WordCount优化
1.基本任务
1.1本项目Github地址
https://github.com/ReWr1te/WcPro
1.2PSP表格分析
| PSP2.1 | PSP阶段 | 预估耗时 (分钟) |
实际耗时 (分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| ·Estimate | ·估计这个任务需要多上时间 | 60 | 60 |
| Development | 开发 | 680 | 890 |
| ·Analysis | ·需求分析(包括学习新技术) | 30 | 30 |
| ·Design Spec | ·生成设计文档 | 30 | 30 |
| ·Design Review | ·设计复审(和同事审核设计文档) | 20 | 30 |
| ·Coding Standard | ·代码规范(为目前的开发制定合适的规范) | 20 | 30 |
| ·Design | ·具体设计 | 60 | 60 |
| ·Coding | ·具体编码 | 240 | 300 |
| ·Code Review | ·代码复审 | 40 | 50 |
| ·Testing | ·测试(自我测试,修改代码,提交修改) | 240 | 360 |
| Reporting | 报告 | 240 | 300 |
| ·Test Report | ·测试报告 | 100 | 120 |
| ·Size Measurement | ·计算工作量 | 40 | 60 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 100 | 120 |
| 合计 | 980 | 1250 |
这次作业的具体编码用时相对减少,但测试所用时间大大增加。
1.3代码设计思路
本人所在小组对WordCount优化项目定义了4个接口,分别为
String parseCommand(String[] args)//输入命令行命令,返回文件内容
HashMap<String, Integer> parseContent(String str)//输入文件内容,返回单词统计信息
void writeResult(HashMap<String, Integer> result)//输入单词统计信息,排序并将其写入文件
GUI//GUI界面完成人机交互
我要设计实现的接口是void writeResult(HashMap<String, Integer> result),输入的参数为单词统计信息,存放在一个HashMap里面,key是字符串类型,存放的是单词内容,value是整型,存放的是词频。首先,我要对单词词频进行降序排列,对单词词频相同的情况,按照单词所包含的每个字母从a到z的次序依次排列,若单词包含连字符-,则连字符优先。这涉及到对HashMap的排序,我参考了博客 如何将HashMap,按照value值排序[1]和Java Map 按Key排序和按Value排序[2]实现对单词词频的降序排列。下面贴出重写实现Comparator接口的compare方法的代码。
/**
* 排序类
*/
private static class ValueComparator implements Comparator<Map.Entry<String,Integer>> {
public int compare(Map.Entry<String,Integer> m,Map.Entry<String,Integer> n){
if(n.getValue()-m.getValue()==0)
return m.getKey().compareTo(n.getKey());
else
return n.getValue()-m.getValue();
}
}
使用的时候需要调用Collections工具类的sort方法,传入我们自己写的这个实现类的对象,作为参数就可以了。
接下来是输出词频排序的结果,排序之后得到的是一个List,里面存放的是Map.Entry<String,Integer>,输出里面的内容要用到Iterator,为了实现输出的单词和词频空一格,需要获取List里的每一个Map.Entry<String,Integer>的key和value赋给一个字符串然后中间用空格隔开,为了仅输出单词词频从高到低排序的前100个(从1到100),需要一个初值为0的计数变量amount,每取一个Map.Entry<>amount加一,amount大于等于100停止取Map.Entry<>,为了去除输出文件末尾多余的换行符,需截取输出字符串的第一个字符到倒数第二个字符,最后再用覆盖写入的方法(参考博客Java读取txt文件和覆盖写入txt文件和追加写入txt[3])写到result.txt。下面贴出部分实现代码。
/**
* 输出
*/
public String output(List<Map.Entry<String,Integer>> list){
