结对作业二
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对作业二 |
| 结对学号 | 221801208、221801227 |
| 这个作业的目标 | 实现顶会热词统计 |
| 其他参考文献 | github、CSDN |
网站链接
tips
- 由于注册功能还未完成,所以提供了两个可用的初始登录账号密码:
- 账户1:账号:admin ,密码:admin
- 账户2: 账号:user ,密码:123456
- “热词图谱”加载较慢,需等待10秒才能加载出完整界面,请不要在刚打开“热词图谱”界面时就点击关键词;
- 搜索论文时,个别关键词匹配的论文较多,需要等待;
- 请用除IE以外的浏览器打开
git仓库链接和代码规范链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Development | 开发 | ||
| • Analysis | • 需求分析 | 40 | 30 |
| • Design Spec | • 生成设计文档 | 20 | 30 |
| • Design Review | • 设计复审 | 10 | 10 |
| • Coding Standard | • 代码规范 | 80 | 100 |
| • Coding | • 具体编码 | 3500 | 4000 |
| • Code Review | • 代码复审 | 200 | 160 |
| • Test | • 测试 | 200 | 300 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 50 | 40 |
| • Size Measurement | • 计算工作量 | 20 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 50 | 60 |
| 合计 | 4170 | 4745 |
成品展示
账户1: 账号:admin ,密码:admin
账户2: 账号:user ,密码:123456
界面展示
登录、注册、找回密码界面
目前只实现登录功能,注册与找回密码只有界面
主页
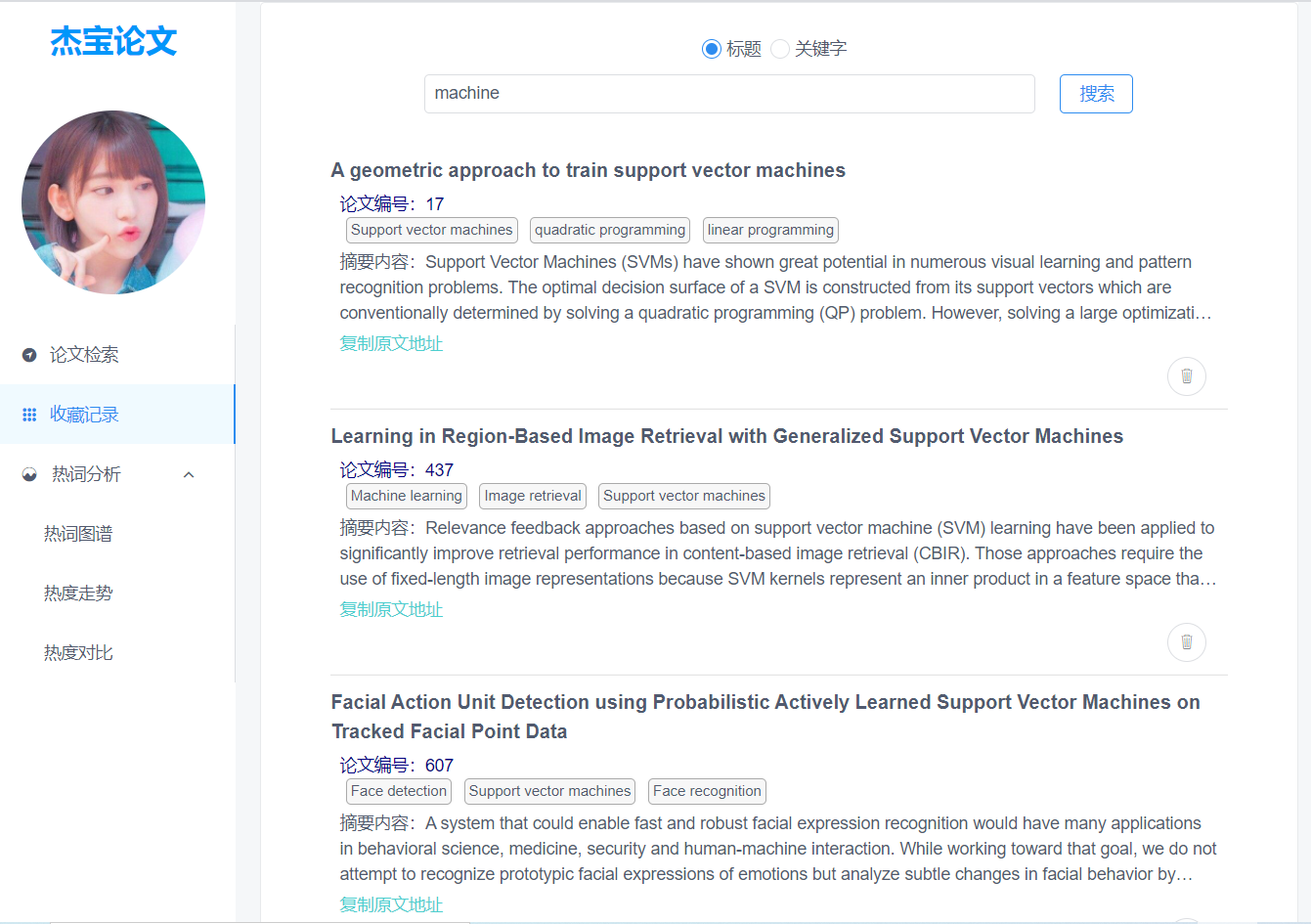
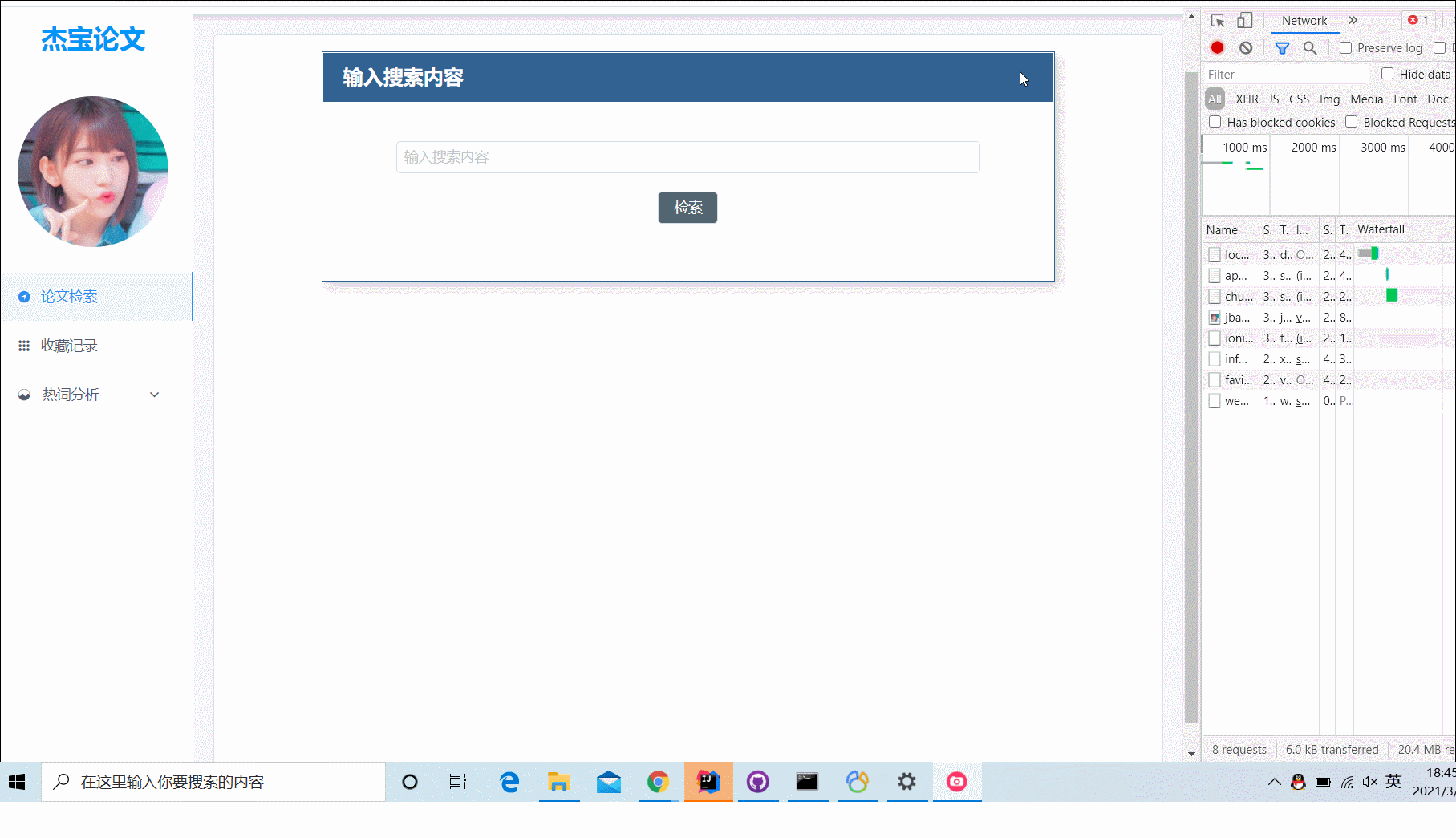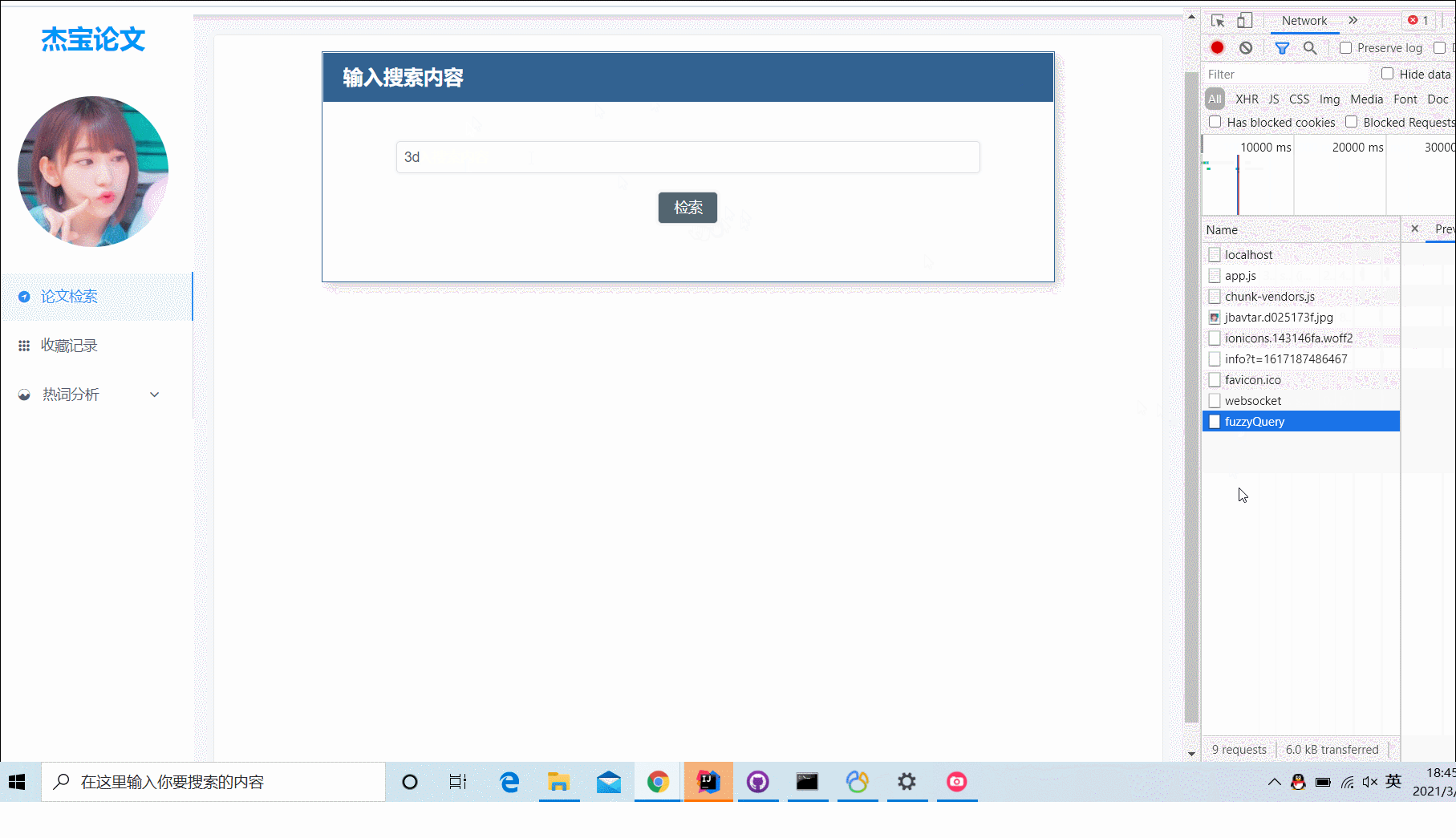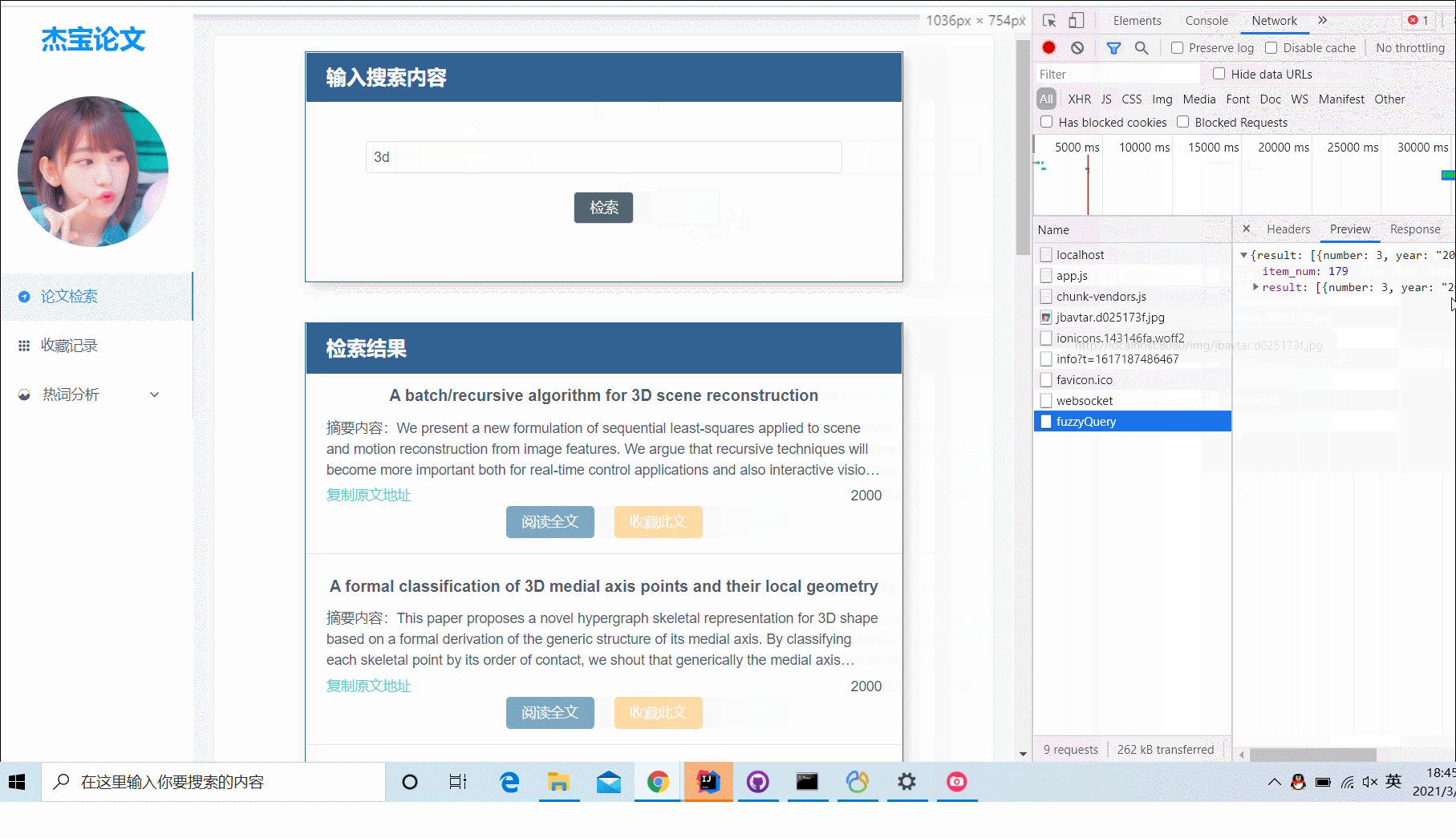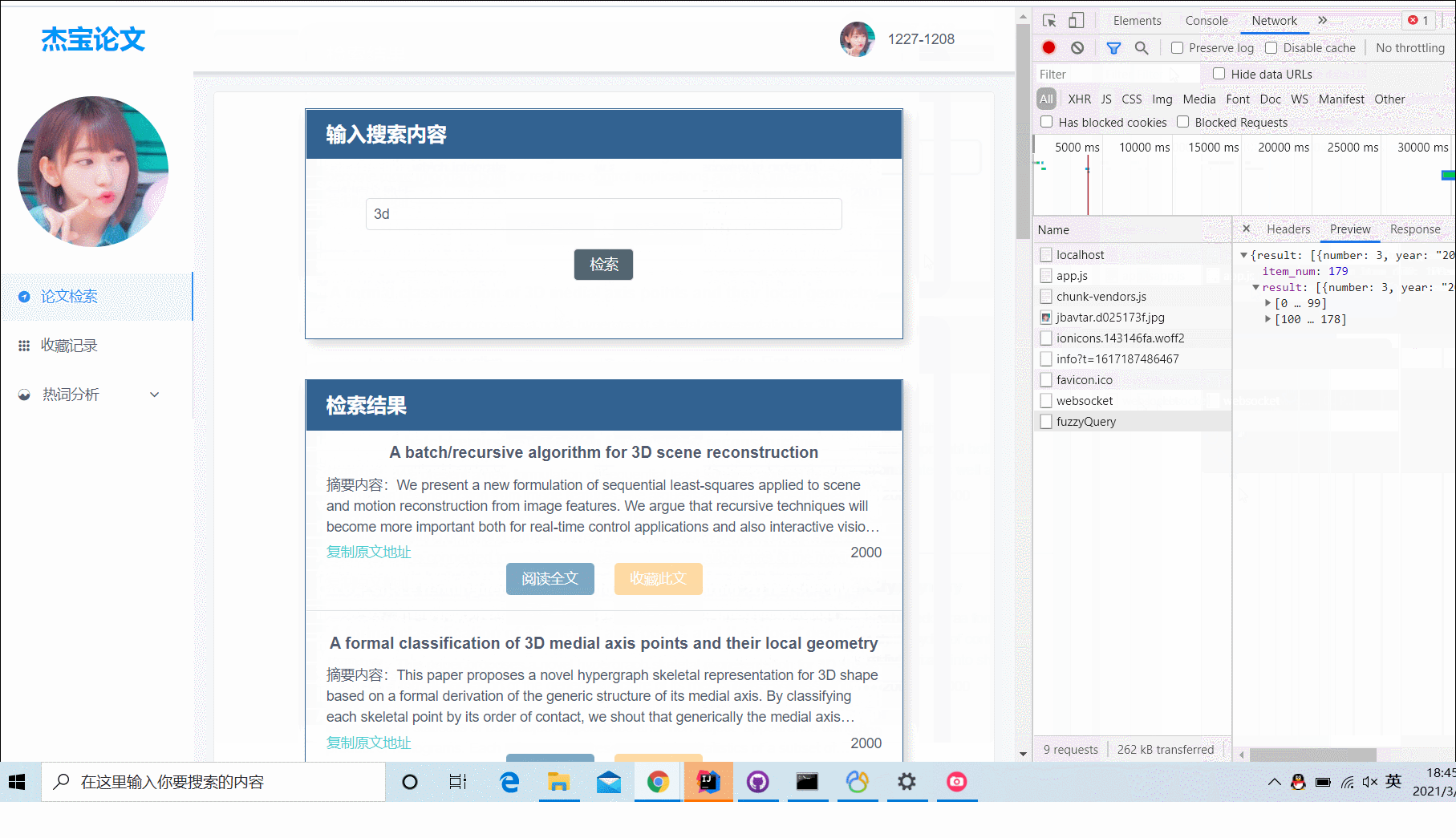
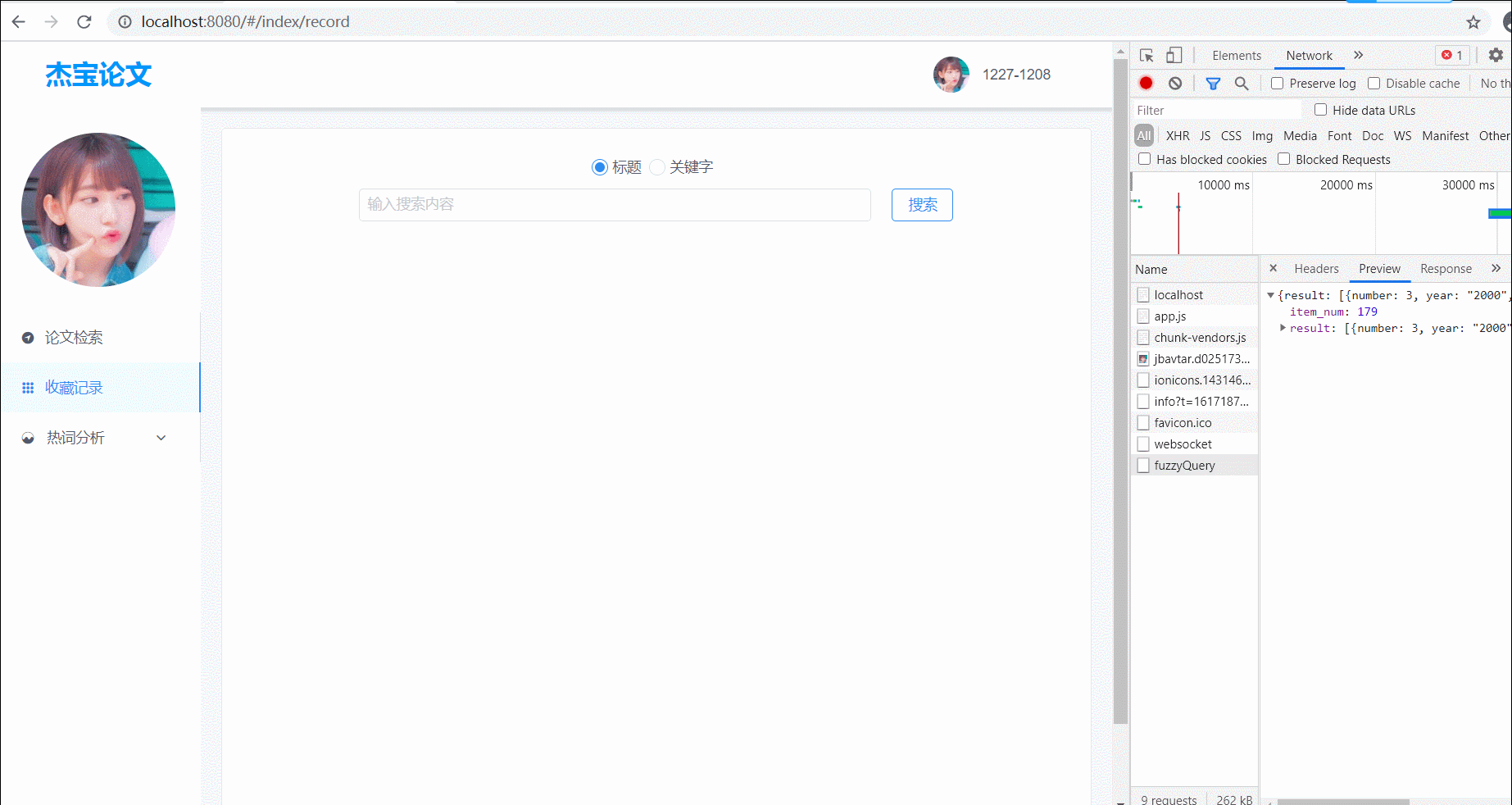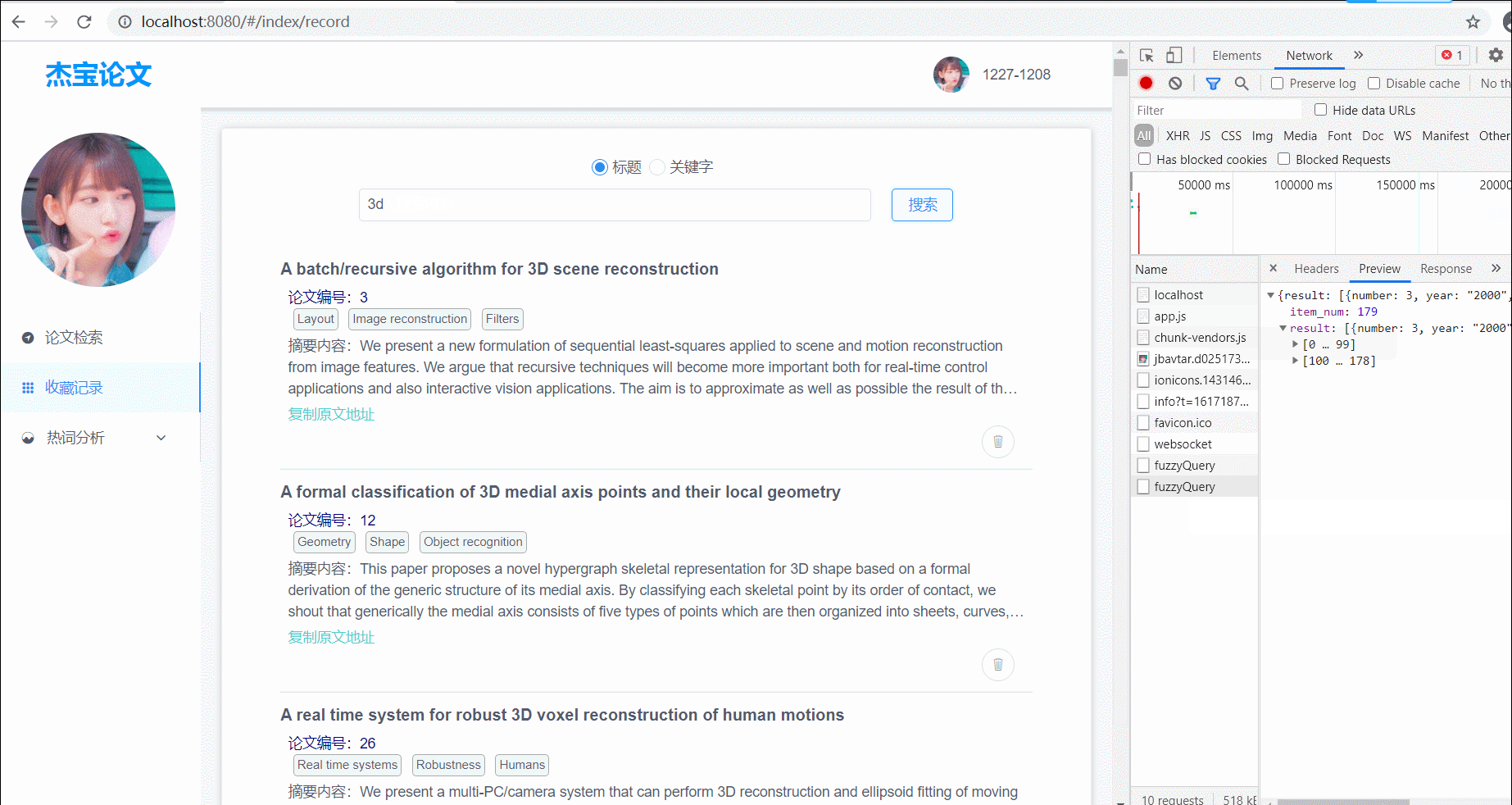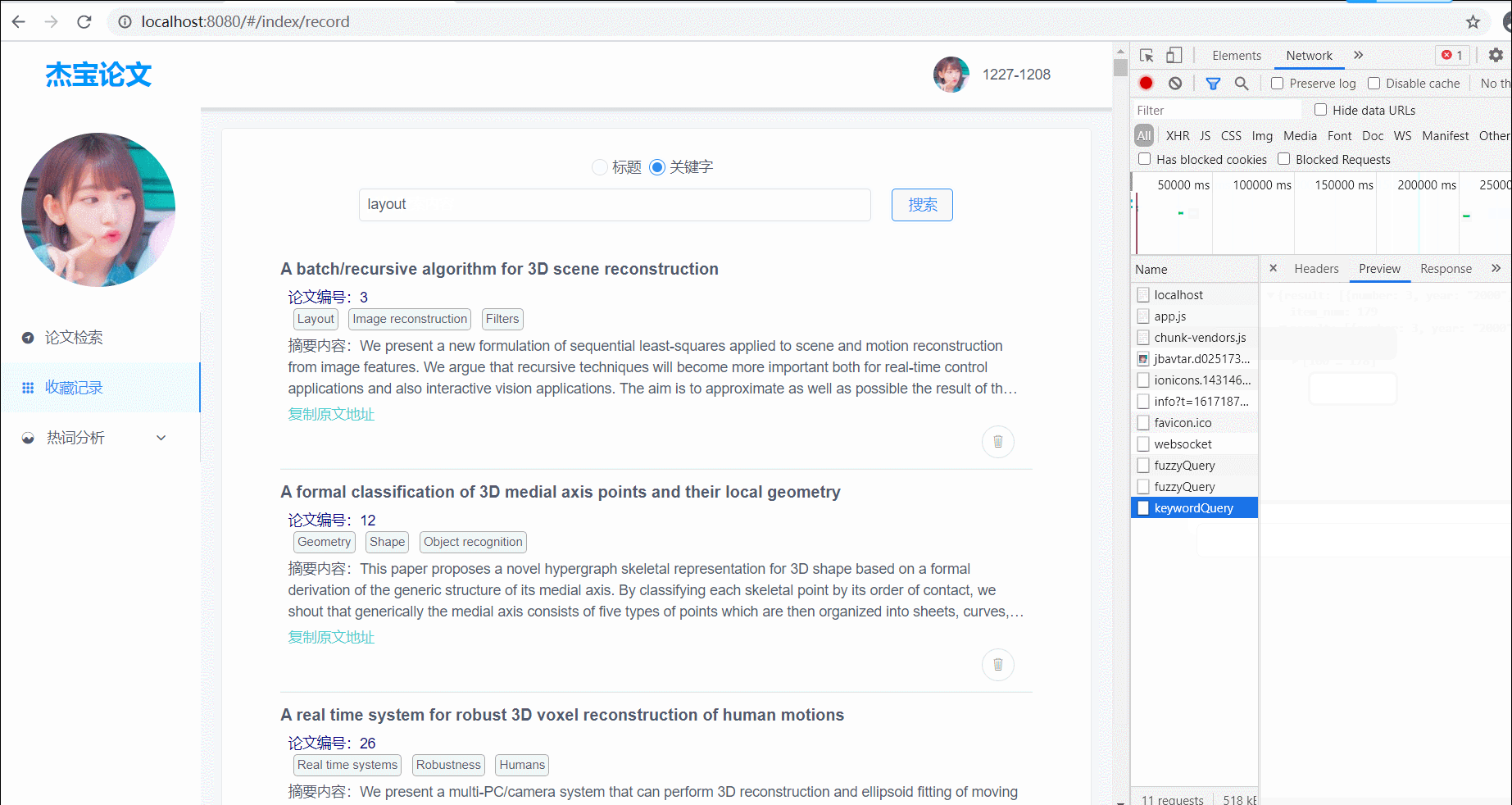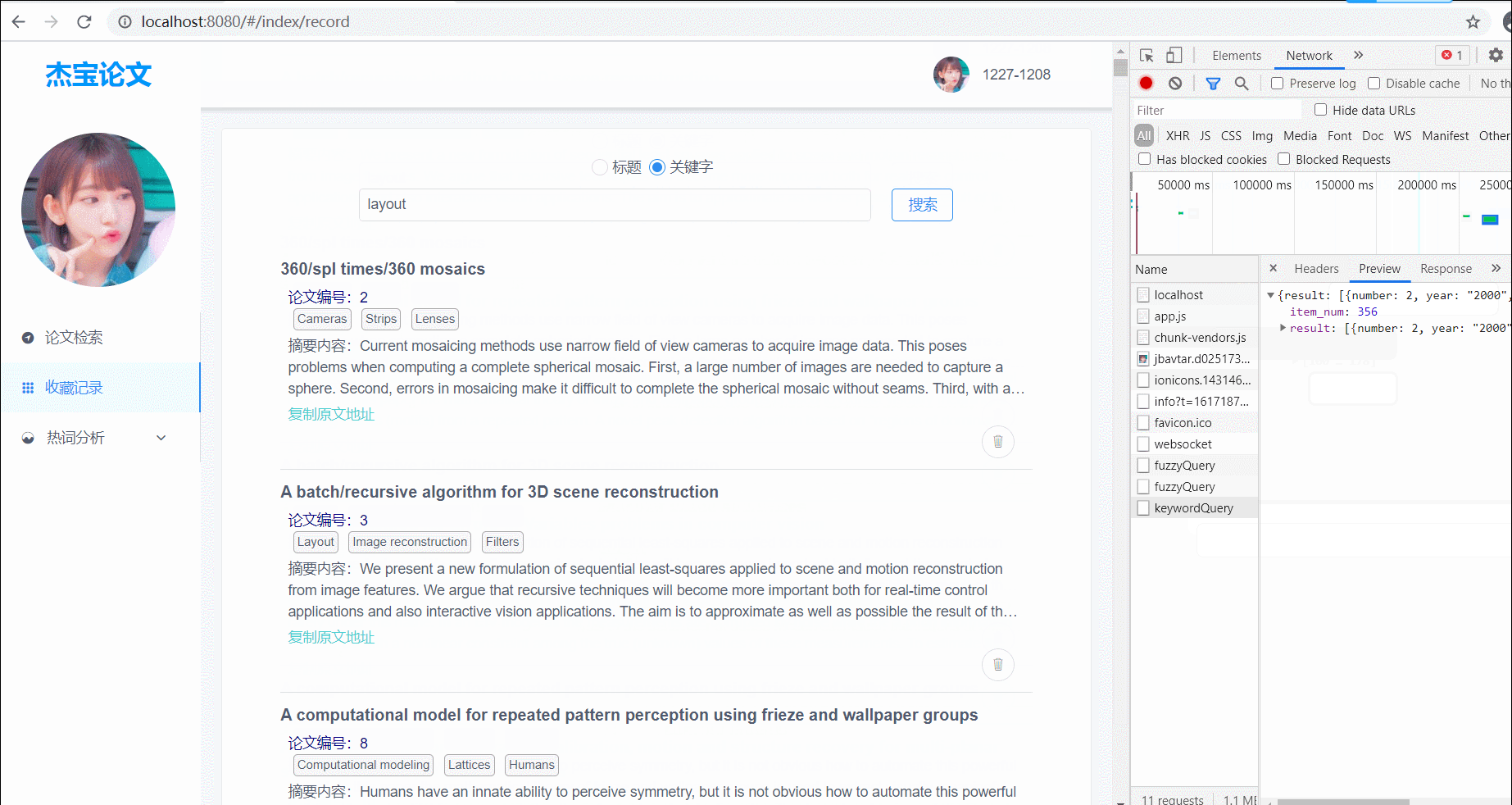
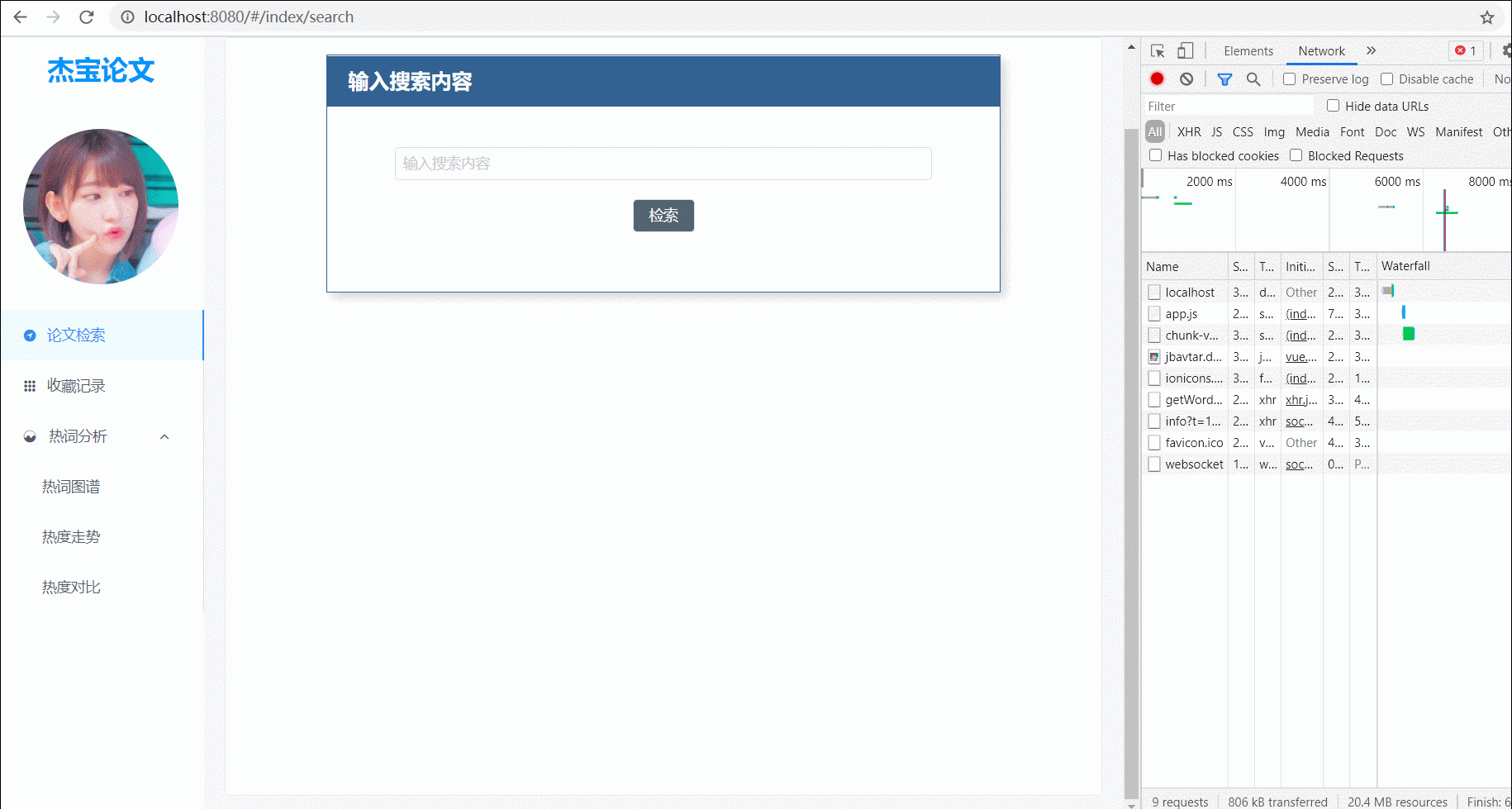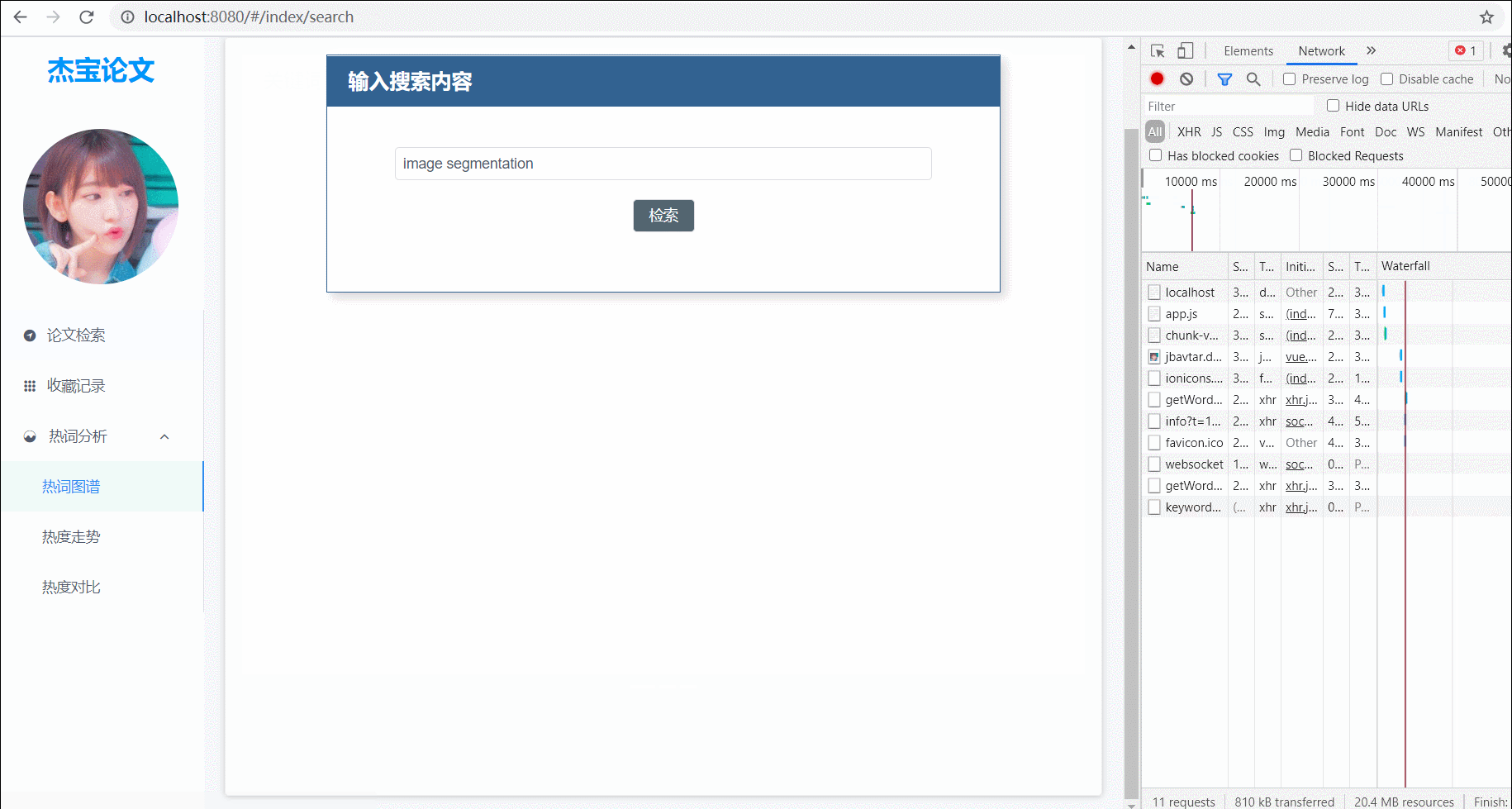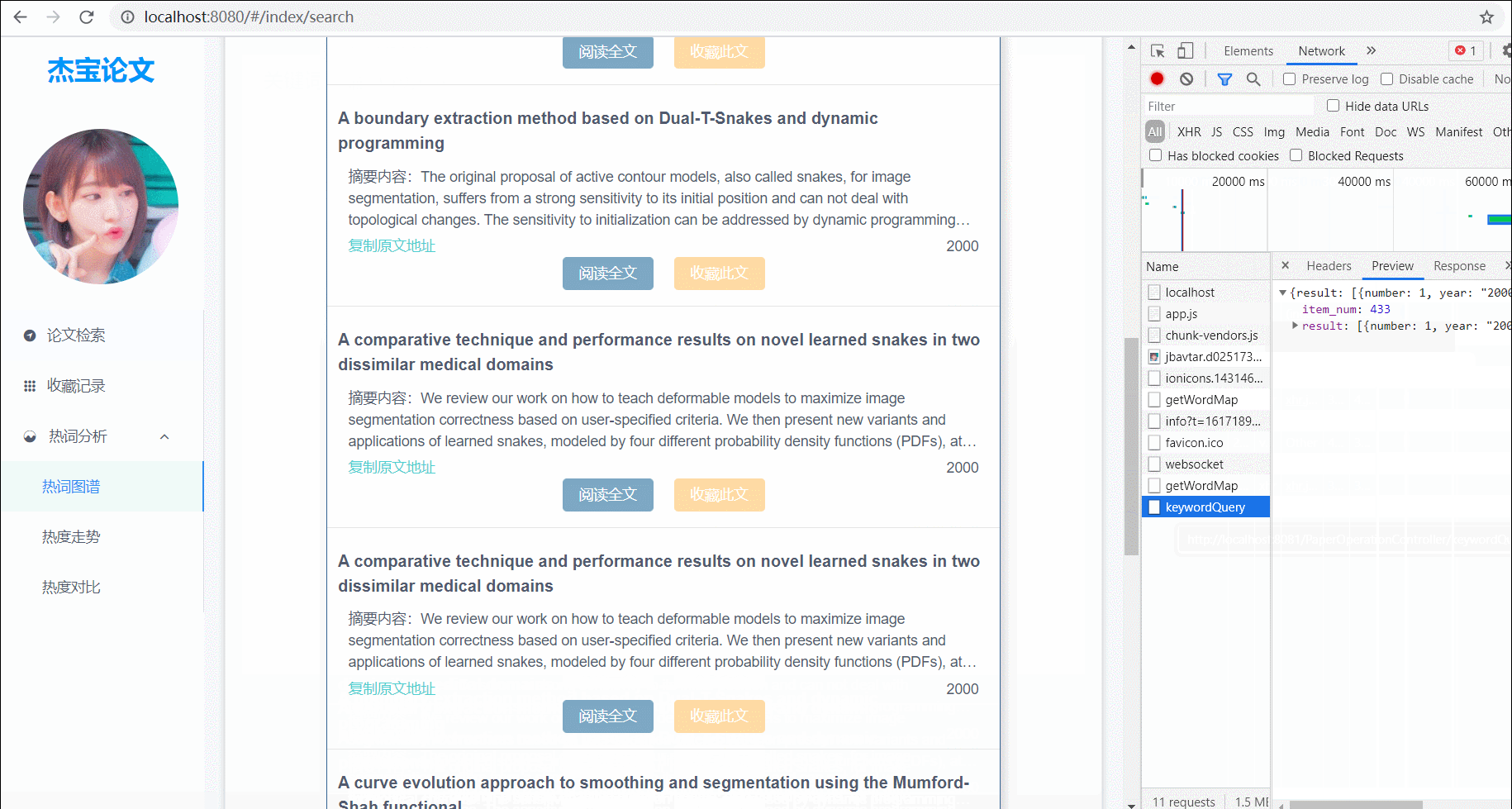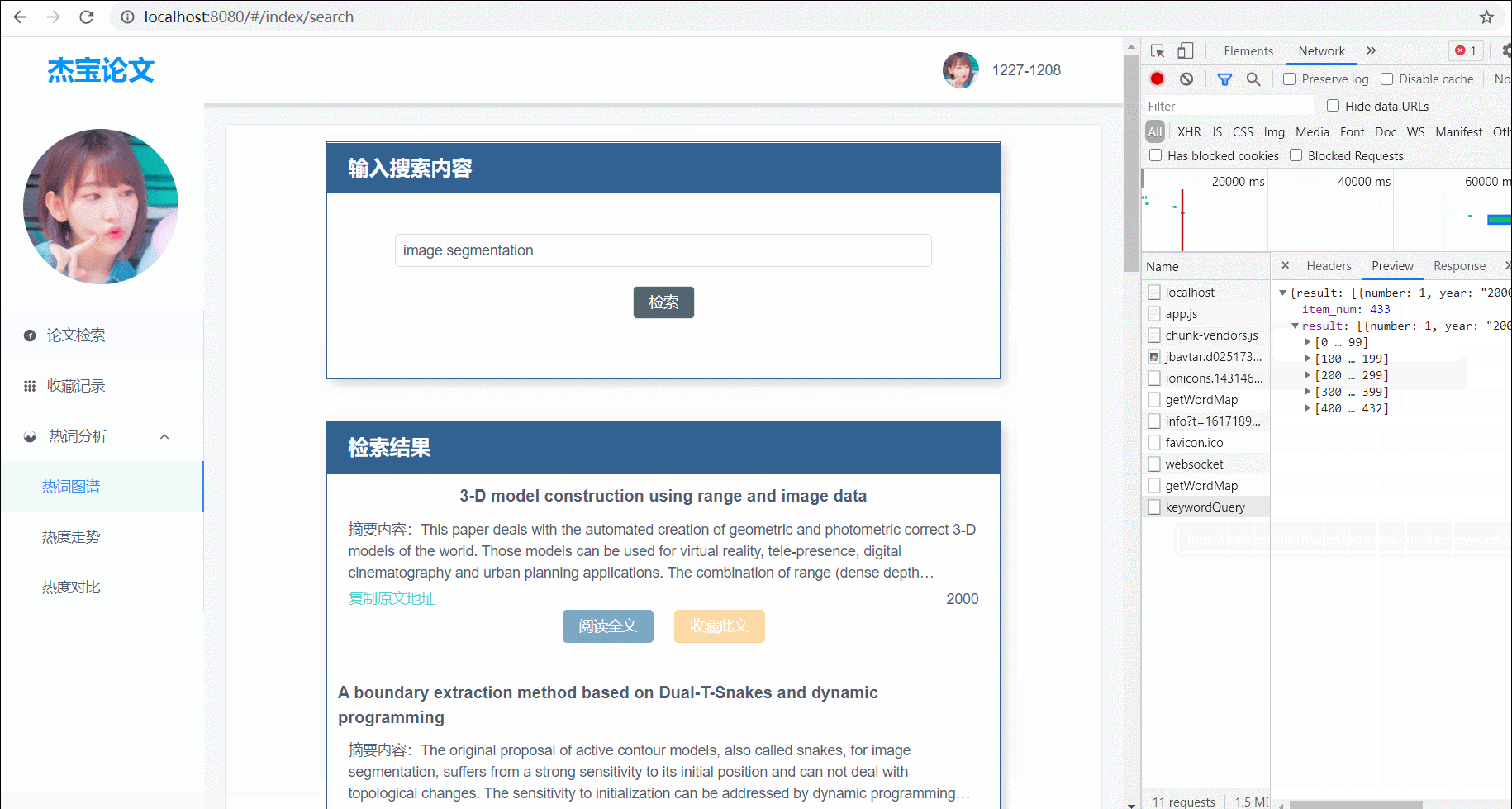
