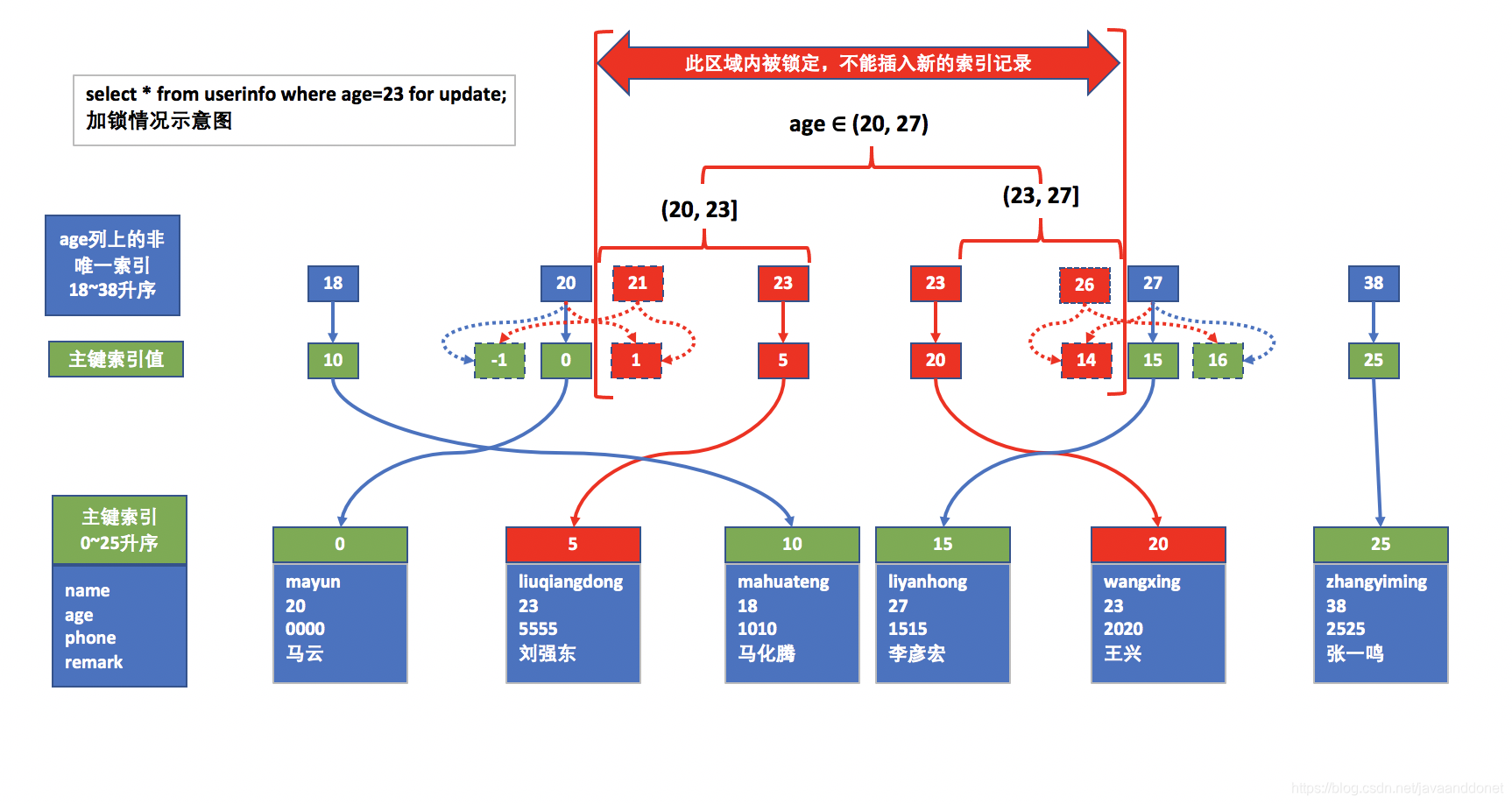
这里需要说明几点:
- 根据非唯一索引加锁规则,此次增加的间隙锁有:(20,23]、(23,27]。对于非唯一索引来说,当扫描到最后一个边界age=27的时候,临键锁退化为间隙锁。所以此时的锁为间隙锁:(20,27),不包含左右两边的边界值20和27。
- 行锁有:在age=23的非主键索引记录上有两把,因为有两个age=23索引记录。同时在id=5和id=20的主键索引记录上也有两把X锁,
- 只要当age的取值范围为(20,27)的时,任何记录行都不能插入成功。因为age上面的间隙锁阻止了数据的插入。
- 只要当age的值不属于(20,27),且不等于20也不等于27的时候,任何记录行都可以插入成功。前提是待插入的数据行中的id的值符合主键id的唯一性和phone的值符合phone唯一索引的唯一性。
- 当age=20的时候,并不是说,id的值可以使用任意表中不存在的主键值作为待插入的主键值。此时id的值必须为小于0的数,不能大于0。举例说明:当待插入的数据中的age=20, id=1,那么在非唯一索引age上面存这一行索引记录的时候,会在上图中的蓝色方框20后面在创建一个age=20的记录,还需要为这个非唯一索引下面村上主键索引(聚簇索引)的值:1,此时的1比表中已经存在的主键值0大,所以它会放在0的后面,如上图中所示此时的1会占用被锁住的索引间隙。所以此时不能插入成功。能插入成功的为:age=20, id=-1或age=20, id=-2这样的组合。
- 当age=27的时候,同理,id的值需要大于15才可以插入成功。比如:age=27, id=16或者age=27, id=17这样的组合。如果此时插入一个age=27, id=14的数据行,你设想一下会怎么存放这个索引记录,索引中已经存在一个age=27, id=15的记录了,此时再来一个age=27, id=14的记录,那这个id=14的记录必须排在id=15的前面。而此时id=14的位置是被间隙锁锁住的。所以它是插入失败的。
- 上面凡是红色的背景或红色箭头的区域都是有锁的区域,也就是这样的数据不能被插入成功。
