8月4日web学习
题目:robots
题目描述:X老师上课讲了Robots协议,小宁同学却上课打了瞌睡,赶紧来教教小宁Robots协议是什么吧。附上题目场景,点进去是空白的。
空白题目场景
解题思路:题目提到robots协议,由于我也不甚了解,那么我们就百度一下robots协议:
robots协议
robots协议也叫robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜素引擎的漫游器(即网络爬虫),此网站中的哪些内容是不应该被搜索引擎的漫游器获取,哪些是可以被漫游器获取的,且robots.txt放置于网站的根目录下。
有了这些信息,我们应该先找到网站的根目录,在网站的根目录下寻找robots。试了很久,发现可以直接根据url访问
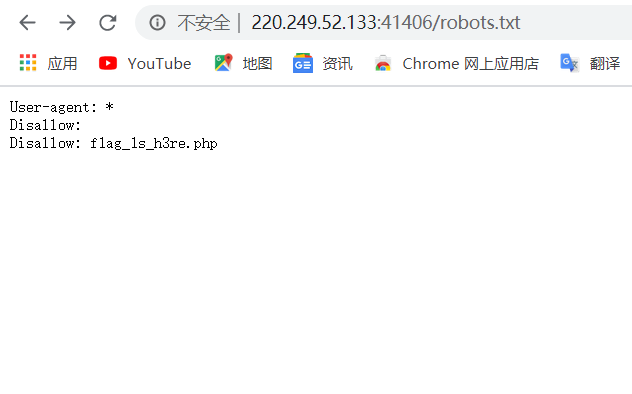
直接根据url访问robots.txt
