决策树算法原理
一、本文总述
决策树是机器学习领域最基础且应用最广泛的算法模型,本文将详细介绍决策树模型的原理,并通过一个案例,着重从特征选择、剪枝等方面讲述决策树模型的构建,讨论并研究决策树模型评估准则。
二、决策树的概念
决策树是附加概率结果的一个树状的决策图,是直观运用统计概率分析的图法。机器学习中决策树是一个预测模型,它表示对象属性和对象值之间的一种映射,树中每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。
三、决策树案例
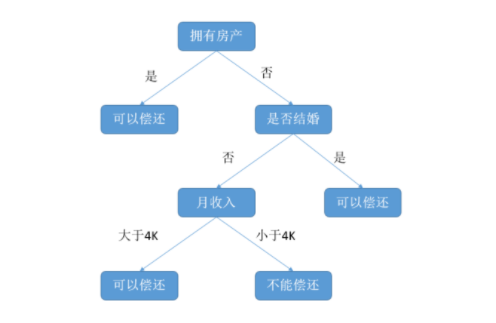
图1 .决策树案例图
图1是一棵简单的决策树,用于预测贷款用户是否具有偿贷能力。贷款客户主要具有三个属性:是否拥有房产、是否结婚、平均月收入。整棵树分为内部节点和叶子节点,每一个内部节点都用作用户属性条件判断,每一个叶子节点都代表用户是否具有偿还能力。例如:用户甲没有房产,没有结婚,月收入 5K。通过决策树的根节点判断,用户符合右边分支(拥有房产为“否”);再判断是否结婚,符合左边分支(是否结婚为“否”);最后判断月收入,符合左边分支(月收入大于4K),该用户落在“可以偿还”的叶子节点上。所以预测用户具有偿还能力。
四、决策树的构建方法
决策树的构建主要分为两步:先通过特征选择确定树节点并生成决策树,再通过剪枝防止过拟合,确定最终的树结构。
决策树的目标是将数据集按照对应的类标签进行分类,理想的情况是通过层层的特征判断可以给数据集贴上不同的标签,完成分类。选择一个合适的特征作为判断节点,可以加速分类,减少决策树的深度。也就是说特征选择的目标是使特征选择后的数据集具有较高的纯度,如何衡量一个数据集的纯度,这里就需要引入数据纯度函数。下面介绍两种数据纯度函数。
4.1 信息熵
信息熵表示的是不确定度。数据均匀分布时,不确定度最大,信息熵最大。当选择某个特征对数据集进行分类时,分类后的数据集信息熵会比分类前的小,其差值表示为信息增益。信息增益可以衡量某个特征对分类结果的影响大小。
假设在样本数据集 D 中,混有 c 种类别的数据。构建决策树时,根据给定的样本数据集选择某个特征值作为树的节点。在数据集中,可以计算出该数据中的信息熵:
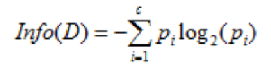
图2 特征作用前数据集的信息熵计算公式
其中 D 表示训练数据集,c 表示数据类别数,Pi 表示类别 i 样本数量占所有样本的比例。
对应数据集 D,选择特征 A 作为决策树判断节点时,在特征 A 作用后的信息熵的为 Info(D),计算如下:
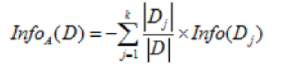
图3 特征作用后数据集的信息熵计算公式
其中 k 表示样本 D 被分为 k 个部分。
信息增益表示数据集 D 在特征 A 的作用后,其信息熵减少的值。公式如下:

图4 信息增益计算公式
对于决策树节点最合适的特征选择,就是 Gain(A) 值最大的特征,即使得信息增益最大的特征
4.2 基尼指数
基尼指数是另一种数据纯度度量方法,原是国际上用来计算社会贫富差距的一个指数,基尼指数越高,表示数据越不纯,其公式为:
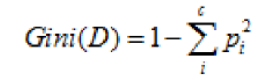
图5 数据集的基尼指数计算公式
其中 c 表示数据集中类别的数量,Pi 表示类别 i 样本数量占所有样本的比例。 从该公式可以看出,当数据集中数据混合的程度越高,基尼指数也就越高。当数据集 D 只有一种数据类型,那么基尼指数的值为最低 0。
如果选取的属性为 A,那么分裂后的数据集 D 的基尼指数的计算公式为:
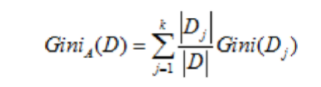
图6 选取特征A后数据集的基尼指数计算公式
其中 k 表示样本 D 被分为 k 个部分,数据集 D 分裂成为 k 个 Dj 数据集。
对于特征选取,需要选择最小的分裂后的基尼指数。也可以用基尼指数增益值作为决策树选择特征的依据。公式如下:
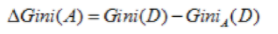
图7 基尼指数增益值计算公式