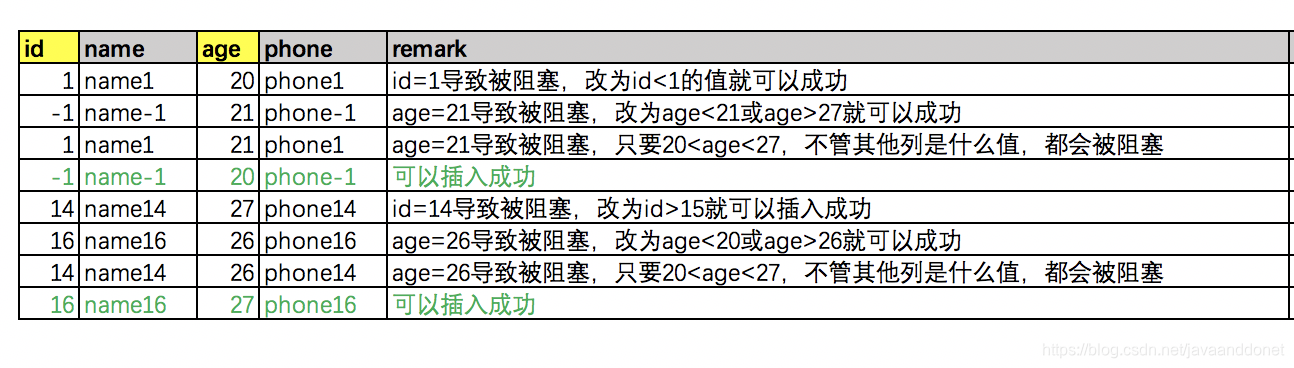
实验前的预测:
实验截图:

实验使用到的SQL语句:
insert into userinfo (id, name, age, phone, remark) values(1, 'name1', 20, 'phone1', 'id=1导致被阻塞,改为id<1的值就可以成功'); insert into userinfo (id, name, age, phone, remark) values(-1, 'name-1', 21, 'phone-1', 'age=21导致被阻塞,改为age<21或age>27就可以成功'); insert into userinfo (id, name, age, phone, remark) values(1, 'name1', 21, 'phone1', 'age=21导致被阻塞,只要20<age<27,不管其他列是什么值,都会被阻塞'); insert into userinfo (id, name, age, phone, remark) values(-1, 'name-1', 20, 'phone-1', '可以插入成功'); insert into userinfo (id, name, age, phone, remark) values(14, 'name14', 27, 'phone14', 'id=14导致被阻塞,改为id>15就可以插入成功'); insert into userinfo (id, name, age, phone, remark) values(16, 'name16', 26, 'phone16', 'age=26导致被阻塞,改为age<20或age>26就可以成功'); insert into userinfo (id, name, age, phone, remark) values(14, 'name14', 26, 'phone14', 'age=26导致被阻塞,只要20<age<27,不管其他列是什么值,都会被阻塞'); insert into userinfo (id, name, age, phone, remark) values(16, 'name16', 27, 'phone16', '可以插入成功');
