
k8s
K8s Pod:
自主式 Pod:死亡后没有控制器将其拉起
控制器管理的 Pod:死亡后控制器能够将其拉起
Pod 内容器:
当一个 Pod 创建后,会立即在 Pod 内创建一个 pause 容器,该 Pod 内其他容器公用该容器的网络协议栈;
因此,一个 Pod 中两个容器的端口不能相同,一个容器访问另一个容器的端口,直接用localhost:port就可以访问;
此外,一个 Pod 内容器也可以共享 pause 的存储卷;
Pod 控制器类型
ReplicationController & ReplicaSet & Deplovment
- ReplicationController
ReplicationController 用于确保 Pod 的副本数始终保持在用户定义的副本数,如果有容器异常退出,会自动创建新的 Pod 取代;异常多出来的容器也会被自动回收;
新版本中,Kubernetes 建议使用 ReplicaSet 替代 ReplicationControlle - ReplicaSet
ReplicaSet 与 ReplicationController 没有本质不同,但 ReplicaSet 支持集合式的 selector - Deployment
建议使用 Deployment 自动管理 ReplicaSet,ReplicaSet 不支持 rolling-update,但 Deployment 支持
Deployment 本身不支持创建 Pod,它可以创建 ReplicaSet,再通过 ReplicaSet 创建 Pod - HPA 平滑扩展
基于 RS 创建,监控 RS 中 Pod 的状态;如可以配置当 RS 中 Pod 的 CPU > %80 时就创建新的 Pod
StatefulSet
用于解决有状态服务问题:
- 稳定的持久化存储:Pod 重新调度后仍然能访问相同的持久化数据,基于 PVC 实现
- 稳定的网络标志,Pod 重新调度后其 PodName 和 HostName 不变
- 有序部署:即 Pod 的创建是有顺序的,按照定义的顺序,下一个 Pod 运行之前,所有之前的 Pod 都是 Running 或 Ready 状态,基于 init containers 实现
- 有序收缩:有序删除
DaemonSet
确保全部(或一些)Node 上运行一个 Pod 的副本;当有 Node 加入集群时,会为他们新增一个 Pod;当有 Node 从集群移除时,这些 Pod 会被回收;删除 DaemonSet 会删除它创建的所有 Pod
应用场景:
- 运行集群存储 daemon,例如再每个 Node 上运行 glusterd、ceph
- 在每个 Node 上运行日志收集 daemon,例如 fluentd、logstash
- 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter
Job,Cronjob
Job 负责批处理任务,即禁止性一次的任务,它保证批处理任务的一个或多个 Pod 成功结束;
Cron Job 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
相比于直接运行的脚本任务,Job 能够确保任务执行一定是成功退出的,并且可以设置正常退出的次数
服务发现
Pod 上都有标签,如 version:1 等等;
Service 服务发现 通过标签来选择 Pod 对外暴漏;客户端可以通过 Service 的 ip:port 来访问这些具有相同标签的 Pod;并且 Service 可以实现负载均衡,如使用 RR 方式
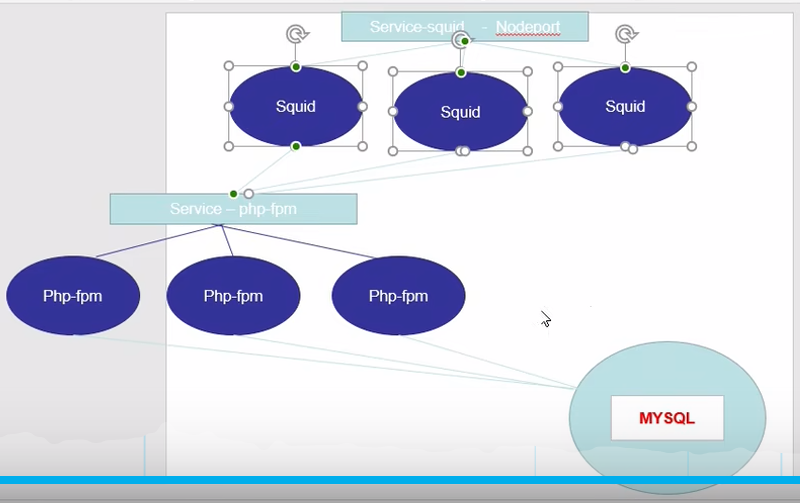
K8s 网络通信方式
K8s的网络模型假定所有 Pod 都在一个可以直接连通的扁平的网络空间中
同一个 Pod 内多个容器之间:localhost 网卡(共享 pause 容器的网络协议栈)
各 Pod 之间的通信: Overlay Network
Pod 与 Service 之间的通讯:各节点的 Iptables 规则
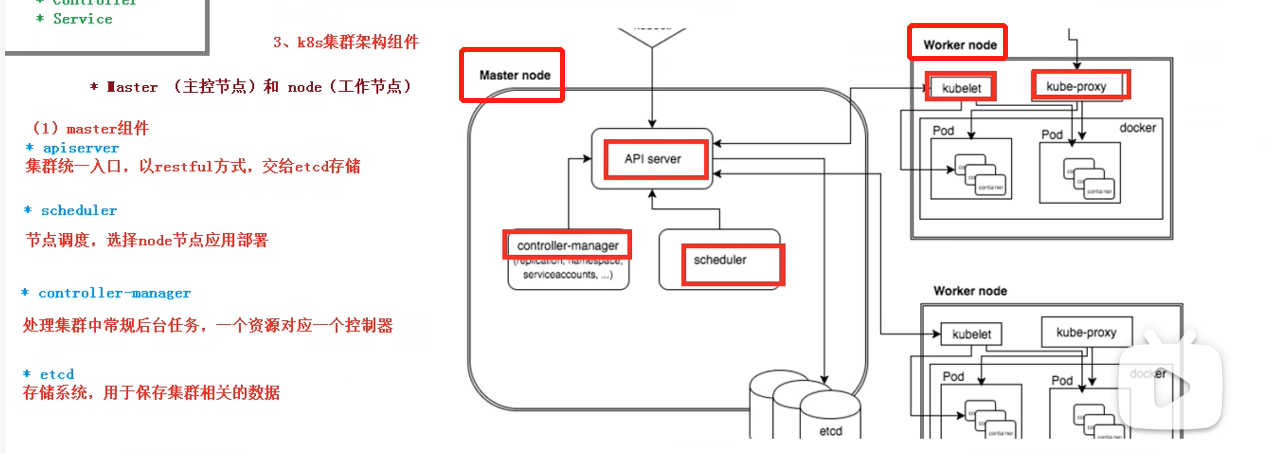
K8S集群架构

