数据结构—包(Bag)
数据结构中的包,就是对现实中的包的一种抽象。 看一下书包,有哪些功能?首先是装东西,里面的东西可以随便放,没有规律,没有顺序,也可以放多个相同的东西。其次,东西可以拿出来,随便拿出一个,拿出特定的一个,比如书本,把所有的东西都拿出来。附带的功能就是,包有没有满,包是不是空的,里面有多少东西,都是什么,里面是不是有书,放了几本书之类的。数据结构中的包定义如下
public interface BagInterface<T> { /** * 获取包中元素的数量 * @return 元素数量 */ int getCurrentSize(); /** * 包是否为空 * @return 包为空,返回true, 否则返回false */ boolean isEmpty(); /** * 向包里添加一个元素 * @param newEntry 要添加到包里的元素 */ void add(T newEntry); /** * 从包里删除任意一个元素 * @return 删除的元素 */ T remove(); /** * 从包里删除一个给定的元素 * @param anEntry 要删除的元素 * @return 是否删除成功 */ boolean remove(T anEntry); // 删除包中所有元素 public void clear(); /** * 计算一个给定元素的数量 * @param anEntry 给定的元素 * @return 给定元素的数量 */ public int getFrequencyOf(T anEntry); /** * 是否包含给定的元素 * @param anEntry 要查找的元素 * @return 如查包含返回true, 否则返回false */ public boolean contains(T anEntry); /** * 获取包中所有的元素, * @return 包含包中所有元素新数组。 * 注意,如果包为空,返回空数组 */ T[] toArray(); }
数组实现
首先考虑类的属性。肯定有一个数组引用,还要有一个记录个数的属性,因为要判断包是否为空等。
private T[] bag; private int numberOfEntries; private static final int DEFAULT_CAPACITY = 25;
构造函数要创建一个数组对象,赋值给bag属性。数组就要指定长度,提供一个默认长度,也可以让用户提供,无参和有参两个构造函数。假设长度是capacity,bag = new T[capacity]; 不行,不能创建泛型数组。bag = new Object[capacity]; 也不行,Object类不能赋值给T,要强制类型转换。bag = (T[])new Object[capacity]; 又有warning(unchecked cast). 编译器想让你确保数组中的每一个元素从Object类强制转化成泛型T是安全的,由于数组刚刚创建,每一个元素都是null,转化是安全的,@SuppressWarnings("unchecked")告诉编译器忽略这个warning。但@SuppressWarnings("unchecked")只能出现在方法定义或变量声明之前,bag = (T[])new Object[capacity]; 是赋值操作,最终整个构造函数如下
public ArrayBag(int capacity) { // 强制类型转化是安全的,因为新数组中所有元素都是null @SuppressWarnings("unchecked") T[] tempBag = (T[]) new Object[capacity]; // Unchecked cast bag = tempBag; numberOfEntries = 0; } public ArrayBag() { this(DEFAULT_CAPACITY); }
add()添加元素,如果数组满了,需要扩容(增加容量)再添加。如果数组没有满,直接添加。由于添加元素没什么要求,直接把元素放到数组最后一个元素的后面就可以了,同时numberOfEntries+1。刚开始,数组为空,添加一个元素,直接放到0位置,然后numberOfEntries + 1。再添加一个元素,那就要放到1的位置,然后numberOfEntries+1。再添加一个元素,那就要放到2的位置,numberOfEntries+1。

可以发现,添加的位置就是bag[numberOfEntries]的位置,包满了,numberOfEntries等于数组的长度。
public void add(T newEntry) { if(isArrayFull()){} else { bag[numberOfEntries] = newEntry; numberOfEntries++; } }
private boolean isArrayFull() {
return numberOfEntries == bag.length;
}
添加完了,就要查看,这就是ToArray() 方法,创建一个新数组,把bag中的元素复制过去,然后返回新数组
public T[] toArray() { @SuppressWarnings("unchecked") T[] result = (T[])new Object[numberOfEntries]; // Unchecked cast for (int index = 0; index < numberOfEntries; index++){ result[index] = bag[index]; } return result; }
isEmpty(),包是否为空,直接判断numberOfEntries是否等于0就可以了。 getCurrentSize(), 包中元素的个数,直接返回numberofEntries。
