
队列
队列,就是排队,先到的站前面,先离开,后到的排后面,后离开。对应到计算机中,就是添加元素在队尾,删除元素是在队头,先进先出或后进后出。添加元素也叫入队(enqueue),删除元素也叫出队(dequeue)。当然还可以查看队头元素,队中元素个数,以及是否为空,所以队列提供了API 就是enqueue, dequeue,getFront, size, isEmpty。
使用单链表实现队列
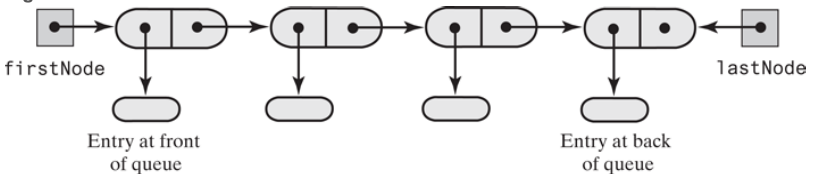
队列在尾部添加元素,在头部删除元素。那就让链表头作为队列的头部,因为链表头部容易执行删除操作(出队)。链表尾部只能作为队列的尾部,执行插入操作(入队)。但链表尾部执行插入操作,有一个问题,那就是每次都要遍历整个链表,找到最后一个元素,才能执行插入操作。为了减少遍历,要再维护一个尾指针,指向链表的尾部。因此,使用单链表实现一个队列,链表需要维护两个指针,头指针和尾指针。头指针指向链表的头部,用于出队。尾指针指向链表尾部,用于入队。
public class LinkedQueue<T> {
private class Node {
T data;
Node next;
Node(T data) {
this.data = data;
}
}
private Node firstNode; //头指针,队头
private Node lastNode; // 尾指针,队尾
private int size;
public void enqueue(T data){}
public T dequeue(){}
public int size(){}
public boolean isEmpty(){}
public T getFront(){}
public void clear(){}
}
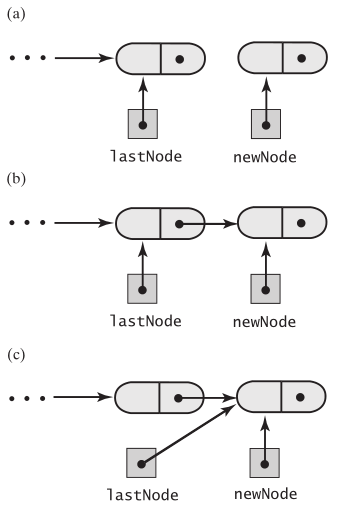
enqueue的实现,就是向链表尾部插入一个节点。创建一个新节点,如果队列(链表)为空,直接让头尾指针都指向它
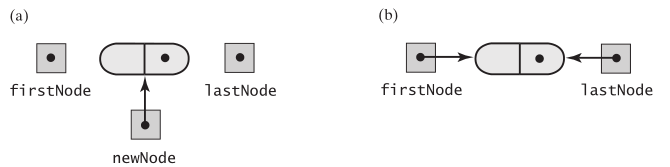
如果链表不空,让尾节点的next指向它,同时更新尾指针的指向,让它指向最新的尾节点
public void enqueue(T data){ Node newNode = new Node(data); if(isEmpty()){ firstNode = lastNode =newNode; } else { lastNode.next = newNode; lastNode = newNode; }
size++; }
dequeue的实现,就是链表头部删除一个节点。链表为空,肯定是不能被删除的,如果链表不空,取出第一个节点,然后让头指针指向它的next节点就好了,
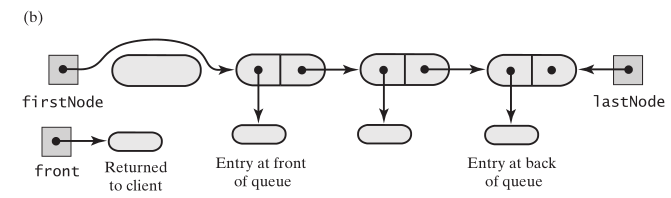
要注意的是一直删除,头指针会指向null,也就是链表中没有元素了,尾指针也要指向null
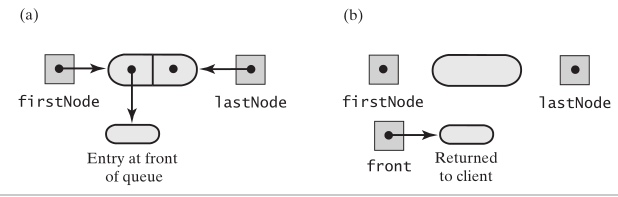