查询论文
支持标题模糊查询、标签查询;查询结果分页展示,每页展示10条结果;有两个查询对象:1. 对爬取的所有论文查询;2. 对已经收藏的论文进行查询;
(图1)对爬取的所有论文进行查询,支持标题模糊搜索
(图2)对已经收藏的论文进行查询,支持标题以及关键字查询
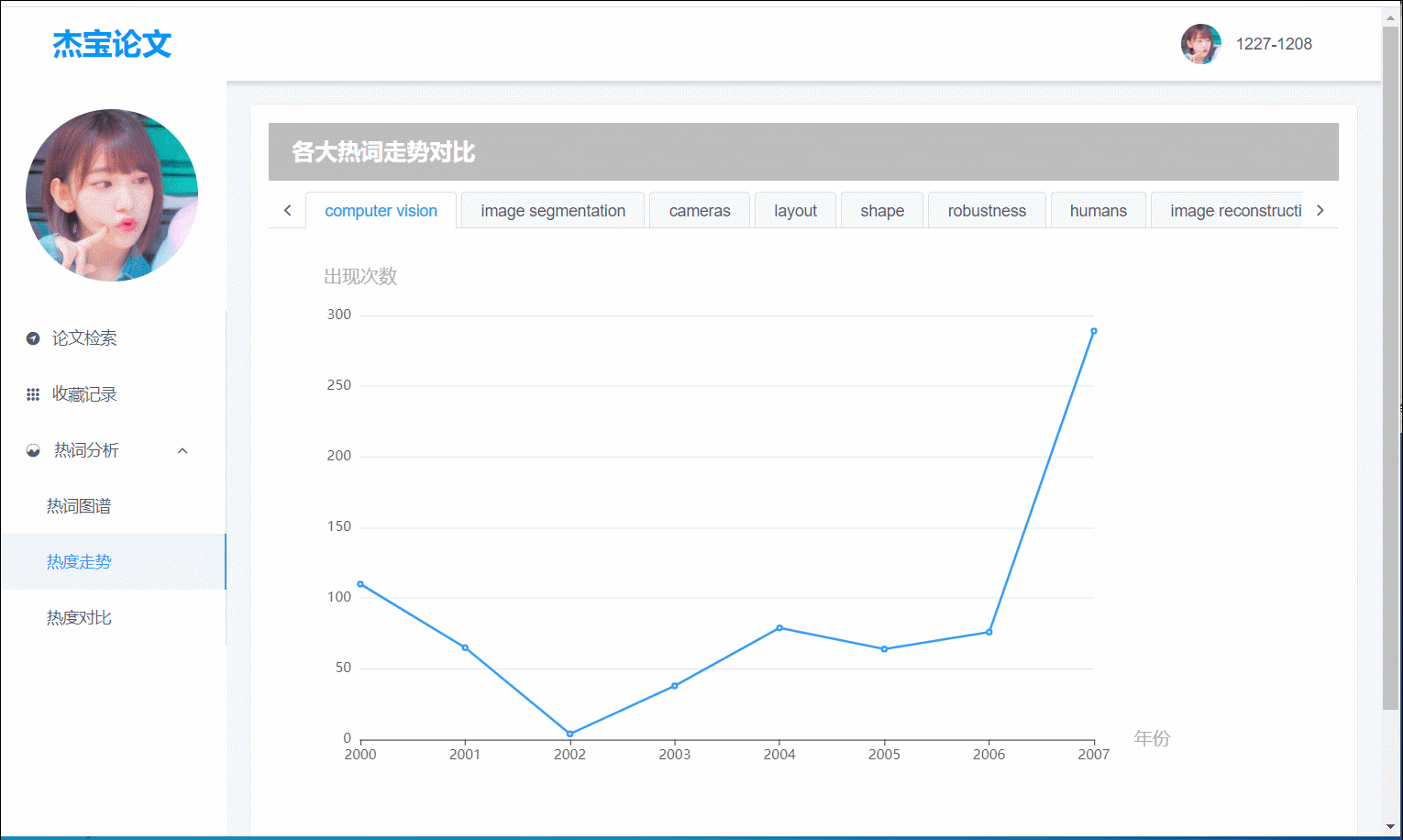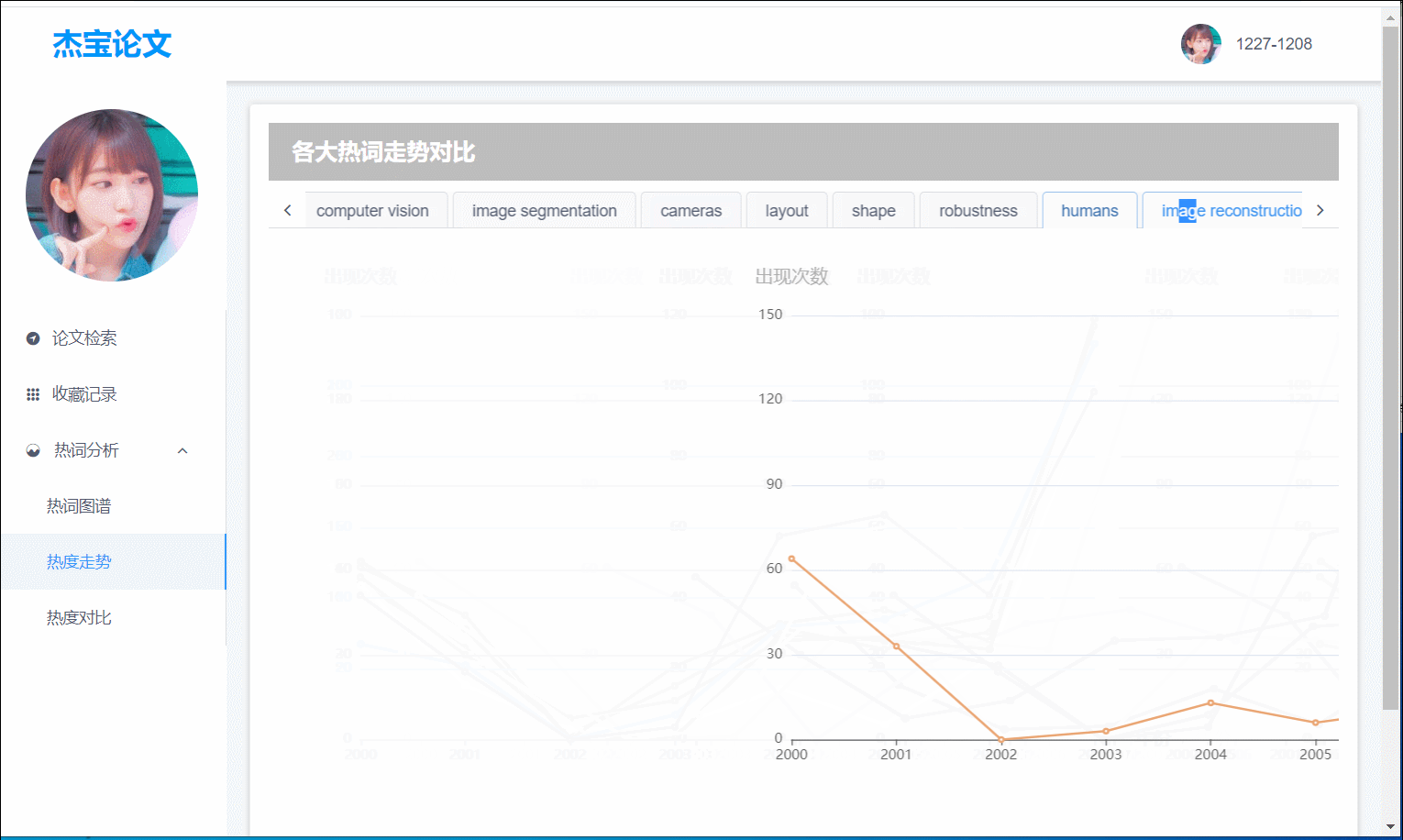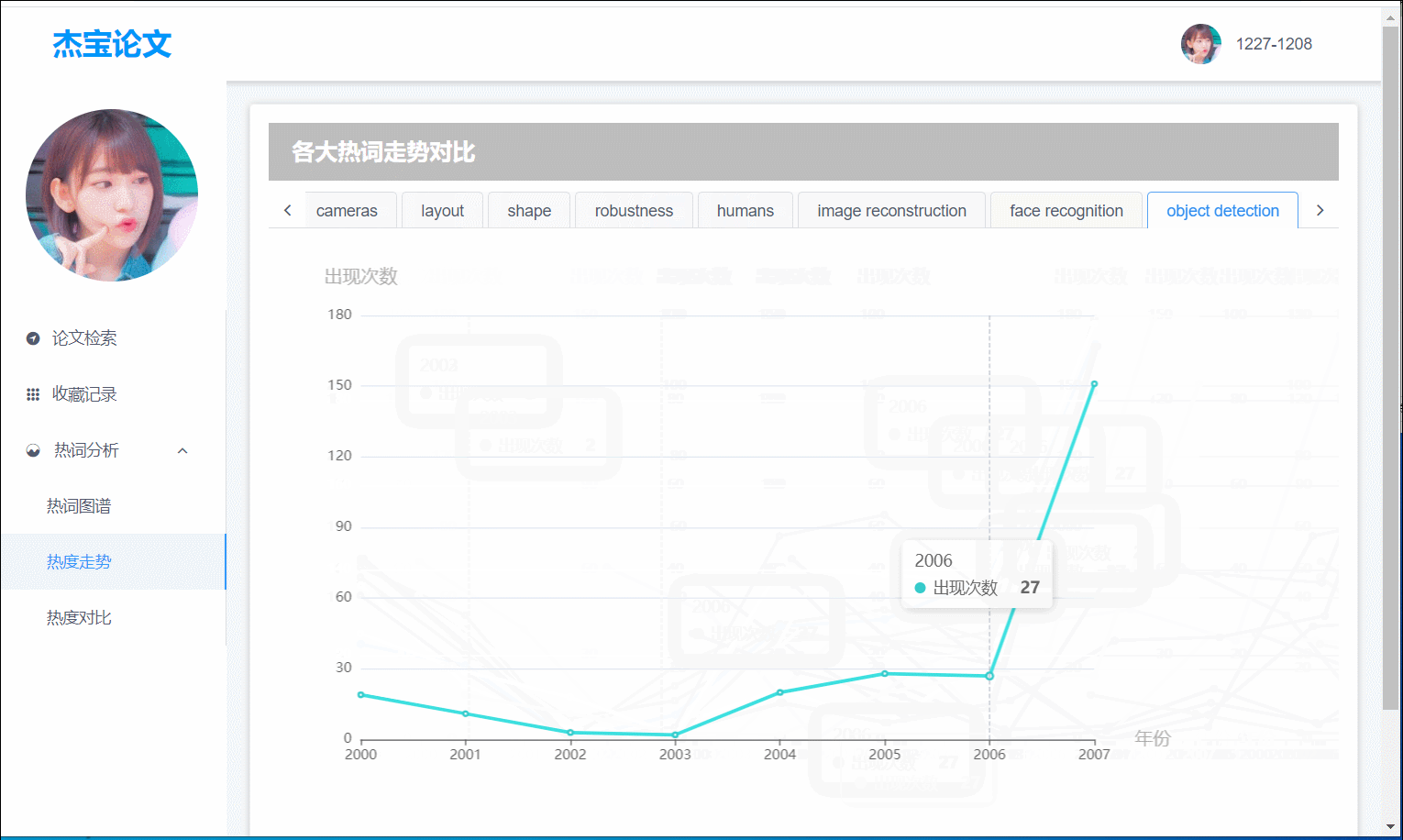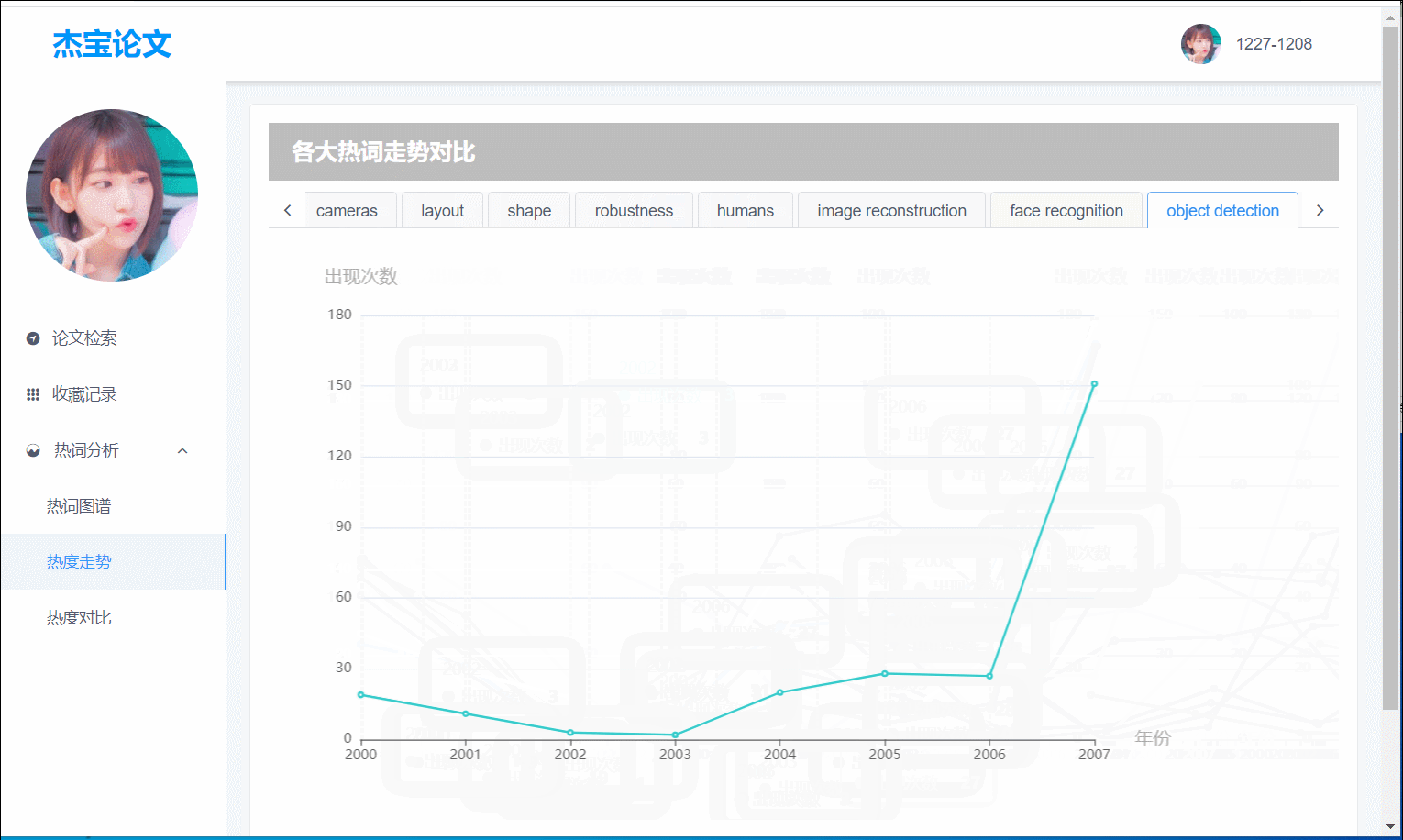
热词分析
其中共有热词图谱,热度走势,热度对比三大部分:
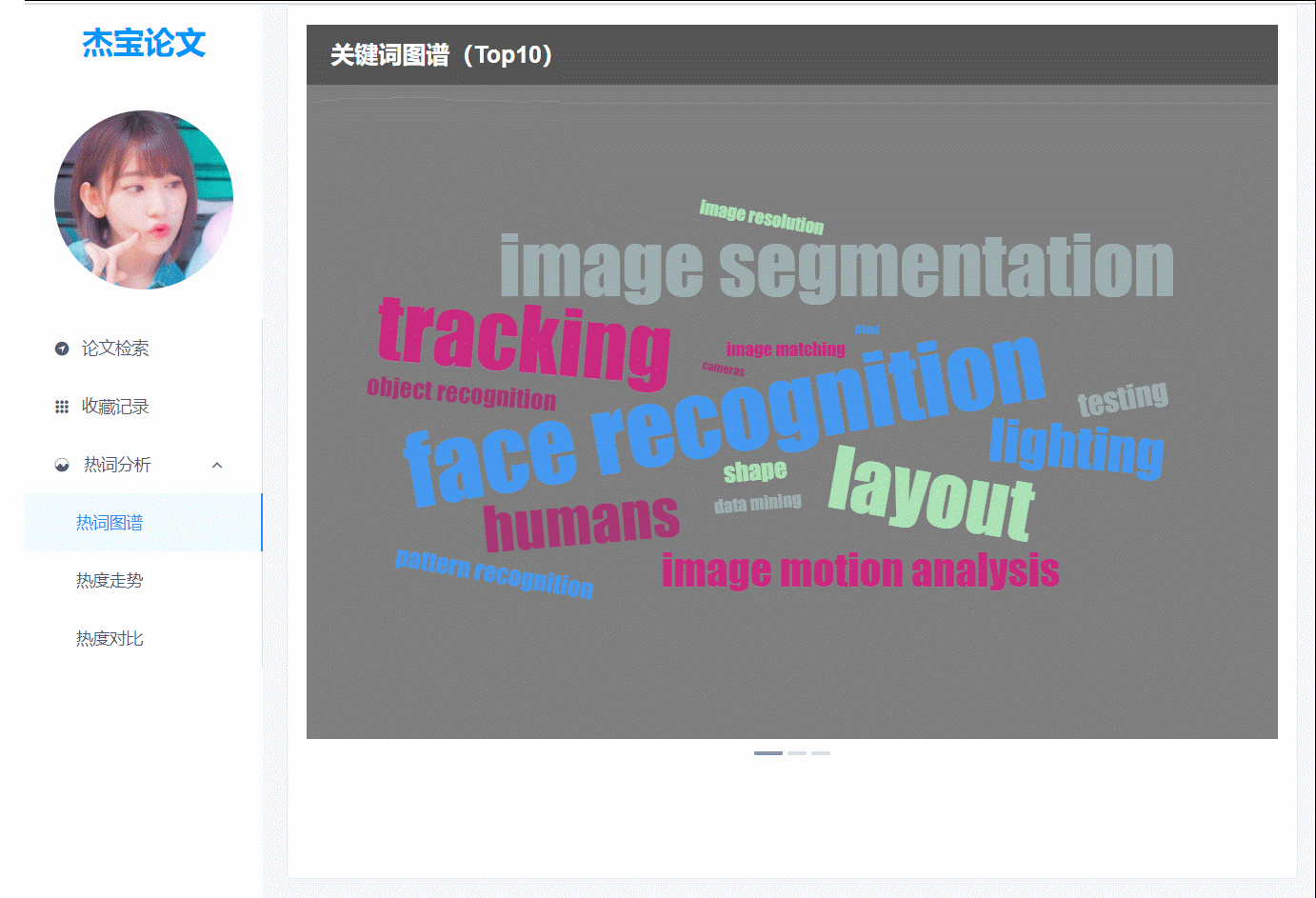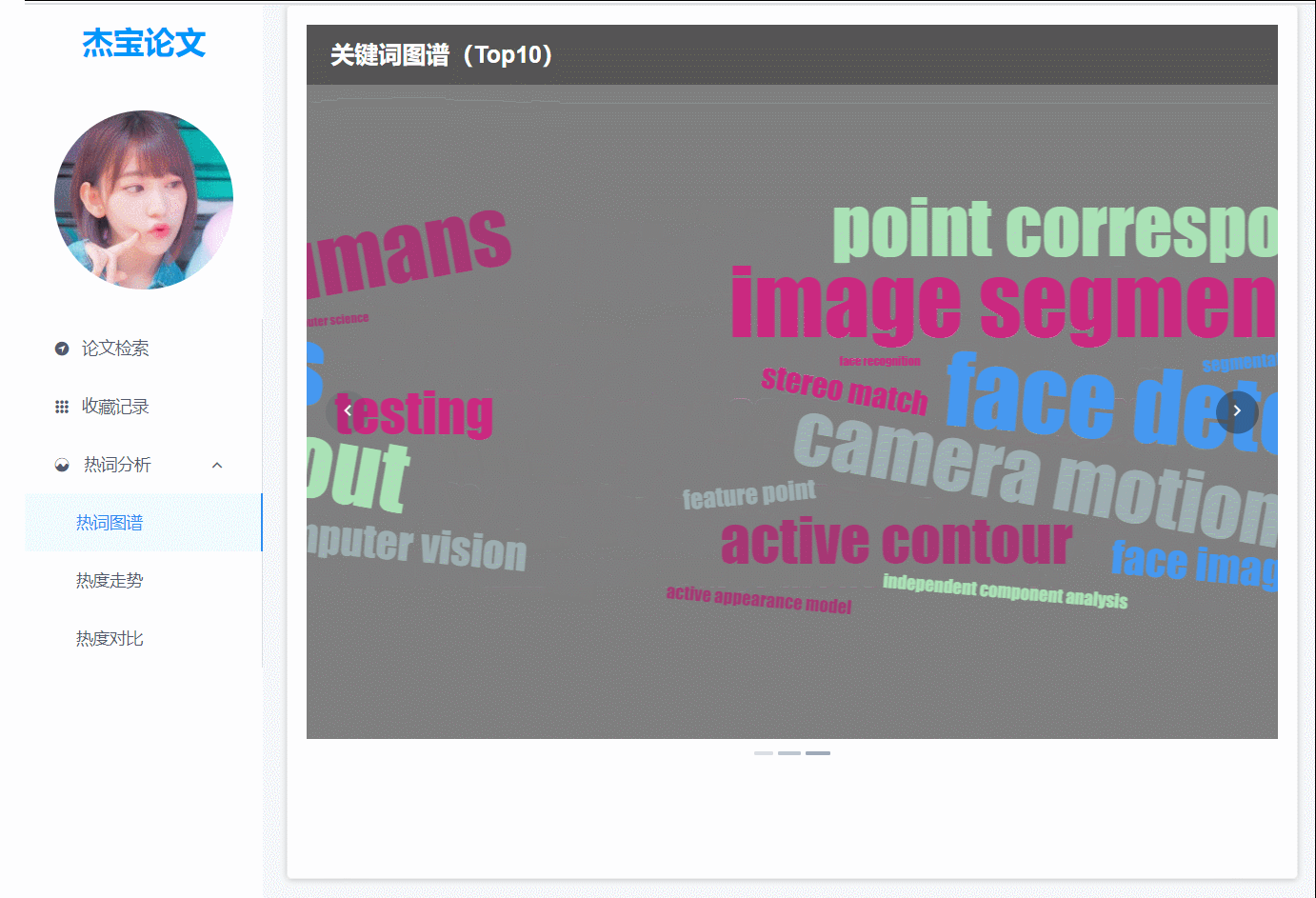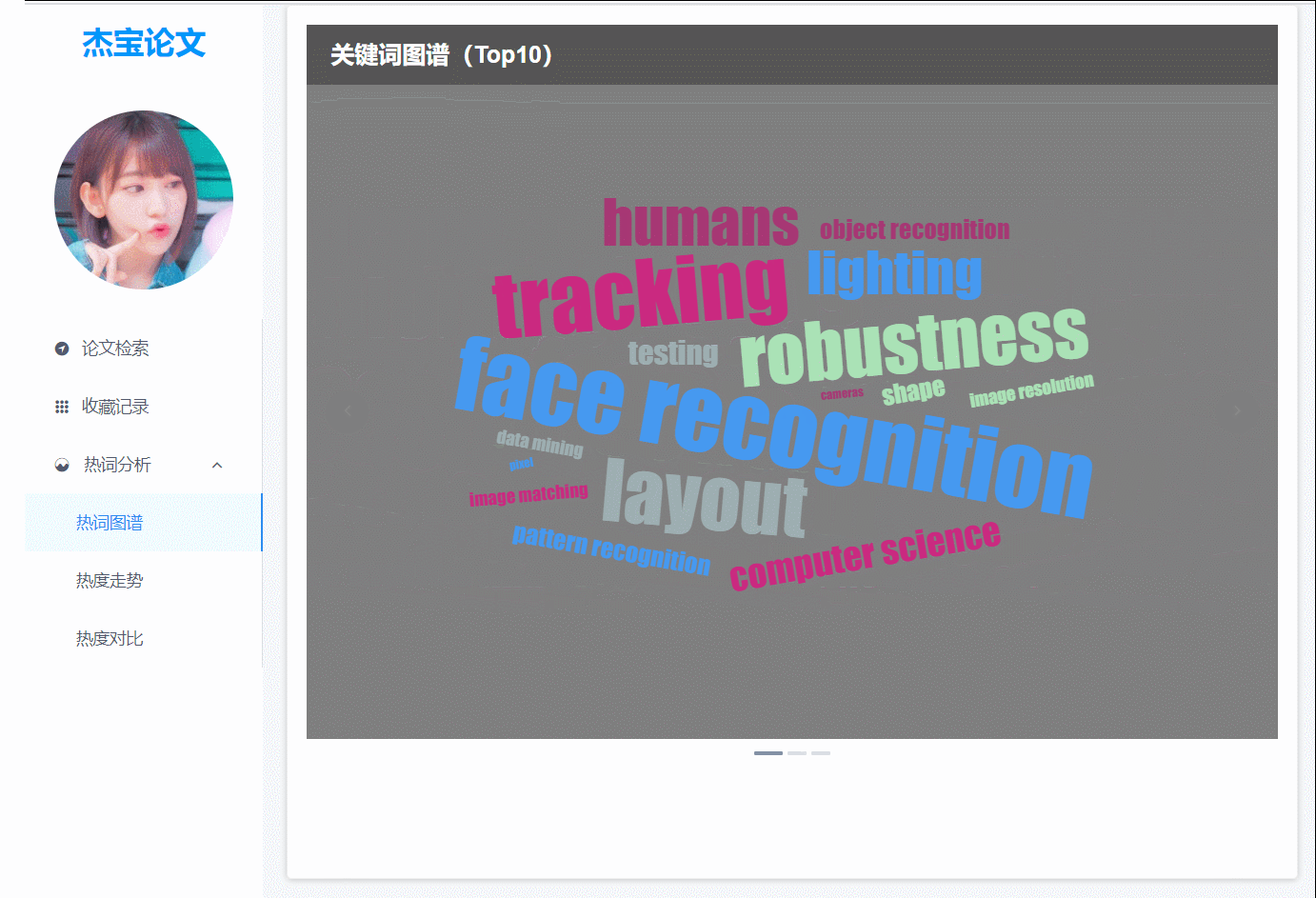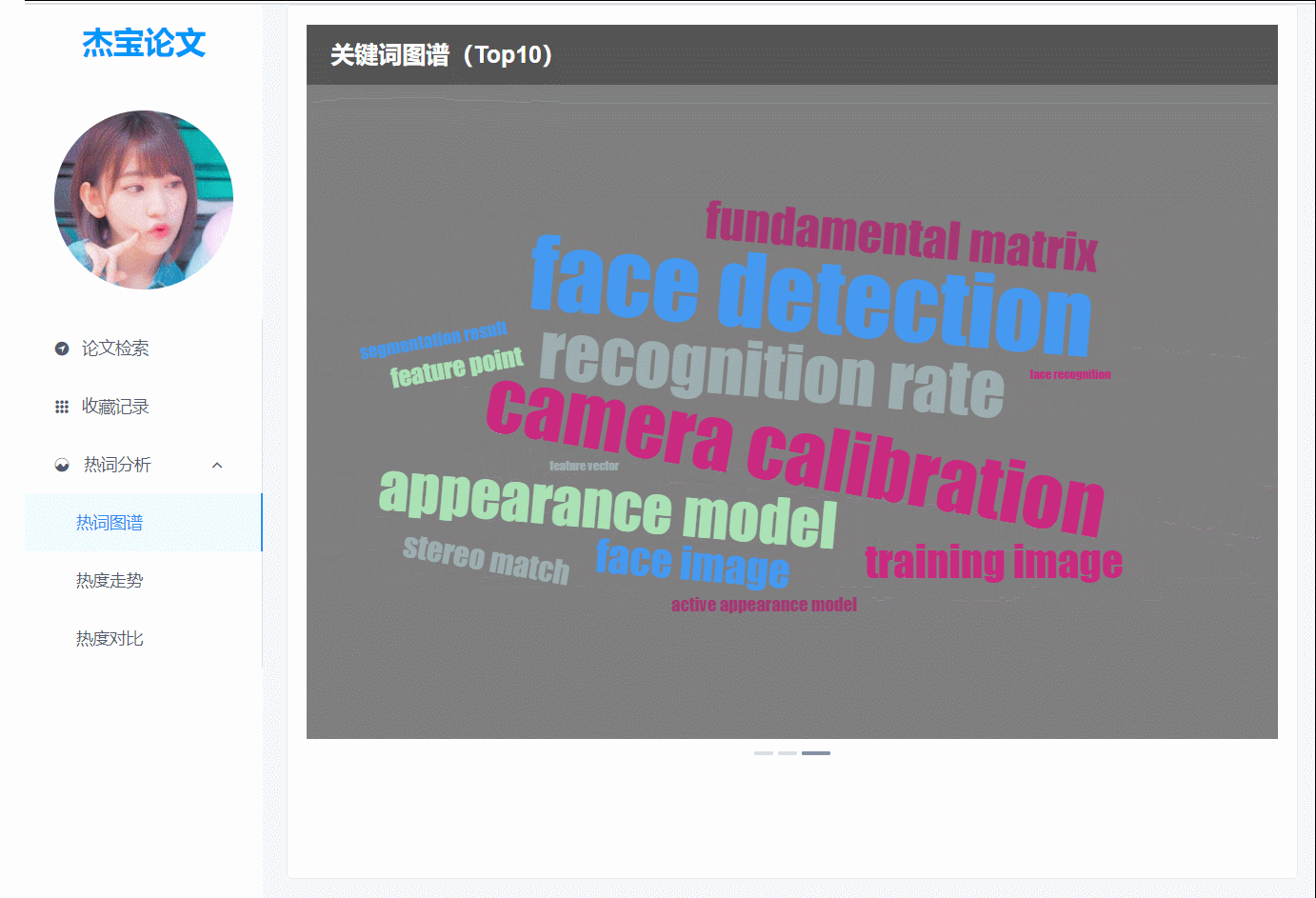
(图3)热词图谱,3大会议的热词词云,以轮播图的方式展示
(图4)热度走势:Top10热词按 年份-频数 得出的折线图
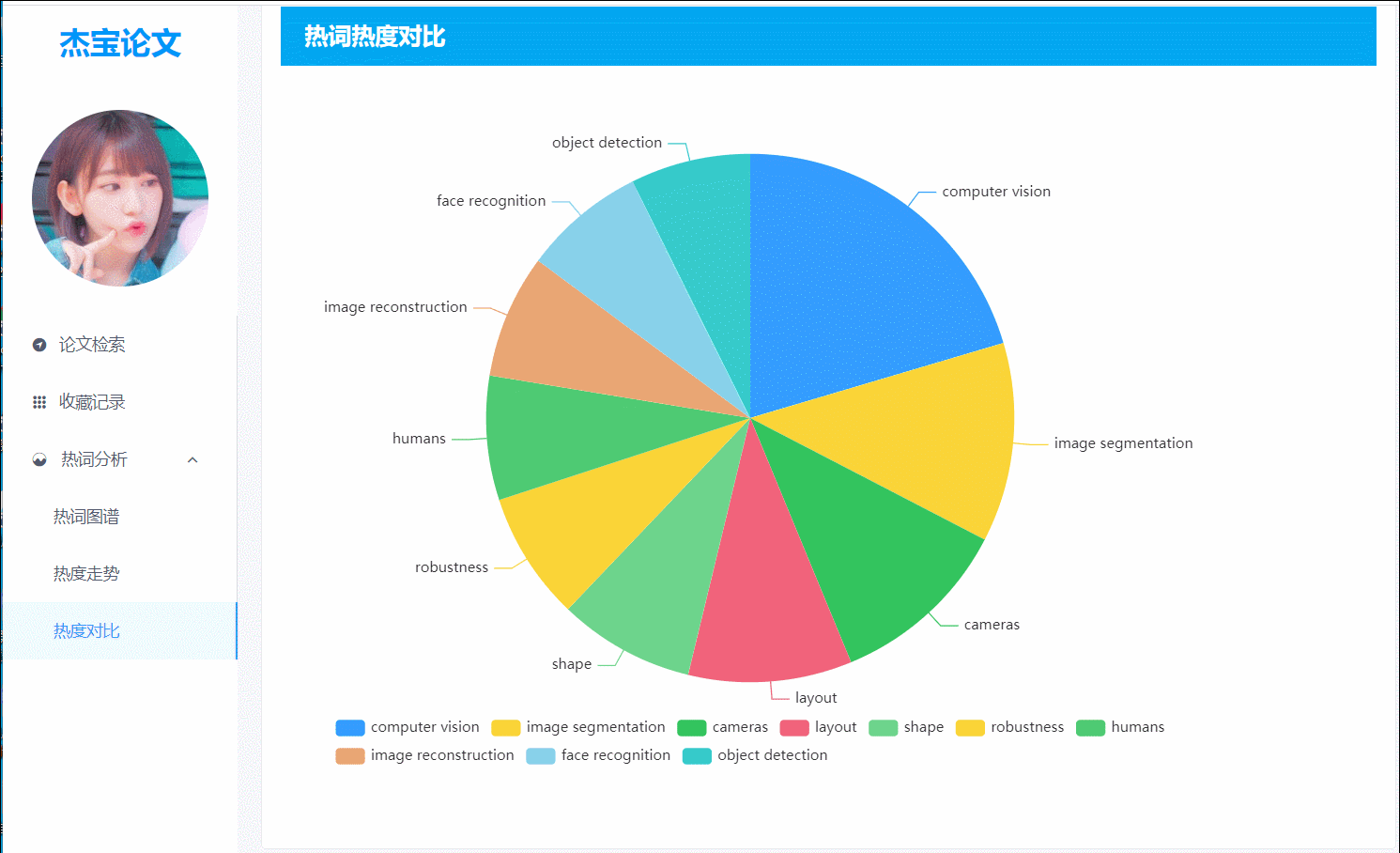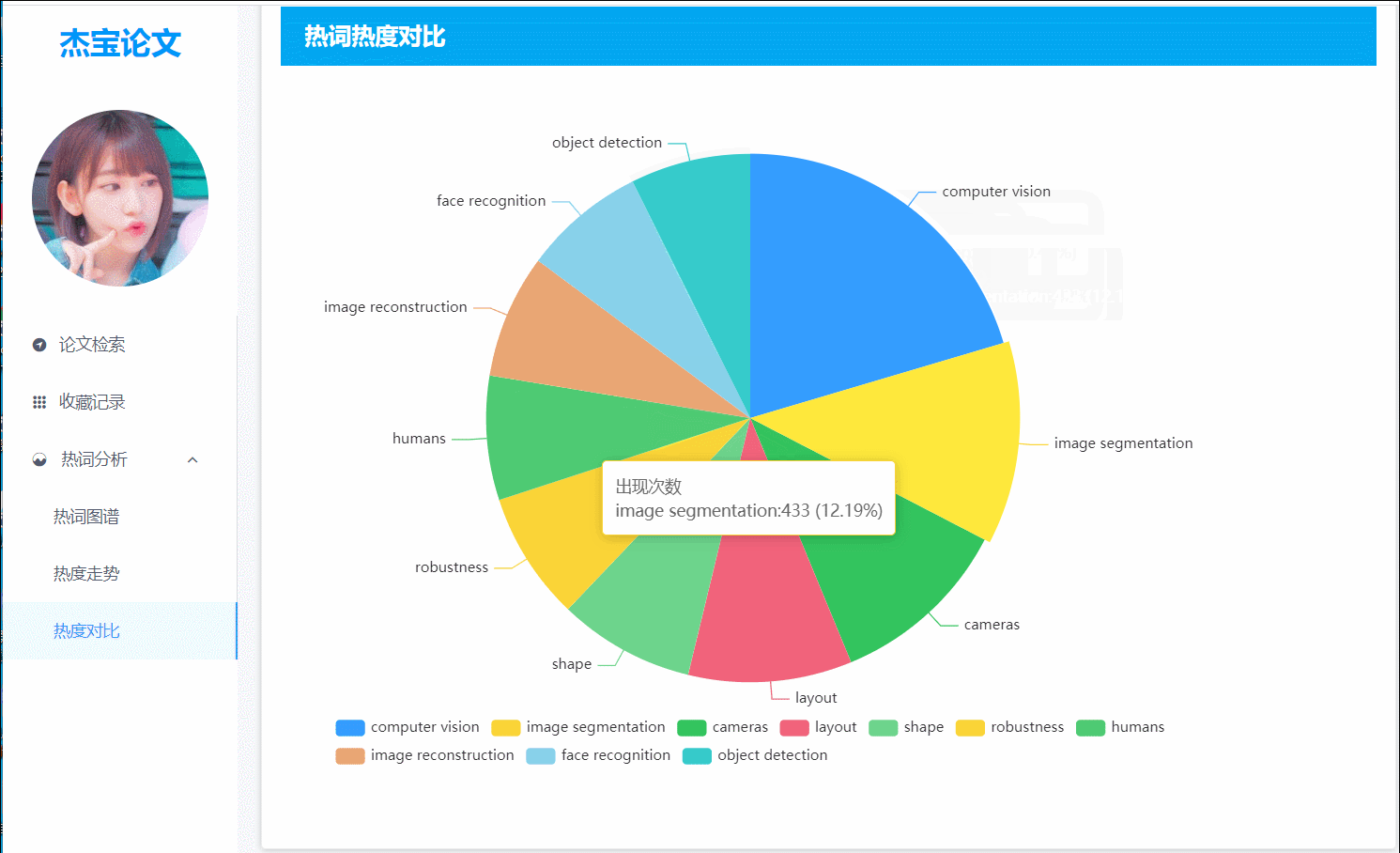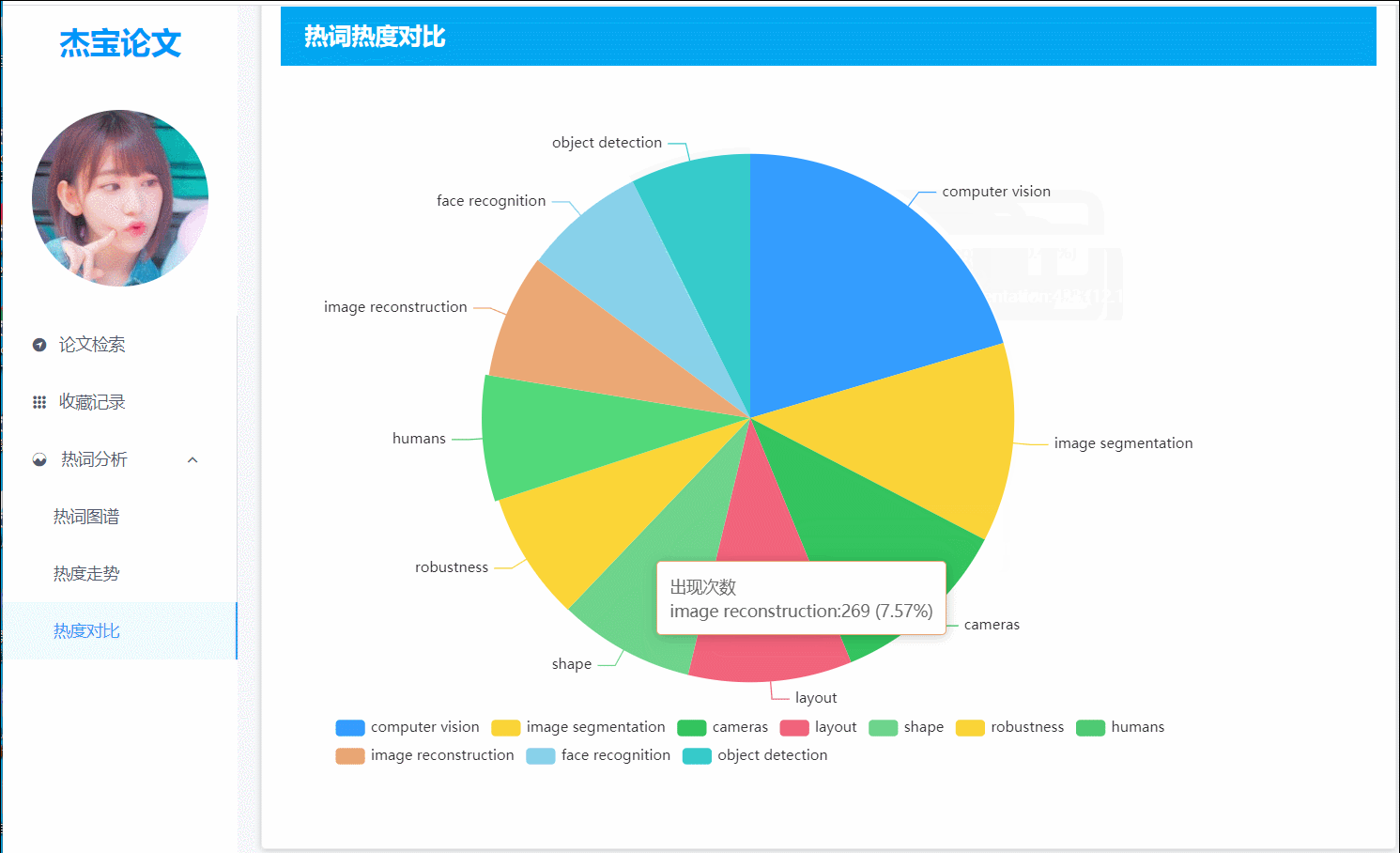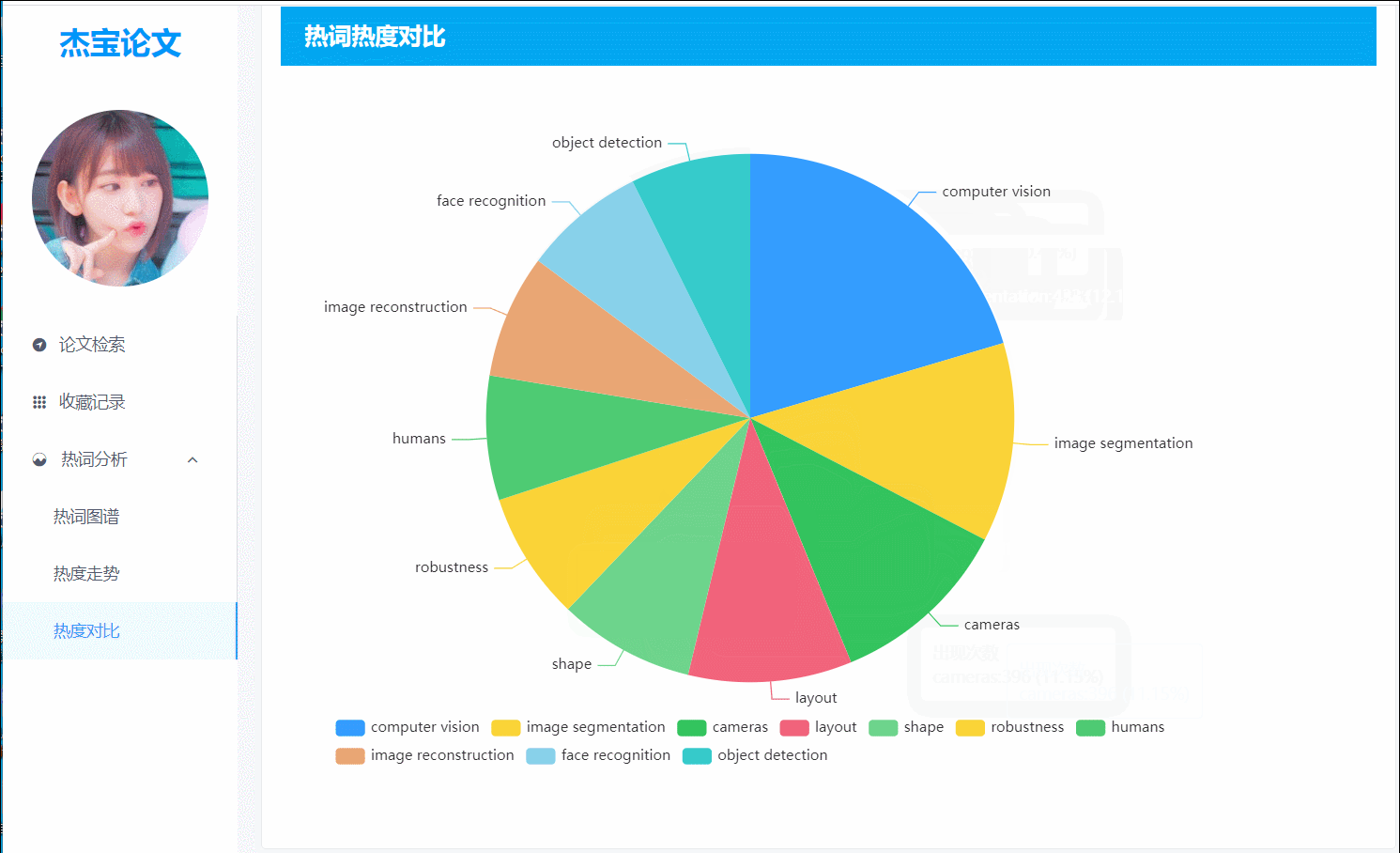
(图5)热词热度:以饼图的形式对比Top10的热词热度
更多功能
(图6)词云图上的词语,点击跳转至相应词的搜索结果
(图7)对搜索结果的地址进行一键复制

结对讨论过程描述
1.前后端交互讨论
一开始不确定用什么框架,经讨论之后确定为vue和springboot,这是我们小组用的相对来说最熟悉的框架。vue有一定基础,而且java接触较多,所以选择springboot作为后端框架。比较麻烦的是数据交换,JSONArray和JSONObject相互嵌套,后端跟前端的同学解释了好一会儿返回值的意义。后面放弃了,还是老老实实写个接口文档,帮助理解。
2.github使用讨论
之前没有用过远程分支,再加上还是用命令行管理项目版本的,所以始终整不明白怎么在远程建立分支并提交。ch建议换成github desktop可视化操作,理解和操作都简单了许多。
3.框架使用讨论
springboot花了不少时间找教程,目的是快速上手。对于新手来说易于理解的教程找起来不容易,二人互相发了很多教程,费了不少功夫才找到简单的一个demo,自己慢慢理解。注解在springboot中出现频率最高,和java语言不同,没有前后端交互经验的初学者不好理解,没看懂的时候就和队友讨论。
4.数据库讨论