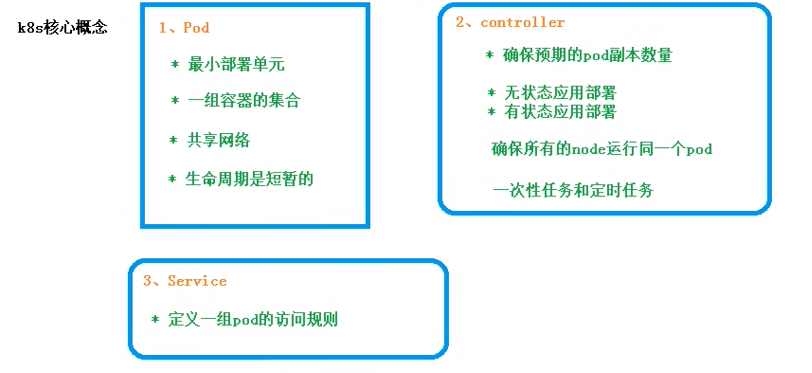
K8S 核心概念:Pod,Controller,Service
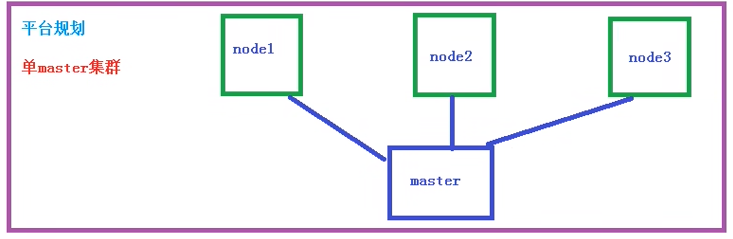
搭建 K8S 集群
平台规划
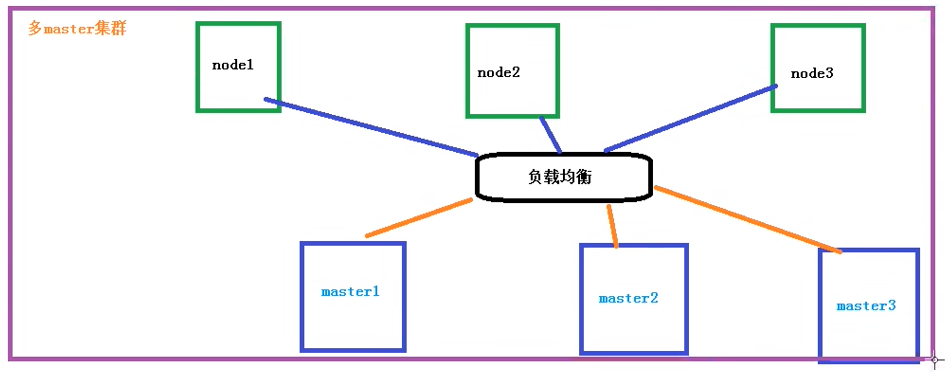
目前 K8S 部署主要两种方式:
- Kubeadm 方式
Kubeadm 是一个 K8S 部署工具,用于快速部署 Kubernetes 集群; - 二进制包
从 github 下下载发行的二进制包,手动部署每个组件,组成 Kubernetes 集群
Kubeadm 搭建 K8s 集群
centos网络配置参考:
https://blog.csdn.net/m0_51913750/article/details/131594908
centos 使用 yum install 命令报错:
Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirrorlist.centos.org
https://www.cnblogs.com/kohler21/p/18331060
在上面连接中按照
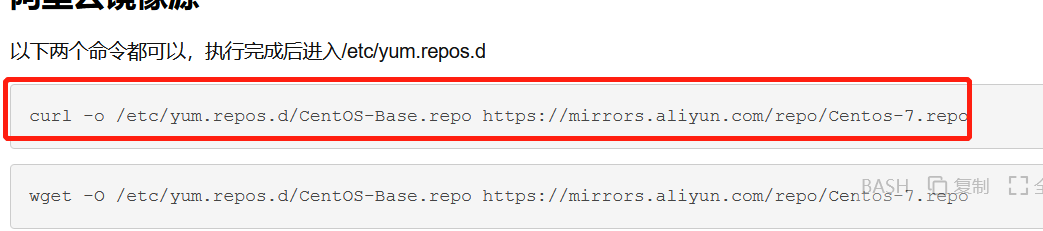
执行
Centos配置静态ip:
https://www.cnblogs.com/xuchuangye/p/14250286.html
注意 DNS1 要配置成网关ip,而不是 8.8.8.8
使用 Kubeadm 搭建单 master 节点集群
先对每台机器进行初始化操作:
# 安装 systemctl
yum install systemd
# 关闭防火墙
systemctl stop firewalld # 临时
systemctl disable firewalld # 永久
# 关闭 selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
# 关闭 swap 分区
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
# 根据规划设置主机名
hostnamectl set-hostname <hostname> # 如 hostnamectl set-hostname k8smaster
#在 master 节点添加 hosts
cat >> /etc/hosts << EOF
192.168.219.129 k8smaster
192.168.219.130 k8snode1
192.168.219.131 k8snode2
EOF
# 将桥接的 IPv4 流量传递到 iptables 的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 生效
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
所有节点安装Docker/kubeadm/kubelet
安装Docker:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum -y install docker-ce-18.06.1.ce-3.el7
systemctl enable docker && systemctl start docker
docker --version
配置 docker 镜像源
cat >> /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
改完后需要重启 docker
systemctl restart docker
添加 kubernetes 软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装 kebeadm,kubelet 和 kubectl
# 安装kubelet、kubeadm、kubectl,同时指定版本
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
# 设置开机启动
systemctl enable kubelet
部署 Kubernetes Master 节点
在 master 节点执行如下命令,该命令拉取 master node 的组件,如 api-server,controller-manager,scheduler 等
kubeadm init --apiserver-advertise-address=192.168.219.129 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
完成后,出现如下提示:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.219.129:6443 --token f9qbuf.1joh8rdpeofe9b6m --discovery-token-ca-cert-hash sha256:f6137add09c0b30fc89619f15647cc0c9e307b6660c1feacb528fa7ea9477ec4
注意,默认 token 有效期为 24 h,过期后该 token 不可用,此时需要重新创建 token,操作如下:
kubeadm token create --print-join-command
根据提示分别执行(不用切换普通用户):
master 节点上:
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
在 node 节点上执行以下命令,加入 master 节点:
kubeadm join 192.168.219.129:6443 --token f9qbuf.1joh8rdpeofe9b6m --discovery-token-ca-cert-hash sha256:f6137add09c0b30fc89619f15647cc0c9e307b6660c1feacb528fa7ea9477ec4
(如果在这一步,node 一直不能加入 master 节点,检查前面的防火墙配置等)
加入完成后,在 master 节点上可以使用kubectl get nodes查看节点
接下来,部署 CNI 网络插件:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
之后,可以使用kubectl get pods -n kube-system查看
搭建 flannel 时没有成功,可以参考
https://www.cnblogs.com/rouqinglangzi/p/11760469.html
https://www.zyixinn.com/archives/使用kubeadm部署k8s集群
验证集群:
# 下载nginx 【会联网拉取nginx镜像】
kubectl create deployment nginx --image=nginx
# 查看状态
kubectl get pod
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看一下对外的端口
kubectl get pod,svc
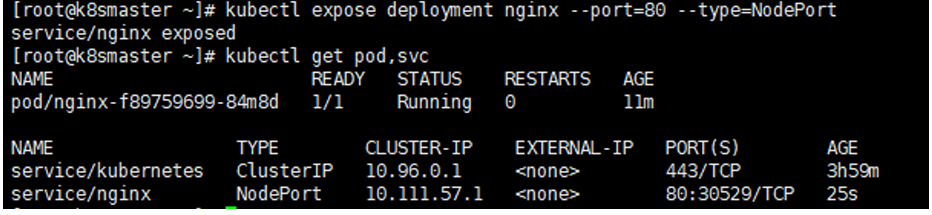
到宿主机浏览器上,访问如下地址
http://master_ip:30529/
kubectl 使用
kubectl [command] [type] [name] [flags]
- command:指定要对资源执行的操作,例如create、get、describe、delete
- type:指定资源类型,资源类型是大小写敏感的,开发者能够以单数 、复数
和 缩略的形式 - name:指定资源的名称,名称也是大小写敏感的
- flags: 指定可选的参数,例如,可用 -s 或者 -server 参数指 Kubernetes API server 的地址和端口
k8s 资源编排:yaml 文件
k8s 集群中对资源管理和资源对象编排部署都可以通过声明样式(YAML)文件来
解决,也就是可以把需要对资源对象操作编辑到YAML 格式文件中,我们把这种
文件叫做资源清单文件,通过kubectl 命令直接使用资源清单文件就可以实现对大量的资源对象进行编排部署了。一般在我们开发的时候,都是通过配置YAML文
件来部署集群的。
yaml 语法格式:
- 通过缩进表示层级关系
- 不能用 Tab 进行缩进,只能用空格
- 一般开头使用两个空格
- 字符后缩进一个空格,如冒号,逗号后需要加一个空格
- 使用 --- 表示一个新的 yaml 文件:
- 使用 # 代表注释
k8s yaml 文件组成部分


