
大数据学习日志——mapreduce过程以及java代码通过mapreduce实现wordcount
首先看mapreduce流程:
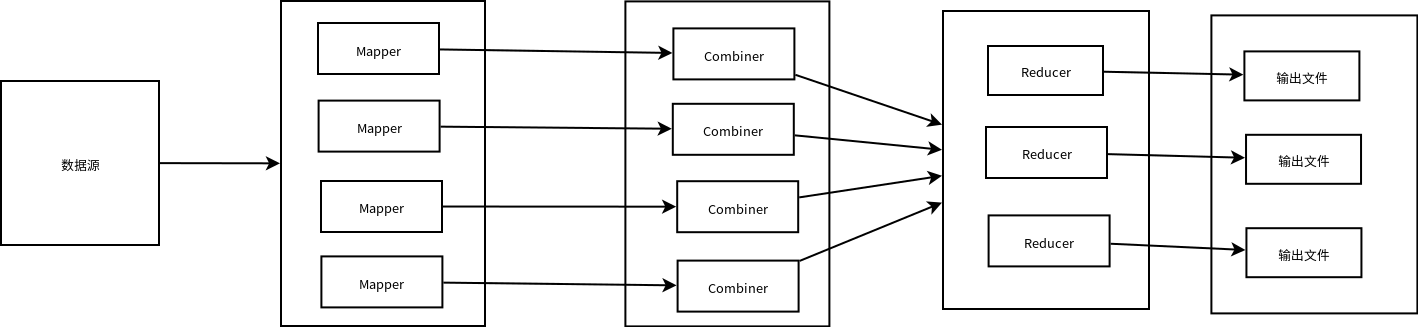
除去输入和输出之后,数据计算只有三个步骤,map,combine,reduce,其中只有map和reduce过程是必要过程,combine若不设置可以略过这一计算过程
首先map过程从数据源读取数据,根据设置的mapper数多个核心同时读取数据,然后在combine过程对每个mapper进行聚合处理操作,map和combine过程输出的数据,将会进行一次重分区shuffle过程,将数据全聚合后根据规则再进行分区放入Reducer中进行计算,默认是根据默认设置的分区数然后计算数据key的哈希值进行分区(数据都是key-value形式),此时可能会存在数据倾斜操作,即当中一些reducer需要处理的数据量极大,而一些处理的数据极小,这些就需要优化过程,这里暂时不谈。最后在输出时,每个reducer对应一个输入源
整个mapreduce便是上述流程,编码过程就容易理解了:
源数据输入mapper,输出到combine(不必要),再从combiner输出到reducer,最后reducer输出
可见mapper的输出类型时combiner的输入类型,mapper和combiner的输出类型时reducer得到输入类型,并且数据都是key-value形式传输
然后mapper类和reducer类,的参数都是如下参数格式<输入key,输入value,输出value,输出key>,注意combiner也是继承自reducer类
注意,初始化输入给mapper的类,key才是从源数据读取到的数据,value时数据偏移量(若是文本文字,即是与第一个位置偏差值)信息
最后编写时候,需要实现tool类重写run方法,并且设置hadoop的参数,可以继承configured类自动加载配置文件中的hadoop配置(此时一定要将配置文件放到工程配置文件目录中)。
run方法中只需要记录一下步骤即可,创建Job类,设置需要运行的class,并且设置好configuration类,设置输入类型和路劲,设置mapper输出类型,设置combiner输出类型,设置reducer输出类型,设置输出类型和路径。
注意:会有人奇怪我什么不设置mapper、combiner、reducer输入类型,上述文字已说过,因为流程的上一步的输出类型即是下一步的输入类型,所以路劲的输出类型即是mapper的输入类型,combiner、reducer同样如此。
以下是一个mapreduce实现wordcount的案例,最后打成jar包,扔到hadoop执行即可。
1 package mapreduce;
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.fs.Path;
5 import org.apache.hadoop.io.IntWritable;
6 import org.apache.hadoop.io.LongWritable;
7 import org.apache.hadoop.io.Text;
8 import org.apache.hadoop.mapreduce.Job;
9 import org.apache.hadoop.mapreduce.Mapper;
10 import org.apache.hadoop.mapreduce.Reducer;
11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
13
14 import java.io.IOException;
15 import java.util.Iterator;
16 import java.util.StringTokenizer;
17
18 public class MyMapReduce {
19 //1自己的map类
20 //继承mapper类,<输入key,输入value,输出value,输出key>
21 public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
22 //每个key设置输出value为1
23 IntWritable i = new IntWritable(1);
24 Text keyStr = new Text();
25
26 @Override
27 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
28 //TextInputFormat是Hadoop默认的数据输入格式,但是它只能一行一行的读记录
29
30 StringTokenizer itr = new StringTokenizer(value.toString());
31 while (itr.hasMoreTokens()) {
32 keyStr.set(itr.nextToken());
33 context.write(keyStr, i);
34 }
35
36 }
37 }
38
39 //2自己的reducer类
40 //继承reducer类,<输入key,输入value,输出value,输出key>
41 //reducer类的输入,就是mapper的输出
42 //mapper类map方法的数据输入到Reduce类group方法中,对key的value进行分组得到values,再放入reduce方法中
43 public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
44 IntWritable countWritable = new IntWritable();
45
46 @Override
47 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
48 String keyStr = key.toString();
49 //在map中每个key对应的value为1,
50 //那么reduce每个key对应的集合便是重复key的个数的长度,并且每个值为1
51 //即集合元素值相加即为key的数量
52 int count = 0;
53 Iterator<IntWritable> it = values.iterator();
54 while (it.hasNext()) {
55 count += it.next().get();
56 }
57 countWritable.set(count);
58 System.out.println(keyStr + "---" + count);
59 context.write(key, countWritable);
60 }
61 }
62
63 //3运行类
64 public int run(String[] args) throws Exception {
65 //hadoop配置上下文
66 Configuration conf = new Configuration();
67 //这里要是没有把配置文件放入resources中,需要手动添加配置文件,或者添加配置参数
68 // conf.addResource("core-site.xml");
69 // conf.addResource("hdfs-site.xml");
70 //通过上下文构建job实例,并传入任务名称
71 Job job = Job.getInstance(conf, this.getClass().getSimpleName());
72 //设置reduce数量
73 job.setNumReduceTasks(3);
74 //必须添加,否则本地运行没问他,服务器报错
75 job.setJarByClass(MyMapReduce.class);
76 //设置任务读取数据
77 //调用时传入参数,第一个参数为路径输入参数
78 Path inputPath = new Path(args[0]);
79 FileInputFormat.addInputPath(job, inputPath);
80
81 //调用时传入参数,第二个参数为路径输出参数
82 Path outputPath = new Path(args[1]);
83 FileOutputFormat.setOutputPath(job, outputPath);
84
85 //设置mapper类参数
86 job.setMapperClass(MyMapper.class);
87 job.setMapOutputKeyClass(Text.class);
88 job.setMapOutputValueClass(IntWritable.class);
89
90 //设置reducer类参数
91 job.setReducerClass(MyReducer.class);
92 job.setOutputKeyClass(Text.