HashMap源码解析:属性字段以及构造器
HashMap源码解析
1. 什么是HashMap
HashMap是一个利用Hash表原理来存储元素的集合。遇到冲突的时候,HashMap采用的链地址法来解决。
hash表经常伴随着冲突问题,解决冲突问题通常有两种做法:
- 开放地址法:当发生冲突的时候,可以简单的将冲突的字段放在下一个位置。这种方法可能会遇到二次冲突,三次冲突,需要良好的散列函数,分布越均匀越好。
- 链地址法:可以hash表中的每一个元素看作一个数组或者一个链表,当发生冲突的时候直接往子链表填充就可以了,进行查找的时候,可能需要遍历子数组或者子链表。这种方法虽然不会造成二次冲突,但是如果一次冲突很多,那么会造成子数组很长或者子链表很长,查找所需要遍历的时间也很长。
在jdk 1.7中HashMap是通过数组+链表构成的,但是在JDK1.8中HashMap是由数组+链表+红黑树构成,新增了红黑树作为底层结构,结构变得复杂了,但是效率变得更加高效。
2. HashMap的定义
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
... ...
}

2.1 AbstractMap和Map
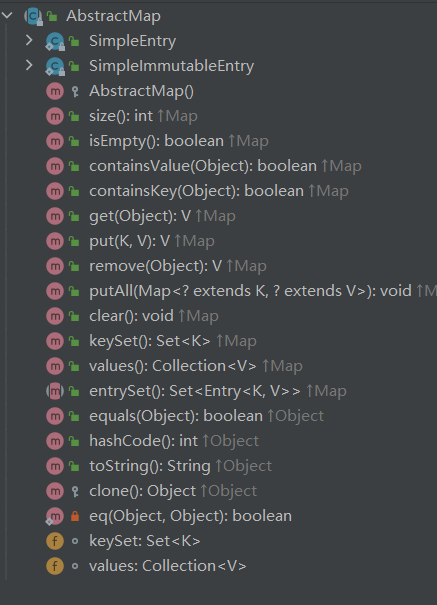
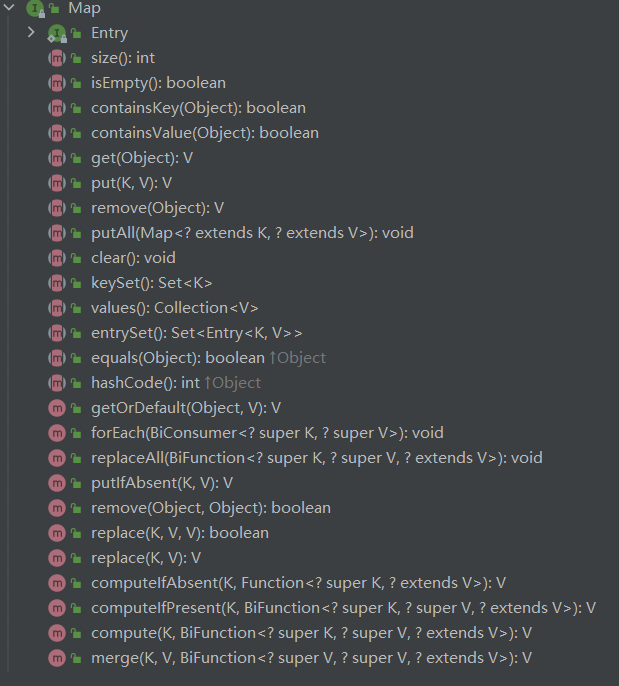
首先该类实现了一个Map接口,该接口定义了一组键值对映射通用的操作。存储成对的键值对象,提供key到value的映射,Map中Key不要求有序,但是不允许重复。value同样不要求有序,但是允许重复,接口方法很多,在实现某个键值对集合不需要那么多方法,所以就提供了抽象类AbstractMap。
AbstractMap继承了Map接口,所以如果不想实现所有的Map方法,可以尝试继承抽象类AbstractMap。
但是HashMap类通过继承了AbstractMap也实现了Map接口,这样做可以说是多此一举。
2.2 Cloneable, Serializable
HashMap集合还实现了Cloneable, Serializable分别表示对象可克隆,以及序列化。
3. HashMap的字段属性
//序列化和反序列化的时候,通过该字段进行版本一致验证
private static final long serialVersionUID = 362498820763181265L;
//默认HashMap集合初始容量为16(必须是2的倍数????)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//集合的最大容量,如果通过带参数构造器指定的最大容量超过此数值,默认还是使用此数值
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//-------------------------------红黑树和链表的相互转换--------------------------------------
// 当桶上的节点大于这个值的时候会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶上的节点小于这个值的时候会转化成链表
static final int UNTREEIFY_THRESHOLD = 6;
// 当集合中的容量大于这个值的时候,表中的桶才能进行树形化,否则桶内元素太多的时候会扩容。
static final int MIN_TREEIFY_CAPACITY = 64;
//--------------------------------------------------------------------------------------
//初始化使用,长度总是2的幂,hash数组是由数组+链表+红黑树组成,这个Node[]就是指的是数组的部分,对其进行初始化长度为DEFAULT_INITIAL_CAPACITY=16
transient Node<K,V>[] table;
//保存缓存的entrySet
transient Set<Map.Entry<K,V>> entrySet;
//此映射中包含的键值映射的数量,集合中存储键值对的数量
transient int size;
//用于记录集合被修改的次数,用于迭代器的快速失败
transient int modCount;
//调整下一个值的大小(容量*加载因子)capacity*load factor,通过公式计算可以得出,threshold是size的最大值,size超过threshold就应该扩容
