
理解Node.js 的重要概念
Node.js是什么
Node.js是JavaScript的运行时(runtime),给它一段JS代码,它就能运行。同时,它又提供了fs,http等对象,用JS也能进行文件读写,创建服务器。这主要是因为Node.js内嵌了V8,V8是用C++写的,只要内部进行一层bind封装,JS就能加载C++模块。同时V8还有FunctionTemplate,可以动态生成JS中没有函数,供JS使用。比如fs的实现中(Node.js项目下的lib下的fs.js)
const binding = internalBinding('fs'); // internalBinding('fs'); 就是调用和加载C++实现的fs模块(src文件夹中node_file.cc文件)。
const { FSReqCallback, statValues } = binding; // FSReqCallback就是通过V8的FunctionTemplate生成JS中没有函数,
// readFile方法
const req = new FSReqCallback();
req.context = context;
req.oncomplete = readFileAfterOpen;
// binding.open相当于调用了C++的Open方法(打开文件),
binding.open(pathModule.toNamespacedPath(path),
flagsNumber,
0o666,
req);
}
src文件夹中node_file.cc,
// C++ 把不认识JS中的数据类型,使用V8转换成自己认识的数据类型 using v8::Array; using v8::BigInt; using v8::Boolean; // Open 方法 static void Open(const FunctionCallbackInfo<Value>& args) { if (argc > 3) { // open(path, flags, mode, req) AsyncCall(env, req_wrap_async, args, "open", UTF8, AfterInteger, uv_fs_open, *path, flags, mode); }
AsyncCall就是调用libuv的open方法,它是异步的,完成后,就把AfterInteger放到事件队列中,事件循环取出执行AfterInteger。事件循序就是一个C程序,替换了V8的默认的事件循环(V8的事件循环是插拔式的)。node程序执行时,就会启动事件循环。
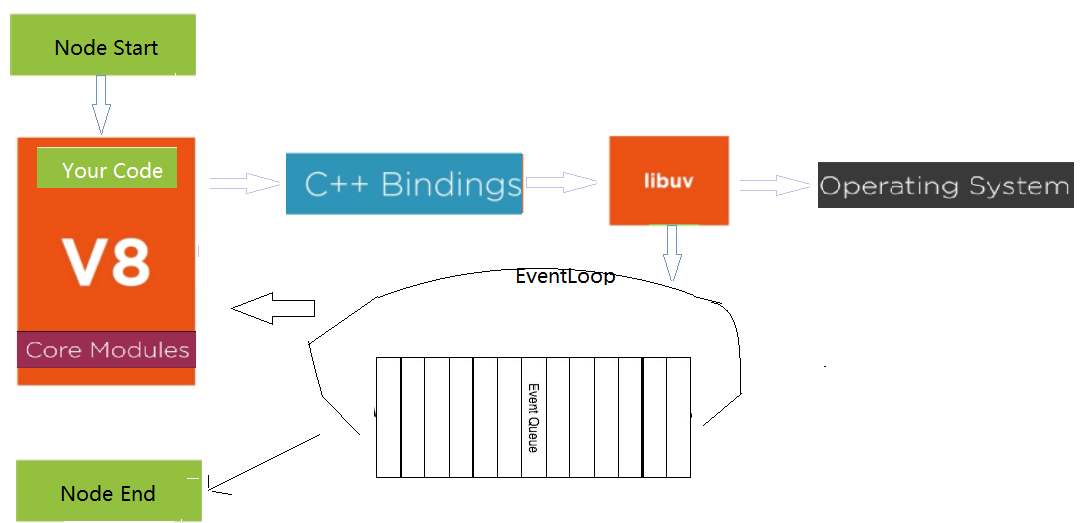
事件循环
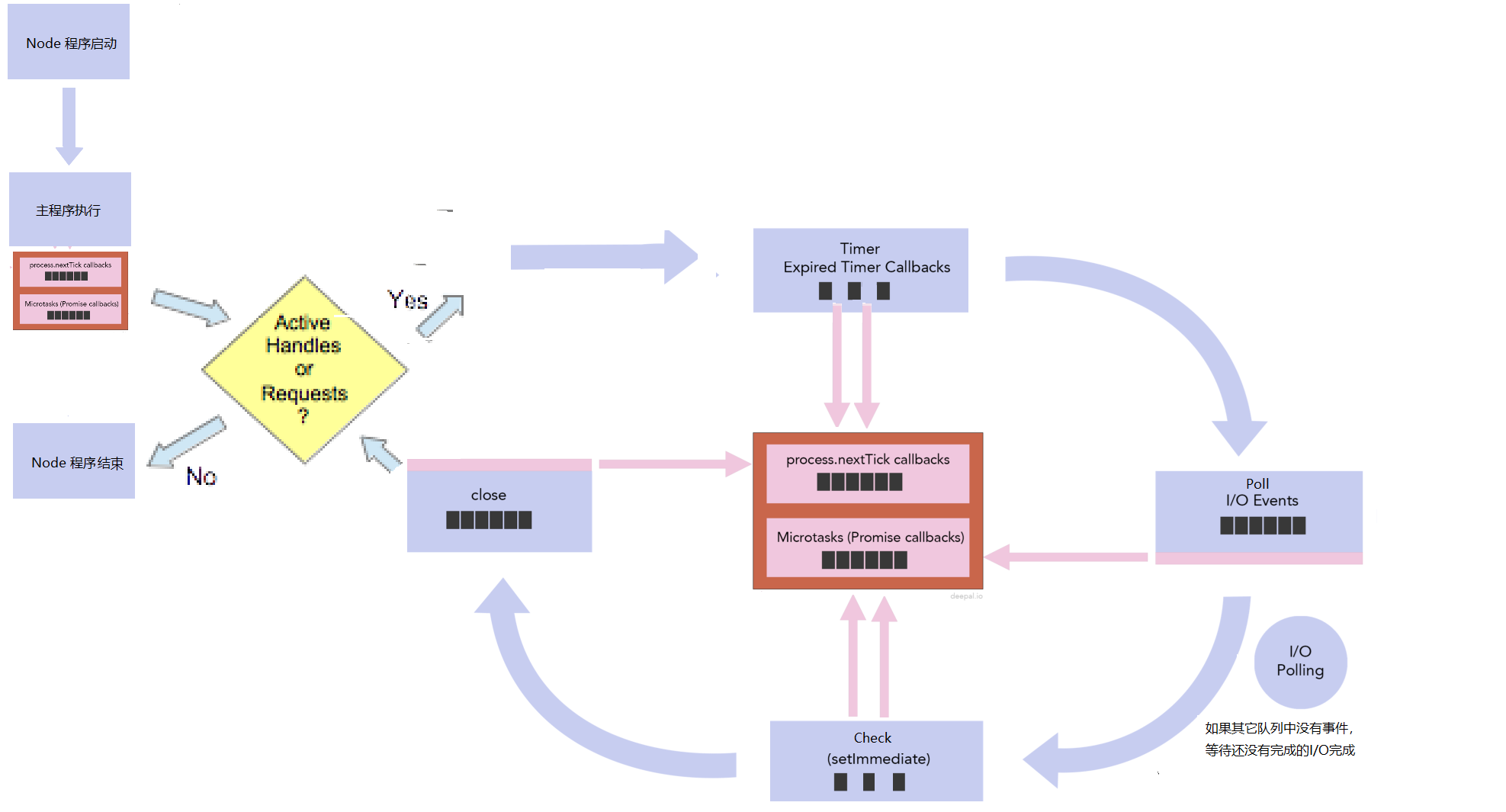
Node.js的事件循环并不是循环一个队列 ,而是循环多个队列,不同类型的事件放到不同的队列中。libuv提供了time、poll、check和close等队列,分别存放setTimeout/setInterval,I/O,setImmediate和close相关的回调函数。Node.js自身提供nextTick和microtasks队列,分别存放process.nexttick和promise相关的回调函数。
node index.js,index.js开始执行(同步代码执行),执行完成后,Node.js就会检查nextTick和microtasks队列,nextTick队列的优先级高于microtasks队列,先把nextTick队列中的所有事件都执行完,再执行microtasks队列中的所有事件,如果microtasks队列中的事件又调用了process.nextTick, 等microtasks队列中的所有事件都执行完毕,Node.js又会返回执行nextTick队列中的事件,直到nextTick和microtasks队列中所有事件都执行完,再看在index.js执行的过程中有没有添加事件到libuv队列中,就是看有没有active handle 或 active request。如果没有,就不会开启事件循环,如果有,就开启事件循环,事件循环按照 timer -> poll -> check -> close的顺序循环,到timer和check阶段时,每执行完队列中的一个事件,就会检查nextTick队列和microtask队列,而poll和close阶段,是把该队列中的所有事件都执行完,再检查nextTick队列和microtask队列。都是先检查process.nextick队列,再检查microtask队列,只有next tick队列中的所有事件都执行完毕,才会执行microtask队列中的事件,process.nextick队列的优先级比microtaks队列的高。循环完一遍,再看有没有active handle或active request,如果没有,Node.js程序退出,如果有,接着按timer -> poll -> check -> close的顺序循环,只要有active handle或active request, Node.js程序就永远执行。handle代表长期存在的对象,例如计时器,TCP/UDP 套接字,requests表示短暂的操作,例如读取或写入文件或建立网络连接。
const fs = require("fs");
Promise.resolve().then(() => console.log('promise1 resolved'));
Promise.resolve().then(() => {
console.log('promise2 resolved');
process.nextTick(() => console.log('next tick inside promise'));
});
process.nextTick(() => console.log('next tick1'));
setImmediate(() => console.log('set immedaite1'));
setTimeout(() => {
console.log('setTimeout 1');
Promise.resolve().then(() => { console.log('setTimeout1 Promise');})
}, 0)
setTimeout(() => console.log('setTimeout 2'), 0);
fs.readFile(__filename, () => {console.log("readFile");});
for (let i = 0; i < 2000000000; i++) {}
执行结果如下
/* next tick1 promise1 resolved promise2 resolved //promise2 resolved添加”next tick inside promise“到nexttick队列。microtasks所有事件完成后,node再一次执行nextTick队列。microtasks和nextTick所有事件完成后,事件循环到timer阶段 next tick inside promise setTimeout 1 // setTimeout 1把setTimeout1 Promise放到micorTask队列,timer队列一个事件执行完了,就检查micorTask队列,正好执行setTimeout1 Promise,再回到timer队列继续执行,setTimeout2执行了。 setTimeout1 Promise set timeout2 // 这个有点奇怪,不应该是先(readFile),再(set immedaite1)吗?这是因为io队列的放置方式有点特别,是在I/O polling 阶段放置的。 set immedaite1 readFile */
当事件循环到poll阶段,队列中有I/O事件,它会把队列中的所有I/O事件都执行完毕,但第一次进来,I/O队列是空,就要到I/O polling, I/O polling 会检查每一个I/O有没有完成,比如readFile有没有完成,在上面的程序中,它肯定是完成了,就把readFile放到I/O队列中,到底I/O polling 要polling多长时间?如果没有active handle 和active request,就不polling了,如果有close事件,也不polling了,但如果有active handle 和active request,但没有close事件呢?这要看Timer, setImmediate 有没有?如果有setImmediate,它也不会polling,如果没有,再看timer有过期的事件要处理,如果有,它也不会polling,如果没有,node会计算,到过期时间的间隔,然后等待这个间隔,如果没有setimeout和setimmediate,它会一直在这里polling,polling也就解释了服务器程序一直不停止的原因。在上面的程序中,有setImmediate,所有先执行了set Immediate 1, 再一次循环中,执行readFile。
注意一个setTimeout 0和setImmediate
