NNDL 神经网络与深度学习 第2章 机器学习概述——学习笔记
机器学习概述
机器学习
概念
从绪论我们谈过了,机器学习就是一个构建映射函数的过程。

为什么要使用机器学习?
在早期的工程领域,机器学习也经常称为模式识别(Pattern Recognition,PR),但模式识别更偏向于具体的应用任务,比如光学字符识别、语音识别、人脸识别等。这些任务都有一个共同的特点,那就是所谓的“玄学”,也就是,这些任务,我们可以完成,但是我们无法描述为什么我们可以做到。现实世界的问题往往都是这样,十分复杂,很难通过规则来手工实现。所以才有了机器学习,
那什么是机器学习?
机器学习就是通过算法使得机器能从大量数据中学习规律从而对新的样本做决策。
机器学习有三要素:
- 模型
- 学习准则
- 优化
常见的机器学习有三种,那就是回归、分类、聚类。
接下来我们就来讲解一下机器学习的三要素
机器学习三要素
三要素
模型
机器学习是通过数据学习一个规律,来进行决策,而这个规律其实就是一种函数。我们不知道这个规律是什么,所以我们通过经验假设了一个函数集合,我们称之为假设空间。而同类问题的假设空间通常是一个函数族,我们将这种函数族,称之为模型。而线性模型的假设空间(模型)就是一个参数化的线性函数族。
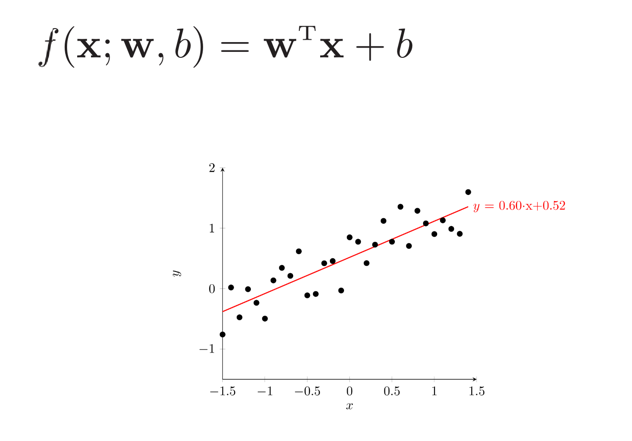
学习准则
损失函数
损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异,也就是评价预测结果的好坏。下面介绍常见的损失函数:
0-1 损失函数
0-1 损失函数(0-1 Loss Function)表示出了模型在训练集上的错误率。但数学性质不是很好,不连续且导数为 0,难以优化。所以常用连续可微的损失函数替代。
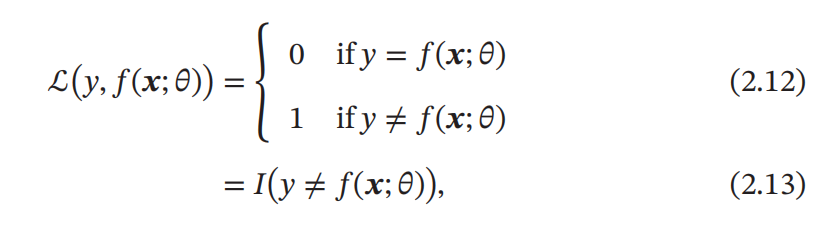
平方损失函数
平方损失函数(Quadratic Loss Function)经常用在预测标签 𝑦 为实数值的任务中,但不适用于分类问题,定义为:
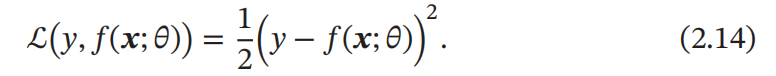
交叉熵损失函数
一般用于分类问题。
Hinge 损失函数
对于二分类问题,假设 𝑦 的取值为 {−1, +1},𝑓(𝒙; 𝜃) ∈ ℝ
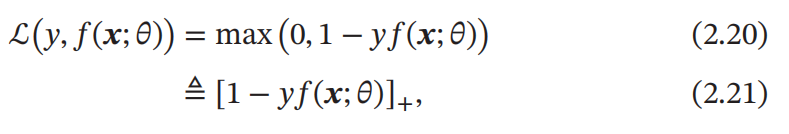
其中[𝑥]+ = max(0, 𝑥).
