逆向基础知识-汇编和PE文件
汇编基础知识
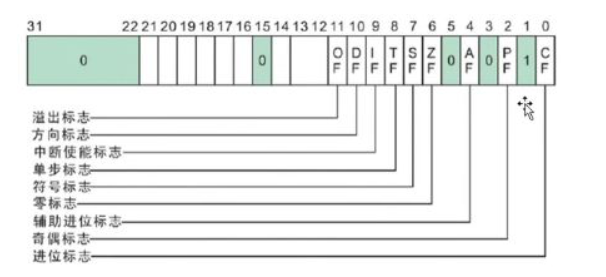
1. 九个寄存器(32位)
寄存器 编号
eax:累加器(accumulator), 它是很多加法乘法指令的缺省寄存器。 0
ecx:计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。 1
edx:总是被用来放整数除法产生的余数。 2
ebx:"基地址"(base)寄存器, 在内存寻址时存放基地址。 3
esp:存储堆栈的最顶端 4
EBP:是"基址指针",不是必须的 5
esi: 6
edi:变址寄存器,主要用于存放存储单元在段内的偏移量,作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。它们可作一般的存储器指针使用。 7
eip:存储当前CPU马上要执行的指令
寄存器32位可以拆分为两个16位寄存器 eax拆分成ax(低16位) ax还可以拆分为ah(高位)和al(低位)
2. 八个标志位
CF(进位标志位):运算时最高位产生进位或借位时为1 # 针对无符号数的运算
ZF(零标志位):若当前运算结果为0,标志位为1 xor eax,eax ZF置1 mov eax,0 不会修改标志位的值
SF(符号标志位):该标志位与运算结果二进制的最高位相同,运算结果为负,则标志位为1
OF(溢出标志位):如果运算结果超过了机器能表示的范围则标志位为1 # 针对有符号数的运算 正+正=负 / 负+负=正 表示溢出
符号位有进位:1,最高有效位有进位:1 最终OF位为1 xor 1 = 0 (计组的溢出判断)
PF(奇偶标志位):运算结果的最低有效字节中(即低八位)含1的个数为偶数则标志位为1
AF(辅助进位标志):运算结果的低4位向高4位有进位或借位时为1
次要
TF(跟踪标志):为方便程序调试而设置,若TF=1,则CPU处于单步工作方式,在每条指令结束后产生中断
DF(方向标志位):用来控制串处理指令(movsd)的处理方向,DF为1则串处理过程中地址自动递减,否则自动递增
溢出判断🚩
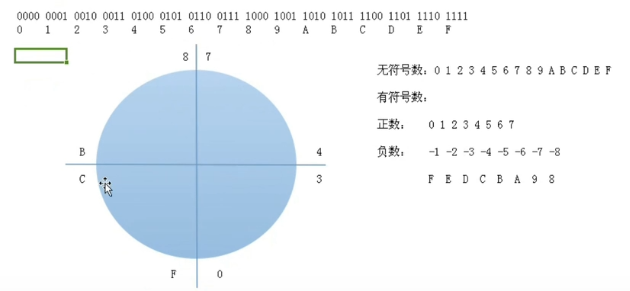
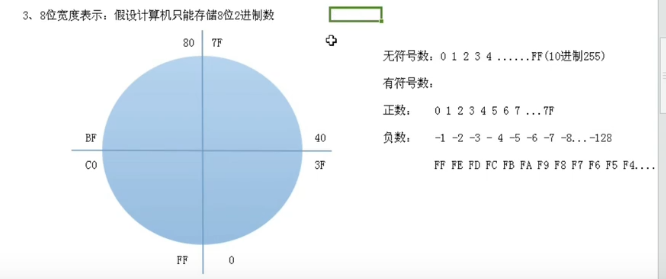
1.无符号,有符号都不溢出 al为8位 无符号超过ff溢出,CF位为1 有符号数两个小于7f的结果超过7f溢出,OF位为1
mov al,8
add al,8
2.无符号溢出,有符号不溢出 当成有符号数后 ff为负数,正数+负数当然不会溢出
mov al,0ff
add al,2
3.无符号不溢出,有符号溢出 有符号数 7f + 2 = 81 两个整数相加结果为负数 所以溢出
mov al,7f
add al,2
4.无符号,有符号都溢出 两个正数相加成了负数
mov al,0FE
add al,80
3. 汇编指令
对寄存器进行操作比较简单
mov eax,0x1 --将1存入eax add eax,0x2 --eax+2存入eax 注意前后两个操作数不可同时为内存单元
对内存进行操作要给出所占内存的空间 word---16位 dword---32位
mov word ptr ds:[0x12345678],0x1234 --ds:为段寄存器,将1234写入内存地址为0x12345678(内存编号-32位)的位置
LEA eax,dword ptr ds:[0x10ffcc] --将ds所指的地址编号(10ffcc)取出存入到寄存器eax中
内存寻址方式
1.直接寻址:mov word ptr ds:[0x12345678],0x1234
2.寄存器寻址:mov ecx,12345678 mov eax,dword ptr ds:[ecx] --先将地址存到寄存器里,然后利用寄存器寻址找到内存地址
3.寄存器+立即数
mov ecx,12345678 mov eax,dword ptr ds:[ecx+4] --将ecx所存地址+4后的内存单元的值存到eax里
mov ecx,12345678 lea eax,dword ptr ds:[ecx+4] --将ecx所存地址+4的内存地址存到eax里
4.[reg+reg*{1,2,4,8}]
mov eax,13ffc4 move ecx,2 mov edx,dword ptr ds:[eax+ecx*4]
5.[reg+reg*{1,2,4,8}+立即数]
mov eax,13ffc4 move ecx,2 mov edx,dword ptr ds:[eax+ecx*4+8]
读取堆栈的数据 --两种方式
1、base加偏移 栈底为高地址
读第一个压入的数据:mov esi,dword ptr ds:[ebx-4]
读第四个压入的数据:mov esi,dword ptr ds:[ebx-0x10]
2.top加偏移 栈顶为低地址
读第二个压入的数据:mov edi,dword ptr ds:[edx+8]
读第三个压入的数据:mov edi,dword ptr ds:[edx+4]
入栈(edx为栈顶,ebx为栈底) 以下三种方式都可以(往往会把push pop 隐藏,要学会看这些识别)
1.sub edx,4 mov dword ptr ds:[edx],0x11111111
2.mov dword ptr ds:[edx-4],0x11111111 sub edx,4
3.lea edx,dword ptr ds:[edx-4] mov dowrd ptr ds:[edx],0x11111111
系统默认栈中esp为栈顶,ebp为栈底
push 0x12345678 --将12345678入栈,同时将top-4
push ax --将寄存器ax的值入栈,top-2 (不可push进8位的)
出栈操作: 以下都可以
1.mov eax,dword ptr ds:[edx] add edx,4
2.lea edx,dword ptr ds:[edx+4] mov eax,dword ptr ds:[edx-4]
pop eax --栈顶出栈,将出栈的元素存到eax里
pop ax --栈顶出栈,将出栈元素的低16位存进ax里
pushad --将八个通用寄存器的值全部存入堆栈,先存eax, esp和ebp不要修改,系统分配的
popad --将堆栈中八个值出栈,存入八个通用寄存器中
其他指令
xor eax,eax --将eax置零
adc R/M,R/M/IMM 带进位加法,结果加上CF位 两边不能同时为内存 R为寄存器,M为内存,IMM为立即数
sbb R/M,R/M/IMM 带借位减法,结果减去CF位 两边不能同时为内存
xchg R/M,R/M 交换数据,不能出现立即数
movs指令 --用于在内存与内存之间移动数据 很有可能是一段字符串的复制
mov edi,0x11111 mov esi,0x11112 --先指定两个变址寄存器的地址
movs dword ptr es:[edi],dword ptr ds:[esi] --在内存与内存间移动数据 简写为movsd 移动四个字节
movs word ptr es:[edi],dword ptr ds:[esi] --简写为movsw 移动两个字节
注意:DF位为0,移动完后esi和edi存的地址编号都会同时加4/2 DF位为1,移动后esi和edi所存的地址同时减4或2
stos指令 --置数,大小由前面的 dword/word/byte决定
stos dword/word/byte ptr es:[edi] 将eax/ax/al的值存储到[edi]指定的内存单元,简写为stosd,移动后同样地址会改变
注意:当出现edi时 段寄存器往往用es
mov ecx,10(ecx中存储操作要重复的次数)
rep movsd --重复执行从esi先edi移动的指令16次,由于edi和esi执行完后会自动 +4 或者 -4
rep stosd
修改eip不可用mov:可用以下指令
1.格式:jmp reg/imm jmp 0x123456 当跳转的位置距离当前小于128个字节 最终指令为:jmp short 0x123456
jmp的作用,修改eip,然后cpu按eip执行对应地址
2.call 0x123456 注意要在call后的地址下断点 call后esp会减4,将call的返回地址的下一地址压栈(call地址+硬编码)
retn call后要返回 相当于pop eip,esp会加4 ret 8 --两条指令,一个rtn,一个esp+8
比较指令
cmp R/M,R/M/IMM 比较两个操作数,实际上相当于sub指令,只是相减的结果不保存在第一个操作数中,根据相减的结果改变零标志位,当两个操作数相等时,零标志位置1,只改变ZF标志位,当相减结果小于0时,符号标志位SF变为1
test R/M,R/M/IMM,一定程度上与cmp相似,两个数进行与操作,结果不保存,但是会改变相应的标志位
常用于判断一个数是否为空,若为空,自身相与之后仍未空
移位指令
SAL/SAR Reg/Mem,CL/IMM --算术左移/右移, 10000001右移1位 1100 0000
正数,三码相同,所以无论左移还是右移都是补0.而负数的补码就需要注意,左移在右边补0,右移需要在左边补1
SHL/SHR Reg/Mem,CL/IMM --逻辑左移/右移
## C语言中往左移有无符号没有区别,往右移需要注意符号位
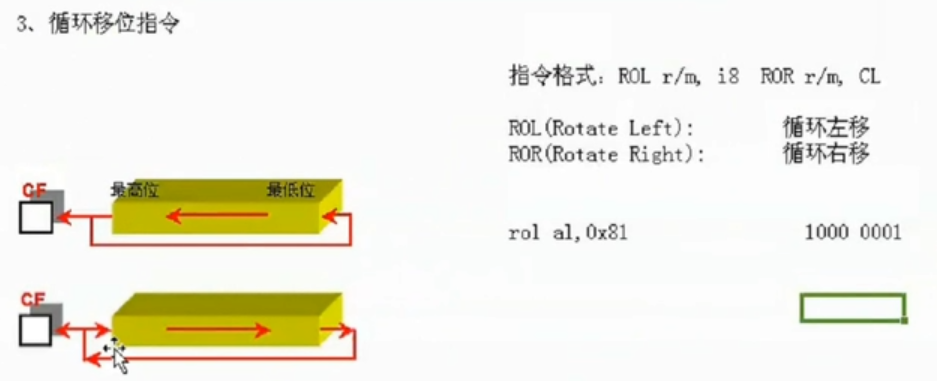
ROL/ROR Reg/Mem,CL/IMM --循环左移/右移 算术右移会将右边溢出的位移到左边的新的位,CF与溢出的为一样 rotate
RCL/RCR Reg/Mem,CL/IMM --带进位左移/右移 把CF位当做自己的一部分

| JCC指令 | 中文含义 | 检查符号位 |
|---|---|---|
| JZ/JE | 若为0则跳转;若相等则跳转 | ZF=1 |
| JNZ/JNE | 若不为0则跳转;若不相等则跳转 | ZF=0 |
| JS | 若为负则跳转 | SF=1 |
| JNS | 若为正则跳转 | SF=0 |
| JP/JPE | 若1出现次数为偶数则跳转 | PF=1 |
| JNP/JPO | 若1出现次数为奇数则跳转 | PF=0 |
| JO | 若溢出则跳转 | OF=1 |
| JNO | 若无溢出则跳转 | OF=0 |
| JC/JB/JNAE(无符号数) | 若进位则跳转;若低于则跳转;若不高于等于则跳转 | CF=1 |
| JNC/JNB/JAE(无符号数) | 若无进位则跳转;若不低于则跳转;若高于等于则跳转; | CF=0 |
| JBE/JNA(无符号数) | 若低于等于则跳转;若不高于则跳转 | ZF=1或CF=1 |
| JNBE/JA(无符号数) | 若不低于等于则跳转;若高于则跳转 | ZF=0或CF=0 |
| JL/JNGE(有符号数) | 若小于则跳转;若不大于等于则跳转 | SF != OF |
| JNL/JGE(有符号数) | 若不小于则跳转;若大于等于则跳转; | SF = OF |
| JLE/JNG(有符号数) | 若小于等于则跳转;若不大于则跳转 | SF != OF 或 ZF=1 |
| JNLE/JG(有符号数) | 若不小于等于则跳转;若大于则跳转 | SF=0F 且 ZF=0 |
4. 堆栈图
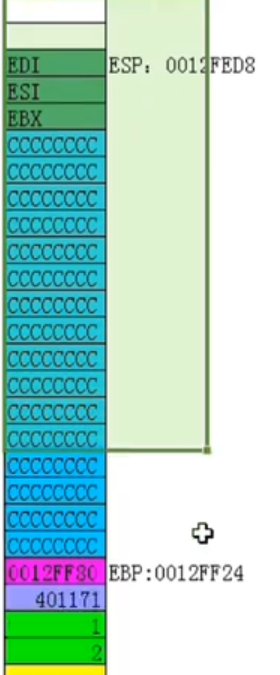
首先将函数调用所用到的参数压栈,然后call语句执行后首先将返回的地址压栈,之后会开辟出一段缓冲区用于存储局部变量,一般会将缓冲区的垃圾数据全部初始化为相同的数,mov eax,0xCCCCCCCC rep stosd --用于初始化缓冲区
在函数外(return后)原来的地址进行平衡堆栈(使esp和ebp指向同一地址),将参数出栈 --称为外平栈 add exp,0x8(由参数个数决定)
5. C语言与汇编
1、C语言中定义一个没有任何操作的函数,在编译时仍会生成固定的出入栈操作的汇编代码,若不想生成,可定义裸函数
int __declspec(naked) plus(){
__asm{
//在函数调用之前会先push 1 push 2(传参数) call后会执行 push 返回地址
//保留调用前的栈底
push ebp
//提升堆栈
mov ebp,esp
sub esp,0x40
//保留现场
push ebx
push esi
push edi
//填充缓冲区 主要用于存储函数的局部变量
mov eax,0xcccccccc
mov ecx,0x10 // 之所以是10 是因为之前提升堆栈0x40 / 4 = 10 栈一个格四个字节
lea edi,dword ptr ds:[ebp-0x40]
rep stosd //每次填充四个字节,重复16次
//函数的核心功能
mov eax,dword ptr ds:[ebp+0x8] //把第一个参数给eax ebp+0x4为函数返回地址
add eax,dword ptr ds:[ebp+0xc] //第二个参数 + eax -> eax
//恢复现场
pop edi //取出栈顶给edi,然后esp+4
pop esi //取出栈顶给esi,然后esp+4
pop ebx //取出栈顶给ebx,然后esp+4
//降低堆栈
mov esp,ebp
pop ebp //恢复栈底,刚开始ebp保留过
ret //相当于pop eip 把函数返回地址401171给eip
}
} //裸函数,系统不会生成任何指令,调用时会出错,会导致指令跳转后回不来,往往需要自己写入汇编指令
IEEE规范🔱
IEE754 规定浮点数阶码 E 采用"指数e的移码-1"来表示,请记住这一点。为什么指数移码要减去 1,这是 IEEE754 对阶码的特殊要求,以满足特殊情况,比如对正无穷的表示。
对于阶码为 0 或 255 的情况,IEEE754标准有特别的规定:
如果 阶码 E=0 并且尾数 M 是 0,则这个数的真值为 ±0, 正负号和数符位有关。
如果阶码 E=255 并且尾数 M 全是0,则这个数的真值为 ±∞(同样和符号位有关)
阶码E = 指数e的移码-1 等价于 E = e + 127
移码(又叫增码)是对真值补码的符号位取反,一般用作浮点数的阶码,引入的目的是便于浮点数运算时的对阶操作。

调用约定
| 调用约定 | 参数压栈顺序 | 平衡堆栈 |
|---|---|---|
| __cdecl(c与c++默认) | 从右至左入栈 | 调用者清理栈(外平栈) |
| __stdcall | 从右至左入栈 | 自身清理堆栈(内平栈) |
| __fastcall | ECX/EDX传送最左的两个(速度快),剩下从右至左入栈 | 自身清理堆栈(内平栈) |
寻找程序入口🚩
VC的入口点(IDA的start函数,会直接调用main()函数,在start()函数中被调用的函数有三个参数的,并且返回值被传入exit()函数的,可以重点查看)
main函数有三个参数,在一些编译器自己执行的函数下找有三个参数调用的函数call(往往有三个push指令)
注:有符号数与无符号数对于计算机内存存储没有任何区别,
char i = 0xff; //对应有符号数-1
unsigned char k = 0xff; //对应无符号数255
//再进行类型转换--比较大小和数值运算时应特别注意是有符号数还是无符号数
全局变量(基址)识别
mov eax,byte/word/dword ptr ds:[0x12345678] [arr (0x1123456)],eax --将eax直接赋值给某块地址,往往为全局变量
可以通过寄存器的宽度确定全局变量类型
变量个数识别

注:C语言中if语句中若为 > 在汇编中的JCC语句为jle(小于等于),因为不满足小于等于才会执行下面的指令
IF..ESLE IF语句判断
1、每个条件跳转指令要跳转的地址前面都有一个jmp指令(另一个判断语句的jmp)
2、这些jmp指令跳转的地址都是一样的(跳转到函数执行后的部分) (if else语句只能执行一次)
3、如果某个分支没有条件判断,则为else部分
数组汇编代码辨认
int x = 1; --mov dword ptr [ebp-4],1
int b = arr[x]; --mov ecx,dword ptr [ebp-4]
mov edx,dword ptr [ebp+ecx*4-34h] #34h为刚开始定义的数组大小最顶端地址
二维数组与一维数组对于内存存储来说没有区别
int arr[3][4] 要取arr[1][2] 对于编译器来说即arr[1*12+2]
汇编 mov edx,dword ptr [ebp+1*4*4+2-34h] 行号*每行元素个数*4+列号*4
void f(int arr[])
{
cout << "数组传参中size为" << sizeof(arr); // 8 64位系统传入的的指针宽度为8字节
}
int main(int argc, char const *argv[])
{
int arr[5] = {1, 2, 3, 4, 5};
/*int arr[1] = {1};
cout << "main中size为" << sizeof(arr) << " "; // 20
f(arr);*/
return 0;
}
字节对齐/结构体对齐🚩
本质:效率还是空间,二选一的结果
用法 #pragma pack(n) 后跟结构体的定义
对齐参数:n为字节对齐数,其值为1、2、4、8,默认为8,如果这个值比结构体成员的sizeof值小,name该成员的偏移量以此值为准,也就是说,结构体成员的偏移量取二者中的最小值,比如说规定字节对齐数为4,结构体内有_int64类型(8字节),结果仍按四字节对齐
#pragma pack(8)
struct test
{
int a;
_int64 b;
char c;
};
//8字节对齐的话,输出sizeof(test) 为 8 * 3 = 24
//4字节对齐,输出sizeof(test)为 4 + 4 * 2 +4 = 16
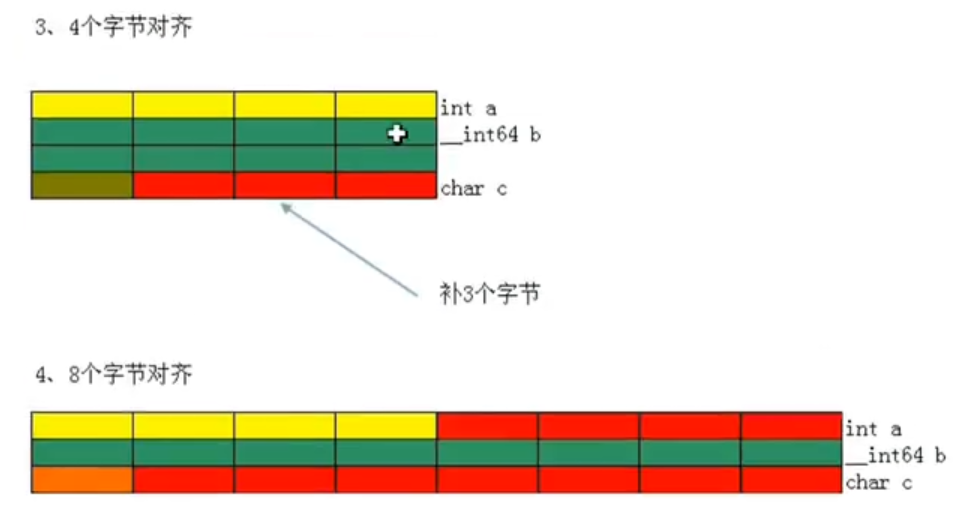
原则一:数据成员对齐规则:结构的数据成员,第一个数据成员放在offset()为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始,如上图8字节对齐,虽然a占了四个字节,b的大小为8个字节,所以b从8开始存储
原则二:结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储(struct a里有struct b,b里有char int double 等元素那b应该从8的整数倍开始存储)
原则三:收尾工作,结构体的总大小,也就是sizeof的结果,必须是内部最大成员大小的整数倍,不足的要补齐
这三个原则具体怎样理解呢?我们看下面几个例子,通过实例来加深理解。
struct test{
char c;
//int a;
double b;
};
int main(){
cout << sizeof(test);
//由于double为8个字节,最终结果为8的整数倍,16字节,如果加上int a,结果仍为8,a可占原来c补齐的位置
//char c;下面在加char c1; char c2; char c3; 结果仍为16,注意顺序,要放在int a前面
}
struct {
short a1;
short a2;
short a3;
}A;
struct{
long a1;
short a2;
}B;
sizeof(A) = 6; 这个很好理解,三个short都为2。
sizeof(B) = 8; 这个比是不是比预想的大2个字节?long为4,short为2,整个为8,因为原则3。
建议:书写时按照数据类型从小到大的顺序书写,节省内存空间
Switch语句识别🔱
当switch语句的case分支小于4时,生成的汇编与if..else 类似,分支大于等于 4 时,编译器会生成一张大表,存储多个分支的case结果,前提是case的值要连续,差值不可太大,差值大于256时按if-else处理,当传入参数x时,首先会对参数进行减1(case分支最小的数),然后根据这个数用统一的表达式进行寻址决定后续的case语句
switch(x):
{
case 1:
cout<<1;
case 2:
cout<<2;
case 3:
cout<<3;
case 4:
cout<<4;
default:
cout<<"error";
}
//switch生成大表的反汇编,不用一个一个判断,大大节省效率,在游戏加密中经常会用到
mov eax,dword ptr [ebp-8] (传进来的参数)
mov dword ptr [ebp-4],eax (参数传给局部变量)
mov ecx,dword ptr [ebp-4] (取出局部变量)
sub ecx,1 (减去case判断中的最小的数决定偏移量) --重点关注
mov dword ptr [ebp-4],ecx (把减后的结果存到局部变量中)
cmp dword ptr [ebp-4],3 (将减后的结果与3比较,其实就相当于判断x是否大于4)
ja 0040d826h (结果大于3的话直接执行default)
mov edx,dword ptr [ebp-4] (将减1的结果赋给edx)
jmp dword ptr [edx*4+40D841h] (根据偏移量,决定每个case的跳转地址,) 40D841h为为创建的大表的起始地址
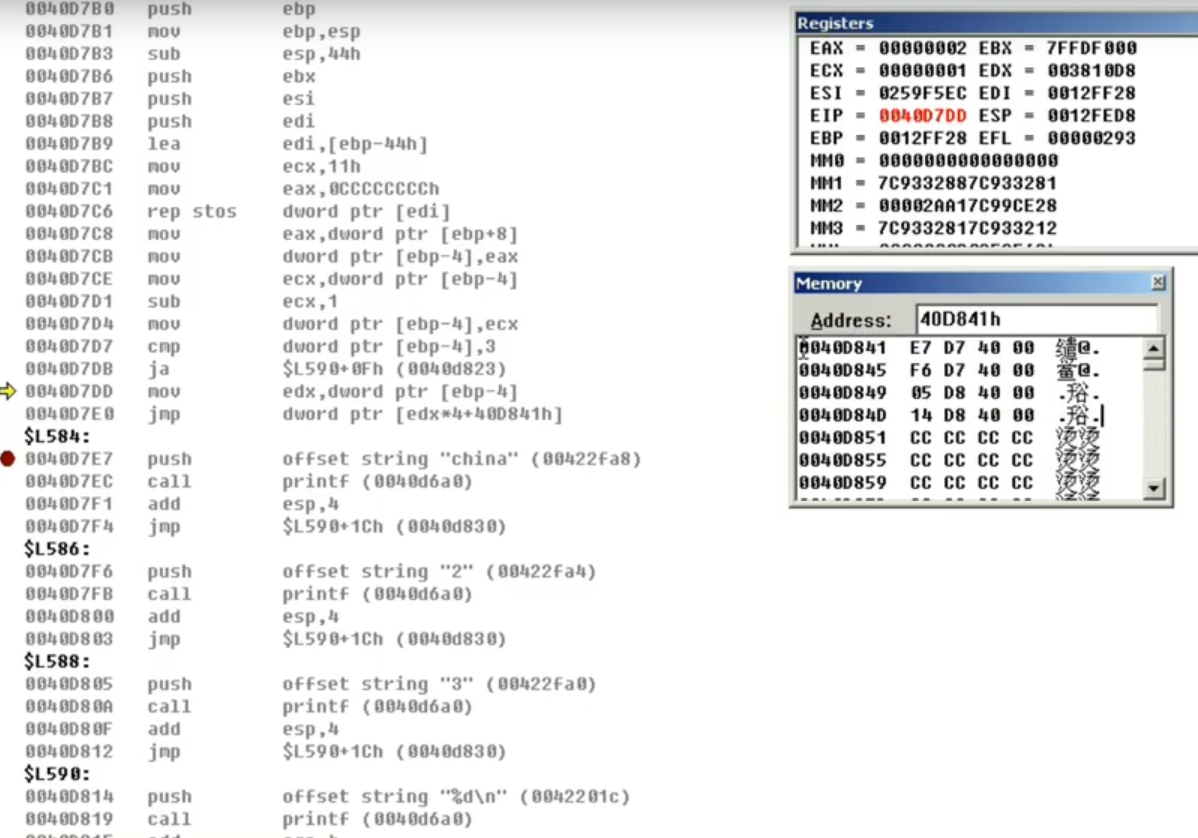
注:case的值的顺序对生成的汇编代码无影响,如果删除case 2,则生成的大表仍会保留,编译器会把default的地址写到case2对应的偏移地址,再删除一个case,该地址也会填充default
如果case的值相差较多但小于256,会生成一个小表
当不断删去中间的值时,不删除最大最小值,因为减去的是最小值,编译器最终会生成一张小表,地址位于紧挨着大表之下,
传入参数x时,编译器会先对小表进行判断,将偏移量存到 dl 里,再根据 dl 去大表中寻找地址 --可节省内存空间
//生成的小表只有一个字节,最多存256,所以case语句的偏移值不可以太大
// 创建小表时,通过小表把中间不连续的值相对于case最小值的偏移做了优化 多了如下的汇编 小表地址004010d0
mov eax,dword ptr [ebp-4] 将传入的参数的值相对于case的最小值的偏移给了ecx后又给了eax
xor edx,edx (将edx清零)
mov dl,byte ptr (004010d0)[eax] --相当于mov dl,byte ptr[004010d0+eax] //去小表中查值给了dl
//比如说case:301 .... case:308,case:309 传入308,根据这项操作会把dl的值变为01,查大表的时候直接 40108ch+4就可以了
jmp dword ptr [edx*4+40108ch] --根据小表得到的 dl 去大表中找case语句执行后的
//如下图小表中的04给了dl 04*4 +40108ch就是default的地址