setTimeout(function() { console.log('setTimeout') }, 0); setImmediate(function() { console.log('setImmediate') });
如果仅执行以上程序,输出结果不能保证。node.js内部最小的timeout是1ms,即使写了0,node.js也会把它变成1ms。当用setTimeout或setInterval 添加一个定时器时,Node.js会把定时器和相应的回调函数放到定时器堆中。每一次事件循环执行到timer阶段,都会调用系统时间,到堆中看看有没有定时器过期,如果有,就会把对应的回调函数,放到队列中。获到系统时间可能需要小于1ms,也可能大于1ms的时间。如果时间少于1ms,timer 并不过期,事件循环就会到setImmediate,如果获取时间大于1ms,过期了,它就会执行setTimeout的回调函数。怎样计算过期时间?setTimeout 返回一个timeOut对象,它有两个属性,一个是_idleTimeout, 就是setTimeout第二个参数 0ms, 一个是_idleStart:它是Node程序启动后,执行setTimeout语句时创建的时间。只要执行到timer阶段,拿获取到的系统时间减去这两个时间,就会计算出有没有过期。
异步I/O
Node.js所有I/O是异步的(libuv库提供的),但实现方式却不相同,这是因为底层的操作系统并不完全支持异步I/O。网络I/O,Linux提供epoll,Mac提供了kqueue,windows提供了IOCP( IOCP (Input Output Completion Port)),它们原生支持异步,但文件I/O不行,Linux并不支持完全异步的文件读取,只能使用线程池。只要I/O不能通过原生异步(epoll/kqueue/IOCP)来解决,就使用线程池. Node.js会尽最大可能地使用原生异步I/O, 对于那些阻塞的或非常复杂才能解决的I/O类型,它使用线程池。高CPU消耗的功能也是使用线程池,比如压缩,加密。node.js 默认开启4个线程
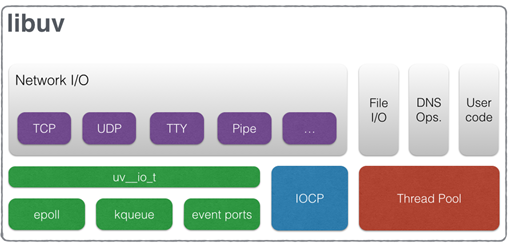
看一下下面的代码,https网络I/O,crytpo(加密)高CPU消耗,fs 文件I/O
const https = require('https');
const crypto = require('crypto');
const fs = require('fs');
const start = Date.now();
function doRequest() {
https.request('https://www.baidu.com/', res => {
res.on('data', () => {})
res.on('end', () => {console.log('http:', Date.now() - start)})
}).end();
}
function doPbkdf() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {console.log('pbkdf', Date.now() - start)})
}
doRequest();
fs.readFile(__filename, () => { console.log('fs:', Date.now() - start);})
doPbkdf();
doPbkdf();
doPbkdf();
doPbkdf();
执行结果是
http: 113 pbkdf 416 fs: 417 pbkdf 424 pbkdf 430 pbkdf 451
https是网络I/O,不走线程池,它调用epoll就返回了,等操作系统返回结果,它执行多少时间,就是多少时间,和其它函数没有关系。但Pbkdf和fs需要创建线程,由于默认4个线程,有一个pbkdf函数在等待中。
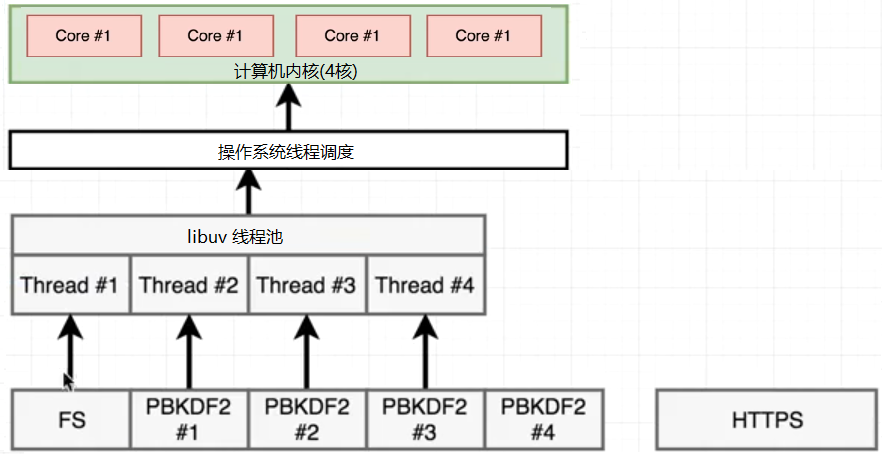
由于fs.readFile是JS层面的内容,分为好几个步骤来完成的,比如先open文件,再read文件。open后就把open的回调函数(read)放到循环队列中,fs占用的线程就释放了,所以它不会一直占用线程,libuv把这个线程给了#4,加密一直占用一个线程,当事件循环执行到read时,没有线程了,FS线程只能等待,
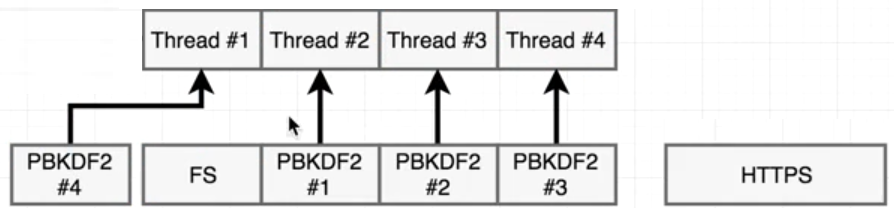
只用当一个pdkb2完成,才能有空余的线程,才能分给FS,所以结果中有一个hash比fs先返回了,现在4个线程4个任务,等待操作系统皇返回结果就可以了。libuv也会调度线程,用户态线程的调度。可以改变线程的个数,在文件的开头process.env.UV_THREADPOOL_SIZE = 5; 这时5个任务,5个线程,libuv不用调度线程,哪个执行完,哪个先返回。再次执行
fs: 14 http: 138 hash 416 hash 427 hash 444 hash 462
EventEmitter(事件发射器)
EventEmitter和events模块是纯JS层面的内容,它和事件循环没有关系,和底层的libuv也没有关系,它只是一种设计模式,事件驱动的编程方式。一个对象拥有emit和on方法,on方法就所有事件函数保存起来,当调用对象的emit,就把保存的函数,都执行一遍,什么都没有涉及,只是js层面的东西,js主线程执行,
const EventEmitter = require('node:events') const em = new EventEmitter(); em.on('myEvent', data => console.log(data)); console.log('Statement A'); em.emit('myEvent', 'Statement B'); console.log('Statement C')
输出Statement A, Statement B, Statement C, 程序同步执行,当emit事件时,所有监听这个事件的回调函数都执行一遍,再执行后面的代码。server.on('request', () => {}), fs.on("data", () => {}) 怎么解释?当server收到请求或fs读取到数据后,会把包含server.emit('request')或fs.emit(data) 的回调函数放到事件队列中,EventLoop循环到它,就在V8中执行了emit方法,也就执行了监听事件的回调函数。
Buffer
Node.js能够读取文件,能够创建服务器处理HTTP请求,它就要处理二进制数据,因为收到的都是二进制数据,最基本的就是怎么把收到的二进制数据存起来?这就是Buffer的由来,创建Buffer来存储二进制数据。由于二进制数据都是一个字节一个字节进行分割的,buffer的创建也是字节为单位,想保存多少个字节,就创建多大的buffer。Buffer.alloc(5);就创建了5个字节大小的buffer,由于程序是在内存中运行,buffer就是在内存中开辟了5个字节大小的空间,拿到Buffer.alloc的返回值,就可以操作这个buffer了。由于内存空间的分配是连续的,可以把buffer看成一个数组,数组中的每一个元素都是一个字节大小,只能存储00000000-11111111之间,就是0-255之间的数字。
const firstBuffer = Buffer.alloc(5); // 默认buffer中所有元素都是0 firstBuffer[0] = 1; // 只能赋值数字 firstBuffer[1] = 2;
const firstBuffer = Buffer.from('abc');
const secondbuffer = Buffer.from('你');
// <Buffer 61 62 63> <Buffer e4 bd a0>
// 在UTF-8下,一个英文占一个字符,一个汉字占3个字节,
console.log(firstBuffer, secondbuffer);
读取buffer,可以使用数组索引一个字节一个字节地读取,也可以使用toString()和toJSON()把buffer看成一个整体进行读取。toJSON() 返回buffer中每一个字节所对应的整数表现形式, 以十进制进行输出
const stringBuffer = Buffer.from('abc');
console.log(stringBuffer[0])
// { type: 'Buffer', data: [ 97, 98, 99 ] }
// 为了和其它JSON对象进行区分, 永远有一个type:'Buffer'属性,data属性才是整个buffer数据的整数展示形式
console.log(stringBuffer.toJSON())
toString() 就是把buffer中的二进制数字转成字符串,默认按照utf-8 进行转化。
const stringBuffer = Buffer.from('abc');
console.log(stringBuffer.toString()); //'abc'
