

python基础:数据分析_Pandas
参考视频:
https://www.bilibili.com/video/BV1HJ411j7NG?p=2
一、Pandas基础操作

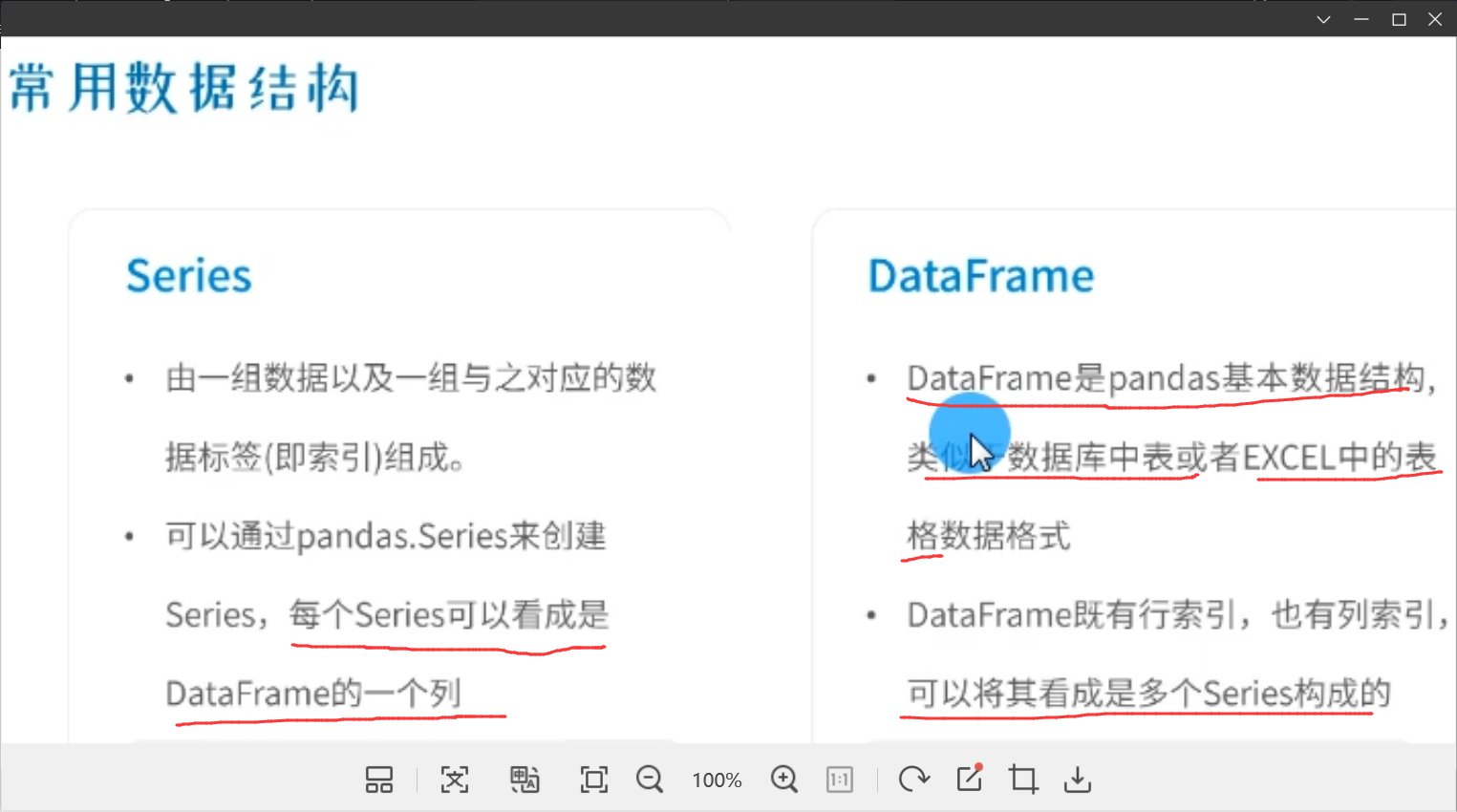
▲:Pandas常用数据结构
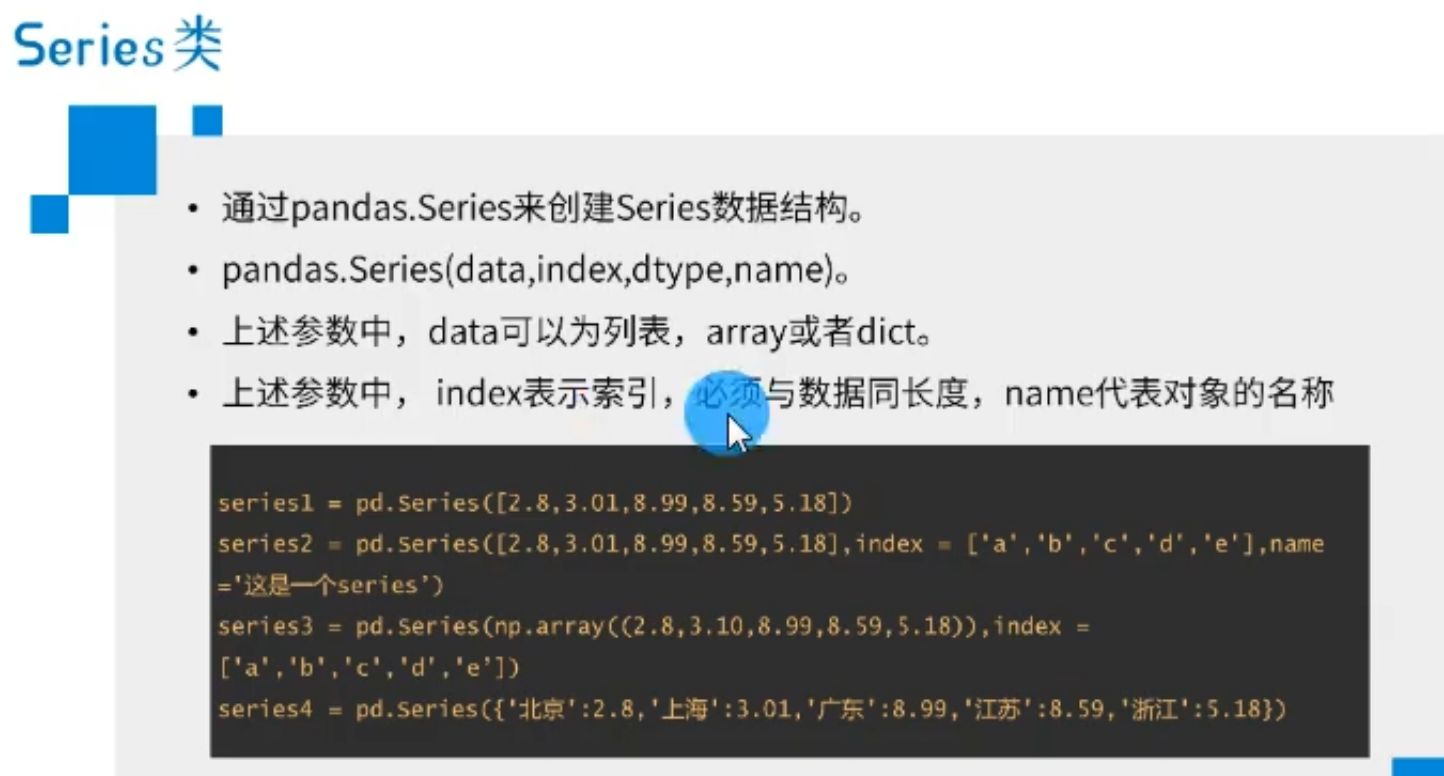
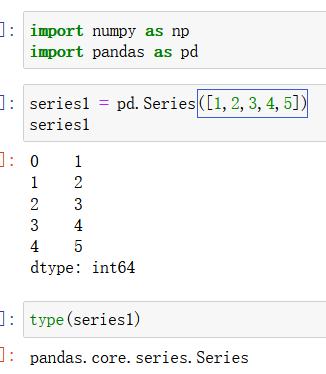
1)Series创建
使用 pd.Series() 函数来创建一个Series对象,括号中的参数通常为一个列表、字典、数组等:
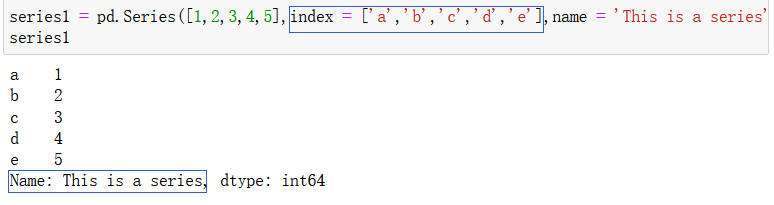
也可以自己对 series 对象配置索引:
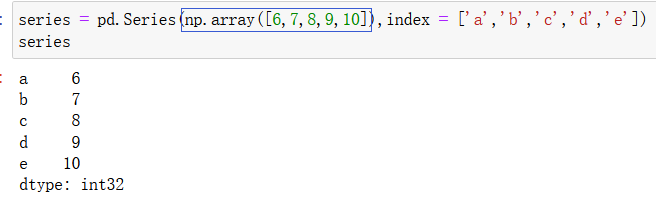
参数为一个数组:
参数为一个字典:
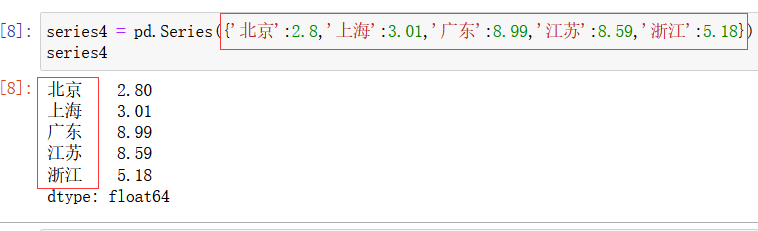
如上图所示,此时,字典的键就是series对象的索引。
2)Series的常用属性及方法