public T dequeue(){ if(isEmpty()){ throw new RuntimeException("链表为空"); } T frontData = firstNode.data; firstNode = firstNode.next; if(firstNode == null){ lastNode = null; } size--; return frontData; }
其它几个实现比较简单
public int size(){ return size; } public boolean isEmpty(){ return firstNode == null; } public T getFront(){ if(isEmpty()){ throw new RuntimeException("链表为空"); } return firstNode.data; } public void clear(){ firstNode = null; lastNode = null; }
数组实现(循环数组)
数组实现队列,queue[0]成为队列的前端,frontIndex和backIndex分别是队列前端和后端元素的索引。
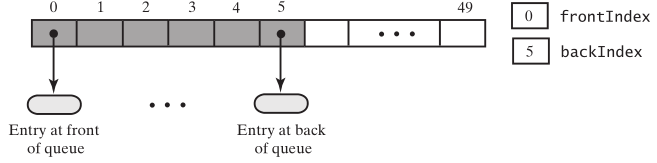
但删除元素时会发生什么?如果坚持新的前端条目在queue[0]中,需要将每个数组条目向数组的开头移动一个位置。这种安排会使出队操作效率低下。相反,当我们删除队列的最前面的条目时,我们可以将其他数组条目保留在其当前位置。出队两次,删除队列前面两个元素
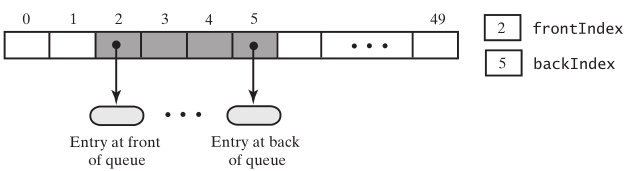
当不停地入队或出队后,可能出现以下情况
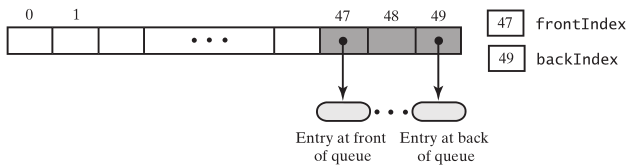
队列中只有3个元素,但头部索引和尾部索引却到了数组的尾部,如果再添加元素,是扩充数组,还是添加到数组的前面?添加前面能充分得用空间
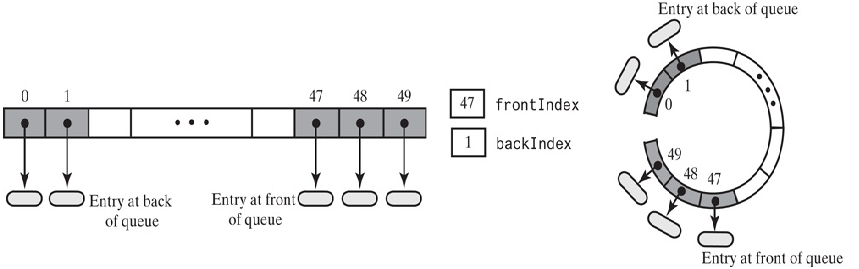
数组表现得像一个圆形,第一个元素跟着最后一个元素后面,计算数组索引的时候,使用取模运算。当backIndex = 49时,再添加一个元素,backIndex成了0,正好是(backIndex+1)%数组的长度。当删除元素的时,也是一样,frontIndex = (frontIndex + 1)%数组的长度。但这也带来一个问题,怎么判断队列是满的,队列是空的?当不停地向队列中添加元素的时候,队列满了
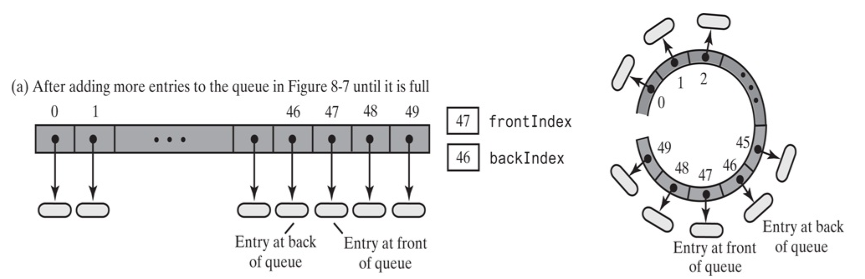
当删除几个元素时,比如5个,frontIndex变成2(47,48,49,0,1)
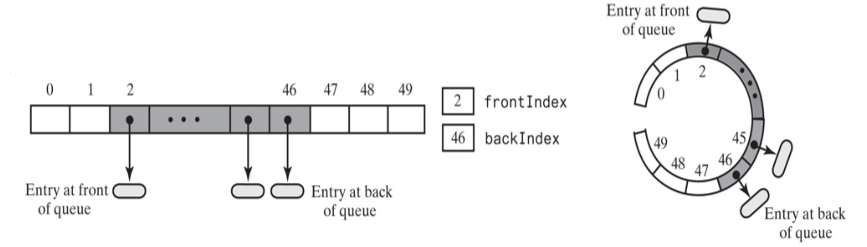
当继续删除,剩下一个元素的时候,

删除最后一个元素

可以发现,frontIndex = backIndex + 1; 和队列是满的的判断条件一致。因此,仅通过backIndex和frontIndex 无法判断队列是满的,还是空的。因此,在使用循环数组时,可以规定一个数组空间不用,假设7个元素的数组,只能使用6个位置,数组为空,frontIndex 为0, backIndex为数组最后一个索引的位置,就是6

