python基础(一):函数、递归、字典、集合、文件系统、else语句和with语句、图形界面入门EasyGui、类和对象、魔法方法:构造和析构、算数运算(运算符重载)、类的属性访问、描述符、定制容器、迭代器和生成器、模块
以下内容参考:
https://www.bilibili.com/video/BV1Fs411A7HZ?p=20&spm_id_from=pageDriver
十三、函数
python中用关键字 def 来创建函数。

函数的参数:

函数的返回值:
在函数中用关键字 return 返回值。

函数的形参和实参:

函数文档:

函数文档主要来对函数进行一些说明作用。
关键字参数:
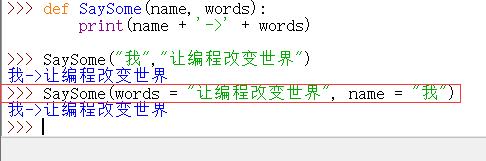
默认参数:
定义了默认值的参数:

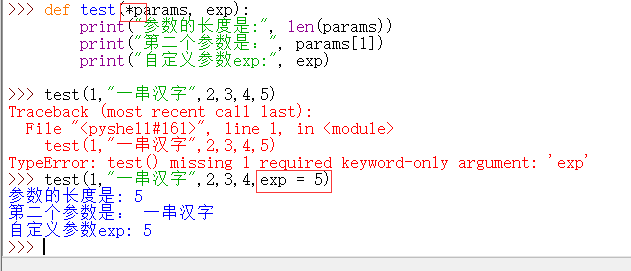
收集参数:
在形参前加上 * 号,这个函数可以有任意多个参数

如果使用收集参数后还要使用自定义的参数,此时自定义参数一定要使用关键字参数来调用:
▲:函数与过程(procedure)
一般来说,函数是有返回值的,而过程是简单的,没有返回值的
而python中只有函数,没有过程,因为python中的任何函数都有返回值,如下图所示:
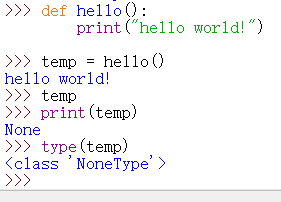
可以看出,及时 hello()没有返回值,也会自动给变量 temp 返回一个None。
python中可以用列表来返回多个值:

如果上图中在return 后不是以列表的形式返回多个值,默认是会以元组的形式返回多个值,如下图所示:

▲函数变量的作用域问题


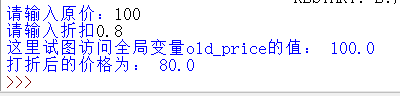
上面程序中,final_price 是局部变量,old_price 以及 rate 、new_price 都是全局变量。
如果在一个函数外访问定义函数时定义的局部变量,则会发生错误:

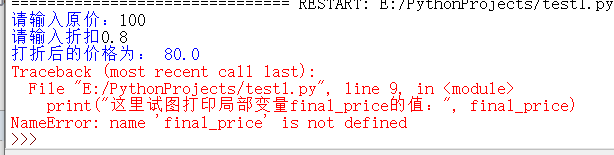
在上述程序中,old_price 以及 rate 、new_price 都是全局变量,如果在一个函数定义时访问全局变量是可以的:

如果尝试在函数中修改全局变量的值:
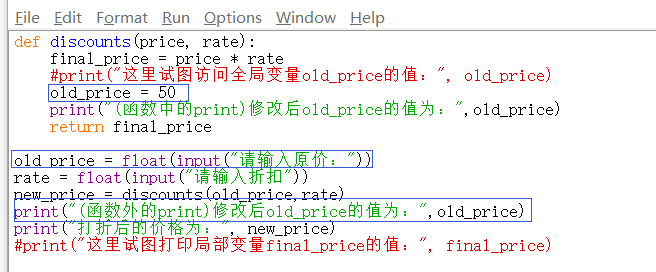
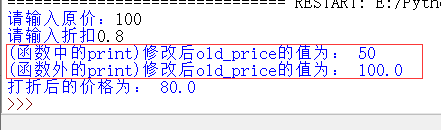
如上图所示,虽然在函数中修改了old_price的值为50,并且在函数中打印的old_price的值也为50,但是在函数外打印的old_price的值却为100。这是因为如果尝试在定义函数时函数内部修改一个全局变量的值,python会自动在此时(在栈内)创建一个与全局变量名相同的局部变量。因此可知在函数内修改的old_price的值只是python刚刚自动创建的函数内的局部变量old_price,并不是修改的全局变量old_price的值。
因此,在定义函数时函数中不建议修改程序中的全局变量的值,但是可以访问程序中全局变量的值。
那么,有没有一种方法能够在函数内修改全局变量呢?
答案是有的,就是使用 global 关键字。如下图:


由上述结果看出,在函数内使用 global关键字后,就可以在函数中修改全局变量的值了。
▲内嵌函数和闭包
python支持函数的嵌套:

注意上面的程序中,内部函数fun2()的整个作用域都在外部函数fun1()之内。在fun1()外是不能够调用fun2()的,如下图。

闭包:
如果在一个内部函数里对外部作用域(但不是全局作用域)的变量进行引用,内部函数就被认为是闭包。
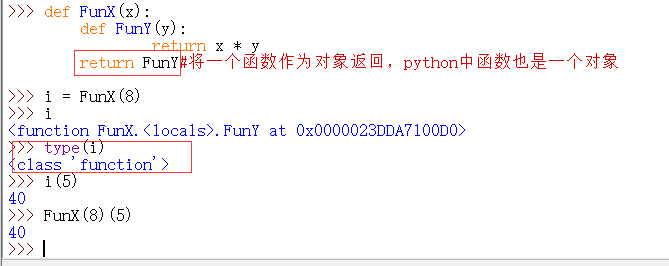
如上图中, FunX 中的内部函数 FunY 就是一个闭包。
注意,上图程序中不能这样写:

因为 执行 return FunY(y)语句时,y 是属于在外部函数 FunX 中执行的,而FunX中并没有定义变量 y,变量 y 只是内部函数 FunY 中的一个局部变量。
同样的,在内部函数FunY中只能对外部函数FunX的变量进行访问,但是不能修改。
如果要在内部函数中访问外部函数的变量(非全局变量),要使用 nonlocal 关键字,如下图:

▲lambda,匿名函数
python允许通过lanbda表达式来创建匿名函数。
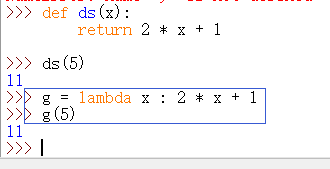
如上图所示,在语句 g = lambda x : 2 * x + 1
中,: 左边是形式参数,:右边是原函数的返回值,实际上 lambda 关键字是构建了一个函数对象。


十四、递归
求阶乘:


十五、字典
即键、值对,python的字典也称为 hash、关系数组。字典是python中的唯一一个映射类型。


还可以使用工厂函数(类型) dict() 函数来创建字典:( str(),int(),list(),tuple() 等都是工厂函数)

字典推导式和集合推导式:

如上图所示,第一个是字典推导式,因为 { } 中有 :,
第二个是集合推导式,因为 { } 中没有 :,所以 c 中的元素都不重复,是集合。
字典中的BIF方法:

该方法用来创建并 返回 一个新的字典。
有两个参数,第一个参数 S 是键,第二个参数 v(可选)是键对应的值,如果第二个参数不提供,默认为NULL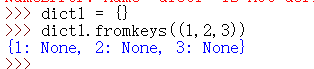
如上图,第二个参数不提供,所以 值 为 NULL。
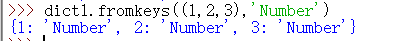
注意,第二个参数只能写一个,并将其设置为每一个键的值,如下图所示:

并且该函数不能修改字典的值,只会创建新的字典,如下图所示,如果想要使用 fromkeys() 函数修改 dict1 的键:1 和 3 对应的值,会发现该函数会创建一个新的字典:

访问字典的几个BIF方法:

keys() 函数用来返回字典中 键 的引用。
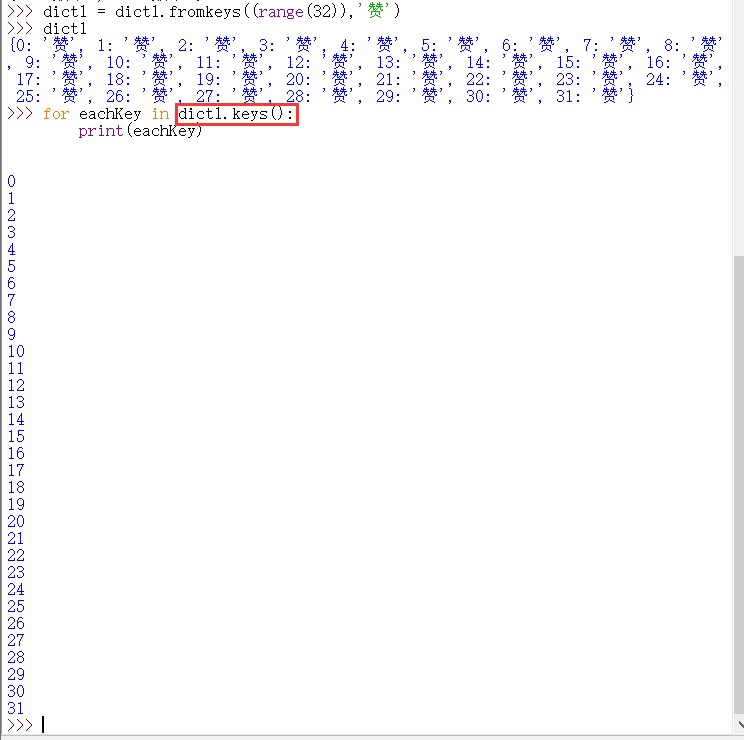
values() 函数用来返回字典中 键 对应的值。

items() 函数用来打印字典中的每一项:

用 get() 方法来访问字典中的项:
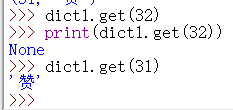
如果该项存在,就会返回,不存在就会返回None。
清空字典用 dict1.clear() 或者直接 dict1 = { },推荐用 clear() 方法。
拷贝:(浅拷贝)copy():

注意上图中浅拷贝和赋值的不同,浅拷贝 是使用了其他的内存来存储copy的内容,而赋值仅仅是将不同的变量名贴到了同一个内存中的内容。
pop() 和 popitem():
pop():给定键弹出对应的值
popitem():弹出末尾一项


十六、集合
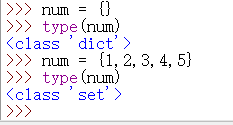
上图是字典和集合之间的关系,一般来说,使用大括号 {} 括起来的内容是字典变量。
注意,集合之间的元素是唯一的:

且集合不支持使用索引下标来访问。

十七、文件系统
我们使用 open 关键字来打开一个文件。
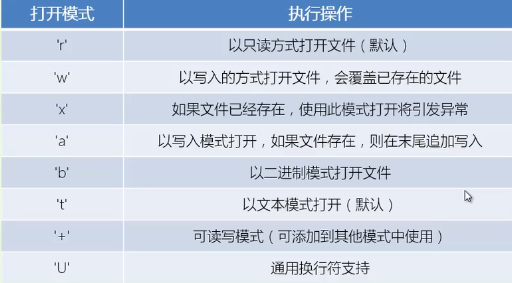

open 的前两个参数最重要,file 参数为文件名,mode 参数为打开模式
如果E盘中有一个“record.txt”:

那么这样来获取该文件对象:

这样就将该文件对象赋值给了f。
☆注意,如果txt中有汉字,应该这样将文件对象赋值给f:
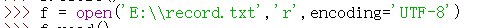
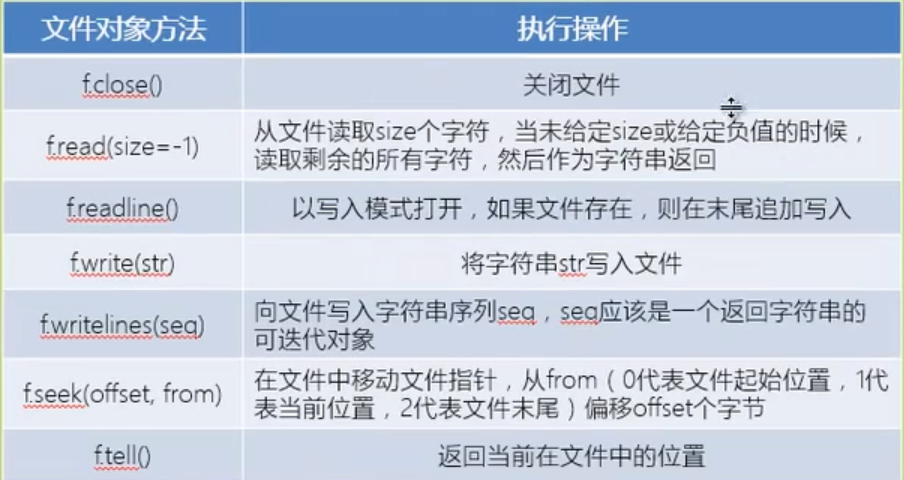
如何对文件对象进行操作呢?如下图所示:
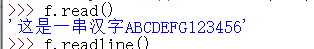
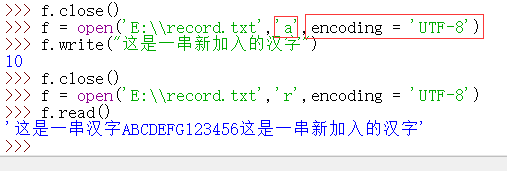
需要注意的是,在文件对象 f 中是存在一个指针的,如下图所示:

我们可以看到,在第一次 f.read() 之后,文件中的指针已经移到文件末尾,因此再用 f.readline() 已经不能读出东西了。只有用 f.seek(0,0) 来讲文件中的指针移到起始位置,在用 f.readline() 函数,才能再读出东西
同时,我们还可以将一个文件对象中的内容赋值给列表:

假如一个文件有多行内容,可以这样来显示其内容:

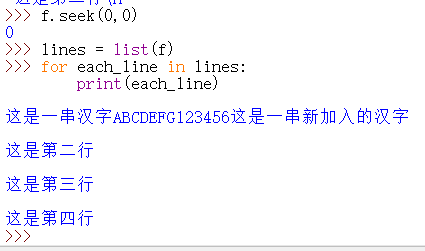
也可以:

▲关于os模块:
首先需要使用 import os ,语句,然后可以使用下面的方法
https://www.cnblogs.com/alan-babyblog/p/5172781.html


▲将列表、元组、字典(即使用{}括起来的内容)等转换为二进制字节流存放:
使用 pickle 模块。
如果要将一个列表保存为二进制文件:
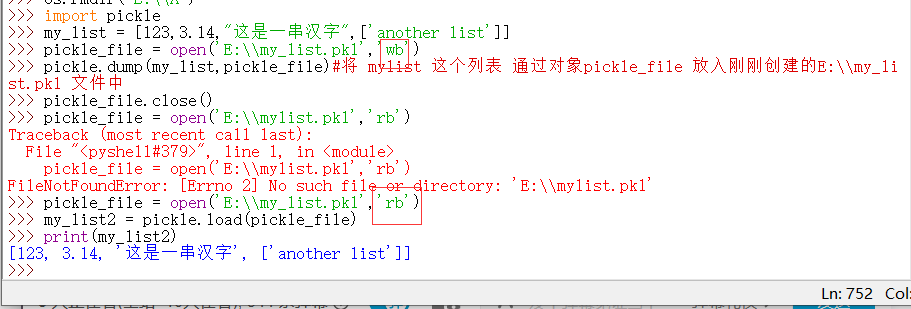
一般来说经常讲 字典 用该方法存储,如果一个字典 (例如:city = {…(很多内容)…} )太大,就可以先将字典 city 放入文件 city_data.pkl 中(即将上图代码中的 my_list 换为 city ,将my_list.pkl 换为 city_data.pkl) ,再进行操作。
十八、else 语句 和 with 语句
else语句除了可以和 if 语句搭配,还可以和 while语句搭配:
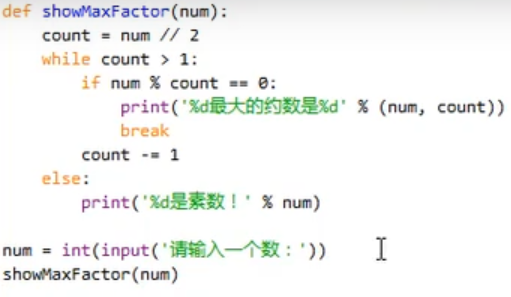
上图中,如果while语句全部执行完毕,紧接着会执行else语句
如果while语句没有全部执行完毕(即执行过程中执行了break语句,跳出了循环),则接下来不会执行else语句
with:
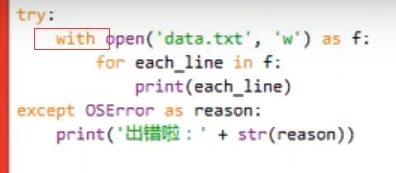
会在用不到文件的时候自动调用 f.close() 函数。
十九、图形界面入门:EasyGui
教学文档:
http://easygui.sourceforge.net/
先安装easygui:
桌面上有:

其中这个文件夹里包含:

这两个程序。
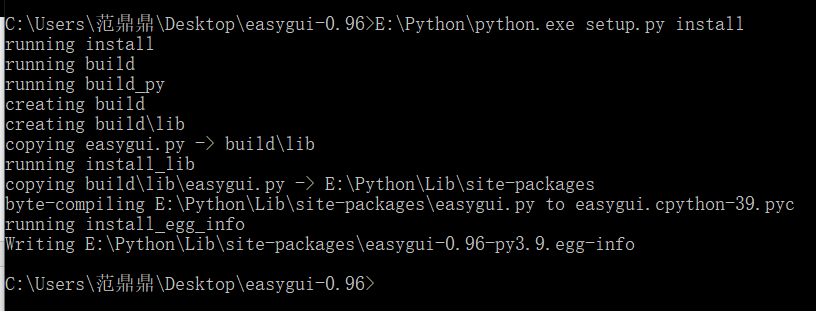
实际上安装到了这里:
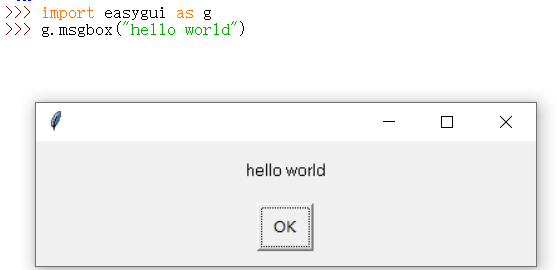
接着就可以使用了:
二十、类和对象
python中的对象 = 属性 + 方法

对象的创建和使用:

▲python中类的继承:

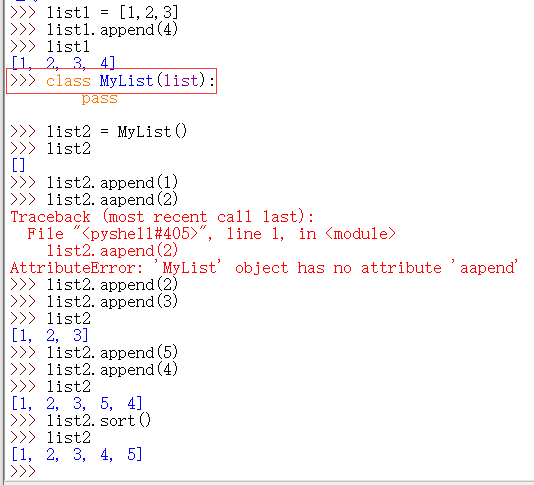
如上图所示,创建了一个 MyList 类继承了 list 类(其中下面一行 pass 表示什么也不做)
这样用 Mylist 类也可以创建对象 list2,并可以使用list类的方法 append(),sort(),等。
更多的例子:
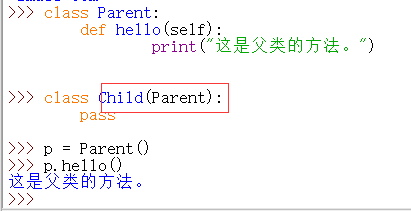
注意:如果子类中定义与父类同名的方法或者属性,则会自动覆盖父类对应的方法或属性。
如果想让子类中的同名函数不覆盖父类的同名函数,有两种方法:

1)调用为绑定的父类方法
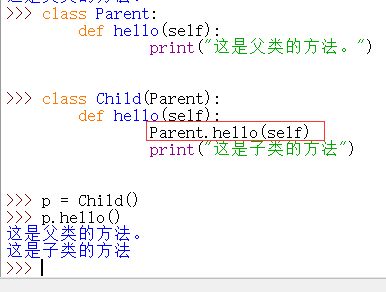
注意,上图中红框里的 self 是子类Child的对象p的self,并不是父类的实例对象。所以实际上还可以这样写:

2)使用 super 函数
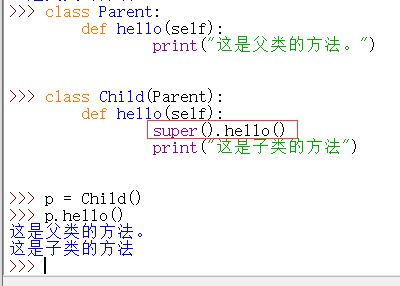
此外,python还支持多重继承:

例子如下:

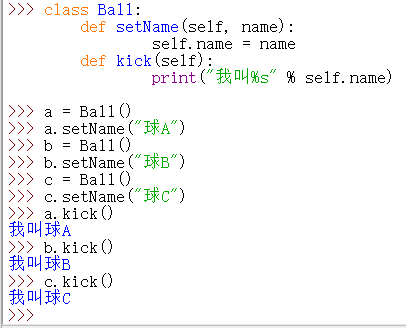
▲python中类的多态性:
self:python中的self相当于C++中的this指针,在定义类的函数的时候,将self写入第一个参数
▲python中的构造函数:被双下划线包围的方法:
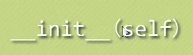
即构造函数,是python自动调用的,其可以被重写:

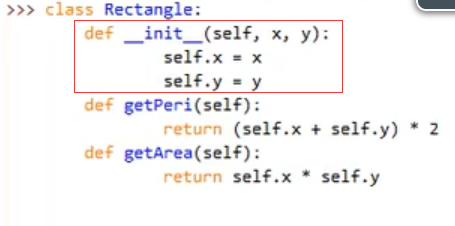
▲公有和私有:
默认来说,python的属性和方法都是公开的:

那么如何在类中定义私有变量呢?

如下图所示,私有变量就不可以被访问了:
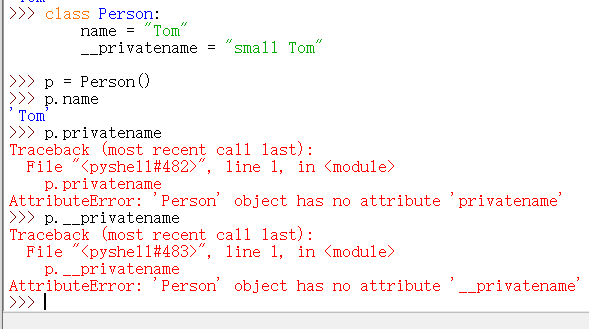
私有变量可以通过使用类中的公有方法来调用:
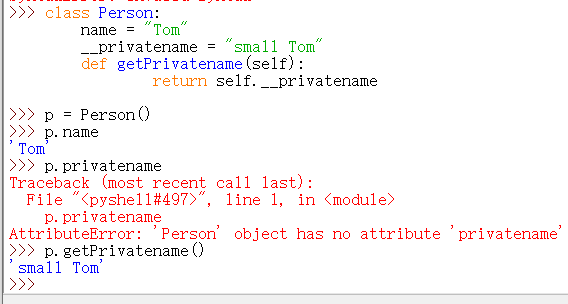
事实上,python的私有机制是伪私有机制,只是将私有变量的名字改变了,可以这样来访问:

▲类的组合:将一个类的实例化放在一个新类的定义中,就称为将旧的类组合进了新的类:
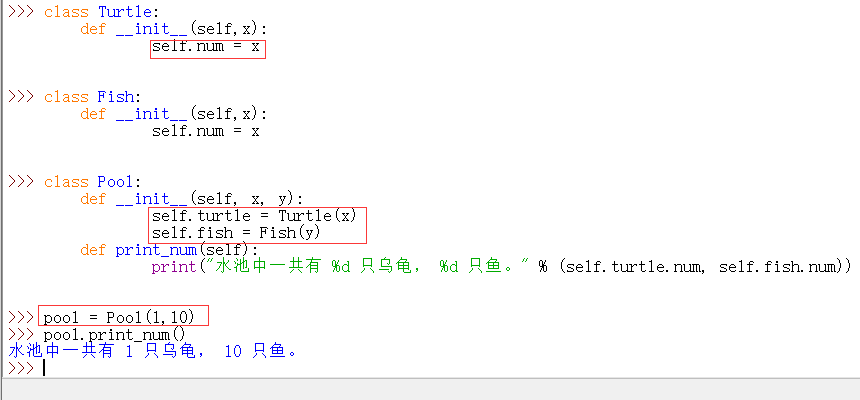
python中,如果属性的名字与方法的名字相同,属性会覆盖方法:
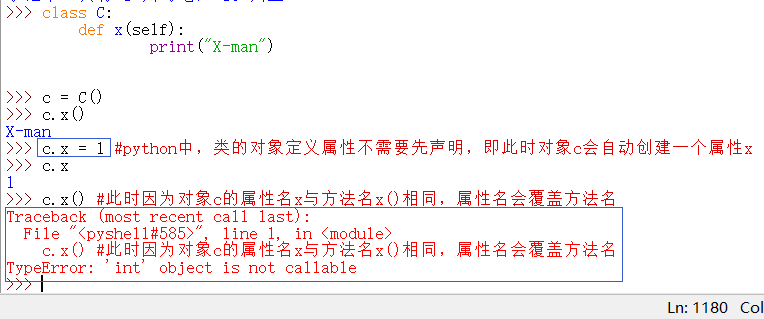
因此:

上图中的组合机制即将旧类组合进新类中。
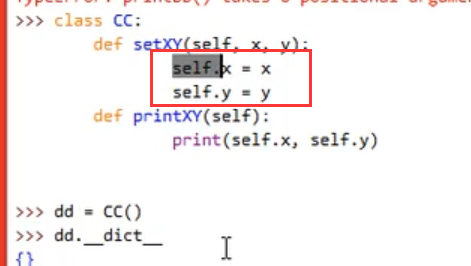
▲python中的 绑定 概念

一般我们创建属性时不使用类属性而使用实例属性。
类属性,一般我们定义属性时不这样:

实例属性,一般如果我们想要定义属性,这样定义:
与类和对象相关的BIF:
查询某个对象是否有某个属性名,其中name要用双引号。



返回一个对象的属性值,如果属性不存在,如果设置了default,会将default返回,否则报错。


设置对象中指定属性的值,如果指定属性不存在,那么会自动创建该属性并给其赋值。

删除对象中指定属性,如果属性不存在,则会抛出异常。

魔法方法篇:
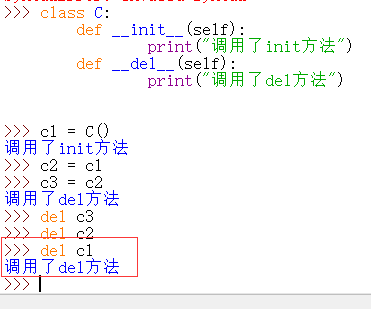
二十一、构造和析构

构造函数:


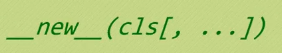
一个对象实例化的时候第一个调用的方法,它的第一个参数是 一个类 cls。该方法需要一个实例对象作为返回值,它会返回一个对象。
一般情况下我们不会重写它,但当一个类继承一个不可变类型的时候,有需要进行修改时,就要重写:

如果不重写new函数,就实现不了大写的功能:

因为str是不可变的类,不能用init()函数对其自身进行修改,如果不重写new函数,创建对象时就会调用 基类 str 的new函数,就实现不了大写功能。
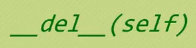
将对象被销毁时,该函数会自动被调用。并不是说使用 del 关键字删除一个变量时候就会自动调用该函数,而是一个对象被垃圾回收机制回收时才会调用该对象。
二十二、算数运算
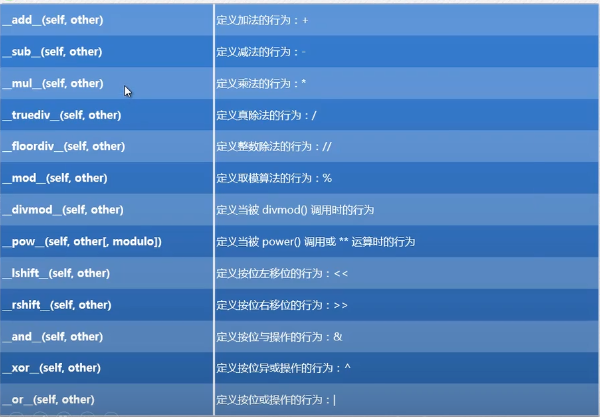
运算符的重载:

如果想自定义加法,注意下面这个方法是错误的:
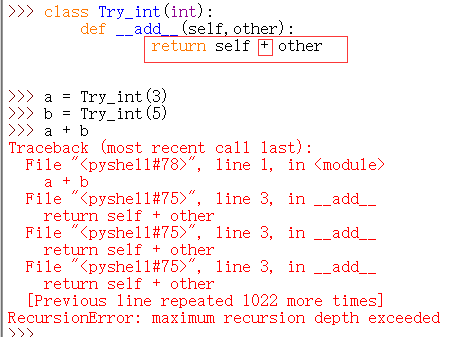
如上图所示,发生了无限递归。在 Try_int中重写了 int 类型的内置函数 __add__(self,other),利用Try_int类创建了两个实例并且将他们相加,执行加法运算时,会执行 Try_int 中的 __add__(self,other)函数,其中 self为a,other 为b;但是执行该函数时又遇到了 + 运算,再次调用该函数……出现了死循环。
改正:

这样在执行 a+b 时调用 Try_int类中的 __add__(self,other) 函数时,再执行 return int(self)+int(other) 时,此时调用的 + 就是int类型中的 __add__(self,other) 函数而不是Try_int 类中的函数了。
反运算:

当执行 a + b 时,如果a的__add__(self,other) 方法不可用,就会调用 b 的 __radd__(self,other) 方法。此时注意,调用 b 的 __radd__(self,other)方法时,self 是 b,other 是b前面的数。

如上图所示,执行 a + b 时,调用的是 a 的 __add__(self,other) 方法。
而执行 1 + b 时,调用的是 b 的 __radd__(self,other) 方法。且self 为 b = 3,other 是1,所以 3 - 1 = 2。
二十三、属性访问