这里一定要注意字符串转化成buffer的时候用的什么编码,调用toString转换回来的时候,就要用什么编码转换。Buffer.from('abc') 创建的buffer在内存中表现形式可以描述为 [01100001, 01100010, 01100011]。 当看到一个buffer的时候,应该看到的是0101... 的排列组合,它本身已经无法表示什么意义了。它具体什么意义,就看我们怎么读取了。如果按utf-16进行读取
console.log(stringBuffer.toString('utf16le')); // 扡
toString('utf16le') 就是按照utf-16编码来读取该buffer。utf-16,每一个字符都占两个字节,所以它就读取buffer的前两个字节:01100001 01100010, utf16le对字节进行操作的时候调换了一个顺序,01100001 01100010 转化成了01100010 01100001, 01100010 01100001 对应的十进制是25185,25185对应的unicode字符是'扡'。读完前两个字节,再往下读,还剩下一个字节, 因为不够两个字节,所以就不操作了。
修改buffer的值,可以使用数组索引的方式,和赋值一样,也可以用write() 方法,它接受一个字符串,用于替换原buffer的内容。
const stringBuffer = Buffer.from('abc');
stringBuffer.write('ABC');
// 如果写的内容多于原buffer的大小, 多余的内容会被忽略
stringBuffer.write('ABCDEF');
console.log(stringBuffer.toString()); // 'ABC',’DEF‘ 被忽略了
// 如果写入的内容少于原buffer的内容, 写入几个,替换几个
stringBuffer.write('X');
console.log(stringBuffer.toString()); // 'Xbc' 只替换掉了原buffer中的第一个字符,剩余的内容不会动
除了write()方法,还可以用copy()方法。source.copy(target). 把source中的内容复制到target。只要哪个buffer中有想要的内容,就调用copy(),传给它需要这些内容的buffer。
const uppcaseBuffer = Buffer.from('ABC');
const lowercaseBuffer = Buffer.from('abc');
uppcaseBuffer.copy(lowercaseBuffer)
console.log(lowercaseBuffer.toString()); // 'ABC'
如果只想替换某一部分内容,只把’A‘ 复制过来替换’a‘,那就给copy()多传几个参数 。source.copy(target, targetStart, sourceStart, sourceEnd)。targetStart: 目的地buffer的起始位置,把复制过来的内容从哪个位置开始替换target中的内容。sourceStart, sourceEnd, 就是表示要复制sourceStart 到sourceEnd 之间的内容。
const uppcaseBuffer = Buffer.from('ABC');
const lowercaseBuffer = Buffer.from('abc');
uppcaseBuffer.copy(lowercaseBuffer, 0, 0, 1)
console.log(lowercaseBuffer.toString()); // 'Abc'
File System 文件系统
文件就是0101的二进制序列,不论是文本文件,还是音视频文件,图像文件,在计算机中的都是0101......,没什么区别,真正的区别在于怎么解析这些二进制文件。不可能用记事本打开图片和视频文件,只能使用画图和视频软件来打开图片和视频。程序也是一样,要用正确的库来操作对应的文件。操作系统默认支持两种文件,一个是文本文件,一个是可执行文件,想要支持其他文件的操作,就要使用第三方库,比如,操作视频用ffmpeg。不论是库还是图形化界面安装的软件,它们本质上是能对0101......的二进制进行正确的解析。
在Node.js中,有三种不同的方式来操作文件,promise的方式,callback方式和同步的方式。通常情况下,使用promise的方式,考虑性能的时候使用callback,官方说callback比promise快。只有在某些特定的情况下,使用同步方式,比如启动服务器的时候读取配置文件,因为它只读取一次。
const fs = require('node:fs'); // node: 是node命名空间,node下面的什么模块
// 异步callback 方式,回调函数都是error first的形式
fs.writeFile('./data.txt', '你好', err => {
if (err) { console.error(err); }
console.log('写入成功');
})
//异步promise的形式
const fsp = require('node:fs/promises')
fsp.writeFile('./text.txt', '你好')
.then(() => {
fsp.readFile('./data.txt')
.then(data => { console.log(data.toString());})
})
.catch(err => { console.log(err); })
// 同步方式
fs.writeFileSync('./text.txt', "你好")
fs.readFileSync('./text.txt')
writeFile()向文件写数据时,如果没有文件,就创建文件,如果有文件,就把文件内容清空,再从头开始写。想在文件后面追加内容,就要提供option参数, 包含 {encoding, mode, flag}的一个对象,encoding: 指定用什么编码写入,文件中永远都是二进制数据,提供的参数是字符串,就要把字符串转换成二进制数据,默认UTF-8; mode: 文件的权限模式,默认是可读,可写。flag 表示用什么模式去写,默为是'w', 如果想追加内容,使用 'a' 就可以了。readFile把读取的二进制数据转换成字符串时,用什么编码写入的,就要用什么编码转换。
readFile()和writeFile()简单好用,但不适合大文件操作,因为它们是把文件一次性读取到内存中,再一次性写入到目的地,内存占用过大。为了粒度更小的操作文件,有了fs.open(),fs.read(), fs.write() 和fs.close()。打开文件,读或写,关闭文件。打开文件有一个参数是打开方式,只读,只写,还是既能读,又能写,打开成功返回文件描述符(打开的文件的引用),拿到它,就能操作文件,进行读写
const fs = require('node:fs');
const buffer = Buffer.alloc(3);
fs.open('./data.txt', 'r' , (err, fd) => { // r, 以只读方式打开文件
// 第二个参数buffer:读到的数据放到buffer中,第三个参数 0,表示从buffer的第0处开始放,buffer类数组
// 第四个参数buffer.length是读取多少个字节, 通常是把整个buffer都放满,所以是buffer.length
// 第五个参数 0是从源文件(data.txt)的哪个位置开始读,第一次读,肯定是从0开始
// 回调函数中readBytes从源文件中读取到多少个字节,data读取到的数据 buffer类型
fs.read(fd, buffer, 0, buffer.length, 0, (err, readBytes, data) => {
console.log(readBytes); //读取了3个字节
console.log(data.toString()); //你
})
})
buffer是3个字节大小,所以只读了一个字。为了读取完整个文件, 在读取完第一个字后,要读第二个字,也就是在回调函数中,再调用fs.read(), 不要注意参数,它不再是从源文件的0字节处开始读,而是从3字节处开始读取,就是已经读取buffer要进行累加。 fs.read的回调函数中调fs.read, 自己调用自己,递归了,所以要把fs.read 抽成 一个函数。递归肯定有结束条件。如果在fs.read()的回调函数中readbytes是0,文件没有内容可读了,就结束读取,并关闭文件
const fs = require('node:fs');
const buffer = Buffer.alloc(3);
// 从源文件的哪里开始读。
let readBegin = 0;
function myReadFile(fd) {
fs.read(fd, buffer, 0, buffer.length, readBegin, (err, readBytes, data) => {
// 文件内容最终会读完,所以最后调用fs.read读取到的字节数readBytes是0.