经验风险最小化原则
一个好的模型,应该有一个比较小的期望错误(期望风险),但是由于不知道真实的数据分布和映射函数,实际上无法计算。我们可以选择合适的损失函数,计算经验风险,也就是训练集的平均损失,用经验风险来近似期望风险。
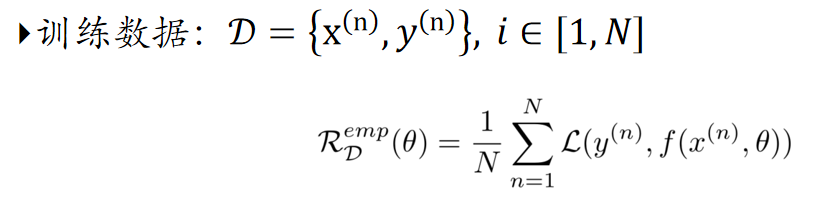
选择了合适的风险函数后,我们寻找一个参数 θ∗,使得经验风险最小化,这就是经验风险最小化原则。
结构风险最小化
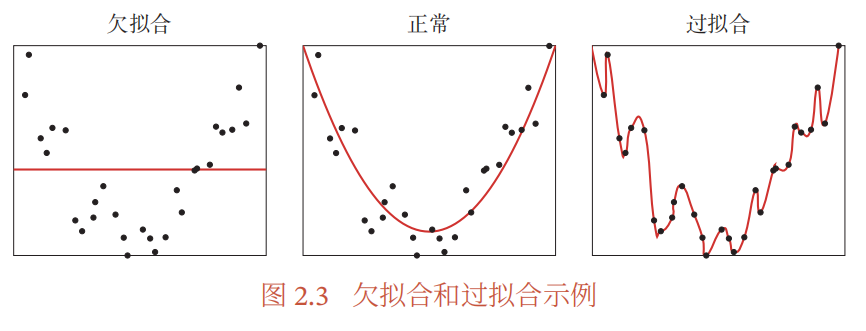
过拟合:有模型 f 和 f'。如果模型 f 在训练集上比 f' 的损失小,但模型 f 在样本集上比 f' 的损失大,我们称模型 f 过度拟合训练数据。(过度拟合训练数据只能保证在训练集的准确率,但相反在测试上准确率下降)
过拟合问题往往是由于训练数据少和噪声以及模型能力强等原因造成的。为了解决过拟合问题,一般在经验风险最小化的基础上再引入参数的正则化(Regularization)来限制模型能力,使其不要过度地最小化经验风险。这就是结构风险最小化(Structure Risk Minimization,SRM):

欠拟合:这是一个和过拟合相反的概念,即模型不能很好的拟合训练数据,在训练集的错误率较高。欠拟合一般是模型能力不足导致的。
优化算法
通过选择合适的损失函数,使用风险最小化原则,我们将机器学习变成了一个最优化问题(Optimization),机器学习就成了一个最优化问题的求解过程,接下来我们要介绍几个优化求解算法。
在机器学习中,优化又可以分为参数优化和超参数优化.模型 𝑓(𝒙; 𝜃)中的 𝜃 称为模型的参数,可以通过优化算法进行学习.除了可学习的参数 𝜃 之外,还有一类参数是用来定义模型结构或优化策略的,这类参数叫作超参数。
常见的超参数包括:聚类算法中的类别个数、梯度下降法中的步长、正则化项的系数、神经网络的层数、支持向量机中的核函数等.超参数的选取一般都是组合优化问题,很难通过优化算法来自动学习.因此,超参数优化是机器学习的一个经验性很强的技术,通常是按照人的经验设定,或者通过搜索的方法对一组超参数组合进行不断试错调整。(所以才会有人为的调参)
梯度下降法( Gradient Descent )
很多机器学习方法都倾向于选择合适的模型和损失函数,以构造一个凸函数作为优化目标.但也有很多模型(比如神经网络)的优化目标是非凸的,只能退而求其次找到局部最优解.