int threshold;
//散列表的装载因子,默认值为DEFAULT_LOAD_FACTOR= 0.75f,用来衡量HashMap满的程度,计算HashMap的实时装载因子的方法为size/capacity,而不是用占用桶的数量去除以capacity,capacity表示桶的数量,也就是table的长度length,装载因子0.75是对空间和效率的一个平衡选择,装载因子越小,对应的消耗的内存空间越大,效率越高。装载因子越大,消耗的内存空间越小,效率越低。
// 我是这样理解的,内存中一般存储的是hash表的table,每个桶内存储的是链表或者树的引用。当装载因子小的时候,桶的数量变多,桶的深度变小就导致效率变高,但是内存占用大
final float loadFactor;
4. 构造函数
4.1 默认无参构造器
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
默认的无参数构造器只做了一件事,初始化负载因子。
4.2 指定初始容量和加载因子的构造函数
public HashMap(int initialCapacity) {
//指向另外一个构造函数
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {// 传入初始容量和加载因子
//初始容量不能小于0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
//初始容量不能大于MAXIMUM_CAPACITY,最大容量只能到MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//加载因子不能小于或为0,且加载因子不能是非数值
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 设置加载因子和初始容量
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
返回大于或者等于initialCapacity的最小二次幂的值,算法比较精妙
static final int tableSizeFor(int cap) {
int n = cap - 1;//如果本身就是二次幂,则通过这个函数,值不变
n |= n >>> 1;//>>>无符号右移高位取0, |按位或
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
//这个算法不断地把第一个1后面的位全部变成1。由00..01XXXXXXX —> 00..011111111,最后再返回n+1(2的幂次方);
return (n < 0)
? 1
: (n >= MAXIMUM_CAPACITY)
? MAXIMUM_CAPACITY
: n + 1;
}
4.3 传入Map的构造函数
public HashMap(Map<? extends K, ? extends V> m) {、
//设置默认的加载因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
将map中的数据放入集合中,putMapEntries方法的详解可以看看这个(27条消息) JDK8 HashMap源码 putMapEntries解析_anlian523的博客-CSDN博客
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();//获取传入map的大小
if (s > 0) {
if (table == null) { // pre-size
//算出一个当前应该匹配的CAPACITY,+1是为了向上取整
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY)
?(int)ft
: MAXIMUM_CAPACITY);
//更新阈值,因为所有的桶都是深度为1的,也就是capcity==threshold==size
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)// 当size大于threshold,需要扩容
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {//遍历map将值放入集合中
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号