
GraqphQL 学习
GraphQL是Graph+QL。Graph是图,用图数据结构来描述数据,来组织数据。QL是query language,写请求就像写query。GraphQL就是用图来组织数据,写query的方式来请求。怎样用图的方式来组织数据?定义Schema(类型), type 类型名称 {},
type Library { branch: String! books: [Book!] } type Book { title: String! author: Author! } type Author { name: String! }
大括号中是键值对,键表示该类型有哪些字段可供查询,值表示查询该字段会返回什么类型的数据。查询library可以查到book,查到book可以查到author,数据形成一个图。String,Int,Float,Boolean,ID是GraphQL提供的基本数据类型,ID类型比较特别,表示唯一性,它会被序列化成字符串。Library,Book是基于基本类型,自定义的对象类型。定义对象类型,不能嵌套定义,每一个对象类型必须单独定义,再进行组合。!表示不能返回null,如果没有!,就可以返回null, null可以赋值给任意类型。[]表示返回的是列表(list)。Graphql没有时间类型,不过可以用字符串表示,new Date().toISOString()。为了能够让客户端查询数据,还要定义一个特殊的类型Query。Query是客户端和服务端的约定,客户端能够查询哪些字段,是查询的入口点。
type Query {
library: Library
}
客户端能够查询library了,但怎么请求?首先是一个{},然后是{libary}, 因为library返回的是一个对象类型,还要继续{},query需要的某个或某些属性,括号里面就是想要的属性,
{
library {
branch
books {
title
}
}
}
这就是GraphQL提出的,query要明确表明想要什么。query都是query对象的某个属性或某些属性,对象类型{属性} 就是query对象类型的某个属性。 但刚开始时,libarary并不是某个对象的属性,它是根,所以写一个{},表示根对象,所有的query 都是以{}开始,以对象的某个属性结束,这也是scalar 类型的概念,query最终都会落脚到scalar类型。scalar类型就是类型再也没有子字段,通常是基本数据类型。query写好了,后端怎么返回数据呢?函数,为类型中的每一个字段提供函数,进行数据的返回,这些函数也称为resolver函数,query发过去,调用函数,返回数据
Query { library: () => { return { branch: '1', books: ['js', 'react'] } } } Library { branch: () => '11', books: () => ['html', 'css'] }
schema中定义返回什么类型,resolver函数一定返回什么类型,请求和返回值都是JSON数据。GraphQL的核心是schema(类型)。前端根据定义的schema来query,服务端根据schema来提供resolver函数。增删改也是一样,定义特殊的类型Mutation,字段表明可以进行哪些增删改,值是增删改返回什么数据类型,类型的定义没有什么区别。
以上说的都是理论,GraphQL只是定义了一套理论,如果要实践,就要写一个GraphQL实现。先看一下,写一个GraphQL实现需要什么?首先,要提供一个请求入口(endpoint),供客户端访问,比如http://localhost:4000/graphql。其次,解析Query请求, 看是否符合GraphQL语法规范(有效的语法),是否符合Schema的定义。然后调用Resolver函数,query就查询数据,mutation就存储数据,subscription,服务端还要开一个chanel来进行数据通信。最后,收集所有resolver返回的数据,把它序列化为JSON格式,返回给请求者。
import { ApolloServer } from '@apollo/server';
import { startStandaloneServer } from '@apollo/server/standalone';
//创建Schema, 在模板字符串前面加#graphql指令,字符串被认定为graphql语法,可能被语法高亮。
const typeDefs = `#graphql
type Query {
hi: String
}
`;
// 创建resolvers, 它是一个对象
const resolvers = {
Query: {
hi: () => "world"
}
};
// 把 schema 和resolvers 传递给Apollo Server, 创建服务器
const server = new ApolloServer({
typeDefs,
resolvers,
});
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 },
});
console.log(`🚀 Server ready at: ${url}`);
node index.js,启动服务,浏览器输入localhost:4000,出现一个 sandbox,左边列出了Schema,中间Operation写query,比如{hi}, 右边的response返回结果。再写个复杂一点的的schema,带参数并返回对象类型。比如查询某个用户信息,需要传递id。schema改成如下
const typeDefs = ` type Query { employee(id: ID!): Employee } type Employee { id: ID name: String email: String } `;
query如下
{ employee(id: 42) { name email } }
那怎么写resovler呢?请求Query类型的employee,employee需要一个resolver函数,接受参数,但它返回的是Employee类型,query又请求了Employee类型的name和email, Employee类型的name和email也需要resolver函数返回数据,但name和email返回的数据是employee resolver返回那个employee对象的name 和email,它们resolver函数依赖employee的resolver函数的返回值,从employee resolver的返回值中取数据。怎么建立resolver之间的关系呢?参数。resolver函数本身接受4个参数(parent, args, context, info)。parent 用来建立联系,args接受客户端传递过来的数据。先调用employee的resolver,返回employee(对象),再调用name和email的resolver,从employee中查询name和email, 有先有后,先的如果为父,那么后的就为子,employee的resolver的返回值可以看作是name和email的resolver的父级。name和email中resolver的parent参数,就是employee resolver的返回值。employee由于是顶级查询,一般没有parent,所以参数用 _ 表示。整个resolver 如下