指针🚩
指针加减
char* a; //指针只要做加减运算就是按 去掉一个*后的数据类型来计算
char* b;
a = (char*)100;
b = (char*)200;
int x = b- a; //只有相同类型才可以做加减,*的数量相同 这里去掉一个*后,x = (200-100)/1=100
printf("%d\n",x);
char** a; //指针只要做加减运算就是按 去掉一个*后的数据类型来计算
char** b;
a = (char**)100;
b = (char**)200;
int x = b- a; // 这里去掉一个*后,x = (200-100)/4=25 64为下指针的宽度为8位
printf("%d\n",x);
long *a;
long *b;
long c;
a = (long *)200;
b = (long *)100;
int x = a - b;
printf("%d\n", x); //(200 - 100)/4 = 25
printf("%d\n", sizeof(c)); //long 的宽度为4 long long 为8
多维指针加减
char* p1;
char** p2;
printf("%d\n",*p1); //mov eax,dword ptr [ebp-4] mov cl,byte ptr [eax] mov byte ptr[ebp-20h],cl
printf("%d\n",*(p1+2)); //mov edx,dword ptr [ebp-4] movsx eax,byte ptr [edx+2](char为1字节) push eax;
printf("%d\n",*p2); //与上面汇编无异
printf("%d\n",*(*p2)); //mov eax,dword ptr [ebp-8] mov ecx,dword ptr [eax]
//movsx edx,byte ptr [ecx](把寄存器里的值当地址取值) push edx
printf("%d\n",*(*(p2+1)+1)); //p2+1的类型char** 计算时先去掉x再决定偏移,*(p2+1)为+4,而*(p2+1)+1为加1
指针类型转换
int x = 1;
char y = 'a';
x = (char)97;
y = x;
cout << x << " " << y; //97 a
int* x;
char* y;
y = (char*)10; //char* 与 int* 是可以互相转换的
x = (int*)y;
指针与汇编
int x; //局部变量的声明不会生成汇编代码
x = 10;
--mov dword ptr [ebp-4],0Ah 把0A赋给ebp-4的位置(缓冲区)
int *px = &x;
--lea eax,[ebp-4] 取出变量x的地址 ebp-4的位置,这里是lea
--mov dword ptr [ebp-8],eax 将变量x的地址给px,缓冲区的 ebp - 8
int x1 = *px;
--mov ecx,dword ptr [ebp-8] 取出ebp-8的地址即px指向的x的地址放到ecx里
--mov edx,dword ptr [ecx] 把ecx里存的px指向的地址里存的数即x放到edx里 现在edx存的就是x
--mov dword ptr [ebp-0Ch],edx 把取出来的*px放到缓冲区 ebp-0Ch的地址
结构体指针
struct Arg{
int a1;
int a2;
int a3;
};
Arg*** pArg;
pArg = (Arg*)100; //类型强转 ,以下不同语句均按pArg = (Arg* 100)为初始值
pArg++; //做运算时去掉一个*,按剩下的类型长度计算,砍掉*后仍为*类型,四字节
printf("%d\n",pArg); //结果为104
Arg* pArg;
pArg++;
printf("%d\n",pArg); //结果为112
pArg = pArg + 5; //结果为100 + 5*12
Arg* pArg2;
pArg2 = (Arg*)20;
int x = pArg - pArg2; //相减结果为int类型,最终结果为(100 - 20) / 12 = 6
Arg s;
s.a1 = 10; //mov dword ptr [ebp-0Ch],0Ah
s.a2 = 20; //mov dword ptr [ebp-8],14h
s.a3 = 30; //mov dword ptr [ebp-4],1Eh
Arg* px = &s; //lea eax,[ebp-0Ch](取第一个值a1的地址) mov dword ptr [ebp-10h],eax(将a1地址作为存放结构体s的地址)
printf("%d %d %d\n",px->a1,px->a2,px->a3);//若a2 a3 为char或short型,编译器会自动根据其类型的宽度先后寻找
//注意char型只有一个字节,其值不可超过127
int x = 10;
Arg* px = (Arg*)&x; //同样可以,编译器只存x的地址,若要取px->a2,其会自动在x后数四个字节作为a2的值,与它是不是结构体无关
cout << px->a1 << " " << px->a2 << " " << px->a3;
//结果为10 7339524 0 第一个值正常取,后面的不一定
数组指针与指针数组
int (*px)[5]; //数组指针 int* px[5]; 为指针数组,本质是数组,数组的内容为int*类型
printf("%d\n",sizeof(px)); //结果为4
px = (int (*)[5]) 10; //强转
printf("%d\n",px); //10
px++; // 10 + 5 * 4 = 30
printf("%d\n",px);
int arr[5]={1,2,3,4,5};
int (*px)[2];
px = (int (*)[2])arr; //px为数组指针的首地址
printf("%d %d\n",px,*px); //px与*px的值一样,但类型不同 *px为arr数组首地址,而px为存放数组首地址的地址
printf("%d %d\n",px++,*px); //px++加的为 4 * 2 = 8,去掉 *后为 int [2]
printf("%d %d\n",px,(*px)+1); //*px + 1 为 + 4 *px为arr,加的为指向的数组类型的每个元素的宽度,
printf("%d\n",*(*(px+1)+1));//*(px+1) 加4*2=8个字节,指向arr的3的地址,之后再往后移四个字节,结果为4,等价于px[1][1]
printf("%d\n",*(*(px+4)+5)); //(8*4+5*4)/4 =13 如果arr有40个元素,这样访问的就是第14个元素
用int型指针访问char型数组,将四个连续的值作为一个int型指针的基本数据单元
char ch[20] = {0x1,0x2,0x3,0x4,0x5,0x6,0x7,0x8,0x9,0xA,0xB,0xC,0xD,0xE,0xF,0x10,0x11,0x12,0x13,0x14};
int *px[2][3];
px = (int (*)[2][3]ch); //类型强转
printf("%x\n",*(*(*(px+1)+2)+2)); 最内层 1*(2*3)*4 次内层2*3*4 外层2*4
printf("%x\n",*(*(*(px)+1)+1)); 1*3*4 + 1*4 = 16 向后偏移16个元素后开始数四个数,小端存储结果即为该值 0x14131211
函数指针
//函数指针
int func(int x,int y){
return x + y;
}
int main(){
int (*pFunc)(int,int);
pFunc = (int (*)(int,int))func; //等价于 pFunc = func;
int x = pFunc(1,2);
printf("%d\n",x); //结果为3
}
宏定义
#define MAX(A,B) ((A)>(B)?(A):(B))
- 宏是在编译前直接做了替换
- 宏名标识符与(A,B)之间不允许有空格
- 宏与函数的区别:函数需要分配额外的空间,宏只是做了替换
- 为了避免出错,宏定义往往给形参加上括号
- 末尾不需要分号
#ifdef和#endif
- 用于注释掉一段代码
我们自己编写程序的时候,需要看到一系列的调试代码,但是发给客户的时候,客户可不希望看到什么什么OK的代码,所以我们希望能很容易地注释掉这段代码。
这时需要用到预处理指令 #ifdef 和 #endif :
#include <stdio.h>
#define CONFIG_DEBUG
int main(){
FILE *fp;
fp=fopen("D:\\DEV\\test.txt","r");
if(NULL==fp){
printf("error!");
}
#ifdef CONFIG_DEBUG
printf("open test.txt ok");
#endif
return 0;
}
- 防止头文件重复包含
a.h文件如下
#include <stdio.h>
#include "b.h"
b.h文件如下
#include "a.h"
c.h
#include "a.h"
#include "b.h"
int main(){
printf("Hello!");
}
程序是这样写的话,编译器就会出现Error #include nested too deeply的错误。因为这里 b.h 和 a.h 都互相包含,c.c文件在include的时候重复include了a.h,我们希望c.c文件中执行#include "b.h"的时候 b.h 能进行判断,如果没有#include "a.h"则include,如果已经include了,则不再重复定义。
把 b.h修改成以下内容
#ifndef _A_H
#define _A_H
#include "a.h"
#endif
内存分区
常量区数据不可修改
void func(){
char *x = "china"; //x放在栈区,存放的是指向china的地址,china存在常量区 所以x指向的字符串不可以修改
char y[] = "china"; //与上同样,但是会从常量区把china拷贝到堆栈里,可以修改。
}
char *x = "china"; //x放在栈区,存放的是指向china的地址,china存在常量区 所以x指向的字符串不可以修改
char y[] = "china";
void func2(){
*(x+1) = 'A'; //不可以修改,china存在常量区
y[1] = 'A'; //可以修改,该字符数组存在全局区
}
内存分配与释放
//动态申请内存:malloc函数 返回类型为void *(可以转为任意类型指针) 或 NULL(如果内存不够申请则返回NULL)
ptr = (int *)malloc(sizeof(int)*128); //申请完一定要判断 ptr 是否为NULL
//初始化分配的内存空间
memset(ptr,0,sizeof(int)*128);
//使用
*(ptr) = 1;
//使用完毕,释放申请的堆空间
free(ptr);
//将指针设置为NULL
ptr = NULL;
6. PE文件格式
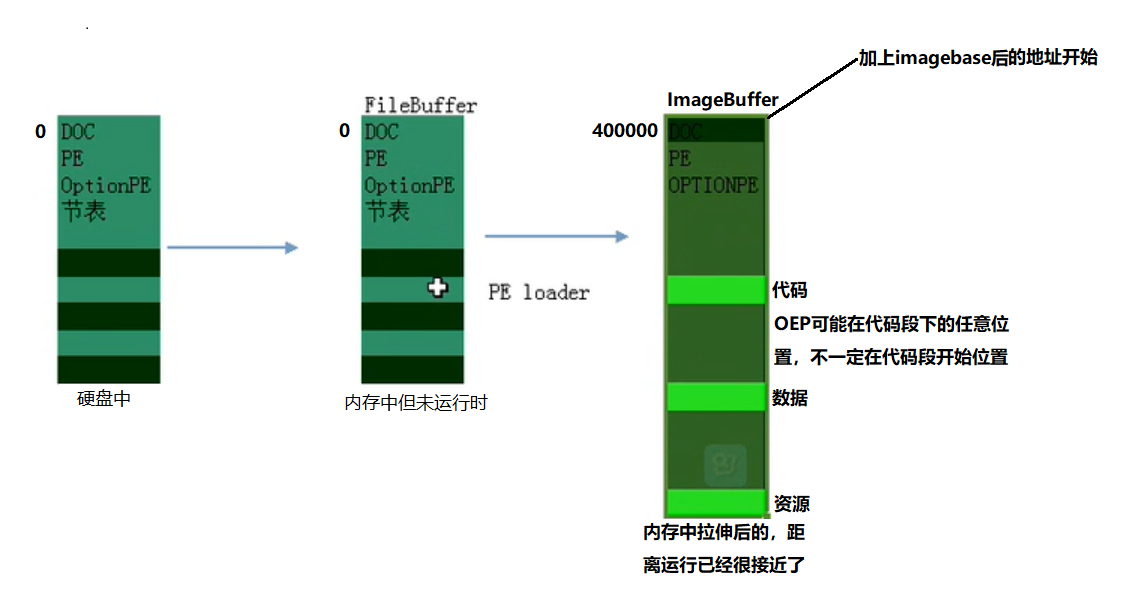
注意
内存中的PE文件格式与磁盘中是不一样的,
PE文件主要分为以下几种:
| 种类 | 主扩展名 |
|---|---|
| 可执行系列 | .exe .scr |
| 库系列 | .dll .ocx .cpl .drv |
| 驱动程序系列 | .sys .vxd |
| 对象文件系列 | .obj |
特征:
执行时先进行拉伸,哪怕只有一字节的数据要存储也需要占据200h字节的空间
分节,每一个节存储不同的数据,数据的概要性描述信息存到块表(节标),应对多开问题,只赋值能读能写的数据
硬盘对齐:200h 内存对齐:1000h
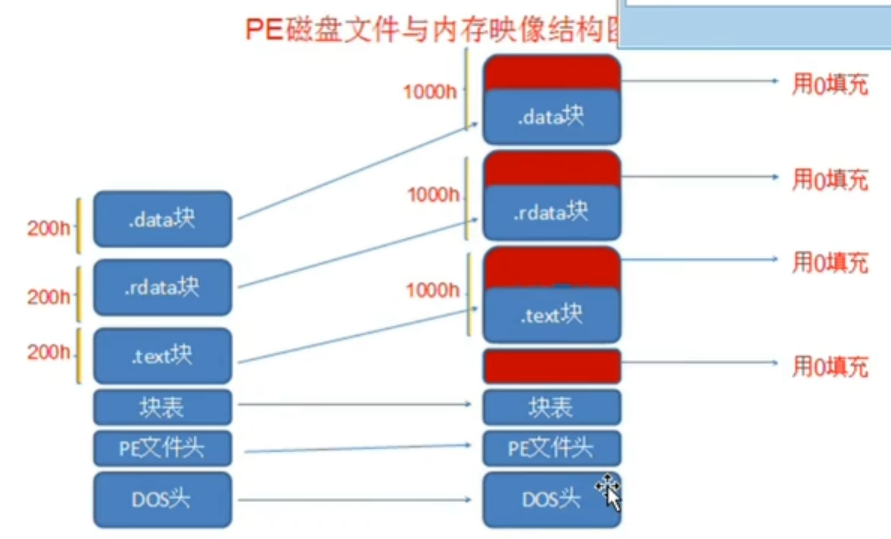
DOS头
e_magic --"MZ标记",用于判断是否是可执行文件,被称为魔术数字,它被用于表示一个MS-DOS兼容的文件类型。所有MS-DOS兼容的可执行文件都将这个值设为0x5A4D,表示ASCII字符MZ。MS-DOS头部之所以有的时候被称为MZ头部,就是这个缘故。
e_lfnew --NT头相对于文件的偏移,比如其值为00 00 00 E8,自此向下查E8个字节即为PE文件头地址,中间有垃圾数据
NT头
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature; //4个字节的PE标志,通常设置成00004550h,其ASCII码为PE00,这个字段是PE文件头的开始
IMAGE_FILE_HEADER FileHeader; //文件头标准PE头
IMAGE_OPTIONAL_HEADER32 OptionalHeader;//可选头可选PE头
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
包含标志位DWORD Signature和标准PE头以及可选PE头,DOS头与标准PE头字节固定,可选PE头字节不固定
标准PE头(20字节)
typedef struct _IMAGE_FILE_HEADER {
WORD Machine; //程序运行的CPU型号,作用是区别这个exe是哪个CPU可以跑的.重要.
WORD NumberOfSections; //节的数量 (可以理解为汇编中区的个数)现在我们有两个,一个.rdata 一个.text 重要
DWORD TimeDateStamp; //时间戳,文件的创建时间 --程序的编译时间,参考用,没有实际作用
//加壳前往往会看PE文件和 对应的map文件(存放了exe要用到的各种信息)的时间戳是否一样,不一样就不能加壳
//DWORD PointerToSymbolTable; //符号表地址 我们使用的PDB文件(里面有函数吗什么的)都存放在这个表中,不过微软是单独生成的PDB文件,所以这个字段没用,主要是给别人用
//DWORD NumberOfSymbols; //符号表大小
WORD SizeOfOptionalHeader; //可选头大小,这个字段很重要.因为要通过这个字段,才知道可选头是多大,而不懂PE的人求选项头都是用sizeof()求出来的.所以真正的选项头大小要靠这个字段
WORD Characteristics; //文件属性,描述文件信息的,每个位有不同含义,可执行文件值为10F,即第0 1 2 3 8位置1
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
可选PE头
--在32位里默认大小为E0h ---64位里默认大小F0h
偏移量 offset = dos_head->e_lfanew + SIZE_OF_NT_SIGNATURE(即:4) + sizeof(IMAGE_FILE_HEADER) -标准PE头
typedef struct _IMAGE_OPTIONAL_HEADER {
WORD Magic; /*机器型号,判断是PE是32位:10B 还是64位:20B*/
//BYTE MajorLinkerVersion; /*连接器版本号高版本*/
//BYTE MinorLinkerVersion; /*连接器版本号低版本,组合起来就是 5.12 其中5是高版本,C是低版本*/
DWORD SizeOfCode; //代码节的总大小(512为一个磁盘扇区),必须是FileAlignment整数倍 没用
DWORD SizeOfInitializedData; //初始化数据的节的总大小,也就是.data必须是FileAlignment整数倍 没用
DWORD SizeOfUninitializedData; //未初始化数据的节的大小,也就是 .data ?必须是FileAlignment整数倍 没用
DWORD AddressOfEntryPoint; //程序执行入口(OEP) RVA(相对偏移) 重要
DWORD BaseOfCode; //代码的节的起始RVA(相对偏移)也就是代码区的偏移,偏移+模块首地址定位代码区
DWORD BaseOfData; //数据节的起始偏移(RVA),同上 没用
DWORD ImageBase; //内存镜像基址,程序在内存中执行时的加载基址 重要 目的:地址被别的程序占用后仍可改为别的值 内存中的程序入口地址一般都是OEP的值加上这个地址的值 最重要
DWORD SectionAlignment; /*内存中的节对齐*/
DWORD FileAlignment; /*文件中的节对齐*/ 重要
//WORD MajorOperatingSystemVersion; /*操作系统版本号高位*/
//WORD MinorOperatingSystemVersion; /*操作系统版本号低位*/
// WORD MajorImageVersion; /*PE版本号高位*/
//WORD MinorImageVersion; /*PE版本号低位*/
// WORD MajorSubsystemVersion; /*子系统版本号高位*/
//WORD MinorSubsystemVersion; /*子系统版本号低位*/
//DWORD Win32VersionValue; /*32位系统版本号值,注意只能修改为4 5 6表示操作系统支持nt4.0 以上,5的话依次类推*/
DWORD SizeOfImage;//整个程序在内存中占用的空间(PE映尺寸imagebuffer),可以比实际值大,必须是SectionAlignment整数倍 重要
DWORD SizeOfHeaders; //所有头(头的结构体大小)+节表的大小,严格按照FileAlignment对齐 重要
DWORD CheckSum; //校验和,对于驱动程序,可能会使用,用于判断文件是否被修改,两个两个值加起来,循环求和 有用
WORD Subsystem; /*文件的子系统 :重要*/
WORD DllCharacteristics; /*DLL文件属性,也可以成为特性,可能DLL文件可以当做驱动程序使用*/
DWORD SizeOfStackReserve; /*预留的栈的大小*/
DWORD SizeOfStackCommit; /*立即申请的栈的大小(分页为单位)*/
DWORD SizeOfHeapReserve; /*预留的堆空间大小*/
DWORD SizeOfHeapCommit; /*立即申请的堆的空间的大小*/
DWORD LoaderFlags; /*与调试有关*/
DWORD NumberOfRvaAndSizes; //目录项 下面的成员,数据目录结构的项目数量 10h 有用
//这个域标识了接下来的DataDirectory数组。请注意它被用来标识这个数组,而不是数组中的各个入口数字,这一点非常重要。
IMAGE_DATA_DIRECTORY DataDirectory[16];/*数据目录,默认16个,16是宏,这里方便直接写成16 有导入导出表重定向表 重要*/
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
//PE格式 imagebase + 偏移
流出imagebase 一般exe是400000h ,目的是为了内存保护,空出一段内存的保护地址。一个exe程序对应一个4GB空间,但这一个4GB空间里会有很多PE文件,所以要有imagebase,防止载入多个PE文件的时候基址被抢占,如果一个PE占据了400000,那么其它的PE可以通过修改自己的imagebase的值从而改变载入的地址完成加载。 经过PEloader拉伸后得到文件镜像(imagebuffer)
DataDirectory:数据目录,这是一个数组,数组的项定义如下:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
RVA与FOA转换🚩
RVA:相对虚拟地址,可以理解为文件被装载到虚拟内存(拉伸)后先对于基址的偏移地址。它的对齐方式一般是以1000h为单位,以虚拟内存对齐的方式对齐的,具体对齐需要参照IMAGE_OPTIONAL_HEADER32中的SectionAlignment成员。
计算公式:RVA = VA - ImageBase
FOA:文件偏移地址。可以理解为文件在磁盘上存放时相对于文件开头的偏移地址。它的对齐方式一般是以200h为单位,以文件对齐的方式对齐的,具体对齐需要参照IMAGE_OPTIONAL_HEADER32中的FileAlignment成员。
RVA转换为FOA🚩
1.文件对齐跟内存对齐一样的情况:RVA即FOA
2.文件对齐和内存对齐不一样的情况:
我们需要判断RVA属于哪个节/头,这里也要分为两种情况!
1)如果RVA属于文件头部(DOS头 + PE头 + 节表),头部大小是文件对齐大小的整数倍!
那么不需要进行计算了,因为DOS头和PE头和节表在文件中和在内存中展开都是一样的,直接从开始位置寻找到RVA个字节即可,就是找0x24A30,也就是FOA(文件偏移地址)
2)如果RVA不在头,就要判断在哪个节里面
判断节开始位置到节结束位置 我们的RVA是否在这个范围里面,总共分为三步骤:
第一步:指定节.VirtualAddress <= RVA <= 指定节.VirtualAddress + VirtualSize(当前节内存实际大小)
第二步:差值 = RVA - 指定节.VirtualAddress
第三步:FOA = 指定节.PointerToRawData + 差值
size_t RVAToFOA(
size_t x,
PVOID memoryBuff
){
PIMAGE_DOS_HEADER idh = NULL;
PIMAGE_NT_HEADERS inh = NULL;
PIMAGE_FILE_HEADER ifh = NULL;
PIMAGE_OPTIONAL_HEADER ioh = NULL;
PIMAGE_SECTION_HEADER ish = NULL;
idh = (PIMAGE_DOS_HEADER)memoryBuff;
inh = (PIMAGE_NT_HEADERS)((BYTE *)memoryBuff + idh->e_lfanew); //NT头
ifh = (PIMAGE_FILE_HEADER)((BYTE *)inh + sizeof(DWORD)); //标准PE头
ioh = (PIMAGE_OPTIONAL_HEADER)((BYTE *)ifh + IMAGE_SIZEOF_FILE_HEADER); //可选PE头
ish = (PIMAGE_SECTION_HEADER)((BYTE *)ioh + ifh->SizeOfOptionalHeader); //节表
DWORD sectionCount = inh->FileHeader.NumberOfSections;
DWORD memoryAli = inh->OptionalHeader.SectionAlignment;
//DWORD RVA = x - ioh->ImageBase;
DWORD RVA = x;
if(RVA < pOptionHeader->SizeOfHeaders) return RVA; //RVA属于文件头部(DOS头 + PE头 + 节表)
for(DWORD i = 0;i < sectionCount ; i++){ //RVA不在文件头部,需要判断在哪个节
PIMAGE_SECTION_HEADER tmpSec = (ish + i); //判断在哪个节 这里是指针的加减 加的是整个节
if( RVA >= tmpSec->VirtualAddress && RVA <= (tmpSec->VirtualAddress + tmpSec->Misc.VirtualSize)){
return tmpSec->PointerToRawData + (RVA - tmpSec->VirtualAddress);//文件中的偏移加上 (RVA-内存中偏移)
}
}
return ERROR;
}
//**************************************************************************
//RVA2FOA:将内存偏移转换为文件偏移
//参数说明:
//pFileBuffer FileBuffer指针
//dwRva RVA的值
//返回值说明:
//返回转换后的FOA的值 如果失败返回0
//**************************************************************************
DWORD RVA2FOA(IN LPVOID pFileBuffer, IN DWORD dwRva)
{
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_FILE_HEADER pFileHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
PIMAGE_SECTION_HEADER pNextSectionHeader = NULL;
//DOS头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);//SIZEOF_FILE_HEADER为固定值且不存在于PE文件字段中
if (dwRva < pOptionalHeader->SizeOfHeaders) //偏移小于头的大小,内存偏移则为文件偏移
{
return dwRva;
}
//首个节表
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
//下一个节表
pNextSectionHeader = pSectionHeader + 1;
//循环遍历节表
for (int i = 1; i < pFileHeader->NumberOfSections; i++, pSectionHeader++, pNextSectionHeader++)//注意这里i从1开始 i < NumberOfSections
{ //注意这里的pSectionHeader已经是加了基址的,不是偏移, 是绝对地址。而dwRva是偏移地址
if (dwRva >= pSectionHeader->VirtualAddress && dwRva < pNextSectionHeader->VirtualAddress)//大于当前节的内存偏移而小于下一节的内存偏移
{ //则dwRva属于当前节,则dwRva - VirtualAddress为dwRva基于当前节的偏移。此偏移加上当前节的文件起始偏移地址 则为dwRva在文件中的偏移
return pSectionHeader->PointerToRawData + (dwRva - pSectionHeader->VirtualAddress);
}
} //出循环后pSectionHeader指向最后一个节表
//大于当前节(最后一节)的内存偏移且小于内存映射大小
if (dwRva >= pSectionHeader->VirtualAddress && dwRva < pOptionalHeader->SizeOfImage)
{ //同上return
return pSectionHeader->PointerToRawData + (dwRva - pSectionHeader->VirtualAddress);
}
else //大于内存映射大小
{
printf("dwRva大于内存映射大小\n");
return -1;
}
}
//测试 内存偏移转换为文件偏移 是否正确
bool TestRvaToFile(LPVOID pFileBuffer ,DWORD Offset)
{
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pFileHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
PIMAGE_SECTION_HEADER pNextSectionHeader = NULL;
//DOS头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer;
//NT头
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pFileBuffer + pDosHeader->e_lfanew);
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)(((DWORD)pNTHeader) + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);//SIZEOF_FILE_HEADER为固定值且不存在于PE文件字段中
//循环遍历节表
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
for (int i = 1; i <= pFileHeader->NumberOfSections; i++, pSectionHeader++)
{
//通过函数由Rva得出的FOA
DWORD FuncFOA = RVA2FOA(pFileBuffer, Offset + pSectionHeader->VirtualAddress);
//查节表得出的FOA
DWORD RealFOA = Offset + pSectionHeader->PointerToRawData;
if (FuncFOA != RealFOA)
{
printf("第%d个节表测试错误!\n", i);
return false;
}
} //出循环后pSectionHeader指向不存在的节表,多了一节
pSectionHeader = NULL; //所以pSectionHeader指针不可再使用
printf("测试成功!\n");
return true;
}
FOA转换为RVA
设FOA为节数据的任意一位置
1.计算差值偏移:
FOA - 指定节.PointerToRawData(文件中偏移) = 差值
2.计算RVA:
差值 + 指定节.VirtualAddress(内存中偏移) = RVA
3.计算虚拟地址:
VA = RVA + ImageBase
需要注意的就是我们的 FOA 在哪一个节中:
指定节.PointerToRawData <= FOA <= 指定节..PointerToRawData + 指定节..SizeofRawData
联合体(共用体)
union data{
int n;
char ch;
double f;
};
共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
节表
偏移:SecOffset = dos_head->e_lfanew + SIZE_OF_NT_SIGNATURE + sizeof(IMAGE_FILE_HEADER)+ peHeader>FileHeader.SizeOfOptionalHeader;
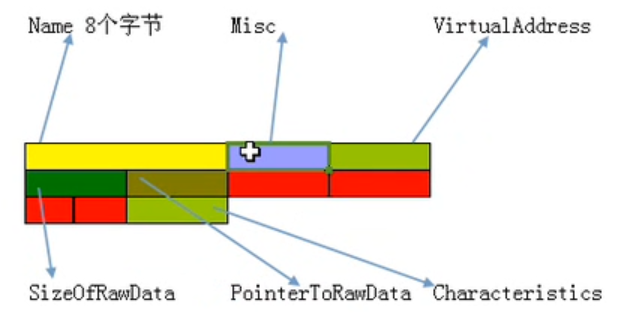
IMAGE_SECTION_HEADER STRUCT
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 8个字节的节区名称,一般情况下是以"\0"结尾的ASCII码字符串来表示的名称
//注意:该名称并不遵守必须以"\0"结尾的规律,如果不以"\0"结尾,系统会截取8个字节的长度进行处理。 .text/.data
union{
DWORD PhysicalAddress;
DWORD VirtualSize; //节区的尺寸,文件对齐前的实际大小,但可以修改故不准确
//不一定比sizeofRawData小 因为VirtualSize在内存中与文件中大小不同,文件中不存放未初始化变量,而内存中会存放
}Misc; //联合体 四个字节,存放该节在没有对齐前内存中的真实Size,但可以修改
DWORD VirtualAddress; // 节区的 RVA(相对偏移地址)地址 节区在*内存*中的偏移地址,加上imagebase才是真实地址
DWORD SizeOfRawData; // 节在文件中对齐后的尺寸
DWORD PointerToRawData; // 节区在文件中的偏移量,一定是文件对齐的整数倍 文件打开根据此值判断节内容位置
//DWORD PointerToRelocations; // 在OBJ文件中使用,重定位的偏移,对exe无意义
//DWORD PointerToLinenumbers; // 行号表的偏移(调试时使用)
//WORD NumberOfRelocations; // 在OBJ文件中使用,重定位项数目,对exe无意义
//WORD NumberOfLinenumbers; // 行号表中行号的数目
DWORD Characteristics;
//节属性如可读,可写,可执行等 .test节6000020 4000000为该节可执行 2000000表示该节可写 20为包含可执行代码
IMAGE_SECTION_HEADER ENDS
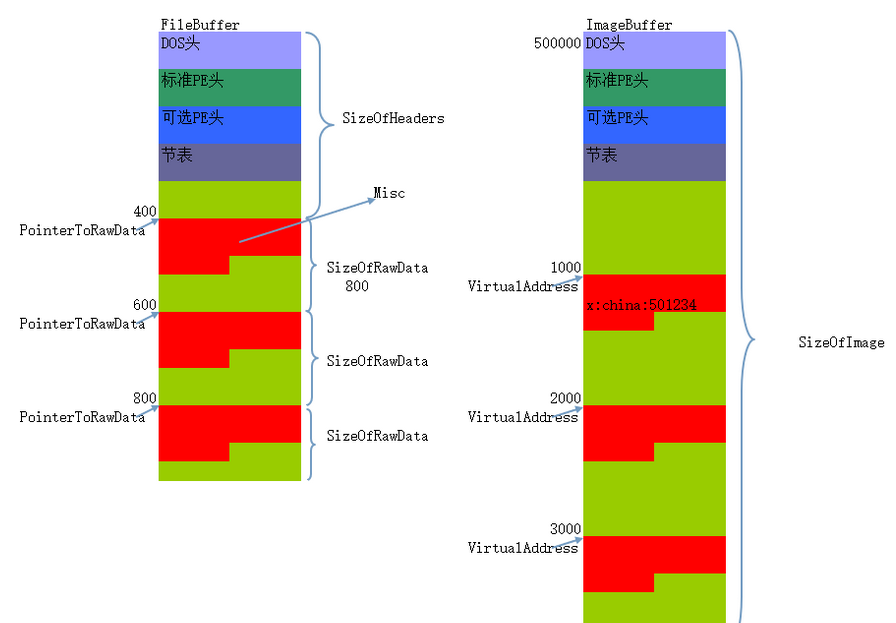
CALL与JMP执行
004011F8 E8 53 FE FF FF call 00401050 步入后地址为 004011FD
004011FD --都是内存中运行时的地址
真正要跳转的地址 = E8这条指令的下一行地址 + X X = 真正要跳转的地址 - E8这条指令的下一行地址 = 401050 - 4011FD = FFFFFE53
E8 53 FE FF FF为五个字节,硬编码知识,E8下一条指令地址为 E8 + 5 = FD
故要跳转的地方 = E8当前指令地址(拉伸后的地址) + 5 + X
JMP指令类似
空白区添加代码时 添加的是E8 53 FE FF FF (x) 需利用上面的公式计算出x
任意代码空白区添加代码🚩
1、根据上面的公式,修改 E8后的地址 ,在代码区手动填写 messagebox函数起始地址 0x77E5425F
计算E8 后的四个字节 x : x = 77E5425F(真正要跳转地址) - (E8指令下一条指令地址+imagebase)(注意区分内存和文件的对齐偏移)
然后修改E9 后的四个字节,方法同上
然后修改OEP(程序入口地址为插入的二进制指令的地址)
-
添加代码前我们要判断ShellCode是否能放得下,就要SizeOfRaw-misc>shellcode的长度
-
我们要知道,添加的代码是正在运行中的,所以要加上ImageBase,但是我们是在ImageBuffer中添加的代码,ImageBuffer的起始地址是我们自己malloc出来的,不是真正在内存中执行的地址,所以我们要减去pImageBuffer加上ImageBase得到真正的运行地址
-
这个代码有两种写法,一是在FileBuffer中添加(需要注意内存偏移的文件偏移的影响),二是在ImageBuffer中添加(不需要注意内存文件偏移,因为文件已经拉伸了)
-
我们需要知道MessageBox的地址,我们在DT里面添加断点bp MessageBoxA,然后查看就知道断点的位置了
#include "stdafx.h"
#include<stdio.h>
#include<windows.h>
#include<malloc.h>
#define ShellCodeIen 0x12
#define MessageBoxAdder 0x77D507EA
BYTE ShellCode[]=
{
0x6A,00,0x6A,00,0x6A,00,0x6A,00,
0xE8,00,00,00,00,
0xE9,00,00,00,00
};
//
//FileBuffer函数
DWORD ReadPEFile(LPVOID* ppFileBuffer)
{
FILE* pFile=NULL;
DWORD SizeFileBuffer=0;
pFile=fopen("软件路径","rb");
if(!pFile)
{
printf("打开notepad失败\n");
return 0;
}
//获取文件大小
fseek(pFile,0,SEEK_END);
SizeFileBuffer=ftell(pFile);
fseek(pFile,0,SEEK_SET);
if(!SizeFileBuffer)
{
printf("读取文件大小失败\n");
return 0;
}
//开辟空间
*ppFileBuffer=malloc(SizeFileBuffer);
if(!*ppFileBuffer)
{
printf("开辟空间失败\n");
fclose(pFile);
return 0;
}
//复制数据
size_t n=fread(*ppFileBuffer,SizeFileBuffer,1,pFile); //将读取到的PE文件存到了pFileBuffer里
if(!n)
{
printf("复制数据失败\n");
free(*ppFileBuffer);
fclose(pFile);
return 0;
}
fclose(pFile);
return SizeFileBuffer;
}
//FileBuffer--->ImgaeBuffer
DWORD FileBufferToImageBuffer(LPVOID pFileBuffer,LPVOID* ppImageBuffer)
{
PIMAGE_DOS_HEADER pDosHeader=NULL;
PIMAGE_NT_HEADERS pNTHeader=NULL;
PIMAGE_FILE_HEADER pFileHeader=NULL;
PIMAGE_OPTIONAL_HEADER pOptionalHeader=NULL;
PIMAGE_SECTION_HEADER pSectionHeader=NULL;
if(!pFileBuffer)
{
printf("FileBuffer函数调用失败\n");
return 0;
}
printf("%x\n",pFileBuffer);
//判断是否是PE文件
pDosHeader=(PIMAGE_DOS_HEADER)pFileBuffer;
if(pDosHeader->e_magic!=IMAGE_DOS_SIGNATURE)
{
printf("不是有效的MZ标志\n");
return 0;
}
pNTHeader=(PIMAGE_NT_HEADERS)((DWORD)pFileBuffer+pDosHeader->e_lfanew);
if(pNTHeader->Signature!=IMAGE_NT_SIGNATURE)
{
printf("不是有效的PE标志\n");
return 0;
}
pFileHeader=(PIMAGE_FILE_HEADER)(((DWORD)pNTHeader)+4); //把pNTHeader转为DWORD NT头+4才是标准PE头
pOptionalHeader=(PIMAGE_OPTIONAL_HEADER)((DWORD)pFileHeader+20); //标准PE头+20位为可选PE头
//开辟ImageBuffer空间
*ppImageBuffer=malloc(pOptionalHeader->SizeOfImage);
if(!*ppImageBuffer)
{
printf("开辟ImageBuffer空间失败");
return 0;
}
printf("SizeOfImage%x\n",pOptionalHeader->SizeOfImage);
//malloc清零
memset(*ppImageBuffer,0,pOptionalHeader->SizeOfImage);
//复制Headers
printf("SizeOfHeader%x\n",pOptionalHeader->SizeOfHeaders);
memcpy(*ppImageBuffer,pDosHeader,pOptionalHeader->SizeOfHeaders);
//循环复制节表 可选PE头 + 标准PE头的SizeOfOptionalHeader得到节表
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
for(int i=1;i<=pFileHeader->NumberOfSections;i++,pSectionHeader++)
{
memcpy((LPVOID)((DWORD)*ppImageBuffer+pSectionHeader->VirtualAddress),(LPVOID)((DWORD)pFileBuffer+pSectionHeader->PointerToRawData),pSectionHeader->SizeOfRawData);
printf("%d\n",i);
}
printf("拷贝完成\n");
return pOptionalHeader->SizeOfImage;
}
//shellCode
LPVOID shellCode(LPVOID pImageBuffer)
{
PIMAGE_DOS_HEADER pDosHeader=NULL;
PIMAGE_NT_HEADERS pNTHeader=NULL;
PIMAGE_FILE_HEADER pFileHeader=NULL;
PIMAGE_OPTIONAL_HEADER pOptionalHeader=NULL;
PIMAGE_SECTION_HEADER pSectionHeader=NULL;
PBYTE ShellCodeBegin=NULL;
if(!pImageBuffer)
{
printf("传入参数pImageBuffer失败\n");
return 0;
}
pDosHeader=(PIMAGE_DOS_HEADER)pImageBuffer;
pNTHeader=(PIMAGE_NT_HEADERS)((DWORD)pImageBuffer+pDosHeader->e_lfanew);
pFileHeader=(PIMAGE_FILE_HEADER)((DWORD)pNTHeader+4);
pOptionalHeader=(PIMAGE_OPTIONAL_HEADER)((DWORD)pFileHeader+20);
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
//看看shellcode是否有地方加入
if((pSectionHeader->SizeOfRawData-pSectionHeader->Misc.VirtualSize)< ShellCodeIen)
{
printf("空间不足加入shellcode!!!!\n");
free(pImageBuffer); //不足必须把刚刚申请的内存释放掉
return 0;
}
printf("SizeOfRaw=%x\n",pSectionHeader->SizeOfRawData);
printf("Misc=%x\n",pSectionHeader->Misc.VirtualSize);
printf("空间充足\n");
//判断FileAligment&SectionAliment
if(pOptionalHeader->FileAlignment==pOptionalHeader->SectionAlignment)
{
printf("文件对齐和内存对齐相等\n");
ShellCodeBegin=(PBYTE)(pSectionHeader->VirtualAddress+pSectionHeader->Misc.VirtualSize+(DWORD)pImageBuffer); //把shellcode复制到空闲区
if(!memcpy(ShellCodeBegin,ShellCode,ShellCodeIen))
{
printf("代码初步加入失败\n");
return 0;
}
printf("代码初步加入成功\n");
//E8修正 pImageBuffer为我们自己malloc的地址基址 得到偏移后加上运行时的imagebase才是真正的地址
DWORD CallAddr=(DWORD)((DWORD)MessageBox-((DWORD)pOptionalHeader->ImageBase+(DWORD)ShellCodeBegin+0xD-(DWORD)pImageBuffer)); // 0xD 是因为E8下一条指令在shellcode的偏移为0xD
if(!CallAddr)
{
printf("E8地址获取失败\n");
return 0;
}
*(PDWORD)(ShellCodeBegin+0x9)=CallAdd;
printf("E8修正完成\n");
//E9修正
DWORD JmpAddr=(DWORD)((DWORD)pOptionalHeader->AddressOfEntryPoint-((DWORD)ShellCodeBegin+ShellCodeIen-(DWORD)pImageBuffer)); //ShellCodeIen为宏常量 0x12
if(!JmpAddr)
{
printf("E9地址获取失败\n");
return 0;
}
*(PDWORD)(ShellCodeBegin+0xE)=JmpAddr;
printf("E9修正完成\n");
//修正OEP 为偏移, ShellCodeBegin-pImageBuffer即可 注意类型转换
printf("OEP=%x\n",pOptionalHeader->AddressOfEntryPoint);
pOptionalHeader->AddressOfEntryPoint=(DWORD)ShellCodeBegin-(DWORD)pImageBuffer;
printf("OEP=%x\n",pOptionalHeader->AddressOfEntryPoint);
printf("OEP修正完成\n");
printf("完成!!!!!\n");
return pImageBuffer;
}
else
{
printf("文件对齐和内存对齐不一样\n");
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
ShellCodeBegin=(PBYTE)(pSectionHeader->VirtualAddress+pSectionHeader->Misc.VirtualSize+(DWORD)pImageBuffer); //把shellcode复制到空闲区
if(!memcpy(ShellCodeBegin,ShellCode,ShellCodeIen))
{
printf("代码初步加入失败\n");
return 0;
}
printf("代码初步加入成功\n");
//E8修正
DWORD CallAddr=(DWORD)((DWORD)MessageBox-((DWORD)pOptionalHeader->ImageBase+(DWORD)ShellCodeBegin+0xD-(DWORD)pImageBuffer));
if(!CallAddr)
{
printf("E8地址获取失败\n");
return 0;
}
*(PDWORD)(ShellCodeBegin+0x9)=CallAdd;
printf("E8修正完成\n");
//E9修正
DWORD JmpAddr=(DWORD)((DWORD)pOptionalHeader->AddressOfEntryPoint-((DWORD)ShellCodeBegin+ShellCodeIen-(DWORD)pImageBuffer));
if(!JmpAddr)
{
printf("E9地址获取失败\n");
return 0;
}
*(PDWORD)(ShellCodeBegin+0xE)=JmpAddr;
printf("E9修正完成\n");
//修正OEP
printf("OEP=%x\n",pOptionalHeader->AddressOfEntryPoint);
pOptionalHeader->AddressOfEntryPoint=(DWORD)ShellCodeBegin-(DWORD)pImageBuffer;
printf("OEP=%x\n",pOptionalHeader->AddressOfEntryPoint);
printf("OEP修正完成\n");
printf("完成!!!!!\n");
return pImageBuffer;
}
}
//ImageBufferToFileBuffer 将插入代码后的再缩短,缩短后才可以存盘
DWORD ImageBufferToFileBuffer(LPVOID pImageBuffer,LPVOID* ppBuffer)
{
PIMAGE_DOS_HEADER pDosHeader=NULL;
PIMAGE_NT_HEADERS pNTHeader=NULL;
PIMAGE_FILE_HEADER pFileHeader=NULL;
PIMAGE_OPTIONAL_HEADER pOptionalHeader=NULL;
PIMAGE_SECTION_HEADER pSectionHeader=NULL;
if(!pImageBuffer)
{
printf("error");
return 0;
}
pDosHeader=(PIMAGE_DOS_HEADER)pImageBuffer;
pNTHeader=(PIMAGE_NT_HEADERS)((DWORD)pImageBuffer+pDosHeader->e_lfanew);
pFileHeader=(PIMAGE_FILE_HEADER)((DWORD)pNTHeader+4);
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER)((DWORD)pFileHeader + 20);
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
//得到FileBuffer的大小
for(int i=1;i<pFileHeader->NumberOfSections;i++,pSectionHeader++)
{
printf("%d\n",i);
}
//循环到最后一个节表
DWORD SizeOfBuffer=pSectionHeader->PointerToRawData+pSectionHeader->SizeOfRawData;
//开辟空间
*ppBuffer=malloc(SizeOfBuffer);
if(!*ppBuffer)
{
printf("开辟Buffer空间失败\n");
return 0;
}
printf("SizeOfBuffer%x\n",SizeOfBuffer);
memset(*ppBuffer,0,SizeOfBuffer);
//复制头
memcpy(*ppBuffer,pImageBuffer,pOptionalHeader->SizeOfHeaders);
//复制节表
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
for(int j=1;j<=pFileHeader->NumberOfSections;j++,pSectionHeader++)
{
printf("%d\n",j);
memcpy((LPVOID)((DWORD)*ppBuffer+pSectionHeader->PointerToRawData),(LPVOID)((DWORD)pImageBuffer+pSectionHeader->VirtualAddress),pSectionHeader->SizeOfRawData);
}
printf("拷贝完成\n");
return SizeOfBuffer;
}
//存贮到新的exe 将内存数据存到硬盘
BOOL MemeryToFile(LPVOID pBuffer,DWORD SizeOfBuffer)
{
FILE* fpw=fopen("软件路径","wb");
if(!fpw)
{
printf("fpw error");
return false;
}
if (fwrite(pBuffer, 1, SizeOfBuffer, fpw) == 0)
{
printf("fpw fwrite fail");
return false;
}
fclose(fpw);
fpw = NULL;
printf("success\n");
return true;
}
int main()
{
LPVOID pFileBuffer=NULL;
LPVOID* ppFileBuffer=&pFileBuffer;
LPVOID pImageBuffer=NULL;
LPVOID* ppImageBuffer=&pImageBuffer;
DWORD SizeOfFileBuffer=0;
DWORD SizeOfImageBuffer=0;
DWORD SizeOfBuffer=0;
LPVOID pBuffer=NULL;
LPVOID* ppBuffer=&pBuffer;
//调用filebuffer函数
SizeOfFileBuffer=ReadPEFile(ppFileBuffer);
if(!SizeOfFileBuffer)
{
printf("FileBuffer函数调用失败 \n");
return 0;
}
pFileBuffer=*ppFileBuffer;
printf("ni ma de");
//调用FileBufferToImageBuffer函数
SizeOfBuffer=FileBufferToImageBuffer(pFileBuffer,ppImageBuffer);
if(!SizeOfBuffer)
{
printf("调用FileBufferToImageBuffer函数失败");
return 0;
}
//调用ShellCode函数
pImageBuffer=shellCode(pImageBuffer);
//调用ImageBufferToBuffer
SizeOfBuffer=ImageBufferToFileBuffer(pImageBuffer,ppBuffer);
pBuffer=*ppBuffer;
if(!SizeOfBuffer)
{
printf("SizeOfBuffer error");
return 0;
}
//调用MemeryToFile
if(MemeryToFile(pBuffer,SizeOfBuffer)==false) //pBuffer为存盘的起始位置,SizeOfBuffer为要存盘的大小
{
printf("end");
return 0;
}
return 0;
}
合并节与扩大节