if (readBytes === 0) {
fs.close(fd);
return;
}
console.log(data.toString());
readBegin += readBytes; // 累加读取到的数据,下一次读取的时候从该位置读取
myReadFile(fd);
})
}
fs.open('./data.txt', 'r', (err, fd) => {
myReadFile(fd);
})
fs.write() 需要fs.open() 以写'w' 的方式打开文件
const fs = require('node:fs');
const buffer = Buffer.from("你好");
fs.open('./anoterdata.txt', 'w', (err, fd) => {
// 第二个参数buffer是要写入的内容, 可以全部写入,也可以拿出一部分写入,这就是第三个和第四个参数。
// 第三个参数是从buffer中的哪个位置开始读取,第四个参数是要从buffer读取多少个字节,一般是全部读取,0, buffer.length
// 第五个参数是从目的地文件的哪个位置开始写入
// 回调函数,也是三个参数(err, bytesWritten, buffer),error,表示写入成功或失败
fs.write(fd, buffer, 0, buffer.length, 0, (err, bytesWritten, buffer) => {
console.log("写入成功");
fs.close(fd);
})
})
和fs.read()方法一样,如果读取的要写入的内容过长,还是要递归,
const fs = require('fs');
const data = Buffer.from("你好啊");
let begin = 0; // 从哪个位置开始写入,从data的哪个位置开始读取
const size = 3; // 一次写入多少个节字
function write(fd) {
if (begin >= data.length) {
console.log("写入成功");
fs.close(fd);
return;
}
fs.write(fd, data, begin, size, begin, err => {
begin += size;
write(fd);
})
}
fs.open('./anoterdata.txt', 'w', (err, fd) => {
write(fd);
})
以r+打开文件,可以对文件进行读写,如果打开文件不存在,会报错。创建一个text.text文件,内容写abcdef. 文件可以进行读写,就分为两种情况下,先读再写,先写再读。打开文件的时候,有一个offset,默认它是0,就是游标在文件开头。先读再写的时候,先读把文件内容读完,游标到了文件末尾,再写,那就相当于追加内容。
const fs = require('fs');
fs.open('./text.txt','r+', (err,fd) => {
fs.read(fd, (err, bytes, buffer) => {
console.log(buffer.toString())
fs.write(fd, 'write this line', (err,bytes,string) => {
console.log(string)
})
})
})
先写再读,由于在默认情况下,打开文件,游标在文件开头,先写就意味着覆盖式写入,实际写多少内容,就覆盖多少内容。写入完成后,游标停留在写完的位置而不是文件的末尾,此时再进行读取,可以读出未被新内容覆盖的文档内容,如果文件内容都覆盖完了,那什么就读不出来了。
fs.open('./text.txt', 'r+', (err, fd) => {
fs.write(fd, 'write this line', (err, bytes, string) => {
fs.read(fd, (err, bytes, buffer) => {
console.log(buffer.toString())
})
})
})
以w+打开文件,也可以对文件进行读写,但w+时,没有文件会创建新文件,如果有文件,则会清空文件,r+ 则不会清空文件,所以对于w+来说,打开文件时,文件永远都是空,先读再写没有意义,只有先写再读,但先写之后,游标到了文件末尾,需要把游标放到文件开头,才能读取到刚写的内容。fs.read的第二个参数,可以接受position参数,
const fs = require('fs');
fs.open('./text.txt', 'w+', (err, fd) => {
fs.write(fd, 'write this line', (err, bytes, string) => {
fs.read(fd, { position: 0 }, (err, bytes, buffer) => {
console.log(buffer.toString())
})
})
})
fs.read()和fs.write()方法又太细节了,于是有了用流来操作文件,读文件创建可读流,写文件创建可写流。可读流pipe可写流,就可以实现文件的复制
const fs = require('node:fs'); const readStream = fs.createReadStream('./data.text'); const writeStream = fs.createWriteStream('./anoterdata.txt'); readStream.pipe(writeStream)
fs 使用相对路径读取文件时,相对路径相对的是启动node 进程时所在的路径。打开命令行窗口,当在某个路径下,启动node 程序,shell 就会把当成路径传递给node程序,fs相对路径,就是相对的传递过来的路径,比如 当前shell在用户目录下,node path/app/index.js 启动node程序,fs相对的路径就是 path/app, 可以在程序中,使用process.cwd() 来获取传递过来的路径,所以fs 读取建议使用绝对路径,__dirname配合path.join。
路径:当在node.js 文件中,使用相对路径,require(‘./file.js’), fs.readfile(‘./test.txt’), 这些相对路径是相对于哪个路径?fs模块的相对路径是相对的current work directory。在哪个目录下执行node 命令,哪个目录就是current work directory(process.cwd()方法)。’./test.txt’ 相当于process.cwd() + ‘./test.txt’. 但是commonJs 规范的require 不管current work directory,它就以它所在的文件的路径(会转换成绝对路径)作为相对路径的开始。想在任何地方执行程序,fs的路径需要使用绝对路径,__dirname, 可以在任何地方,执行node命令
简单说一下process和path对象。node index.js会创建一个进程,process对象就代表这个进程。因此,可以通过process对象获取到进程执行相关的信息,比如环境变量,程序执行时的参数,标准输入,输入流等。process.env获取整个环境信息,比如用户名,PATH环境变量。process.env[变量名],获取某个环境变量,在linux终端 NODE_ENV=prod node index.js, process.env.NODE_ENV就能获取到prod。process.argv获取命令行参数。process.exit()退出程序。path操作文件和目录的路径,basename(),
const path = require('path');
const filename = "/home/sam/Documents/node-learning/main.js";
const directoy = "/home/sam/Documents/node-learning/";
