
单链表
链表,和数组一样,也是一种线性的数据结构。但链表在存储数据的时候,却不像数组把所有的数据都存储在一片连续的内存空间中,而是数据分散在内存中,数据和数据之间相互链接。数据和数据怎么才能相互链接?比如,5和10怎么才能进行链接?很显然,仅仅依靠数据本身是无法链接起来的,还需要地址。存储数据的时候,同时存储一个地址,当再存储一个数据的时候,把该数据的地址赋值前一个数据中的地址,只要知道地址,就能找到元素,也就相当于,数据和数据链接起来了,所以链表在存储数据的时候,不仅要存数据本身,还要存地址。也正因为如此,链表存储的是一个对象。对象的一个属性是数据,一个属性是地址。链表是对象与对象之间的链接。但地址怎么获取呢?只要链表存储的是对象,地址就很好获取了。在Java 和JavaScript中,当创建一个对象,并把这个对象赋给一个变量的时候,这个变量保存的是就这个对象的地址。当把这个变量复制给另外一个变量的时候,复制的是对象的地址,也就是说,两个变量同时指向了一个对象。也就是说,链表中的每一个对象中,它的地址属性只要声明成对象类型的变量就可以了。链表是对象与对象的链接,这也引出了另外一个问题,链表是存储在堆内存中的(因为对象都是存储在堆内存中的),怎么才能操作它呢?只能把链表中的第一个对象赋值给一个变量,操作链表的时候,通过这个变量去找到链表中的第一个对象,进而找到整个链表进行操作。也就是说,链表中始终都要存在一个指向链表第一个对象的变量,用来找到链表,进而操作链表。链表中的每一个对象也称为节点, 指向链表第一个对象的变量称为链表头。一个简单的链表如下:

链表的分类有三种,单向链表(单链表),双向链表,循环链表。
单向链表:链接方向是单向的,一个节点只能链接它的后一个节点,而不能链接它的前一个节点,链表的最后一个节点链向null。对链表的访问只能从头部开始,依次向后顺序访问,像上图一样。
双向链表,链接方向是双向的,就是它的每一个节点中都有两个地址(假设是prev和next),prev指向它的前一个节点, next指向后一个节点,第一个节点的prev提向null,最后一个节点next指向null