const resolvers = { Query: { employee: (_, args) => { console.log(args.id); return { "id": 42, "name": "sam", "email": "123@qq.com" } } }, Employee: { name: parent => parent.name, email: parent => parent.email } };
当resolver返回一个对象类型时,服务器会遍历该类型的字段,依次调用每一个字段的resolver 函数,然后把这些函数的返回值收集起来,形成一个响应。在这个例子中,GraphQL服务继续一个接一个的遍历Employee对象的字段(name和email),调用每个字段的resolver函数,每个resolver函数都会接受到employee的resolver函数的返回值作为第一个参数,GraphQL服务使用这3个resovler函数的返回值,组合到一起,形成query的响应(As each field is resolved, the resulting value is placed into a key-value map with the field name(or alias) as the key and the resolved value as the value. This continues from the bottom leaf fields of the query all the way back up to the original field on the root Query type. Collectively these produce a structure that mirrors the origianl query which can then be send(typically as JSON) to the client which requested it )
{ data: { employee: { name: "sam", email: "123@qq.com" } } }
但是像email这种resolver(parent => parent.email),只是parent对象的某个属性值,太简单了,于是许多grahpql实现都提供了一个这样的默认resolver。如果某个字段没有resolver 函数,直接读取parent对象上和这个字段名相同的key的值。email字段名匹配parent对象的email属性。resovler通常这么写
const resolvers = { Query: { employee: (_, args) => ({ "id": 42, "name": "sam", "email": "123@qq.com" }) } };
当看到一个schema返回了对象类型,但该对象类型并没有为每个字段提供resolver时,不是不用写resolver函数,而是使用了默认的resolver。由于schema定义employee(id: ID!): Employee,employee的resolver可以返回null,表示没有找到id对应的employee。
const resolvers = { Query: { employee: (_, args) => null } };
query请求没有变化,服务器直接返回了employee: null,并不会调用Employee类型上面的resolver
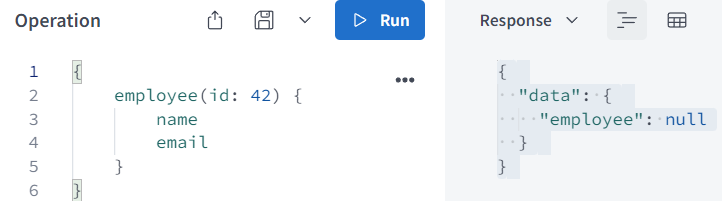
请求一个可能返回null的字段,客户端虽然请求了它的属性,但它可以直接返回null,没有子属性。同时请求id为42和43的employee的信息呢?
{ employee(id: 42) { name email } employee(id: 43) { name email } }
报错了,不同的参数,却query相同的字段,使用alias,给字段起别名,格式为别名: schema名
{ employee42: employee(id: 42) { name email } employee43: employee(id: 43) { name email } }
可以对任何查询的字段进行alias,name也可以写成 nickname: name。只要GraphQL中定义的schema和自己要求的字段不一致,都可以alias。但还有一个问题,name,email字段重复了,可以把这些字段抽取出来,形成一个fragement。 由于字段都是定义在Schema类型中的,所以fragement也是基于Schema类型的。 在query中使用fragement,在它前面加...,query如下
{ employee42: employee(id: 42) { ...NameEmail } employee43: employee(id: 43) { ...NameEmail } } fragment NameEmail on Employee { nickname: name email }
再进一步,参数能不能是个变量, 想查询哪个id就传哪个id?有点复杂,首先给query起个名字,在最外层的{前面加query关键字和名称,比如 query getEmployeeById {...},然后再在名字后面加(),括号中定义变量(变量名:变量类型)。变量名必须以$开始,变量的类型必须是scalars, enum,或input 类型。定义好变量后,query 语句中就可以使用变量。
query getEmployeeById($employeeId: ID!) { #声明变量 $employeeId employee(id: $employeeId) { #使用变量 name email } } # 或者 query getEmployeeById($employeeId: ID!) { # 如果query中使用framement employee(id: $employeeId) { ...NameEmail } } fragment NameEmail on Employee { # name(id: $employeeId) fragement也能够获取到变量 name email }