// basename(): 获取路径的基础名称
console.log(path.basename(filename)) // main.js
// basename(filename, '.js'), 第二个参数 去掉指定的后缀
console.log(path.basename(filename, '.js')); // main
// 如果参数是目录,返回最后一个,后面的/(node-learning/) 会去掉
console.log(path.basename(directoy)) // directoy
path.join和path.resolve(),拼接多个路径片段,只不过path.join并不是总会返回绝对路径,如果拼接的字符串是相对路径的话,它返回的是相对路径。比如 path.join('./a', 'b') 返回的是'a/b', 并不是绝对路径, 拼接的字符串是绝对路径,才返回绝对路径,resolve() 永运 返回绝对路径。parse() 解析路径,返回一个对象
const path = require('path');
const filename = "/home/sam/Documents/node-learning/main.js";
const directoy = "/home/sam/Documents/node-learning/";
/* 参数是文件
{
root: '/',
dir: '/home/sam/Documents/node-learning',
base: 'main.js',
ext: '.js',
name: 'main'
}
*/
console.log(path.parse(filename))
/* 参数是目录,
{
root: '/',
dir: '/home/sam/Documents',
base: 'node-learning',
ext: '',
name: 'node-learning'
}
*/
console.log(path.parse(directoy))
流
流处理数据,是把数据分割成一块一块的进行处理。数据读取时,读取到一块内容,就会发送事件,有机会去处理这一块内容。读取一块数据,处理一块数据,数据不会一直占用内存中,内存使用效率高,更有可能来处理大文件。数据的写入也是一块一块写,比如网络下载,服务器一块一块地写数据,浏览器一块一块的读数据,时间高效。在Node.js中,有4种流:
可读流(readable stream): 从里面读取数据的流。它负责从数据源里读取数据(到内存),程序负责从它里面读取数据,把它看作数据源的抽象。
可写流(writable stream): 向里面写入数据的流,程序向可写流里写入数据(把内存中的数据写入到可写流中),它负责向目的地写入数据,它是目的地的抽象。
双向流或双工流(duplex stream): 既可以从它里面读取数据,也可以向它里面写入数据。
转换流(transform stream):特殊的双工流,向它里面写入数据,它可以对写入的内容进行转换,然后把数据放到它的读端,可以从里面读取到转换到后的内容。
可读流
可读流有两种模式:pause和flow。pause是默认模式,就是创建可读流后,它并不会从数据源中读取数据,
const fs = require('fs');
const readable = fs.createReadStream("a.txt");
setInterval(() => {
// 监听可读流读取了多少数据
console.log(readable.bytesRead, 'bytesRead')
}, 1000);
// readable.on('readable', () => {})
控制台永远输出0,不会读取数据。继续使用pause模式,为了让可读流从数据源中读取数据,需要监听readable事件,打开程序最后一行注释,控制台永远输出65536 bytes (64kb),程序读取64kb的内容,也不会再读了, pause了。这是因为在pause模式下,可读流使用了缓冲区技术,它内部有一个缓冲区,默认大小64kb,可读流读取数据到缓冲区中,当认为数据可读时,发出readable事件。如果监听readable 事件,并没有提供处理函数, 可读流填充满缓冲区就不读了,它并不会从缓冲区中删除数据。readable事件处理函数就要从缓冲区读取数据,清空缓冲区,调用可读流的read()方法。
const fs = require('node:fs');
const readable = fs.createReadStream("a.txt");
readable.on('readable', () => {
console.log('readable event')
let chunk;
// read() 方法,如果从缓冲区读取不到数据,就会返回null。
while (null !== (chunk = readable.read())) {
console.log(chunk.length)
}
});
read方法还可以接受一个参数,表示一次从缓冲区读取多少字节,如果没有提供参数(像上面一样),就把缓冲区的所有数据全读取出来,上面的程序中控制台先输出65536 就是证明。给read参数提供30000
const fs = require('fs');
const readable = fs.createReadStream("a.txt");
readable.on('readable', () => {
console.log('readable event')
let chunk;
while (null !== (chunk = readable.read(30000))) {
console.log(chunk.length)
}
});
/** read 从缓冲区中一次读取30000 byte
readable event
30000
30000
readable event
30000
readable event
125
*/
这时发现一个现象,提前读取,当buffer 中数量少时,会提前读取。程序每次从缓冲区拉取数据,当缓冲区的数据较少时,可读流就会进行读取操作,填充空余的缓冲区,发出一次readable事件。pause 模式下,监听readable事件,事件处理函数中调用read()方法,处理数据,如下图所示
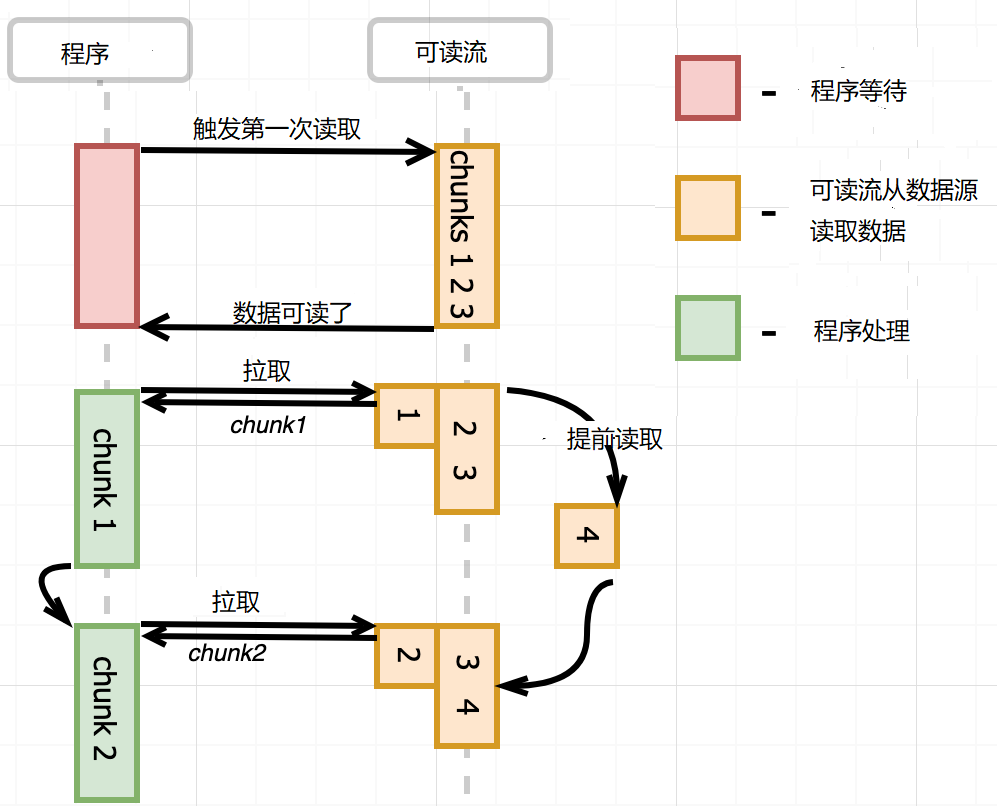
但有时候,异步的数据处理逻辑,需要等到buffer中的数据全部读取完毕,再触发下一次读取,不需要提前读取,这就要使用once,手动添加readable 事件。
const fs = require('fs');
const stream = fs.createReadStream('a.txt');
stream.once('readable', consume); // 触发第一次可读流读取操作
async function consume() {
let chunk;
// 消费数据,
while ((chunk = stream.read()) !== null) {
await asyncHandle(chunk);
}
//消费完毕,触发另一次可读流的读取操作
stream.once('readable', consume);
}
async function asyncHandle(chunk) {
console.log(chunk);
}
说完pause,再说flow。监听可读流的data事件,流就自动转化成flow模式,不停地从数据源中读取数据,读取一块数据,就发送data事件,它不管你处不处理,也不管你处理的快慢,它就是按自己的速度读取数据,直到读完为止。
const fs = require('fs');
const readable = fs.createReadStream("a.txt");
setInterval(() => {
// 监听可读流读取了多少数据
console.log(readable.bytesRead, 'bytesRead')