循环链表就是,链表的最后一个元素不是指向null,而是指向第一个结点。不管是单向链表还是双向链表,它都能变成循环列表

链表的实现方式也有两种方式,一种是不带头结点,链表头指向的第一个元素就是真实的数据节点
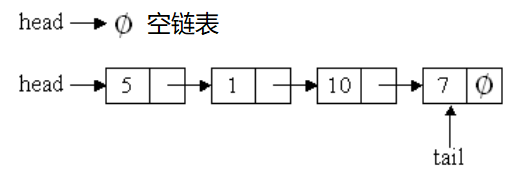
一种是带一个头节点,头节点并不保存任何有效数据,链表头指向头节点,头节点指向链表中真正有意义的第一个节点。
先看单向链表,由于链表中的每一个节点都是对象,所以要声明一个类来表示这个对象,由于这个类仅在单向链表中使用,可以声明为私有内部类,类的属性分为数据和地址,为了简单起见,数据使用整数,地址就是节点类的变量。为了能够操作链表,还需要一个变量,让它指向链表中的第一个节点,所以一个单向链表要有两个属性,一个是内部节点类,一个是指向链表的第一个元素。有时还要计算链表中节点的个数,再加上一个属性size
public class SingleLinkedList { private class Node { // 链表的节点类型 int data; // 数据 Node next; // 地址 Node(int data){ this.data = data; } } private Node head; // 指向链表的第一个元素,用来找到链表,操作链表 private int size; // 记录节点的个数 }
可以想到,这样的实现方式是不带头节点的,因为head默认初始化为null,它并没有指向一个节点。
插入节点,可以从链表的头部插入,可以从链表的尾部插入,还可以从链表的中间插入,还可以在某个节点后面插入,相应的,你可以单独提供方法,也可以提供通用的方法。头部插入最为简单,就是创建新的节点,让新的节点next指向head(把head赋值给新节点的next属性),然后再让head指向新的接点(把新节点赋值给head),最后不要忘记size++;
public void insertFirst(int data){ // 创建新的节点 Node newNode = new Node(data);// 新的节点的next指向head newNode.next = head; // 让head指向新的节点 head = newNode;
size++; }
从尾部插入节点,就有点麻烦了,因为要先找到尾节点,然后再让尾节点的next 指向新的节点。怎样才能找到尾节点?尾节点的next 是null,只要找到一个节点的next 属性是null, 它就是尾节点。如果head.next 是null,则head是尾节点,如果head.next.next 是null,那head.next 就是尾节点。找一个临时变量temp, 把head赋值给它, 那么temp 也就是指向了第一个节点,判断temp.next 是不是null, 如果是,它就是尾节点,如果不是,那就把temp.next 再赋值给temp, 这时temp就指向第二个节点。如果temp.next 还不是null, 那就再把temp.next 赋值给temp, 这时temp指向第三个节点。 可以发现,就是不停地把temp.next 赋值给temp,让temp 指向下一个节点,直到temp.next 是null,那temp 就是最后一个节点,这时把新的节点赋值给temp.next。赋值成功后,不要忘记size++。尾部插入节点要注意的是,先判断head是否为null,如果head是null,head赋值给temp,temp.next就会报错。head为null,链表为空,也没有必要循环链表。
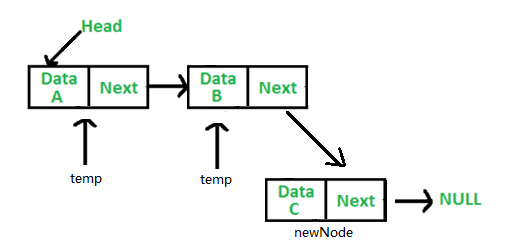
public void insertLast(int data) { // 新node的next默认是null Node newNode = new Node(data); if (head == null){ head = newNode; } else{ Node temp = head; // 只有node的next的节点是null, 才是最后一个节点。 while (temp.next != null) { temp = temp.next; } // temp是最后一个节点 temp.next = newNode; }
size++; }
在链表的中间位置或任意位置插入节点,那就要先定位到这个位置,找到这个位置的前一个节点,因为单链表只能链接到下一个节点,要在某个位置插入节点,肯定要让这个位置之前的那个节点的next指向新的节点,同时让新的节点的next指向原来前一个节点指向的后一个节点。定位位置,找到前一个节点,肯定是要循环遍历了,遍历到指定的位置。插入到第n个位置,遍历n-1次,得到的节点,就是前一个节点。