在sandbox,中间Operation下面有一个Variables, 可以给query中的变量传值,要传一个对象,属性是在query中定义的变量,不过没有$符号,值就是query中变量要接受的值,比如{employeeId: 42}。说一下enum类型,有些变量的取值是有特定范围的,比如性别,就男和女。声明类型时把可能取值范围都列出来,这个类型用enum来声明,
enum Gender {
MAN
WOMAN
}
由于enum类型的变量取值只能是它定义的列表中的一个,Apollo Server会把值序列化为字符串,enum类型可以和scalar 类型一样使用。
const typeDefs = ` type Query { employee(id: ID!, gender: Gender): Employee } type Employee { id: ID name: String email: String } enum Gender { MAN WOMAN } `
然后query如下
query getEmployeeById($employeeId: ID!, $gender: Gender) {
employee(id: $employeeId, gender: $gender) {
name
}
}
给变量传值时,gender的取值为 “MAN” 和“WOMEN” 两种,传的是字符串,就是因为Apollo Server 把enum 序列化成了字符串
{ "employeeId": 42, "gender": "MAN" // 传的是字符串 }
input类型,和type定义类型一样,不过它仅用于定义参数类型。当Schema要求传递的参数越来越多时,一个一个列出就有点麻烦,可以声明一个对象类型,Schema中,参数是对象类型。比如新建一个employee,需要姓名,年龄,性别,地址等。input CreateEmployeeInput {name: String, gender: Gender, age: int} ,更改数据用mutation,type Mutation { createEmployee(input: CreateEmployeeInput): Employee } ,typeDefs 添加如下内容,
const typeDefs = `
# ....
type Mutation {
createEmployee(input: CreateEmployeeInput): Employee
}
input CreateEmployeeInput {
name: String
age: Int
gender: Gender
}
`;
resolver 中添加
const resolvers = { // ... // 添加muation Mutation: { createEmployee(_, args) { const {name, age, gender} = args.input; return { name, age, gender } } } };
可以直接写Muation的请求,
mutation { # 如果在语句中直接传参,enum类型变量的值直接写类型中的任意一个值,如MAN createEmployee(input: {name: "sam", age: 30, gender: MAN}) { name } }
可以声明变量的方式,来发送请求
mutation CreateEmployee ($input: CreateEmployeeInput) { createEmployee(input: $input) { name } } # 传递的参数 { "input" : { "name": "sam", "age": 30, "gender": "MAN" } }
GraphQL还有几个不太常用的语法:指令,interface,union。指令是用来改变query结构的,在某些情况下,query这个字段,在某些情况下,又不query这个字段,@include(if Boolean) 和@skip(if Boolean) 如要Boolean是true,返回值包含或跳过,false则相反
query getEmployeeById($employeeId: ID!, $gender: Gender, $withName: Boolean!) { employee(id: $employeeId, gender: $gender) { name @include(if: $withName) email } }
union是几个类型联合在一起形成一个新类型,union Person = Student | Employee,当Schema中返回Person时,可能返回Student类型,也可能返回Employee类型。这时resolver和query都有点复杂,由于resolver中不能返回抽象类型,person的resolver它必须返回Student或Employee类型的对象,同时在Person类型下写__resolveType确定返回的真正类型。
const typeDefs = ` type Query { person: Person } union Person = Student | Employee type Employee { name: String email: String } type Student { name: String studentNumber: Int } `; const resolvers = { Query: { person: () => ({ // 返回 Employee 类 "name": "sam", "email": "123@qq.com" }) }, Person: { __resolveType(parent) { if(parent.email) { return "Employee" } if(parent.studentNumber) { return "Student" } return null // 抛出错误 } } };
由于返回的类型不确定,query时,也要query某个类型字段,使用inline fragement。此时,还可以query 一个__typename字段,看是返回什么具体类型, __typename不用定义,Apollo Server 自动加的, 每一个对象类型都自动获得一个__typename字段
{
person {
__typename,
... on Student {
studentNumber
}
... on Employee {
email
}
}
}
interface定义了多个类型共有的字段,子类型(具体类型)必须实现它, 当shema中返回interface类型时, resolver中要必须返回具体类型,当query interfacei 中的字段时,可以正常 query,如果要query特定的类型,必须使用inline framgemnet.