}, 1000);
readable.on('data', () => {})
控制台显示了整个文件的大小,没有处理data事件,仍然从源中读取数据。
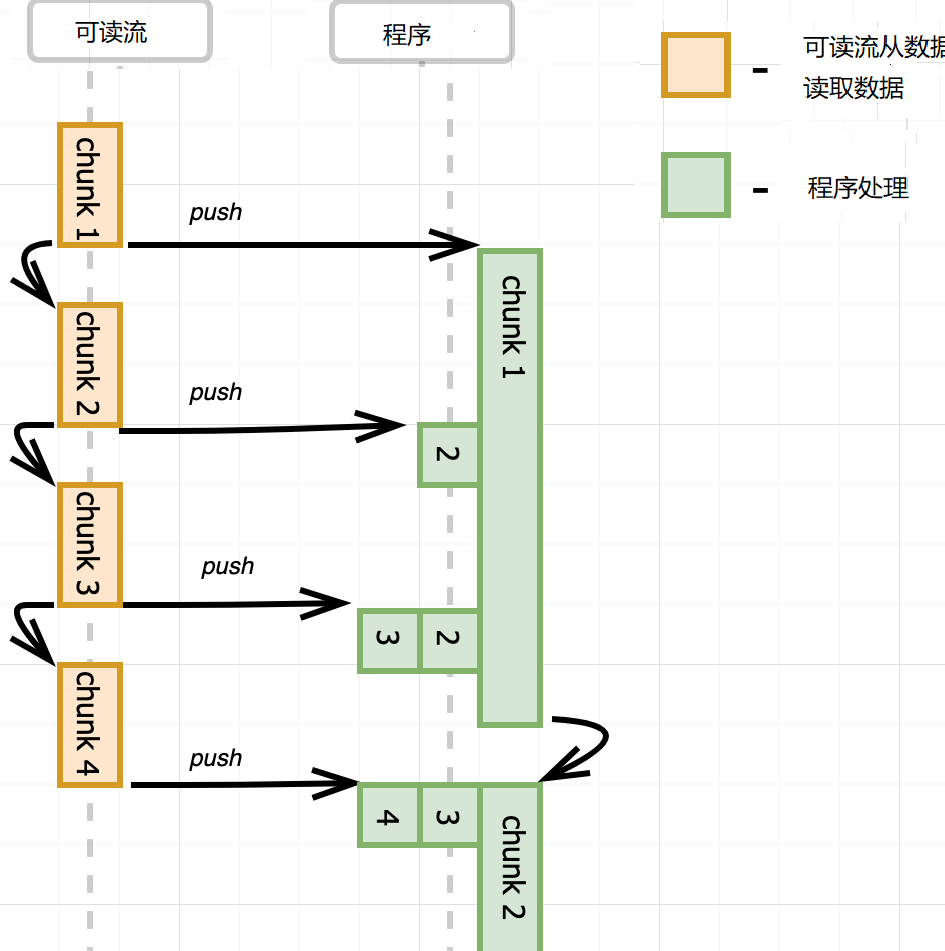
这就有一个问题,可读流推送数据太快,事件处理函数处理太慢,要么丢失数据,要么无限缓存,消耗大量内存。比如data事件处理函数中,把数据写入到另外一个文件,写入很慢。怎么办?可写流默认内置了一个缓冲区,数据先写到缓冲区,再写入到目的地。如果缓冲区满了,那不要再写数据了,等清空缓冲区,再写入数据,这就是背压(backpressure)。
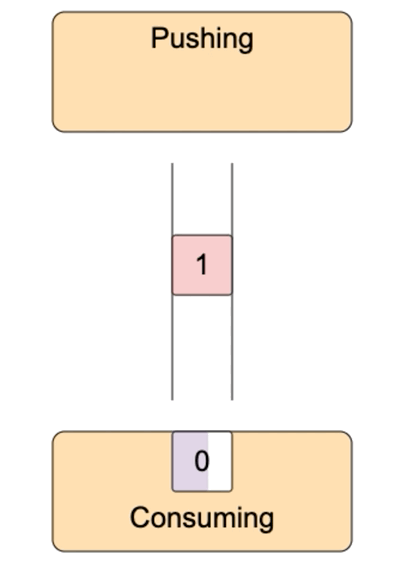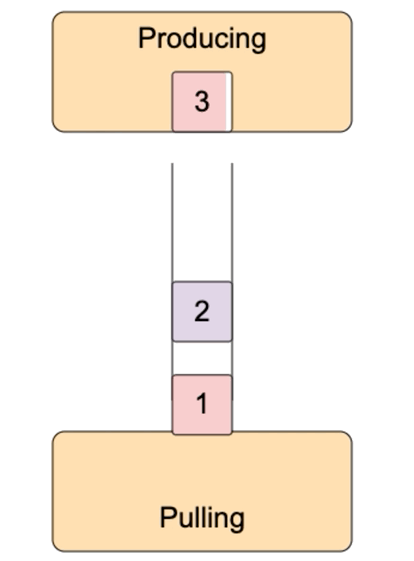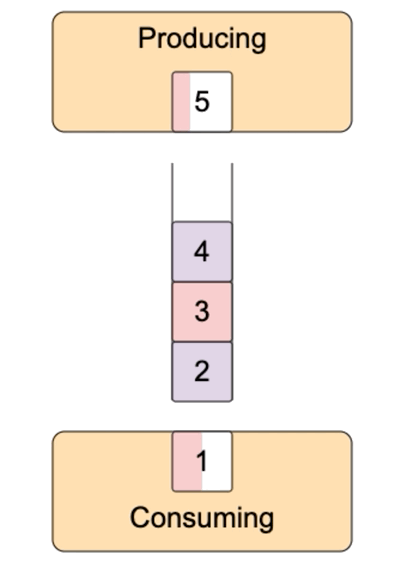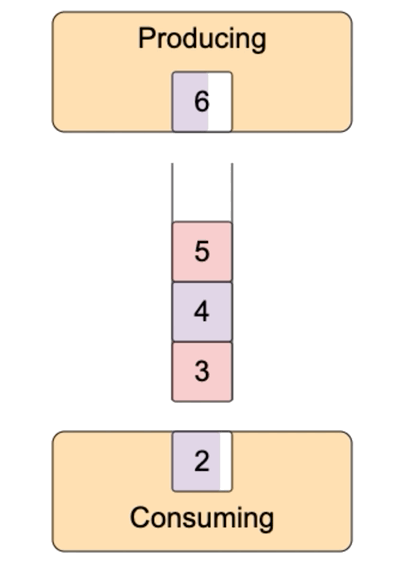
可写流write方法返回true表示写入成功后内置的buffer仍有空闲,仍然可以写入。返回false表示写入后内置的buffer满了,不能再写入了。可写流写入到目的地后,内部的buffer就有空闲,它就会发出发出drain事件,收到drain事件,就可以继续向可写流中写入数据了。
const fs = require('fs');
const readable = fs.createReadStream('./biji.txt');
const writeable = fs.createWriteStream('anotehr.txt');
readable.on('data', (data) => {
if (!writeable.write(data)) {
readable.pause();
writeable.on('drain', () => {
readable.resume();
})
}
})
监听可读流的data事件,可读流去读取数据,同时在事件监听函数中,调用可写流的write()方法写入数据。如果write()返 回false, 可读流就就要暂停读取。同时,可写流要监听'drain'事件,在事件中调用可读流的resume()方法。一旦在可读流的buffer中有空间,可写流发出'drain'事件,继续可读流的读取数据。Node.js对这些操作进行了抽象,形成了pipe方法,readableStream.pipe(writeStream); 可读流的内容向可写流里面写。同时pipe返回第一个参数,如果第一个参数是转换流或双工流,pipe写到它们的可写端,由于又返回了它们,它们有可读端,可以继续从里面读取数据,形成pipe的链式调用。

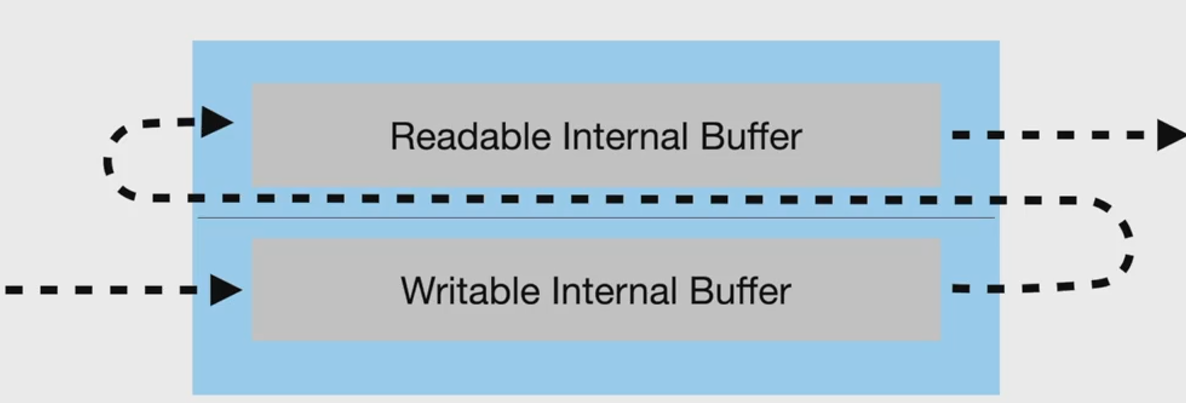
双工流内部有读缓冲区和写缓冲区,可读可写,写就写到它的写缓冲区中,读就从它的读缓冲区中读取数据,读缓冲区和写缓冲区可以没有任何关系,只有net模块使用了双工流。
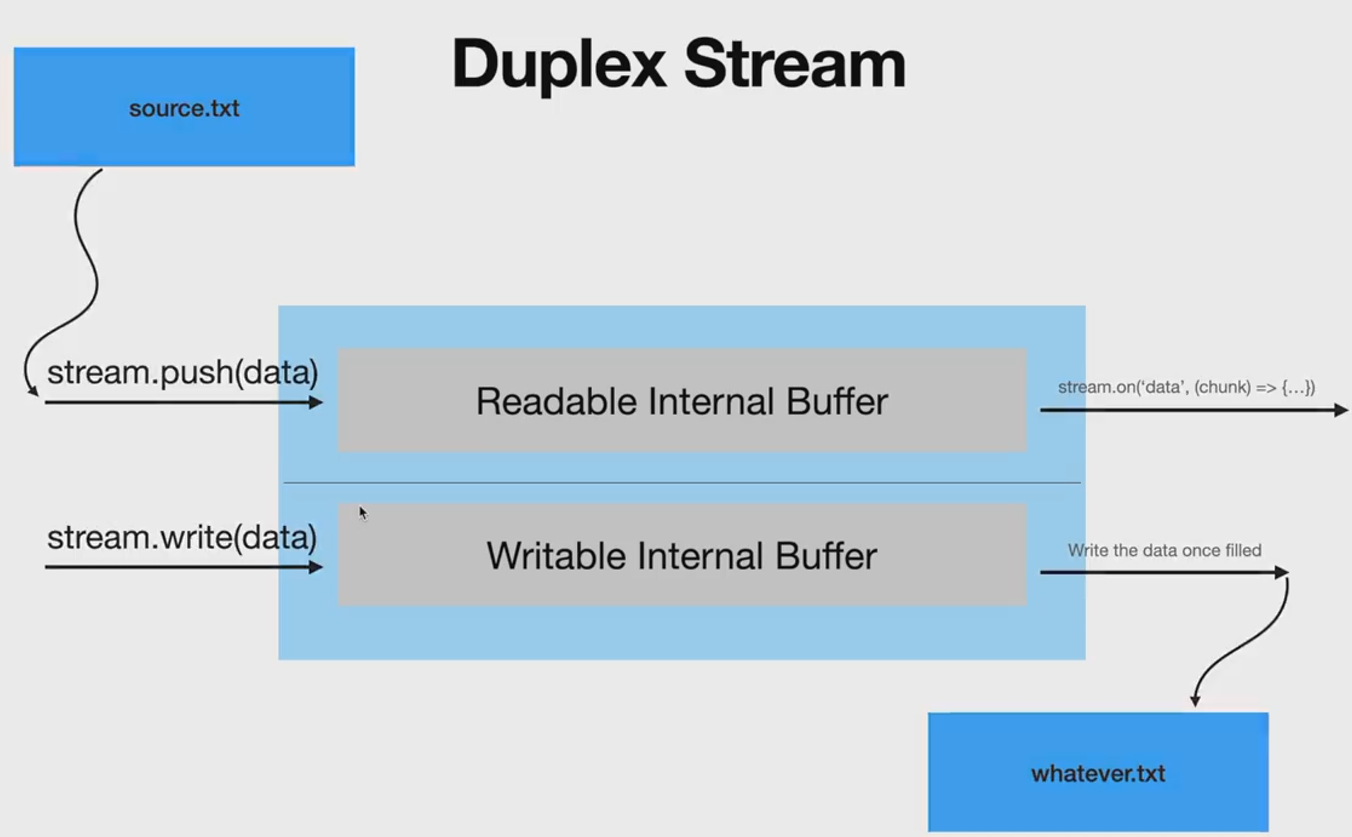
转化流是特殊的双工流,调用它的write方法写入到内部的写缓冲区中,然后它自己把写缓冲区中的数据放到它内部的读缓冲区中,外界监听可读流事件读取转化流中的数据。写入的数据成为可读的数据,当然写缓冲区数据到读缓冲区之间,可以对数据做转化,如果对数据什么都不做,就成了pass through流了。转化流内部的write和read方法,只是从两个缓冲区中搬运数据。
whateveer stuff you write to the stream will be the source of the readable side, it will also do some operations on the writtend data before putting into the readable side(如果写了转换函数)
zlib模块是转化流,对文件压缩和解压缩。
const { createGzip } = require('node:zlib'); const { createReadStream, createWriteStream } = require('node:fs'); const gzip = createGzip(); const source = createReadStream('input.txt'); const destination = createWriteStream('input.txt.gz'); source.pipe(gzip).pipe(destination)
pipe的使用并没有处理error,如果pipe出现了error怎么办?使用pipe()方法,并不会关闭流发出事件。事件依然有效,可以监听source,gzip,destination流的error事件,但这样不太友好,用pipeline方法,第一个参数是readableStream, 中间参数是0,1,或多个转化流,后面再跟可写流,最后一个参数是回调函数,pipeline完成后,执行的回调。source.pipe(gzip).pipe(destination) 换成
const { pipeline } = require('node:stream');pipeline(source, gzip, destination, (err) => { if (err) { console.error('An error occurred:', err); process.exitCode = 1; } });
自定义转换流就是继承Transform, 重写_transfrom方法和可选的_flush方法。 _transform的三个参数是 chunk(数据), encoding(字符编码), 和callback(回调函数),它的作用就是读取上游传递过来的数据,然后把转换后的数据再push回去。_flush则是,如果上游发送的数据完了,但在 transform流中还有数据,那就在_flush中把剩余的数据push出去,它接受一个回调函数,也是通知的作用
const { Transform } = require('stream');
class MyTransform extends Transform {
_transform(chunk, encoding, callback) {
var upperChunk = chunk.toString().toUpperCase();
this.push(upperChunk); // 调用push方法,向流中push数据。
callback();
}
}
流还有一种Object 模式,流中流动的是object对象,一个对象一个对象的流动。
const { Transform, Readable } = require('node:stream') class SumProfit extends Transform { constructor(opts = {}) { super({ ...opts, readableObjectMode: true, writeableObjectMode: true }) this.total = 0; } _transform(record, encoding, cb) { this.total += JSON.parse(record).profit; cb(); } _flush(cb) { this.push(this.total.toString() + ' \n') cb() } } // Readable.from创建可读流,默认是Object模式,流中都是object。一个元素一个object。 // 由于流中只能是字符串,buffer,所以要把对象进行序列化,转化成字符串 // 可读流,还会触发end事件 const objRead = Readable.from([ JSON.stringify({profit: parseInt(Math.random() * 100)}), JSON.stringify({profit: parseInt(Math.random() * 100)}) ]) objRead.pipe(new SumProfit()).pipe(process.stdout)
