
MongoDB 学习
MongoDB 简介
MongoDB是一个文档数据库,但文档并不是一般理解的pdf, word文档,而是JSON对象,因为文档来自于“JSON Document”(JSON文档),所以MongoDB是存JSON对象的数据库,比如{"greeting”: "hello world"}。说起文档,想到的应该是JSON对象,所以文档中的键都是字符串,任何utf-8字符都可以,但不能包含\0(空字符),因为它表示键的结束,最好也不要包含$和 .,因为它们有特殊的意义, 只在某些特殊场合使用。文档中的值却有多种类型,1,String: utf-8 编码;2,Number类型,默认是double类型,{"x": 3}, {"x": 3.14}, 如果使用整数,要使用NumberInt 和NumberLong. {"x": NumberInt("3")};高精度的小数NumberDecimal, 128个bit,小数点后面34位,它们的参数最好用字符串。3,布尔类型;4,对象类型,也称嵌入式文档,比如下面的address的值就是Object类型或嵌入式文档
{
"name": "John Doe",
"address": {
"street": "123 Park Street",
"city": "Anytown",
"state": "NY"
}
}
5,数组类型; 6 Null 类型;7, ObjectId类型,MongoDB中的每一条文档,都有一个"_id"属性,表示这条文档的唯一性。它的值可以是任意类型,默认是ObjectId类型,插入文档时,没有插入"_id", MongoDB会自动生成_id,{"_id": ObjectId()};8,Date类型, MongoDB把时间存储为64位的整数,代表Unix时间的毫秒数。所以在JS中,Date类可以用于MongoDB的date类型,调用new Date(),比如{"x": new Date()}。9,正则表达式,{"x": /\d/}。Mongodb是类型敏感和大小写敏感,{"count" : 5}和{"count" : "5"}, {"count" : 5} 和{"Count" : 5}都是两条不同的文档,但一条文档中不能有相同的key值。{"greeting" : "Hello, world!", "greeting" : "Hello, MongoDB!"}是不允许的。
MongoDB并不是直接存储文档,而是把文档放到集合中。通常来讲,放到一起的东西都要有共同点,比如集合中的每一条文档(JSON对象)都有相同的属性(形状),但MongoDB并没有要求这一点,下面两条完全不一样的文档就可以放在同一个集合中
{"greeting" : "Hello, world!", "views": 3}
{"signoff": "Good night, and good luck"}
这也称MongoDB无Schema。那是不是意味着,所有的文档都放到一个集合中?也不是,首先文档的大小有限制,一个文档最大16MB。再者文档也有嵌套层级的限制,最多100级,最后,也是最重要的一点,不相关的内容放到一起,不好用 ,尤其是查询。在MongoDB的文档中,不存在的字段,总是被看成是null。如果要查询字段的值不等于某个值,null和某个值也不相等,也会查出这条文档。最好相同形状(Schema)的文档放到一个集合中。集合名,也是任意的utf-8字符, 但不能是空字符串,也不能包含\0, 不要使用 system.开头,不要包含$符。集合名称有一个惯例,就是使用命名空间的子集合,用. 号隔开。比如 blog.posts, blog.authors.
多个集合放在一起就组成了数据库,一个应用的所有数据都放到一个数据库中。数据库的名字,是不区分大小写的,最长是64个字节。把数据库的名字和集合的名字合在一起,就形成了一个完整的集合的名字, 称为命名空间。如果cms数据库下面有blog.posts集合,那么命名空间就是cms.blog.posts, 命名空间的最大长度是120个字节,但在实际中,最好不要超过100个字节。
所以在使用MongoDB数据库时,要先有数据库,再有集合,最后才在集合中增删除改查文档。
安装和连接MongoDB服务器
在Linux下,官网下载 .tgz 文件(mongodb-linux-x86_64-ubuntu2004-7.0.11.tgz),默认下载到了下载目录,进入到下载目录
tar -zxvf mongodb-linux-x86_64-ubuntu2004-7.0.11.tgz # 解压 mv mongodb-linux-x86_64-ubuntu2004-7.0.11 mongodb # 重命名 mv mongodb /opt #移动到/opt 目录 sudo ln -s /opt/mongodb/bin/* /usr/local/bin/ # 创建命令的软链接 sudo mkdir -p /data/db/ # 创建mongodb的默认数据存储路径,mongodb启动时自动寻找
sudo mongod 启动服务。安装图形化界面工具MongoDB Compass,它是一个.deb 包,直接双击就能安装 。打开软件,
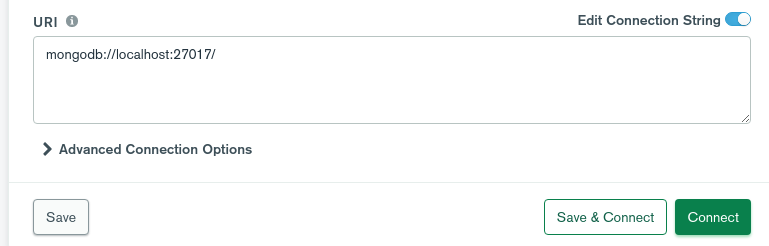
点击Save,输入名称,把这个连接保存起来,点击Connect 进行连接,弹出的界面中,最底部有一个_MONGOSH,点击,弹出命令行shell,就可以输入命令。

shell自动连接到test数据库。如果要创建或切换数据库,就要使用use 数据库名,比如 use mflix。如果mflix数据库存在,则切换到mflix。如果数据库不存在,则先创建再切换,但此时,mflix数据库只是在内存中,不会在硬盘中创建数据库。如果show dbs, 是查不到mflix数据库的。只有在向数据库中插入数据的时候,才会在硬盘真正创建数据库。切换成功,这个数据库连接就赋值给全局变量db,通过db变量就可以操作数据库了。在shell中,输入db,按enter,就可以看到连接或操作的是哪个数据库。db.[集合名]就可以获取当前数据库下面的任意一个集合,就可以进行增删除改查了。
MongoDB 数据库操作
创建集合:可以通过createCollection()方法,比如db.createCollection('movies'),也可以通过向不存在的集合中插入文档的方式来创建集合。当向一个集合中插入文档时,MongoDB会先检查这个集合是否存在,如果不存在,则先创建这个集合,再执行插入操作。
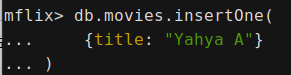
db.movies.insertOne( {title: "Yahya A"} )
movies集合创建成功,同时插入数据。如何在shell中多行输入呢?第一行输入命令,以左括号(结束,再shift+enter 换行,想要输入多少行内容,就按多少shift+enter,想要结束命令,输入右括号),按enter, 执行命令。
show collections 可以显示数据库中有多少个集合。如果没有集合,则什么都不显示。
插入文档:除了insertOne() 插入一条文档外,还有insertMany()插入多条文档。insertMany() 接受数组,数组中的每一个元素都是一条文档
db.movies.insertMany( [ { "title": "Blacksmith Scene", "rated": "UNRATED", "year": 2020, "awards": { "wins": 1, "nominations": 0, "text": "1 win." }, "comments": [{ "rating": 6.2, "votes": 1189 }] }, { "title": "The Great Train Robbery", "languages": [ "English" ], "rated": "TV-G", "year": 2022, "awards": { "wins": 1, "nominations": 0, "text": "1 win." }, "comments": [{ "rating": 7.4, "votes": 9847 }] }, { "rated": "PASSED", "title": "In Old Arizona", "year": 2024, "languages": [ "English", "Spanish", "Italian" ], "awards": { "wins": 1, "nominations": 4, "text": "Won 1 Oscar. Another 4 nominations." }, "comments": [ { "rating": 5.8, "votes": 576 }, { "rating": 7.2, "votes": 600 } ] } ] )
插入多条文档,会有一个问题,如果中间的数据出错,怎么办?默认有序插入(一条一条插入),如果出错了,出错的那一条数据的前面的数据,都会插入到数据库里面,后面的数据就不会插入到数据库里面。不过,插入的方式可以配置,insertMany接受第二个参数,是个对象,它有一个ordered属性,值是true, 表示有序插入,值为false,表示无序插入的,默认值是true。无序插入,就是能插入的都插入,只有出错的数据不会插入。
查询文档:find()和findOne() 。find()返回符合条件的所有文档,findOne返回符合条件的一条文档。使用方式都一样, 两个可选参数(查询条件和投影),投影就是要显示哪些文档字段,查询是整条文档都查询出来,但我们只需要文档的某些字段,就是投影。find()如果没有查询条件,就是使用默认参数{},find()或find({}) 将返回集合中的所有文档,但通常都会有查询条件。查询条件是个对象,键表示查询哪个字段,值表示符合什么条件。条件可简单,可复杂,简单的话,就是基本类型,db.movies.find({"title" : "Blacksmith Scene"})。复杂的话,就是个对象,使用各种操作符,正则表达式,数组和嵌入式文档等。
比较操作符: $eq(等于),$ne(不等于),$gt(大于), $gte(大于等于), $lt(小于), $lte(小于等于),使用方式是 {字段名:{操作符: 值}},比如,
db.movies.find({ "rated": { $eq: "UNRATED" } })
要注意的是$ne,会查出不包含查询字段的文档,
db.movies.find({ "rated": { $ne: "UNRATED" } })
/* 结果中有{ _id: ObjectId("6653070b0a2ddb2e92ae720d"), title: 'Yahya A' },但它并没有rated的字段*/
在MongoDB中,如果文档中没有某个字段时,这个字段的值为null,null和查询条件并不相等,所以就出现了,为了避免这种情况,需要再加一个查询条件$exists: true
db.movies.find({ "rated": { $ne: "UNRATED", $exists: true } })
如果查询字段是某些值中的一个值,使用$in, $nin,
db.movies.find({"rated": {$in: ["TV-G", "PASSED"]}})
$nin和$ne是一个道理,不包含rated字段的文档也会包含进来,还是要加$exists: true
db.movies.find({ rated: { $nin: ["UNRATED", "PASSED"], $exists: true } })
db.movies.find({ $and: [{ "title": "Blacksmith Scene" }, { "rated": "UNRATED" }] // $or: [{ "title": "Traffic in Souls" }, { "title": "Blacksmith Scene" }] // $nor: [{ "title": "Traffic in Souls" }, { "title": "Blacksmith Scene" }] })
db.movies.find({ "title": "Blacksmith Scene", "rated": "UNRATED" })
$not 则是把查询条件进行取反,不符合查询条件的文档才会查出来,
db.movies.find({ "rated": { $not: { $eq: "UNRATED" } } })
查询结果仍然存在不包含rated字段的文档,和$ne,$nin一样的道理。还有就是查询字段的值是不是null ,如果只写db.movies.find({"z" : null}) ,不包含z字段的文档也会返回,因此需要检查字段的值是null,并且存在这个字段。db.movies.find({"z" : {$eq : null, $exists : true}})
正则表达式, 有以下两种格式,推荐使用第一种,就是如果有options,使用$options字段,而不是使用正则有达式字面量。只有在$in 的情况下,才使用第二种。
db.movies.find( { "title": { $regex: /the great/, $options: "i" } } // $options字段 ) db.movies.find( { "title": { $regex: /The Great/i } } // 正则表达式字面量语法 )
如果字段的值是数组,想查询该字段是不是包含某个值,可以像查询普通字段的一样,{字段名:值},数组中包含该值的所有文档都会被查出来
db.movies.find( {"languages" : "English"} // 字段languages的值(数组)中包含"English"的文档都会查出来。 )
如果要查询该字段是不是包含多个元素,可能会想到使用[]把元素全列出来,
db.movies.find({"languages" : ["English", "Spanish"]})
db.movies.find({languages : {$all : ["English", "Spanish"]}})
如果想查出数组某个位置上的元素是不是某个值,使用key.index的形式,
db.movies.find({"languages.0" : "English"}) // 数组位置1上的元素是"English"的文档,会被查出来
如果数组的元素是对象,要查询对象的某个属性是不是某个值,使用字段名.对象属性名的方式,
db.movies.find( { "comments.votes": 576 } // comments是数组, 每一个元素都是对象,只要对象的属性votes是"576",整条文档就会查出来 )
如果查询
db.movies.find(
{"comments.votes" : 576, "comments.rating": 5.8}
)
这时可以使用$elemMatch,减少写commnets
db.movies.find(
{"comments": {
"$elemMatch": {
"votes": 576, "rating": 5.8
}
}}
)
数组和范围查询:如果查询条件是"x" : {"$gt" : 10, "$lt" : 20}}, 文档 {x: [5, 25]} 却能匹配到, 因为,25大于10, 满足第一个条件,5小于20,满足第二个条件, 范围查询对于数组来言也就没有意义了。还是使用$elemMatch, 数组的每一个元素在不在这个范围内,它只对单个元素起作用。{"x" : {"$elemMatch" : {"$gt" : 10, "$lt" : 20}}}。 $elemMatch, 只对key的值是数组类型起作用。
如果字段的值是对象类型,想要查询字段是不是包含某个对象,可以和普通字段一样进行查询,
db.movies.find(
{"awards":
{"wins": 1}
}
)
但没有查出任何数据,还是因为精确匹配。awards字段的值只能有 {"wins": 1},并且顺序也要一样。通常,只想确定awards字段是不是有个wins属性,它的值是不是2,这时,可以采用对象的属性的方式,
db.movies.find(
{"awards.wins": 1}
)
默认情况下,find会把整条文档的所有字段都返回,但通常只需要某几个字段,这就要用第二个参数,指定返回哪些字段,它是一个对象,需要的字段属性值是1, 不需要的属性值是0
db.movies.find(
{rated: "UNRATED" },
{ title: 1 }
);
默认情况下,_id都会返回,如果不想要,可以设为0。但需要注意的是,除了_id外,不能在投影(project)中 混合使用包含或不包含这两种操作,要么在投影中列出所有包含的字段, 要么在投影中列出所有不包含的字段。数组字段需要单独处理,因为,默认情况下,查询数组的某个元素,整个数组的内容都会返回,db.movies.find({"comments.votes" : 576, "comments.rating": 5.8} ) 返回整个comments数组。当返回的文档中有数组时,字段的整个数组返回
{ _id: ObjectId("66533c610a2ddb2e92ae7213"),
rated: 'PASSED',
title: 'In Old Arizona',
languages: [ 'English', 'Spanish', 'Italian' ],
awards:
{ wins: 1,
nominations: 4,
text: 'Won 1 Oscar. Another 4 nominations.' },
comments: [ { rating: 5.8, votes: 576 }, { rating: 7.2, votes: 600 } ] }
可以限定返回的数组的元素的个数,find的第二个参数中用$slice。
db.movies.find(
{
"comments": {
"$elemMatch": {
"votes": 576, "rating": 5.8
}
}
},
{
"comments": { "$slice": -1 } // 取前几条,数字几,就取几条
// "comments": {"$slice" : -10} // 取后几条,数字几,就取几条
// "comments": {"$slice" : [10, 20]}, 取10-20条, 如果没有这么多元素, 能取多少取多少
}
)
尽管find的第二个参数只声明了comments, 但还是返回整条文档的所有字段。如果只想返回commnets字段, 要使用$
db.movies.find(
{
"comments": {
"$elemMatch": {
"votes": 576, "rating": 5.8
}
}
},
{
"comments.$" : 1
}
)
不过这有个问题,它只返回匹配到的第一条数据。$只返回一个元素,如果字段的数组中有多个元素匹配成功,它只返回第一个。
其实,find()方法的执行结果是封装到一个集合中的,并且返回一个游标(迭代器),指向这个集合。需要迭代或遍历集合,才显示查询到的文档。但在mongo shell中,我们并没有使用游标,也显示了执行结果,那是因为Mongo shell中执行 find() 时,会自动迭代游标,展示前20条文档。当查询的数据量过大时,它会显示 type it for more, 这就是因为find其实返回的是一个游标,而不是数据,只不过shell默认遍历20条数据给你。 如果要在编程语言中,就需要手动迭代游标了。游标使用也比较简单,直接把find()的返回值赋值给一个变量
var movies = db.movies.find({"rated" : "UNRATED"})
游标有next()方法,移动游标到下一个位置,并把文档返回。默认情况下,游标在集合的开始位置。当第一次调next()方法时,游标移动到集合的第一条文档,然后把该文档返回。再调一次,游标移动到第二条位置,文档返回。当游标移动到集合中的最后一条文档,再调next方法,就会报错。所以在调用next之前,先调用hasNext()方法。
movies.hasNext()
movies.next()
while(movies.hasNext()){
printjson(movies.next())
} 除了hasNext()和next()方法外,游标还有forEach(), limit(), 和skip(),sort() 和count()方法。forEach(), 用于遍历集合
movies.forEach(printjson)limit() 限制返回的结果的条数,movies.limit(1),相当于db.movies.find({"rated": "UNRATED"}).limit(1)
skip()跳过几条数据,comments.skip(1),相当于db.movies.find({"rated": "UNRATED"}).skip(1)
sort() 用于排序。它接受一个对象,键为按哪个字段进行排序,值为-1或1,1表示升序,-1表示降序。movies.sort({"year": 1}),相当于db.movies.find({"rated" : "UNRATED"}).sort({"year": 1}) .官网https://www.mongodb.com/docs/manual/reference/bson-type-comparison-order/,有比较详细地说明。排序的比较大小,也是使用该规则。mongodb是弱类型,同一个字段可以取不同类型的值。

count()返回集合中有多少条文档。movies.count(), 相当于db.movies.find({"rated": "UNRATED"}).count()
需要注意的是,count() 默认会忽略limit和skip方法的返回,如果不想忽略,则给它传递一个参数true。 注意skip() 要先于limit()函数执行。sort函数则是在skip和limt函数之前执行,所以执行顺序永远是sort(), skip(), limit()
整个集合也有一个count()方法,它返回集合中有多少条文档。如果没有什么参数,就返回整个集合有多少条文档。db.movies.count() 返回整个movies集合中有多少条文档,此时,MongoDB不会真正地一条一条文档去数,而是查询集合的元信息,所以有时会不准确。如果有参数,就返回符合查询条件的文档数,此时MongoDB 是真正地从集合中数出来了, db.movies.count({"num_mflix_comments" : 6})。在mongodb4.0中,这两种不同的行为拆分成了两个函数, countDocuments() 和 estimatedDocumentCount(). countDocuments() 它必须接受一个查询参数, 如果查询整个集合,参数是{}. countDocuments({}) , 它总是查询整个集合,然后返回值。estimatedDocumentCount 则是 根据集合的元信息,它不会对整个表进行查询。它不接受参数,只返回整个集合的文档数。
distinct() 函数,它接受一个字段,找出这个字段中所有不相同的值,返回包含这些值的数组。 比如电影中的评分,用户肯定有相同的评分,找出一共几种类型的评分,就要使用distinct(). db.movies.distinct("rated") 返回[ 'G', 'TV-G', 'UNRATED' ], 'UNRATED'只出现了一次。它还有一个可选的第二个参数,就是查询条件,比如查询某一年的评分 db.movies.distinct('rated', {year: 2020})
替换文档:replaceOne()替换一条文档,两个参数一个是查询条件,查出要替换的那条文档,一个是要替换成的新文档。需要注意的是,_id 字段是不能替换的 ,它是不可变的。替换的时候,新文档要么不写_id, 要么保证_id和原文档中_id 一致。安全的替换方式,使用_id 找到要替换的文档,新文档中不包含_id。假设title 为Yahya A的_id 为6653070b0a2ddb2e92ae720d
db.movies.replaceOne( {"_id" : ObjectId("6653070b0a2ddb2e92ae720d")}, {"title": "Traffic in Souls"} )
替换文档时,如果没有找到要替换的文档,MongoDB什么都不会做。如果找到文档就替换,找不到文档,就插入这条文档,这叫upsert。 This operation is called an update (if found) or insert (if not found), which is further shortened to upsert, 给replaceOne设置第三个参数,{upsert: true}。
db.movies.replaceOne( {"_id" : 1}, {"name": "Gertie the Dinosaur"}, {upsert: true} )
找不到{"_id": 1 }这条文档,所以就插入了这条新文档。findOneAndReplace() 默认会返回替换之前的文档,除可以配置sort,project外,还可以配置{returnNewDocument: true}, 返回替换后的文档
db.movies.findOneAndReplace( {"_id" : 1}, { title: 'In the Land of the Head Hunters' }, { projection: {"_id": 0, "title": 1}, returnNewDocument: true } ) // 返回 { title: 'In the Land of the Head Hunters' }
更新文档: 替换是整条文档的替换,但在大多数情况下,只需要更新文档的某个或某些字段。updateOne更新一条文档, updateMany更新多条文档,它们都接受两个参数, 一个是查询条件,一个是要更新的字段及其新值,这里要注意,更新不是给字段赋新值,而是使用更新操作符。直接给要更新的字段赋新值,它会替换掉整条文档。mongodb 默认的更新是先删除,再插入。更新操作符是键,它的值才是要更新的字段和和要设置的值。语法就是 {更新操作符:{字段名:值, 字段名: 值,........}},更新操作符有很多,列举几个常用的:
$set: 给指定字段设一个新值,如果字段不存在,则在原文档中创建这个字段,字段的值就为设定的值。
// 由于之前没有rated 字段,所以新增rated 字段,并设置值为"UNRATED" db.movies.updateOne( {"title" : "Traffic in Souls"},
{$set : {"rated" : "UNRATED"}}
)
// rated 字段已存在,更新值为"PG"
db.movies.updateOne( {"title" : "Traffic in Souls"}, {$set : {"rated" : "PG"}} )
$unset: 删除字段。如果指定的字段不存在, 则什么都不做,如果指定的字段存在,由于是删除字段,给它随便赋个值就可以了。
// 删除rated字段 db.movies.updateOne( {"title" : "Traffic in Souls"}, {$unset : {"rated" : 1}} )
$inc: 增加或减少字段的值,$mul: 对字段乘一个数,它们都只对数字类型的字段起作用。如果字段不存在,则会创建这个字段,不过$inc设置这个字段的值为增加的数,$mul 设置这个字段的值为0, 设置的数值需要注意,只写数字的话,是double类型。inc 之后,结果也变成了double类型,如果想inc int类型,要写 $inc: {"scoring": NumberInt("2")}
// 没有字段,就新增 db.movies.updateOne( {"title" : "Traffic in Souls"}, {$inc : {"scoring" : 2}} // 新增scoring字段, 值为2 ) db.movies.updateOne( {"title" : "In the Land of the Head Hunters"}, {$mul : {"scoring" : 2}} // 新增scoring字段,值为0 ) // 有字段 db.movies.updateOne( {"title" : "Traffic in Souls"}, {$mul : {"scoring" : 3}} // 有字段, 就相乘, 2*3, scoring字段的值为6 ) db.movies.updateOne( {"title" : "In the Land of the Head Hunters"}, {$inc : {"scoring" : 2}} // 有字段, 就相加, 0+2, scoring字段的值为2 )
$rename: 重命名字段,如果重命名的字段存在,就重命名,如果不存在,则什么都不做。
db.movies.updateOne( { "title": "Blacksmith Scene" }, { $rename: { "title": "name" } } ) db.movies.updateOne( { "name": "Blacksmith Scene" }, { $rename: { "name": "title" } } )
但如果重命名后的字段名,正好原文档中也有一个字段名与之相同,原文档中的字段将会被覆盖掉,因为先执行删除除操作,再执行添加操作。$min, $max 先比较,再更新。$min设定的字段的值与原文档中的字段的值相比较,比如$min设置的值比原文档中的值小,就改变原文档中的值,否则,文档不变。$max正好相反,它设置的值比原文档中的值大,就改变原文档中的值,否则文档不变。$min取两者中的小值做为文档的值,$max取两者中的大值做为文档的值。如果$min 和$max设置的字段不存在,则创建字段。
// 没有字段,新增字段 db.movies.updateOne( { "title": "Blacksmith Scene" }, { $min: { "scoring": 5 } } ) db.movies.updateOne( { "title": "In Old Arizona" }, { $max: { "scoring": 8 } } ) // 有字段,比较之后更新 db.movies.updateOne( { "title": "Blacksmith Scene" }, { $min: { "scoring": 4 } } // 4比5小, 修改 ) db.movies.updateOne( { "title": "In Old Arizona" }, { $max: { "scoring": 9 } } // 9比8大, 修改 )
如果某个字段的值是数组类型,对这个字段的更新,就涉及到对数组的操作,增删改查。$push: 向字段的数组末尾添加元素,如果字段不存在,则会创建新字段。{$push : {字段名 :要添加的元素}}
db.movies.updateOne( { "title": "Traffic in Souls" }, { $push: { "languages": "English" } } //languages字段不存在, 新增 -> languages: ["English"] ) db.movies.updateOne( { "title": "Traffic in Souls" }, { $push: { "languages": "French" } } // languages字段已存在,追加 -> languages: ["French"] )
如果想向数组中一次添加多个值,需配合$each ,$push : {<field_name> : {$each : [<element 1>, <element2>, ..]}}
// 没有字段,新增字段 db.movies.updateOne( { "title": "In the Land of the Head Hunters"}, { $push: { "languages": {$each: ["French", "English", "Russia"]} } } )
添加多个值,但数组又不能超过固定的长度,要使用$slice,比如$slice: 3。当数组插入元素后,如果长度小于3, 则什么也不用做,如果长度大于3, 就从数组头开始,截取3个。$slice 可以是-3, 就是数组长度超出3后,从数组末尾倒着截取3个。
db.movies.updateOne( { "title": "Blacksmith Scene" }, { $push: { "languages": { $each: ["French", "English", "Russia", "Chinese"], $slice: 3 } } }, )
截取的时候,还可以先排个序。再添加一个$sort字段, $sort: 1 正向排序,$sort: -1 倒序。此时,按排序好的内容进行插入,如果超出固定的长度,再slice。$slice和$sort 要配合$each一起使用,不能单独使用。
$addToSet: 和$push一样,只不过,重复的元素不会添加,让数组变成了set
db.movies.updateOne( { "title": "Traffic in Souls" }, { $addToSet: { "languages": { $each: ["Russia", "English", "Russia", "Russia"], // 只插入"Russia", } } }, )
数组元素的删除:$pop:取值1, 删除数组最后一个元素,取值为-1, 删除最前面一个元素
db.movies.updateOne( { "title": "Traffic in Souls" }, { $pop: { "languages": -1 } } // 删除"English" )
$pullAll 接受一个数组,删除掉这个数组中包含的元素。
db.movies.updateOne( { "title": "Traffic in Souls" }, { $pullAll: { "languages": ["Russia", "French"] } } // 删除"Russia" 和"French" )
$pull: 给它提供特定的值或特定的筛选条件,用于删除特定的元素 {$pull: {字段名: {值或 筛选条件}} 。
db.movies.updateOne( { "title": "Blacksmith Scene" }, { $pull: { "languages": "English" } } // 删除"English" )
需要注意的是,$pull会删除所有匹配元素。如果有个数组arr是 [1, 1, 2, 1],$pull: {arr: 1},三个元素都会删除,只剩下[2]一个元素。如果删除的数组元素也是数组,就要使用$elementMatch,
数组元素的更新,可以使用元素的下标位置。
db.movies.updateOne( { "title": "In the Land of the Head Hunters" }, { $set: { "languages.0": "English"} } // 使用更新操作符,设置languages数组0下标位置为"English" )
但大多数情况下,并不会提前知道元素的位置,只能先查询到元素,再更改元素,这时可以使用位置操作符$,$指的是数组中第一个符合筛选条件的数组元素的占位符,使用$时,updateOne的查询条件中要有数组的筛选条件,并且,位置操作符$只能更新一条匹配元素
db.movies.updateOne( { "title": "In the Land of the Head Hunters", "languages": "English" // languages(查询条件中要有数组的筛选条件) }, { $set: { "languages.$": "Russia" } } // languages.$ 如果languages数组中第1,2,3个元素都是English,那只有第一个元素被更新成Russia )
如果更新数组中所有匹配元素,使用$[] , $[]指代数组中匹配查询条件的所有元素
db.movies.updateOne( { "title": "In the Land of the Head Hunters", "languages": "Russia" }, { $set: { "languages.$[]": "English" } } // languages.$[] 就是匹配筛选条件的所有数组元素 )
updateOne第三个参数arrayFilters,也可以更新数组元素的值。
db.movies.updateOne( { "title": "In the Land of the Head Hunters" }, { $set: { "languages.$[elem]": "Russia" } }, // 声明了elem变量,表示匹配到每一个的数组元素,$set设置值。 { arrayFilters: [{ "elem": { $eq: "English" } }] }// 使用elem变量,定义筛选条件 )
数组中元素是对象(嵌套文档类型)时,有些细节要注意一下。比如push的时候,$sort 不能是1或-1了,要指定按照哪个字段进行排序, 比如sort: {votes: 1}
// push 一个嵌入式文档 db.movies.updateOne( { "title": "Traffic in Souls" }, { $push: { "comments":{ votes: 2, author: "Lily" } } }, ) // push多个嵌入式文档,$sort不能是1或-1了,要指定按照哪个字段进行排序, 比如sort: {votes: 1} db.movies.updateOne( { "title": "Traffic in Souls" }, { $push: { "comments": { $each: [ { votes: 6, author: "John" }, { votes: 5, author: "Make" } ], $sort: { votes: 1 } // 指定按votes 进行排序 } } }, )
$pull删除元素的时候,{$pull: {字段名: {值或 筛选条件}} , 这里的值或筛选条件,是对象类型,键为对象元素的属性,值为值或筛选条件
db.movies.updateOne( { "title": "Traffic in Souls" }, { $pull: { "comments": { "votes": { $gt: 5 } } } // 数组元素对象的属性,votes 大于5, // 也可以 $pull: { "comments": { "votes": 6 } } } )
更新数组元素的某个对象的值时
db.movies.updateOne( { "title": "Traffic in Souls" }, { $inc: { "comments.0.votes": 1 } // 数组下标后面可以加某个属性,修改数组第几个元素(对象)的哪个属性 } ) db.movies.updateOne( { "title": "Traffic in Souls", "comments.author": "Lily" }, { $set: { "comments.$.author": "Lucy" } // 修改匹配到的数组元素的哪个属性 } ) db.movies.updateOne( { "title": "Traffic in Souls" }, { $set: { "comments.$[elem].author": "LiLy" } // elem 指的是匹配的每一个对象 }, { arrayFilters: [{ "elem.votes": { $lt: 5 } }] } )
$elementMatch, 也要是个对象,比如 hobby: [{title: 'sport', frenquency: 3}]。使用$elementMatch 也要用对象,db.collection.find({hobby: {$elementMatch: {title: 'sports', frenquency: {$gt: 3}}}})
如果某个字段的值是对象类型或嵌入式文档,更新该字段,也是使用更新操作符,只不过,更新操作符的值(对象)的键,使用的是属性的方式
db.movies.updateOne( { "title": "Blacksmith Scene" }, { $set: { "awards.wins": 2 }} )
findOneAndUpdate() 返回更新之前的文档,如查没有查找到,返回null, 设置{"returnNewDocument" : true} 返回更新后的文档
db.movies.findOneAndUpdate( { "title": "Blacksmith Scene" }, { $set: { "awards.text": "1 win." } } )
更新操作也有upsert,如果找到文档就更新,如果没有找到文档就插入,第三个参数{upsert: true}
db.movies.updateOne( { "title": "Gertie the Dinosaur" }, { $set: { "awards.wins": 2 } }, { upsert: true } )
集合中没有文档的title 是"Gertie the Dinosaur”,所以就插入了一条新文档。有时候,字段只需要在文档创建之初设置值,在后续的更新中,值就不会发生变化,这时更新的时候要使用$setonInsert, 只有在插入文档时才设置值,更新文档,值不会发生变化。
// 第一次执行,插入文档,创建createdAt db.movies.updateOne( { "title": "The Perils of Pauline" }, { $setOnInsert: { "createdAt": new Date() } }, { upsert: true} ) // 第二次执行,文档已存在,不需要插入,什么都不会发生 db.movies.updateOne( { "title": "The Perils of Pauline" }, { $setOnInsert: { "createdAt": new Date() } }, { upsert: true} )
删除文档:deleteOne()和deleteMany()都接受一个查询条件,只不过前者只删除符合条件的一条文档,后者删除符合查询条件所有文档
db.movies.deleteOne({"title": "Yahya A"})
db.movies.deleteMany({"title": "The Great Train Robbery"})
如果deleteMany()的参数是{},没有任何条件,则会删除所有文档,但集合仍然存在。如果清空整个集合,要用drop(), db.movies.drop(),集合都不存在了。
findOneAndDelete: 删除符合条件的一条文档,但会返回删除掉的文档,如果查询条件匹配多条文档,可以使用sort进行排序,删除掉一条文档,还可以使用投影,指定返回的字段。
db.movies.findOneAndDelete(
{"title": "Blacksmith Scene"},
{sort: {"_id" : -1}, projection: {"_id": 0, "title": 1}}
)
返回
{ title: 'Blacksmith Scene' }
索引
说到索引,可能会想到书本的索引,按章节排序,每章节下有大标题,小标题,每个标题的后面跟着页数,表明具体的内容在那里。索引是独立于书本内容的,目的是为了提高查询效率。知道第几章节,就能马上查到多少页,直接到那一页查询内容就可以了。数据库的索引就像书本的索引,独立于数据库中的集合,是一个单独的数据存储结构,可以把它想像成一个map,键就是排序好的某个字段或某些字段,值就是相对应的具体的文档内容的地址。索引就是排序和指针, 指向原来的整条文档。当查询文档时,如果查询字段有索引,先查索引,通过索引定位到原始的文档。索引是排序好的,所以非常快。如果没有索引,那就要整个集合中一条文档一条文档进行匹配,直到找到符合条件的文档。假设插入10000条user数据
for (let i = 0; i < 10000; i++) {
db.users.insertOne(
{
"i": i,
"username": "user" + i,
"age": Math.floor(Math.random() * 120),
"created": new Date()
}
);
}
然后找出"username" 是 "user101"的文档, 为了能够查看执行的情况,可以使用explain
db.users.find({"username": "user101"}).explain("executionStats")
executionStats里面totalDocsExamined: 10000,表示为了找到符合条件的文档,MongoDB查询了10000条数据,也就是查询了整个users集合。查询username, 可以创建username的索引。创建索引是createIndex
db.users.createIndex({"username" : 1})
重新执行 db.users.find({"username": "user101"}).explain("executionStats"),结果是totalDocsExamined: 1,MongoDB只查询了users集合中的1条数据,非常快。创建username的索引,就相当于
["user0"] -> 776 ["user1"] -> 768 ["user11"] -> 880 ["user12"] -> 881 ["user13"] -> 883 ... ["user20"] -> 890 ["user21"] -> 891 ... ["user34"] -> 1008 ["user35"] -> 1009
索引对字段的值进行了排序,然后指向一个记录标识符(record identifier)。由于排序,索引中能快速找到username 等于”user101",进而得到一个记录标识符,MongoDB的存储引擎使用记录标示符来定位集合中的文档,进而找到这条文档的在集合中的具体位置,MongoDB直接到集合中读取这条文档就可以了。当进行query操作时,mongodb会查找索引,和query 进行匹配,看能不用用索引,然后建立几个查询的plan,比如3个。然后再建立一个winning condition, 比如查找100条记录,然后三个方法竞争去跑,看哪个先到达条件,哪个就是winning 的方法,Mongodb就会用这个方法执行真正的query,并把这个方法缓存起来。当collection 发生变化后,比如新增100条记录,新建了索引,等,缓存的记录会被清除
如果查询条件是{"age": 20, "username": "user101"}呢? 就要对age和username两个字段创建索引,这是复合索引。复合索引是对两个或两个以上的字段创建的索引
db.users.createIndex({"age" : 1, "username" : 1})
创建索引后,
[0, "user1000"] -> 8623513776 [0, "user1002"] -> 8599246768 [0, "user1003"] -> 8623560880 ... [0, "user10041"] -> 8623564208 [1, "user1001"] -> 8623525680 [1, "user1002"] -> 8623547056 [1, "user1005"] -> 8623581744 [2, "user1001"] -> 8623535664
涉及到复合索引,就要想想怎么设计复合索引。先看几个query查询,看看能不能用上复合索引{age: 1, username: 1}
db.users.find({"age" : 21}).sort({"username" : -1})
这是一个等式查询(age等于21),并且只查询单个值(21),age有索引,可以快速找到age等于21, 再看sort,按username进行排序,username在索引也排序好了,MongoDB可以直接跳转到最后一个{age: 21},然后遍历索引。
[21, "user1001"] -> 8623530928 [21, "user1002"] -> 8623545264 [21, "user1003"] -> 8623545776 [21, "user1004"] -> 8623547696 [21, "user1005"] -> 8623555888
排序的方向没有关系,MongoDB可以从任意一个方向遍历索引。再看第二种查询
db.users.find({"age" : {"$gte" : 21, "$lte" : 30}})
这是范围查询,查找匹配多个值的文档,由于age是索引,将返回如下
[21, "user100154"] -> 8623530928 [21, "user100266"] -> 8623545264 [21, "user100270"] -> 8623545776 ... [21, "user999390"] -> 8765250224 [21, "user999407"] -> 8765252400 [21, "user999600"] -> 8765277104 [22, "user100017"] -> 8623513392 ... [29, "user999861"] -> 8765310512
再看第三种
db.users.find({"age" : {"$gte" : 21, "$lte" : 30}}).sort({"username" :1})
多值查询带排序,通过age索引能找快速找到age,但就像上面一样,username 并没有排序,需要重新排序,这种查询就不是很有效率。 索引{age: 1, username: 1},只有在age相同的情况下,再按username进行排序,age不同,useraname之间没有进行排序。怎样设计组合索引
db.users.find({ age: { $gt: 50 }, username: "user100" })
.sort({ age: 1 })
当有单值查询和多值查询时,通常单值查询返回的数据是少的,可以以它为基础建立索引,再由于sort 和多值查询都依赖age,可以给age建索引,
db.students.createIndex({username:1, age:1})
当设计复合索引时,需要平衡查询中的多值查询条件,单值查询条件和排序条件。查询语句再变一下,db.users.find({ age: { $gt: 50 }, username: "user100" }) .sort({ created: 1 }),这会导致MongoDB 按created进行排序。如果能用索引避免排序,就尽量避免排序,但需要做一个权衡,为了避免排序,需要对比更多的age字段来查找满足条件的文档。
db.users.createIndex({username:1, created:1, age:1})
等值过滤条件放到第一位,排序的过滤条件放到第二位,最后是多值过滤条件。 等值过滤条件在前面,可以最大程序缩小范围。当sort 排序的时候,如果有多个条件,比如,.sort({age: 1, username: -1}), 这时创建索引的时候,要注意方向。
隐式索引:
当创建{username:1, created:1, age:1} 复合索引时,先对username 进行排序,如果username相等,再对created进行排序,created再相等,要按age进行排序,就相当于创建了 {username: 1} ,{username: 1, created: 1} 和{username:1, created:1, age:1}索引
涵盖索引
当创建索引后,如果只查询和显示索引中包含的字段,MongoDB 就没有必要再到集合中获取额外的字段,直接使用索引中的数据就可以了。默认情况下,MongoDB的查询都会返回_id, 如果没有给_id 创建索引,就要使用投影去掉_id
db.users.find({username: "user100" }, {_id: 0, username: 1}).explain("executionStats")
totalDocExamined 是0,MongoDB直接从索引中读取数据,没有查询集合。
唯一索引
用于创建索引的字段的值,在集合中的所有文档中都不相同,字段不会出现重复值。
db.users.createIndex({"username" : 1}, {"unique" : true} )
部分索引
想为某个字段创建索引,但文档中可能存在,也可能不存在该字段,那就要使用部分索引,比如仅对存在的字段创建唯一索引。创建索引时,加partialFilterExpression
db.movies.ensureIndex({"scoring":1},{"partialFilterExpression": {"scoring": {$exists: true}}, "unique": true})
其它索引
MongoDB默认会为 _id字段创建索引,对数组字段创建索引,也称为多键索引, 因为MongoDB会为数组中的每一个元素创建索引。嵌入式文档创建索引,就是属性方式,db.movies.createIndex({"awards.wins":1})
索引的操作
getIndexes() 查看集合中存在的索引,db.movies.getIndexes() 。dropIndex()删除索引,参数是索引的名称或创建索引的方式,怎么创建的,怎么删除,比如db.movies.dropIndex("scoring_1") 或db.movies.dropIndex({'awards.wins': 1})
但是索引也有代价,插入,更新和删除索引字段时,需要更长的时间。因为MongoDB不仅需要更新集合文档,还需要更新索引,所以创建索引,最关键的是为哪个字段创建索引。
聚合框架
MongoDB的聚合框架是基于流水(pipeline)的概念。流水(pipeline)的概念和现实中的流水线没有什么区别。在流水线上,第一个工位接收原材料,做完后交给下一个工位,每一个工位做一个工作,做完之后,交给下一个工位,最后产出一个产品。对于MongoDB来说,每一个工位相当于一个stage,当文档经过stage时,对文档进行数据处理,上一个stage的输出文档,变成下一个stage的输入,最后产出想要的文档集合。所以pipeline是一个数组,包含多个stage,stage是通过提供的操作符来进行数据处理,$match 过滤条件。$project需要什么字段(reshape the documents), $limit限制返回的数据条数,$sort 排序,$skip跳过。聚合框架,相比find, 在每一个阶段,能提供更多的控制。Simply put, aggregation is a method for taking a collection and, in a procedural way, filtering, transforming, and joining data from other collections to create new, meaningful datasets.
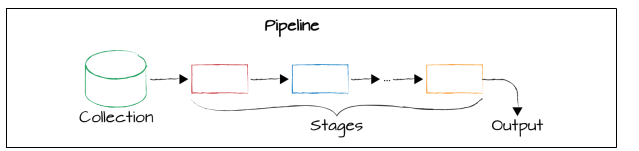
stage对数据的处理是基于流的方式,It takes in a stream of input documents one at a time, processes each document one at a time, and produces an output stream of documents one at a time
var pipeline = [ {$stage-operator : parameters} { . . . }, {....}, {....} ] var cursor = db.[集合].aggregate(pipeline, options) // 返回 a cursor containing the search result.
使用聚合框架,需要大量的数据,为此MongoDB的官网提供了一些样例数据(sample_airbnb等),可以导入到本地的数据库学习使用。在MongoDB Compass 左下方显示数据库的基本信息,点击mflix,点击movies, 右侧显示

点击 ADD Data,选Import File,再点击Select a file, 选择movies.json, 再点击右下角的Import,就可以导入成功。同样的方法也可以导入comments, users等数据
用聚合框架来实现find功能,点开__MONGOSH,use mflix,
db.movies.aggregate([ { $match: { year: 1915} }, { $sort: { runtime: -1 } }, { $skip: 2 }, { $limit: 5 }, { $project: { _id: 0, title: 1 } }, ])
$match,或者说,aggregation的第一步可以使用索引。聚合框架可以实现更高级的功能,先看$project,它可以reshape 形状,
db.movies.aggregate([ { $match: { year: 1915} }, { $project: { _id: 0, title: 1, imdb_rating: "$imdb.rating" // $加上原文档中的字段,称为字段路径(field paths),取原文档中该字段的值。 } }, ])
对数组也可以使用$elementMatch, 还可以使用表达,$project: {fullName: {$concat: [{$toUpper: "$name.firstName"}, " ", {$toUpper: "$name.lastName"}]}}
$group:以某个条件对集合进行分组或聚合。分组和现实中的分组没有区别,比如一群学生按班级进行分组,一班,二班等。分组之后,只知道这组是几班,而不知道每个组员具体的信息,比如,姓名和年龄。所以对于MongoDB来说,每一组都形成一条单独的文档,分组就要形成新的_id, 按什么条件分组,_id就是什么,比如{$group: {_id: "$rated"}} 就是以电影评分进行分组,新生成的文档的_id 就是评分的值。$rated告诉MongoDB使用文档中rated字段的值。

那分组有什么用呢? 可以用来统计信息,比如每个组多少个人?平均分多少? 这些信息就是$group对象的其它字段,要想获取这些数据,就要用累加器表达式,格式:field: { accumulator: expression}。field:给想要的信息起个名字,因为它是计算出来的,原文档中没有。accumulator 就是MongoDB支持的操作,express 就是accumulator的输入,对什么进行accumulate
db.movies.aggregate( [ { $group: { _id: "$rated", "numTitles": { $sum: 1 }, } } ])
$group 的_id 可以接受一个对象,按照多个条件进行group。
$lookup: 多集合查询,比如找出一个movie 的comments。movie在一个集合中,comments 在另一个集合中,所以要两个集合一起查询,关联
db.movies.aggregate([ { $match: { title: "The Saboteurs" } }, { $lookup: { from: "comments", localField: "_id", foreignField: "movie_id", as: "comments" } }, { $project: { title: 1, comments: 1 } } ])
$lookup 的四个字段
- from: 关联哪一个集合进行查询
- localField: 用哪个字段去关联,
- foreignField: 被关联的集合中,用哪个字段和关联字段进行匹配
- as: 关联查询完成后,给查询到的数据起个名字
$lookup 关联查询,查到的匹配文档会封装到数组中,没有查到文档,就是空数组,然后嵌入到主查询文档中,comments 是一个数组,嵌入到 { $match: { title: "The Saboteurs" } } 查询到的文档中。
{ _id: ObjectId("573a13e9f29313caabdcc269"),
title: 'The Saboteurs',
comments:
[ { _id: ObjectId("5a9427658b0beebeb697b894"),
name: 'Khal Drogo',
email: 'jason_momoa@gameofthron.es',
movie_id: ObjectId("573a13e9f29313caabdcc269"),
text: 'Qui placeat magni quisquam reiciendis. Quo dolores quidem quam odit sunt. Dolores nam temporibus consequatur voluptates iste illo voluptatem. Facilis asperiores sequi corrupti quam.',
date: 1988-12-27T23:28:01.000Z },
{ _id: ObjectId("5a9427658b0beebeb697b897"),
name: 'Rast',
email: 'luke_barnes@gameofthron.es',
movie_id: ObjectId("573a13e9f29313caabdcc269"),
text: 'Recusandae placeat tempore occaecati magni velit eveniet ipsam. Velit enim voluptates nobis ipsa dignissimos non.',
date: 2016-08-21T16:26:52.000Z },
{ _id: ObjectId("5a9427658b0beebeb697b89a"),
name: 'Victor Patel',
email: 'victor_patel@fakegmail.com',
movie_id: ObjectId("573a13e9f29313caabdcc269"),
text: 'Optio accusamus similique tempore praesentium aliquid repellat. Illum exercitationem quae rem est. Quas fuga magnam aspernatur cupiditate quos.',
date: 2013-04-02T22:36:11.000Z } ] }
localField使用的字段,还可以是个数组字段。比如 book:{authors: [1,2,3]},就可以用authors字段去关联author表。$lookup: {from: 'author', localField: "authors", foreignField: _id, as: "creator"}
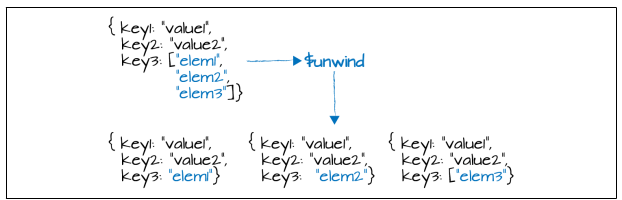
$unwind :将文档中的某一个数组类型字段进行展开, 数组中有几个元素,就会生成几条文档,每一条文档都包含数组的一个元素 ,所以它的参数是要拆分字段的路径。{a: 1, b: 2, c: [1, 2, 3, 4]} 对c进行unwind
{"a" : 1, "b" : 2, "c" : 1 }
{"a" : 1, "b" : 2, "c" : 2 }
{"a" : 1, "b" : 2, "c" : 3 }
{"a" : 1, "b" : 2, "c" : 4 }
db.movies.aggregate([
{ $match: { title: "The Saboteurs" } },
{
$lookup: {
from: "comments",
localField: "_id",
foreignField: "movie_id",
as: "comments"
}
},
{ $unwind: "$comments"},
{
$project: {
title: 1,
"comments.text": 1 // 展开数组后,可以对每一个文档进行单独操作
}
}
])
$lookup 还有第二种使用方式:在lookup中创建新的pipeline
{ $lookup: { from: "comments", let: { movieId: "$_id" }, // 可以声明多个变量, 用,隔开 pipeline: [{ $match: { $expr: { $eq: ["$movie_id", "$$movieId"] } } }], as: "comments" }, },
由于在新的pipeline中不能使用上一个stage传下来的文档,在这里,就是 { $match: { title: "The Saboteurs" } } 传下来的文档,所以要使用let声明变量,变量的值就是传下来的文档中的值。 let: { movieId: "$_id" } 就是声明了movieId变量,它的值是传下来的文档的_id字段的值。新的pipeline中,每一个stage都要用$expr来表达关联关系,$expr中如果要使用let中声明的变量,用$$变量名,如果要使用from集合中的某个字段的值,要用$字段名。$eq: ["$movie_id", "$$movieId"],表示 from集合(comments)中movie_id字段的值等于let中声明的变量movieId的值,也是集合movies中_id的值。
创建companies集合,考虑字段数组中还包含数组的情况:
db.companies.insertOne({ "name": "Facebook", "category_code": "social", "founded_year": 2004, "funding_rounds": [ { "id": 4, "round_code": "b", "raised_amount": 27500000, "raised_currency_code": "USD", "funded_year": 2006, "investments": [ { "company": null, "financial_org": { "name": "Greylock Partners", "permalink": "greylock" }, "person": null }, { "company": null, "financial_org": { "name": "Meritech Capital Partners", "permalink": "meritech-capital-partners" }, "person": null } ] }, { "id": 2197, "round_code": "c", "raised_amount": 15000000, "raised_currency_code": "USD", "funded_year": 2008, "investments": [ { "company": null, "financial_org": { "name": "European Founders Fund", "permalink": "european-founders-fund" }, "person": null } ] } ], "ipo": { "valuation_amount": 104000000000, "valuation_currency_code": "USD", "pub_year": 2012, "stock_symbol": "NASDAQ:FB" } })
funding_rounds字段的值是数组,它还包含investments数组。当数组的元素是对象时,用字段名.对象属性名的方式,数组中包含数组,就要继续 .对象属性名 进行查询
db.companies.aggregate([ { $match: { "funding_rounds.investments.financial_org.permalink": "greylock" } }, { $project: { _id: 0, name: 1, ipo: "$ipo.pub_year", valuation: "$ipo.valuation_amount", funding_rounds: 1 } } ])
整个funding_rounds数组的内容全都返回回来。如果进行project,取出funding_rounds中需要的信息,比如permalink。把上面的funding_rounds: 1改成funders: "$funding_rounds.investments.financial_org.permalink" 进行查询,返回的结果
{ name: 'Facebook', ipo: 2012, valuation: 104000000000, funders: [['greylock', 'meritech-capital-partners'], ['european-founders-fund']] }
funders是个二维数组,funding_rounds是个数组,investments是个数组,格式没有变化,只是取出了financial_org.permalink的值,相当于map方法。这时可以想到对funding_rounds进行$unwind,funders变成了一维数组。
db.companies.aggregate([ { $match: { "funding_rounds.investments.financial_org.permalink": "greylock" } }, { $unwind: "$funding_rounds" }, { $project: { _id: 0, name: 1, funders: "$funding_rounds.investments.financial_org.permalink" } } ])
db.companies.aggregate([ { $match: { "funding_rounds.investments.financial_org.permalink": "greylock" } }, { $unwind: "$funding_rounds" }, { $match: { "funding_rounds.investments.financial_org.permalink": "greylock" } }, { $project: { _id: 0, name: 1, funders: "$funding_rounds.investments.financial_org.permalink" } } ])
如果上一个stage传递给$project的文档中有数组字段时,比如funding_rounds,可以对数组字段进 $filter, $slice等操作,还可以使用 $max, $min, $sum, $avg
db.companies.aggregate([ { $match: { "funding_rounds.investments.financial_org.permalink": "greylock" } }, { $project: { _id: 0, name: 1, rounds: { $filter: { // $filter 对数据时行过滤 input: "$funding_rounds", as: "round", // 给$funding_rounds定义个别名,供下面的条件表达式使用。下面的$$round就用引用的round变量,也就是文档中的funding_rounds。 cond: { $gte: ["$$round.raised_amount", 100000000] } } }, first_round: { $arrayElemAt: ["$funding_rounds", 0] }, // 数组第一个元素 last_round: { $arrayElemAt: ["$funding_rounds", -1] }, // 数组第三个元素 early_rounds: { $slice: ["$funding_rounds", 1, 3] }, // 取数组前三个元素 total_rounds: { $size: "$funding_rounds" }, // 数组的大小 total_funding: { $sum: "$funding_rounds.raised_amount" }, largest_round: { $max: "$funding_rounds.raised_amount" } } }, ])
模型设计
数据模型就是关注哪些信息,怎么表现出来?因为同一个对象,对于不同的应用程序,关注的信息可能不同,比如同一个人来说,保险公司关注的是年收入,理发店关心的是个性和喜好。模型设计就是根据需求,把关注的信息列出来,就是确定对象(实体)及其属性。通常实体和实体存在各种各样的关系,比如一个人有多个电话号码,就是1对多的关系,还有1对1,多对多的关系。怎么表现出来?因为MongoDB存储的是JSON,对象和属性就用JSON对象表式,那关系怎么表示?通常情况下,1对1,以内嵌为主(嵌入式文档),比如学生有学生卡,每一个学生卡都对应一个学生,把学生卡的信息内嵌到学生信息中,
{ "_id": ObjectId("62bc"), "first_name": "Sammy", "last_name": "shark", "id_card": { "number": "123-1234-123", "issued_on": "2020-01-23" } }
但对于某些不被经常查询,但又特别大的属性,比如二进制的头像,查询时整条文档查询出来,太占内存,可以把头像放到单独的集合中,用id引用。1对多时,考虑这个多有多大,10?20?再考虑independent acess, 多的元素是不是需要单独获取,比如学生的邮箱,它不会太多,并且也不会单独获取,这时就可以使用内嵌数组文档,将需要一起访问的内容存储在一起
{ "_id": ObjectId("62bc"), "first_name": "Sammy", "last_name": "shark", "emails": [ { "email": "sammy@outlook.com", "type": "work" }, { "email": "sammy@gmail.com", "type": "home" } ] }
但多方的数据量比较大,或者多方的元素需要单独查询(独立更改),比如学生的课程,这是就要把多的一方,放到一个单独的集合中,可以在多的一方加one 的id,类似外键,也可以在1的一方,使用内嵌数组,数组元素都是引用进行关联,这也称为子引用。多对多,也可以使用内嵌数组文档的方式,但通常使用子引用的方式。比如课程的集合
{ "_id": 1, "name": "python" } { "_id": 2, "name": "java" }
学生文档
{ "_id": ObjectId("62bc"), "first_name": "Sammy", "last_name": "shark", "courses": [1,2] }
` 1对多有一个特殊的情况,那就是多方的数量有可能持续增长(随着时间的推移),没有封顶,比如学生的留言板,这就需要父引用,在多的一方的元素上,加引用,比如在流量文档中,加学生文档的引用。子引用始终数量有上限。
{ "_id": 3, "subject": "books", "message": "Hello, reconmmend a good inroductory books", "post_by": ObjectId("62bc") }
对于某些数据,有特定的设计模式可以参考。比如一分钟1条数据的,

可以1小时一条数据,把一分钟一条的数据放到1小时数据的数组中。

可以减少文档数量, 减少索引占据的空间。再比如一些字段非常多的文档,

可以把相似的列,放到一个数组中,称为列转行

灵活模型的文档不同的版本管理,可以加一个version字段

复制集
单台服务器容易出故障,那就多台服务器组合在一起,每台服务器都运行一个mongod进程,形成一个集群,对外提供服务。多台服务器中,只有一台是主服务器(主节点), 负责读写操作,其它都是副或从服务器(副节点),负责不停地从主节点进行备份和复制数据。各个节点之间相互通信,最重要的是心跳请求,进行健康检测。默认情况下,每隔2秒发送一次,超过10s,就算请求超时,某个节点出故障。如果主节点出故障,副节点中,可以选出一个主节点,继续提供读写服务,最多50个节点组合在一起,但具有投票权的节点最多7个,这就是MongoDB的复制集。
主副节点之间的数据同步依靠的是Oplog (Operation Log), 它是一个固定集合(Capped Collections)或环形队列(circular buffer),存在主节点的local数据库中。主节点上的写操作完成后,会按照一定的格式,向Oplog写入一条记录(写库记录),副节点不断的从主节点获取新的记录并应用自己身上,这样主副节点的数据就会保持一致。Oplog数据不断增加,当容量达到配置上限时,从头开始写起。写库记录在副节点上可以重复应用,即重复应用也会得到相同的结果。看一下三个节点的复制集
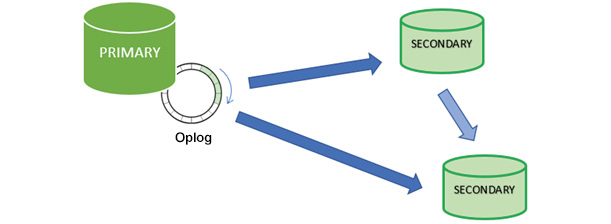
主节点把自己的接收并执行的写记录按照顺序依次写到Oplog中,副节点发送query请求到主节点,查询Oplog中有没有新的记录,如果有,Oplog 中的记录就会被复到到副节点,副节点也有自己的Oplog,记录从主节点复制过来的记录,然后,把这些记录应用到自己身上,再把自己执行的记录保存到自己的Oplog中,如果执行记录失败,副节点可能就不提供服务了。通常副节点是从主节点复制数据,但有时,副节点也会从另外一个副节点复制数据,这种类型的copy称为链式复制(Chained Replication)。
复制集的主节点是通过选举算法推选出来的,如果主节点出问题,则会再重新选举一个主节点出来。在复制集的每一个节点中,都有选举计算数,参与一个次选举,选举计数器加1。任意一个副节点,都会发起一次新的选举。当然,实际上,每一个节点都有不同的优先级,优先级高的节点会优先发起选举。发起选举的主要目的是,询问其它所有节点,是不是同意它成为新的主节点。发起选举的过程是,它自己的选举计数器加1,给自己投1票 ,然后向其它节点发起投票请求,收到投票请求的节点,先把自己的计数机加1, 再比较它和发起投票请求的节点的同步优先级(对比操作日志oplog),如果比它低,就会同意,如果比它高,就会反对。如果发起投票的节点,得到同意的票数超过复制集中节点个数的一半,它就会成了新的主节点。如果主节点再坏了,那就再发起投票。所以复制集的最小节点是3个,因为投票数要超过一半。超过复制集的成员的一半,称为“大多数”。这里的复制集成员是复制集初始配置中定义的。如果复制集的成员为N,大多数为(N/2 + 1)

当一个副节点联系不上主节点后,它就会向复制集的其他成员发起请求,它要当主节点。其它成员就会做一些考虑,它们能不能联系上主节点?发起请求的节点的数据是不是最新的?复制集中是不是有其它优先级更高的节点?等。如果有任何一种情况,其它节点不会为该节点进行投票。如果没有什么理由,其它节点会对它进行投票。如果发起请求的节点得到了大多数的投票,它就成了主节点,如果没有,它还是副节点。
创建复制集。1, 创建3个数据文件夹(mkdir -p ~/data/rs{1,2,3})2,启动3个mongo的实例,
sudomongod --replSet mdbDefGuide --dbpath ~/data/rs1 --port 27017sudomongod --replSet mdbDefGuide --dbpath ~/data/rs2 --port 27018sudomongod --replSet mdbDefGuide --dbpath ~/data/rs3 --port 27019
3, 连接一个mongod 实例。MongoDB 7 没有了mongo 命令,需要下载新的mongosh,它是一个.deb的文件,双击安装。安装完成后,mongosh --port 27017,连接到27017 服务器,执行
rs.initiate({ _id: "mdbDefGuide", // _id: 命令行中 --replSet mdbDefGuide, 就是复制集的名字 。 members: [ {_id: 0, host: 'localhost:27017'}, {_id: 1, host: 'localhost:27018'}, {_id: 2, host: 'localhost:27019'} ] })
rs.status() 检查复制集的状态。如果27017 被选为了主节点,那么shell 就会显示 mdbDefguide: primary. 如果27018当选主节点,需要退出shell,重新连接到主节点( mongosh --port 27018)。 随便在主节点上添加数据,for (i=0; i<10; i++) {db.coll.insertOne({count: i})}, 然后,打开一个新的命令窗口,mongosh --port 27019,连接一个副节点,db.coll.find() 可以找到主节点写入的数据。MongoDB 7,副节点可以直接读取数据了,不用调setSlaveOk()了。
停止主节点,db.adminCommand({"shutdown" : 1})。 然后再rs.status,可以发现新的主节点选举出来了。添加新节点:rs.add("localhost:27020"), 删除新节点rs.remove("localhost:27017"). rs.config() 可以查看配置。
创建集群后,连接方式有变化,连接的url是服务器列表,比如"mongodb://localhost:27017, localhost:27018, localhost:27019, 建议多写几个,如果只写一个,链接不上这一个,复制集就不能用了。
MongoDB事务
首先需要说明,MongoDB的事务只有在复制集中才能使用。事务的ACID是通过配置writeConcern和readConcern来实现的,一致性强调的是 各个节点之间的一致性。
writeConcern 决定一个写操作落到多少个节点才算成功, 0表示不关心是否成功,1-n的数字,写操作需要被复制到指定节点数才算成功,marjority: 写操作要被复制到大多数节点才算成功。发起写操作的程序将被阻塞到写操作到达指定的节点数为止。默认情况下,写操作,写到主节点的内存中就算成功,。writeconcern:{w: “majority“},3节点的复制集,只有写操作,写到两个节点,一个主节点,一个副节点才算成功。writeConcern 还有一个j是不是写到journal文件才算成功, true表示是,false表示不是,只要写到内存就算成功。设置timeout, 如果节点不响应,最多等多少时间,就算失败了, 不是所有的节点都失败,有的节点写入成功,有的节点写入失败,这种error 最好记录一下日志。
readConcern关注什么样的数据可以读,关注数据的隔离性,readConcern: available: 读取所有可用的数据,local:读取所有可用且属于当前分片的数据,是默认值。majority: 读取在大多数节点提交完成的数据,linearizable:可线性化读取文档,snapshot: 读取最近快照的数据,类似关系型数据库的可重复读。 在复制集中,available和local 没有区别,链接到哪个节点就从哪个节点读取。majority 是链接到哪个节点就读哪个节点,但是这个被链接到的节点要被其他节点通知,它才能知道,这个数据是不是在大多数节点上都提交完成。
readConcern(majority)和脏读: 写操作到达大多数节点之前都不是安全的,一旦主节点崩溃,而从节点还没有复制到该次操作,刚才的写操作就丢失了;把一次写操作看作一个事务,从事务的角度看,可以认为事务被回滚了。所以从分布系统的角度来看,事务的提交被提升到了分布式集群的多个节点级别的提交,而不是单个节点的提交。如果在一次写操作到达大多数节点前读取了这个操作,然后因为系统故障该操作回滚了,则发生了脏读。readConcern: majority 则有效避免脏读。相当于读已提交。
readConcern(snapshot): 事务中的读,不出现脏读,不出现不可重复读,不出现幻读,因为所有的读都将使用同一个快照,直到事务提交为止,该快照才被释放。实现可重复的的事务

readConcern和writeConcern除了配合事务外,还可以单独使用,比如向主节点写入一条数据,立即从从节点读取这条数据,如何保证自己能够读取到刚刚写入的数据
db.orders.insert({_id: 101, sku: "kit", q: 1}, {writeConcern: {w: 'majority' }})
db.orders.find({_id: '101'}).redPref("secondary").readConcern('majority')
redpref(readPreference)表示从哪里读,主节点还是副节点。
分片
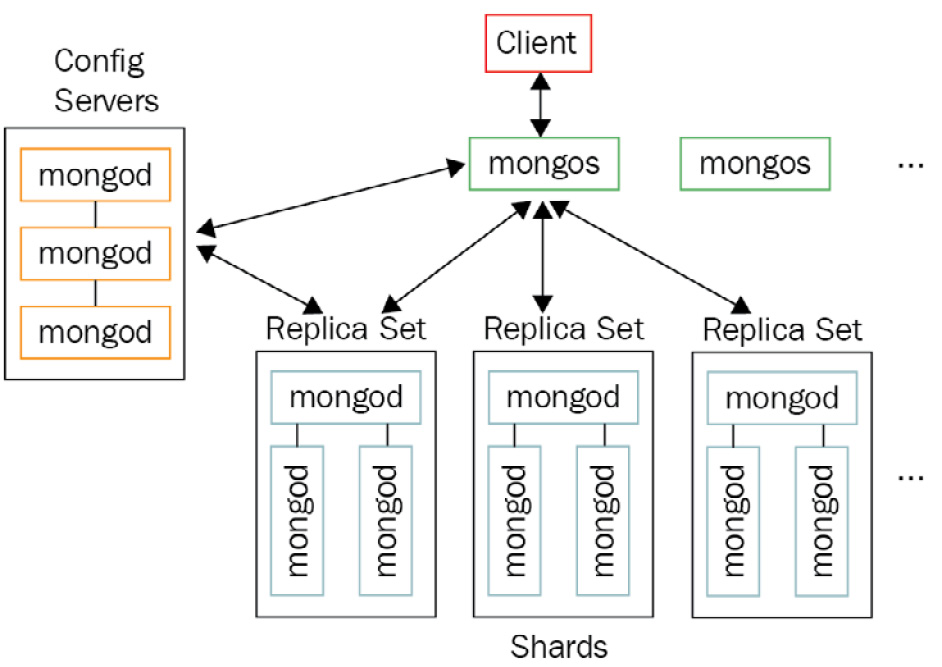
分片解决水平扩展问题,一个集合中的数据太大,在一个服务器上放不下,要放到多个服务器上。把数据分成一个一个的子集,把每一个子集存在一个服务器(分片)上,所有的分片合在一起,形成一个分片集群,每一个分片必须是复制集。一个完整的分片集群中除了分片之外,还有一个配置服务器和一个或多个mongos(路由,从配置服务器获到信信息,查找哪个分片)。配置服务器也要是复制集,它存储整个分片集群的元信息和配置信息。mongos 提供客户端和数据库之间的接口,隐藏了分片集群的实现细节,查询分片集群和查询没有分片的集合使用的方法是一样的。
MongoDB 脚本:mongo shell 是JS 解释器,我们可以把要执行的mongo shell的命令写到一个JS文件中,然后,用mongosh <script_name>.js 这个JS文件也称为mongodb的脚本。 但在JS的文件中,并不能获取到mongo shell 的全局变量,比如,db, show dbs, 不过,有对应的JS 函数

默认情况下,在哪个文件夹下启动的mongosh, mongosh就在哪个文件夹下面查找脚本文件。在Linux下,打开终端窗口就是用户目录,在下面建一个mong.js文件,内容是
console.log(db.adminCommand('listDatabases'))
然后mongosh mong.js 就会执行脚本文件。
Audit log 和log是两个不同的概念, 日志记录是指在程序执行过程中发生的程序层面的事件,包含对开发、错误识别和修复有用的信息。日志记录包含对开发人员有用的详细程度的信息( Logging includes information about what happened in the level of detail that is useful for the developers.) 。Audit log 是业务层面的事件,指的是用户执行的操作,Auditing answers the question of “Who did What and When?” in the system. We might also want to answer the question of “Why?” in the case of a root cause investigation. 下面是一个audit log


 浙公网安备 33010602011771号
浙公网安备 33010602011771号