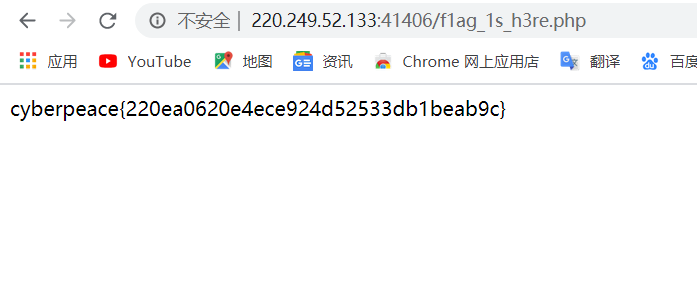
发现flag,直接访问。
题目:backup
题目描述;X老师忘记删除备份文件,他派小宁同学去把备份文件找出来,一起来帮小宁同学吧!后面跟上的是题目场景

题目场景
解题思路:我自己看是没有什么思路,看了一下writeup,就知道了本题目考察的是备份文件后缀。
备份文件
常见的备份文件后缀有:git,svn,swp,~,bak,bash_history
到这里来挨个去试一试,还有一种方法就是使用扫目录脚本/软件,我这里使用的是writeup中的一个脚本dirsearch
dirsearch
使用dirsearch脚本,先进入到dirsearch脚本的解压目录
d:
cd d:\dirsearch
然后运行命令
py dirsearch.py -u [url] -e *
就可以扫描相应url下的目录,在扫描的时候url错误都是不可行的,比如我写错了协议,http写为了https,发现是不可扫描的。猜想ssl对扫描网页目录的脚本有防御作用。