const typeDefs = ` type Query { person: Person } interface Person { name: String } type Employee implements Person { name: String email: String } type Student implements Person { name: String studentNumber: Int } `; const resolvers = { Query: { person: () => ({ // 返回 Employee 类 "name": "sam", "email": "123@qq.com" }) }, Person: { __resolveType(parent) { if(parent.email) { return "Employee" } if(parent.studentNumber) { return "Student" } return null // 抛出错误 } } };
query
{
person {
__typename,
name # 请求interface中的字段
... on Student { #请求具体类型的字段
studentNumber
}
... on Employee {
email
}
}
}
现在resolver都是简单的同步函数,如果resolver中有异步操作,比如数据库查询,它就要返回promise,Apollo Server会等待Promise的resolve 或reject ,然后返回数据。用pg库演示一下,在默认数据库postgres下,创建users表,
CREATE TABLE users( id INT PRIMARY KEY, name VARCHAR(10), email VARCHAR(50) ) INSERT INTO users (id, name, email) VALUES (1, 'sam', '123@qq.com'), (2, 'jason', '456@qq.com');
在代码中,npm i pg, 连接数据库。
import pg from 'pg' // ... const pgClient = new pg.Client({ connectionString: 'postgres://postgres:123456@localhost:5432/postgres' }); await pgClient.connect(); const { url } = await startStandaloneServer(server, { listen: { port: 4000 }, });
pgClient就是数据库的连接实例,用它来操作数据库。那resolver中怎么获取到这个连接呢?Apollo Server 有一个context的概念,在配置startStandaloneServer时设置,它是一个函数,返回一个对象,这个对象就可以在resover中的第三个参数context获取到。
const { url } = await startStandaloneServer(server, { context: () => ({ pgClient }), listen: { port: 4000 }, });
然后
const typeDefs = ` type Query { users: [User] } type User { name: String email: String } `; const resolvers = { Query: { users: async (_, args, context) => { // async 函数自己就是返回Promise // 从context中获取数据库的连接 const users = await context.pgClient.query('select * from users') return users.rows } }, };
对数据库的操作,还可以进行一层抽象,添加了一层dataSources 层,data source 层操作数据库,resovler 调用data sources 层。新建userModel.js, 专门操作users表,
export const generateUserModel = (pgClient) => ({ getAll: () => { return pgClient.query('select * from users') } });
错误处理:GraphQL执行过程中出现错误,Apollo Server会捕获这个错误,然后把它返回客户端,服务器不会崩溃,也就是说,抛出错误是可行的,在resovler函数中,可以抛出错误。比如验证不通过,抛出错误。 如果觉得返回的错误信息太多,可以定制错误。ApolloServer 构造函数除了接受typeDefs和resolvers,还接受formatError,格式化GraphQL执行产生的错误。GraphQL产生的每一个错误在返回客户端之前,都会经过formatError。它是一个函数,接受两个参数,第一个是JSON化后的错误信息,用来作为响应返回给客户端,第二个是原始的错误,如果是resovler中抛出的错误,error会被GraphQLError包裹。此时,要想获取原始错误,需要unwrapResolverError
const server = new ApolloServer({ typeDefs, resolvers, formatError(formattedError, error) { if (formattedError.message.startsWith('Database Error: ')) { // 只要返回message 字段就可以了 return { message: 'Internal server error' }; } // 或者 // if (error instanceof CustomDBError) { // return { message: 'Internal server error' }; // } // 再或者 // import { unwrapResolverError } from '@apollo/server/errors'; // if (unwrapResolverError(error) instanceof CustomDBError) { // return { message: 'Internal server error' }; // } return formattedError; } });
第二种错误处理方式是构建带有error的类型,返回这个类型,