从 filebuffer拷贝到imagebuffer(文件中而非内存中):首先根据sizeofimage决定需要在内存中分多大的空间,然后首先拷贝头+节表按照对齐的方式拷贝过去,然后拷贝节,根据PointerToRawData决定从哪里开始拷贝,拷贝到imagebuffer的位置由 VirtualAddress+imagebase决定, 内存中运行时,imagebuffer的值变为imagebase
拷贝的大小在Misc的SizeOfRawData,
在imagebuffer中的某个地址映射到filebuffer 首先根据该地址 - imagebuffer 得到偏移量a,
如果a > VirtualAddress 并且 a < VirtualAddress + misc.VirtualSize 则该地址位于VirtualAddress对应的节中,
a - VirtualAddress 得到该地址距离该节开始地址的偏移,那么在文件中的映射相对于节的偏移也是 a - VirtualAddress
//将所有节合并为一个节
#include "windows.h"
#include "stdio.h"
VOID h3202()
{
char FilePath[] = "CrackHead.exe"; //CRACKME.EXE CrackHead.exe
char CopyFilePath[] = "CrackHeadcopy.exe"; //CRACKMEcopy.EXE CrackHeadcopy.exe
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
LPVOID pImageBuffer = NULL;; //会被函数改变的 函数输出之一
LPVOID* ppImageBuffer = &pImageBuffer; //传进函数的形参
int SizeOfFileBuffer;
int SizeOfImageBuffer;
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pFileHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
PIMAGE_SECTION_HEADER pFirstSectionHeader = NULL;
PIMAGE_SECTION_HEADER pEndOfSectionHeader = NULL;
DWORD CallX = NULL; //即E8后跟的4字节
DWORD JmpX = NULL; //即E9后跟的4字节
//pFileBuffer即指向已装载到内存中的exe首部
if (!ReadPEFile(FilePath, ppFileBuffer))
{
printf("文件读取失败\n");
return;
}
SizeOfImageBuffer = CopyFileBufferToImageBuffer(pFileBuffer, ppImageBuffer);
//VerifyFileBufferAndImageBuffer(pFileBuffer, pImageBuffer);
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pImageBuffer; // 强转 DOS_HEADER 结构体指针
//NT头
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pImageBuffer + pDosHeader->e_lfanew);
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)(((DWORD)pNTHeader) + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);//SIZEOF_FILE_HEADER为固定值且不存在于PE文件字段中
//首个节表 可选PE头加上标准PE头里的可选PE头大小SizeOfOptionalHeader
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
pFirstSectionHeader = pSectionHeader;
//修改首个节表长度信息
//printf("SizeOfImageBuffer:%x\nVirtualAddress:%x\n", SizeOfImageBuffer, pFirstSectionHeader->VirtualAddress);
pFirstSectionHeader->SizeOfRawData = Align(SizeOfImageBuffer -
pFirstSectionHeader->VirtualAddress,pOptionalHeader->FileAlignment);
//printf("SizeOfRawData:%x\n", pFirstSectionHeader->SizeOfRawData);
pFirstSectionHeader->Misc.VirtualSize = pFirstSectionHeader->SizeOfRawData;//将第一个节的内存与文件大小相等
//printf("VirtualSize:%x\n", pFirstSectionHeader->Misc.VirtualSize);
//修改首节表Characteristics
DWORD Characteristics = pSectionHeader->Characteristics;
pSectionHeader++;
for (int i = 2; i <= pFileHeader->NumberOfSections; i++, pSectionHeader++) //注意从第二个开始
{
Characteristics = Characteristics | pSectionHeader->Characteristics;
memset(pSectionHeader, 0, IMAGE_SIZEOF_SECTION_HEADER); //抹去其他节表信息
}
//出循环后pSectionHeader指向节表末尾
pFirstSectionHeader->Characteristics = Characteristics;
pEndOfSectionHeader = pSectionHeader;
printf("Characteristics:%x\n", pFirstSectionHeader->Characteristics);
//修改节数量
pFileHeader->NumberOfSections = 1;
//拷贝到文件
free(pFileBuffer);
SizeOfFileBuffer = CopyImageBufferToFileBuffer(pImageBuffer, ppFileBuffer);
MemeryToFile(pFileBuffer, SizeOfFileBuffer, CopyFilePath);
}
//**************************************************************************
//Align:计算对齐后的值
//参数说明:
//x 需要进行对齐的值
//Alignment 对齐大小
//返回值说明:
//返回x进行Alignment值对齐后的值
//**************************************************************************
int Align(int x, int Alignment)
{
if (x%Alignment==0)
{
return x;
}
else
{
return (1 + (x / Alignment)) * Alignment;
}
}
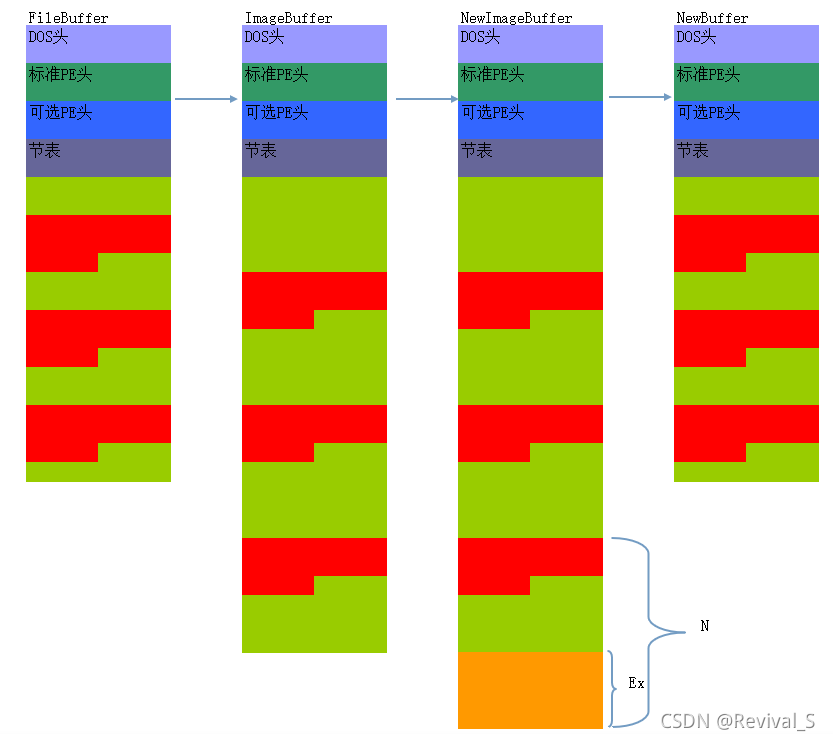
扩大节
--只能扩大最后一个
1、拉伸到内存(只是逻辑上,实际代码操作并不需要这一步),需要注入的代码为 ShellCode
2、分配一块新的空间NewImageBuffer:SizeOfImage + sizeof ( ShellCode) --Ex
3、扩大节,修改最后一个节的 SizeOfRawData 和 VirtualSize
OrgSecSize = max ( SizeOfRawData 或 VirtualSize内存对齐后的值 )
∵ 有些初始化数据未全部写入文件,VirtualSize 可能比 SizeOfRawData 大,必须保证添加的代码不影响到原程序
VirtualSize = OrgSecSize + sizeof ( ShellCode)
SizeOfRawData = ( OrgSecSize + sizeof(ShellCode) ) 按文件对齐后的值
4、修改SizeOfImage大小
SizeOfImage = SizeOfImage + Ex(即sizeof ( ShellCode))
//扩大节
#include "windows.h"
#include "stdio.h"
#define MESSAGEBOXADDR 0x76AF39A0 //这个值需要将任一exe文件拖入OD打开,搜索bp MessageBoxA 记录它的地址到这里(每次开机都不同)
unsigned char ShellCode320[] =
{
0x6A,0x00,0x6A,0x00,0x6A,0x00,0x6A,0x00,
0xE8,0x00,0x00,0x00,0x00,
0xE9,0x00,0x00,0x00,0x00
};
void h320()
{
char FilePath[] = "CrackHead.exe"; //CRACKME.EXE CrackHead.exe
char CopyFilePath[] = "CrackHeadcopy.exe"; //CRACKMEcopy.EXE CrackHeadcopy.exe
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
LPVOID pNewFileBuffer = NULL;
int SizeOfFileBuffer;
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pFileHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
DWORD CallX = NULL; //即E8后跟的4字节
DWORD JmpX = NULL; //即E9后跟的4字节
SizeOfFileBuffer = ReadPEFile(FilePath, ppFileBuffer); //pFileBuffer即指向已装载到内存中的exe首部
if (!SizeOfFileBuffer)
{
printf("文件读取失败\n");
return;
}
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//NT头
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pFileBuffer + pDosHeader->e_lfanew);
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)(((DWORD)pNTHeader) + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);//SIZEOF_FILE_HEADER为固定值且不存在于PE文件字段中
//首个节表
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
for (int i = 1; i < pFileHeader->NumberOfSections; i++, pSectionHeader++){} //注意这里i从1开始 i < NumberOfSections
//出循环后pSectionHeader指向最后一个节表
// OrgSecSize 为 该节的原始大小 (最后一个节的原始大小)
printf("VirtualSize: %x\nSizeOfRawData: %x\n", pSectionHeader->Misc.VirtualSize, pSectionHeader->SizeOfRawData);
DWORD OrgSecSize = max(pSectionHeader->Misc.VirtualSize, pSectionHeader->SizeOfRawData);
printf("OrgSecSize: %x\n", OrgSecSize);
//ShallCode即放在节区头起Size之后,这里先计算地址,再修改PE中的值与开辟空间
//X即E8后的数 = 要跳转的地址 - (E8所在地址 + 5) (E8 所在地址+5 即 call指令的下一条指令的地址)
//那么要跳转的地址即messageboxA地址。E8所在地址即 ImageBase内存运行基址 + VirtualAddress节所在偏移+Size +8 才到E8 (∵ShallCode就在节开头)
CallX = MESSAGEBOXADDR - (pOptionalHeader->ImageBase + pSectionHeader->VirtualAddress + OrgSecSize + 8 + 5); // 8 为E8在shellcode的偏移
//jump 要跳转的地址即OEP程序入口点, X = 程序入口点 - (E9所在地址 + 5)
//这里程序入口点即ImageBase基址 + 修改前的OddAddressOfEntryPoint E9所在地址计算同上 下式是化简后约去了ImageBase
//ImageBase + AddressOfEntryPoint - (ImageBase + VirtualAddress +13 +5 )
JmpX = pOptionalHeader->AddressOfEntryPoint - (pSectionHeader->VirtualAddress + OrgSecSize + 13 + 5);
//将上述计算后的值放入ShellCode320
*(PDWORD)(ShellCode320 + 9) = CallX;
*(PDWORD)(ShellCode320 + 14) = JmpX;
for (int i = 0; i < sizeof(ShellCode320); i++)
{
printf("%x ", ShellCode320[i]);
}
printf("\n");
//计算完地址后 计算新节表值 VirtualSize以Size + ShellCode长度 按内存对齐(其实VirtualSize可以不用内存对齐),SizeOfRawData同理
int NewVirtualSize = OrgSecSize + sizeof(ShellCode320);
int NewSizeOfRawData = Align(OrgSecSize + sizeof(ShellCode320), pOptionalHeader->FileAlignment);
printf("NewSizeOfRawData%x, NewVirtualSize:%x\n", NewSizeOfRawData, NewVirtualSize);
// 在修改节表值之前需要用到新旧值 ∴上述节表新值暂不真正修改只作记录。
// 修改SizeOfImage值
pOptionalHeader->SizeOfImage = Align(pSectionHeader->VirtualAddress + NewVirtualSize, pOptionalHeader->SectionAlignment);
//在修改节表值之前新空间长度 原空间长度 减去 旧SizeOfRawData 加上新SizeOfRawData
int SizeOfNewFileBuffer = SizeOfFileBuffer - pSectionHeader->SizeOfRawData + NewSizeOfRawData;
//修改入口点 pSectionHeader指向最后一个节表 OrgSecSize为最后一个节的原始大小 此时pOptionalHeader为添加的shellcode
pOptionalHeader->AddressOfEntryPoint = pSectionHeader->VirtualAddress + OrgSecSize;//最后一个节偏移+大小,即插入的shellcode代码
//Characteristics
printf("Characteristics:%x\n", pSectionHeader->Characteristics);
pSectionHeader->Characteristics = pSectionHeader->Characteristics | 0x60000020;
printf("Characteristics:%x\n", pSectionHeader->Characteristics);
//修改最后一个节表值
pSectionHeader->Misc.VirtualSize = NewVirtualSize;
pSectionHeader->SizeOfRawData = NewSizeOfRawData;
//printf("VirtualSize: %x\nSizeOfRawData: %x\n", pSectionHeader->Misc.VirtualSize, pSectionHeader->SizeOfRawData);
//修改值后开始重新分配空间
pNewFileBuffer = malloc(SizeOfNewFileBuffer);
memset(pNewFileBuffer, 0, SizeOfNewFileBuffer);
memcpy(pNewFileBuffer, pFileBuffer, SizeOfFileBuffer); //复制原空间
printf("SizeOfFileBuffer:%x\nSizeOfNewFileBuffer:%x\n", SizeOfFileBuffer, SizeOfNewFileBuffer);
// 复制新空间
memcpy((void*)((DWORD)pNewFileBuffer + pSectionHeader->PointerToRawData + OrgSecSize), ShellCode320, sizeof(ShellCode320));
//memcpy((void*)((DWORD)pNewFileBuffer + SizeOfFileBuffer), ShellCode320, sizeof(ShellCode320)); //复制ShellCode
//剩余部分填充0
//memset((void*)((DWORD)pNewFileBuffer + SizeOfFileBuffer + sizeof(ShellCode320)), 0, (SizeOfNewFileBuffer - SizeOfFileBuffer - sizeof(ShellCode320)));
MemeryToFile(, SizeOfNewFileBuffer, CopyFilePath);
free(pNewFileBuffer);
free(pFileBuffer);
}
新增节