当添加一个元素的时候,backIndex变成了0,

继续添加元素,直到满,

再删除一个元素,再添加一个元素
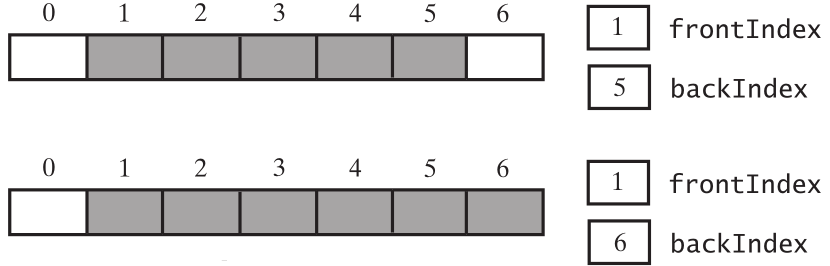
队列还是满的。再删除一个,再添加一个,
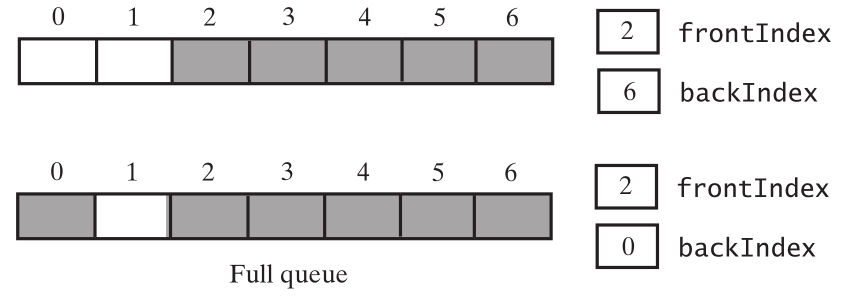
队列还是满的,一直删除,剩下最后一个,和空队列
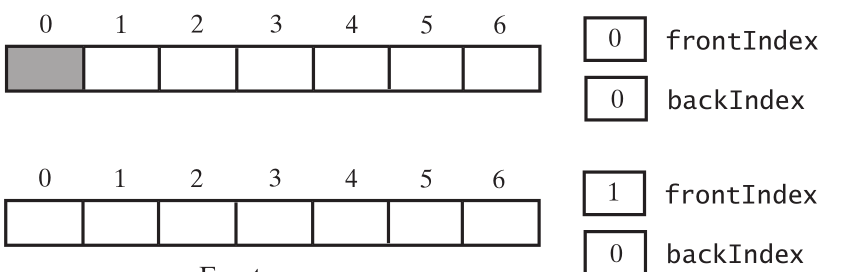
可以发现,空的,没有使用的空间的索引,永远比backIndex 大1,比frontIndex 小1, 因此,frontIndex == (backIndex + 2) % 数组的长度,队列满了。面队列空的时候,frontIndex 比backIndex 大1, 所以frontIndex == (backIndex +1)% 数组的长度, 队列为空。
public class ArrayQueue<T> implements QueueInterface<T> { private T[] queue; private int frontIndex; private int backIndex; private static final int DEFAULT_CAPACITY = 50; public ArrayQueue() { this(DEFAULT_CAPACITY); } public ArrayQueue(int intialCapacity) { @SuppressWarnings("unchecked") T[] temp = (T[]) new Object[intialCapacity + 1]; queue = temp; frontIndex = 0; backIndex = intialCapacity; } @Override public void enqueue(T newEntry) { ensureCapacity(); backIndex = (backIndex + 1) % queue.length; queue[backIndex] = newEntry; } private void ensureCapacity() { } @Override public T dequeue() { if (isEmpty()) throw new RuntimeException("empty"); else { var front = queue[frontIndex]; queue[frontIndex] = null; frontIndex = (frontIndex + 1) % queue.length; return front; } } @Override public T getFront() { if (isEmpty()) throw new RuntimeException("empty"); else return queue[frontIndex]; } @Override public boolean isEmpty() { return frontIndex == ((backIndex + 1) % queue.length); } @Override public void clear() { for (int index = 0; index < queue.length - 1; index++) { queue[index] = null; } } }