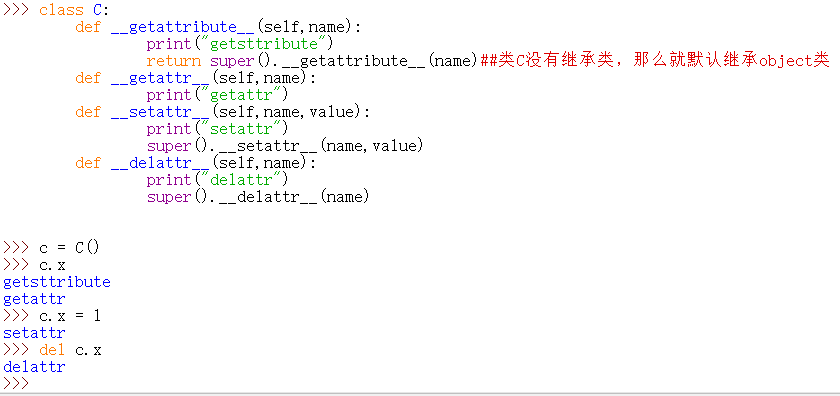

二十四、描述符

特殊类型就是实现了上图中三个方法中的至少一个。
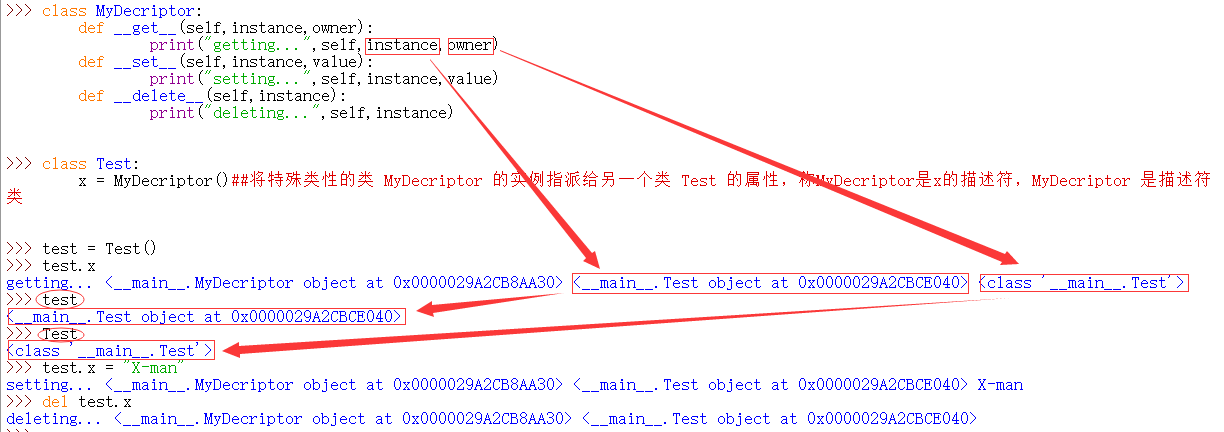
二十五、定制容器

python中,序列类型(列表、字符串等)和映射类型(字典等)都是容器类型

如:编写一个不可改变的自定义列表,要求记录列表中每个元素被访问的次数。
根据第一张图,应该使用 __len__(self) 以及 __getitem__(self,key) 方法

在上图中,创建了一个自定义容器CountList,由于该容器只定义了 len() 和 getitem() 方法,因此该列表只能返回列表长度和获取列表元素,即是一个不可改变的自定义列表。
我么使用 count 字典对象来计算列表中每一个元素被访问的次数,初始值全部为0,即刚开始每一个元素都未被访问。
二十六、迭代器

对于一个容器对象,调用 iter() 就得到一个迭代器,调用next(),迭代器就会返回下一个值。
在另一篇python基础中 十二、列表 这一知识点也有有关迭代器的内容。
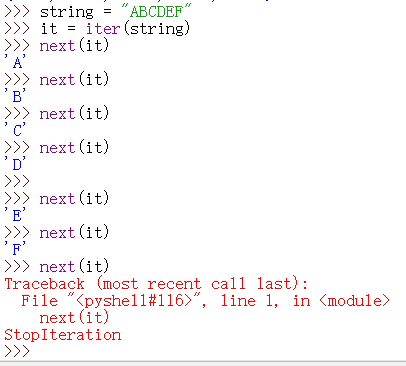
关于迭代器的魔法方法有两个:

iter() 用来返回迭代器本身。

二十七、生成器
生成器使用 yield 关键字,生成器是一个特殊的迭代器。
生成器是一个特殊的函数,调用时会中断暂停,暂停后将控制权交出来。在需要时还可以重新拿回控制权。
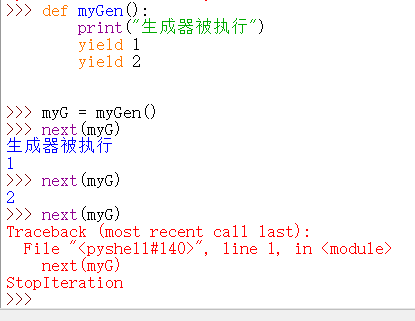
如上图,一旦一个函数中出现 yield 关键字,这个函数就被定义为生成器。yield 与函数中的 return 类似,但是普通函数中的 return 一旦被执行,这个函数就结束了。但对于生成器来说,出现 yield 就会把 yield后的参数返回,并暂停在 yield 的位置。
生成器相当于一个特殊的迭代器,所以用 next() 来访问接下里的内容。
生成器还可以使用循环来访问:
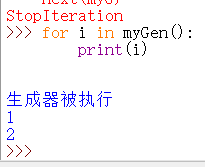
之前讲过推导式的内容。
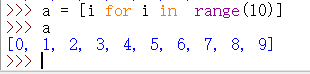
如图,上图是一个列表推导式。
但是注意,由 ( ) 中构成的推导式并不是 元组(tuple)推导式,而是 生成器推导式。

生成器推导式如果作为函数的参数,则可以直接写推导式,而不用再加括号:

如上图中,第一行代码就没有加 sum() 函数的括号,但仍是正确的。
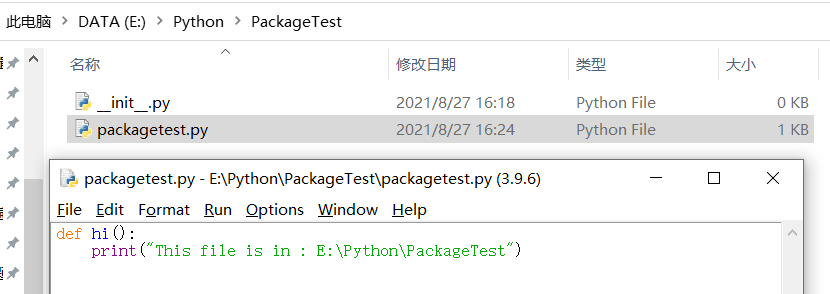
二十八、模块

在python路径下创建 moudletest.py:
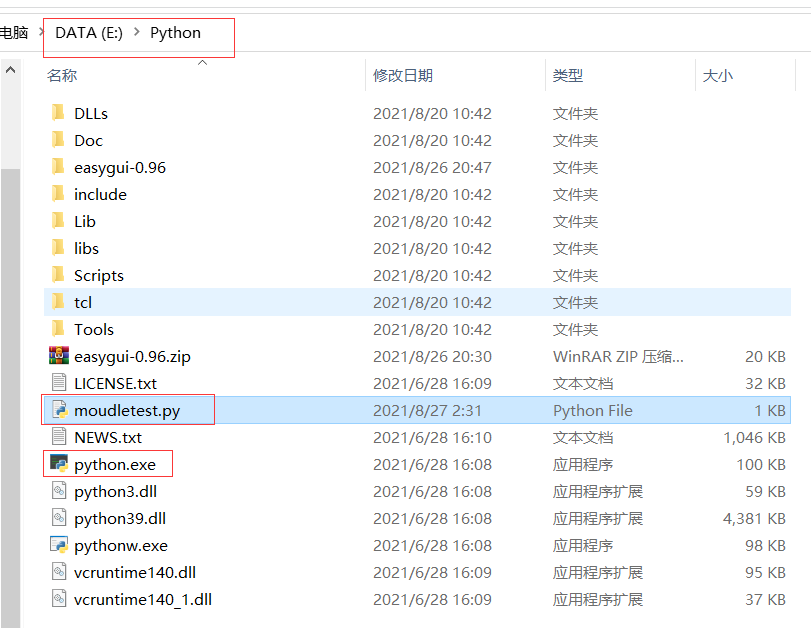
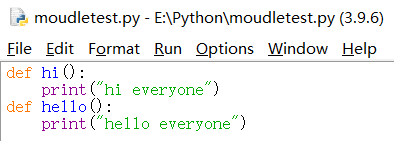
此时 moudletest.py 就是一个模块。注意,应确保模块 moudletest.py 与 python.exe 在同一目录下。
紧接着:
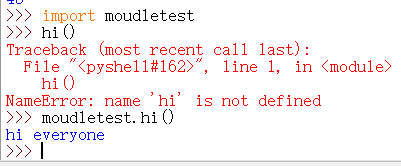
导入模块的方法:

注意,第二种:
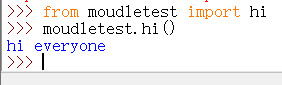
但是一般不推荐使用。推荐使用第三种:
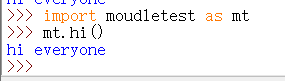
搜索路径:
写好的模块应该放在:
除了放在和 python.exe 同一目录下
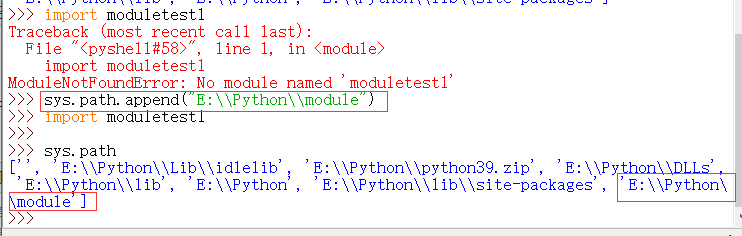
python模块的导入会有一个路径搜索的过程,如果在搜索路径中找到该模块,则导入成功,否则导入失败。搜索路径是一个列表,可以通过 sys 模块的 path 变量将其显示出来:

即python会从上述路径中一个个查找需要导入的模块,可以使用下面方法来在搜索路径中加入内容:
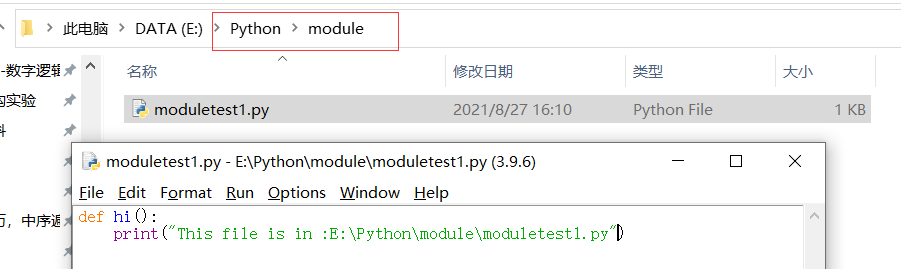
在没有添加搜索路径时,导入模块失败,使用 sys.path.append() 方法添加该路径后,导入成功:
包 package:

然后使用 import 包名.模块名 即可