1、判断是否有足够的空间,可以添加一个节表.
判断条件:
1、判断是否有足够的空间,可以添加一个节表(40个字节 28h).新增节后面加一个全0的节,所以共需80个字节
判断条件:SizeOfHeader - (DOS + 垃圾数据 + PE标记 + 标准PE头 + 可选PE头 + 已存在节表) >= 2个节表的大小 (如果只有一个节表以上的空间也可以加不会报错,但是会有安全隐患)
2、需要修改的数据
- 添加一个新的节表(可以copy一份可执行的.text节表)
- 在新增节后面 填充一个节大小的000
- 修改PE头中节的数量
- 修改sizeOfImage的大小
- 在原有数据的最后,新增一个节的数据(内存对齐的整数倍)
- 修正新增节表的属性
(1)首先判断头部的空白区够不够加节表, 所有的节表后面必须跟40个字节0。所以添加节表时得确保有两个节表大小(即80字节)的连续剩余。
分三种情况:
a.头部的最后一个节表后直接可以放下两个节区
b.节表后放不下,但是dos头后 标准PE头前的一堆垃圾数据可以放下,可以修改e_lfnew
c.前两种情况都不行,需扩大最后一个节把代码填进去
(2)新增节需要修改的内容:
SizeOfImage
NumOfSections
节表内属性
(3) 在内存中添加新的节表时,需要注意:
新增节表中的VirtualAddress(内存中的偏移)必须它上一个节表中VirtualAddress+max(VirtualSize,SizeOfRawData)
(注意: 不一定SizeOfRawData比VirtualSize大)
新增节表中的PoinTtoRawData(文件中的偏移)是最后一个节表中的PointToRawData(文件偏移)+SizeOfRawData(文件大小)
-
需要修改的属性
-
添加一个新的节表(可以直接copy 可执行的.text段,)
-
修改标准PE头的NumberOfSection
-
修改sizeOfImage(+1000,可选PE头里)
-
-
我们怎么修改新的节表的属性
-
VirtualSize的修正:跟内存对齐相等即可,内存对齐的倍数就行,可以直接修改为自己加的节的Size
-
VirtualAddress的修正:看上一个节表的属性,如果文件对齐和内存对齐相等,就等于上一个节的VirtualAdress+RawSize,如果文件和内存对齐不相等,就等于上一个节的VirtualAdress+RawSize(内存对齐后的大小)
-
SizeOfRaw的修正:和VirtualSize一样即可。
-
PointToRawData的修正:上一个节的PointToRawData+SizeOfRaw
-
-
写代码的时候要注意节表的遍历,清楚这是第几个节表,增加完没有?
-
文件对齐和内存对齐不一样的时候,我们可以做一个循环,让他累加,直到内存对齐的倍数
#include "stdafx.h"
#include<stdio.h>
#include<windows.h>
#include<malloc.h>
#define ShellCodeIen 0x12
#define MessageBoxAdder 0x77D507EA
BYTE ShellCode[]=
{
0x6A,00,0x6A,00,0x6A,00,0x6A,00,
0xE8,00,00,00,00,
0xE9,00,00,00,00
};
//这里只是新增了个节表,并没有加具体的内容
//FileBuffer函数
DWORD ReadPEFile(LPVOID* ppFileBuffer)
{
FILE* pFile=NULL;
DWORD SizeFileBuffer=0;
pFile=fopen("C://Documents and Settings//ma_lic//桌面//IISPutScanner.exe","rb");
if(!pFile)
{
printf("打开notepad失败\n");
return 0;
}
//获取文件大小
fseek(pFile,0,SEEK_END);
SizeFileBuffer=ftell(pFile);
fseek(pFile,0,SEEK_SET);
if(!SizeFileBuffer)
{
printf("读取文件大小失败\n");
return 0;
}
//开辟空间
*ppFileBuffer=malloc(SizeFileBuffer);
if(!*ppFileBuffer)
{
printf("开辟空间失败\n");
fclose(pFile);
return 0;
}
//复制数据
size_t n=fread(*ppFileBuffer,SizeFileBuffer,1,pFile);
if(!n)
{
printf("复制数据失败\n");
free(*ppFileBuffer);
fclose(pFile);
return 0;
}
fclose(pFile);
return SizeFileBuffer;
}
//FileBuffer--->ImgaeBuffer
DWORD FileBufferToImageBuffer(LPVOID pFileBuffer,LPVOID* ppImageBuffer)
{
PIMAGE_DOS_HEADER pDosHeader=NULL;
PIMAGE_NT_HEADERS pNTHeader=NULL;
PIMAGE_FILE_HEADER pFileHeader=NULL;
PIMAGE_OPTIONAL_HEADER pOptionalHeader=NULL;
PIMAGE_SECTION_HEADER pSectionHeader=NULL;
if(!pFileBuffer)
{
printf("FileBuffer函数调用失败\n");
return 0;
}
printf("%x\n",pFileBuffer);
//判断是否是PE文件
pDosHeader=(PIMAGE_DOS_HEADER)pFileBuffer;
if(pDosHeader->e_magic!=IMAGE_DOS_SIGNATURE)
{
printf("不是有效的MZ标志\n");
return 0;
}
pNTHeader=(PIMAGE_NT_HEADERS)((DWORD)pFileBuffer+pDosHeader->e_lfanew);
if(pNTHeader->Signature!=IMAGE_NT_SIGNATURE)
{
printf("不是有效的PE标志\n");
return 0;
}
pFileHeader=(PIMAGE_FILE_HEADER)(((DWORD)pNTHeader)+4);
pOptionalHeader=(PIMAGE_OPTIONAL_HEADER)((DWORD)pFileHeader+20);
//开辟ImageBuffer空间
*ppImageBuffer=malloc(pOptionalHeader->SizeOfImage+pOptionalHeader->SectionAlignment);//增加节才加上SectionAligement
if(!*ppImageBuffer)
{
printf("开辟ImageBuffer空间失败");
return 0;
}
printf("SizeOfImage%x\n",pOptionalHeader->SizeOfImage);
//malloc清零
memset(*ppImageBuffer,0,pOptionalHeader->SizeOfImage);
//复制Headers
printf("SizeOfHeader%x\n",pOptionalHeader->SizeOfHeaders);
memcpy(*ppImageBuffer,pDosHeader,pOptionalHeader->SizeOfHeaders);
//循环复制节表
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
for(int i=1;i<=pFileHeader->NumberOfSections;i++,pSectionHeader++)
{
memcpy((LPVOID)((DWORD)*ppImageBuffer+pSectionHeader->VirtualAddress),(LPVOID)((DWORD)pFileBuffer+pSectionHeader->PointerToRawData),pSectionHeader->SizeOfRawData);
printf("%d\n",i);
}
printf("拷贝完成\n");
return pOptionalHeader->SizeOfImage;
}
//AddSection
LPVOID AddSection(LPVOID pImageBuffer)
{
if(!pImageBuffer)
{
printf("pImageBuffer参数传入失败\n");
return 0;
}
PIMAGE_DOS_HEADER pDosHeader=NULL;
PIMAGE_NT_HEADERS pNTHeader=NULL;
PIMAGE_FILE_HEADER pFileHeader=NULL;
PIMAGE_OPTIONAL_HEADER pOptionalHeader=NULL;
PIMAGE_SECTION_HEADER pSectionHeader=NULL;
PIMAGE_SECTION_HEADER pNewSectionTable=NULL;
pDosHeader=(PIMAGE_DOS_HEADER)pImageBuffer;
pNTHeader=(PIMAGE_NT_HEADERS)((DWORD)pImageBuffer+pDosHeader->e_lfanew);
pFileHeader=(PIMAGE_FILE_HEADER)((DWORD)pNTHeader+4);
pOptionalHeader=(PIMAGE_OPTIONAL_HEADER)((DWORD)pFileHeader+20);
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
//判断文件对齐和内存对齐
if(pOptionalHeader->FileAlignment==pOptionalHeader->SectionAlignment)
{
printf("文件对齐和内存对齐相等\n");
// 判断是否有足够的空间新增节表
DWORD SizeOfSectionTable=0x28; // 要加的节表为40个字节 但需要有80个字节的空白区
DWORD FreeBase=((DWORD)pOptionalHeader->SizeOfHeaders-((DWORD)pSectionHeader+pFileHeader->NumberOfSections*SizeOfSectionTable-(DWORD)pImageBuffer));
if(FreeBase<SizeOfSectionTable*2) //但需要有80个字节的空白区
{
printf("没有足够的空间新增节表!!!\n"); //可以把PE标记以下的PE头,可选PE头,节表整体上移,然后修改e_lfnew
free(pImageBuffer);
return 0;
}
printf("有足够的空间新增节表!!!\n");
//修改NumberOfSection
pFileHeader->NumberOfSections=pFileHeader->NumberOfSections+1;
printf("NumberOfSection=%d\n",pFileHeader->NumberOfSections);
//修改SizeOfImage
printf("SizeOfImage=%x\n",pOptionalHeader->SizeOfImage);
pOptionalHeader->SizeOfImage=pOptionalHeader->SizeOfImage+pOptionalHeader->SectionAlignment;
printf("SizeOfImage=%x\n",pOptionalHeader->SizeOfImage);
//这里就不同扩大ImageBuffer了,上面已经增加了
//填写新的节表(复制.text节表然后再修正)
pNewSectionTable=(PIMAGE_SECTION_HEADER)((DWORD)pSectionHeader+(pFileHeader->NumberOfSections-1)*SizeOfSectionTable);
//开始复制.text
memcpy(pNewSectionTable,pSectionHeader,SizeOfSectionTable);
//修正新的节表
//循环到倒数第二个节表
for(int i=1;i<pFileHeader->NumberOfSections-1;i++,pSectionHeader++)
{
printf("%d\n",i);
}
pNewSectionTable->Misc.VirtualSize=pOptionalHeader->SectionAlignment;
printf("%x\n",pNewSectionTable->Misc.VirtualSize);
pNewSectionTable->VirtualAddress=pSectionHeader->VirtualAddress+
max(pSectionHeader->SizeOfRawData,pSectionHeader->VirtualSize);
printf("%x\n",pNewSectionTable->VirtualAddress);
pNewSectionTable->SizeOfRawData=pOptionalHeader->SectionAlignment;
printf("%x\n",pNewSectionTable->SizeOfRawData);
pNewSectionTable->PointerToRawData=pSectionHeader->PointerToRawData+pSectionHeader->SizeOfRawData;
printf("%x\n",pNewSectionTable->PointerToRawData);
printf("新的节表修正完成!!!\n");
return pImageBuffer;
}
else
{
printf("内存对齐和文件对齐不相等\n");
printf("文件对齐和内存对齐相等\n");
// 判断是否有足够的空间新增节表
DWORD SizeOfSectionTable=0x28;
DWORD FreeBase=((DWORD)pOptionalHeader->SizeOfHeaders-((DWORD)pSectionHeader+pFileHeader->NumberOfSections*SizeOfSectionTable-(DWORD)pImageBuffer));
if(FreeBase<SizeOfSectionTable*2)
{
printf("没有足够的空间新增节表!!!\n");
free(pImageBuffer);
return 0;
}
printf("有足够的空间新增节表!!!\n");
//修改NumberOfSection
pFileHeader->NumberOfSections=pFileHeader->NumberOfSections+1;
printf("NumberOfSection=%d\n",pFileHeader->NumberOfSections);
//修改SizeOfImage
printf("SizeOfImage=%x\n",pOptionalHeader->SizeOfImage);
pOptionalHeader->SizeOfImage=pOptionalHeader->SizeOfImage+pOptionalHeader->SectionAlignment;
printf("SizeOfImage=%x\n",pOptionalHeader->SizeOfImage);
//这里就不用扩大ImageBuffer了,上面已经增加了
//填写新的节表(复制.txt节表然后再修正)
pNewSectionTable=(PIMAGE_SECTION_HEADER)((DWORD)pSectionHeader+(pFileHeader->NumberOfSections-1)*SizeOfSectionTable);
//开始复制.text
memcpy(pNewSectionTable,pSectionHeader,SizeOfSectionTable);
//修正新的节表
//循环到倒数第二个节表
for(int i=1;i<pFileHeader->NumberOfSections-1;i++,pSectionHeader++)
{
printf("%d\n",i);
}
pNewSectionTable->Misc.VirtualSize=pOptionalHeader->SectionAlignment;
printf("%x\n",pNewSectionTable->Misc.VirtualSize);
DWORD RawSize=pSectionHeader->SizeOfRawData;
printf("%x????\n",RawSize);
//这里因为文件对齐和内存对齐不一样,所以需要对齐
while(RawSize%pOptionalHeader->SectionAlignment!=0)
{
RawSize++;
//printf("RawSize=%x\n",RawSize);
}
pNewSectionTable->VirtualAddress=pSectionHeader->VirtualAddress+RawSize;
printf("%x\n",pNewSectionTable->VirtualAddress);
pNewSectionTable->SizeOfRawData=pOptionalHeader->SectionAlignment;
printf("%x\n",pNewSectionTable->SizeOfRawData);
// 新增节的PointerToRawData 等于 之前最后一个节的PointerToRawData + 这个节的SizeOfRawData
pNewSectionTable->PointerToRawData=pSectionHeader->PointerToRawData+pSectionHeader->SizeOfRawData;
printf("%x\n",pNewSectionTable->PointerToRawData);
printf("新的节表修正完成!!!\n");
return pImageBuffer;
}
}
//ImageBufferToFileBuffer
DWORD ImageBufferToFileBuffer(LPVOID pImageBuffer,LPVOID* ppBuffer)
{
PIMAGE_DOS_HEADER pDosHeader=NULL;
PIMAGE_NT_HEADERS pNTHeader=NULL;
PIMAGE_FILE_HEADER pFileHeader=NULL;
PIMAGE_OPTIONAL_HEADER pOptionalHeader=NULL;
PIMAGE_SECTION_HEADER pSectionHeader=NULL;
if(!pImageBuffer)
{
printf("error");
return 0;
}
pDosHeader=(PIMAGE_DOS_HEADER)pImageBuffer;
pNTHeader=(PIMAGE_NT_HEADERS)((DWORD)pImageBuffer+pDosHeader->e_lfanew);
pFileHeader=(PIMAGE_FILE_HEADER)((DWORD)pNTHeader+4);
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER)((DWORD)pFileHeader + 20);
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
//得到FileBuffer的大小
for(int i=1;i<pFileHeader->NumberOfSections;i++,pSectionHeader++)
{
printf("%d\n",i);
}
printf("numberofsection=%d\n",pFileHeader->NumberOfSections);
printf("%x\n",pSectionHeader->Misc.VirtualSize);
printf("%x\n",pSectionHeader->VirtualAddress);
printf("%x\n",pSectionHeader->SizeOfRawData);
printf("%x\n",pSectionHeader->PointerToRawData);
//循环到最后一个节表
DWORD SizeOfBuffer=pSectionHeader->PointerToRawData+pSectionHeader->SizeOfRawData;
printf("SizeOfBuffer=%x\n",SizeOfBuffer);
//开辟空间
*ppBuffer=malloc(SizeOfBuffer);
if(!*ppBuffer)
{
printf("开辟Buffer空间失败\n");
return 0;
}
memset(*ppBuffer,0,SizeOfBuffer);
//复制头
memcpy(*ppBuffer,pImageBuffer,pOptionalHeader->SizeOfHeaders);
//复制节表
pSectionHeader=(PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader+pFileHeader->SizeOfOptionalHeader);
printf("woc\n");
for(int j=1;j<=pFileHeader->NumberOfSections;j++,pSectionHeader++)
{
printf("%d\n",j);
memcpy((LPVOID)((DWORD)*ppBuffer+pSectionHeader->PointerToRawData),(LPVOID)((DWORD)pImageBuffer+pSectionHeader->VirtualAddress),pSectionHeader->SizeOfRawData);
}
printf("拷贝完成\n");
return SizeOfBuffer;
}
//存贮到新的exe
BOOL MemeryToFile(LPVOID pBuffer,DWORD SizeOfBuffer)
{
FILE* fpw=fopen("C://Documents and Settings//ma_lic//桌面//NEWSECIISPutScanner.exe","wb");
if(!fpw)
{
printf("fpw error");
return false;
}
if (fwrite(pBuffer, 1, SizeOfBuffer, fpw) == 0)
{
printf("fpw fwrite fail");
return false;
}
fclose(fpw);
fpw = NULL;
printf("success\n");
return true;
}
int main()
{
LPVOID pFileBuffer=NULL;
LPVOID* ppFileBuffer=&pFileBuffer;
LPVOID pImageBuffer=NULL;
LPVOID* ppImageBuffer=&pImageBuffer;
DWORD SizeOfFileBuffer=0;
DWORD SizeOfImageBuffer=0;
DWORD SizeOfBuffer=0;
LPVOID pBuffer=NULL;
LPVOID* ppBuffer=&pBuffer;
//调用filebuffer函数
SizeOfFileBuffer=ReadPEFile(ppFileBuffer);
if(!SizeOfFileBuffer)
{
printf("FileBuffer函数调用失败 \n");
return 0;
}
pFileBuffer=*ppFileBuffer;
printf("ni ma de");
//调用FileBufferToImageBuffer函数
SizeOfBuffer=FileBufferToImageBuffer(pFileBuffer,ppImageBuffer);
if(!SizeOfBuffer)
{
printf("调用FileBufferToImageBuffer函数失败");
return 0;
}
//调用AddSection函数
pImageBuffer=AddSection(pImageBuffer);
//调用ImageBufferToBuffer
SizeOfBuffer=ImageBufferToFileBuffer(pImageBuffer,ppBuffer);
pBuffer=*ppBuffer;
if(!SizeOfBuffer)
{
printf("SizeOfBuffer error");
return 0;
}
//调用MemeryToFile
if(MemeryToFile(pBuffer,SizeOfBuffer)==false)
{
printf("end");
return 0;
}
return 0;
}
//新增节另一种写法
//**************************************************************************
//AddNewSection:新增节,可能含有头抬升。函数将保存新增节后的文件
//参数说明:
//pFileBuffer:FileBuffer指针
//SizeOfFileBuffer:pFileBuffer指向的大小,也即FileBuffer大小
//SizeOfNewSectio:新增节的大小
//pNewFileBuffer:返回指向新FileBuffer的指针
//返回值说明:
//新FileBuffer的大小,NewFileBuffer的大小
//**************************************************************************
int AddNewSection(IN LPVOID pFileBuffer,IN int SizeOfFileBuffer,IN DWORD SizeOfNewSection, OUT LPVOID* ppNewFileBuffer)
{
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pFileHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
PIMAGE_SECTION_HEADER pLastSectionHeader = NULL; //指向最后一个节表
PIMAGE_SECTION_HEADER pNewSectionHeader = NULL; //指向最后一个节表的下一个节表,即不存在的节表作为新开辟的节表
bool isUplift = false;
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);
//首个节表
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
for (int i = 1; i < pFileHeader->NumberOfSections; i++, pSectionHeader++) //注意这里i从1开始 i < NumberOfSections
{
} //出循环后pSectionHeader指向最后一个节表
pLastSectionHeader = pSectionHeader;
pNewSectionHeader = pLastSectionHeader + 1;
//节表结束的位置+两个节表的大小 仍然≤ 头大小,才可继续。插一个留两个为了插入一个新节表后仍有一个节表的位置填充0
if ((DWORD)pNewSectionHeader + IMAGE_SIZEOF_SECTION_HEADER * 2 <= (DWORD)pFileBuffer + pOptionalHeader->SizeOfHeaders)
{ //要节表后留出两个节表的空位且全为0,保证其中没有可能使用的数据,才允许插入新节表。
PBYTE pTemp = (PBYTE)pNewSectionHeader;
for (int i = 0; i < IMAGE_SIZEOF_SECTION_HEADER * 2; i++, pTemp++)
{
if (*pTemp)
{
printf("节表插入空位存在数据,需进行头抬升\n");
isUplift = true;
break;
}
}
}
else
{
printf("无节表插入空位,需进行头抬升\n");
isUplift = true;
}
//isUplift = true; //头抬升测试 需要修改e_lfanew
if (isUplift)
{
if ((DWORD)pFileBuffer + sizeof(IMAGE_DOS_HEADER) - (DWORD)pNTHeader >= IMAGE_SIZEOF_SECTION_HEADER * 2)
{
printf("可抬升NT头\n");
//开始拷贝,将NT头拷贝到DOS头结束之后,长度为NT头开始到最后一个节表结束时的长度,即pNewSectionHeader
memcpy((void*)((DWORD)pFileBuffer + sizeof(IMAGE_DOS_HEADER)), pNTHeader, (DWORD)pNewSectionHeader - (DWORD)pNTHeader);
//拷贝后重置e_lfanew位置
//printf(" e_lfanew: %x\n", pDosHeader->e_lfanew);
pDosHeader->e_lfanew = sizeof(IMAGE_DOS_HEADER);
//printf("e_lfanew: %x\n", pDosHeader->e_lfanew);
//抬升后更新所有被抬升的头指针
//NT头
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pFileBuffer + pDosHeader->e_lfanew);
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)(((DWORD)pNTHeader) + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);//SIZEOF_FILE_HEADER为固定值且不存在于PE文件字段中
//首个节表
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
for (int i = 1; i < pFileHeader->NumberOfSections; i++, pSectionHeader++) //注意这里i从1开始 i < NumberOfSections
{
} //出循环后pSectionHeader指向最后一个节表
pLastSectionHeader = pSectionHeader;
pNewSectionHeader = pLastSectionHeader + 1;
//验证代码,判断是否是有效的PE标志
if (*((PDWORD)((DWORD)pFileBuffer + pDosHeader->e_lfanew)) != IMAGE_NT_SIGNATURE) //基址pFileBuffer + lfanew 为 NTHeader首址
{
printf("抬升后验证失败,不是有效的PE标志\n");
return 0;
}
printf("抬升成功!\n");
//抬升成功后将最后一个节表后两个节表位置的空间置零
memset(pNewSectionHeader, 0, IMAGE_SIZEOF_SECTION_HEADER * 2);
}
else
{
printf("不可抬升NT头,不可插入节表\n");
free(pFileBuffer);
return 0;
}
}
//开始构造新节表
printf("可插入节表\n");
strcpy((char*)pNewSectionHeader->Name, (char*)".NewSec");
//printf("Name:%s\n", pNewSectionHeader->Name);
pNewSectionHeader->Misc.VirtualSize = SizeOfNewSection;
//节区在内存中的偏移 = 内存中整个PE文件映射的大小
pNewSectionHeader->VirtualAddress = pOptionalHeader->SizeOfImage;
//节区在文件对齐中的大小 以VirtualSize内存对齐向上取整
printf("FileAlignment:%x\n", pOptionalHeader->FileAlignment);
pNewSectionHeader->SizeOfRawData = Align(SizeOfNewSection, pOptionalHeader->FileAlignment);
printf("SizeOfRawData:%x\n", pNewSectionHeader->SizeOfRawData);
//节区在文件中的偏移 = 文件大小 (也可以是最后一个节区所在文件中位置 + 最后一个节区在文件对齐中的大小)二者一致
pNewSectionHeader->PointerToRawData = SizeOfFileBuffer;//pLastSectionHeader->PointerToRawData + pLastSectionHeader->SizeOfRawData;
//printf("PointerToRawData:%x\n",pNewSectionHeader->PointerToRawData);
pNewSectionHeader->PointerToRelocations = 0;
//printf("PointerToRelocations:%x\n", pNewSectionHeader->PointerToRelocations);
pNewSectionHeader->PointerToLinenumbers = 0;
pNewSectionHeader->NumberOfRelocations = 0;
pNewSectionHeader->NumberOfLinenumbers = 0;
pNewSectionHeader->Characteristics = 0xe0000060;
//新节表构造完毕, 修改节的数量
pFileHeader->NumberOfSections++;
//修改sizeOfImage的大小
//节区在内存对齐中的大小 以VirtualSize内存对齐向上取整,对齐后加到SizeOfImage中
printf("SectionAlignment: %x\nSizeOfImage:%x\n", pOptionalHeader->SectionAlignment, pOptionalHeader->SizeOfImage);
pOptionalHeader->SizeOfImage += Align(SizeOfNewSection, pOptionalHeader->SectionAlignment);
printf("SizeOfImage:%x\n", pOptionalHeader->SizeOfImage);
//printf("Characteristics:%x\n", pNewSectionHeader->Characteristics);
//开辟节区新空间
int SizeOfNewFileBuffer = SizeOfFileBuffer + pNewSectionHeader->SizeOfRawData;
*ppNewFileBuffer = malloc(SizeOfNewFileBuffer);
//新节区之前的值全部复制,新节表部分已改变
memcpy(*ppNewFileBuffer, pFileBuffer, SizeOfFileBuffer);
//新节区全部置零
memset((void*)((DWORD)*ppNewFileBuffer + pNewSectionHeader->PointerToRawData), 0, pNewSectionHeader->SizeOfRawData);
return SizeOfNewFileBuffer;
}
导出表
导出表在可选PE头的最后一个结构--目录项数组(16项)的第一个目录就是导出表,该结构只有两个属性,VirtualAddress和 Size(没用),之后可以不再拉伸,直接算偏移,将VirtualAddress (RVA)转换为FOA,再去文件中找具体的导出表结构。
导出表就是提供函数的,不一定只有dll才可以提供函数,exe也可以
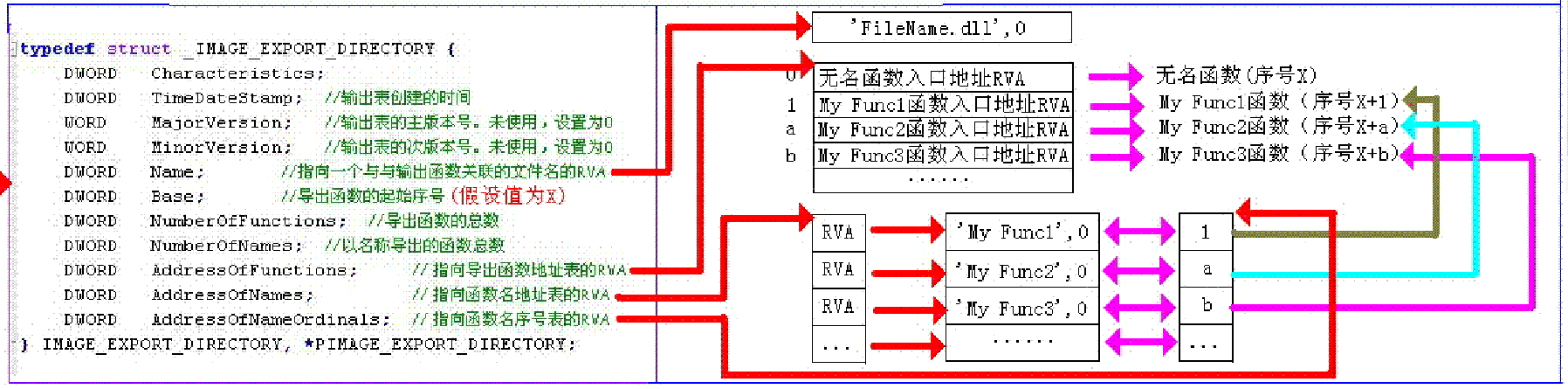

