



AlexNet
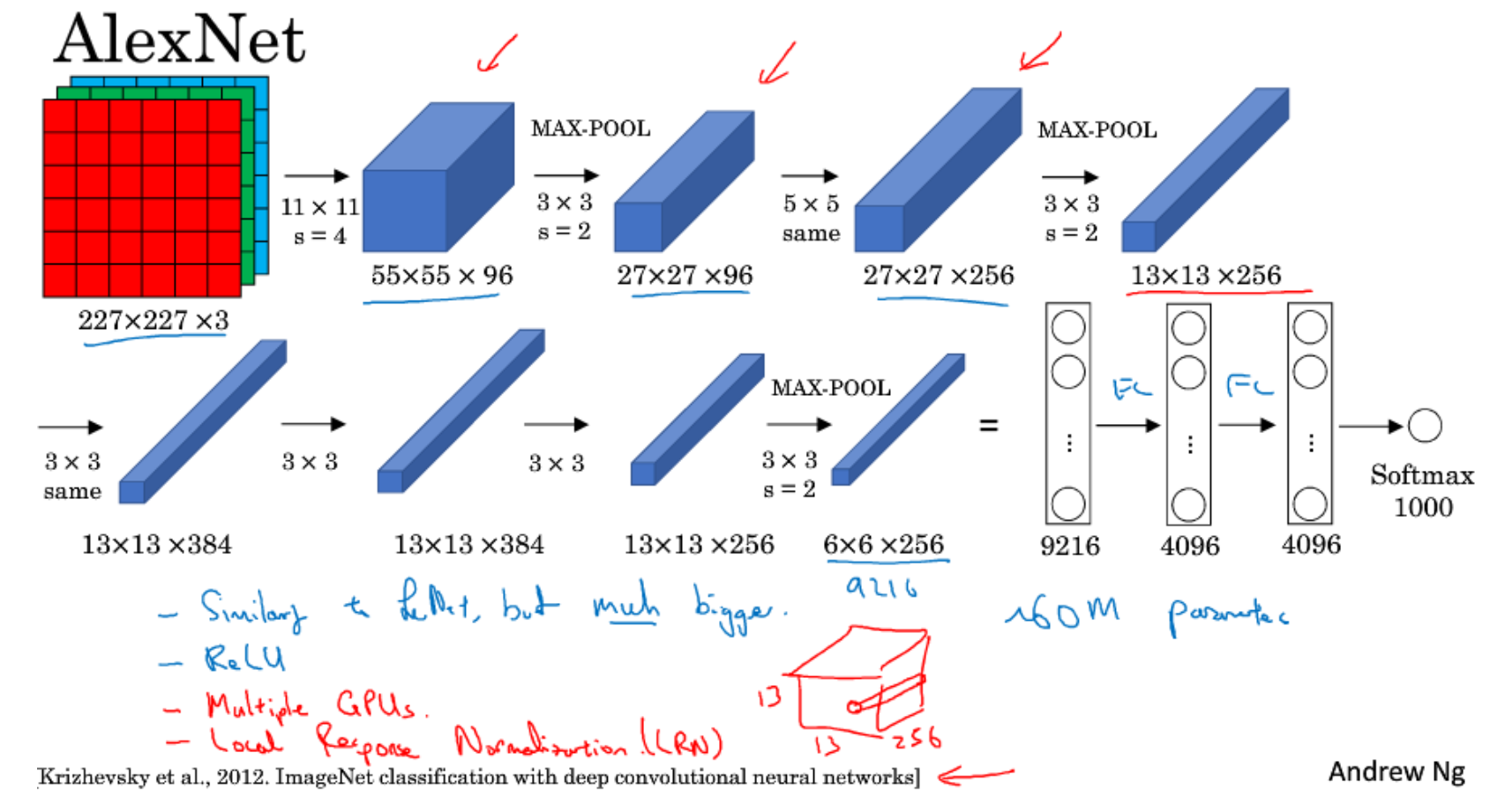


在单张数据集输入网络之前,要将数据集的所有图片,比如18w张都展开成一个227*227*3的向量,然后求这18w个向量的均值,在将这单张图像展开成227*227*3的向量减去均值向量,再将这个减去均值的向量作为输入。

对抗轻微目标偏移带来的影响:


- 卷积核的数量越多,代表基元越多,能学到的特征就越多
- 第一层的输入是原图尺寸是227*227*3,第二层的输入是27*27*96,那么采用5*5的卷积核对27*27*96的卷积看到的内容相当于在原图227*227*3使用大概50*50的卷积核看到的东西,有更大的感受野





ZFNet



- 卷积核从11*11变到了7*7使得可以提取更多的细节信息
- 第一层卷积核的步长设置为2,使得第二层卷积核卷积的图像是55*55,这样在更大尺寸的图像上可以提取更多的信息
VGG
首先输入图像的处理方面:


上图中各小点的解释见感受野

卷积核的个数越多,就能记录下更多的结构信息
前面几层得到的特征图描述的是一些基元(比如点线边),基元的个数是很少的(由基元组合成的语义还是很多的)因此不需要那么多的卷积核,并且前面几层的图像比较大卷积核的个数多的话也会导致计算量过大。
后面几层的特征图语义比较多,就需要更多的卷积核记录


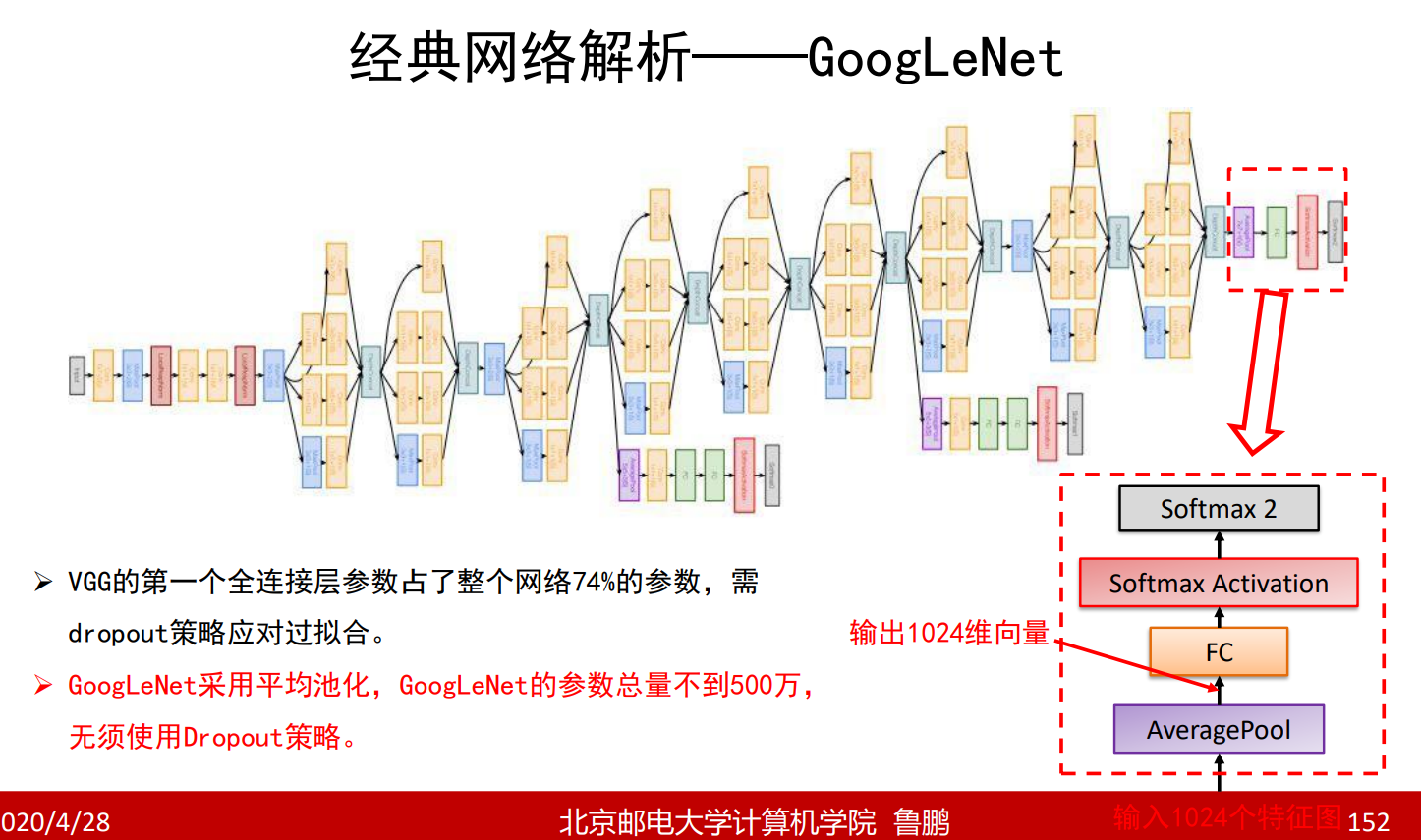
7*7是卷积神经网络最终输出的特征图的尺寸,一共有1024个特征图
4096是第一个全连接层神经元的个数。
GoogleNet

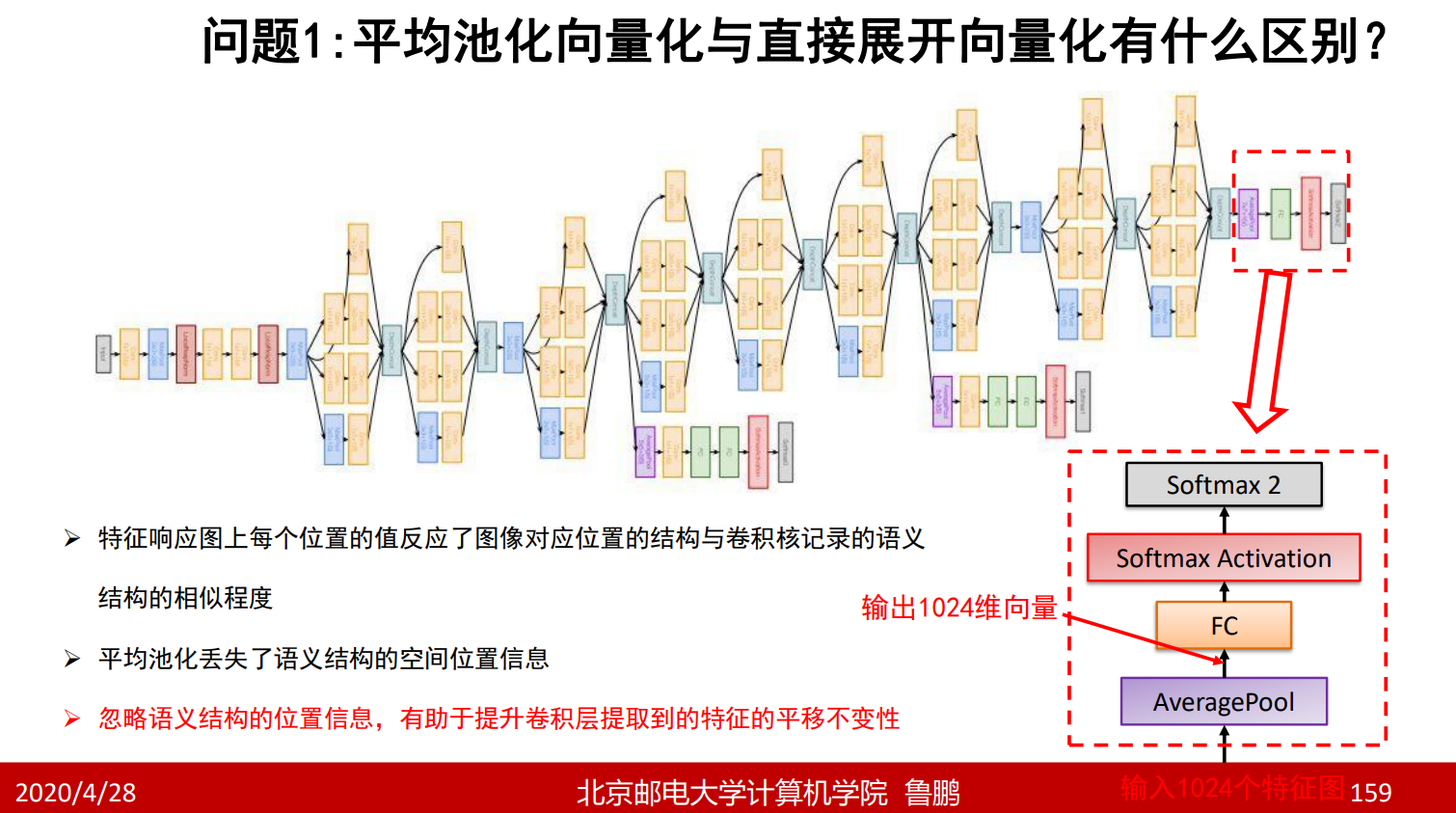
平均池化的作用是求取每一张特征图的平均值作为向量的一维,而不像上面的网络将每一个特征图都展开成一个向量