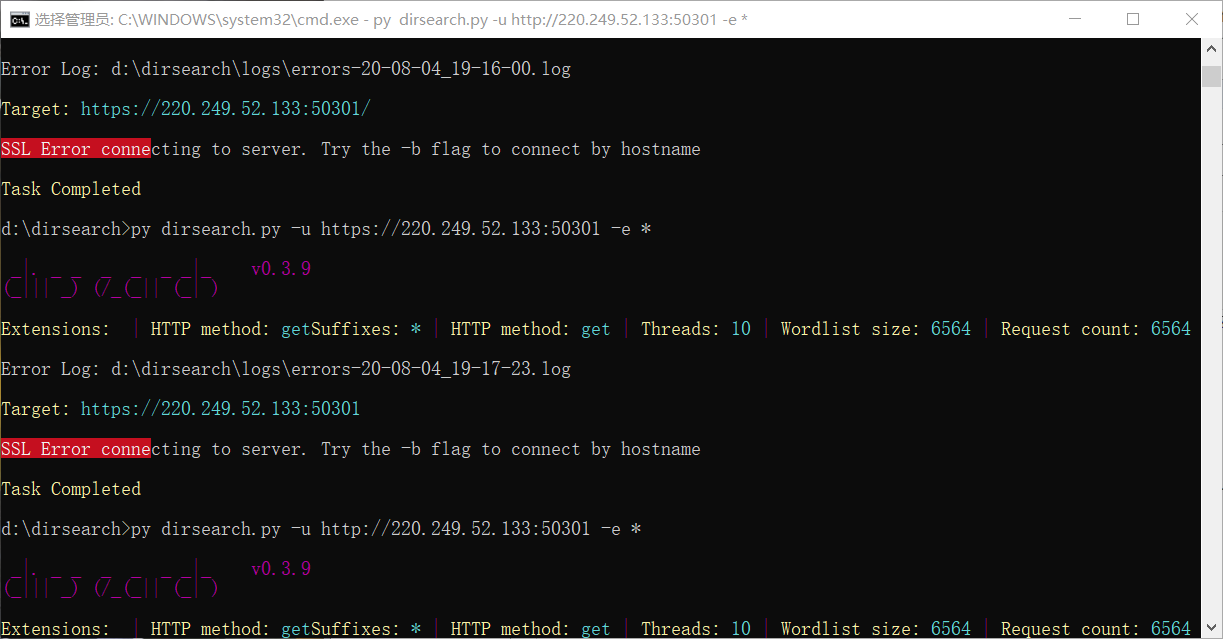
http改为https出现的错误
改回来后,可正常扫描。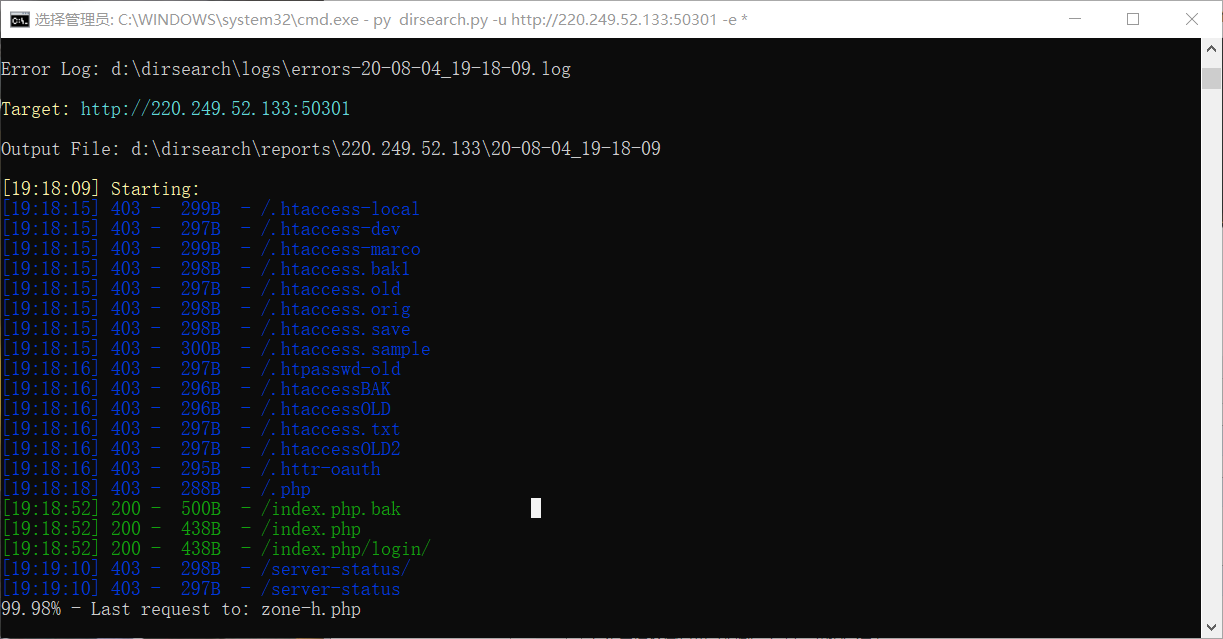
得到结果
黄色区域即为目录下得到结果,知道网页压缩文件是bak格式。直接到该目录下,即可得到flag。
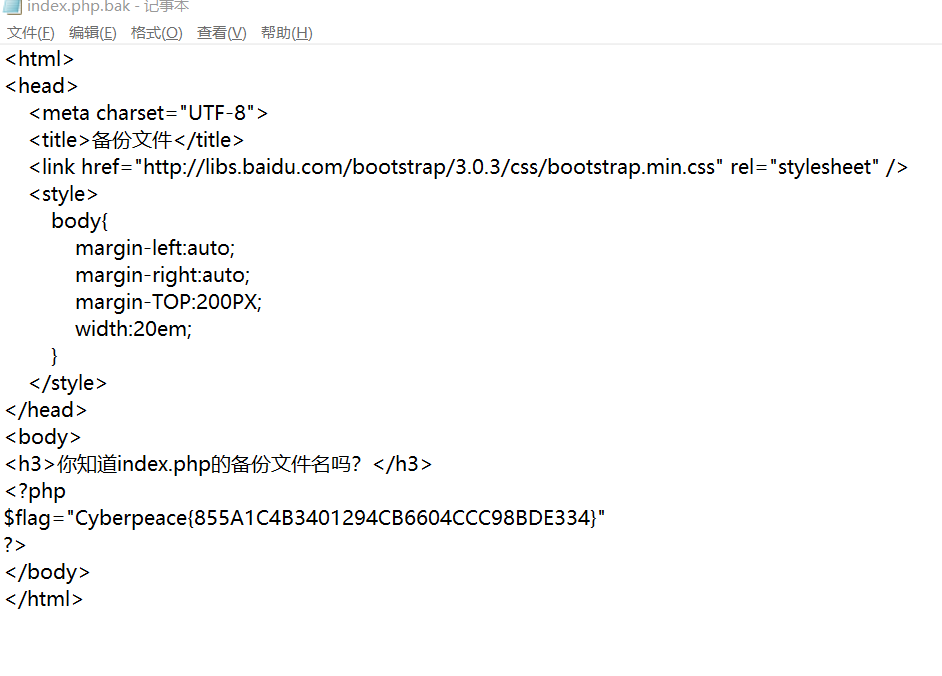
跳转,下载,得到结果
题目:cookie
题目描述:X老师告诉小宁他在cookie里放了些东西,小宁疑惑地想:‘这是夹心饼干的意思吗?后面附上题目场景。
题目场景
解题思路:直接查看cookie,发现
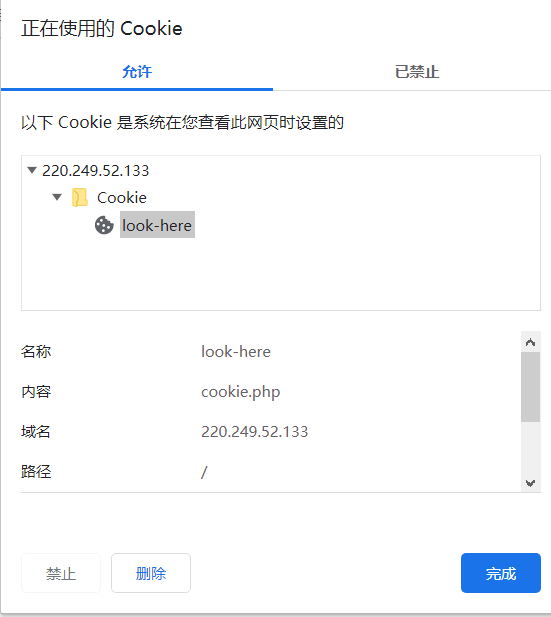
cookie内容
没想到还有一层
这里不知道怎么抓包,所以找了找,发现了一种工具burp suite