上图中,AddressOfNames指向一个数组,数组里保存着一组RVA,每个RVA指向一个字符串,这个字符串即导出的函数名,与这个函数名对应的是AddressOfNameOrdinals中的对应项。
获取导出函数地址时,先在AddressOfNames中找到对应的名字,(注意要将AddressOfNames的RVA转为FOA)比如Func2,他在AddressOfNames中是第二项,然后从AddressOfNameOrdinals中取出第二项的值,这里是2,表示函数入口保存在AddressOfFunctions这个数组中下标为2的项里,即第三项,取出其中的值,加上 模块基地址 便是导出函数的地址。
如果函数是以序号导出的,那么查找的时候直接用序号减去Base(见上上图X),得到的值就是函数在AddressOfFunctions中的下标。此时与AddressOfNameOrdinals这张表无关。函数地址表的下标从0开始。
注:序号表宽度为2
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
//以下重要
DWORD Name; // DLL的名称地址
DWORD Base; // 索引基数,序号 的基数,按序号导出函数的序号值从Base开始递增。
DWORD NumberOfFunctions; // 所有导出函数的数量,不一定准确,其值为序号最大-最小+1 若序号不连续则此值不准确
DWORD NumberOfNames; // 按函数名字导出的函数的数量。
DWORD AddressOfFunctions; //一个RVA,指向一个DWORD数组,数组中的每一项是一个导出函数的RVA,顺序与导出序号相同。
DWORD AddressOfNames; //一个RVA,依然指向一个DWORD数组,数组中的每一项仍然是一个RVA,指向一个表示函数名字。
//AddressOfNames与AddressOfFunctions大小可以不一样,有的把函数名字隐藏了
DWORD AddressOfNameOrdinals; //一个RVA,还是指向一个WORD数组,
//数组中的每一项与AddressOfNames中的每一项对应,表示该名字的函数在AddressOfFunctions中的序号
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
练习:
1、编写程序打印所有的导出表信息
2、编写函数 GetFunctionAddrByName ( FileBuffer指针,函数名指针)
3、编写函数 GetFunctionAddrByOrdinals ( FileBuffer指针,函数名导出序号)
//1、编写程序打印所有的导出表信息
#include "Currency.h"
#include "windows.h"
#include "stdio.h"
VOID h324() //输出导出表
{
char FilePath[] = "Dll1.dll"; //CRACKME.EXE CrackHead.exe
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_EXPORT_DIRECTORY pExportDirectory = NULL;
DWORD nameFOA = NULL;
DWORD AddressOfNamesFOA = NULL;
DWORD AddressOfNameOrdinalsFOA = NULL;
DWORD AddressOfFunctionsFOA = NULL;
DWORD AddressOfFunctions = NULL;
WORD Ordinal = NULL;
char * name = NULL;
DWORD result = NULL;
typedef int(*lpPlus)(int, int); //测试查找出的函数用
lpPlus myPlus;
if (!ReadPEFile(FilePath, ppFileBuffer))
{
printf("文件读取失败\n");
return;
}
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//可选PE头 简化后的处理
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4 + IMAGE_SIZEOF_FILE_HEADER);
//导出表
pExportDirectory = (PIMAGE_EXPORT_DIRECTORY)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress));
printf("DIRECTORY_ENTRY_EXPORT VirtualAddress:%x\n", pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress);
printf("FOA:%x\n", RVA2FOA(pFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress));
printf("导出表文件名字符串Name:%x\n", pExportDirectory->Name);
printf("导出函数起始序号Base:%d\n", pExportDirectory->Base);
printf("导出函数的个数:%d\n", pExportDirectory->NumberOfFunctions);
printf("以函数名字导出的函数个数NumberOfNames:%d\n", pExportDirectory->NumberOfNames);
printf("*******函数地址表*******\n");
AddressOfFunctionsFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfFunctions);
for (int i = 0; i < pExportDirectory->NumberOfFunctions; i++)
{ //因Address表元素为4字节,绝对地址加上i*4直接取第i个元素
AddressOfFunctions = *(PDWORD)((DWORD)pFileBuffer + AddressOfFunctionsFOA + i * 4);
printf("下标:%d,函数地址:%x\n", i, AddressOfFunctions);
}
printf("*******函数名称表*******\n");
//导出表中的AddressOfNames为Rva,将其转换为FOA得到AddressOfNamesFOA
AddressOfNamesFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfNames);
for (int i = 0; i < pExportDirectory->NumberOfNames; i++)
{ //AddressOfNamesFOA只是Names表的FOA地址,需加上pFileBuffer构成的绝对地址才能取出其中的值。
//取出的值即Names地址表第i个name的Rva地址,转成FOA得到name的FOA地址
nameFOA = RVA2FOA(pFileBuffer, *(PDWORD)((DWORD)pFileBuffer + AddressOfNamesFOA));
name = (char *)(nameFOA + (DWORD)pFileBuffer);//name的FOA加上pFileBuffer构成绝对地址,该地址才真正指向字符串
printf("下标:%d,函数名:%s\n", i, name);
AddressOfNamesFOA += 4; //往前走4字节,指向Names地址表下一个元素,即下一个name地址
}
printf("*******函数序号表*******\n");
AddressOfNameOrdinalsFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfNameOrdinals);//同Names表找法
for (int i = 0; i < pExportDirectory->NumberOfNames; i++)
{
Ordinal = *(PWORD)((DWORD)pFileBuffer + AddressOfNameOrdinalsFOA + i * 2); //因为Ordinal表元素为2字节,绝对地址加上i*2直接取第i个元素 序号表宽度为两个字节
printf("下标:%d,Ordinal序号:%d\n", i, Ordinal);
}
result = (DWORD)GetFunctionAddrByName(pFileBuffer, "Plus"); //得到的是函数Rva地址
printf("result:%x\n", result);
result = (DWORD)GetFunctionAddrByOrdinals(pFileBuffer, 2);
printf("result:%x\n", result);
}
//2、编写函数 GetFunctionAddrByName ( FileBuffer指针,函数名指针)
//**************************************************************************
//GetFunctionAddrByName:根据名字找到导出表中的函数地址
//参数说明:
//pFileBuffer:FileBuffer指针
//str: 函数名指针
//返回值说明:
//返回导出表中的函数地址
//**************************************************************************
LPVOID GetFunctionAddrByName(LPVOID pFileBuffer, char* str)
{
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_EXPORT_DIRECTORY pExportDirectory = NULL;
DWORD nameFOA = NULL;
DWORD AddressOfNamesFOA = NULL;
DWORD AddressOfNameOrdinalsFOA = NULL;
DWORD AddressOfFunctionsFOA = NULL;
WORD Ordinal = NULL;
char * name = NULL;
int i = 0;
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//可选PE头 简化后的处理
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4 + IMAGE_SIZEOF_FILE_HEADER);
//导出表
pExportDirectory = (PIMAGE_EXPORT_DIRECTORY)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress));
//printf("NumberOfNames:%d\n", pExportDirectory->NumberOfNames);
//导出表中的AddressOfNames为Rva,将其转换为FOA得到AddressOfNamesFOA
AddressOfNamesFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfNames);
for (i = 0; i < pExportDirectory->NumberOfNames; i++)
{ //AddressOfNamesFOA只是Names表的FOA地址,需加上pFileBuffer构成的绝对地址才能取出其中的值。
//取出的值即Names地址表第i个name的Rva地址,转成FOA得到name的FOA地址
nameFOA = RVA2FOA(pFileBuffer, *(PDWORD)((DWORD)pFileBuffer + AddressOfNamesFOA));
name = (char *)(nameFOA + (DWORD)pFileBuffer);//name的FOA加上pFileBuffer构成绝对地址,该地址才真正指向字符串
if (!strcmp(str, name)) //要查找名字为 str 的函数地址
{
break;
}
AddressOfNamesFOA += 4; //往前走4字节,指向Names地址表下一个元素,即下一个name地址
}
if (i == pExportDirectory->NumberOfNames)
{
printf("找不到名为%s的函数!\n", str);
return 0;
}
AddressOfNameOrdinalsFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfNameOrdinals);//同Names表找法
Ordinal = *(PWORD)((DWORD)pFileBuffer + AddressOfNameOrdinalsFOA + i*2); //因为Ordinal表元素为2字节,绝对地址加上i*2直接取第i个元素 找到名字为str的函数对应的序号为Ordinal
printf("i:%d,Ordinal:%d\n", i,Ordinal);
AddressOfFunctionsFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfFunctions);
//得到序号后,根据序号再去函数地址表中找对应的索引,注意这里的ordinal*4,因为在AddressOfFunctionsFOA一个序号对应四字节的地址
return (LPVOID)*(PDWORD)((DWORD)pFileBuffer + AddressOfFunctionsFOA + Ordinal * 4);//同上
}
//3、编写函数 GetFunctionAddrByOrdinals ( FileBuffer指针,函数名导出序号)
//**************************************************************************
//GetFunctionAddrByOrdinals:根据序号找到导出表中的函数地址
//参数说明:
//pFileBuffer:FileBuffer指针
//ord:函数序号
//返回值说明:
//返回导出表中的函数地址
//**************************************************************************
LPVOID GetFunctionAddrByOrdinals(LPVOID pFileBuffer, DWORD ord)
{
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_EXPORT_DIRECTORY pExportDirectory = NULL;
DWORD nameFOA = NULL;
DWORD AddressOfNameOrdinalsFOA = NULL;
DWORD AddressOfFunctionsFOA = NULL;
WORD Ordinal = NULL;
int i = 0;
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//可选PE头 简化后的处理
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4 + IMAGE_SIZEOF_FILE_HEADER);
//导出表
pExportDirectory = (PIMAGE_EXPORT_DIRECTORY)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress));
if (ord - pExportDirectory->Base >= pExportDirectory->NumberOfNames || ord - pExportDirectory->Base < 0)
{
printf("找不到序号为%d的函数!\n", ord);
return 0;
}
AddressOfFunctionsFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfFunctions);//导入表函数表地址转FOA
return (LPVOID)*(PDWORD)((DWORD)pFileBuffer + AddressOfFunctionsFOA + (ord - pExportDirectory->Base) * 4);//绝对地址 加上(ord-base)*4 直接取第ord-base个元素
}
重定位表
为什么需要重定位表