在决策树选择特征时,应选择基尼指数增益值最大的特征,作为该节点分裂条件。
接下来介绍剪枝。在分类模型的建立过程中,很容易出现过拟合现象。过拟合是指在模型学习训练过程中,训练样本达到非常高的逼近精度,但检验样本的误差随着训练次数增多出现先上升后下降的现象。过拟合时训练误差很小,但检验误差很大,不利于实际应用。
决策树的过拟合现象可以通过剪枝进行一定的修复,剪枝分为预先剪枝和后剪枝两种。
预剪枝指的是在决策树生长过程中,通过一定的条件加以限制,使得产生完全拟合的决策树之前就停止生长。预先剪枝的判断方法也有很多,比如信息增益小于一定阈值的时候通过剪枝使决策树停止生长。但如何确定一个合适的阈值也需要一定的依据,阈值太高导致模型拟合不足,阈值太低又会导致模型过拟合。
后剪枝是指在决策树生长完成之后,按照自底向上的方式修剪决策树。后剪枝的方式有两种,一种是用新的叶子节点替换子树,该节点的预测类由子树数据集中的多数类决定。另一种用子树中最长使用的分支替代子树。预剪枝可能过早的终止决策树的生长,后剪枝一般能产生更好的效果。但后剪枝在子树被剪掉后,决策树生长的一部分计算就被浪费了。
五、决策树模型的评估
建立了决策树模型后需要给出该模型的评估值,这样才可以来判断模型的优劣。学习算法模型使用训练集建立模型,使用校验集来评估模型。本文通过评估指标和评估方法来评估决策树模型。评估指标有分类准确度、召回率、虚警率和精确度等。而这些指标都是基于混淆矩阵进行计算的。
混淆矩阵是用来评价监督式学习模型的精确性,矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。以二类分类问题为例,如下表所示:
表1 混淆矩阵
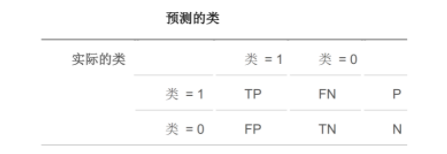
P(Positive Sample):正例的样本数量。N(Negative Sample):负例的样本数量。其中:
TP(True Positive):正确预测到的正例数量,FP(False Positive):错误预测到的正例数量
FN(False Negative):错误预测到的负例数量,TN(True Negative):正确预测到的负例数量
根据混淆矩阵可以得到评价分类模型的指标有以下几种:
分类准确度,就是正负样本被正确分类的概率,计算公式为:

图8 分类准确度计算公式
召回率,就是正样本被识别出的概率,计算公式为:
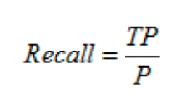
图9 召回率计算公式
虚警率,就是负样本被错误分为正样本的概率,计算公式为:
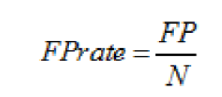
图10 虚警率计算公式
精确度,就是分类结果为正样本的情况真实性程度,计算公式为:
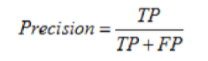
图11 精确度计算公式
评估方法有保留法、随机二次抽样法、交叉验证法和自助法等
保留法(holdout):是评估分类模型性能最常用的一种方法。将被标记的原始数据集分成训练集和检验集两份,训练集用于训练分类模型,检验集用于评估分类模型性能。但此方法不适用样本较小的情况,模型可能高度依赖训练集和检验集的构成。
随机二次抽样(random subsampling):是多次重复使用保留法改进分类器评估方法。同样此方法也不适用训练数量不足的情况,而且也可能造成有些数据未被用于训练集。
交叉验证(cross-validation):指将数据分成数量相同的K份,每次使用数据进行分类时,选择其中一份作为检验集,剩下K-1份作为训练集,重复K次,正好使每一份数据都被用于一次检验集和K-1次训练集。该方法的优点是尽可能多的数据作为训练数据,且每一次的训练集和测试集数据都是相互独立的且覆盖整个数据集的,也存在一个缺点,就是分类模型计算了K次,计算开销比较大。
自助法(bootstrap)是指在其方法中,训练集数据采用的是有放回的抽样,即已经选取为训练集的数据又被放回原来的数据集中,使得该数据能有机会被重新抽取一次,该方法适用于样本不多的情况,效果非常好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号