
数据结构--栈
栈对数据的存取有着限制,它遵循着先进后出或后进先出的原则。怎么理解呢?想一想收件箱中的邮件。打开收件箱,邮件是按时间顺序从晚到早时进行排列的,第一封邮件时间最晚,最后一封邮件时间最早,邮件来的越早,它越在收件箱的底部,邮件来的越晚,它越在收件箱的顶部。看邮件的时候,先看第一封邮件,看的是来的最晚的邮件。如果不重要就删除了,这就是后进先出,最晚的邮件最先删除。看了好久,终于快看完了,先进后出。此时,又收到一封邮件,它又放到收件箱的顶端,你发现,无论是添加还是删除,都是在收件箱的顶部操作。如果把收件箱看作栈,你会出现栈的一些特征,栈中元素的排列顺序,正好和它们的添加时间相反,添加的越早,越在栈的下面,添加的越晚,越在栈的上面。添加元素相当于把原有元素向下压,删除元素相当于下面的元素向上顶,把元素弹出去。添加或删除,都在栈的一端操作,栈的顶部操作,而不是随意的操作栈中的元素,如果想获取栈底的元素,只能把它上面的元素都弹出来。元素称为入栈或压栈,删除元素称为出栈或弹栈。
栈是一种抽象的概念,要怎么实现它的呢?实际上,只要保证先进后出或后进先出的原则,用什么实现都可以,数组,链表,甚至队列,都没有问题。
数组实现
使用数组,怎么保证先进后出或后进先出呢?在数组的尾部进行添加或删除元素就可以了。添加第一个元素放到数组的0位置,添加第二个元素放到数组的1位置 ,删除的时候,先删除第1个位置的元素,再删第0个位置上的元素。 数组的尾部进行操作,保证了后进先出。数组尾部操作也简单,它不会影响数组内的其它元素。根据描述,也可以知道实现栈的类的属性,一个是数组的引用,一个是追踪元素的索引。

构造函数就是要创建数组,进行初始化栈。创建数组要指明数组的长度,长度具体是多少,可以让使用者指定,也可以设一个默认的长度。
public class ArrayStack<T> { private T[] stack; // 实现栈的底层数组 private int topIndex; // 记录栈中或数组中最后一个元素的位置 private static final int DEFAULT_CAPACITY = 50; // 默认数组的大小 public ArrayStack() { this(DEFAULT_CAPACITY); } public ArrayStack(int initialCapacity) { stack = (T[])new Object[initialCapacity]; topIndex = 0; } }
添加元素(入栈),称为push,就是向数组的尾部添加元素,如下图所示
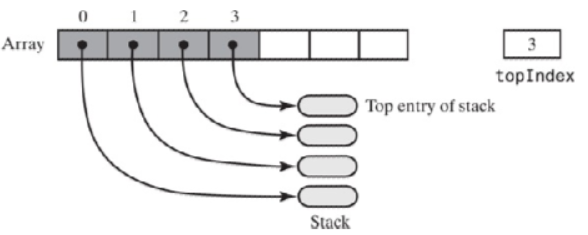
就是数组topIndex 的位置处设为添加的元素,同时topIndex加1。
public void push(String elem) { stack[topIndex] = elem; topIndex++; }
删除元素或出栈,称为pop。就是topInex--,获取到topIndex处的元素,然后把数组这个位置设为null。