看一下ensureCapacity。假设有7个元素的数组,已经满了,现在要扩展成14个元素,
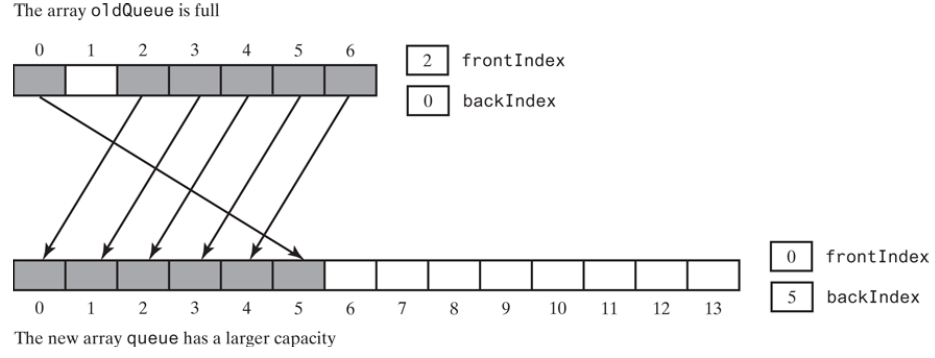
ensureCapacity的实现方式
private void ensureCapacity() { if(frontIndex == (backIndex + 2) % queue.length) { var oldQueue = queue; int oldSize = queue.length; int newSize = oldSize * 2; @SuppressWarnings("unchecked") T[] tempQueue = (T[]) new Object[newSize]; queue = tempQueue; for (int i = 0; i < oldSize - 1; i++) { queue[i] = oldQueue[frontIndex]; frontIndex = (frontIndex + 1) % oldSize; } frontIndex = 0; backIndex = oldSize - 2; } }
循环链表实现
单链表时,尾节点的next指向null,如果尾节点的next指向头节点,链表就循环了。在循环链表中,没有一个节点的next指向null。尽管每一个节点都指向下一个节点,但循环链表还是有头部和尾部之分。外部怎么访问循环链表?需要一个外部的引用指向链表,那指向链表的头节点还是尾节点?指向链表的尾节点。因为指向头节点的话,链表尾部的插入需要遍历整个链表,指向尾节点不存在这个问题。如果在头部插入,循环列表尾节点的next就是头节点,也没有问题,循环列表有如下几种情况
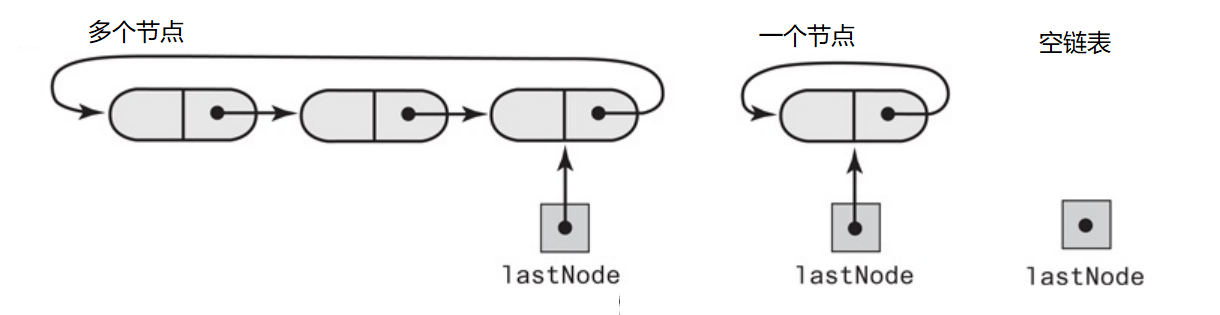
两部分循环链表:
The linked nodes that form the queue are
followed by linked nodes that are available for use in the queue, as Figure 8-13 illustrates. Here
queueNode references the node assigned to the front of the queue; freeNode references the first
available node that follows the end of the queue. You could think of this configuration as two chains—one