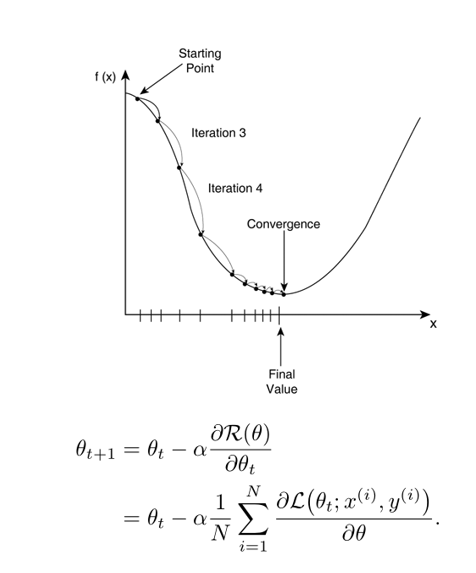
在机器学习中,最简单、常用的优化算法就是梯度下降法,即首先初始化参数𝜃0,然后按下面的迭代公式来计算训练集 𝒟 上风险函数的最小值。
其中𝜃𝑡 为第𝑡 次迭代时的参数值,𝛼为搜索步长.在机器学习中,𝛼一般称为学习率(Learning Rate)!(学习率是十分重要的超参数)
提前停止
针对梯度下降算法,我们还需要使用提前停止来防止它过度拟合。由于会出现过拟合,除开训练集和测试集,有时还会用一个验证集(Validation Set)来进行模型选择,测试模型是否能在验证集上最优。
每次迭代时,把得到的新模型就可以放在验证集上测试,计算错误率,当错误率不再上升时,停止迭代,这个时候得到的模型就是效果比较好的模型。我们把这种策略称之为提前停止。
如果没有验证集,可以在训练集上划分出一个小比例的子集作为验证集
针对过拟合问题,我们说了有提前停止方法,而提前停止其实属于正则化的一种,机器学习中的正则化到底有什么用?,优化是为了让经验风险最小,而正则化是为了降低模型复杂度。
随机梯度下降法
在前面提到的梯度下降法中, 目标函数是整个训练集的风险函数,我们称之为批量梯度下降法(Batch Gradient Descent,BGD),它在每次迭代时都需要计算每个样本的损失函数并求和。当样本量过大时,空间复杂度也较大,每次迭代成本很高。
如果说,批量梯度下降法是从样本抽出 N 个样本将其经验风险来近似期望风险,为了减少迭代的计算复杂度,我们可以只抽出 1 个样本,计算这个样本损失函数的梯度并更新参数,这就是随机梯度下降法(Stochastic Gradient Descent,SGD)。而当经过足够的迭代次数时,随机梯度下降也可以收敛到局部最优解。随机梯度下降法的训练过程如算法2.1所示.

随机梯度下降相当于在批量梯度下降的梯度上引入了随机噪声.在非凸优化问题中,随机梯度下降更容易逃离局部最优点。凸优化就是找凸函数最小值,由于凸函数只有一个最小值,所以容易找到这类算法,其中最经典最常用的是SGD。实践中这类算法常被用于非凸函数,这么做一般仍然可以找到 local minima 不过不保证是全局最小值。
Optimization problem: Maximizing or minimizing some function relative to some set, often representing a range of choices available in a certain situation. The function allows comparison of the different choices for determining which might be “best.”
小批量梯度下降法
小批量梯度下降法(Mini-Batch Gradient Descent)是批量梯度下降和随机梯度下降的折中。每次迭代时,我们随机选取一小部分训练样本来计算梯度并更新参数,这样既可以兼顾随机梯度下降法的优点,也可以提高训练效率。
偏差-方差分解
为避免过拟合,我们通常会在模型的拟合能力和复杂度之间平衡。为了平衡拟合能力与复杂度,我们介绍一个分析与指导工具————偏差-方差分解(Bias-Variance Decomposition)。
偏差:指一个模型在不同训练集上的平均性能和最优模型的差异,可以用来衡量一个模型的拟合能力。
方差:指一个模型在不同训练集上的差异,可以用来衡量一个模型是否容易过拟合。
而最小化期望错误等价于最小化偏差和方差之和。
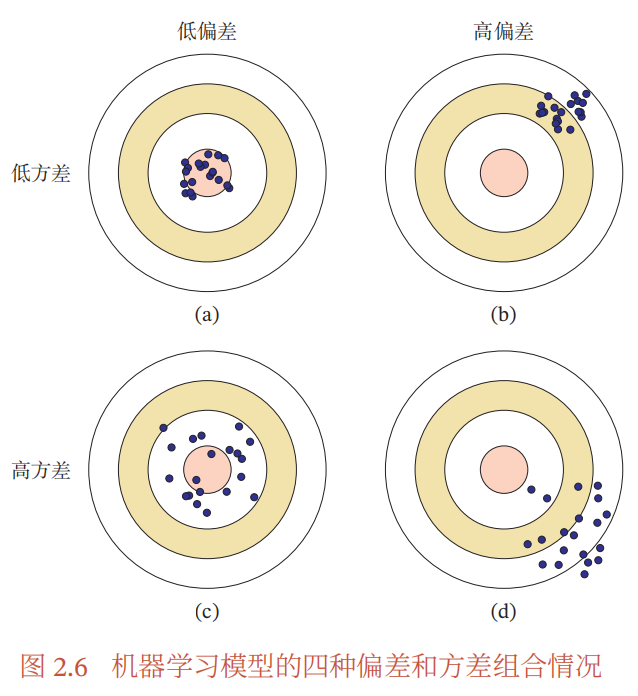