当可读流读取到数据时给转换流时,一次data事件,一次_transform函数的调用。当可读流中没有数据,它就不调_transform了,但转化流中还存在this.total 数据没有处理,当可读流发出end事件之前时,转换流的_flush方法会被调用,所以正好利用这个机会,在_flush方法中把this.total 放到转化流的可读缓冲区。实现可读流的时候,一定要表示可读流结束,实现可写流时,也要表示结束
const { Readable } = require('node:stream') const objRead = new Readable({ objectMode: true }); objRead._read = () => {}; let i = 0; const id = setInterval(() => { objRead.push(JSON.stringify({ profit: parseInt(Math.random() * 100) })); i++ if( i == 10) { objRead.push(null); // push(null) 可读流读取数据结束了 clearInterval(id) } }, 100);
Socket 网络编程
两台计算机要进行通信,首先要能找到对方,然后发送消息。操作系统实现了TCP/IP协议,帮我们寻找对方,发送消息。怎样使用TCP/IP协议呢?Node.js提供了net模块,可以直接使用TCP的传输功能,创建TCP server 和 TCP client,client发送数据给server,server 返回数据给client,实现通信,通信的两端称为socket。创建server.js
const net = require('node:net');
const server = net.createServer(); // 创建服务器
// 监听客户端连接,连接成功,socket就是对应的客户端标记
server.on('connection', (socket) => {
//socket是一个双工流,接收客户端发送过来的数据,就监听data事件,
socket.on('data', (data) => {
console.log(data)
})
socket.on('end', () => {
console.log('end')
})
})
// 监听3000 端口
server.listen(3000, '127.0.0.1', () => {
console.log("server")
})
client.js
const net = require('node:net');
const socket = net.createConnection({ // 连接server
host: 'localhost', port: 3000
}, () => { // 成功连接后,执行回调函数
socket.write('hello')
socket.end() // 断开连接
})
node server.js, 然后node client.js 成功发送消息。创建一个文件发送和接收服务,server.js
const net = require('net');
const fs = require('node:fs/promises');
const server = net.createServer();
let filehandler;
let writeStream;
server.on('connection', (socket) => {
socket.on('data', async (data) => {
if (!filehandler) {
// data事件触发太快,而fs.open太慢,比如data 事件发生了5次,
// fs.open才打开,那这5次事件,fs.open就要执行5次。
// 所以,没有打开文件,就不接收数据了,等打开文件后,把已经接收到数据写入,再开始接收数据。
socket.pause();
const indexOfDivdier = data.indexOf('-------');
// 客户端写过来的数据是 filename: ddddd.txt-----
// 由于是filename: 占10个字节,所以从10开始截取。
const fileName = data.subarray(10, indexOfDivdier).toString();
filehandler = await fs.open(`storage/${fileName}`, 'w');
writeStream = filehandler.createWriteStream();
// 从 ------- 后面开始写
writeStream.write(data.subarray(indexOfDivdier + 7));
socket.resume()
writeStream.on('drain', () => {
socket.resume()
})
} else {
if (!writeStream.write(data)) {
socket.pause()
}
}
})
socket.on('end', () => {
console.log('end')
filehandler.close()
// 虽然把流关了,但是 filehander 仍然存在
filehandler = null;
writeStream = null;
})
})
server.listen(3000, '127.0.0.1', () => {
console.log("server")
})
client.js
const net = require('net');
const fs = require('node:fs/promises');
const path = require('path');
const socket = net.createConnection({
host:"localhost", port: 3000
}, async () => {
// 启动客户端时用 node client text.txt
const filePath = process.argv[2];
// filePath是绝对路径,所以取basename。
const fileName = path.basename(filePath);
const filehandler = await fs.open(filePath, 'r')
const fileReadStream = filehandler.createReadStream();
// showing the upload process
const fileSize = (await filehandler.stat()).size;
let uploadedPercentage = 0;
let bytesUploaded = 0;
socket.write(`fileName: ${fileName}-------`);
fileReadStream.on('data', data => {
if(!socket.write(data)) {
fileReadStream.pause()
}
bytesUploaded += data.length;
let newPercentage = Math.floor(bytesUploaded / fileSize * 100)
// 因为有太多的data事件,不想展示太多
if(newPercentage % 5 === 0 && newPercentage !== uploadedPercentage) {
uploadedPercentage = newPercentage;
console.log('Uploading.........')