字段说明:
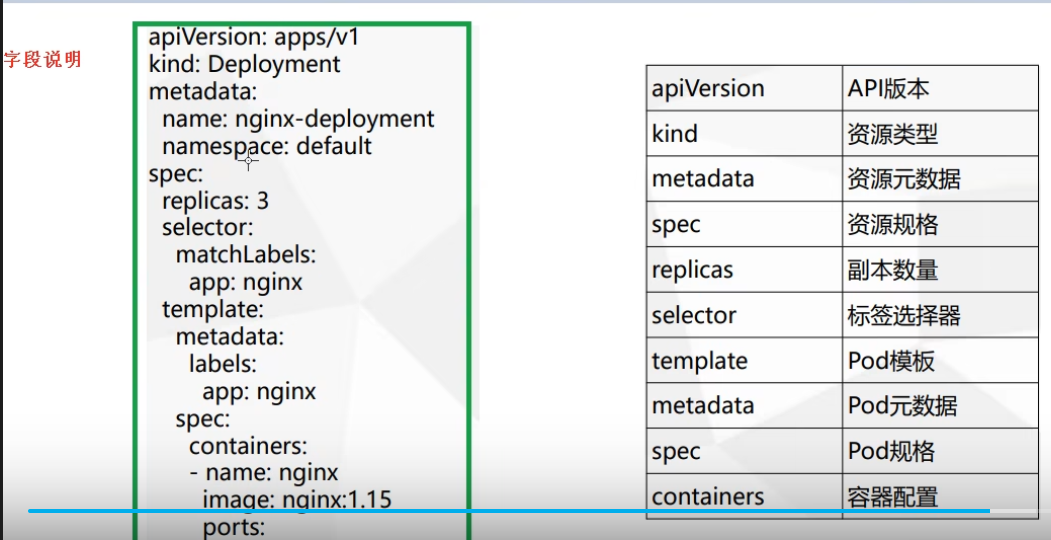
kind 资源类型,如
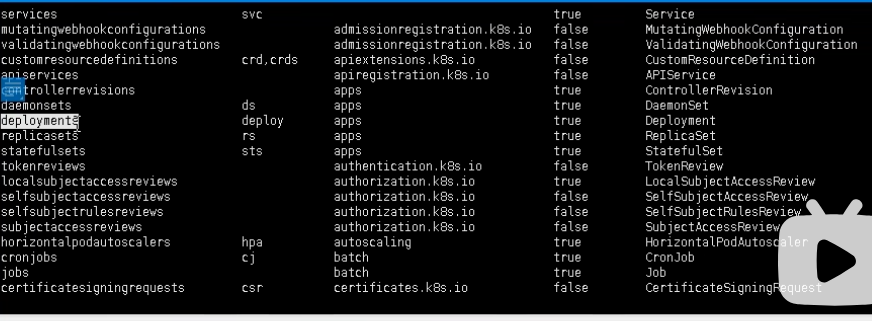
其中 deployments 用的比较多
快速编写 yaml 文件
- 使用 Kubectl create 命令生成 yaml 文件
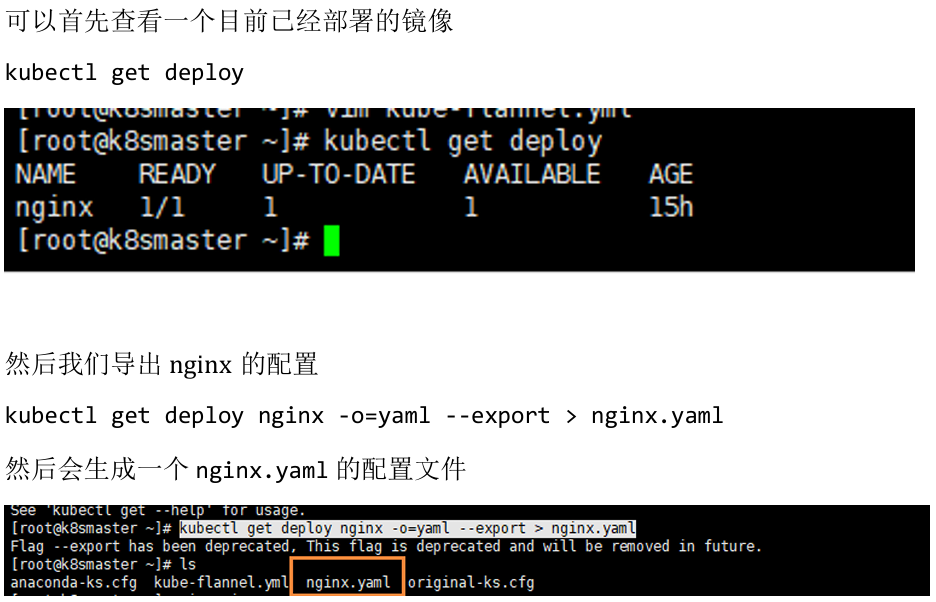
kubectl create deployment test-k8s --image=suse12sp5x86 -o yaml --dry-run -n fd - 对于部署的资源,使用 kubectl get 导出 yaml 文件
k8s Pod
pod 基本概念
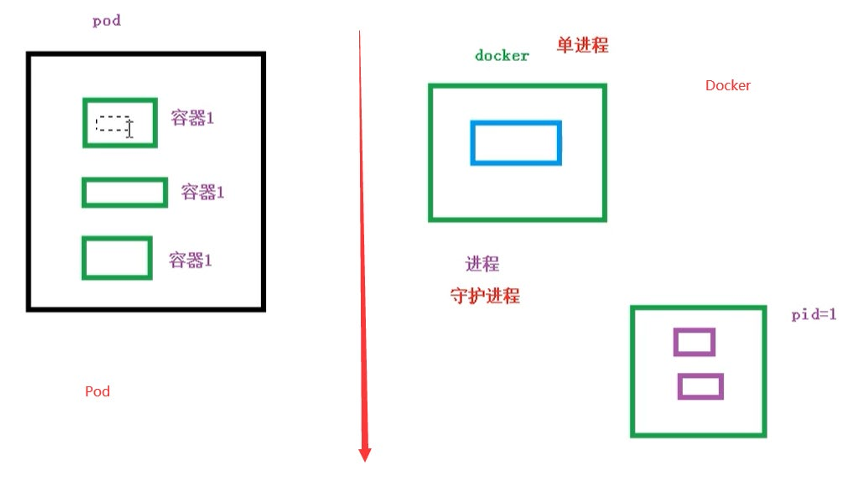
- Pod 是 k8s 中最小部署单元(不是容器)
- 包含多个容器(一组容器的集合)
- 一个 pod 中的容器 共享网络命名空间
- Pod 是短暂(如重启后 ip 不唯一等)
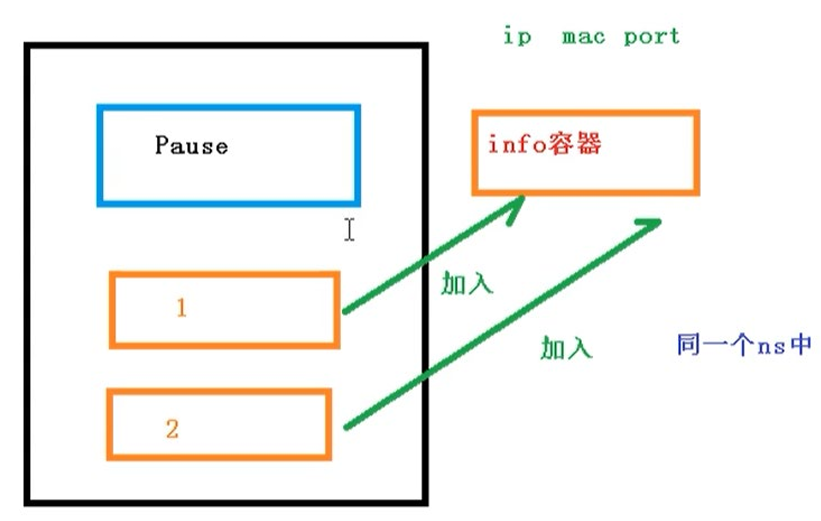
每一个Pod 都有一个特殊的被称为 “根容器”的 Pause 容器。Pause 容器对应的镜像属于Kubernetes 平台的一部分,除了Pause 容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
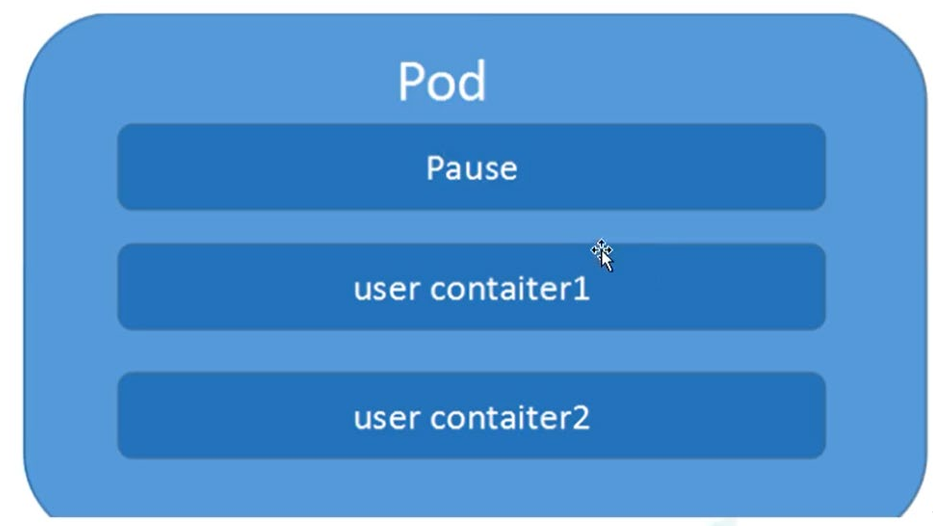
Pod 存在的意义
- 创建容器使用docker,一个docker对应一个容器,一个容器运行一个应用进程
- Pod是多进程设计,运用多个应用程序,也就是一个Pod里面有多个容器,而一个容器里面运行一个应用程序
Pod 实现机制
- 共享网络