public boolean isEmpty() { return numberOfEntries == 0; } public int getCurrentSize() { return numberOfEntries; }
getFrequencyOf(T anEntry),一个元素在包中出现的次数。循环遍历数组就可以了,在遍历过程中,只要有元素和要查找的元素相等,计数器加1。遍历完成后,返回计数器。
public int getFrequencyOf(T anEntry) { int count = 0; for (int i = 0; i < numberOfEntries; i++) { if(anEntry.equals(bag[i])){ count++; } } return count; }
contains()方法,包中是否包含某个元素,还是循环遍历数组,只不过是返回true或false。可以先设一个表示找到找不到的变量found,默认是false,只有当fasle的时候,才遍历数组,在遍历过程中,如果找到了,设为true。如果遍历完,还没有找到,那还是false,直接返回found就可以了。
public boolean contains(T anEntry) { boolean found = false; int index = 0; while (!found && index < numberOfEntries){ if (anEntry.equals(bag[index])){ found = true; } index++; } return found; }
clear()方法,清空bag,简单一点的实现,就是numberOfEntries = 0;,复杂一点就是包不为空的时候,循环调用remove()方法
public void clear() { // numberOfEntries = 0; while (!isEmpty()){ remove(); } }
remove() 删除任意一个元素,由于包中的元素没有顺序要求,可以随便删除,简单起见,就删除最后一个元素,当然,如果包为空的话,是不允许删除的,可以抛出错误。
public T remove() { if (isEmpty()) { throw new RuntimeException("空"); } T result = bag[numberOfEntries - 1]; bag[numberOfEntries - 1] = null; numberOfEntries--; return result; }
remove(anEntry),删除一个给定的元素,首先要先查找这个元素,如果没有就没有办法删除,直接return false。如果有就删除。
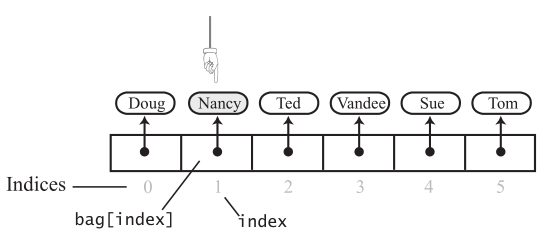
怎么删除呢?index位置设为null,数组就不连续了。可以让要删除的元素和最后一个元素,进行交换,直接删除最后一个元素就好了。
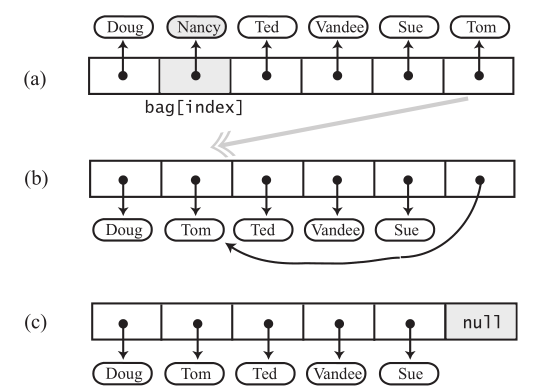
public boolean remove(T anEntry) { if(isEmpty()){ throw new RuntimeException("空"); } boolean found = false; int index = 0; while (!found && index < numberOfEntries){ if (anEntry.equals(bag[index])){ found = true; } else { index++; } } if(found){ bag[index] = bag[numberOfEntries - 1]; bag[numberOfEntries - 1] = null; numberOfEntries--; return true; } else { return false; } }
remove()和remove(T anEntry)代码有了重复,实现上remove() 就是remove(numberOfEntry-1), 这时可以写一个私有方法,删除给定index处的元素,它接受一个index参数,返回要删除的元素
private T removeEntry(int givenIndex){ if(isEmpty()){ throw new RuntimeException("空"); } T result = bag[givenIndex]; bag[givenIndex] = bag[numberOfEntries - 1]; bag[numberOfEntries - 1] = null; numberOfEntries--; return result; }
remove()方法简化成
public T remove() { return removeEntry(numberOfEntries - 1); }
再看remove(T anEntry), 里面查找定位元素的代码和contains()方法,也是重复的,也可以写一个私有方法getIndexOf来返回index。
private int getIndexOf(T anEntry) { int where = -1; boolean found = false; int index = 0; while (!found && (index < numberOfEntries)) { if (anEntry.equals(bag[index])) { found = true; where = index; } index++; } return where; }
contains()方法就变成了
public boolean contains(T anEntry) { return getIndexOf(anEntry) > -1; }
remove(T anEntry)变成了
public boolean remove(T anEntry) { int index = getIndexOf(anEntry); if(index > -1){ removeEntry(index); return true; } else { return false; } }
数组扩容的基本原理:假设有一个数组myArray,先让它赋值一个临时变量oldArray, 再创建一个新数组赋值给myArray, 最后把oldArray中的每一个元素都复制到myArray中。
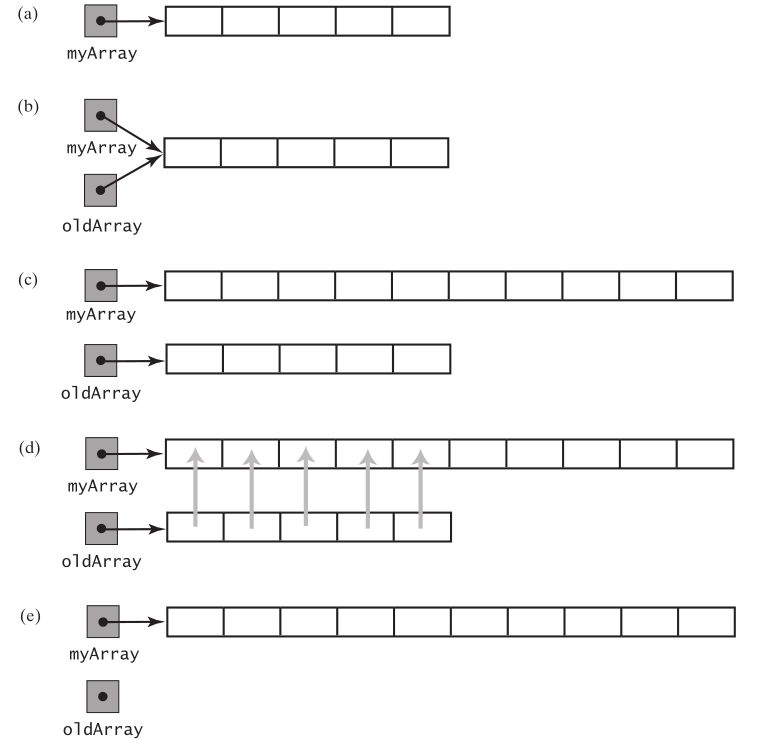
扩容要注意是新生成的数组的大小。如果太小,就要经常扩容,也就是经常把元素从一个数组复制到另一个数组,浪费性能。通常来说,新的数组长度是旧的数组的2倍。比如有50个元素,添加51个元素的时候,扩容到100,剩下的49个元素添加,就不用扩容,抵消掉这个扩容的成本。expanding the array by m elements spreads the copying cost over m additions instead of just one. Doubling the size of an array each time it becomes full is a typical approach. When increasing the size of an array, you copy its entries to a larger array. You should expand the array sufficiently to reduce the impact of the cost of copying. A common practice is to double the size of the array.
private void resize(int newLength) { @SuppressWarnings("unchecked") T[] newArray = (T[]) new Object[newLength]; // Unchecked cast for (int index = 0; index < numberOfEntries; index++) { newArray[index] = bag[index]; } bag = newArray; }
add()方法变成了
public void add(T newEntry) { if (isArrayFull()) { resize(2 * bag.length); } bag[numberOfEntries] = newEntry; numberOfEntries++; }
remove方法需要缩容(减少容量),如果把所有元素都删除了,剩下那么大空间也不合适。缩容和扩容的原理相似,只不过是创建的新数组比原数组要小。缩容的时机是,当删除的元素时,数组元素的个数是数组长度的1/4时,缩小一半的容量。removeEntry() 方法改成
private T removeEntry(int givenIndex){ if(isEmpty()){ throw new RuntimeException("空"); } T result = bag[givenIndex]; bag[givenIndex] = bag[numberOfEntries - 1]; bag[numberOfEntries - 1] = null; numberOfEntries--; if(numberOfEntries > 0 && numberOfEntries == bag.length / 4){ resize(bag.length / 2); } return result; }
链表实现
链表是由节点组成,节点中的数据域可以存放包中的元素
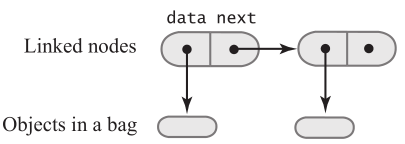
需要创建一个私有内部类Node
private class Node { T data; Node next; Node(T dataPortion) { data = dataPortion; next = null; } }
操作链表需要头指针,它指向链表中的第一个节点,还需要一个变量来记录包中元素的个数。
private Node firstNode; private int numberOfEntries;
add(T newEntry) 方法,既然包中的元素没有顺序,而在链表的头部插入节点,又比较简单,那add(T newEntry) 就定义为从头部插入节点。刚开始,链表为空,插入节点,就是创建新节点,并赋值给头指针

Node newNode = new Node(newEntry); firstNode = newNode;
当链表不为空时,头部插入节点,就是,创建新节点,新节点的next指向链表中的第一个节点(firstNode),再让新节点成为链表中的第一个节点(新节点赋值给firstNode)
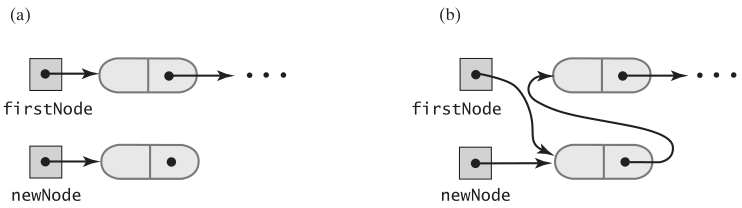
Node newNode = new Node(newEntry); newNode.next = firstNode; firstNode = newNode; // New node is at beginning of chain
实际上,向一个空链表中插入节点,和向一个非空链表头部插入节点是一样的。向空链表中插入节点时,如果加入newNode.next = firstNode,也没有问题,因为此时firstNode为null,而newNode的next本来也是null。所以add()方法的完整实现
public void add(T newEntry) { Node newNode = new Node(newEntry); newNode.next = firstNode; firstNode = newNode; numberOfEntries++; }
toArray()方法,需要遍历链表,把链表中的每一个节点中的数据放到数组中。怎么遍历呢?firstNode指向链表中的第一个节点,第一个节点又包含第二个节点的引用,第二个节点又包含第三个节点的引用,因此需要一个变量来顺序地引用每一节点,到达每一个节点时, .data就可以获取节点中的数据。刚开始的时候,变量引用第一个节点,把firstNode赋值给这个变量,假设变量是currrentNode, 那么currentNode = firstNode. currentNode.data就可以获取到数据。currentNode= currentNode.next, currentNode指向第二个节点,currentNode.data获取数据。currentNode = currentNode.next,第三个节点,一直到最后一个节点currentNode为null。
public T[] toArray() { @SuppressWarnings("unchecked") T[] array = (T[]) new Object[numberOfEntries]; Node current = firstNode; int index = 0; while (current != null){ array[index] = current.data; index++; current = current.next; } return array; }
getFrequencyOf(), 像toArray()一样,遍历链表,只不过获取到数据后,要做的是判断是否相等。
public int getFrequencyOf(T anEntry) { int frequency = 0; Node currentNode = firstNode; while (currentNode != null) { if (anEntry.equals(currentNode.data)) frequency++; currentNode = currentNode.next; } return frequency; }
contains() 还是遍历链表
public boolean contains(T anEntry){ boolean found = false; Node currentNode = firstNode; while (!found && (currentNode != null)) { if (anEntry.equals(currentNode.data)) found = true; else currentNode = currentNode.next; } return found; }
remove(), 因为包中的元素顺序没有要求,所以删除第一个元素就好了,简单
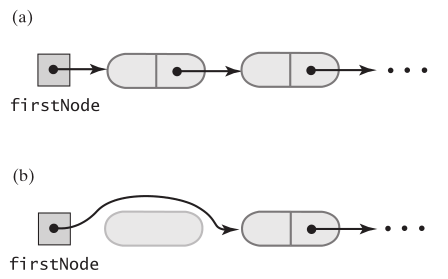
public T remove() { T result = null; if (firstNode != null) { result = firstNode.data; firstNode = firstNode.next; numberOfEntries--; } return result; }
remove(T anEntry), 遍历链表,找到元素,然后和第一个节点进行交换,删除第一个节点
private Node getReferenceTo(T anEntry) { boolean found = false; Node currentNode = firstNode; while (!found && (currentNode != null)) { if (anEntry.equals(currentNode.data)) found = true; else currentNode = currentNode.next; } return currentNode; } public boolean remove(T anEntry) { boolean result = false; Node nodeN = getReferenceTo(anEntry); if (nodeN != null) { nodeN.data = firstNode.data; firstNode = firstNode.next; numberOfEntries--; result = true; } return result; }
clear()方法,直接让firstNode = null就好了
public void clear() { firstNode = null; }
迭代方法,就要实现Iterable<T>接口,实现Iterable<T>接口,就要提供一个iterator方法,这个方法要返回Iterator<T>接口类型的对象,有对象就要创建一个类来这个Iterator<T>接口,它有两个方法,一个是hasNext(),表示,还有迭代对象中还没有元素,next()方法,返回每一次迭代的元素。
import java.util.Iterator; public class LinkedListBag<T> implements BagInterface<T>, Iterable<T> { public Iterator<T> iterator() { return new ListIterator(); } private class ListIterator implements Iterator<T> { private Node current = firstNode; public boolean hasNext() { return current != null; } public T next() { T item = current.data; current = current.next; return item; } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号