const typeDefs = ` type Query { user(id: Int): UserWithError } type User { name: String email: String } type UserError { message: String } type UserWithError { userErrors: [UserError!]! user: User } `; const resolvers = { Query: { user: async (_, args, context) => { if (args.id > 2) { return { userErrors: [{ message: "没有user" }], user: null } } const users = await context.pgClient.query('select * from users') return { userErrors: [], user: users.rows[args.id] } } }, }; // query { user(id: 3) { user { email } userErrors { message } } }
GraphQL的resolver 函数, 查询数据库时,会造成 N+1 查询 。比如一个博客网站, 提供query查询整个posts, 由于post 和users 又有关系, 查询Post时也想查询它的user。
const typeDefs =` type Query { posts: [Post!]! } type Post { id: ID! title: String! user: User! } type User { id: ID! name: String! email: String! } `
在pg库创建posts表,插入几条数据
CREATE TABLE posts( id INT, title VARCHAR(100), userId INT ) INSERT INTO posts (id, title, userid) VALUES (1, 'learing web development', 1), (2, 'learing react', 1), (3, 'learing redux', 1), (4, 'learing backend development', 1), (5, 'learing node.js', 2) ;
resolvers 修改如下
const resolvers = { Query: { posts: async (_, args, { pgClient }) => { const query = 'select * from posts' console.log(query, 'post query') const result = await pgClient.query(query) return result.rows }, }, Post: { user: async (parent, args, { pgClient }) => { const query = { text: 'SELECT * FROM users WHERE id = $1', values: [parent.userid] } console.log(query, 'user query') const result = await pgClient.query(query) return result.rows[0]; // 是返回一个对象 }, }, };
查询post对应的user时,
{
posts {
title
user {
name
}
}
}
看控制台的输出,post的查询(select * from posts)只执行了一次,而user的查询(SELECT * FROM users WHERE id = $1)却执行了5次。posts resovler返回的posts中每一条post都会发送一次请求(SELECT * FROM users WHERE id = $1),返回的posts中有多少条post, 就要执行多少次请求,这就是N。

但是1,2,3,4条post是属于user 1, 而5属于user 2,能不能把前4个变成一个请求,
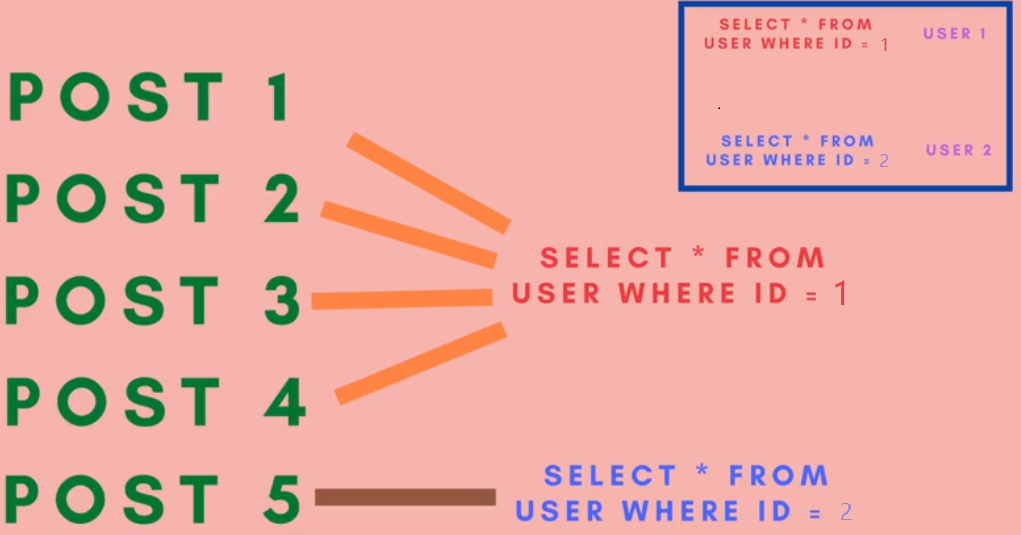
这要用DataLoader库,npm install dataloader,它会把所有的user的请求用的id 参数都收集起来,发送一个query, 一个请求带着所有的userid,然后返回所有的数据,整个user的查询就只有一次查询。要先定义一个批量函数,接受所有的userId, 去请求数据
const batchUsers = async (userIds) => { const query = { text: 'SELECT * FROM users WHERE id = ANY($1::int[])', values: [userIds] } const result = await pgClient.query(query) return result.rows }
怎么使用呢?把它传给DataLoader的构造函数,创建一个DataLoader的实例,然后在resovler中调用实例的load方法,把id传递进去。
import Dataloader from "dataloader"; function userLoader(pgClient) { const batchUsers = async (userIds) => { const query = { text: 'SELECT * FROM users WHERE id = ANY($1::int[])', values: [userIds] } const result = await pgClient.query(query) return result.rows } return new Dataloader(batchUsers); } // post resolvers Post: { user: async (parent, ars, { userBatch }) => { return userBatch.load(parent.userid) } }, // 把 userloader 放到context中,供resolver 使用 const { url } = await startStandaloneServer(server, { context: () => ({ pgClient, userBatch: userLoader(pgClient) }), listen: { port: 4000 }, });
现在的batchuser方法还有一点小问题,post 中resolver 调用load方法,调用了5次,分别传入userid 是1,1,1,1,2, batchUsers方法的参数userIds接受到[1, 2],返回user数组。如果返回的数组是
[ { id: 2, name: 'jason', email: '456@qq.com' }, { id: 1, name: 'sam', email: '123@qq.com' } ]
就会有问题,接收的参数是数组,返回的结果也是数组,要建立某种关联。dataLoader 会按照传递进来的参数的顺序从返回的结果中取值,也就是说,userid 是1, 是参数数组的第0个元素, dataloader就会从返回的结果中取第0个元素,bashUser要求返回的数据的id和 传入的数据的 ids 顺序保持一致
function userLoader(pgClient) { const batchUsers = async (userIds) => { const query = { text: 'SELECT * FROM users WHERE id = ANY($1::int[])', values: [userIds] } const result = await pgClient.query(query) const userMap = {}; result.rows.forEach(user => { userMap[user.id] = user }) // {1: {id: 1, name: 'sam'}, 2: {id: 2} } return userIds.map(id => userMap[id]) } return new Dataloader(batchUsers); }
权限管理:context可以是异步的函数,并且接受request 和response 做为参数,因此可以从request的header中,取出token, 然后访问数据库获取到用户信息,放到context中,此时,resolver中都能获取user信息,可以进行权限管理
const { url } = await startStandaloneServer(server, {
context: async (request, resonse) => {
// 假设有一个getUserInfo
const user = await getUserInfo(request.header.token)
return ({
pgClient,
userBatch: userLoader(pgClient),
user
})
},
listen: { port: 4000 },
});
GraphQL服务写好了,Apollo Studio测试成功,前端页面怎么调用?Graphql和Restful API 有几个不同, 首先,GraphQL只有一个endpoint, 并不像restful 有很多endpoint。其次,graphql 并不遵循http 规范,前端都是发送post请求,query只是简单的字符串,放在请求的body中。后端graphql 报错,有可能返回200,需要查看响应的对象,GraphQL的一切都是基于响应。GraphQL的API可以用fetch请求,但通常使用第三方GraphQL客户端,比如 apollo client, 它们帮忙处理http请求和响应,只需要把query和variables传递给它们,apollo client还有cache功能。npx create-react-app graphql-client 创建一个client项目,npm install @apollo/client graphql安装依赖,在index.js中初始化apollo client, 就是连接哪个服务器,使用什么缓存,默认情况下,apollo client 会把query回来的数据进行缓存。npm install @apollo/client graphql
import { ApolloClient, InMemoryCache, ApolloProvider } from '@apollo/client';
const client = new ApolloClient({
uri: 'http://localhost:4000/graphql', // 链接本地服务器
cache: new InMemoryCache(),// 缓存到内存中
});
const root = ReactDOM.createRoot(document.getElementById('root'));
root.render(
<ApolloProvider client={client}>
<App />
</ApolloProvider>,
);
在App.js中请求posts, 可以像普通的fetch请求一样,在useEffect中调用client的query,但apollo client 提供了useQuery,它会返回error, loading 和data,实现了部分的状态管理。
import { useQuery, gql } from '@apollo/client';
const GET_POSTS = gql`
query GetPosts {
posts {
id
title
user {
id
name
}
}
}
`;
export default function App() {
const { loading, error, data } = useQuery(GET_POSTS);
if (loading) return <p>Loading...</p>;
if (error) return <p>Error : {error.message}</p>;
return data.posts.map(({ id, title, user }) => (
<div key={id}>
<h3>{title}</h3>
<p>{user.name}</p>
</div>
));
}
graghql的返回值一定包含data或error,这是规定,当成功请求到数据时,data存在,error是null,当请求失败,error包含错误信息,data为null。默认情况下,Apollo client会把query的数据缓存起来,安装浏览器插件Apollo Client Devtools能看到缓存数据,插件中使用的也是程序中创建的client。在Firefox下面
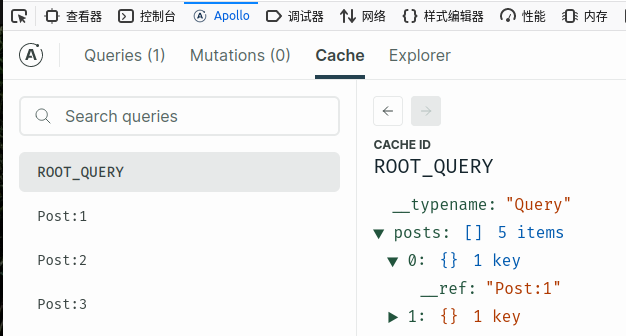
缓存的数据是扁平化的,它不是把整个数组进行缓存,而是把数组中的每一项拿出来进行缓存,数组中使用引用进行关联。post中关联的user也拿出来进行单独缓存,post和user使用引用进行关联,缓存的id是返回的__typenamet和Id,所以graphql 请求一定要返回id。it automatically attempts to identify and store the distinct objects (i.e., those with a __typename and an id property) from a query's data into separate entries within its cache.