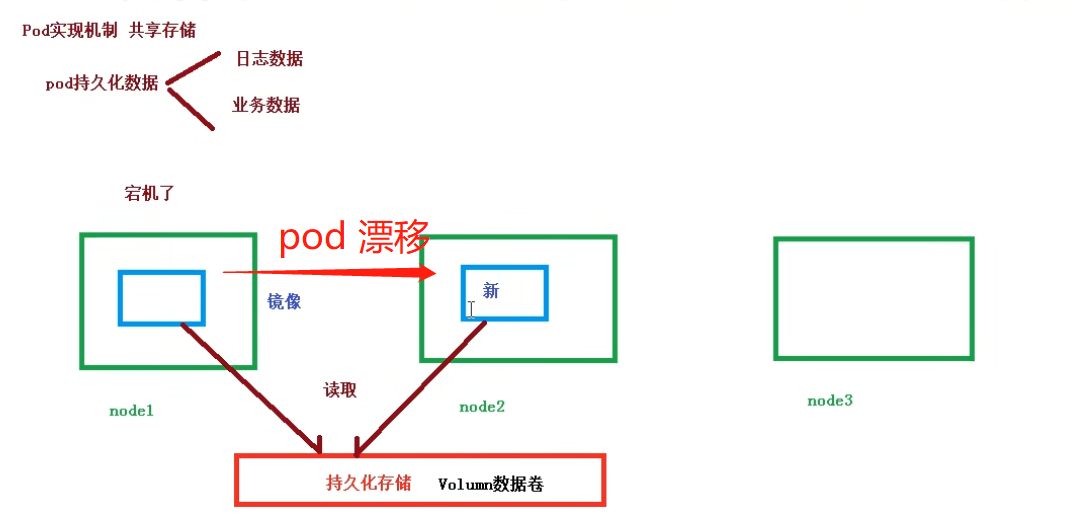
- 共享存储
当一个 node 中的 pod 宕机后,会飘到另一个 node(即在其他 node 中重新拉取该镜像),但业务数据、日志数据等 pod 持久化数据 等内容应该仍然不丢失,即新镜像创建后仍然能使用之前的业务数据、日志等内容;因此对 pod 持久化数据存储到 数据卷 volumn 中;
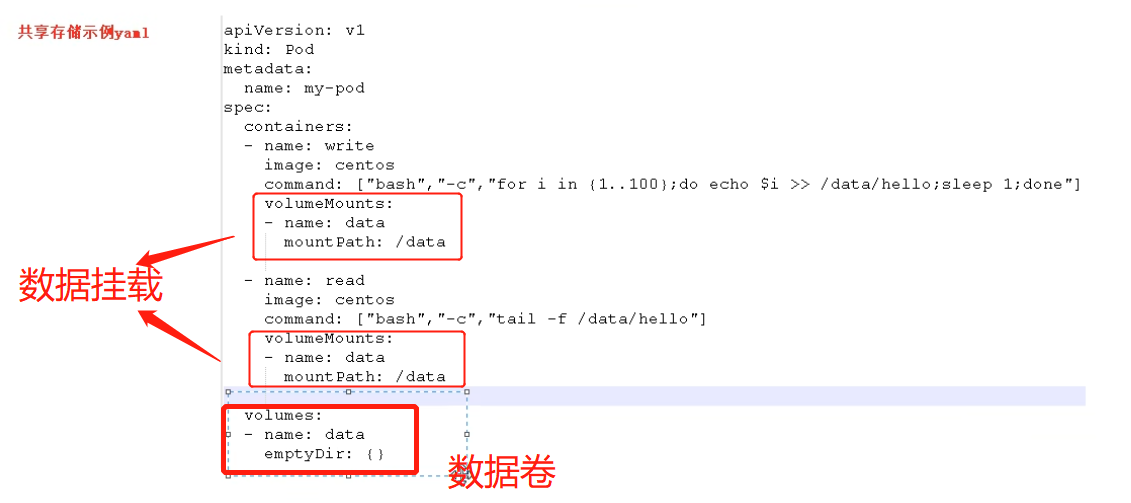
yaml 文件中配置如下:
Pod 镜像拉取策略

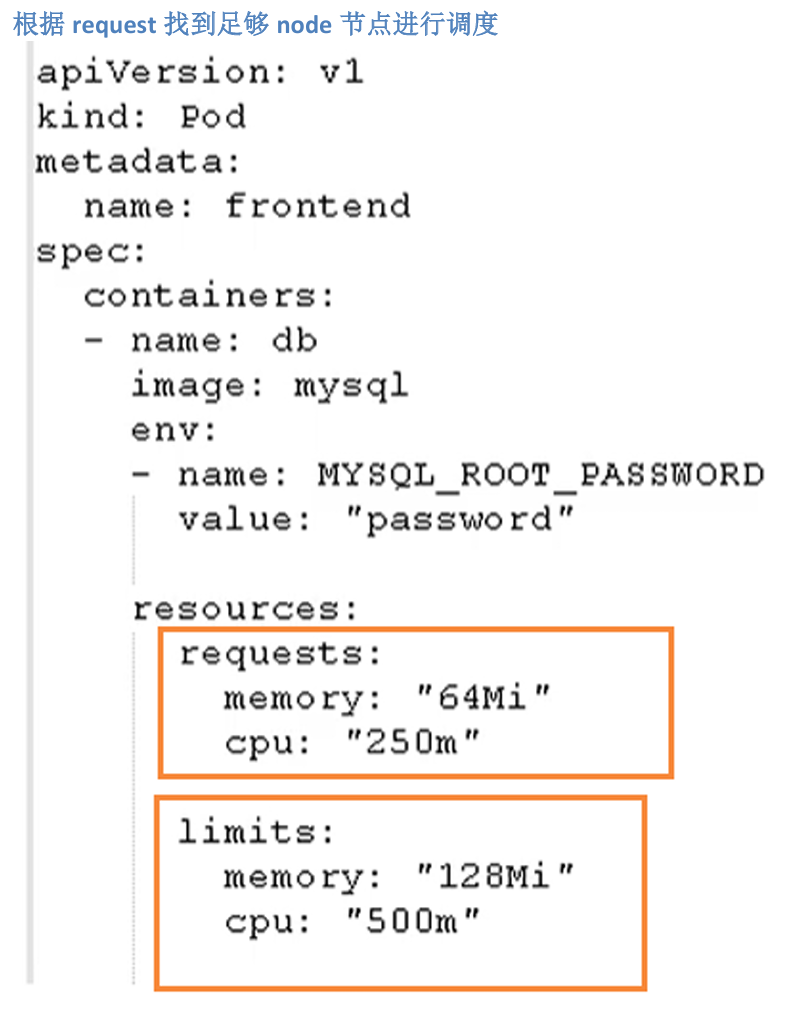
Pod 资源限制
Pod在进行调度的时候,可以对调度的资源进行限制,例如我们限制 Pod 调度是使用的资源是 2Core4G,那么在调度对应的node节点时,对于不满足资源的节点,将不会进行调度
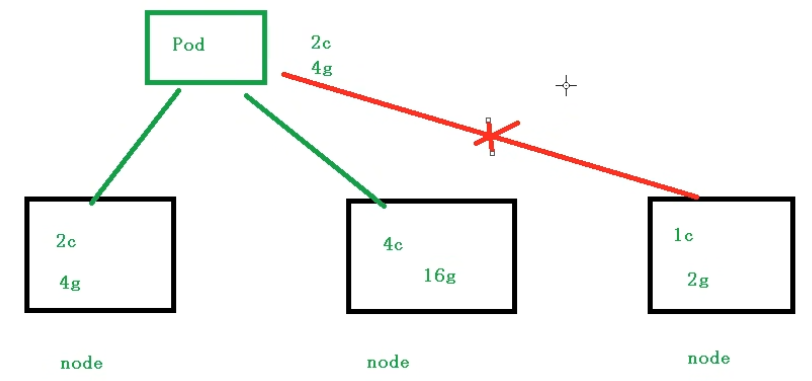
Pod 资源限制示例
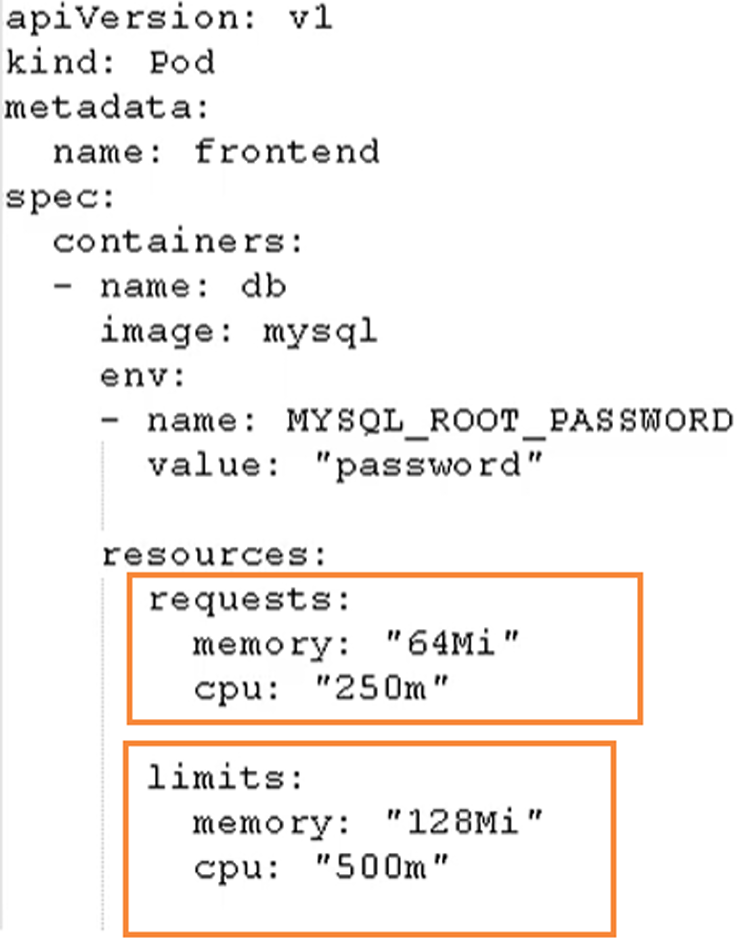
- request:表示调度所需的资源
- limits:表示最大所占用的资源
Pod 重启机制
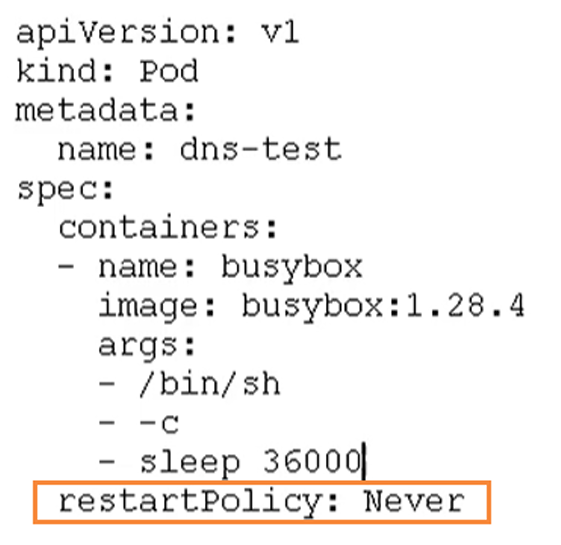
- Always:当容器终止退出后,总是重启容器,默认策略 【nginx等,需要不断
提供服务】 - OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。
- Never:当容器终止退出,从不重启容器
Pod 健康检查
使用kubectl get pod可以检查 pod 状态,但:

Probe 支持以下三种检查方式:
- http Get:发送HTTP 请求,返回200 - 400 范围状态码为成功
- exec:执行Shell 命令返回状态码是0为成功
- tcpSocket:发起TCP Socket 建立成功
配置示例:
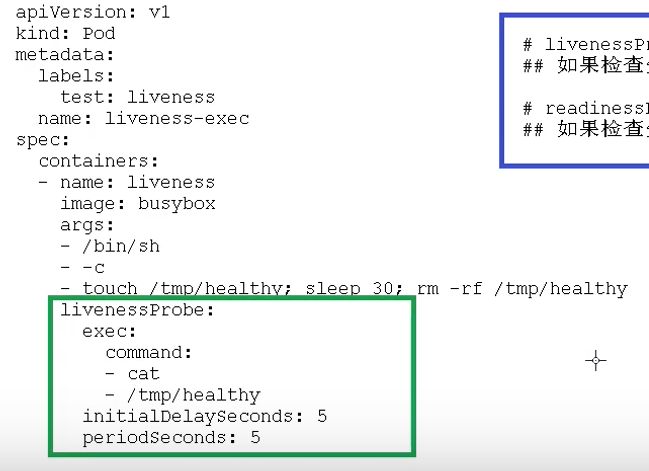
上图配置了一个 livenessProbe 检查,容器 liveness 创建时会首先执行touch命令创建/tmp/healthy文件,30 s 后删除该文件;
livenessProbe 检查使用 exec 检查方法,不断执行cat /tmp/healthy命令,并判断该命令的返回状态码是否为0;当容器内/tmp/healthy文件存在时,cat命令返回 0;当容器内/tmp/healthy文件被删除时,cat命令返回 1;此时 livenessProbe 会检测到,将杀死容器,然后根据 Pod 的 restartPolicy 来操作;
Pod 调度策略
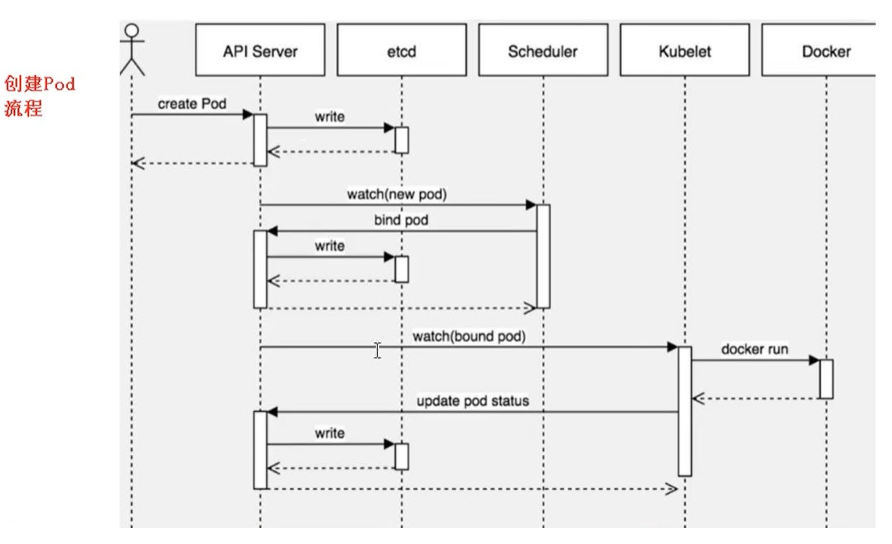
创建 Pod 流程
master 节点:
- 在 API Server 创建一个新的 Pod,之后将 Pod 信息写入 etcd 中;
- Scheduler 实时监控 API Server,当发现新的 Pod 创建后,会通过 API Server 到 etcd 上获取 Pod 信息,并通过调度算法在某一 node 上创建该 Pod,并把最终结果返回给 API Server,并存储到 etcd 中
node 节点:
- 通过 kubelet 到 API Server 上获取需要在该 node 上创建的 Pod 的信息,通过 docker run 创建 Pod,并将创建结果返回给 API Server,存储到 etcd 中;
影响 Pod 调度
-
Pod 资源限制对 Pod 调度产生影响,如
-
节点选择器标签影响 Pod 调度
根据节点的标签不同进行调度:

如不同的 node 上有不同的标签,可以使用 nodeSelector 来选择具有某一标签的 node 上进行调度:
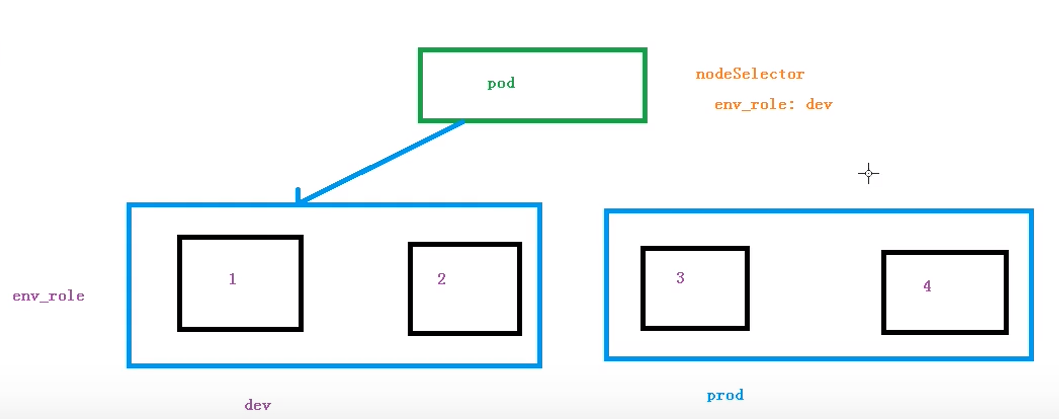
对某一 node 创建标签使用:
kubectl label node k8snode1 env_role=dev
查看 node 上的标签:
kubectl get nodes k8snode1 --show-labels

-
节点亲和性 nodeAffinity 影响节点调度
节点亲和性 nodeAffinity 和 之前nodeSelector 基本一样,根据节点上标签约束来决定Pod调度到哪些节点上- 硬亲和性:约束条件必须满足
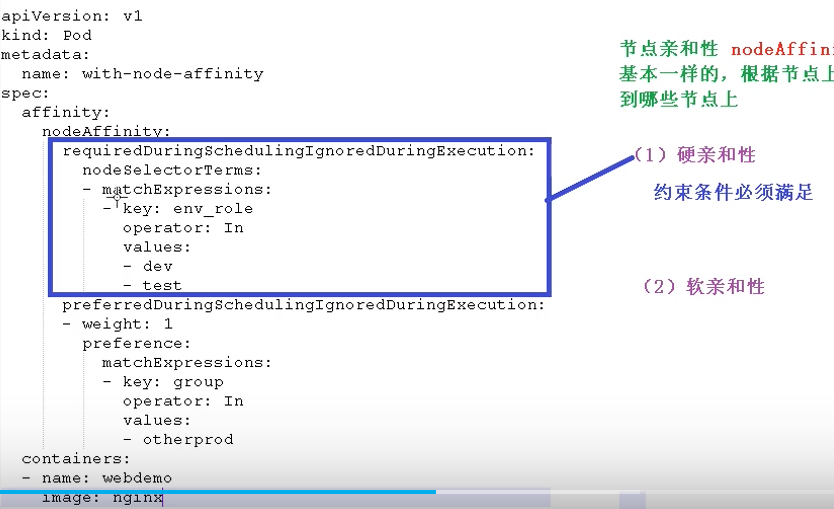
上图requireDuringSchedulingIgnoreDuringExecution表示硬亲和性,表示只选择标签env_role为dev和test的节点进行调度,operator: In表示值在...之中;若没有env_role为dev或test的节点,则一直等待; - 软亲和性:
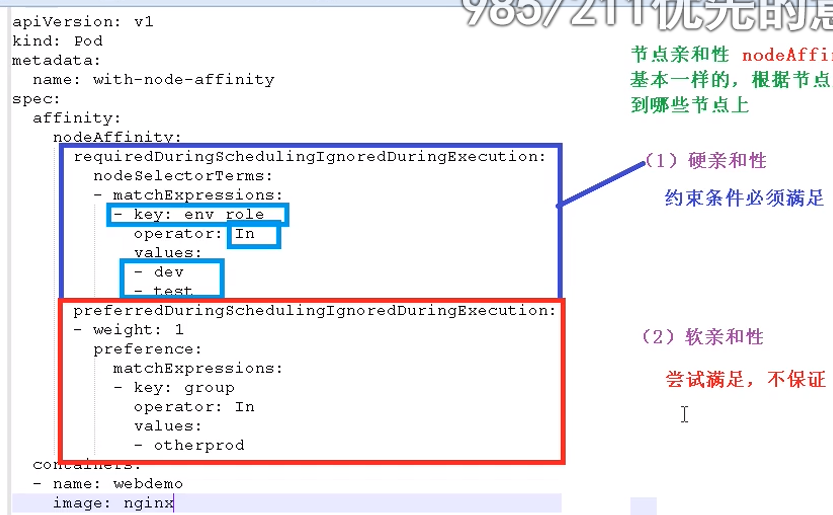
preferredDuringSchedulingIgnoreDuringExecution表示软亲和性,优先选择group标签值为otherprod中的节点进行调度
支持常用操作符:In、NotIn、Exists、Gt、Lt、DoesNotExists
- 硬亲和性:约束条件必须满足
-
污点和污点容忍 影响 Pod 调度
nodeSelector 和 NodeAffinity,都是 Prod 调度到某些节点上,属于Pod 的属性,是在调度的时候实现的。
Taint 污点:节点不做普通分配调度,是节点属性
应用场景:- 专用节点【限制ip】
- 配置特定硬件的节点【固态硬盘】
- 基于Taint驱逐【在node1不放,在node2放】
查看污点情况:
kubectl describe node k8smaster | grep Taint