数据库表结构关乎后端模型。讨论出的第一种方案是一张表解决,把所有关键词作为text存储。起初以为在同一张表存储所有信息会加快查找速度,但是不利于编码,而且每次取出来还要分割字符串会降低性能(果然讨论比个人的想法要周全)。另一种方案是两张表。最后还是决定对于每个会议建了两张表,一张主表存一对一信息(id为主键),另一张表存id对应的所有关键词(id为外键)。
设计实现过程
1.后台数据管理:
论文与关键词是一对多关系,所以需要两张表:表一包含编号、题目、摘要、原文链接、年份,表二包含编号、关键词。依照数据库的设计原则,这种方式可以避免冗余。后端代码中一个Dao接口服务一个Controller,将单个Controller的所有数据库操作封装到唯一的Dao中,调用的时候不易混乱。
2.后端框架选择:
后端使用springboot框架。由于集成了spring和mybatis,编程时能更多地集中于与需求相关的实现上,像数据库连接关闭、解析前端请求和给前端返回数据都,这些都只要通过简单的注释就能解决。实现逻辑放在Controller下,数据库相关操作放在Dao层,对象模型放在model,三者分离开有利于debug和后期维护。
3. 前端总体
前端使用Vue框架,使用了axios、echarts、view-design、vue-router、vue-woedcloud、vuescroll、vuex插件。
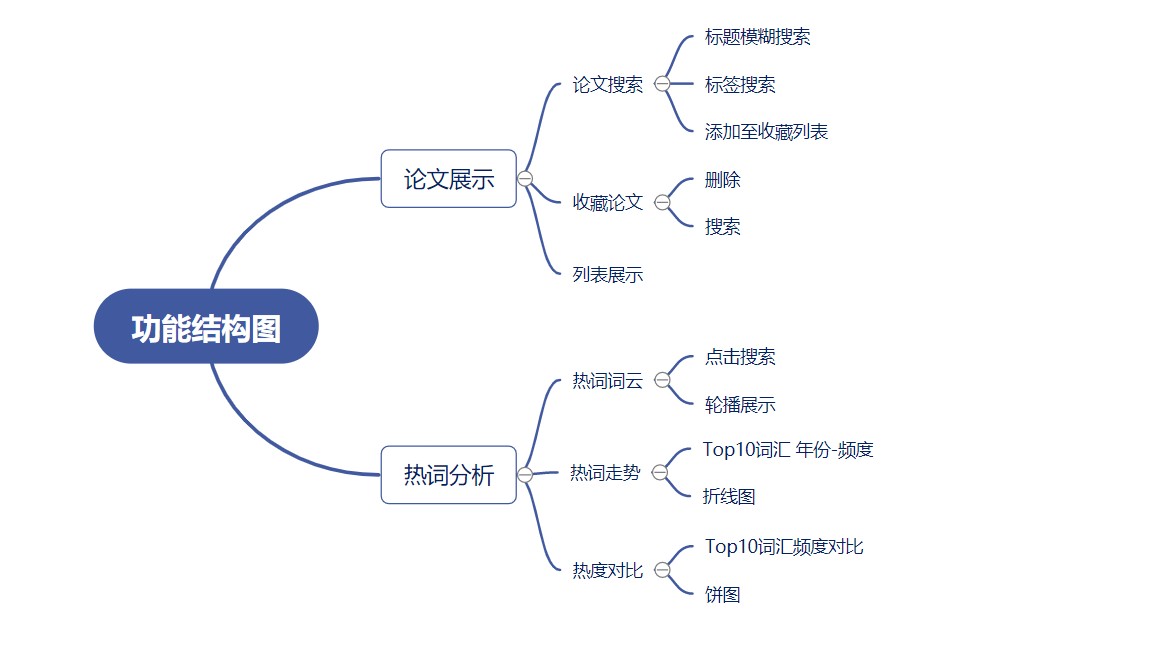
功能结构图
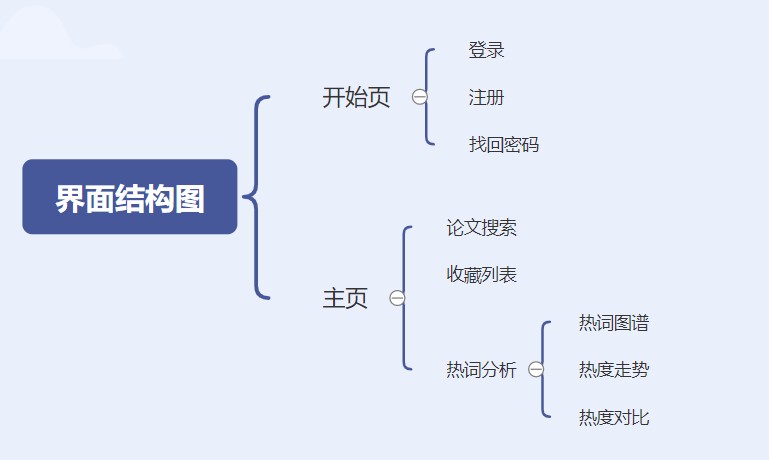
界面结构图
设计概述
1.登录
- 前端参数:用户输入账号、密码,账号密码打包成JSONObject,传给后端验证。
- 后端处理:查看数据库里已有的账号密码,看是否有完全匹配的元组。
- 后端返回值:返回一个status和一个验证结果。(status为状态码)
- 登陆后,主页为侧边导航菜单以及主面板构成,共有5个界面分别为:论文搜索 、本地收藏、热词图谱、热度走势、热度对比。
2.论文搜索
- 前端布局:搜索结果在搜索框下,是一个无限滚动的论文列表。每个论文项带有题目、编号、摘要、原文链接、年份和关键词。
- 前端参数:用户在搜索框搜索题目或者题目的一部分,title作为给后端的参数。
- 后端处理:将title作为查询条件,查询对应论文的所有信息。
- 后端返回值:后端经过模糊匹配(可以通过数据库的模糊匹配实现),返回给前端一个JSONArray,内部包含多个JSONObject,每个JSONObject是一篇论文的所有信息。
3.本地收藏按钮
- 前端参数:被收藏的论文的所有信息。
- 后端处理:将收藏论文插入数据库表。
4.论文删除
- 前端参数:前端提供论文id。
- 后端处理:将对应论文从数据库删除。
5.论文本地查找
- 前端布局:和论文搜索界面相似,多了一个关键词搜索
- 前端参数:如果是模糊搜索则参数名为fuzzyTitle,如果是关键词搜索参数名为keyword,调用的后端接口不同。
- 后端处理:用子查询的方式查询两个表。
- 后端返回值:返回论文列表,是一个JSONArray类型的数据。
6.top10热词(用于关键词图谱)
- 前端界面:关键词云图,支持点击跳出相应论文。分别由三张云图,对应三个会议,以轮播图的形式展现。
- 后端处理:借助单词统计的算法实现,统计所有关键词的频度。
- 后端返回值:返回top10热词及其频度。
7.关键词走势
