论文查重
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业目标 | 实现论文查重 |
GitHub链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 400 | 420 |
| Analysis | 需求分析 (包括学习新技术) | 200 | 190 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 23 | 23 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 120 | 100 |
| Coding | 具体编码 | 400 | 400 |
| Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 45 |
| Reporting | 报告 | 120 | 180 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 20 | 23 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| Sum up | 合计 | 1493 | 1641 |
计算模块接口的设计与实现过程
1.算法选择:
从网上关于查重软件中,我了解到了“余弦相似度算法”。
思路:
(1)找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
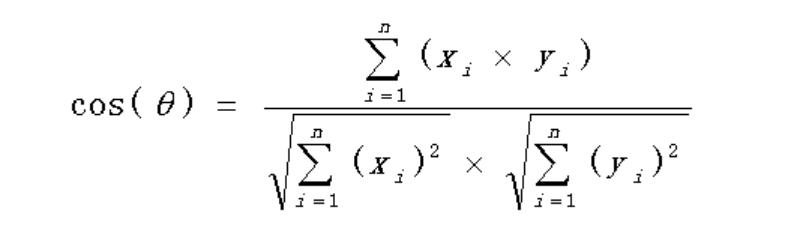
余弦相似度算法:一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
2.流程图:

计算模块接口部分的性能改进
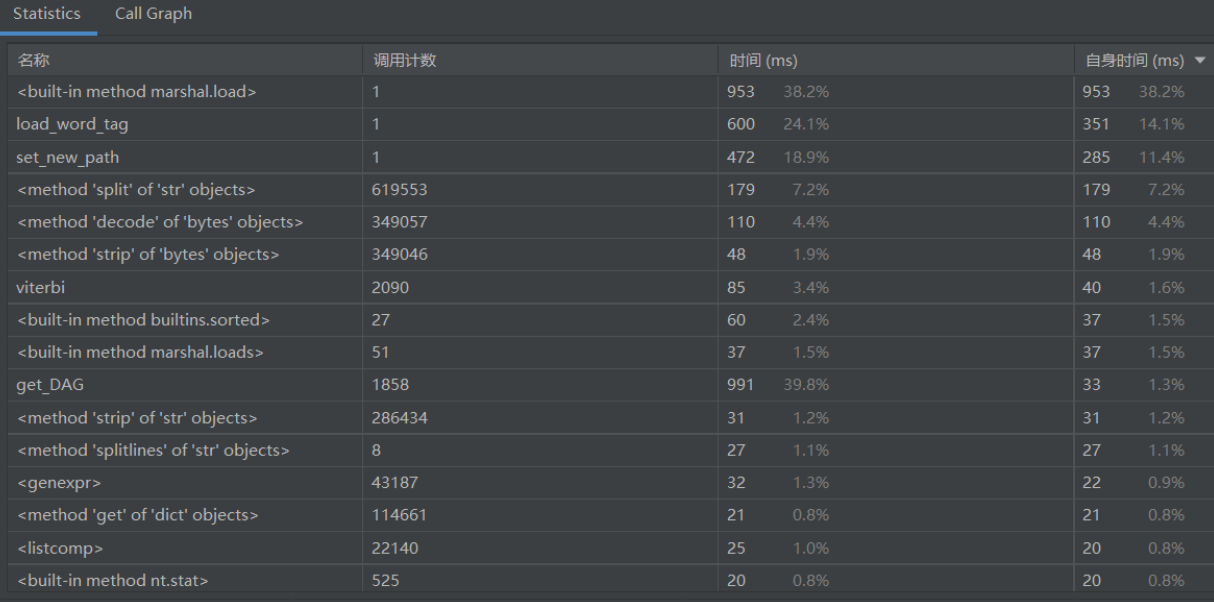
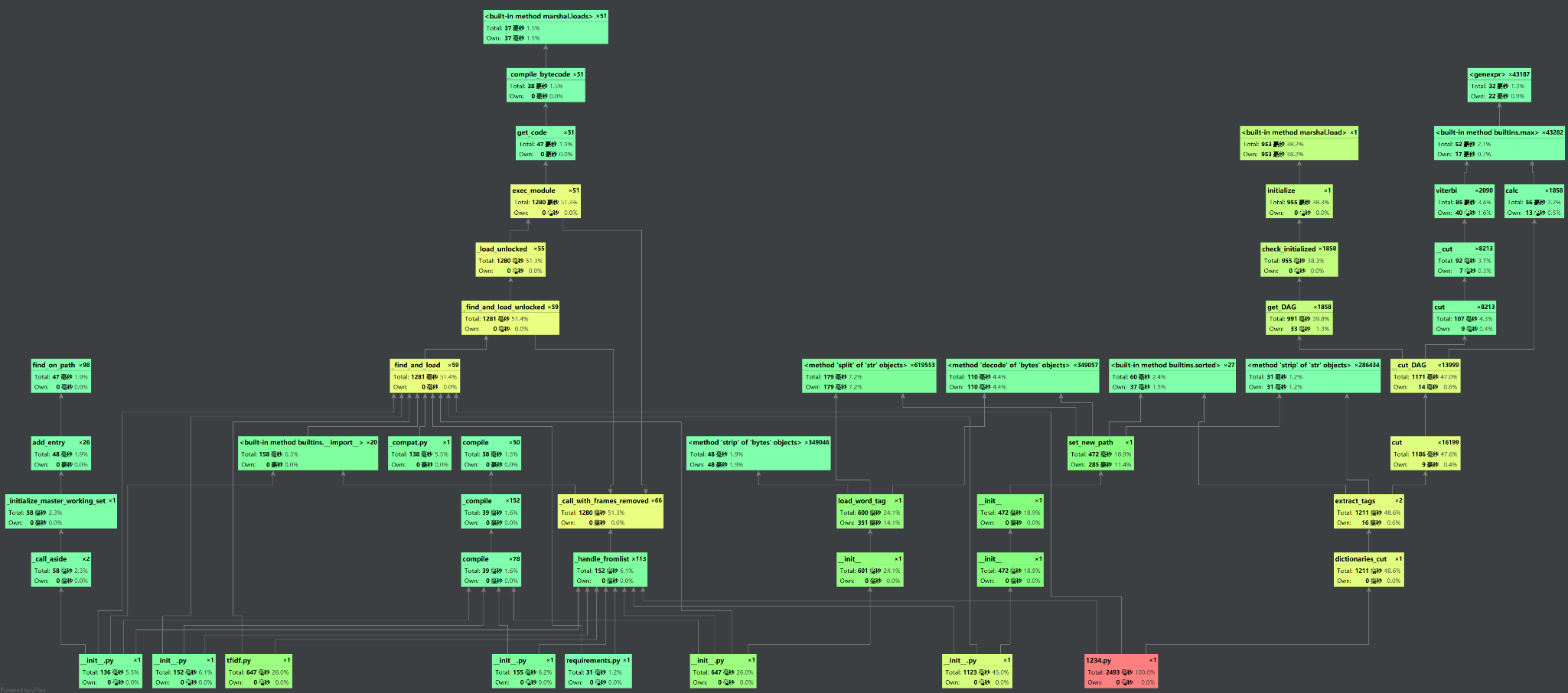
1、关键在于利用余弦算法,通过简单的词频计算作为特征值,但是仅仅只能通过词语本身来衡量其特性,而没有语境(即上下文)来更准确的确定一个词的特征。可能如果要提升效率以及准确性,可能需要换TD-IDF等新的算法去提升
部分单元测试
1.代码中的[0-9A-Za-z\u4e00-\u9fa5] 表示所有标点符号,我想法是先将文本内的所有符号排除,以免加大文本重复率。将文体提取成全文字时,准确率可以提升。

2.这里运用到了计算两个向量的余弦距离来求文本相似度。

3.覆盖率

4.最终结果
1)orig.txt与orig_0.8_add.txt的测试结果

2)orig.txt与orig_0.8_del.txt的测试结果

3)orig.txt与orig_0.8_dis_1.txt的测试结果

4)orig.txt与orig_0.8_dis_10.txt的测试结果

5)orig.txt与orig_0.8_dis_15.txt的测试结果

计算模块部分异常处理说明

即如果文本地址输入发生错误,无法载入文本,作为异常处理,直接输出“文件不存在”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号