}
})
socket.on('drain', () => {
fileReadStream.resume()
})
fileReadStream.on('end', () => {
console.log("The file was successfully uploaded");
socket.end()
})
})
在client和server 同级目录下,创建text.txt和storage文件夹,node server.js 启动服务, node client.js text.txt, 文件成功上传。上面有一个细节需要注意,client在发送消息的时候,先发送filename: ----, 再发送数据,而服务端解析的时候,也是认定先有filename:,占10个字节,然后解析文件名,读取数据。这就是一种协议,只不过是自己定义的,只要向服务器发送数据,就先发filename:--再发送数据,因为都是0101序列,需要按照某种格式进行解析。只要有人向服务端发送数据,你就要告诉他,先发送filename: ---再发送数据,非常麻烦,于是就出现了标准化的协议,HTTP,FTP等, HTTP协议只是规定了发送消息的格式,好让客户端和服务端都能正确的解析数据。
HTTP
http协议只是规定了发送消息的格式。客户端向服务端发送消息,要有请求头,如果有数据,还要有请求体,请求头包含请求方法,请求路径,如果有请求体,请求头还要包含请求体的格式。服务端向客户端发送消息的时候,也要告诉客户端端发送的是什么。Content-Type表示什么类型,它的值MIME(media type)。media type的格式是 type/subtype,比如text/css,它还有一个可选的key=value, 比如text/html;charset=utf-8. 还有一种type是multipart, 比如文件上传,multipart/form-data。Content-Length 表示发送了多少个字节。创建http服务器,它就帮你把客户端发送过来的请求解析完成,封装了request对象中,同时把客户端连接封装到response对象中。http服务器程序,只操作两个对象,一个是request对象,表示请求,有method, url,headers等属性, 一个是response对象,用于响应,主要有setHeader,write,end方法,向客户端写入数据。当用write的时候,一定要调用end表示结束,因为写入的都是buffer,客户端也不知道什么时候结束,就一直等待。get请求比较简单,就是服务器返回数据。
const http = require('node:http'); //node: 表示它是node内置的module,不是第三方module。
const fs = require("node:fs/promises")
const server = http.createServer()
server.on('request', async (request, response) => {
if (request.url === '/' && request.method === 'GET') {
response.setHeader("content-type", 'text/html');
const fileHanlde = await fs.open('./public/index.html', 'r');
const fileStream = fileHanlde.createReadStream();
fileStream.pipe(response)
}
if (request.url === '/styles.css' && request.method === 'GET') {
response.setHeader("content-type", 'text/css');
const fileHanlde = await fs.open('./public/styles.css', 'r');
const fileStream = fileHanlde.createReadStream();
fileStream.pipe(response)
}
if (request.url === '/scripts.js' && request.method === 'GET') {
response.setHeader("content-type", 'text/javascript');
const fileHanlde = await fs.open('./public/scripts.js', 'r');
const fileStream = fileHanlde.createReadStream();
fileStream.pipe(response)
}
})
server.listen(3000, () => {
console.log('server listening on 3000')
})
post请求会携带数据,所以要确定数据类型,不同的类型,不同的处理方式。request对象是一个可读流,发送过来的数据在流中,只要监听data事件,就能获取post发送过来的数据,request有一个header属性,它有一个content-type,可以知道发送过来的是什么类型。如果是发送的form表单,可以这么处理
function post(req, res) { if (req.headers["content-type"] === "application/x-www-form-urlencoded") { const input = []; req.on("data", (chunk) => { input.push(chunk); }); req.on("end", () => { const parsedInput = Buffer.concat(input).toString() // 告诉客户端已经写完了。write只是写trunk,没有结束标志 res.end(http.STATUS_CODES[200] + " " + parsedInput); }); } }
如果发送过来的是json数据
function post(req, res) { if (req.headers["content-type"] === "application/json") { const input = []; req.on("data", (chunk) => { input.push(chunk) }); const parsed = JSON.parse(Buffer.concat(data).toString()); if (parsed.err) { error(400, "Bad Request", res); return; } console.log("Received data: ", parsed); res.end('{"data": ' + input + "}"); } }
上传文件则比较复杂,Browsers embed files being uploaded into multipart messages。 Multipart messages allow multiple pieces of content to be combined into one payload. To handle multipart messages, we need to use a multipart parser. 这里要用到第三方模块formidable
function post(req, res) { if (/multipart\/form-data/.test(req.headers["content-type"])) { const form = formidable({ multiples: true, uploadDir: "./uploads", }); form.parse(req, (err, fields, files) => { if (err) return err; res.writeHead(200, { "Content-Type": "application/json", }); res.end(JSON.stringify({ fields, files, })); }); } }
http 模块还能请求别的服务器。它有一个get方法,可以直接发送get请求
const http = require("http");
http.get("http://jsonplaceholder.typicode.com/posts/1",
(res) => res.pipe(process.stdout));
发送post请求,则使用http.request()方法,它的第一 个参数是对象,配置post请求的参数,比如hostname, 第二个参数就是回调函数,接受返回的数据
const http = require('http');
const payload =JSON.stringify({
name: "Beth",
job: "Web"
})
const opts = {
method: "POST",
hostname: "postman-echo.com",
path: "/post",
header: {
"Content-type": "application/json",
'Content-Length': Buffer.byteLength(payload)
}
}
const req = http.request(opts, (res) => {
res.setEncoding('utf8');
res.on('data', (chunk) => {
console.log(`BODY: ${chunk}`);
});
res.on('end', () => {
console.log('No more data in response.');
});
});
req.on('error', (e) => {
console.error(`problem with request: ${e.message}`);
});
// 发送post请求,带着数据,也可以直接res.end(payload)
req.write(payload);
req.end();
当用http.request,如果调用write方法写数据时,一定要调end方法,告诉server写完了, 因为它的发送就transfer coding 是buffer,服务端也不知道写没写完。const request = http.request() request.write(); request.end()。如果不调用end(), 要在request的header里面写content-length, 告诉服务器器发送了多少数据,服务器直接读取这么些数据,就可以了。
在http 中,发送双方要告诉对方,它发送的是什么内容?就是content-type,这样才能够正确的解析他们。类型是怎么定义的,type类型,一个类型下面有好多子类型,png,jpg,
Type/subtype. Media type类型分为两类,Discrete type 和multipart, discrete 表示只有一个文件,multipart 表示有多个文件,都是指的发送的数据(message)中
Node.js 设计模式
API设计要么全同步,要么全异步,如果读取了数据并缓存,下一次从缓存中读取数据,它是同步的,可以使用process.nextTick 来让它变成异步。
function readFileIfRequired(cb) {
if (!content) {
fs.readFile(__filename, 'utf8', function (err, data) {
content = data;
console.log('readFileIfRequired: readFile');
cb(err, content);
});
} else {
process.nextTick(function () {
console.log('readFileIfRequired: cached');
cb(null, content);
});
}
}
代理模式:代理是一个对象,它控制着对另一个对象的访问。代理对象和被代理对象有相同的接口(方法)。代理拦截对被代理对象的部分或所有操作,然后进行增强或补充这个形为。
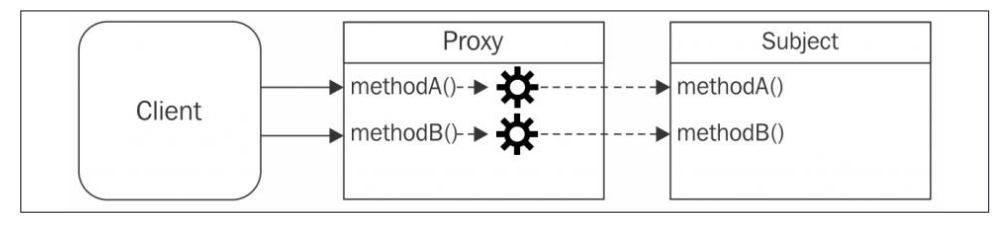
The proxy forwards each operation to the subject, enhancing its behavior with addtional preprocessing or postprocessing. 创建代理对象后,都是直接访问代理对象,因为代理对象做了增强。
装饰器模式:动态地增强原对象的功能,我们还是调用原对象,不过执行的是装饰后的方法。dynamically augmenting the behavior of an existing object.
an adapter converts an object with a given interface so that it can be used in a context where a different interface is expected.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号