理论上是这样,但实现上还要复杂,因为有好多情况要判断,链表是否为空,如果为空,那就只能插入第一个节点。插入的位置是否符合要求,这里要确定一下,链表的第 一个节点是位置0还是位置1,如果按照数组的规则,链表中的第一个节点就是位置0。那么要插入的位置范围就是[0, size]. 如果链表中只有一个节点,是可以插入到位置1的,位置0的节点next指向这个节点就可以了。
public void insert(int position, int data) { // 创建新节点 Node newNode = new Node(data); // 判断链表是否为空 if(head == null) { // 如果为空,那只允许插入到第一个节点,也就是位置0处,否则报错 if (position != 0){ throw new RuntimeException("链表为空"); } else { head = newNode; } } else { // 至少有一个节点 // 判断位置是否符合要求 if(position < 0 || position > size) { throw new RuntimeException("超出范围"); } else { // 插入头节点 if(position == 0) { insertFirst(data); } else if (position == size) { // 插入尾节点 insertLast(data); } else { Node prevNode = head; // 注意是position -1,如果插入到1位置,那head就是前一个节点,无需循环,position-1 -> 0, 不循环 for (int i = 0; i < position -1; i++) { prevNode = prevNode.next; } // prevNode就是前一个节点。 // nextNode是后一 个节点 Node nextNode = prevNode.next; // 新节点的链接:前一个节点的next指向新节点,新节点的next指向后一个节点 prevNode.next = newNode; newNode.next = nextNode; } } }
size++; }
插入功能完成后,就要验证实现的对不对,简单的办法就是把链表中的数据打印出来,遍历整个链表。找一个临时变量curNode, 把head赋值给它, 那么curNode也就指向了第一个节点,此时判断curNode是不是null, 如果是,链表为空,什么都不用做了。如果不是,把curNode的data打印出来,再把curNode.next 赋值给curNode, 这时curNode就指向第二个节点。再判断curNode是不是null, 如果不是,继续打印它的data,把curNode.next 赋值给curNode, 这时curNode指向第三个节点。 可以发现,就是不停地判断curNode是否为null, 如果不是,那就打印data,并curNode.next 赋值给curNode,让curNode指向下一个节点,直到curNode 为null。这里要注意它和插入尾节点遍历的不同,插入尾节点,是判断.next是否为null,这里只判断节点是否为null

public void display() { Node curNode = head; while (curNode != null) { System.out.print(curNode.data); curNode = curNode.next; } }
删除节点,删除节点也有很多情况,删除头节点,删除某个位置节点,删除某个指定的节点。删除头节点比较简单,直接让head指向head.next 就可以了,删除方法通常会返回要删除的节点

public Node deleteFirst() { if (head == null) { throw new RuntimeException("链表为空"); } Node firstDeleted = head; head = head.next; return firstDeleted; }
删除某个指定的节点,分为三种情况,这个节点正好是头节点,这个节点在中间或尾节点,这个节点没有找到。当删除某个节点时,不仅要找到这个节点,还要找到这个节点的上一个节点,还是因为链表是单向的,删除某个节点,就要让某个节点的上一个节点的next指向这个节点的next指向的下一个节点,那遍历查找某个节点时,还要记录前一个节点。
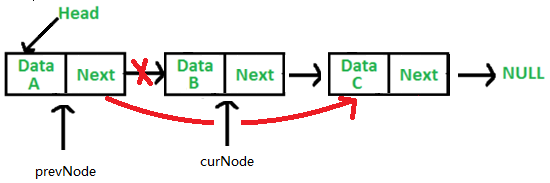
public Node deleteKey(int key){ if (head == null) { throw new RuntimeException("链表为空"); } Node curNode = head; Node prevNode = null; // 删除的某个key正好位于头节点中 if(curNode.data == key){ head = curNode.next; return curNode; } // 删除的某个key位于中间节点或尾节点 while (curNode != null && curNode.data != key) { prevNode = curNode; //记录前一个节点 curNode = curNode.next; } // 如果找到了 if(curNode != null){ prevNode.next = curNode.next; return curNode; } // 如果没有找 curNode == null System.out.println("没有找到"); return null; }
删除某个位置的节点,要先找到这个节点,同时记录上一个节点。怎么才能找到这个节点呢?遍历到该位置。
public Node deleteByPostion(int postion) { if (head == null) { throw new RuntimeException("链表为空"); } if(postion < 0 || postion >= size) { throw new RuntimeException("位置不对"); } if(postion == 0){ Node first = head; head = head.next; return first; } Node curNode = head; Node prevNode = null; for (int i = 0; i < postion; i++) { prevNode = curNode; curNode = curNode.next; } prevNode.next = curNode.next; return; curNode; }
查找
public int find(int data){ Node curNode = head; int index = 0; boolean isFind = false; while (curNode != null){ if(curNode.data == data){ isFind = true; break; } else { index++; curNode = curNode.next; } } if(isFind) { return index; } else { return -1; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号