重定位表中每个块存储的是相对地址,偏移量
位置:可选PE头中数据目录项的第6个结构就是重定位表,注意该结构可能不止一个
typedef struct _IMAGE_BASE_RELOCATION {
DWORD VirtualAddress; //重定位内存页的起始RVA 就是下面的 X, 根据偏移去找要重定向的地址RVA,可以节省空间
DWORD SizeOfBlock; //重定位块的长度 单位是字节,可根据它确定下一块从什么时候开始
// WORD TypeOffset[1]; 后面跟的两字节的数据,有若干个,记录了有多少地方需要修复,16位,低12位地址 + X就是要修复的RVA
// 因为内存中的页大小为1000H,2^12就可以表示所有的页内地址
} IMAGE_BASE_RELOCATION;
//之所以有多个块,每个块给一个起始RVA 因为要重定位的地址有可能差距比较大 比如说一个块40000 一 个块60000 一个节有多个块


注:联合体不是连续的,分为块,每个块的前八个字节时确定的,后边的不确定,SizeOfBlock中存的Y即每一块的大小,每个块其实就是一个分页,把每一页中需要修改的东西放到一块里,根据基址 + 偏移 确定需要修改的位置
用12位就足以存储所需要的的内存大小,但由于内存对齐,需要16位,但真正需要修改的地址等于低12位+VirtualAddress存的X的值
最后一个结构的VirtualAddress和SizeOfBlock都为0,
具体项的数量 = (SizeOfBlock - 8) / 2,(整个块的大小 - 前八个字节)/ 2 除以2是因为每个项占两个字节,
#include "Currency.h"
#include "windows.h"
#include "stdio.h"
VOID h325() //打印重定向表所有内容
{
char FilePath[] = "Dll1.dll"; //CRACKME.EXE CrackHead.exe Dll1.dll R.DLL LoadDll.dll
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_BASE_RELOCATION pRelocationTable = NULL;
DWORD nameFOA = NULL;
DWORD AddressOfNamesFOA = NULL;
if (!ReadPEFile(FilePath, ppFileBuffer))
{
printf("文件读取失败\n");
return;
}
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//可选PE头 简化后的处理
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4 + IMAGE_SIZEOF_FILE_HEADER);
//重定向表
pRelocationTable = (PIMAGE_BASE_RELOCATION)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress));
printf("RelocationTable VirtualAddress:%x\n", pOptionalHeader
->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress);
if (!pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress)
{
printf("该文件没有重定向表!\n");
return;
}
int i = 1;
while ( pRelocationTable->VirtualAddress && pRelocationTable->SizeOfBlock)
{
printf("第%d个块VirtualAddress:%x\n", i, pRelocationTable->VirtualAddress);
printf("第%d个块SizeOfBlock:%x\n", i,pRelocationTable->SizeOfBlock);
printf("第%d个块项数:%d\n", i, (pRelocationTable->SizeOfBlock - 8)/2);
pRelocationTable = (PIMAGE_BASE_RELOCATION)(pRelocationTable->SizeOfBlock + (DWORD)pRelocationTable);
i++;
}
}
移动导出表
第一步:在DLL中新增一个节,并返回新增后的FOA
第二步:复制 AddressOfFunctions (函数地址表)进这个FOA的位置
长度:4*NumberOfFunctions (每个表项4字节)
第三步:复制 AddressOfNameOrdinals(函数序号表)注意是无缝衔接,接上面的位置继续复制
长度:NumberOfNames*2(每个表项2字节)
第四步:复制AddressOfNames (函数名称表) 同样无缝衔接,下同
长度:NumberOfNames*4 (每个表项4字节)
第五步:复制所有的函数名字符串(长度不确定)
长度不确定,注意:复制时需要修复 AddressOfNames 逐个指向这些字符串首址
第六步:复制IMAGE_EXPORT_DIRECTORY结构
第七步:修复IMAGE_EXPORT_DIRECTORY结构中的
AddressOfFunctions
AddressOfNameOrdinals
AddressOfNames
第八步:修复目录项中的 VirtualAddress 值,指向新的 IMAGE_EXPORT_DIRECTORY
这里要梳理清楚在移动过程中的各个参数,在什么时候转换为FOA,什么时候转换为RVA。
定位导出表的地址时,需要将IMAGE_SECTION_HEADER[0].VirtualAddress的RVA->FOA,以便于在文件中定位导出表的地址。
在移动导出表的AddressOfFunction、AddressOfNameOrdinals、AddressOfNames时,需要将RVA->FOA以便于在文件中复制
在移动AddressOfNames中的地址指向的函数名字符串时,要将AddressOfNames中的地址RVA->FOA,并且在移动完后,修改AddressOfNames中存储的地址时,要FOA->RVA。
将导出表中的AddressOfFunctions、AddressOfNameOrdinals、AddressOfNames 地址修改为新复制的对应的地址时,要将新复制的对应的地址FOA->RVA。
修复数据目录项中的VirualAddress时,要将新复制的导出表的存储地址FOA->RVA
上述流程大致为下图所示:(主要还是理解文字)
#include "Currency.h"
#include "windows.h"
#include "stdio.h"
VOID h3261() //移动导出表的全部内容到新节,包括函数地址表,名称表,序号表。 修改完后的Dll仍然好使
{
char FilePath[] = "Dll1.dll"; //CRACKME.EXE CrackHead.exe
char CopyFilePath[] = "Dll12.dll"; //CRACKMEcopy.EXE CrackHeadcopy.exe
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_FILE_HEADER pFileHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_EXPORT_DIRECTORY pExportDirectory = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
PIMAGE_SECTION_HEADER pNewSectionHeader = NULL; //指向最后一个节表的下一个节表,即不存在的节表作为新开辟的节表
int SizeOfFileBuffer;
int SizeOfNewFileBuffer;
LPVOID pNewFileBuffer = NULL;
LPVOID* ppNewFileBuffer = &pNewFileBuffer;
DWORD nameFOA = NULL;
DWORD AddressOfNamesFOA = NULL;
DWORD AddressOfNameOrdinalsFOA = NULL;
DWORD AddressOfFunctionsFOA = NULL;
DWORD AddressOfFunctions = NULL;
WORD Ordinal = NULL;
char* name = NULL;
DWORD result = NULL;
typedef int(*lpPlus)(int, int); //测试查找出的函数用
DWORD P = 0; //相对新节的偏移即相对pNewSectionHeader->PointerToRawData的偏移,会随着数据填充而一直变化,初值必须为0
SizeOfFileBuffer = ReadPEFile(FilePath, ppFileBuffer); //pFileBuffer即指向已装载到内存中的exe首部
/*pFileBuffer = *ppFileBuffer;*/
if (!SizeOfFileBuffer)
{
printf("文件读取失败\n");
return;
}
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//可选PE头 简化后的处理
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4 + IMAGE_SIZEOF_FILE_HEADER);
//导出表
pExportDirectory = (PIMAGE_EXPORT_DIRECTORY)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress));
printf("DIRECTORY_ENTRY_EXPORT VirtualAddress:%x\n", pOptionalHeader
->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress);
printf("FOA:%x\n", RVA2FOA(pFileBuffer, pOptionalHeader
->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress));
printf("导出表文件名字符串Name:%x\n", pExportDirectory->Name);
printf("导出函数起始序号Base:%d\n", pExportDirectory->Base);
printf("导出函数的个数:%d\n", pExportDirectory->NumberOfFunctions);
printf("以函数名字导出的函数个数NumberOfNames:%d\n", pExportDirectory->NumberOfNames);
printf("*******函数地址表*******\n");
AddressOfFunctionsFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfFunctions);
for (int i = 0; i < pExportDirectory->NumberOfFunctions; i++)
{ //因Address表元素为4字节,绝对地址加上i*4直接取第i个元素
AddressOfFunctions = *(PDWORD)((DWORD)pFileBuffer + AddressOfFunctionsFOA + i * 4);
printf("下标:%d,函数地址:%x\n", i, AddressOfFunctions);
}
printf("*******函数名称表*******\n");
//导出表中的AddressOfNames为Rva,将其转换为FOA得到AddressOfNamesFOA
AddressOfNamesFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfNames);
for (int i = 0; i < pExportDirectory->NumberOfNames; i++)
{ //AddressOfNamesFOA只是Names表的FOA地址,需加上pFileBuffer构成的绝对地址才能取出其中的值。
//取出的值即Names地址表第i个name的Rva地址,转成FOA得到name的FOA地址
nameFOA = RVA2FOA(pFileBuffer, *(PDWORD)((DWORD)pFileBuffer + AddressOfNamesFOA + i * 4));//真正的FOA
name = (char*)(nameFOA + (DWORD)pFileBuffer);//name的FOA加上pFileBuffer构成绝对地址,该地址才真正指向字符串
printf("下标:%d,函数名:%s\n", i, name);
//AddressOfNamesFOA += 4; //往前走4字节,指向Names地址表下一个元素,即下一个name地址
}
printf("*******函数序号表*******\n");
AddressOfNameOrdinalsFOA = RVA2FOA(pFileBuffer, pExportDirectory->AddressOfNameOrdinals); //同Names表找法
for (int i = 0; i < pExportDirectory->NumberOfNames; i++)
{
Ordinal = *(PWORD)((DWORD)pFileBuffer + AddressOfNameOrdinalsFOA + i * 2); //因为Ordinal表元素为2字节,绝对地址加上i*2直接取第i个元素
printf("下标:%d,Ordinal序号:%d\n", i, Ordinal);
}
result = (DWORD)GetFunctionAddrByName(pFileBuffer, "Plus"); //得到的是函数Rva地址
printf("result:%x\n", result);
result = (DWORD)GetFunctionAddrByOrdinals(pFileBuffer, 2);
printf("result:%x\n", result);
//新增节,可能头抬升,因此全拷贝到pNewFileBuffer,之后上面的寻址得全部来一遍
SizeOfNewFileBuffer = AddNewSection(pFileBuffer, SizeOfFileBuffer, 1000, ppNewFileBuffer);
//参数分别为 原filebuffer指针,原大小,新节的大小,指向新节的指针 返回值为新节区的大小
//重新对pNewFileBuffer来一遍
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pNewFileBuffer; // 强转 DOS_HEADER 结构体指针
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)((DWORD)pNewFileBuffer + pDosHeader->e_lfanew + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);
//首个节表
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
for (int i = 1; i < pFileHeader->NumberOfSections; i++, pSectionHeader++) //注意这里i从1开始 i < NumberOfSections
{
} //出循环后pSectionHeader指向最后一个节表,也即新的节表
pNewSectionHeader = pSectionHeader;
//导出表
pExportDirectory = (PIMAGE_EXPORT_DIRECTORY)((DWORD)pNewFileBuffer + RVA2FOA(pNewFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress));
/*******************************************************************************************/
//旧函数地址表
AddressOfFunctionsFOA = RVA2FOA(pNewFileBuffer, pExportDirectory->AddressOfFunctions);
//拷贝函数地址表
//新filebuffer头+新节表中的文件偏移 作为拷贝目的地址, 新filebuffer头 + 旧函数地址表文件偏移 作为拷贝源, 拷贝长度 函数表项数 *4
//P为相对新节的偏移即相对pNewSectionHeader->PointerToRawData的偏移,会随着数据填充而一直变化
memcpy((PVOID)((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData + P), (PVOID)((DWORD)pNewFileBuffer + AddressOfFunctionsFOA), pExportDirectory->NumberOfFunctions * 4);
//修改导出表中函数地址表地址值 节头 + 偏移
pExportDirectory->AddressOfFunctions = pNewSectionHeader->VirtualAddress + P;
//所有操作完毕,偏移可以往前加了 P相当于记录了SizeOfRaw 拷贝完地址表还要接着利用P拷贝下面的序号表和函数名表
P += pExportDirectory->NumberOfFunctions * 4;
//新函数地址表测试
AddressOfFunctionsFOA = RVA2FOA(pNewFileBuffer, pExportDirectory->AddressOfFunctions);
for (int i = 0; i < pExportDirectory->NumberOfFunctions; i++)
{ //因Address表元素为4字节,绝对地址加上i*4直接取第i个元素
AddressOfFunctions = *(PDWORD)((DWORD)pNewFileBuffer + AddressOfFunctionsFOA + i * 4);
printf("下标:%d,函数地址:%x\n", i, AddressOfFunctions);
}
/*******************************************************************************************/
//旧序号表
AddressOfNameOrdinalsFOA = RVA2FOA(pNewFileBuffer, pExportDirectory->AddressOfNameOrdinals);
//拷贝序号表
//新filebuffer头+新节表中的文件偏移+上一次拷贝后P记录的相对新节的偏移 作为拷贝目的地址, 新filebuffer头 + 旧函数地址表文件偏移 作为拷贝源, 拷贝长度 序号表项数 *2
memcpy((PVOID)((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData + P ), (PVOID)((DWORD)pNewFileBuffer + AddressOfNameOrdinalsFOA), pExportDirectory->NumberOfNames * 2);
//修改导出表中序号表地址值 这里修正之后最后再移动完导出表后就不用修正了 同样是节头+偏移
pExportDirectory->AddressOfNameOrdinals = pNewSectionHeader->VirtualAddress + P;
//所有操作完毕,偏移可以往前加了
P += pExportDirectory->NumberOfNames * 2;
//新序号表测试
AddressOfNameOrdinalsFOA = RVA2FOA(pNewFileBuffer, pExportDirectory->AddressOfNameOrdinals);
for (int i = 0; i < pExportDirectory->NumberOfNames; i++)
{
Ordinal = *(PWORD)((DWORD)pNewFileBuffer + AddressOfNameOrdinalsFOA + i * 2); //因为Ordinal表元素为2字节,绝对地址加上i*2直接取第i个元素
printf("下标:%d,Ordinal序号:%d\n", i, Ordinal);
}
/*******************************************************************************************/
//旧函数名表
AddressOfNamesFOA = RVA2FOA(pNewFileBuffer, pExportDirectory->AddressOfNames);
//拷贝旧函数名表,这里因为字符串地址未确定,所以全拷贝0
//拷贝目的地址同上,值0,长度为函数名表*4,因为表内装的是地址值,每项4字节
memset((PVOID)((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData + P), 0, pExportDirectory->NumberOfNames * 4);
//记录下函数名表中的项在FOA中的地址,即现在按照这个地址真实找得到表所在的地址,∵过了之后P就改变了,∴需先记录下
PDWORD NamesTableFOA = (PDWORD)((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData + P);
//修改导出表中函数名表地址值
pExportDirectory->AddressOfNames = pNewSectionHeader->VirtualAddress + P;
//所有操作完毕,偏移可以往前加了
P += pExportDirectory->NumberOfNames * 4;
//接下来拷贝每一个字符串
for (int i = 0; i < pExportDirectory->NumberOfNames; i++)
{ //AddressOfNamesFOA只是Names表的FOA地址,需加上pFileBuffer构成的绝对地址才能取出其中的值。
//取出的值即Names地址表第i个name的Rva地址,转成FOA得到name的FOA地址
nameFOA = RVA2FOA(pNewFileBuffer, *(PDWORD)((DWORD)pNewFileBuffer + AddressOfNamesFOA));
name = (char*)(nameFOA + (DWORD)pNewFileBuffer);//name的FOA加上pFileBuffer构成绝对地址,该地址才真正指向字符串
printf("下标:%d,函数名:%s,字符串长度%d\n", i, name,strlen(name));
//拷贝目的为新filebuffer头+新节表中的文件偏移+上一次拷贝后P记录的相对新节的偏移, 拷贝源为name(name本身是个指向字符串的地址, 拷贝长度为name字符串长度
memcpy((PVOID)((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData + P), name, strlen(name)+1); // + 1 名字后面还有 '\0'
printf("下标:%d,函数名:%s\n", i, (char*)((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData + P));
//函数名表中的项 = 新的函数名Rva地址 这里用先前记录的FOA而不用pExportDirectory->AddressOfNames ∵AddressOfNames是RVA,寻址麻烦,先前记录的FOA能直接找到真正地址 修复名字地址表的地址
* NamesTableFOA = pNewSectionHeader->VirtualAddress + P;
//所有操作完毕,偏移可以往前加了
P += strlen(name)+1; //复制完一个名字后才知道下一个地址在哪里 因为名字的长度不确定
NamesTableFOA++; //该值是PDWORD ++会往前走四字节
AddressOfNamesFOA += 4; //往前走4字节,指向Names地址表下一个元素,即下一个name地址
}
//测试
printf("*******函数名称表*******\n");
//导出表中的AddressOfNames为Rva,将其转换为FOA得到AddressOfNamesFOA
AddressOfNamesFOA = RVA2FOA(pNewFileBuffer, pExportDirectory->AddressOfNames);
for (int i = 0; i < pExportDirectory->NumberOfNames; i++)
{ //AddressOfNamesFOA只是Names表的FOA地址,需加上pFileBuffer构成的绝对地址才能取出其中的值。
//取出的值即Names地址表第i个name的Rva地址,转成FOA得到name的FOA地址
nameFOA = RVA2FOA(pNewFileBuffer, *(PDWORD)((DWORD)pNewFileBuffer + AddressOfNamesFOA));
name = (char*)(nameFOA + (DWORD)pNewFileBuffer);//name的FOA加上pFileBuffer构成绝对地址,该地址才真正指向字符串
printf("下标:%d,函数名:%s\n", i, name);
AddressOfNamesFOA += 4; //往前走4字节,指向Names地址表下一个元素,即下一个name地址
}
/***********************************************************************************************/
//整个导出表转移到新节 把导出表包含的三个表移动完后 最后移动导出表
printf("导出表长度:%d\n",sizeof(IMAGE_EXPORT_DIRECTORY));
//拷贝导出表到新节
memcpy((PVOID)((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData + P), pExportDirectory, sizeof(IMAGE_EXPORT_DIRECTORY));
//改变导出表地址
pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress = pNewSectionHeader->VirtualAddress + P;
MemeryToFile(pNewFileBuffer, SizeOfNewFileBuffer, CopyFilePath);
free(pNewFileBuffer);
free(pFileBuffer);
}
移动重定位表
重定位表的移动相比导出表就简单太多了,因为重定位表相当于只有一个大表。统计一下这个“大表”的大小,全部移动到新节就行了。因为是使用下一块 VirtualAddress 和 SizeOfBlock 是否全0 来判断重定位表是否结束的,所以拷贝的时候也把这8字节的全0内容也加上一起拷贝进新节。
重定位表是由于在代码中写入的绝对地址,而 DLL 不能按照设想的 ImageBase 作起始加载位置去了别的地方占坑,那么需要根据重定位表记录的这些绝对地址在内存中的位置(RVA),逐一去到这些位置修复绝对地址,而产生的表。
表中记录的是代码中 绝对地址 所在的RVA,需要根据偏移去到这个RVA修改掉这四字节的绝对地址
修改 DLL 的 ImageBase 来模拟这个过程, 相当于模拟 DLL 加载时 占不住原来的 ImageBase 的情况,所以只能在操作系统安排的其他位置加载,
修复重定位地址:这个被安排的位置就相当于我们修改的 ImageBase根据这个新占坑位置和原来 ImageBase 之间的增量来进行重定位表修正,然后存盘.看DLL是否可以使用。
//移动重定位表到新添加的节
#include "Currency.h"
#include "windows.h"
#include "stdio.h"
void h3262()
{
char FilePath[] = "CRACKME.EXE"; //CRACKME.EXE CrackHead.exe Dll1.dll R.DLL LoadDll.dll
char CopyFilePath[] = "CRACKMEcopy.EXE"; //CRACKMEcopy.EXE CrackHeadcopy.exe
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
int SizeOfFileBuffer;
int SizeOfNewFileBuffer;
LPVOID pNewFileBuffer = NULL;
LPVOID* ppNewFileBuffer = &pNewFileBuffer;
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_FILE_HEADER pFileHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = NULL;
PIMAGE_BASE_RELOCATION pRelocationTable = NULL;
PIMAGE_SECTION_HEADER pNewSectionHeader = NULL; //指向最后一个节表的下一个节表,即不存在的节表作为新开辟的节表
DWORD nameFOA = NULL;
DWORD AddressOfNamesFOA = NULL;
SizeOfFileBuffer = ReadPEFile(FilePath, ppFileBuffer); //pFileBuffer即指向已装载到内存中的exe首部
/*pFileBuffer = *ppFileBuffer;*/
if (!SizeOfFileBuffer)
{
printf("文件读取失败\n");
return;
}
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer; // 强转 DOS_HEADER 结构体指针
//可选PE头 简化后的处理
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileBuffer + pDosHeader->e_lfanew + 4 + IMAGE_SIZEOF_FILE_HEADER);
//重定向表
pRelocationTable = (PIMAGE_BASE_RELOCATION)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress));
printf("RelocationTable VirtualAddress:%x\n", pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress);
if (!pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress)
{
printf("该文件没有重定向表!\n");
return;
}
int i = 1;
int SizeOfRelocationTable = 0; //重定向表的大小,单位字节
while (pRelocationTable->VirtualAddress && pRelocationTable->SizeOfBlock)
{
printf("第%d个块VirtualAddress:%x\n", i, pRelocationTable->VirtualAddress);
printf("第%d个块SizeOfBlock:%x\n", i, pRelocationTable->SizeOfBlock);
SizeOfRelocationTable += pRelocationTable->SizeOfBlock;
printf("第%d个块项数:%d\n", i, (pRelocationTable->SizeOfBlock - 8) / 2);
pRelocationTable = (PIMAGE_BASE_RELOCATION)(pRelocationTable->SizeOfBlock + (DWORD)pRelocationTable);
i++;
}
SizeOfRelocationTable += 8; //加上最后全0的八字节
printf("重定位表的大小:%d\n", SizeOfRelocationTable);
//新增节,可能头抬升,因此全拷贝到pNewFileBuffer,之后上面的寻址得全部来一遍
SizeOfNewFileBuffer = AddNewSection(pFileBuffer, SizeOfFileBuffer, SizeOfRelocationTable, ppNewFileBuffer); //参数分别为 原filebuffer指针,原大小,新节的大小,指向新节的指针 返回值为新节区的大小
//重新对pNewFileBuffer来一遍
//Dos头
pDosHeader = (PIMAGE_DOS_HEADER)pNewFileBuffer; // 强转 DOS_HEADER 结构体指针
//PE头
pFileHeader = (PIMAGE_FILE_HEADER)((DWORD)pNewFileBuffer + pDosHeader->e_lfanew + 4); //NT头地址 + 4 为 FileHeader 首址
//可选PE头
pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + IMAGE_SIZEOF_FILE_HEADER);
//首个节表
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);
for (int i = 1; i < pFileHeader->NumberOfSections; i++, pSectionHeader++) //注意这里i从1开始 i < NumberOfSections
{
} //出循环后pSectionHeader指向最后一个节表,也即新的节表
pNewSectionHeader = pSectionHeader;
//旧重定向表绝对地址
pRelocationTable = (PIMAGE_BASE_RELOCATION)((DWORD)pNewFileBuffer + RVA2FOA(pNewFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress));
//拷贝重定位表到新添加的节 新filebuffer头+新节表中的文件偏移 作为拷贝目的地址 旧重定向表绝对地址为拷贝源
memcpy(PVOID((DWORD)pNewFileBuffer + pNewSectionHeader->PointerToRawData ), pRelocationTable, SizeOfRelocationTable);
//修改重定位表的地址值 节头 + 偏移
pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress = pNewSectionHeader->VirtualAddress;
//输出测试
//计算新的重定向表 注意这里新的重定向表 是原来的VirtualAddress转为FOA 再加上pNewFileBuffer 新的imagebase
pRelocationTable = (PIMAGE_BASE_RELOCATION)((DWORD)pNewFileBuffer + RVA2FOA(pNewFileBuffer, pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress));
printf("RelocationTable VirtualAddress:%x\n", pOptionalHeader
->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress);
if (!pOptionalHeader->DataDirectory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress)
{
printf("该文件没有重定向表!\n");
return;
}
i = 1;
while (pRelocationTable->VirtualAddress && pRelocationTable->SizeOfBlock)
{
printf("第%d个块VirtualAddress:%x\n", i, pRelocationTable->VirtualAddress);
printf("第%d个块SizeOfBlock:%x\n", i, pRelocationTable->SizeOfBlock);
printf("第%d个块项数:%d\n", i, (pRelocationTable->SizeOfBlock - 8) / 2);
pRelocationTable = (PIMAGE_BASE_RELOCATION)(pRelocationTable->SizeOfBlock + (DWORD)pRelocationTable);
i++;
}
MemeryToFile(pNewFileBuffer, SizeOfNewFileBuffer, CopyFilePath);
free(pNewFileBuffer);
free(pFileBuffer);
}
流程
1、File-> FileBuffer
2、添加节
3、定位重定位表
4、移动重定位表
5、修复重定位的地址
6、存盘
IAT表与导入表
IAT表