- 前端界面:热度走势为Top10的每个热词的不同年份与出现频数的折线图。用户易于看出近期热词。
- 后端处理:对top10的关键词查询数据库,按年份统计出现次数。
- 后端返回值:年份横坐标,出现频度纵坐标,都为JSONArray。
8.top10热词的饼图
- 前端界面:展示top10热词各自的占比,有助于用户了解长期以来热度较高的词。
代码说明
前端代码
图表组件及其复用
使用props向写好的图表组件传入数据,进行渲染,实现复用
图表主要使用
echarts组件实现折线图与饼图使用
vue-wordcloud实现词云图
<div id="myChart2"></div>
// data部分
data () {
return {
data1: [5, 10, 12, 69, 25, 14, 18, 55, 47, 33],
data2: ['key1', 'key2', 'key3', 'key4', 'key5', 'key6', 'key7', 'key8', 'key9', 'key10'],
datat: [],
color: ['#349dff', '#fbd438', '#33c45e', '#f2637b', '#6dd48c', '#fbd437', '#4ecb73', '#eaa674', '#88d1ea', '#36cbcb']
}
// 渲染折线图的代码
drawLine () {
this.chartLine = echarts.init(document.getElementById('myChart2'))
const option = {
tooltip: { // 设置tip提示
formatter: '{a}<br/>{b}:{c} ({d}%)'
},
legend: { // 设置区分(哪条线属于什么)
y: 'bottom',
x: 'center',
data: this.data2
},
color: this.color, // 设置区分(每条线是什么颜色,和 legend 一一对应)
series: [
{
name: '出现次数',
data: this.datat,
type: 'pie'
// radius: ['50%', '70%']
// center: ['50%', '50%']
}
]
}
// 使用刚指定的配置项和数据显示图表。
this.chartLine.setOption(option)
},
论文列表的展示:调用接口后传来的数据存在一个数组变量中,使用
vue的方法v-for对这个数组中的数据遍历展示
<div class="recordItem" v-for="(item,index) in searchResult" :key="index">
<div class="recordTitle">{{item.title}}</div>
<div class="recordCode"><span>论文编号:</span>{{item.number}}</div>
<div class="recordTag">
<span v-for="(item1,index1) in item.keyword.slice(0,3)" :key="index1">{{item1}}</span>