series.values : 返回Series对象所有元素

Series.index : 返回索引

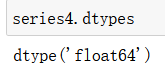
Series.dtypes : 返回数据类型
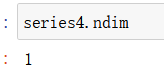
Series.ndim : 返回对象维度
Series.size : 返回对象中元素个数
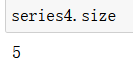
Series对象还可以根据切片、索引来访问
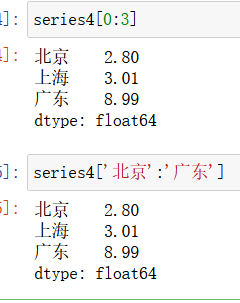
注意上图中,当使用标签索引来访问Series对象时,不再是左闭右开的访问了。
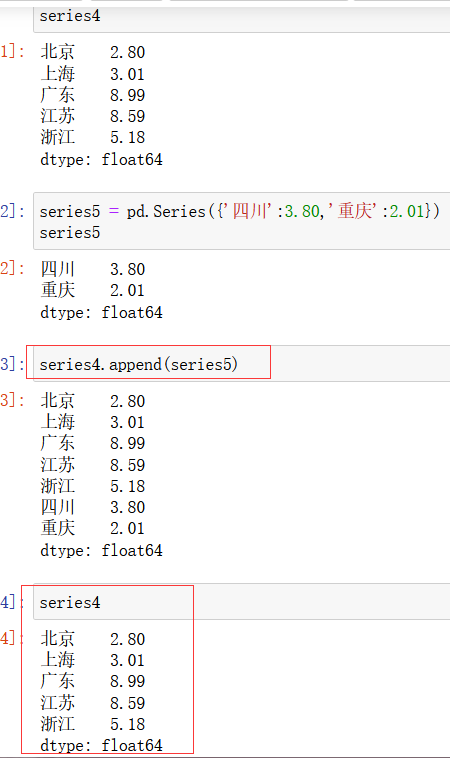
Series.append(a) 函数:用来返回一个添加了a对象之后的series对象,但注意,使用 append() 函数并不会改变series对象,只是返回一个新的对象。
Series.drop() :用来删除series对象中的元素,返回一个视图,但是不会修改原对象;但是如果加上 inplace = True 参数,就可以对原对象进行修改。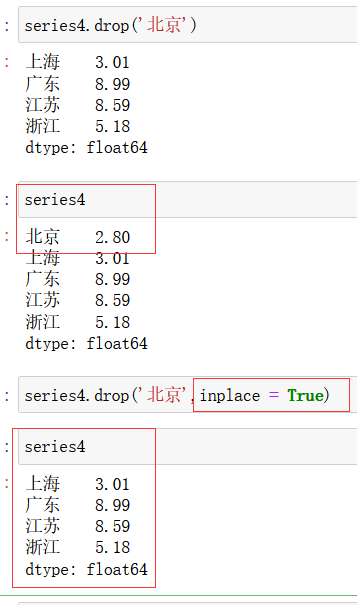

3)DataFrame类对象的创建
我们可以将series看做是一个dataframe的一列,或者说dataframe就是由series构成。
创建DataFrame对象时,里面的数据参数可以是列表、字典或数组。index 代表每一行的索引的名字,columns 参数代表列的名字:
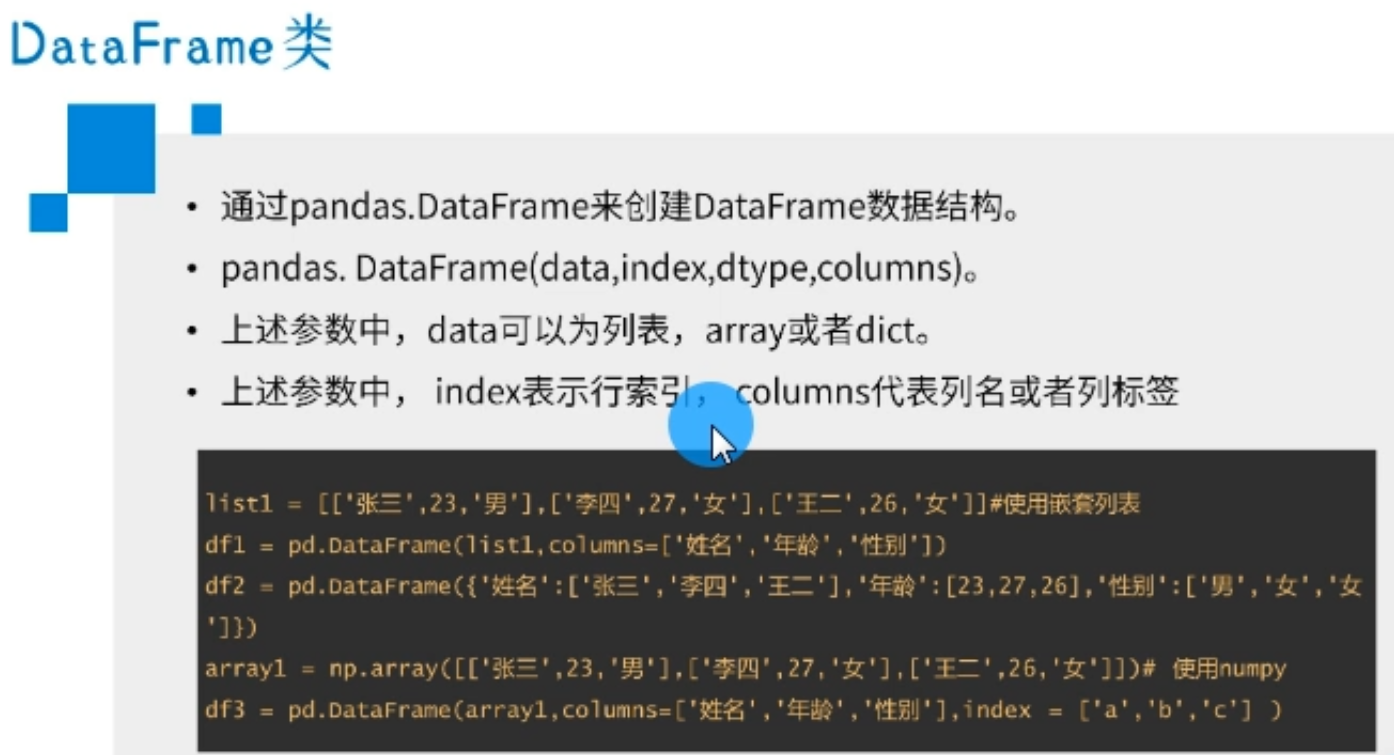
使用列表作为数据参数创建DataFrame对象:
使用字典作为数据对象来创建DataFrame对象:
字典的键名就是df对象的列的名字,即 columns 的值。