在我们调用 dll 函数的时候,发现代码中的汇编,是通过间接寻址的。也就是不直接 call 函数地址,而是通过一个中间地址再跳转的。
比如调用MessageBox这类系统函数的时候(这也是个 dll 中的函数),那么它的汇编会为 call dword ptr [ (004322d4) ] 通过间接寻址,004322d4里面存的是X就可以跳到X,这个X变量可以任意指定。004322d4是.exe领空的,而间接寻址的X可以不是.exe领空,比如这次运行中X会变为77d5050b,就跳到了.dll 的领空了
前面也讲到,因为 dll 是随着其他程序加载进4GB内存的,就可能占不住自己的 ImageBase,因而它提供的导出函数位置就会随之变化,所以 call 的时候不能把相应 dll 函数的位置写死,得根据dll加载情况而动态的变化。所以采用间接寻址的方式来实现动态变化。(因为你不知道这个函数的领空和实际地址在哪,只能先写自己代码领空的位置在 call 后面,操作系统根据 dll 实际调用情况,把真正函数地址填进类似这个 004322d4 的间接区域)
那么当编译的.exe 是未运行的文件状态时,这个 004322d4 指向的地址(还要根据 RVA 转 FOA,减去 Imagebase 才能在文件中找到这个位置),只是一个 MessageBox.USER32.dll 字符串。但内存中这 004322d4 指向的地址却是一个 77d5050b 绝对地址。那么他是什么时候改变的呢?是当.exe 和用到的所有.dll 都贴进4GB空间(并且都修复了各自的重定位表)的时候,这个值就从字符串被修改为绝对地址。
而这些存放着.dll 和函数信息并将要被转换为绝对地址的类似 004322d4 的中间地址,连起来就是IAT表(import name table,导入名称表)
注:只有当DDL文件全部贴到内存里后,IAT表里的值才可以真正的确定下来,考虑到dll的地址可能会发生变化
导入表🚩
和之前的好多表一样,VirtualAddress 指向多个一样的导入表结构,最后 sizeOf (IMAGE_IMPORT_DESCRIPTOR)个0代表导入表结束
Name 是指向 dll 名的 RVA,只记录了一个 dll 名,所以导入表会有若干张,顺序无缝存放,一张导入表就是一个要使用的 dll,以全0作为结尾,所以一个exe程序会有多个导入表
OriginalFirstThunk(导入表结构第一个成员)指向一张叫 INT 的表(import name table,导入名称表),存的是若干个 IMAGE_THUNK_DATA 结构,最后以0结尾作结束标志。
FirstThunk(导入表结构最后一个成员)也指向一张表,IAT表(import address table,导入地址表),找到这张表有两种方式,一种就是通过导入表这里找到,第二种就是通过数据目录表,倒数第三个项就是指向的 IAT 表,IMAGE_DIRECTORY_ENTRY_IAT,也是以0结束。在文件加载前,这两个表存的内容完全一致,都是存储的IMAGE_THUNK_DATA 结构(IMAGE_THUNK_DATA32)(详见下下图)。注意虽然一致,但 INT 表和 IAT 表是两块不同的空间,分别记录的都是程序中使用到的 dll 函数,不使用的 dll 函数不会记录。
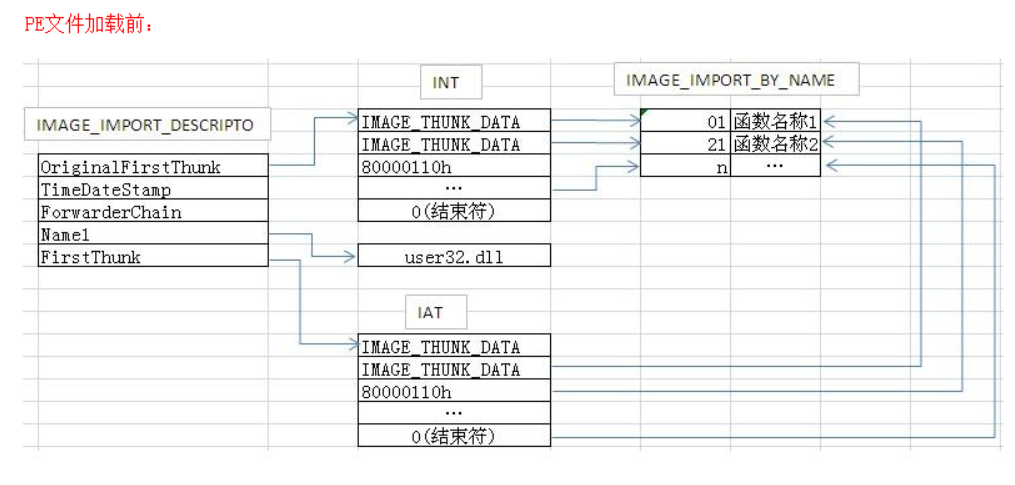
注:加载前INT与IAT两个表存的内容完全一样
原因:1、留一个函数名称的备份 INT表,运行时IAT表变为地址,如果还要查找函数名,必须有备份,INT就做了这件事
更新IAT表时:通过INT去找函数名称,再根据之前写的GetFunctionAddrByName()函数得到函数地址,填入IAT表
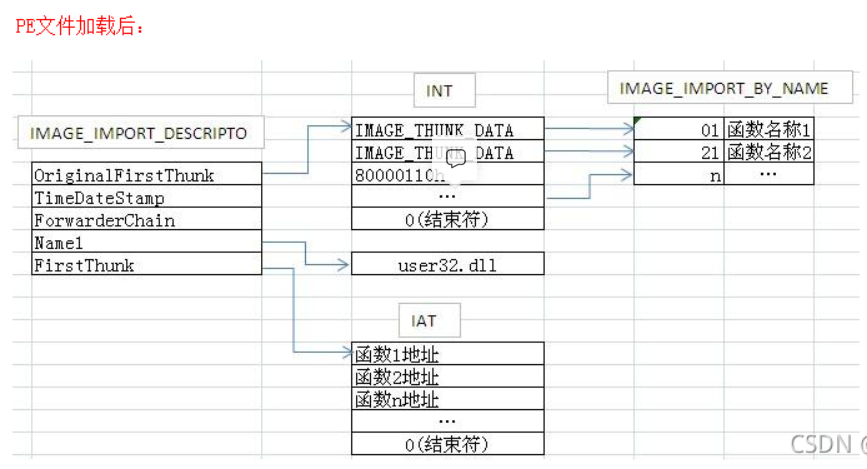
在加载前,IMAGE_THUNK_DATA 只存一个 RVA,这个 RVA 指向上图的IMAGE_IMPORT_BY_NAME 结构
在加载后,IAT 表变为存储函数的地址了,所以才有文章最前面提到的,在调用 MassageBox 文件加载前call间接寻址找的是一个字符串,而文件加载后这个间接寻址变为了函数的真正地址。而 INT 表不变。
上图提到的 IMAGE_THUNK_DATA 结构其实只是一个四字节的 联合体union,
typedef struct _IMAGE_THUNK_DATA32 {
union {
PBYTE ForwarderString;
PDWORD Function;
DWORD Ordinal; //序号
PIMAGE_IMPORT_BY_NAME AddressOfData;//指向IMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA32;
typedef IMAGE_THUNK_DATA32 * PIMAGE_THUNK_DATA32;
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint; //可能为空,编译器决定 如果不为空 是函数在导出表中的索引
BYTE Name[1]; //函数名称,以0结尾
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
🔱注意,IMAGE_IMPORT_BY_NAME 中的 Name 并不只有 1 个字节,而是一直遍历到元素为 '\0' 为止,OriginalFirstThunk 和 FirstThunk 的遍历 具体详见下图(这俩的遍历都一样的,其实都是遍历的 IMAGE_THUNK_DATA)
🔱IMAGE_THUNK_DATA32为DWORD,由于导出表有按名称导出和按序号导出两种形式,故定义了这个变量,最高位如果是1,那么去掉最高位剩下的就是函数的导出序号,如果最高位不为1,该值就是指向按名字导出的一个RVA
注意下面的系统函数GetProcAddr(m,函数名或函数导出序号) ,m为module句柄,返回函数句柄,系统会自动根据传入参数的不同实施不同的寻找策略

注意 IMAGE_IMPORT_BY_NAME 中的 Hint 不是导出序号,而是当前这个函数在导出表函数地址表中的索引。但基本没用,所以不一定是准确的,可以全部为0。而Name并不是一字节,这里只是存储了第一个字符,而是以’\0’结尾的不定长字符串。

// 打印导入表
VOID PrintImportTable(LPVOID pFileBuffer)
{
PIMAGE_DOS_HEADER pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer;
PIMAGE_FILE_HEADER pPEHeader = (PIMAGE_FILE_HEADER)(pDosHeader->e_lfanew + (DWORD)pDosHeader + 4);
PIMAGE_OPTIONAL_HEADER32 pOptionHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pPEHeader + sizeof(IMAGE_FILE_HEADER));
PIMAGE_SECTION_HEADER pSectionHeader = \
(PIMAGE_SECTION_HEADER)((DWORD)pOptionHeader + pPEHeader->SizeOfOptionalHeader);
PIMAGE_IMPORT_DESCRIPTOR pImportTable = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)pFileBuffer + \
RvaToFoa(pFileBuffer, pOptionHeader->DataDirectory[1].VirtualAddress));
// 严格来说应该是 sizeof(IMAGE_IMPORT_DESCRIPTOR) 个字节为0表示结束
while (pImportTable->OriginalFirstThunk || pImportTable->FirstThunk) //外层循环打印所有dll
{
// 打印模块名 pImportTable->Name 也是一个指向字符串的RVA, 模块名即dll名比如说kernel32.dll
printf("%s\n", (LPCSTR)(RvaToFoa(pFileBuffer, pImportTable->Name) + (DWORD)pFileBuffer));
// 遍历INT表(import name table) OriginalFirstThunkRVA指向INT
printf("--------------OriginalFirstThunkRVA:%x--------------\n", pImportTable->OriginalFirstThunk);
PIMAGE_THUNK_DATA32 pThunkData = (PIMAGE_THUNK_DATA32)((DWORD)pFileBuffer + \
RvaToFoa(pFileBuffer, pImportTable->OriginalFirstThunk));
while (*((PDWORD)pThunkData) != 0) // 内存循环打印所有函数
{
// IMAGE_THUNK_DATA32 是一个4字节数据
// 如果最高位是1,那么除去最高位就是导出序号
// 如果最高位是0,那么这个值是RVA 指向 IMAGE_IMPORT_BY_NAME
if ((*((PDWORD)pThunkData) & 0x80000000) == 0x80000000) //取出最高位
{
printf("按序号导入 Ordinal:%04x\n", (*((PDWORD)pThunkData) & 0x7FFFFFFF)); //取出低31位
}
else // 最高位不为1,整个32位作为指向函数名字表的RVA
{
PIMAGE_IMPORT_BY_NAME pIBN = (PIMAGE_IMPORT_BY_NAME)(RvaToFoa(pFileBuffer,
*((PDWORD)pThunkData)) + \(DWORD)pFileBuffer);
//强转为(PIMAGE_IMPORT_BY_NAME)后就可以直接 ->Hint ->Name 了
printf("按名字导入 Hint:%04x Name:%s\n", pIBN->Hint, pIBN->Name);//Hint为索引序号
}
pThunkData++;
}
// 遍历IAT表(import address table) FirstThunkRVA指向IAT表
printf("--------------FirstThunkRVA:%x--------------\n", pImportTable->FirstThunk);
pThunkData = (PIMAGE_THUNK_DATA32)((DWORD)pFileBuffer + \
RvaToFoa(pFileBuffer, pImportTable->FirstThunk));
while (*((PDWORD)pThunkData) != 0)
{
// IMAGE_THUNK_DATA32 是一个4字节数据
// 如果最高位是1,那么除去最高位就是导出序号
// 如果最高位是0,那么这个值是RVA 指向 IMAGE_IMPORT_BY_NAME
if ((*((PDWORD)pThunkData) & 0x80000000) == 0x80000000)
{
printf("按序号导入 Ordinal:%04x\n", (*((PDWORD)pThunkData) & 0x7FFFFFFF));
}
else
{
PIMAGE_IMPORT_BY_NAME pIBN = (PIMAGE_IMPORT_BY_NAME)(RvaToFoa(pFileBuffer,
*((PDWORD)pThunkData)) + \(DWORD)pFileBuffer);
printf("按名字导入 Hint:%04x Name:%s\n", pIBN->Hint, pIBN->Name);
}
pThunkData++;
}
pImportTable = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)pImportTable + sizeof(IMAGE_IMPORT_DESCRIPTOR));
}
}
IAT 表在文件中存储的内容未必是序号和函数名的 RVA,还有可能直接就是上章讲的文件运行加载进内存后呈现的真正的函数地址。Notepad就是这样。而这个本来应该是加载后才做的事,在加载前的文件状态就已经做过了,就不用再等 exe 和所有 dll 挨个贴进内存空间,贴完后再挨个找 dll 函数地址才把 IAT 表改掉了。加快了程序的加载速度,在加载前的文件就已经把这个事做了,
其实我们也可以自己做这个过程,完全是可行的。在 exe 文件加载前根据导入表已经知道他用哪些 dll,挨个找到这些 dll,查询他们的导出表依次得到每个函数的位置,当然还要 RVA 转 FOA,加上 dll 的 Imagebase(dll 之间的 Imagebase 冲突了也就是需要重定向的时候就没办法了),把这些函数绝对地址挨个贴到 IAT 表中。
绑定导入表
我们的PE程序在加载的时候.我们知道. PE中导入表的子表. IAT表.会填写函数地址. 但是这就造成了一个问题.PE程序启动慢.每次启动都要给IAT表填写函数地址. 我们可不可以在文件中就给填写好. 这样是可以的。
PE中包含导入表的优点是程序启动快,但是其缺点也十分明显,当存在dll地址重定位和dll修改更新,则绑定导入表也需要修改更新。
typedef struct _IMAGE_BOUND_IMPORT_DESCRIPTOR {
DWORD TimeDateStamp;
WORD OffsetModuleName;
WORD NumberOfModuleForwarderRefs;
// Array of zero or more IMAGE_BOUND_FORWARDER_REF follows
} IMAGE_BOUND_IMPORT_DESCRIPTOR, *PIMAGE_BOUND_IMPORT_DESCRIPTOR;
typedef struct _IMAGE_BOUND_FORWARDER_REF {
DWORD TimeDateStamp;
WORD OffsetModuleName;
WORD Reserved;
} IMAGE_BOUND_FORWARDER_REF, *PIMAGE_BOUND_FORWARDER_REF;


绑定导入表_IMAGE_BOUND_IMPORT_DESCRIPTOR 第一个成员就是真正的时间戳
在coff头/标准PE头 FILE_HEADER 中有个 TimeDateStamp字段,记录了文件生成时的时间戳
exe 绑定导入表中的时间戳,和对应 dll 标准 PE 头中的时间戳,如果吻合,证明是绑定的时候的dll,没有出错,*如果不吻合证明dll已经被更新,或者 DLL 需要重定位的时候,exe 的绑定导入可能会出错,则系统在加载文件时会重新计算 IAT 中的值,不使用原本记录的绑定信息。
第二个成员 OffsetModuleName 是 dll 名
第三个成员 NumberOfModuleForwarderRefs 说明了在当前所在这个绑定导入表IMAGE_BOUND_IMPORT_DESCRIPTOR 之后有几个 _IMAGE_BOUND_FORWARDER_REF (依赖的)结构,这是个整数。如下图所示,如果是2,则后跟两个_IMAGE_BOUND_FORWARDER_REF 结构,再之后才是下一个绑定导入表IMAGE_BOUND_IMPORT_DESCRIPTOR,以此类推。最后以绑定导入表长度的内容为全 0 结束。
至于为什么有这个结构呢?是因为一个 exe 会直接使用好几个 dll,这些 dll 如果绑定了就是绑定导入表的内容,但这些直接使用的dll可能还会再使用其他的dll,这个IMAGE_BOUND_FORWARDER_REF 结构就是用来记录间接使用的dll 的。
因为也是描述的 dll 信息,所以IMAGE_BOUND_FORWARDER_REF 结构 其实也是和绑定导入表一样的结构,第一个成员是时间戳,功能和绑定导入表的时间戳一样,第二个成员也一样是 dll 名,第三个成员是保留字段,无意义。
上述表示 dll 名的第二个成员 OffsetModuleName 不是 RVA 也不是 FOA,是使用第一个绑定导入表的RVA(即第一个IMAGE_BOUND_IMPORT_DESCRIPTOR的RVA),加上OffsetModuleName 的值。得到的才是名字字符串真正的 RVA。其他的绑定导入表结构和 所有IMAGE_BOUND_FORWARDER_REF 结构都一样,计算方法都是用当前OffsetModuleName 的值 加上 第一个绑定导入表IMAGE_BOUND_IMPORT_DESCRIPTOR的RVA,注意全都是加第一个导入表的RVA。
IAT中存储的函数地址是dll未加载的地址,当PE文件中导入表未绑定,IAT就与INT一样,此时导入表中的时间戳就为0;导入表中的时间戳为-1时,当前的dll已经绑定了,dll绑定的真正时间戳存放于绑定导入表中(绑定导入表地址存放在数据目录的第12项,IAT是第13项)。
现在大多数情况,导入表的TimeDateStamp都为0,而Windows早期的自带软件(如WinXP的notepad.exe)基本都采用了TimeDateStamp为-1的情况即包含绑定导入表的情况。
这里用的是 Windows XP 中取出来的notepad.exe,可以去xp虚拟机中搞到这个exe,win10找了很多exe,都是没有绑定导入表的,没办法
#include "Currency.h"
#include "windows.h"
#include "stdio.h"
VOID h330() //打印绑定导入表所有内容
{
char FilePath[] = "notepad.exe"; //CRACKME.EXE CrackHead.exe Dll1.dll R.DLL notepad.exe LoadDll.dll PETool.exe 打印dll用最后一个看
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
if (!ReadPEFile(FilePath, ppFileBuffer))
{
printf("文件读取失败\n");
return;
}
// 头查找
PIMAGE_DOS_HEADER pDos = (PIMAGE_DOS_HEADER)pFileBuffer;
PIMAGE_NT_HEADERS32 pImageNts = (PIMAGE_NT_HEADERS32)((DWORD)pFileBuffer + pDos->e_lfanew);
PIMAGE_DATA_DIRECTORY pDir =
&pImageNts->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT];
PIMAGE_BOUND_IMPORT_DESCRIPTOR pBoundImport = (PIMAGE_BOUND_IMPORT_DESCRIPTOR)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer,pDir->VirtualAddress));
//printf("VirtualAddress:%x\n", pDir->VirtualAddress);
if (pDir->VirtualAddress == 0)
{
printf("没有绑定导入表!\n");
return;
}
//全 0 判断,如果全 0 那就不循环了,只要有一个字段不等于 0 就继续循环
while (pBoundImport->NumberOfModuleForwarderRefs != 0 || pBoundImport->OffsetModuleName != 0 || pBoundImport->TimeDateStamp != 0)
{
printf("TimeDateStamp:%x\n", pBoundImport->TimeDateStamp);
// 当前 OffsetModuleName 的值 加上 第一个绑定导入表的RVA即pDir->VirtualAddress
// 上面的加法结果作为 新的 RVA, 新的 RVA 转换为绝对地址,作为字符串地址
printf("DllName:%s\n", (DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pBoundImport->OffsetModuleName + pDir->VirtualAddress));
printf("NumberOfModuleForwarderRefse:%d\n", pBoundImport-> NumberOfModuleForwarderRefs);
printf("***********************************\n");
for (int i = 0; i < pBoundImport->NumberOfModuleForwarderRefs; i++) //打印每一个绑定过导入表的所有依赖
{
pBoundImport++; //能走到这里的NumberOfModuleForwarderRefs值必不为0,由于绑定导入表和REF大小是一样的,所以这里相当于一起++
PIMAGE_BOUND_FORWARDER_REF pREF = (PIMAGE_BOUND_FORWARDER_REF)pBoundImport;
printf(" TimeDateStamp:%x\n", pREF->TimeDateStamp);
printf(" DllName:%s\n", (DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pREF->OffsetModuleName + pDir->VirtualAddress)); //和绑定导入表的字符串打印一样
printf(" ****************************\n");
}
pBoundImport++; //外循环最后别忘了查找下一个绑定导入表
}
}
导入表注入
当dll被加载进4GB空间时,会调用一次DllMain(入口方法,当程序执行完了要把dll从4GB空间被卸载,也会调用一次DllMain
注入的本质就是想方设法把自己的dll扔到别人进程的4GB空间里

只有在PE文件内隐式调用(静态使用)时才会在调用者PE文件的导入表内出现该 dll 的名字和相关函数,若为显式调用(动态使用),则这个被调用的dll名和相关函数不会在调用者导入表内出现。
反过来也就是说,写入导入表中的 dll ,必定是被调用者隐式调用(静态使用)的。而事实是也确实如此,我们把毫不相关的 dll 写入被调用者PE文件完整的导入表中,那打开这个PE文件时,这个 dll 会当做隐式调用(静态使用)直接被加载!(这是操作系统的规则,也是操作系统干的事)这个过程就叫导入表注入,下面是一些细节:
我们可以把 dll 通过导入表注入弄进其他 exe 的4GB空间。只要将一个 dll 相关的信息以一张新导入表写入.exe中,并且具有至少一个函数的 INT 表和 IAT 表,和对应的 IMPORT_BY_NAME 表,也就是整个导入表结构必须完整!操作系统就会在.exe启动时加载这个 dll,而当加载 dll,就会先执行一次 DllMain 中的代码,于是实现我们的注入目的。
若INT表或IAT表为空、或 IMPORT_BY_NAME 表为空、通过INT、IAT无法找对对应的函数名称或序号,操作系统都不会把 dll 加载进 4GB 空间。总之让整个导入表结构正确完整即可。而且只用写入一个函数就够了。
导入表注入流程:
目的无非就是多加一张导入表,导入表通常在其他的节,而原导入表后面大概率没有空位给我们新增一张表和对应的附表。所以这里直接选择在新增节中把整个旧导入表移动过去,并且在其后增加新导入表和对应附表,其实也可以在各节空白区中找合适的位置添加。
所以首先是移动导入表到新增节,其次就是增加新的导入表在紧接着移动后的导入表之后
也就是增加下面这个东西,在新增节的一众导入表之后:
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics;
DWORD OriginalFirstThunk;
};
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name;
DWORD FirstThunk;
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
新增这个东西后,有一堆内容需要填充,比如 OriginalFirstThunk 需要填充指向这个dll 的 INT表的 RVA,Name 填充指向 dll 名的 RVA,FirstThunk 填充指向该dll IAT表的RVA, INT 和 IAT 表,只用填写一个内容,保证至少有一个导入函数,并且保证第二个内容为全0,即要让 INT和 IAT不为空(8字节),操作系统才会加载我们导入表中的 dll,也就是下图所示