for the queue and one for the available nodes—that are joined at their ends to form a circle.
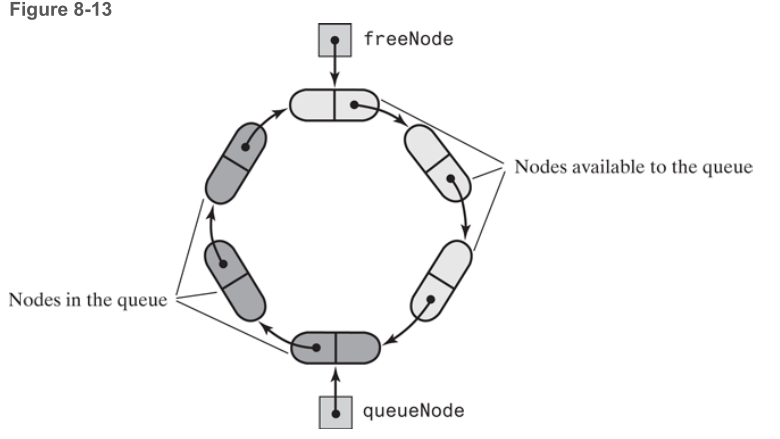
在初始化的时候,没有可用的节点,向队列中添加节点的时候,创建新的node。但是从队列中删除元素的时候,节点仍然在循环队列中。后续的添加就使用这些可用的节点。如果没有这些节点,再重新添加节点。当在循环链表中有一个节点,不使用时,链表是否为空,链表是否满了,很容易判断。
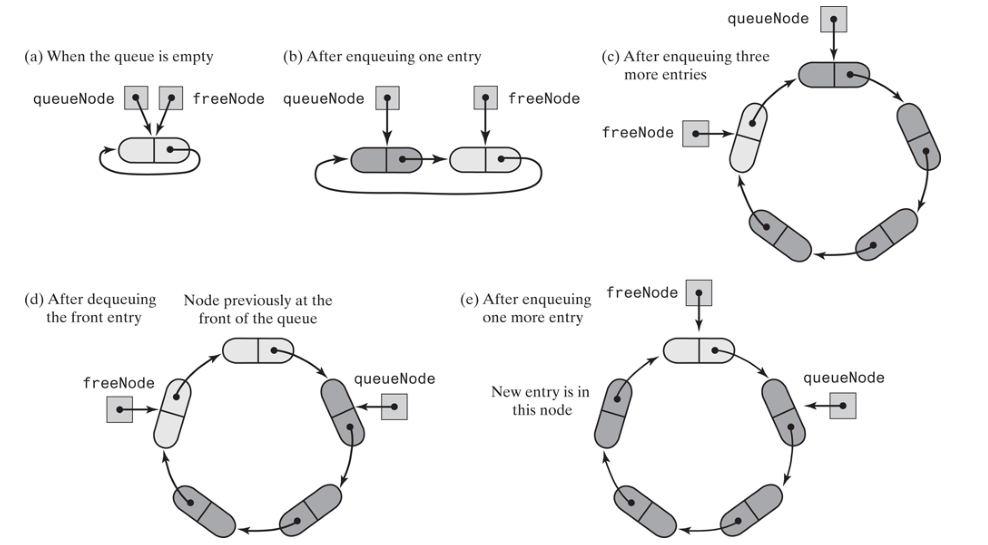
当queueNode和freeNode都引用没有使有的节点时,链表为空。当添加一个元素,创建了一个节点的节点,让queueNode指向它,freeNode仍然指向这个没有使有的节点。queueNode指向队列的头部。 当删除一个节点的时候,queueNode 指针向前移动,后续的添加则使用这个节点,移动freeNode. 当queue 满了,freeNode 的next指针,指向queueNode时,链表满了。
向队列中添加元素时,判断是否有可用的节点,如果没有再创建新的节点,把它放到链表中。把新节点放到freeNode的后面,新的节点变成了未使用的节点,让freeNode 指向新的节点。
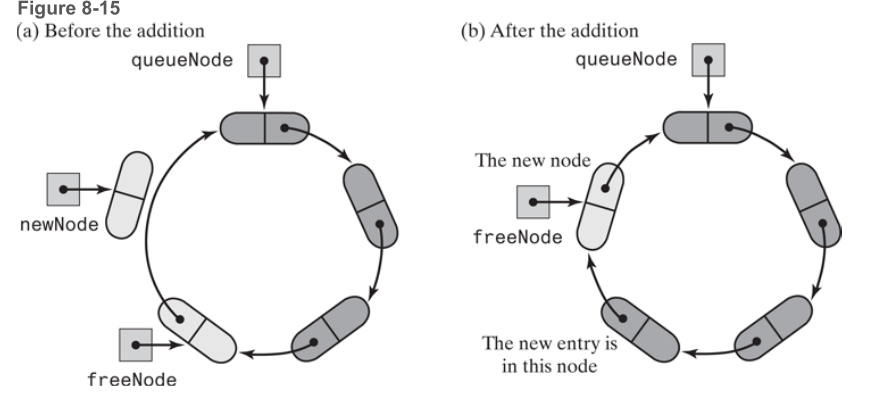
如果有可用的节点,freeNode的data域就是新插入的队列的元素,然后,freeNode指针移动。
整个代码如下
public class TwoPartCircularLinkedQueue<T> implements QueueInterface<T> { private Node queueNode; private Node freeNode; @Override public void enqueue(T newEntry) { freeNode.data = newEntry; if(queueNode == freeNode.next) { Node newNode = new Node(); newNode.next = freeNode.next; freeNode.next=newNode; } freeNode = freeNode.next; } public TwoPartCircularLinkedQueue() { var node = new Node(); node.next = node; freeNode = queueNode = node; // 不存储数据的node。 } @Override public T dequeue() { T front = getFront(); queueNode.data = null; queueNode = queueNode.next; return front; } @Override public T getFront() { if(isEmpty()) { throw new RuntimeException("empty"); } else { return queueNode.data; } } @Override public boolean isEmpty() { return freeNode == queueNode; } @Override public void clear() { } private class Node { T data; Node next; } }