public T pop(){ topIndex--; String item = stack[topIndex]; stack[topIndex] = null; return item; }
当然,如果栈为空的话,是不能执行删除操作的,如果执行删除操作,就报错。这时还需要isEmpty()的方法,同时在pop()中调用
public boolean isEmpty() { return topIndex == 0; } public T pop(){ if (isEmpty()){ throw new RuntimeErrorException("栈为空"); } topIndex--; T item = stack[topIndex]; stack[topIndex] = null; return item; }
除了主要的push和pop方法外,栈还有其它几个基本方法。peek() 方法, 看一下栈的顶部元素是什么,它只需要获取元素,而不用移动topIndex。和pop()方法一样,如果栈为空,peek()方法报错
public T peek() { if(isEmpty()){ throw new RuntimeErrorException("栈为空"); } return stack[topIndex - 1]; }
size()方法,栈中有多少个元素,直接返回topIndex 就可以了。
public int size() { return topIndex; }
clear(), 清空栈,简单点,就直接让topIndex = 0; 复杂一点,就是调用pop() 方法。
public void clear() { topIndex = 0; }
数组实现有一个问题,就是是数组的长度是固定的,如果不停地添加元素,数组会满的。这个时候,就要扩容。扩容的实现方式是重新创建一个大数组,把stack数组中的元素,复制到新的数组中,然后让stack指向这个新数组
public void ensureCapcity(){ T[] bigArray = (T[])new Object[stack.length * 2]; for(int i = 0; i < stack.length; i++){ bigArray[i] = stack[i]; } stack = bigArray; }
当不断删除元素的时候,数组就需要缩容。缩容和扩容的原理一样,只不过是生成一个小的数组,这时可以把ensureCapcity()方法接受一个参数,扩容和缩容就可以使用一个方法了,把方法名改成resize()
private void resize(int max) { T[] tempArray = (T[])new Object[max]; for (int i = 0; i < N; i++) tempArray[i] = stack[i]; stack = temp; }
push() 方法,就要选判断数组是不是还有剩余空间,如果没有就扩容,调用resize()方法,扩多大呢?一般是原数组大小的两倍。
public void push(String elem) { if (topIndex == stack.length) resize(2 * stack.length); stack[topIndex] = item; topIndex++; }
缩容,就是在断删除元素的时候,
public T pop(){ if (isEmpty()){ throw new RuntimeErrorException("栈为空"); } topIndex--; T item = stack[topIndex]; stack[topIndex] = null; if (topIndex > 0 && topIndex== stack.length / 4) { resize(stack.length / 2); } return item; }
迭代方法的实现
import java.util.Iterator; public class ArrayStack<T> implements Iterable<T> { @Override public Iterator<T> iterator() { return new ReverseArrayIterator(); } private class ReverseArrayIterator implements Iterator<T> { int i = topIndex; @Override public boolean hasNext() { return i > 0; } @Override public T next() { return stack[--i]; } } }
链表实现
链表需要节点和头指针,栈需要记录元素的个数,所能实现栈的链表类需要三个属性,
public class LinkedListStack<T>{ private class Node { T item; // 栈中元素 Node next; } private Node topNode; private int N; }
入栈和出栈的操作可以放在链表的头部,

从头部插入节点,头指针指向最近插入的节点,从头部删除节点,最近插入的节点补删除了,后进先出。链表的头部插入节点,创建新节点newNode, 它的next指向原来的头指针,再把新节点newNode赋值给头指针
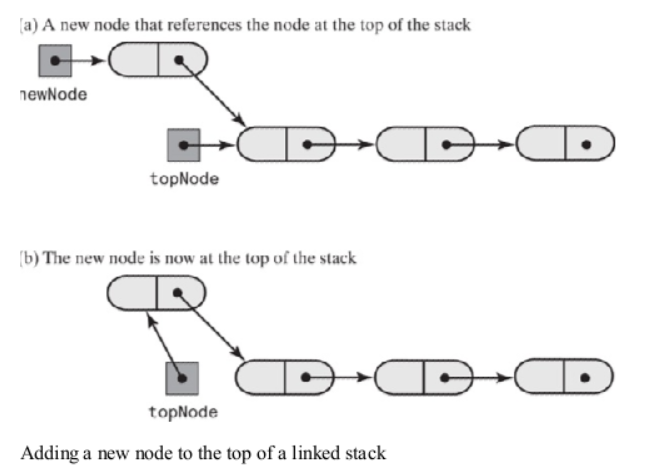
public void push(T item) { Node newNode = new Node(); newNode.item = item; newNode.next = topNode; topNode =newNode; N++; }
出栈,从链表的头部删除节点,直接让topNode = topNode.next, topNode 指向链表的第二个节点,第一个节点也就引用不到了,也就删除了。

public T pop() { if(isEmpty()){ throw new RuntimeException("栈为空"); } T item = topNode.item; first = topNode.next; N--; return item; }
其它几个简单方法
public boolean isEmpty() { return topNode == null; } public int size() { return N; } public void clear() { topNode = null; } public T peek(){ if(isEmpty()){ throw new RuntimeException("栈为空"); } return topNode.item; }
栈的迭代,一个是next()方法,返回栈中的元素,可以声明一个变量temp,先指向第一个元素,每调用一次next方法,就让这个变量,指向下一个节点,temp=temp.next 。一个是hasNext方法,栈中还有没有元素,可以判断,temp是否等于null,如果等于null,就表明到了链表的尾部,没有元素了,反之,则有元素。
import java.util.Iterator; public class LinkedListStack<T> implements Iterable<T>{ @Override public Iterator<T> iterator() { return new StackIterator(); } private class StackIterator implements Iterator<T> { Node temp = topNode; @Override public boolean hasNext() { return temp != null; } @Override public T next() { T item = temp.item; temp = temp.next; return item; } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号