IMAGE_IMPORT_BY_NAME 从2字节之后直接写入需要导入dll 的导出函数名的字符串(Hint的2字节为空)dll 名直接填 dll 名字符串
INT表 内容 就是指向 IMAGE_IMPORT_BY_NAME 的 RVA,这里直接就填充新增节的 VirtualAddress 属性
下一个 IAT表同理,一样的内容。
第一步:
//根据目录项(第二个就是导入表)得到导入表信息:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress; //指向导入表结构
DWORD Size; //导入表的总大小
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
第二步:
判断哪一个节的空白区 > Size(原导入表的大小) + 20(导入表大小) + A + B + C + D,如果不够可能需要扩大最后一个节或新增一个节
第三步:
将原导入表全部Copy到空白区
第四步:
在新的导入表后面,追加一个导入表.
第五步:
追加8个字节的INT表 8个字节的IAT表
INT 和 IAT 表,只用填写一个内容,保证至少有一个导入函数,并且保证第二个内容为全0,即要让 INT和 IAT不为空,操作系统才会加载我们导入表中的 dll
第六步:
追加一个IMAGE_IMPORT_BY_NAME 结构,前2个字节是0 后面是函数名称字符串
第七步:
将IMAGE_IMPORT_BY_NAME结构的RVA赋值给INT和IAT表中的第一项
第八步:
分配空间存储DLL名称字符串 并将该字符串的RVA赋值给Name属性
第九步:
修正IMAGE_DATA_DIRECTORY结构的VirtualAddress和Size
代码如下:
#include "Currency.h"
#include "windows.h"
#include "stdio.h"
VOID h331() //移动导入表到新增节
{
char FilePath[] = "CrackHead.exe"; //CRACKME.EXE CrackHead.exe Dll1.dll R.DLL notepad.exe LoadDll.dll PETool.exe 打印dll用最后一个看
char CopyFilePath[] = "CrackHeadcopy.exe"; //CRACKMEcopy.EXE CrackHeadcopy.exe
LPVOID pFileBuffer = NULL; //会被函数改变的 函数输出之一
LPVOID* ppFileBuffer = &pFileBuffer; //传进函数的形参
LPVOID pNewFileBuffer = NULL; //用于新增节后的新 FileBuffer
LPVOID* ppNewFileBuffer = &pNewFileBuffer; //传进函数的形参
PIMAGE_DOS_HEADER pDos = 0; //头相关信息
PIMAGE_NT_HEADERS32 pNts = 0;
PIMAGE_DATA_DIRECTORY pDir = 0;
PIMAGE_IMPORT_DESCRIPTOR pImportTable = 0;
PIMAGE_SECTION_HEADER pSection = 0;
IMAGE_IMPORT_DESCRIPTOR NewImportTable = { 0 }; //新增的导入表
int NumOfImport = 0; //导入表个数
int SizeOfImport = 0; //导入表长度
DWORD SizeOfNewFileBuffer = 0; // NewFileBuffer 的大小
DWORD SizeOfFileBuffer = ReadPEFile(FilePath, ppFileBuffer);// FileBuffer 的大小
if (!SizeOfFileBuffer)
{
printf("文件读取失败\n");
return;
}
// 头查找
pDos = (PIMAGE_DOS_HEADER)pFileBuffer;
pNts = (PIMAGE_NT_HEADERS32)((DWORD)pFileBuffer + pDos->e_lfanew);
pDir = &pNts->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT]; //导入表
pImportTable = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)pFileBuffer + RVA2FOA(pFileBuffer, pDir->VirtualAddress));
// 判断导入表最保险的是全部为0才结束,但其实不可能没有dll名,这里就只用INT表和 dll名是否都为0 作为结束条件
while(pImportTable->OriginalFirstThunk && pImportTable->Name)
{
NumOfImport++;
pImportTable++;
}
SizeOfImport = NumOfImport * sizeof(IMAGE_IMPORT_DESCRIPTOR);
// 新增节,内容为重新移动的导入表(因为原导入表后面大概率没有空位给我们新增)+ 一张我们新增的导入表和对应的附表
// 三参为新节大小,用 导入表个数 * 导入表大小 + 256 作为 新节大小,因为我们只新增一张导入表和对应附表,256足矣
SizeOfNewFileBuffer = AddNewSection(pFileBuffer, SizeOfFileBuffer, SizeOfImport + 256, ppNewFileBuffer);
free(pFileBuffer); // copy 完,旧的pFileBuffer就没用了
// 因为加上新节了,整个空间都变了,得以pNewFileBuffer重新头查找,重新找到导入表
pDos = (PIMAGE_DOS_HEADER)pNewFileBuffer;
pNts = (PIMAGE_NT_HEADERS32)((DWORD)pNewFileBuffer + pDos->e_lfanew);
pDir = &pNts->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT]; //导入表
pImportTable = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)pNewFileBuffer + RVA2FOA(pNewFileBuffer, pDir->VirtualAddress));
pSection = IMAGE_FIRST_SECTION(pNts); //指向第一个节表
for (int i = 1; i < pNts->FileHeader.NumberOfSections; i++) //注意这里 i 从1 开始,i<NumberOfSections
{
pSection++; //下一个节表
} //出循环后pSection指向最后一个节表,也即新的节表
// 下面开始构造新节内容,内容按顺序排列如下:
// IMAGE_IMPORT_BY_NAME 结构,30字节
// dll 名称,30字节
// OriginalFirstThunk 指向的INT表,8 字节 (只用一个函数)
// FirstThunk 指向的IAT表,8 字节
// 原导入表本身,SizeOfImport 字节
// 新增的导入表,20字节(sizeof(IMAGE_IMPORT_DESCRIPTOR)==20字节 )
// 于是往新节表中逐一填充以上内容,只在有数据的地方memcpy,无数据的地方AddNewSection函数已经帮填充0了,所以不需要管
// 首先填充 IMAGE_IMPORT_BY_NAME ,其中Hint首2字节为0不管,∴从+2的位置开始填充字符串,字符串为海东dll的导出函数名ExportFunction
memcpy((PVOID)((DWORD)pNewFileBuffer + pSection->PointerToRawData + 2), "ExportFunction", sizeof("ExportFunction"));
// 填充 dll名,目的地址从+30 开始,字符串为海东dll名,"InjectDll.dll"
memcpy((PVOID)((DWORD)pNewFileBuffer + pSection->PointerToRawData + 30), "InjectDll.dll", sizeof("InjectDll.dll"));
// 填充 INT表,从+30+30 开始,内容为IMAGE_IMPORT_BY_NAME 的 RVA,显然这个RVA值就是新节的内存起始位置,长度4
memcpy((PVOID)((DWORD)pNewFileBuffer + pSection->PointerToRawData + 30 + 30), &pSection->VirtualAddress, 4);
// IAT表,思想和上面一致,也是一样的 RVA 值
memcpy((PVOID)((DWORD)pNewFileBuffer + pSection->PointerToRawData + 30 + 30 + 8), &pSection->VirtualAddress, 4);
// 移动原导入表到新节 目的地址:新节表的绝对地址 源地址:导入表绝对地址 长度:全部导入表长度
memcpy((PVOID)((DWORD)pNewFileBuffer + pSection->PointerToRawData + 30 + 30 + 8 + 8), pImportTable, SizeOfImport);
// 移动完后 别忘了把数据目录中导入表的 VirtualAddr 给改了, 改成新节的RVA
pDir->VirtualAddress = pSection->VirtualAddress + 30 + 30 + 8 + 8;
pDir->Size += sizeof(IMAGE_IMPORT_DESCRIPTOR);
// 新增导入表,由于NewImportTable已经初始化全0,因此时间戳和ForwarderChain没必要赋0值了
//指向INT表的RVA,即新节的内存起始位置 + 30 + 30
NewImportTable.OriginalFirstThunk = pSection->VirtualAddress + 30 + 30;
// 指向IAT表的RVA
NewImportTable.FirstThunk = pSection->VirtualAddress + 30 + 30 + 8;
// Name 指向
NewImportTable.Name = pSection->VirtualAddress + 30;
// 最后别忘了拷贝整个 NewImportTable ,别忘了二参要取地址
memcpy((PVOID)((DWORD)pNewFileBuffer + pSection->PointerToRawData + 30 + 30 + 8 + 8 + SizeOfImport), &NewImportTable, sizeof(IMAGE_IMPORT_DESCRIPTOR));
MemeryToFile(pNewFileBuffer, SizeOfNewFileBuffer, CopyFilePath);
free(pNewFileBuffer);
}
注意这里有个坑,就是新增节的属性,即节表记录的Characteristics, 必须包含 C000 0040。如果没有这个属性,那运行exe 后会报错0xc0000005。(遇到这个坑后我直接把新增节函数的节属性改为e000 0060了,既可以执行代码,也可以放导入表及其附表)同理如果找节空白区的做法,也要保证添加的导入表和附表所在节包含这个属性,可以在所在节表直接或上 C000 0040。
7. ELF文件
ELF头,16个字节
前四个字节确定文件类型,决定了该文件是否可以被加载
第七个字节01表示ELF版本号,最后的九个字节没有定义,以0填充

ELF的其他节

强符号:函数和已初始化的全局变量
弱符号:未初始化的全局变量
注:连接器不允许多个同名的强符号一起出现 编译时可以加-fno-common选项,遇到多重定义的全局符号时会触发错误
8. 静态数据链接库与动态数据链接库
静态数据链接库:起到链接程序和函数(或子过程)的作用,*.lib,相当于Linux中的.a文件。
静态编译将导出声明和实现都放在lib中。编译后所有代码都嵌入到宿主程序。
//加入预编译指令
#pragma comment (lib,"*.lib")
//加入函数声明
extern "C" __declspec(dllexport) int add(int a, int b); //按照c的语法去导出,如果不加为了防止c++的函数重载的影响,编译器会更改函数名字为特别复杂的。
//直接在当前文件调用函数即可
静态编译的优点是编写出来的程序不需要调用DLL和载入函数,直接可以当成程序的一部分来使用。
静态编译的缺点也是显而易见的,使用静态编译的程序体积会比动态编译大,原因是函数的实现被嵌入为程序代码的一部分。
动态数据链接库:动态LIB文件相当于一个C语言中的h文件,是函数导出部分的声明,而不将实现过程嵌入到程序本身中,编译后只是将函数地址存在宿主程序中,运行到调用函数是调用DLL并载入函数来实现函数的具体操作。.dll文件,相当于linux的*.so文件
dll其实就是exe,只不过它没有main函数,所以不能单独执行而已。事实上, 在实际的使用过程中我们也发现,很多应用程序都并不是一个完整的单独可执行文件,它们被分割成一些单独的相对对立的动态链接库,只有在执行应用程序的时候,用到的dll才会被调用。
一个dll工程生成一个dll文件的时候,总是伴随着生成一个lib文件,这个lib文件其实是一个动态的lib,它的大小比静态lib要小很多,因为这个lib文件其实只是包含了一些函数索引信息,记录了dll中那些函数的入口和位置,dll中才是具体的函数实现。
(1)lib是编译时需要的,dll是运行时需要的。如果要完成源代码的编译,有lib就够了。如果要使动态连接的程序运行起来,有dll就够了。
在动态库的情况下,有两个文件,一个是引入库(.LIB)文件,一个是DLL文件,引入库文件包含被DLL导出的函数的名称和位置,DLL包含实际的函数和数据,应用程序使用LIB文件链接到所需要使用的DLL文件,库中的函数和数据并不复制到可执行文件中,因此在应用程序的可执行文件中,存放的不是被调用的函数代码,而是DLL中所要调用的函数[内存地址,这样当一个或多个应用程序运行时再把程序代码和被调用的函数代码链接起来,从而节省了内存资源。
区别:静态链接库相当于代码嵌入到宿主程序的exe程序里,如果需要优化之前的代码,宿主程序需要重新编译。
动态链接库并不复制到宿主程序中,存放DLL要调用的函数内存地址,优化之前的代码只需要修改DLL即可,不需重新编译
静态lib和动态dll使用注意事项
-
调用静态lib库,需要用到的文件是:
(1).h文件,包含函数的声明,数据结构等东西,在调用lib的时候,需要把该头文件包含进你的代码;
(2).lib文件,包含具体的实现。
-
调用动态dll库,需要用到的文件是:
(1).h文件,如上,同样需要包含到你的代码;
(2).lib文件,包含一些函数的入口和具体位置,必须在编译阶段引入这个文件,否则会报错。【根据查到的资料,如果没有这个动态lib文件或者不想用lib文件,需要用Win32的API函数LoadLibrary和GetProcAddress来装载】
(3).dll文件,实际的实现,在程序运行时动态调用。
项目分成独立的几个模块,每个模块都有一个dll文件,然后有一个最终的程序入口exe文件,最后把dll文件和exe文件发行给用户。当用户每次点击这个exe文件的时候,自然会动态调用用到的dll文件。注意这个过程就不再需要什么.h和.lib了,那是别人调用你的库,再进行加工写代码时才需要做的事。上面说过dll其实就是个不能单独打开执行的exe而已,所以你最终发行给用户的只能是dll和exe,当然你完全可以把所有的东西只打包在一个exe中。但是当你的软件非常大的时候,这样进行更新维护就非常不方便,如果有问题就得重新发行一次exe,但是如果把各个模块单独弄成dll,你只需要打个补丁,对那些有问题的dll进行更换就行了。
另外一个是把你的dll写好给别人拿来调用,以免别人做重复的工作。这个时候你刚开始提供的时候,就需要把.h文件,.lib文件,.dll文件都提供给对方,然后如果你代码里面有改动,只需要重新编译一次dll给对方,替换掉原来的dll就可以了,非常方便。
dll的隐式链接和显示链接
编写一个dll,选择win32,然后win32控制台程序,选择DLL,然后在文件名.cpp中写下代码:
// testDLL.cpp : 定义 DLL 应用程序的导出函数。
#include "stdafx.h"//这里保存的是DLL的导出函数
extern "C" __declspec(dllexport) int add(int a, int b) //dllexport告诉编译器此函数为导出函数
{
return (a + b);
}
extern "C" __declspec(dllexport) int sub(int a, int b) //导出函数
{
return (a - b);
}
extern "C" __declspec(dllexport) int msg()
{
MessageBox(NULL,TEXT("第一个dll程序"),TEXT("MY"),MB_OK);
return 0;
}
//通过上面的代码编译在Debug中,可以得到一个testDLL.lib文件和一个testDLL.dll文件。然后在写程序来调用这个dll。
隐式链接:让编译器去找import的函数,将生成的lib文件放入loadDLL工程文件夹下面,并设置编译器的附加依赖项中增加此lib(也可以直接在代码中增加使用语句如#pragma comment(lib,"testDLL.lib"))
//步骤1、将*.dll,*.lib放到工程目录下
#include <iostream>
#include <windows.h>
#pragma comment(lib,"testDLL.lib") //步骤2、将该声明添加到调用文件
//步骤3、加入函数的声明
extern "C"_declspec(dllimport) int add(int a, int b);//dllimport告诉编译器此函数为导入函数
extern "C"_declspec(dllimport) int sub(int a, int b);
extern "C"_declspec(dllimport) int msg();
int main()
{
int a = 9;
int b = 3;
int nAdd = add(a, b);
int nSub = sub(a, b);
std::cout << nAdd << ":" << nSub << std::endl;
msg();
system("pause");
return 0;
}
显示链接:只需要生成的一个dll文件就能使用了,但是使用较为复杂需要用到指针函数及LoadLibrary等相关知识。在使用dll中的函数时我们首先需要使用导入函数将dll文件导入到进程地址空间再使用GetProcAddress得到dll中的函数地址再使用。
#include <iostream>
#include <windows.h>
int main()
{
//步骤1、定义函数指针 步骤2、声明函数指针变量 _pAdd myadd
typedef int (*_pAdd)(int a, int b);
typedef int (*_pSub)(int a, int b);
typedef int (*_pmsg)();
//步骤2、动态加载dll到内存中
HINSTANCE hDll = LoadLibrary(TEXT("testDLL.dll"));
int nParam1 = 9;
int nParam2 = 3;
//步骤4、获取函数地址
_pAdd pAdd = (_pAdd)GetProcAddress(hDll, "add"); //不加_stdcall函数名不会改变,原来是什么这里就写什么
_pSub pSub = (_pSub)GetProcAddress(hDll, "sub");
_pmsg pmsg = (_pmsg)GetProcAddress(hDll, "msg");
int nAdd = pAdd(nParam1, nParam2);
int nSub = pSub(nParam1, nParam2);
pmsg();
std::cout << nAdd << ":" << nSub << std::endl;
FreeLibrary(hDll);
system("pause");
return 0;
}
假设你想调用DLL中的一个函数ExportedFn,你可以像这样很简单地导出它:
extern "C" _declspec(dllexport) void ExportedFn(int Param1, char* param2);
必须使用extern "C"链接标记,否则C++编译器会产生一个修饰过的函数名,这样导出函数的名字将不再是ExportedFn
假设这个函数从DLL1.dll导出,那么客户端可以像这样调用这个函数:
HMODULE hMod = LoadLibrary("Dll1.dll"); //在win32下HMODULE与HINSTANCE无区别
typedef void (*PExportedFn)(int, char*);
PExportedFn pfnEF = (PExportedFn)GetProcAdress("ExportedFn");
pfnEF(1, "SomeString");
如果不想让别人看到自己写的函数名字,可以写一个*.def文件,里面对函数名进行符号导出
*.def文件,使用序号对函数名进行导出,可以达到隐藏的目的 #名字是一段程序最精华的注释
EXPORTS
add @12
sub @15
9. c++虚函数表
普通函数与虚函数
总结:
1.通过对象调用时,virtual函数与普通函数都是E8 Call
2.通过指针调用时,virtual函数是FF Call, 也就是间接Call
虚函数大小
class Base
{
public:
int x;
int y;
virtual void func1()
{
printf("func1\n");
}
virtual void func2()
{
printf("func2\n");
}
virtual void func3()
{
printf("func3\n");
}
};
int main()
{
Base base;
printf("%x\n",sizeof(base)); //输出结果为C 12字节 4 + 4 + 4 两个虚函数占同一块4字节地址
//如果上面不是virtual函数,普通的成员函数并不会使结构体大小发生变化
Base* bs = &base;
printf("base 的首地址为(即this):%x\n",&base); //注意base的首地址并不是虚表的地址
printf("base 的虚函数表地址为:%x\n",*(int*)&base); //取前四个字节
typedef void(*pFunction)(void); //声明新变量 函数指针 因为Function函数返回值为void类型
pFunction pFn;
for (int i = 0; i < 3; i++)
{
int temp = *((int*)(*(int*)&base) + i); //把虚函数首地址强转为int* 类型 分别取虚表的第1、2、3个虚函数
pFn = (pFunction)temp; //类型强转为函数指针 pFunction
pFn();
}
}
总结:
1.当类中有虚函数时,会多一个属性,4个字节
2.多出的属性是一个地址,指向一张表(数组)的首地址,里面存储了所有虚函数的地址,结构体首地址的第一个4字节就是虚表地址
绑定 --函数的调用与函数的地址结合的过程
静态绑定:前期绑定,又叫早绑定,在函数编译时已经确定地址 E8 call
动态绑定:又叫晚绑定,在函数运行时才确定地址 ff call 就是多态 --父类指针可以访问子类方法
10. win32
编码
ASCII:用八位二进制的低七位,一共规定了128个字符的编码
扩展ASCII:第八位为1,规定了以1开头的128个字符
Unicode:通常两个字节表示一个字符,而ASCII是一个字节表示一个字符, char c = L'中' 显式告诉编译器使用Unicode表
UTF-8:是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
编码规则:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
C语言宽字节
char x[] = "中国"; // d6 d0 69 fa 00 使用ASCII编码 strlen(x) = 4 不包含00
wchar_t x1[] = L"中国"; // 2d 4e fd 56 00 00 使用Unicode编码 宽字节 strlen(x1) = 2
printf("%s\n",x); //使用控制台默认的编码 打印出 中国
printf(L"%s\n",x1); //打印出乱码 #include<locate.h> 声明 setlocate(LC_ALL,""); 即可告诉编译器使用控制台格式
TCHAR x2[] = TEXT("中国") //宏定义,针对不同的char和tchar做了统一,在不同编译环境中体现不同特性
| 编码 | 大小 | 支持语言 |
|---|---|---|
| ASCII | 1个字节 | 英文 |
| Unicode | 2个字节(生僻字4个) | 所有语言 |
| UTF-8 | 1-6个字节,英文字母1个字节,汉字3个字节,生僻字4-6个字节 | 所有语言 |
WIN32
主要存放在C:\windows\system32 非常重要的几个DLL
Kernel32.dll:最核心的功能模块,比如管理内存,进程和线程相关的函数等 但并不是内核模块
User32.dll:是Windows用户界面相关应用程序接口,如创建窗口和发送信息等
GDI32.dll:Graphical Device Interface(图形设备接口),包含用于画图和显示文本的函数,显示窗口
使用WIN32 API 需要添加头文件#include<windows.h>
WIN32入口函数
WinMain 四个参数
(HINSTANCE hInstance, //imagebase可以理解为程序实例的handle。当程序装入内存中时,操作系统需要利用这个值来标识exe
HINSTANCE hPrevInstance, //永远为空
LPSTR lpCmdLine, //包含了命令行参数,
int mCmdShow) //一个标志,表明窗口是否要最大化,最小化,或者是正常显示。
win32程序出错后不会报错 可以在程序下加一个 GetLastError 返回一个DWORD编码,取MSDN查
Windows为了描述应用程序什么时候产生的,什么位置产生的,提供了一个结构体:MSG,记录事件的详细信息
typedef struct tagMSG{
HWND hwnd; // 消息所指窗口句柄,比如鼠标点击的消息由那个窗口处理
UINT message; //消息名称,形式如WM_SIZE
WPARAM wParam; //32位消息的特定附加信息,具体表示什么取决于message
LPARAM lParam; //32位消息的特定附加信息,具体表示什么取决于message,对消息的进一步说明
DWORD time; //消息创建时间
POINT pt; //消息创建时的鼠标位置 二维坐标
} MSG;
系统消息队列与应用程序消息队列
应用从队列中取出消息,判断消息的类型是不是我关心的,是就处理,不是就让Windows去处理
事件(动作)-->封存在消息中MSG-->系统消息队列-->应用消息队列-->循环取出消息-->处理消息
🏀👑🙃🖐️👊❤️🏷️👈👉🚩😃☝️👆✌️🌞❌⚡⚪
Windows窗口
typedef struct tagWNDCLASSEXW {
UINT cbSize; //WNDCLASSEXA 结构体的大小(sizeof(WNDCLASSEX))
/* Win 3.x */
UINT style; //窗口类的样式
★ WNDPROC lpfnWndProc; //窗口处理函数的指针
int cbClsExtra; //为窗口类的额外信息做记录,初始化为0。
int cbWndExtra; //记录窗口实例的额外信息,系统初始为0
HINSTANCE hInstance; //本模块的实例句柄,当前窗口属于的应用程序
HICON hIcon; //窗口类的图标,为图标资源句柄
HCURSOR hCursor; //窗口类的鼠标样式,为鼠标样式资源的句柄
HBRUSH hbrBackground; //窗口类的背景刷,为背景刷句柄
LPCWSTR lpszMenuName; //指向菜单的指针
LPCWSTR lpszClassName; //指向类名称的指针
/* Win 4.0 */
HICON hIconSm; //小图标的句柄,在任务栏显示的图标
} WNDCLASSEXW, *PWNDCLASSEXW, NEAR *NPWNDCLASSEXW, FAR *LPWNDCLASSEXW;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号