存储过程 Row_number() 分页
---恢复内容开始---
自己之前一直是使用的通用的存储过程 ,也是封装好的只要传表名 + 条件 等等
来到新环境 让自己写一个存储过程, 没办法 自己就需要写一个咯 之前写的比较多的是 按 top 来分页 现在公司要求是使用Row_number 当然 后者效率还是高一点 。至于索引什么的 暂时还没有用到 (有什么需求 现学也是可以的)其中也有 with(nolock) 但是会容易造成数据脏读。如果你有用到索引 或者你想看到你的语句查询开销 你可以使用(ctrl+M)键调执行计划。至于你看到这些占用啥的 聚集索引什么的,懵了? 那就请你移驾自行查找(自己没有太懂,所以就不在这里板门弄斧了)。
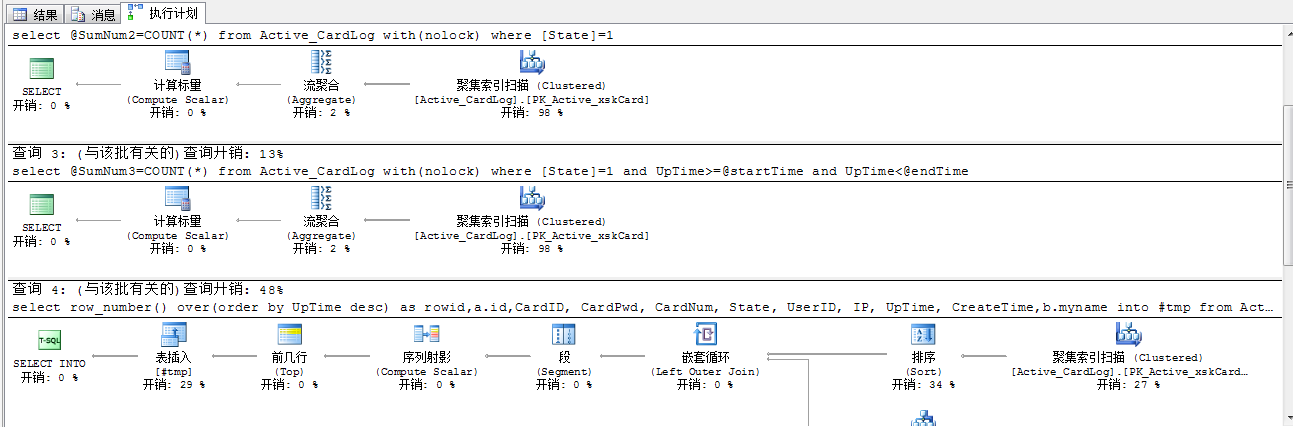
1 USE [JHMinGameDB] 2 GO 3 SET ANSI_NULLS ON 4 GO 5 6 SET QUOTED_IDENTIFIER ON 7 GO 8 -- ============================================= 9 -- Author: yanyunhai 10 -- Create date: 2016-04-13 11 -- Description: 新手送豆 12 -- ============================================= 13 CREATE PROCEDURE [dbo].[Web_Active_Buyu_CardLog_page] --创建该存储过程名字(如已经存在 要改的时候就把 create 变成 Alter) 14 @State int, 15 @startTime datetime, 16 @endTime datetime, 17 @pageSize int, 18 @pageIndex int, 19 @recd int output,--输出参数 20 @totalpeas int output --输出参数 21 22 AS 23 set @recd=0 --赋值为0是避免查询结果为0 时 显示为null 24 set @totalpeas=0 25 Declare @recdst int=0,@recdend int=0 --@recdst起始条数 26 Set @recdst=@pageSize * (@pageIndex-1)+1 -- @recdend 结束条数 27 Set @recdend=@pageSize + @recdst-1 28 BEGIN 29 --在对于时间判断时建议 少用 between and 因为 0:00-23:59 30 declare @SumNum1 int,@SumNum2 int,@SumNum3 int 31 select @SumNum1=COUNT(*) from Active_CardLog with(nolock) where [State]=0 32 select @SumNum2=COUNT(*) from Active_CardLog with(nolock) where [State]=1 33 select @SumNum3=COUNT(*) from Active_CardLog with(nolock) where [State]=1 and UpTime>=@startTime and UpTime<@endTime 34 35 if @State>=0 36 begin 37 select row_number() over(order by UpTime desc) as rowid,a.id,CardID, CardPwd, CardNum, State, UserID, IP, UpTime, CreateTime,b.myname into #tmp from Active_CardLog a 38 left join JH_member b on b.idx=a.UserID 39 where State=@State --and UpTime>=@startTime and UpTime<@endTime 40 41 select @totalpeas=isnull(SUM(CardNum),0),@recd=count(1) from #tmp 42 select rowid,CardID, CardPwd, CardNum, State, UserID, IP, UpTime, CreateTime,myname,@totalpeas sumnum,@recd sumRowID,@SumNum1 SumNum1,@SumNum2 SumNum2,@SumNum3 SumNum3 from #tmp 43 where rowid between @recdst and @recdend --根据rowid 来确定显示区间 44 drop table #tmp 45 end 46 else if @State<0 47 begin 48 select row_number() over(order by UpTime desc) as rowid,a.id,CardID, CardPwd, CardNum, State, UserID, 49 IP, UpTime, CreateTime,b.myname into #temp from Active_CardLog a 50 left join JH_member b on b.idx=a.UserID 51 where UpTime>=@startTime and UpTime<@endTime 52 53 select @totalpeas=isnull(SUM(CardNum),0),@recd=count(1) from #temp 54 where rowid between @recdst and @recdend --根据rowid 来确定显示区间 55 drop table #temp 56 end 57 END 58 --其实上问可以用不用判断也可以解决这个问题 那就是用 where(([State]=2)or([State]=@state)) 59 --有人在使用时 会出现 Rowid 报错?自己找找子查询 60 GO
——————– with (nolock)—-数据多的时候可以《索引之后的选择》—————–
使用情况: 当我们在下SQL Command时,在语法中加一段WITH (NOLOCK)可以改善在线大量查询的环境中数据集被LOCK的现象藉此改善查询的效能。
不过有一点千万要注意的就是,WITH (NOLOCK)的SQL SELECT有可能会造成数据脏读。
用法:select * from table with(nolock) left join table with(nolock) 表名后面接上 with (nolock)
注意事项:①也就是说当使用NoLock时,它允许阅读那些已经修改但是还没有交易完成的数据。因此如果有需要考虑transaction事务数据的实时完整性时,使用WITH (NOLOCK)就要好好考虑一下
②:with(nolock)的写法非常容易再指定索引。
跨服务器查询语句时 不能用with (nolock) 只能用nolock
同一个服务器查询时 则with (nolock)和nolock都可以用
比如:
select * from [IP].a.dbo.table1 with (nolock) 这样会提示用错误
select * from a.dbo.table1 with (nolock) 这样就可以
当然 你也可以看看 over() 开窗函数
其中的一些东西也是看前一任 程序员写的, 然后就有在园子里面看看介绍。 自己摘了一部分 因为看别人的东西的时候也没有做到用怀疑的态度去看 去分析 所以贴出来 。如果你看到以后有错误 有误区 欢迎指正!!
对你的能力是一次证明, 对我是一次帮助。 虚心求学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号