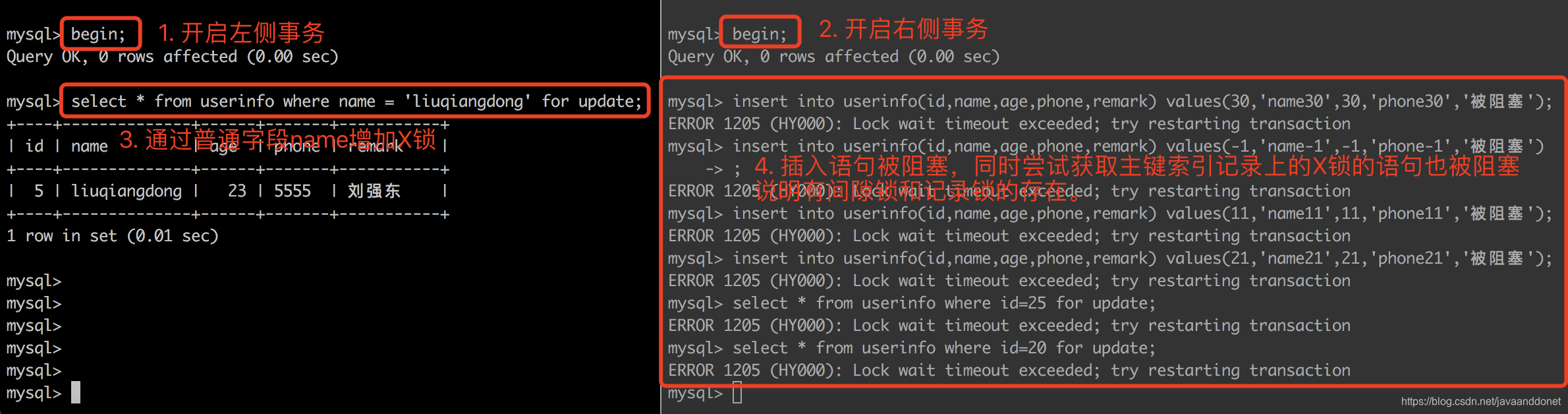
RR级别+普通字段列
如果是使用如下的一个普通字段来加锁,会是什么情况呢?
select * from userinfo where name = 'liuqiangdong' for update;
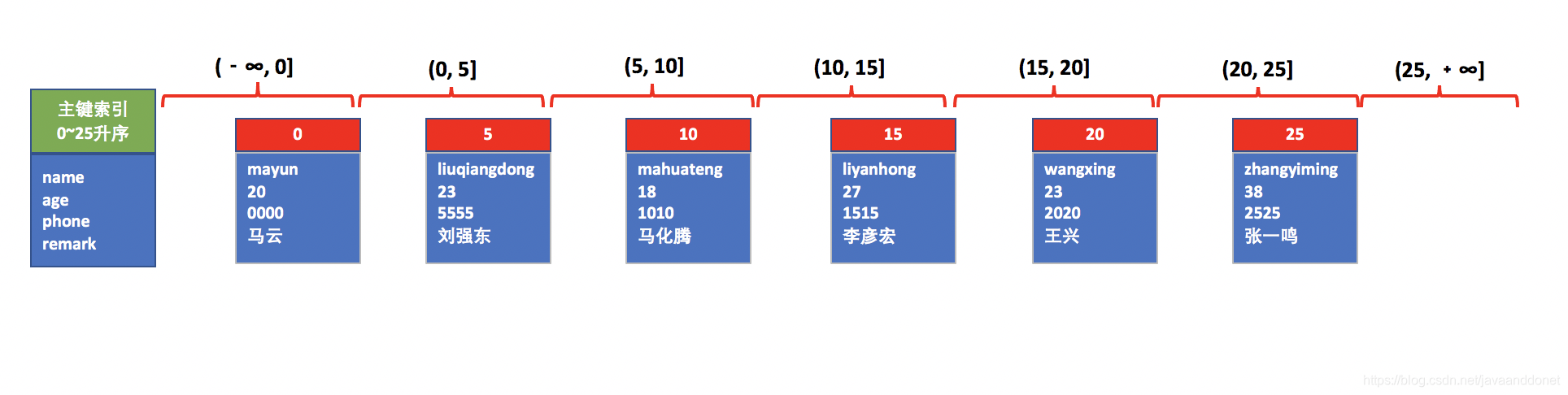
此时加锁的情况是这样的:因为name是一个普通的列,上面没有任何索引可以使用,所以根据这个条件进行搜索数据的时候,会进行全表扫描的操作,当搜索到第一个name='liuqiangdong’的数据行的时候,不会马上停下来,因为后面可能还有很多个name='liuqiangdong’的数据行,所以要进行全表扫描。根据前面我们说的加锁规则,凡是扫描到的对象都要加锁,所以此时全表中的每一个主键索引记录上都有一个X锁。同时为了防止幻读的凡是,会对这个表上所有的主键索引的间隙也都增加上间隙锁。
加锁情况示意图如下:
实验过程:
总结
在可重复读RR隔离级别下,间隙锁的加锁规则如下,如果不是RR级别,也就不会有间隙锁存在了,所以间隙锁只在RR级别下才会存在。
- 原则 1:加锁的基本单位是临键锁next-key lock。next-key lock是前开后闭区间。
- 原则 2:查找过程中访问到的对象才会加锁。
- 优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
- 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
- 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止,这个在MySQL8.0以后已经修复,但是在MySQL5.7版本中有这个问题。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/javaanddonet/article/details/111187345