图 2.7 给出了机器学习模型的期望错误、偏差和方差随复杂度的变化情况,其中红色虚线表示最优模型。最优模型并不一定是偏差曲线和方差曲线的交点。
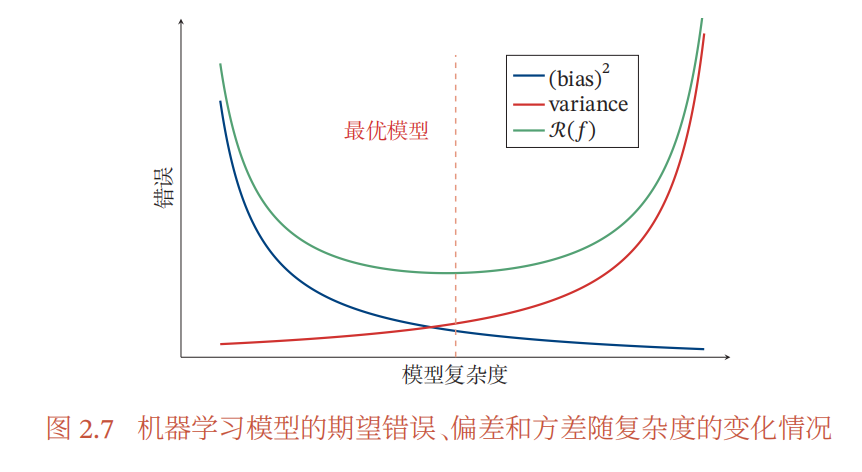
以通过降低模型复杂度、加大正则化系数、引入先验等方法可以来缓解模型过拟合,此外还有集成模型也就是引入多个高方差模型的平均来降低方差。之后会有更进一步的了解。
、
机器学习算法类型
一般来说,我们会按照训练样本提供的信息以及反馈方式的不同,将机器学习算法分为以下几类(当然其他标准的也有):
监督学习(Supervised Learning)
- 特点:训练集中每个样本都有标签
- 根据标签类型的不同,可以分为:
- 回归问题:标签 y 为连续值(实数或者连续整数)
- 分类问题:标签 y 为离散值(学习到模型称之为分类器,问题有二分类和多分类的类别)
- 结构化学习:标签 y 为结构化对象(序列、树等),求解过程称之为解码
无监督学习(Unsupervised Learning)
- 特点:训练集样本无标签
- 典型的无监督学习问题有聚类、密度估计、特征学习、降维等
强化学习(Reinforcement Learning)
- 特点:通过交互来学习的机器学习算法。
一般而言,监督学习通常需要大量的有标签数据集,这些数据集一般都需要由人工进行标注,成本很高.因此,也出现了很多弱监督学习(Weakly Supervised Learning) 和半监督学习(Semi-Supervised Learning,SSL)的方法,希望从大规模的无标注数据中充分挖掘有用的信息,降低对标注样本数量的要求.强化学习和监督学习的不同在于,强化学习不需要显式地以“输入/输出对”的方式给出训练样本,是一种在线的学习机制。

理论和定理
在机器学习中,有一些非常有名的理论或定理,对理解机器学习的内在特性非常有帮助。
PAC 学习理论(Probably Approximately Correct)
一个PAC 可学习(PAC-Learnable)的算法是指该学习算法能够在多项式时间内从合理数量的训练数据中学习到一个近似正确的𝑓(𝒙)。
PAC学习可以分为两部分:
- 近似正确(Approximately Correct)
- 可能(Probably)
没有免费午餐定理(No Free Lunch Theorem,NFL)
对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。如果一个算法对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差。
不能脱离具体问题来谈论算法的优劣,任何算法都有局限性.必须要“具体问题具体分析”
丑小鸭定理(Ugly Duckling Theorem)
丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大.
因为世界上不存在相似性的客观标准,一切相似性的标准都是主观的
奥卡姆剃刀原理(Occam's Razor)
如无必要,勿增实体
如果有两个性能相近的模型,我们应该选择更简单的模型
归纳偏置(Inductive Bias)
很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置。
- 在最近邻分类器中,我们会假设在特征空间中,一个小的局部区域中的大部分样本都同属一类。
- 在朴素贝叶斯分类器中,我们会假设每个特征的条件概率是互相独立的。
- 归纳偏置在贝叶斯学习中也经常称为先验(Prior)
线性回归
讲了那么多,接下来我们要从最简单的线性回归模型开始,了解机器学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号