下载地址:https://blog.csdn.net/u013291076/article/details/90081313
上面那个下载地址不太灵,所以换一个下载地址:https://www.52pojie.cn/thread-1194411-1-1.html
但是在安装的时候也出现了很多问题,如注册机keygen文件无法作为可执行jar文件打开

手动执行可执行jar文件
但是在执行vbs文件时又出现了闪退问题,查了资料,据说是因为java版本问题。只好重装jdk14。而今天刚装了kali,自带burp,所以window装burp的计划暂时搁置。
而在火狐浏览器中,我发现浏览器自带的开发者工具,就可以对http进行抓包,拿到httpresponse的应答头。
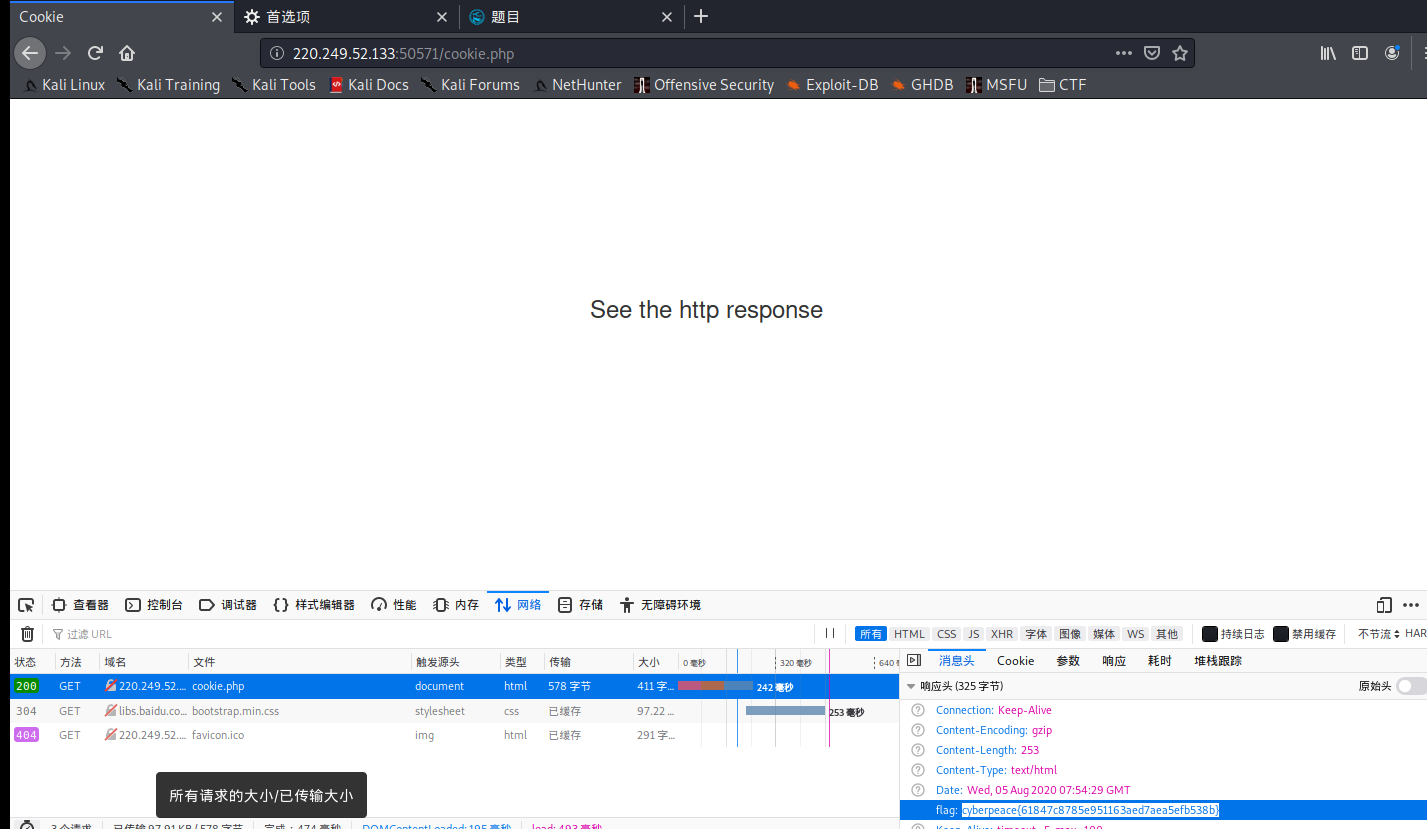
response

 浙公网安备 33010602011771号
浙公网安备 33010602011771号