</div>
<div class="recordContent"><span>摘要内容:</span>{{item.abstract}}</div>
<div class="recordAddress">
<div @click="copy(item.link)">复制原文地址</div>
</div>
<div class="opeBtn">
<!-- <Button shape="circle" icon="ios-create-outline"></Button>-->
<Button shape="circle" icon="ios-trash-outline" @click="myDelete(item)"></Button>
</div>
</div>
前端接口调用,使用的是axios。封装axis。
this.$axios.post('http://localhost:8081/PaperOperationController/fuzzyQuery', {
fuzzyTitle: this.searchContent
})
.then(res => {
this.searchResult = res.data.result
this.totle = res.data.item_num
this.showResult = this.searchResult.slice(0, 10)
})
.catch(err => {
console.log(err)
})
.finally({
})
后端代码
1.论文title的模糊查询:为了将数据区分开,保证论文id的唯一性,三个会议分别建了2个表。所以下面的模糊查询需要针对不同的的会议数据库表查询,index = 0,1,2分别代表三个会议。模糊查询的本质是数据库的LIKE模糊查询。先通过题目查询论文id及其他信息,再通过论文id查询关键词。
public int queryPaper(JSONArray result,int index,String fuzzyTitle,int itemNum){
List<Conference> conferenceList = null;
if(index == 0){
conferenceList = paperOperationDao.getCvpr(fuzzyTitle);
}else if(index == 1){
conferenceList = paperOperationDao.getEccv(fuzzyTitle);
}else if(index == 2){
conferenceList = paperOperationDao.getIccv(fuzzyTitle);
}
for (int j = 0; j < conferenceList.size(); j++) {
Conference conference = conferenceList.get(j);
JSONObject paperInfo = new JSONObject();
paperInfo.put("title", conference.getTitle());
paperInfo.put("number", conference.getNumber());
