
从Softmax到知识蒸馏--读论文《Distilling the Knowledge in a Neural Network》
Softmax
在神经网络训练中,最后一层往往是全连接层接Softmax输出,而最近读的论文《Distilling the Knowledge in a Neural Network》也将Softmax层加入了温度系数实现蒸馏。这里简单介绍Softmax层的意义,并且写下我对知识蒸馏这篇经典论文的理解。
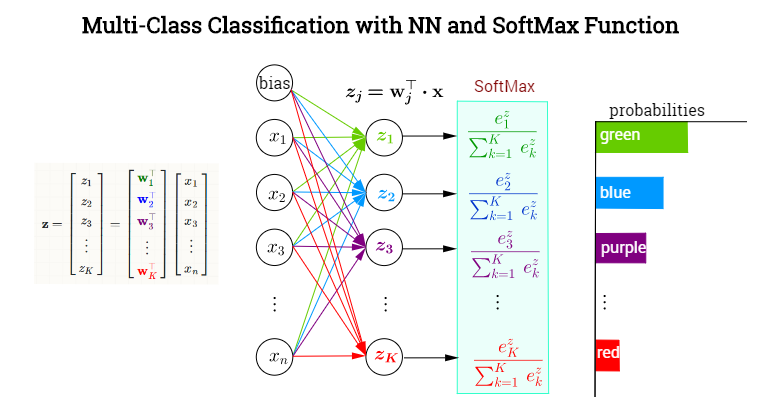
Softmax层有什么具体意义呢?参考[https://blog.csdn.net/blogshinelee/article/details/84826837],通过分类网络获得每个类别的分数z,经过Softmax层映射成概率。
\(\hat{y_j} = softmax(z_j) = \frac{e^z_j}{\sum{e^z_j}}\)
同时查找到资料https://segmentfault.com/a/1190000017320763中也有Softmax函数与交叉熵之间的关系,交叉熵损失函数的导数是Softmax层输出的概率-1,因而反向传播迭代时更方便。
Knowledge Distillation
Introduction

复杂的神经网络就像毛毛虫,需要经过大量的吸收营养,完成成长的过程;而浅层神经网络就像蝴蝶,完成神经网络的破茧而出。

文章的核心思路在于实现 Soft Target 的提取,将复杂网络神经元输出经过改进的Softmax层后,信息熵增加,使得浅层网络可以学习到数据之间的关联性;具体步骤为:
- 正常训练复杂网络,如使用交叉熵作为损失函数;
- 训练浅层网络,输入为复杂网络经过改进Softmax层输出,将神经元输出的Logits映射成概率分布更平滑的 Soft Target ;浅层网络输出为实际Label,损失函数是两部分:第一部分是Soft Target对应的经过改进Softmax层的浅层网络输出,第二部分是Hard Target和浅层网络对于真实Label的输出。
- 使用网络推断时,将浅层网络温度系数重新调整为 1 即可得到实际输出。