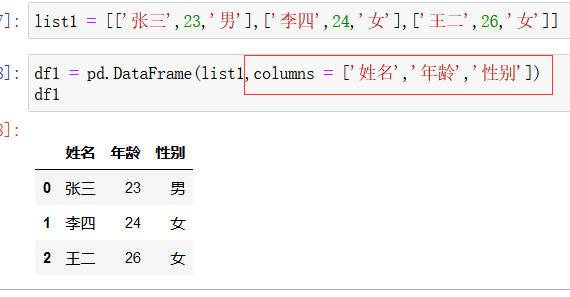
使用数组结构来创建DataFrame对象:
如下图所示,可以使用 index 来修改每一行的索引的名字:
4)DataFrame的常用属性

df.values:将数据集以数组的形式输出:


▲数据的获取和保存:
虽然我们学习了通过numpy获取外部数据,但是我们还是常用pandas做数据分析,因为pandas读取出来的结构是数据框格式(即 dataframe的格式),非常类似于数据库中的表结构,非常有利于我们以后的分析。
开始之前先将 os库也导入,它可以用来查看当前路径等等,并可以设置python当前默认路径。
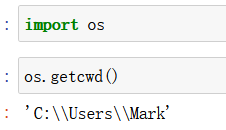
假如我们需要读取的数据都在 C:\\Users\\Mark 中,可以将python默认路径改为:
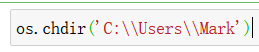
这样我们读取数据时,写路径就不需要再 加上 C:\\Users\\Mark 了
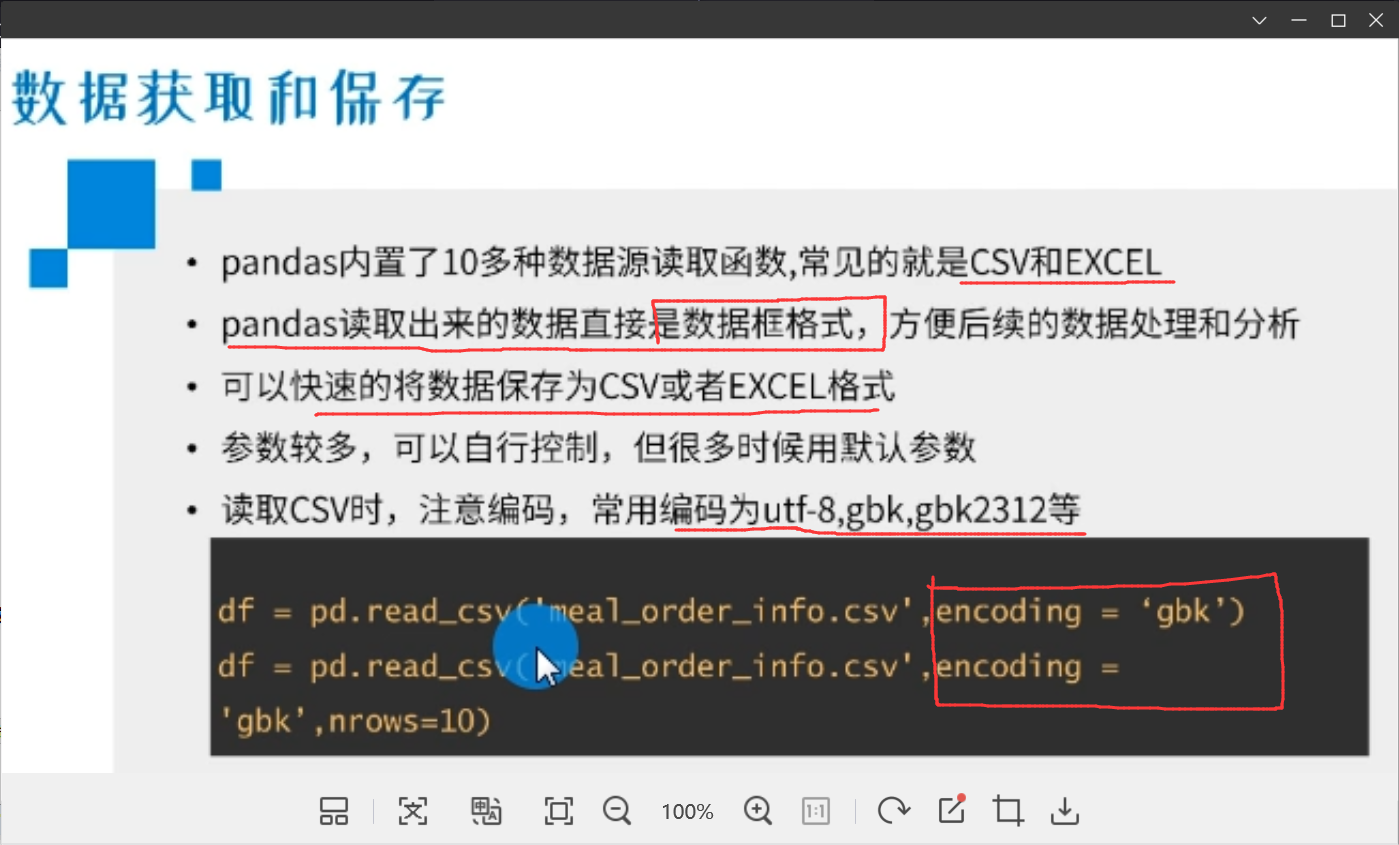
1)读取csv数据:使用 df = pd.read_csv() 函数(注意,读取出来的格式是数据框 dataframe 格式的数据,所以将读取出来的数据复制给 df对象)
假如桌面上有:
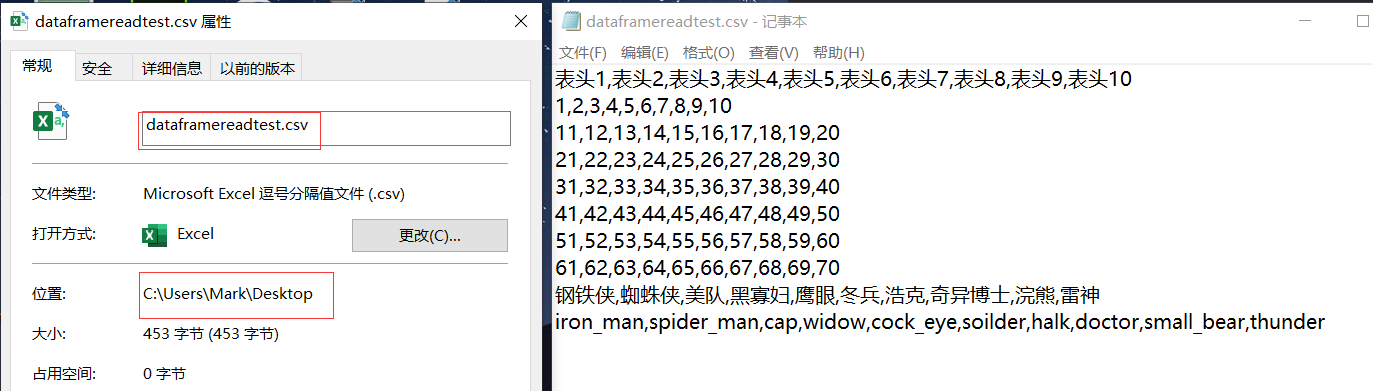
使用:
pd.read_csv() 函数来读取csv数据:

使用 df.head(5) 来查看前5行数据
df.tail(5)来查看后5行数据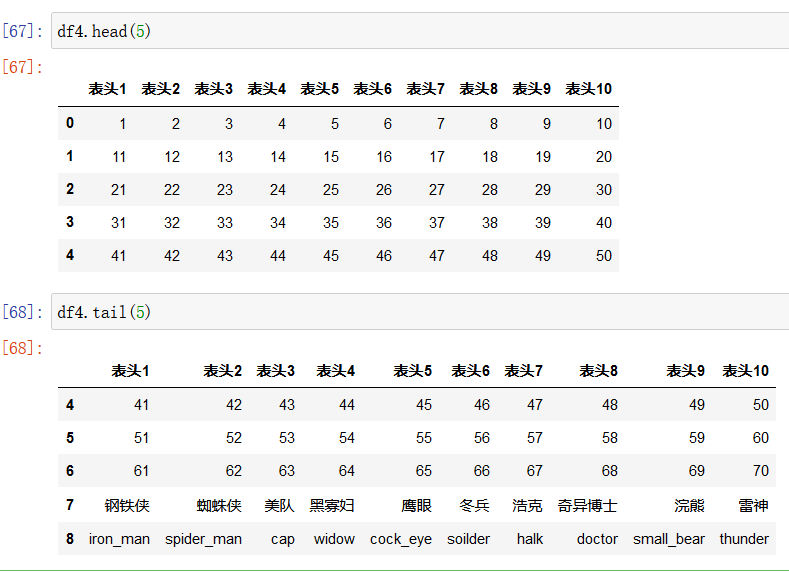
df.types
输出每一变量的类型

还可以在 pd.read_csv() 函数 使用参数 dtype (注意不加s)来改变每一列(每一个series)的类型:

还可以在 pd.read_csv() 函数 使用参数 nrows = 5 来只读取数据的前5行:
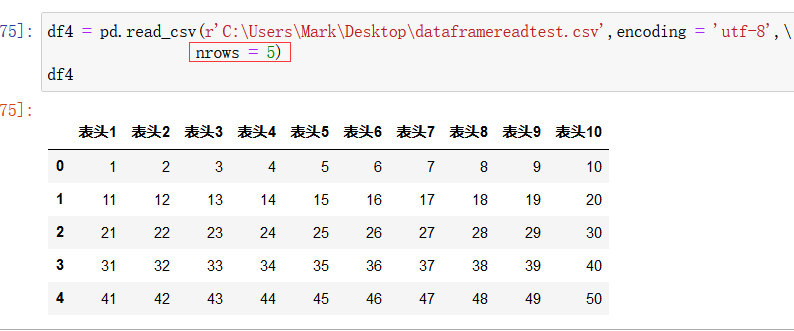
pd.read_csv() 函数读取时默认的 delimiter 分隔符为英文的 逗号,
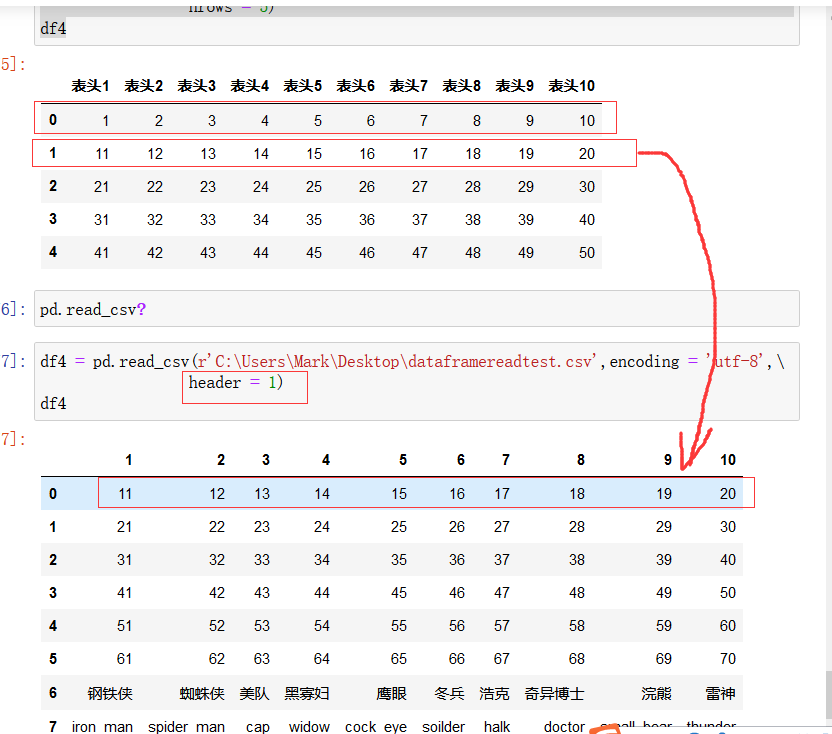
pd.read_csv() 函数的参数 header = 1 表示想从第一行开始读取,即将第一行作为表头:
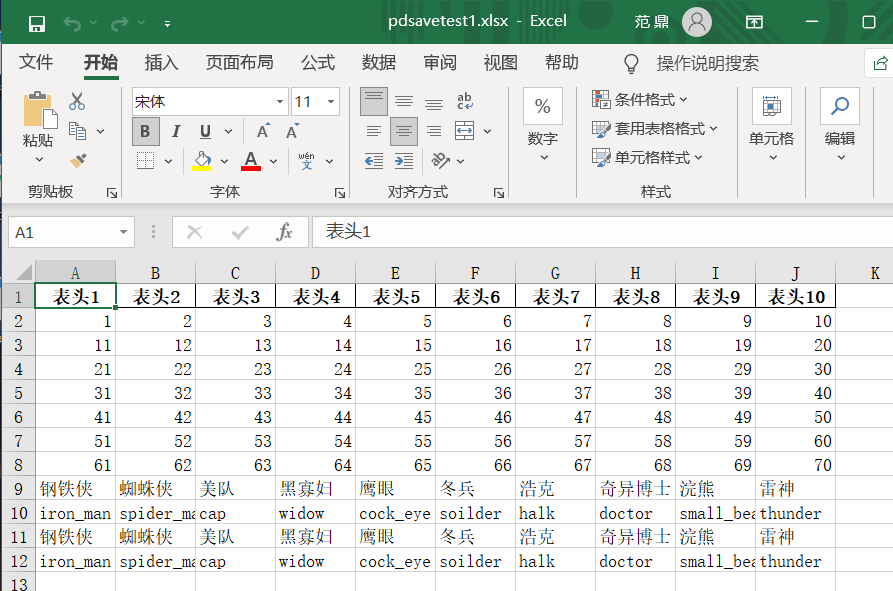
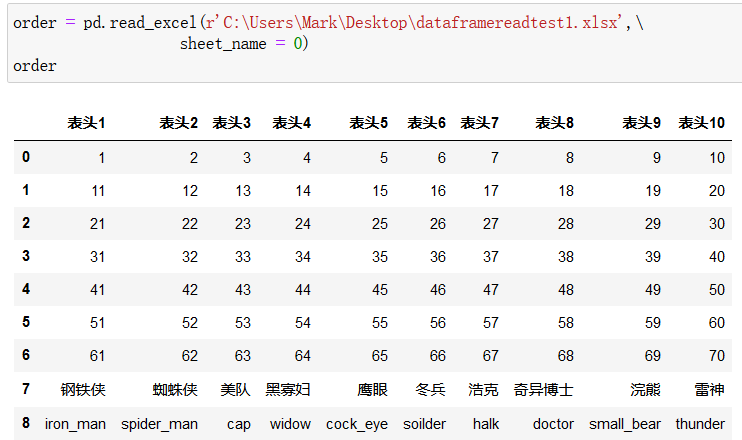
2)读取excel数据:使用 df = pd.read_excel() 函数
假如桌面上有:
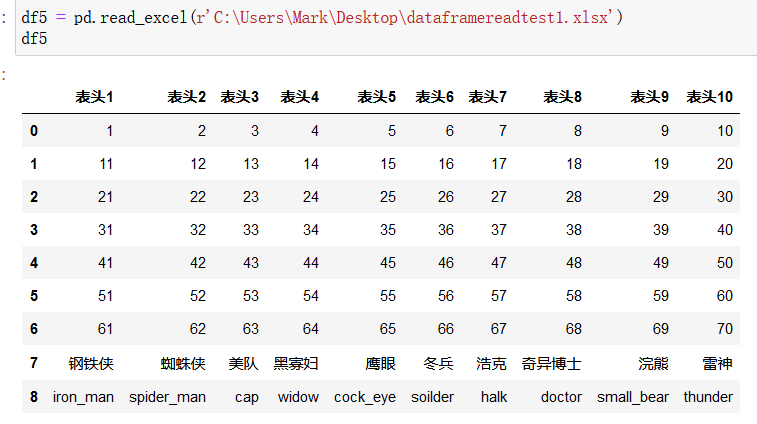
使用 pd.read_excel() 函数来读取excel:
注意,pd.read_excel() 函数的参数与 pd.read_csv() 函数的参数基本相同,但最新版的pandas的 pd.read_excel() 函数不支持 encoding 参数,直接读取就可以了。
此外,pd.read_excel() 函数中还增加了一个 sheet_name 参数,指读取excel的哪一页,也可以不用工作页的名字,用0代表第一页,1代表第二页等:
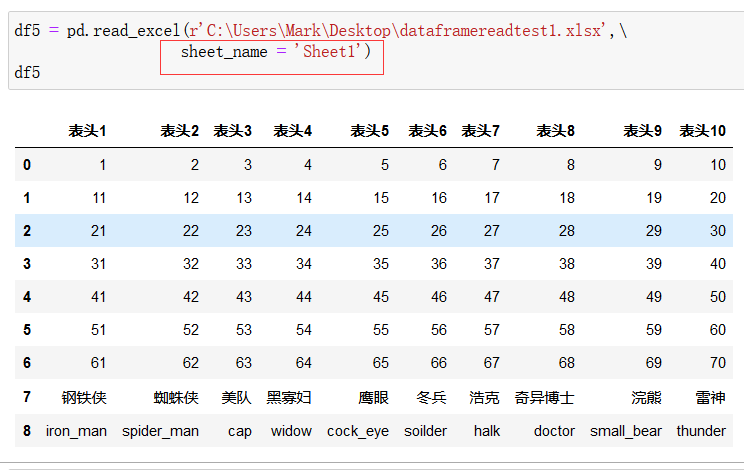
如果想同时读取两页,只需:
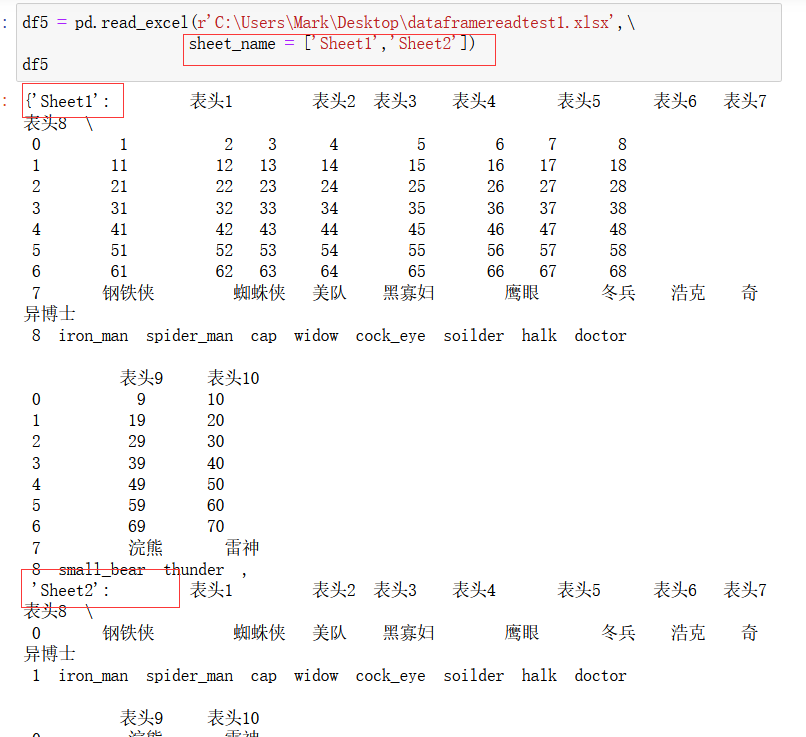
那么如何将两个工作页读取到一个大的数据框中呢?
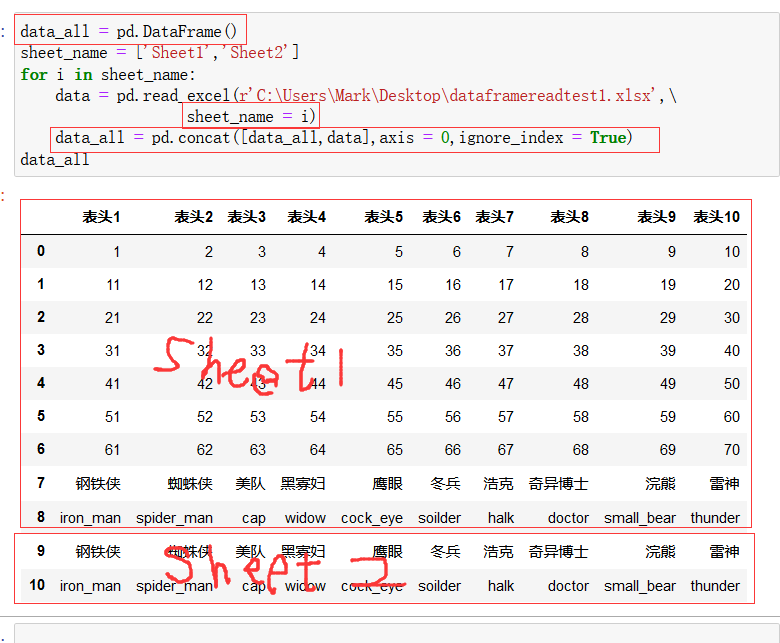
上图中,pd.concat()是拼接函数,拼接的结果需要放在一个新的df对象data_all中,循环每执行一次,就访问excel中的一页,就将data_all(全局变量) 与在excel 新页中读取到的数据data(局部变量,每读取一次都会覆盖上一次的读取结果)进行拼接,实现读取全部页数据。ignore_index = True 参数表示将左边的索引号按顺序写下去,如果不加该参数就会如下图所示:
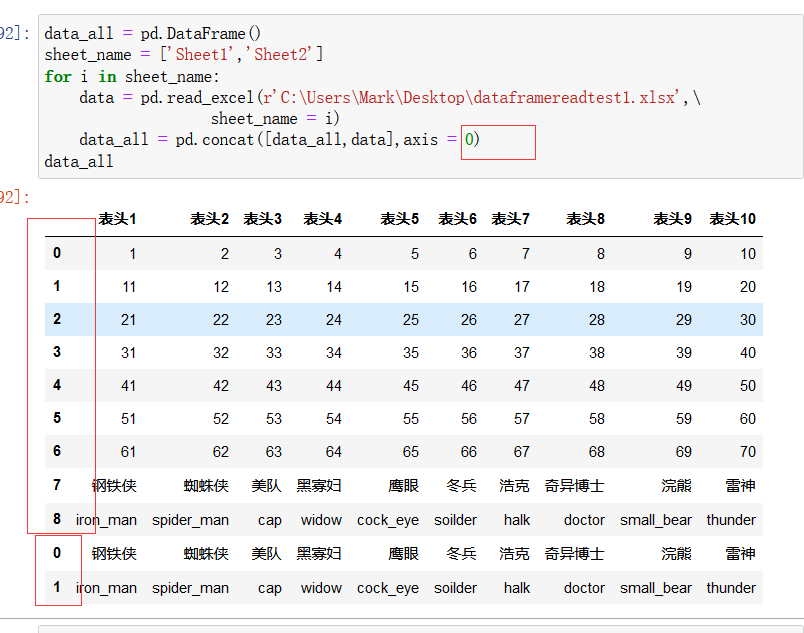
3)将读取的数据框保存:
我们使用 df.to_csv() 函数来保存数据框为 csv 文件。一般加上一个参数 index = False ,表示不将数据框的索引也保存进数据, 如果不加该参数,数据的最前面一列就会保存上列索引。