paperInfo.put("abstract", conference.getPaperabstract());
paperInfo.put("link", conference.getLink());
paperInfo.put("year", conference.getYear());
paperInfo.put("type",type[index]);
List<ConferenceKwd> conferenceKwdList = null;
if(index == 0){
conferenceKwdList = paperOperationDao.getCvprKwd(conference.getNumber());
}else if(index == 1){
conferenceKwdList = paperOperationDao.getEccvKwd(conference.getNumber());
}else if(index == 2){
conferenceKwdList = paperOperationDao.getIccvKwd(conference.getNumber());
}
JSONArray keywordArray = new JSONArray();
for (int k = 0; k < conferenceKwdList.size(); k++) {
ConferenceKwd conferenceKwd = conferenceKwdList.get(k);
keywordArray.add(conferenceKwd.getKeyword());
}
paperInfo.put("keyword", keywordArray);
result.add(paperInfo);
itemNum++;
}
return itemNum;
}
2.基于论文关键词的查询:论文关键词查询和模糊查询方法区别不大。先用关键词查找id,再通过id查找论文的所有信息。代码类似,就不展示了。
3.生成关键词图谱的热词:前端需要top10热词以及热词在图谱中的字体大小,后端用随机数对热词字体进行变化,界面展示的时候会更美观。
public JSONArray getWordMap(){
Random random = new Random();
JSONArray map = new JSONArray();
JSONObject result = getHotWords();
JSONArray hotWords = result.getJSONArray("hotWord");
for(int i = 0;i < hotWords.size();i++){
JSONObject jsonObject = new JSONObject();
jsonObject.put("name",hotWords.get(i));
jsonObject.put("value",random.nextInt(16)+12);
map.add(jsonObject);
}
return map;
}
4.单个热词的走势:用一个数组保存关键词2000~2007年的频率。前端需要的用echarts绘制折线图,所以返回两个数组,分别表示横纵坐标。