污点值有三个:- NoSchedule:为某个节点设置后,该节点一定不被调度
- PreferNoSchedule:尽量不被调度【也有被调度的几率】
- NoExecute:不会调度,并且还会驱逐Node已有Pod
为某一节点添加污点:
kubectl taint node [nodename] key=value:污点值
如:
kubectl taint node k8snode1 env_role=yes:NoSchedule
删除污点:
kubectl taint node k8snode1 env_role:NoSchedule-实战举例:
我们现在创建多个Pod,查看最后分配到Node上的情况
首先我们创建一个 nginx 的pod
kubectl create deployment web --image=nginx
然后使用命令查看
kubectl get pods -o wide

我们可以非常明显的看到,这个Pod已经被分配到 k8snode1 节点上了
下面我们把pod复制5份,在查看情况pod情况
kubectl scale deployment web --replicas=5
我们可以发现,所以节点都被分配到了 node1 和 node2 节点上

我们可以使用下面命令,把刚刚我们创建的pod都删除
kubectl delete deployment web
现在给了更好的演示污点的用法,我们现在给 node1节点打上污点
kubectl taint node k8snode1 env_role=yes:NoSchedule
然后我们查看污点是否成功添加
kubectl describe node k8snode1 | grep Taint

然后我们在创建一个 pod 并复制 5 次
kubectl create deployment web --image=nginx
kubectl scale deployment web --replicas=5
然后我们在进行查看
kubectl get pods -o wide
我们能够看到现在所有的pod都被分配到了 k8snode2上,因为刚刚我们给node1
节点设置了污点

最后我们可以删除刚刚添加的污点
kubectl taint node k8snode1 env_role:NoSchedule-污点容忍:
示例配置如下:

其中key和values是设置污点是的key和value;这样设置后,具有污点的 node 可能会被调度,也可能不会被调度
k8s-Controller(Deployment)
概述和应用场景
什么是 controller:

controller 是在集群上管理和运行容器的对象
Pod 和 Controller 关系:
Pod 通过 Controller 实现应用的运维,如伸缩、滚动升级等
Pod 和 Controller 之间通过 label 标签建立关系:
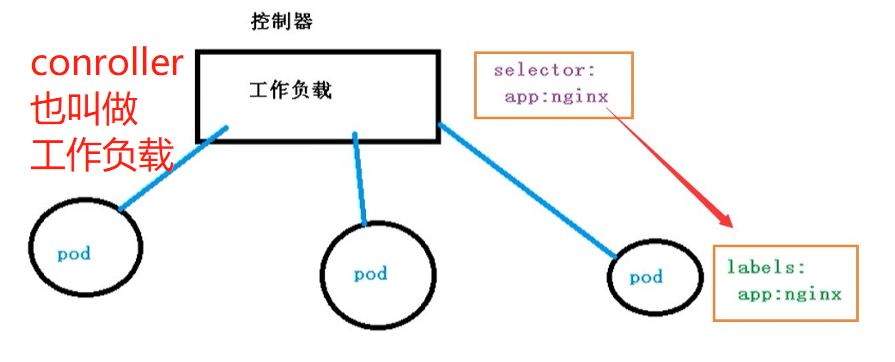
deployment 应用场景
- 部署无状态应用:web 服务,微服务
- 管理 Pod 和 ReplicaSet (副本数量)
- 部署,滚动升级等功能
通过 deployment 部署应用
kubectrl create deployment web --image=nginx
上述命令可以部署,但不能复用,因此采用 yaml 文件进行配置:
先创建 yaml 文件:
kubectl create deployment web --image=nginx --dry-run -o yaml > nginx.yaml
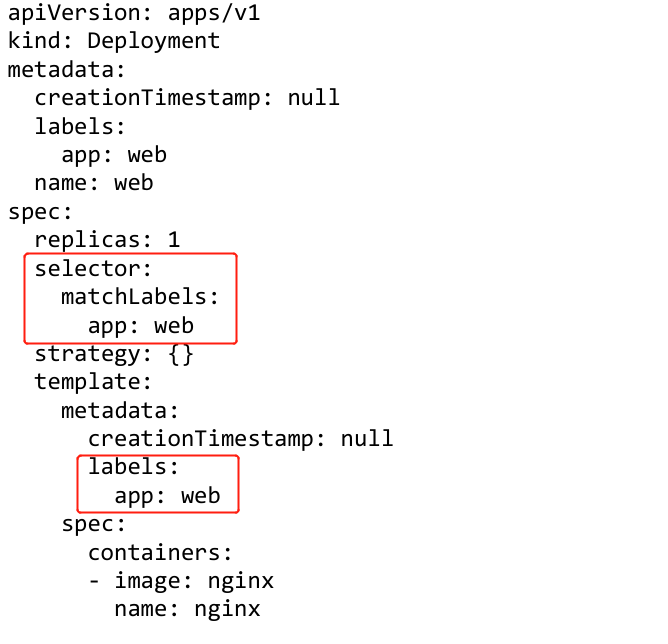
yaml 文件中,selector 和 label 就是我们Pod 和 Controller 之间建立关系的桥梁
使用kubectl apply -f nginx.yaml创建 pod
应用发布:
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web1

同理,我们一样可以导出对应的配置文件,然后用配置文件发布:
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web1 -o yaml > web1.yaml
查看对外暴漏的服务:
kubectl get pods,svc
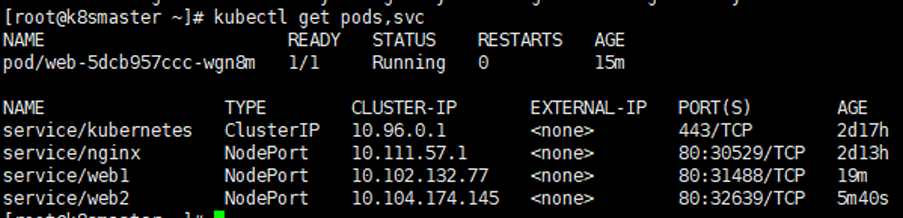
访问对应的url即可:nginx了http://192.168.177.130:32639/
应用升级回滚和弹性伸缩
见 pdf