如下图所示:
我们使用 df.to_excel() 函数来将数据框保存为 excel 文件:

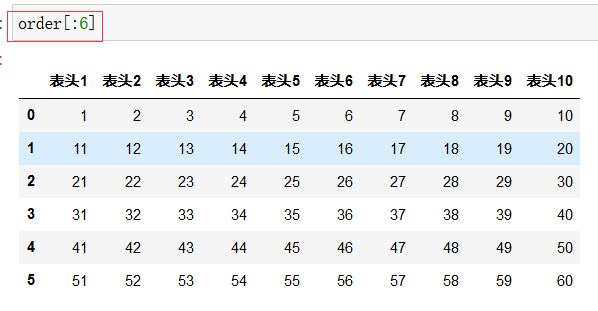
▲数据筛选

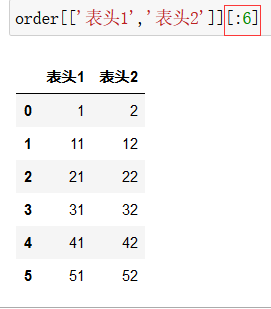
查看前6行可以用切片的方式:
df[:6]
假如想选择某一列(某一个series),可以有两种方法:
df.列名
df['列名']

如果想选择多列:
df[ ['列名1','列名2'] ]
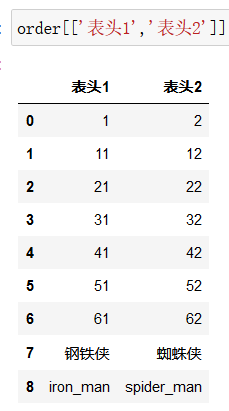
某些列的前几行:
loc [A,B]和 iloc [A,B]的用法:
单独取出某一(某些)行列:
loc函数用法中,里面的参数A,B都是行的标签名或者列的名字,而不是数字
iloc函数用法中,里面的参数都是行的标签名或者列的位置(数字),而不是名字
loc函数:
df.loc[:,'列名']
df.loc[:,['列名1',‘列名2’]]
(逗号前的冒号表示取所有行)

如果还需要限制行标签:
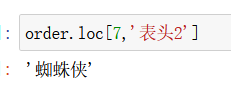
df.loc[行索引名,'列名']
df.loc[[行索引名1,行索引名2],['列名1',‘列名2’]]
注意,行索引名不需要加引号

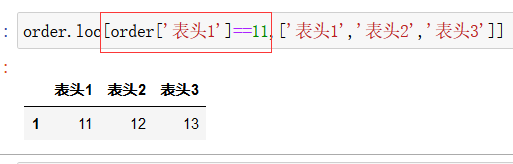
loc函数还可以进行条件查询:
iloc函数:
取2~4列:
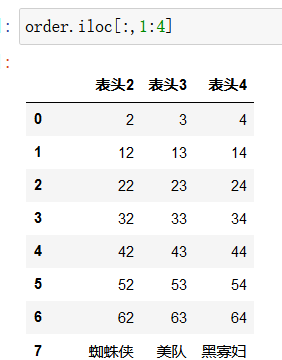
取2,5两列:
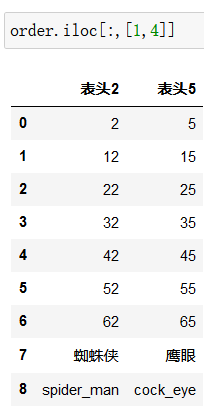
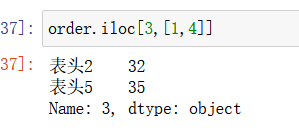
取第四行的第二和第五列:注意此时的前面的参数写的是索引而不是行索引名字,所以前面一个参数应该是3
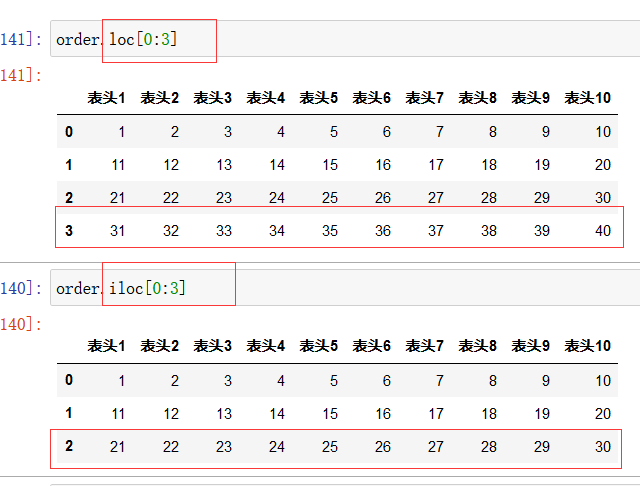
注意上图中的区别,因为loc参数是行索引的名字,所以取的是从索引名为0的行到索引名为3的行
而iloc函数中参数为索引值,所以取的第1行(行索引为0)到第3行(行索引为2)(因为python是左闭右开)
增删改查和条件查询:
条件查询,查询 表头1 该列内容为21的 那一行的数据:

在此基础上限定列:
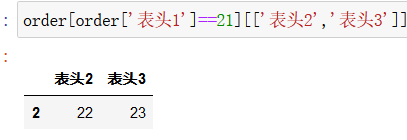
或者不将列的名字写成列表形式:

多个条件时,每个条件用括号括起来,并用 & 连接:

如果是表示 或 ,用符号 | 连接:
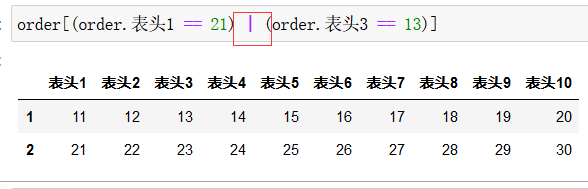
数据增加 列:
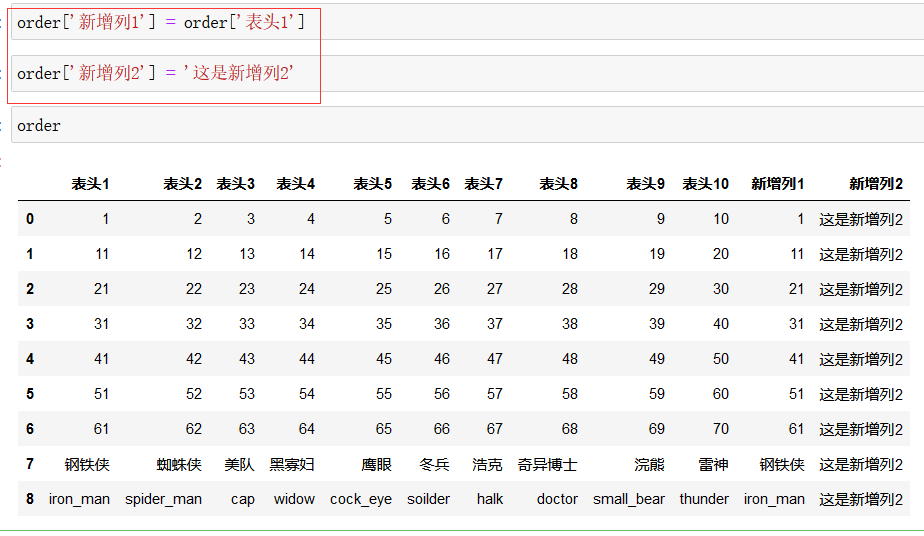
数据列删除
drop(),注意如果要删除列,drop()函数中参数 axis = 1 时是删除列,axis = 0时是删除行
因为axis = 0 时是按照行进行遍历,axis = 1 时是按照列的方向进行遍历
如删除新增列1:
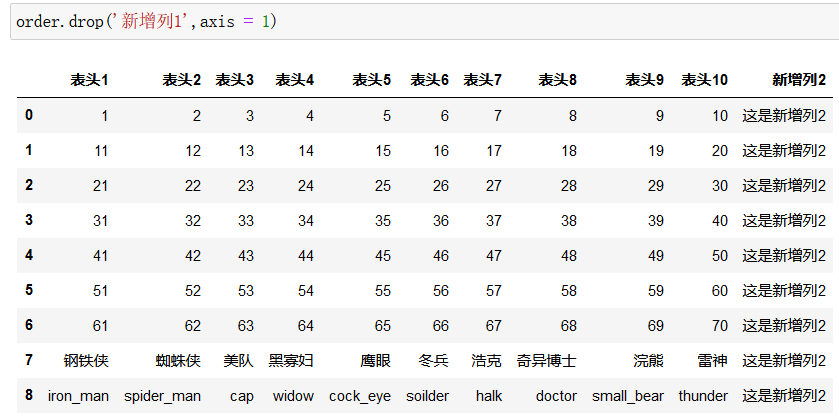
但是这种方式只是返回了一个 删除了 新增列1 的视图,原数据并未删除 新增列1,如果想要原数据也删除,需要增加参数 inplace = True
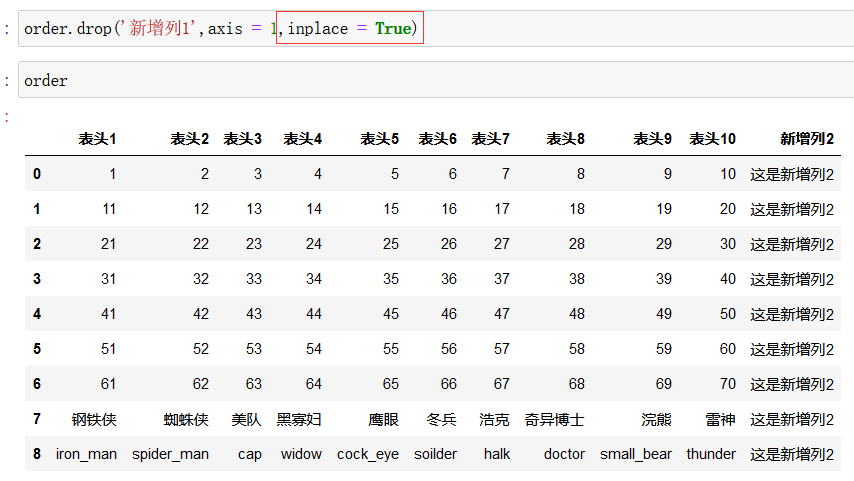
还有一种删除 是 del df['列名']
但是这种方式只能一列列删,此种方式会删除原数据中的列
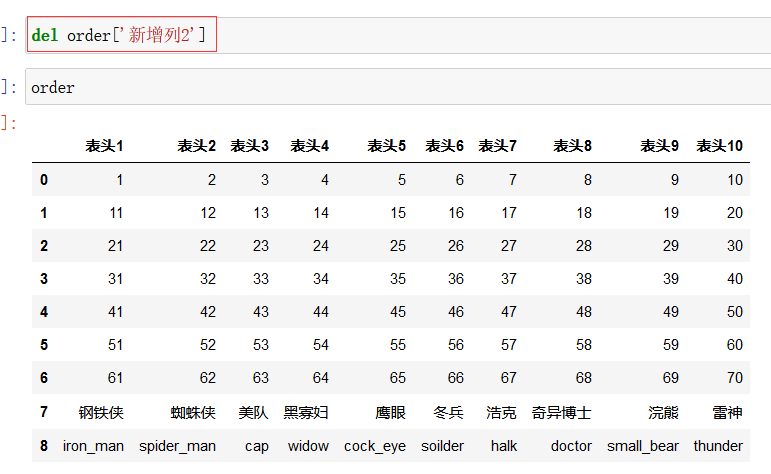
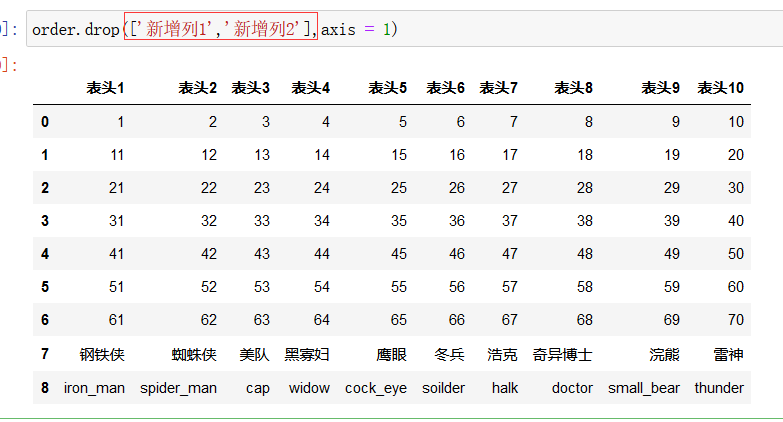
同时删除两列,就把要删除的多个列以列表的形式作为参数:
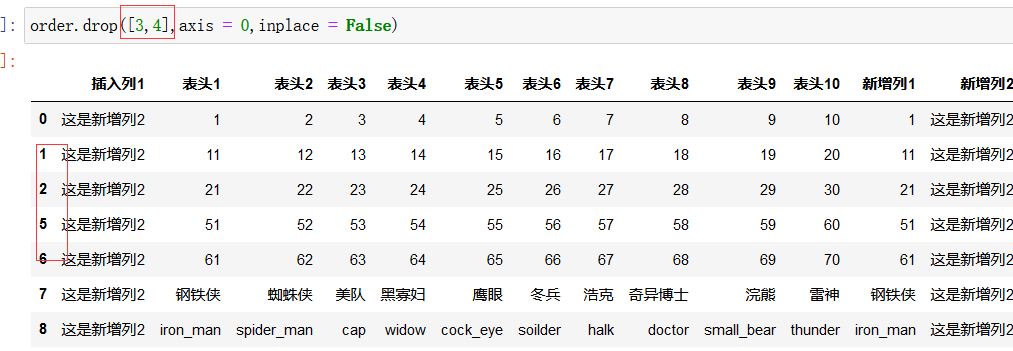
按行删除:
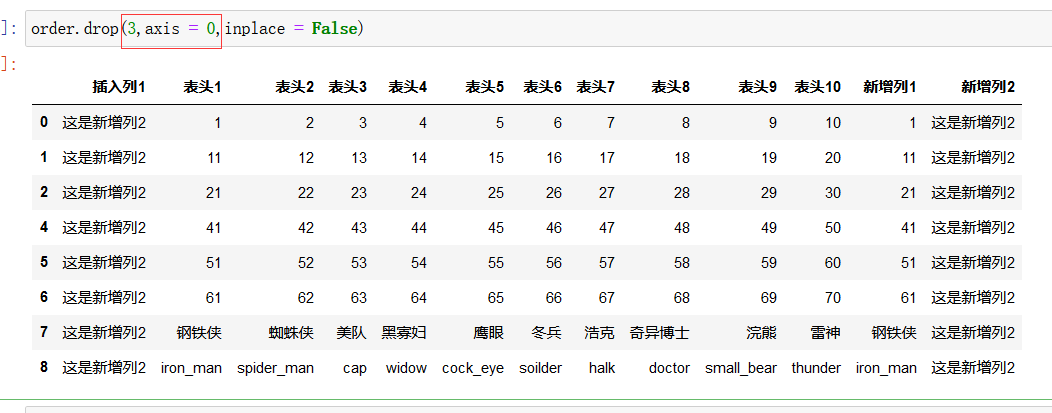