public JSONObject getTrend(@RequestBody JSONObject request){
String keyword = request.getString("keyword");
int[] frequency = new int[8];
for(int i = 0;i < frequency.length;i++){
frequency[i] = 0;
}
JSONObject trend = new JSONObject();
JSONArray horizontal = new JSONArray();
JSONArray vertical = new JSONArray();
for(int i = 0;i < 3;i++){
List<ConferenceKwd> conferenceKwdList = null;
if(i == 0){
conferenceKwdList = keywordTrendDao.getCvprKwd(keyword);
}else if(i == 1){
conferenceKwdList = keywordTrendDao.getEccvKwd(keyword);
}else if(i == 2){
conferenceKwdList = keywordTrendDao.getIccvKwd(keyword);
}
for(int j = 0;j < conferenceKwdList.size();j++){
ConferenceKwd conferenceKwd = conferenceKwdList.get(j);
int number = conferenceKwd.getNumber();
List<String> yearList = null;
if(i == 0){
yearList = keywordTrendDao.getCvprYear(number);
}else if(i == 1){
yearList = keywordTrendDao.getEccvYear(number);
}else if(i == 2){
yearList = keywordTrendDao.getIccvYear(number);
}
String year = yearList.get(0);
String lastCharacter = year.substring(year.length() - 1);
int index = Integer.parseInt(lastCharacter);
frequency[index]++;
}
}
for(int i = 0;i < frequency.length;i++){
horizontal.add(2000+i);
vertical.add(frequency[i]);
}
trend.put("year",horizontal);
trend.put("frequency",vertical);
return trend;
}
5.获取top10热词及其对应频率:这项功能涉及到单词的统计。为提高效率,加快统计速度,将HashMap作为从关键词映射到频率的数据结构。HashMap本身不具有排序功能,所以需要把关键词和频率封装到类Word,放在TreeSet排序。具体实现步骤:select所有关键词--》插入HashMap--》插入TreeSet。