- 辅助分类器的作用是提前梯度回传避免梯度消失,训练好的网络辅助分类器就不要了
- 前面章节所述的网络全都采用串联结构会丢失掉很多信息,比如一个长方形,由于前面层的感受野比较小因此只能检测到它的四条边,而不认为它是一个长方形,那么后面的层也会认为它是4条线,那么就丢失了长方形的这一信息,采用如下方法进行解决:

上图中第一个图中
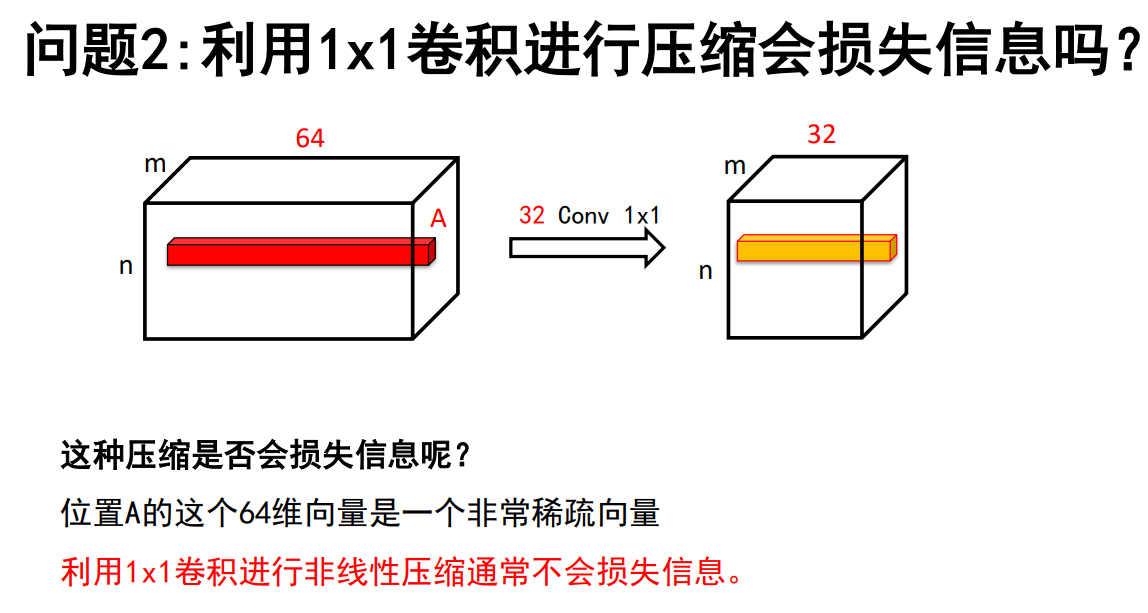
1*1的卷积核表示对输入特征图所有通道进行相加,起到压缩的作用
3*3表示提取输入特征图3*3感受野的内容
5*5表示提取输入特征图5*5感受野的内容
这里面的maxpooling和之前的不一样,不进行降采样,也就是将一个像素的像素值用它3*3领域内最大的像素值代替,也就是相当于在某一领域内所有像素都要使用像素值最大值替代
1*1,3*3,5*5,池化通过零填充保证它们的输出尺寸相同
Filter concatenation的输出通道个数是64+128+32+256。
以上的做法可以使输出得到更多的信息
上图中第二个图
由于第一个图进行多次卷积和池化因此计算量较大
采用的方法是(如红色的所示)比如原来的输入是256个特征图,经过96个卷积核之后就变成了96个特征图了,这样减少了后续3*3,5*5的计算量


ResNet

前向传播:
最差的情况F(X)没提取出任何特征,那么该层的输出就和输入一样,稍微差一点的情况只提取出一些特征,但这也是有用的,和输入加和这些特征在输入上就会被加强。原来的模型只有F(X),如果没有提取出任何特征到最后输出就是一个没有特征的结果,而ResNet即便是F(X)没有提取出任何特征但是我还之前层的输出。
反向传播:



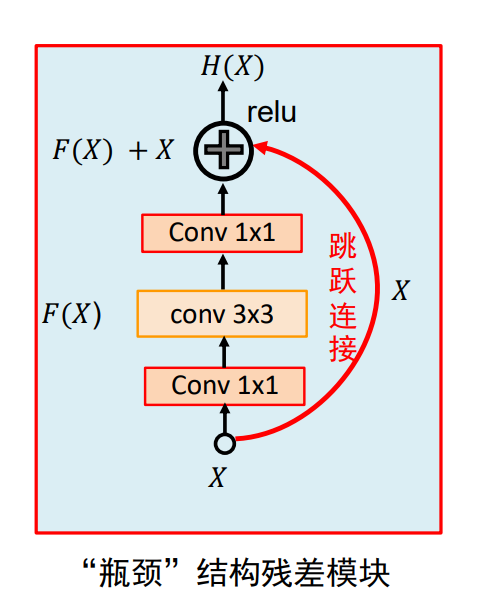
第一个Conv1*1是由于直接对输入进行3*3的卷积计算量太大,需要降低通道数。第二个Conv1*1是要还原到原来的通道数这样才能和X相加。

最后的输出也和GoolgeNet类似使用平均池化。
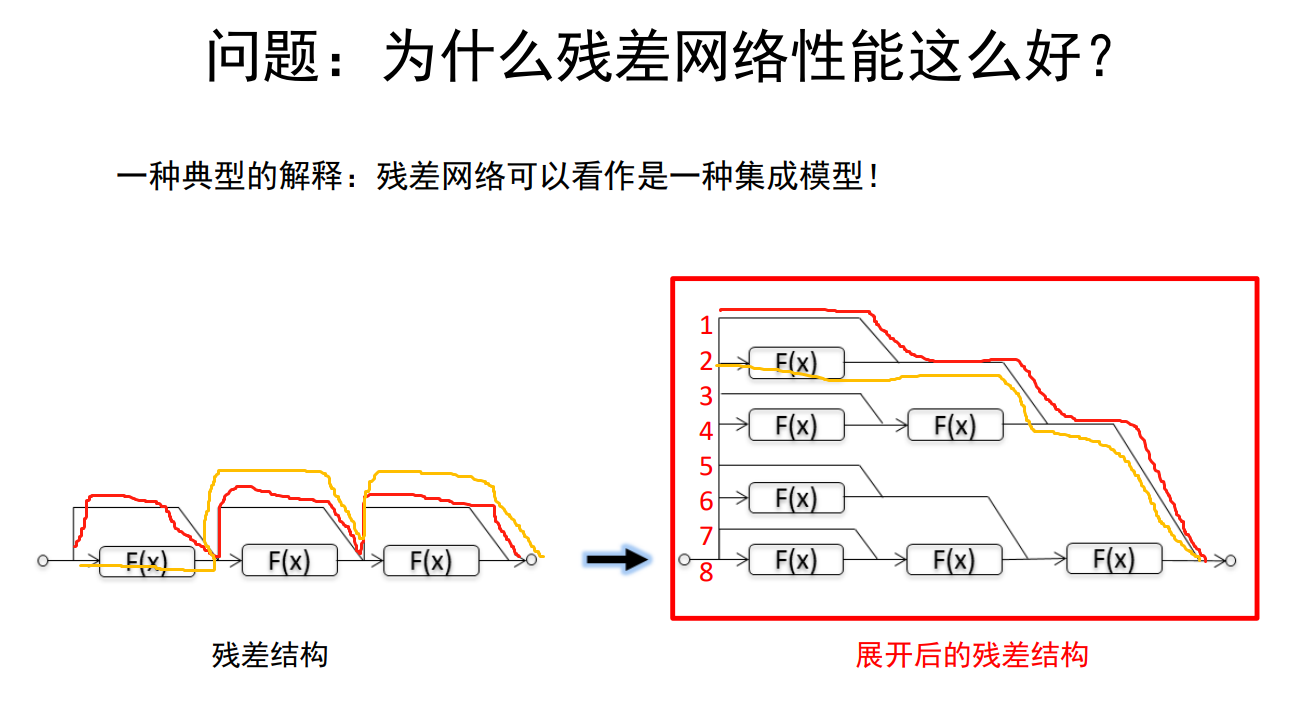
当删除1~8的任意一层对整体的网络没有任何的影响