其中第一个参数是行标签的名字,而不是索引值, axis 一定要设定为0
删除多行:
插入:
df.insert() 函数
假如将新增列2 插入原数据的第一列:
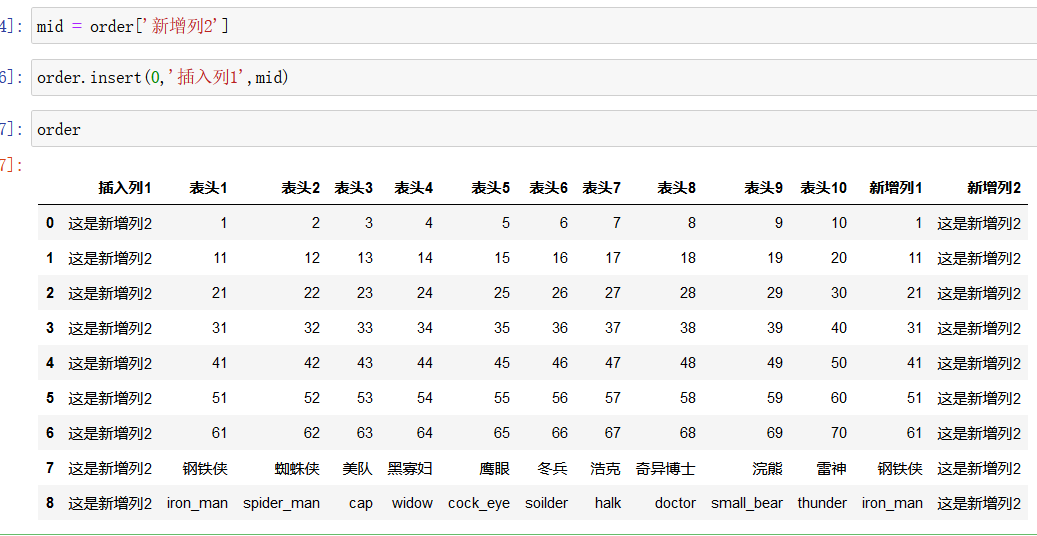
如上图所示,首先将要插入的 series对象赋值给 mid,然后使用 order.insert()函数
其中,order.insert(0,‘插入列1’,mid) 中, 0 表示要插入哪一列,‘插入列1’ 表示新插入的列的名字,mid 表示要插入的series
修改:
修改还是使用 loc和iloc函数,先找到列(行),然后再修改
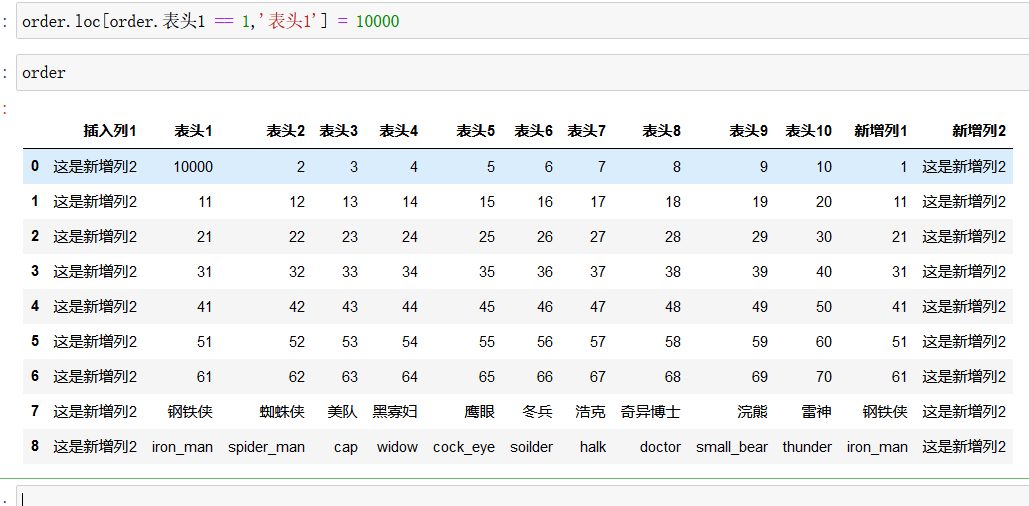
注意上图,因为是loc函数,索引使用 列的名字 或者 行索引的名字找到某一列(行),然后后面一个参数是要修改的哪一个位置,上图即先找到 表头1 = 1 所在的行,然后修改 表头1 的值为10000
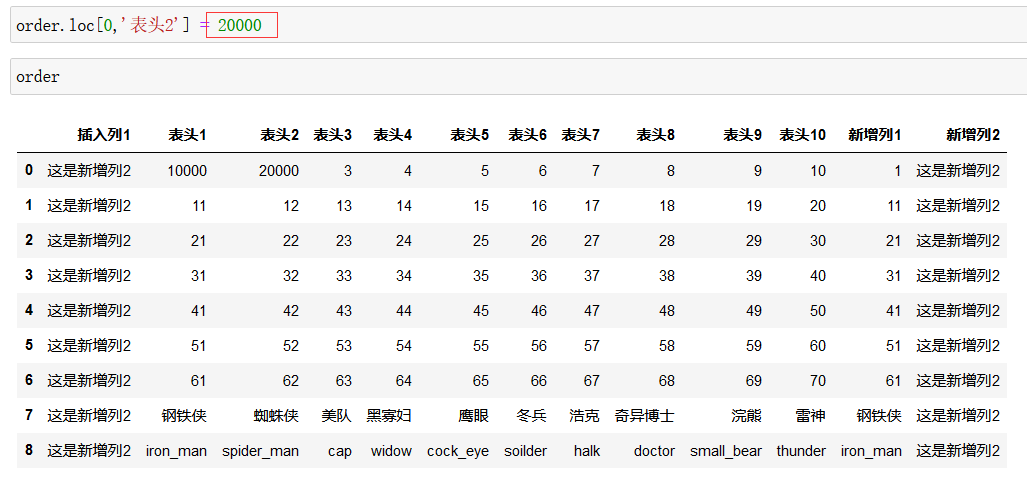
上图还是用loc函数进行修改,因此 0 代表行索引名字为0 的那一行,然后找到 表头2 这一列,将表头2 的值修改为20000
修改列名:
order.rename()
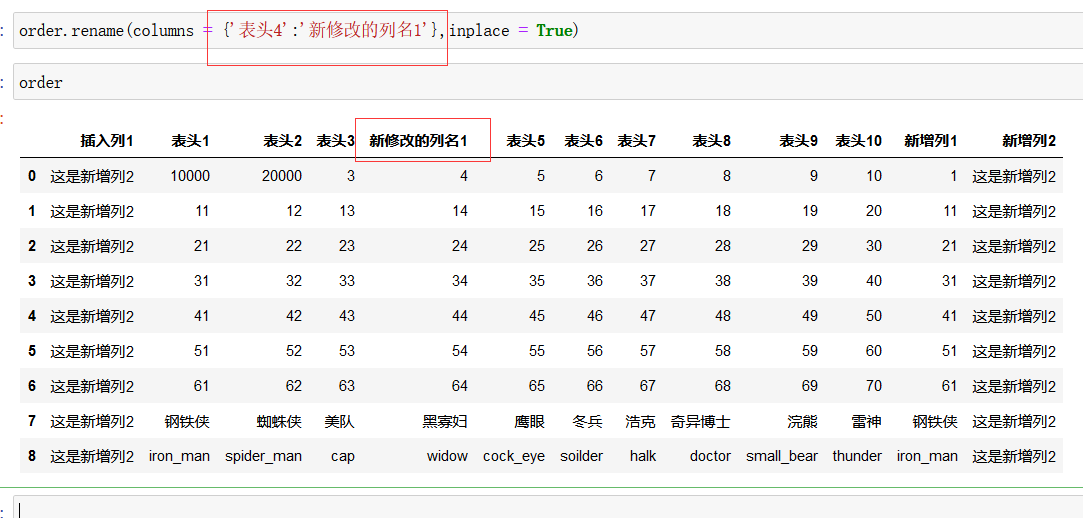
如上图所示,注意使用字典的符号 {} 来修改的
修改行索引的名字:

