
大数据学习日志——解析sparkstreaming滑动窗口源码
写这篇随笔的原因在于本人在网上看了很多相关博客很多文章内容给出的用法都一致是如下形式:
1 reduceByKeyAndWindow(_ + _,_ - _,Minutes(2),Seconds(10),2)
但是详细描述函数的各个参数怎么使用,为什么要怎么写,可以怎么修改参数的文章基本没看到。于是便想着自己动手丰衣足食,从源码粗略看起来,这个滑动窗口到底怎么用!spark2.4版本
本内容主要说明滑动窗口对于丢出去的数据批次和新来的数据批次以及共同的数据批次源码粗看和讲解
1 如何使用reduceByKeyAndWindow
首先看看官网提供的图片:
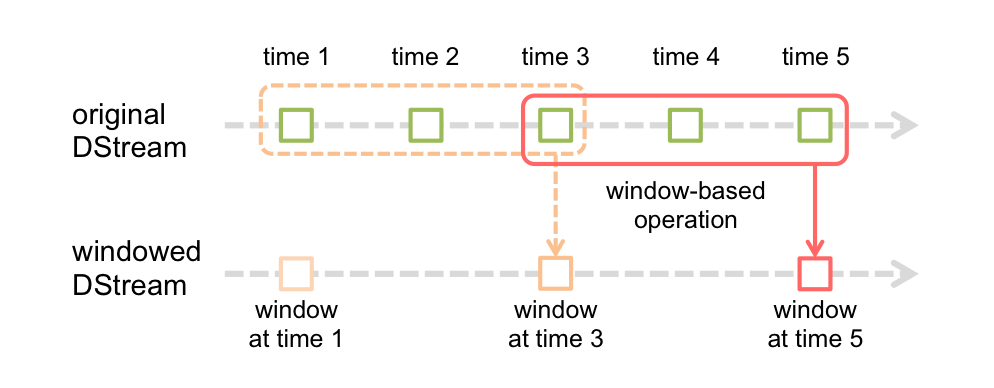
众所周知sparkSteaming是隔一段时间将一部分数据聚合成一个批次然后处理,如上图中一个绿框就是一个批次的数据集。
再看看源码内容:
1 /** 2 * Return a new DStream by applying incremental `reduceByKey` over a sliding window. 3 * The reduced value of over a new window is calculated using the old window's reduced value : 4 * 1. reduce the new values that entered the window (e.g., adding new counts) 5 * 2. "inverse reduce" the old values that left the window (e.g., subtracting old counts) 6 * This is more efficient than reduceByKeyAndWindow without "inverse reduce" function. 7 * However, it is applicable to only "invertible reduce functions". 8 * @param reduceFunc associative and commutative reduce function 9 * @param invReduceFunc inverse reduce function 10 * @param windowDuration width of the window; must be a multiple of this DStream's 11 * batching interval 12 * @param slideDuration sliding interval of the window (i.e., the interval after which 13 * the new DStream will generate RDDs); must be a multiple of this 14 * DStream's batching interval 15 * @param partitioner partitioner for controlling the partitioning of each RDD in the new 16 * DStream. 17 * @param filterFunc Optional function to filter expired key-value pairs; 18 * only pairs that satisfy the function are retained 19 */ 20 def reduceByKeyAndWindow( 21 reduceFunc: (V, V) => V, 22 invReduceFunc: (V, V) => V, 23 windowDuration: Duration, 24 slideDuration: Duration, 25 partitioner: Partitioner, 26 filterFunc: ((K, V)) => Boolean 27 ): DStream[(K, V)] = ssc.withScope { 28 29 val cleanedReduceFunc = ssc.sc.clean(reduceFunc) 30 val cleanedInvReduceFunc = ssc.sc.clean(invReduceFunc) 31 val cleanedFilterFunc = if (filterFunc != null) Some(ssc.sc.clean(filterFunc)) else None 32 new ReducedWindowedDStream[K, V]( 33 self, cleanedReduceFunc, cleanedInvReduceFunc, cleanedFilterFunc, 34 windowDuration, slideDuration, partitioner 35 ) 36 }
一共需要6个参数,实际运算中有相关重载方法,一些参数会有默认值,这里是最底层源函数。第5、6个参数分别是分区和过滤参数,这里不讨论,根据实际运用
1.1窗口大小和滑动长度
windowDuration为窗口大小参数,slideDuration为滑动长度参数。
一下以time表示每个批次时间长度,即每过一个time事件传来一个批次的数据,就以上图为例详细描述窗口大小和滑动长度的内容:
A.窗口大小为批次3time,上图可见window at time 3 ,wimdow at time 5都包含三个批次的数据集即窗口每次能对3time事件的数据进行运算
B.滑动事件长度为2time,上图可见window at time 1、window at time 3,window at time 5都相隔2time,并且window at time 3 和window at time 5 所共有的批次只有一块即1time时间内的数据,已知每个窗口还有三个3time的数据,于是相隔批次便把前2time的数据集去掉再加上2time数据。
根据上图所示,可以想象滑动窗口的大小和滑动长度都是以批次为最小单位,即设置窗口大小和滑动长度时间时候必须是设置的批次事件的整数倍,否则会报错;若是在初始时,进入窗口的批次并没有填满窗口,则窗口并不会对已经进入的批次进行计算。本篇不对这里进行详细说明。
1.2reduce和invReduce
1.1内容说明了窗口处理批次的时间间隔和每次处理的数据批次大小,这里说明窗口是怎么对进出批次进行处理,窗口中的数据怎么运算。
考虑以下事情,若是窗口每次滑动一次,就对窗口中的所有数据全都做一次运算,这样的实现似乎并不难,但是要是本次窗口的数据和上次窗口的数据有重复,要是每次都全部进行计算,是会对已经计算过的数据再进行一次计算,所以每次窗口都全部计算所有数据的方式时可以优化的,要是存在重复数据的情况下,只需要保留上次计算的重复数据计算值,然后减去上次运算多余的计算值,再加上本次运算新加入的数据计算值,于是reduceByKeyAndWindow便提供了如此的实现方式:
reduceFunc参数是窗口数据的处理函数,这是最基本的,通过这个函数获得想要的每个批次运算值。
invReduceFunc参数时窗口数据减去上一次运算多余的数据值函数。
2 滑动窗口数据处理过程
现在知道了reduceFunc是用来对窗口数据进行运算的,那么这个运算是怎么对相邻窗口运算优化的、invReduceFunc是怎么减去上次运算多余数据的,一下便从源码探究。
从reduceByKeyAndWindow函数中可见,此函数最终调用是new ReducedWindowedDStream这个class,一起进入这个函数看看:
1 class ReducedWindowedDStream[K: ClassTag, V: ClassTag]( 2 parent: DStream[(K, V)], 3 reduceFunc: (V, V) => V, 4 invReduceFunc: (V, V) => V, 5 filterFunc: Option[((K, V)) => Boolean], 6 _windowDuration: Duration, 7 _slideDuration: Duration, 8 partitioner: Partitioner 9 ) extends DStream[(K, V)](parent.ssc)
着重关注三个参数parent是这个窗口的DStream,reudceFunc、invReduceFunc同上,不在描述,
然后到compute函数中看看,为避免篇幅过长,只看部分关键代码。
源码中给出了一张图,描述了内部运算中分出的运算对象:
// _____________________________
// | previous window _________|___________________
// |___________________| current window | --------------> Time
// |_____________________________|
//
// |________ _________| |________ _________|
// | |
// V V
// old RDDs new RDDs
//
从代码中看看那几个关键对象,从代码中摘出
val currentTime = validTime val currentWindow = new Interval(currentTime - windowDuration + parent.slideDuration, currentTime) val previousWindow = currentWindow - slideDuration // Get the RDDs of the reduced values in "old time steps" val oldRDDs = reducedStream.slice(previousWindow.beginTime, currentWindow.beginTime - parent.slideDuration) logDebug("# old RDDs = " + oldRDDs.size) // Get the RDDs of the reduced values in "new time steps" val newRDDs = reducedStream.slice(previousWindow.endTime + parent.slideDuration, currentWindow.endTime) logDebug("# new RDDs = " + newRDDs.size) // Get the RDD of the reduced value of the previous window val previousWindowRDD = getOrCompute(previousWindow.endTime).getOrElse(ssc.sc.makeRDD(Seq[(K, V)]())) // Make the list of RDDs that needs to cogrouped together for reducing their reduced values val allRDDs = new ArrayBuffer[RDD[(K, V)]]() += previousWindowRDD ++= oldRDDs ++= newRDDs // Cogroup the reduced RDDs and merge the reduced values val cogroupedRDD = new CoGroupedRDD[K](allRDDs.toSeq.asInstanceOf[Seq[RDD[(K, _)]]], partitioner)
这里说明一下,只需要看参数名和上图的对应关系即可,本身计算变量的过程和上图不怎么对应得上,无论currentTime是哪个时间的值,最终的参数currentWIndow并不是上图表示的currentWindow而是一个间隔为两次运算重复的时间长度,然后通过这个变量运算的oldRDDs、newRDDs反而是对的。个人猜测可能时开发人员初期确实时想做成currentTime这样的理解,但是实际运算并不理想比如currentTime值并不是那么的在标准时间上还是其他原因,为了更通用,于是改了时间逻辑,但是变量名没变。如有错误,欢迎指出一起学习!
现在重点看cogroupedRDD,这是把allRDDs转为cogroupedRDD,之后的计算过程都是通过cogroupedRDD操作。然后还有两个参数也需要注意:
1 val numOldValues = oldRDDs.size
2 val numNewValues = newRDDs.size
先看看这个数据时怎么处理的:
val mergedValuesRDD = cogroupedRDD.asInstanceOf[RDD[(K, Array[Iterable[V]])]]
.mapValues(mergeValues)
即把cogroupedRDD调用mergeValues运算,mapValues相当于数据整理后分区map运算,这里不深入
然后是关键的运算部分,在这一部分不同版本的spark源码会大有不同:
1 val mergeValues = (arrayOfValues: Array[Iterable[V]]) => { 2 if (arrayOfValues.length != 1 + numOldValues + numNewValues) { 3 throw new Exception("Unexpected number of sequences of reduced values") 4 } 5 // Getting reduced values "old time steps" that will be removed from current window 6 val oldValues = (1 to numOldValues).map(i => arrayOfValues(i)).filter(!_.isEmpty).map(_.head) 7 // Getting reduced values "new time steps" 8 val newValues = 9 (1 to numNewValues).map(i => arrayOfValues(numOldValues + i)).filter(!_.isEmpty).map(_.head) 10 11 if (arrayOfValues(0).isEmpty) { 12 // If previous window's reduce value does not exist, then at least new values should exist 13 if (newValues.isEmpty) { 14 throw new Exception("Neither previous window has value for key, nor new values found. " + 15 "Are you sure your key class hashes consistently?") 16 } 17 // Reduce the new values 18 newValues.reduce(reduceF) // return 19 } else { 20 // Get the previous window's reduced value 21 var tempValue = arrayOfValues(0).head 22 // If old values exists, then inverse reduce then from previous value 23 if (!oldValues.isEmpty) { 24 tempValue = invReduceF(tempValue, oldValues.reduce(reduceF)) 25 } 26 // If new values exists, then reduce them with previous value 27 if (!newValues.isEmpty) { 28 tempValue = reduceF(tempValue, newValues.reduce(reduceF)) 29 } 30 tempValue // return 31 } 32 }
oldValues把oldRDDs的数据清理一遍拿出来,newValues同理。
这里关注源码中早就定义的两个变量:
1 val reduceF = reduceFunc
2 val invReduceF = invReduceFunc
reduceF即要对窗口数据处理的函数,invReduceF对上一次窗口数据多余部分的处理函数
arrayOfValues(0)根据allRDDs知道这个部分是previousWindowRDD
arrayOfValues.isEmpty若为真,即没有上一次滑动窗口数据即对新数据进行reduce(reduceF)运算即可完成,reduce函数就是调用参数对本身数据集元素处理的函数,这里不详细说明,源码可见相关内容。
arrayOfValues.isEmpty若为假,即需要处理上次窗口多余部分数据,将之取出为tempValue
当oldRDDs数据存在则通过invReduceF函数处理上次窗口函数和oldRDDs的reduceF运算后的数据赋值给tempValue
当newRDDs数据存在则通过reduceF函数处理tempValue和newRDDs自身reduceF运算后的值。
这里便把源码计算过程看完了。
3 总结
A.窗口大小和滑动长度都必须是批次时间的整数倍
B.reduceFunc函数必须满足结合律,单独数据之间的运算,多个单独数据的运算缓存值和单个数据间的运算以及多个多个单独数据的运算缓存值之间的运算,无论怎么组合都保持一致性
C.invReduceFunc函数必须是reduceFunc逆元运算过程
大白话讲reduceFunc、invReduceFunc两个函数,reduceFunc要是加法、乘法运算,那么invReduceFunc就得是减法,除法运算;若reduceFunc要是求平均值运算,若只给出一个平均值数值,就会出问题,若要实现必须给出数据数量,为避免平均值省略数位误差的情况最好再给出总数据值大小,甚至可以在外部代码中计算平均值,reduceFunc函数主要计算总数值大小以及数据数量。
posted on 2019-04-20 12:39 SaltFishYe 阅读(990) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号