写一个mutation, 更新了一个 post,在服务器typeDefs加
type Mutation { updatePost(id: ID!, title: String!): Post }
在resolvers中加
Mutation: { updatePost: async (_, args, {pgClient}) => { var params = [args.title, args.id] // 要使用return * 把更新后的数据返回 var query = 'UPDATE posts SET title = $1 WHERE id = $2 RETURNING *'; const result = await pgClient.query(query, params); return result.rows[0] } }
在前端app.js中,加一个update button,添加onClick事件,调用updatePost
const UPDATE_POST = gql` mutation UpdatePost($updatePostId: ID!, $title: String!) { updatePost(id: $updatePostId, title: $title) { id title } } ` export default function App() { const { loading, error, data } = useQuery(GET_POSTS); const [updatePost] = useMutation(UPDATE_POST); if (loading || error) return null return ( <> <div><button>Add post</button></div> <div><button>delete post</button></div> { data.posts.map(({ id, title, user }) => ( <div key={id} style={{ display: 'flex' }}> <h3>{title}</h3> <p>{user.name}</p> <button onClick={() => { updatePost({ variables: { updatePostId: id, title: `${title} ${id}` } }) }} > updatePost </button> </div> )) } </> ) }
点击updatePost 按钮,页面实时显示了更改后的数据。mutation只是更新一条数据时,apollo client会自动更新cache,根据id进行匹配。如果mutation返回的字段比缓存的对象的字段少,剩下的字段保持原样不变。当写mutation时候,最好想一下已经写过的query,最好返回的数据和query返回的数据相同同。
addPost(id: ID!, title: String!, userId: ID!): Post
resolves对象的Mutation下面增加
addPost: async (_, args, {pgClient}) => {
var params = [args.id, args.title, args.userId]
var query = 'INSERT INTO posts VALUES($1, $2, $3) RETURNING *';
const result = await pgClient.query(query, params);
return result.rows[0]
}
给前端的Add post, 添加一个onclick事件
const ADD_POST = gql` mutation AddPost($addPostId: ID!, $title: String!, $userId: ID!) { addPost(id: $addPostId, title: $title, userId: $userId) { id title user { id name } } } ` const [updatePost] = useMutation(UPDATE_POST); <div><button onClick={() => { addPost({ variables: { addPostId: 10, title: 'Learning Java', userId: 2 } }) }}
添加成功,页面并没有显示添加成功的post,看一下控制台的cache,Post:10 已经缓存起来了,但是页面上显示的是posts,在ROOT_QUERY 中,它的cache并没有发生变化,还是5个数据。a newly cached object isn't automatically added to any list fields that should now include that object。本地cache的post数据和服务器中的post并不一致(同步)了。执行mutation时,修改后端数据。通常,希望更新本地缓存的数据来反映后端的修改。最直接的办法是把这次mutation影响到的query再执行一遍(refetch the query)。有两种方式实现,一种是使用useQuery返回的refetch,一种是useMuattion接受第二个参数refetchqueries, 把要refetch的query列出来。使用refetch
import { NetworkStatus } from '@apollo/client';
export default function App() {
const { loading, error, data, refetch, networkStatus } = useQuery(GET_POSTS, {
notifyOnNetworkStatusChange: true,
});
const [updatePost] = useMutation(UPDATE_POST);
const [addPost] = useMutation(ADD_POST);
// 检测networkSatus的状态,一定要在loading 和error 检测之前。
if (networkStatus === NetworkStatus.refetch) return 'Refetching!';
if (loading || error) return null
return (
<>
<div><button
onClick={async () => {
await addPost({
variables: {
addPostId: 10,
title: 'Learning Java',
userId: 2
}
})
// refetch the posts query
refetch()
}}
>Add post</button></div>
...
使用refetchQueries
<div><button onClick={async () => { await addPost({ variables: { addPostId: 11, title: 'Learning spirng', userId: 2 }, refetchQueries: [ "GetPosts", //query的名称
// 或者{query: GET_POSTS} ], }) }} >Add post</button></div>
但多了一次网络请求,如果mutation返回了变更的所有字段,我们可以直接更新缓存,mutation第二个参数中,接受一个update方法, 它有两个参数,第一个参数是cache,表示Apollo client缓存对象,它提供对缓存 API 方法的访问,例如 readQuery / writeQuery、readFragment / writeFragment、modify 和 evict。这些方法使您能够对缓存执行 GraphQL 操作,就像您正在与 GraphQL 服务器交互一样。第二个参数是mutation的返回值,使用这个值通过 cache.writeQuery、cache.writeFragment 或 cache.modify 更新缓存。
<div><button onClick={async () => { await addPost({ variables: { addPostId: 11, title: 'Learning spirng', userId: 2 }, update(cache, { data: { addPost } }) { cache.modify({ fields: { posts(existingPostsRefs = []) { const newPostRef = cache.writeFragment({ data: addPost, fragment: gql` fragment NewTodo on Post { id title } ` }); return [...existingPostsRefs, newPostRef]; } } }); } }) }} >Add post</button></div>
cache.modify 直接操作缓存,更改某个缓存字段的值,或删除某个缓存字段,所以它有fields字段,修改哪些缓存字段。怎么修改呢?给修改的字段名定义一个函数,函数接受现有的字段的值作为参数,然后返回新值作为缓存值。添加一个post,更改的是缓存中ROOT_QUERY.posts数组,所以给posts字段添加了一个函数,把新添加的post的引用添加到posts数组中。借助 cache.writeFragment,可以获得对添加的 post 的内部引用,然后将该引用附加到 ROOT_QUERY.posts 数组。在mutation函数中对缓存数据所做的任何更改都会自动广播到正在监听该数据更改的查询。因此,您的应用程序的 UI 将更新以反映这些更新的缓存值。
更新缓存还有一种情况,

还有一种情况,就是messages 和chatId 想关联,那就不能直接cache.modify了,cache.modidy, 会更改所有的messages,就要使用readQuery和writeQuery了。
const useCreateMessage = (chatId: string) => { return useMutation(createMessageDocument, { // update update(cache, { data }) { const messagesQueryOptions = { query: getMessagesDocument, variables: { chatId, }, }; const messages: any = cache.readQuery({ ...messagesQueryOptions }); console.log(messages, 'message') if (!messages || !data?.createMessage) { return; } cache.writeQuery({ ...messagesQueryOptions, data: { messages: messages.messages.concat(data?.createMessage), }, }); }, }); };
和create一样,当mutation修改多个对象或删除对象时,Apollo 缓存也不会自动更新。只有当mutation更新单个对象时,它才会更新。所以删除或更改多个对象时,还是需要refetch或update函数来更新缓存。
以上就是cache优先策略,优先使用cache,如果cache中没有数据,才请求服务器。cache 是整个应用的cache,整个应用的所有数据都进行cache。所以对mutation 来说,要么更新cache, 要么refetch,来更新缓存,以保持数据一致。可以更改cache策略,给useQuery提供fetchpolicy参数,比如fetchpolicy: 'network-only', 先网络请求服务器,不用检查cache有没有数据。不过,cache 策略,好像都是针对组件的首次渲染,组件首次出现时,执行的cache策略,比如页面的首次加载,路由时组件来回切换。如果组件一直存在,组件更新时,都是走cache,从cache中获取数据,不管是什么fetchpolicy(除了standby),cache更新了,页面都会更新,cache没有更新,页面不会更新。
DataLoader 详细解释
DataLoader 在一次事件循环(during one tick of the event loop)中,收集所有的key(collects an array of keys),然后用这些key请求一次数据库(hits the database once with all those keys), 返回一个promise,它resolve 一个数组(Returns a promise which resolves an array of values). 所以我们需要做的就是让DataLoader 是一个批处理的函数,接受数组keys作为参数,返回一个promise,resolve 为值的数组。需要注意的是这两个数组的长度必须相等,因为dataLoader 会进行key/value 键值对存储,数组keys 的第一项是key,数组value的第一项是value,组成一个键值对,数组key的第二项是key,数组value的第二项是value,组成一个键值对,依次类推。
使用DataLoader,使用它的load方法,每一个load方法都保存它的参数key,然后返回promise。在一个事件循环tick中,它收集到所有的key,然后把它们传递给批处理函数。批处理函数返回值存储到相应的key上,最后每一个load方法的promise都resolve成它的参数key 所对应的值。DataLoader 是使用事件循环的tick处理来标记什么时候触发批处理函数。之所以这么做是因为,一个tick结束,一个query的所有load方法都调用完成,也就意味着,Dataloader知道多少key来请求数据库。

如果在一个resolver中就要请求多个id的数据,可以使用loadMany,
userLoader.load([3, 4]).then(res => { console.log('return an array of values', res) })
Data loader 是每一个请求的batch 和cache,当server 收到一个graphql请求后,它就会创建一个DataLoader的实例,来处理请求,当返回响应时,这个DataLoader的实例就会被垃圾回收了。
当booksId传入[1,2,3] 时,数据库返回10条数据,dataLoader的批处理函数要做一个映射,哪一个id和哪些数据对应起来, 看结果是二位数组。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号