public JSONObject getHotWords(){
Map<String, Integer> map = new HashMap<>();
Set<Word> set = new TreeSet<>();
for(int i = 0;i < 3;i++) {
List<ConferenceKwd> conferenceKwdList = null;
if(i == 0){
conferenceKwdList = hotWordFrequencyDao.getCvprKwd();
}else if(i == 1){
conferenceKwdList = hotWordFrequencyDao.getEccvKwd();
}else if(i == 2){
conferenceKwdList = hotWordFrequencyDao.getIccvKwd();
}
for (int j = 0; j < conferenceKwdList.size(); j++) {
ConferenceKwd conferenceKwd = conferenceKwdList.get(j);
wordToHashMap(conferenceKwd.getKeyword(), map);
}
}
return frequency(set,map);
}
心路历程和收获
hj:整个过程还是比较曲折的。为了确定数据库表,对表结构进行了两次修改,因此数据反复导入花了不少时间。最开始编码的时候,第一次使用springboot框架,改配置和debug也挺困难。后期逐渐熟练,慢慢对springboot有了整体的理解。总的来说收获颇丰,学会了应用新框架,学会了借助官方文档和demo入手新知识,学会了写接口文档,github管理版本的操作也更熟练。经验教训也没比学到的知识少:短时间开发尽量选择自己使用过的框架或工具,避免开发效率低;数据库对编码和类结构设计的影响极大,宁可多花些时间在数据库表设计。
ch:刚看到作业时是比较焦虑的,因为我不仅有这一项作业,还多出上学期生病拉下的缓考,幸好延迟了时间。我在此之前已经有过相应的项目经历,但由于较久没有接触并且没有尝试过快速的,从0开始的两个人以结对的形式共同完成的方式。还是有一段适应期。慢慢地就和队友磨合好了。在写代码这一块,我主要在图表生成与前后端数据格式要求上遇到较大问题,但在多次的沟通以及查询资料后逐个解决了。
评价结对队友
hj:在前端方面ch算是我们当中的专家了,所以和他合作起来很轻松。前后端交互测试的时候,前端基本没bug,很快就完成衔接完了。另外,ch还是个做事精益求精的人,如果界面布局不够美观或者功能展示不够合理,ch会再三考虑并给出可行的方案,并且短时间内完成代码修改,效率很高。ch解决了很多前端技术上的难题,是学习能力很强的队友,是最佳的partner。
ch:hj是一个认真,有干劲的队友。对项目的布局、进度都有较好的安排。他很努力的进行相关知识的学习。打代码也很勤奋,带动我一起认真对待。我们磨合的十分顺利,很高心能跟hj同学合作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号