使用队列模拟现实的队列,比如买奶茶,以测算奶茶店的服务能力。如果要统计1小时内的服务能力,可以计算,在一小时内的到达人数,服务人数,等待时间等等。怎么统计呢?1小时,可以分60分钟,每一分钟检测一次,有没有顾客来,如果有就加到队列中,如果没有,就看有没有顾客在服务,如要有,就继续服务,如果没有,服务下一位顾客。怎么知道有没有人来?由于每一个顾客的到达时间是随机的,可以使用一个随机数,如果生成的随机数小于一个阈值,就说明有顾客到,反之,则没有顾客到。 由于每个顾客的服务时间也不一样,可以再使用一个随机数,计算出服务时间。可以看出有两个类,WaitLine和Customer,在WaitLine中有到达人数(numberOfArrived),服务人数(numberServed), 等待时间(totalTimeWaited),在Customer中有到达时间(arriveTime),服务时间(transactionTime)和排队号码(customerNum)。
public class WaitLine { private int numberOfArrivals; private int numberServed; private int totalTimeWaited; private class Customer { int arriveTime; int transactionTime; int customerNum; Customer(int arriveTime, int transactionTime, int customerNum) { this.arriveTime = arriveTime; this.transactionTime = transactionTime; this.customerNum = customerNum; } } }
现在模拟一下队列的情形,顾客到来的时间是随机的,假设有50%的概率会来,那就表示,只要生成的随机数小于50%,就表明顾客到了,加入队列。顾客的服务时间也是不固定的,可以声明一个最大服务时间,然后和随机数相乘,假设最大服务时间是5s。顾客有没有在服务,就是看它的服务时间有没有到0,如果到了,就表示服务完成,到下一位顾客。
// duration: 要统计的服务时间区间,比如60分钟 // arrivalProbability:每秒钟顾管到达的概率, 比如50% // maxTransactionTime:每位顾客的最长服务时间 public void simulate(int duration, double arrivalProbability, int maxTransactionTime) { var line = new LinkedQueue<Customer>(); // 创建一个队列, var transactionTimeLeft = 0; // 每个顾客服务时间的剩余时间,表示一个顾客在不在服务
// clock就是每一秒,用户的到达时间和用户的服务时间都用clock记录 for (int clock = 0; clock < duration; clock++) { // 监测用户到没到,随机数小于规定的概率,表示有顾客到 if (Math.random() < arrivalProbability) { numberOfArrivals++; var transactionTime = (int) (Math.random() * maxTransactionTime + 1);//生成每位顾客的服务时间 var customer = new Customer(clock, transactionTime, numberOfArrivals); // 创建到达的顾客 line.enqueue(customer); } // 某位顾客是否还在服务中 if (transactionTimeLeft > 0) { transactionTimeLeft--; //还在服务中,继续服务,不过服务时间要减1 } else { if(!line.isEmpty()) { var nextCustomer = line.dequeue(); // 顾客离开队列,被服务 transactionTimeLeft = nextCustomer.transactionTime - 1; // 赋值服务时间,下次验证是不是在服务他 var waitingTime = clock - nextCustomer.arriveTime; // 每个用户等待服务的时间 totalTimeWaited = totalTimeWaited + waitingTime; // 整个队列中用户等待的时间 numberServed++; } } } }
测试一下
public static void main(String[] args) { WaitLine customerLine = new WaitLine(); customerLine.simulate(20, 0.5, 5); System.out.println(customerLine.numberServed); }

双端队列
双端队列就是队列的头尾两端都能进行插入和删除,而普通队列只能在头部删除,尾部插入。双端队列的英文名是deque, double-end queue. 
实现方式是双向链表,链表中每一个节点,都能指向它的前一个节点和后一个节点,只操作一个节点,就能进行插入和删除操作,尾节点和头节点都有一个指向null。
使用双向链表实现队列,只要队列中知道头尾两个节点,就可以在队列的两端进行插入和删除操作。双端队列中,使用双向链表,所以可以声明一个内部类DLNode表示链表中的每一个节点,因为节点中有数据,前一个节点的引用和后一个节点的引用,所以它有三个属性data, next 和previous, 又因为双端队列中要知道链表中头尾两个节点的引用,所以还要声明两个属性firstNode, lastNode.

添加一个元素到尾节点,就是创建一个新节点,如果链表为空,直接让firstNode和lastNode指向这个新节点,如果链表不为空,lastNode.next指向新节点,新节点的previous 指向lastNode,最后,lastNode指向新节点
public void addToBack(T newEntry) { var newNode = new DLNode(); newNode.data = newEntry; if(isEmpty()) { firstNode = lastNode = newNode; } else { newNode.previous = lastNode; lastNode.next = newNode; lastNode = newNode; } } public boolean isEmpty() { return firstNode == null; }
添加一个元素到头节点,就是创建一个新元素,它的lnext要指向firstNode, firstNode的previous指向新节点,然后firstNode 指向新节点
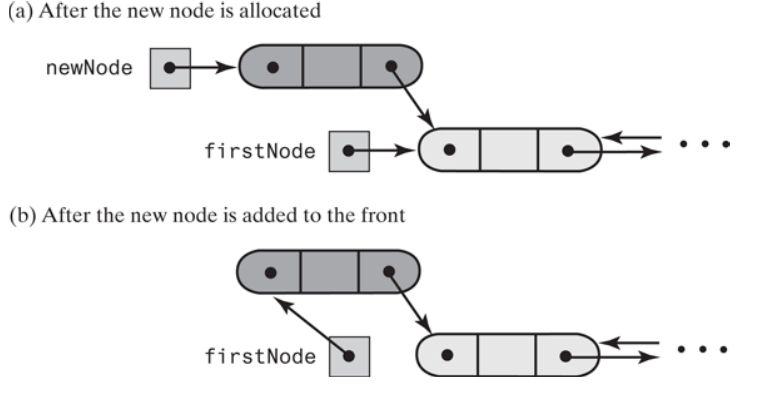
代码如下:
public void addToFront(T newEntry) { var newNode = new DLNode(); newNode.data = newEntry; if(isEmpty()) { firstNode = lastNode = newNode; } else { newNode.next =firstNode; firstNode.previous = newNode; firstNode = newNode; } }
从队列(链表)头部,删除一个元素,如果链表为空,抛出异常,如果链表不为空,firstNode = firstNode.next; 同时iirstNode 的 previous只为null。如要只有一个元素,删除之后,firstNode 为null,那lastNode也为null。
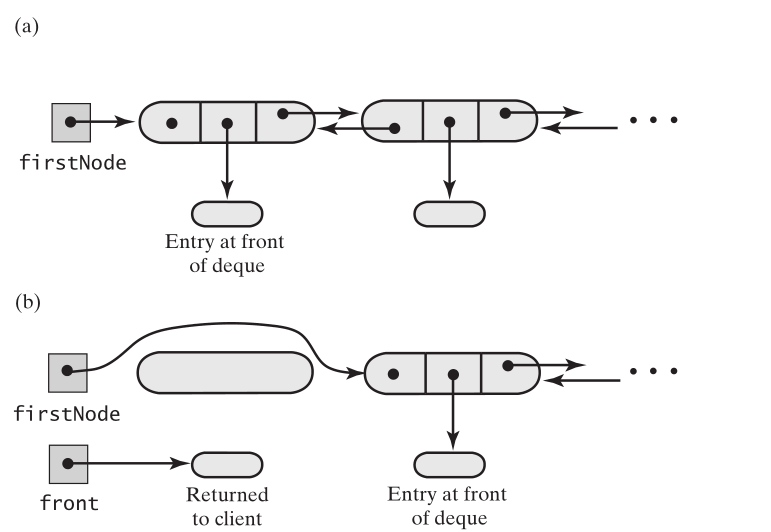
代码如下:
public T removeFront() { if(isEmpty()) { throw new RuntimeException("队列为空"); } DLNode front = firstNode; firstNode = firstNode.next; if (firstNode == null) lastNode = null; else firstNode.previous = null; return front.data; }
从队列(链表)尾部删除一个元素,就是通过lastNode, 找到它的前一个节点,前一个节点的next 为null,就可以。
public T removeBack() { if(isEmpty()) { throw new RuntimeException("队列为空"); } DLNode last = lastNode; lastNode = lastNode.previous; if (lastNode == null) firstNode = null; else lastNode.next = null; return last.data; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号