final String pathOfOutput="result.txt";
String outContent="";
Map.Entry<String,Integer> oMap;
int amount=0;//仅输出单词词频从高到低排序的前100个(从1到100)
for(Iterator<Map.Entry<String,Integer>> it=list.iterator();it.hasNext()&&amount<100;++amount){
oMap=it.next();
outContent+=oMap.getKey()+" "+oMap.getValue()+"\n";
}
if(outContent.length()>0) {
outContent = outContent.substring(0, outContent.length() - 1);//去除输出文件末尾多余的换行符
}
writeFile(pathOfOutput,outContent);
return outContent;
}
关键方法流程图
1.4测试设计过程
我对ResultWriter类的排序方法sort()和输出方法output()进行了单元测试,采用黑盒测试和白盒测试方法设计了22个测试用例,进行了等价类划分,得到以下分类:
- 各单词词频不重复;
- 单词词频重复;
- 词频重复基础上单词首字母重复;
- 词频重复基础上单词首字母、二字母重复;
- 词频重复基础上单词首字母、二字母、三字母重复;
- 词频重复基础上字母和连字符的比较;
- 单词数不过百(50个);
- 单词数过百(113个)。
边界情况:
- 单词数为0;
- 单词数为100;
- 调用排序方法之前单词词频已有序;
- 调用排序方法前单词词频倒序排列。
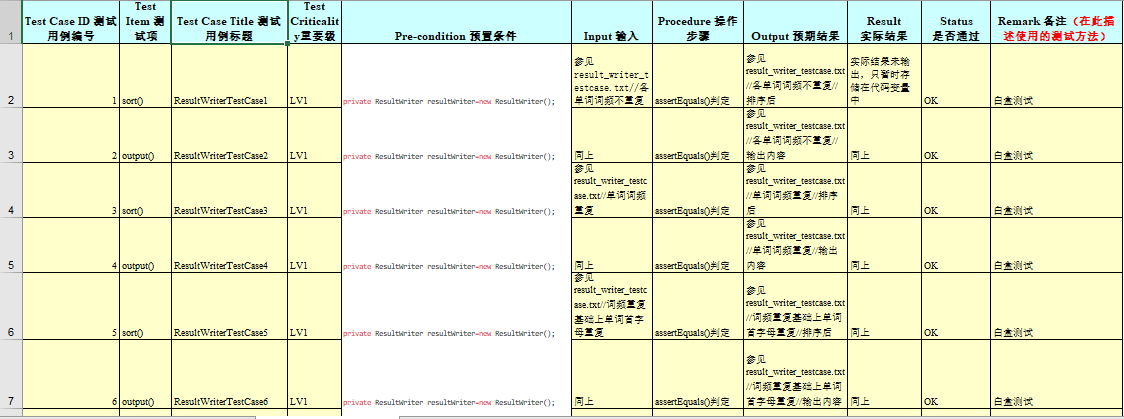
测试用例由于内容过多,下面贴出第一个测试用例的输入和预期输出:
![]()

测试用例详情请见本项目Github的test文件夹上的测试用例清单result_writer_testcase.txt。
下面贴出ResultWriterTestCaseList.xlsx的截图:
1.5测试运行和评价
我在IntelliJ IDEA上用JUnit4单元测试框架(需要安装插件JUnitGenerator V2.0,JUnit插件已被默认安装)对自己负责实现的接口进行单元测试,编写单元测试脚本ResultWriterTest.java,下面给出关键部分代码和运行截图:
/**
* test method sort
* @throws Exception
*/
@Test
public void testSort1() throws Exception {
System.out.println("sort1");
List<Map.Entry<String, Integer>> list = resultWriter.sort(result);
String sortedContent="";
Map.Entry<String,Integer> sortedMap;
for(Iterator<Map.Entry<String,Integer>> it=list.iterator();it.hasNext();){
sortedMap=it.next();
sortedContent+=sortedMap.getKey()+" "+sortedMap.getValue()+"\n";
}
sortedContent=sortedContent.substring(0,sortedContent.length()-1);
assertEquals(sortedStr,sortedContent);
}
/**
* test method output
* @throws Exception
*/
@Test
public void testOutput1() throws Exception {
System.out.println("output1");
List<Map.Entry<String, Integer>> sortedList = resultWriter.sort(result);
String string=resultWriter.output(sortedList);
assertEquals(outContent,string);
}
运行截图:

评价:自己的单元测试的等价类划分还不够完美,可能没覆盖所有情况,边界测试也可能没覆盖所有边界,对输入内容为空的测试没有覆盖,测试覆盖了常见的情况,能满足基本需求。通过测试我觉得被测模块的质量水平较高,该模块被其他模块调用不会出现问题。
2.拓展任务
2.1开发规范说明
我选定的开发规范是《阿里巴巴Java开发手册》,选择了对命名风格、常量定义、代码格式、控制语句、注释规约方面的编程规约,用于检查代码的内容是本人(学号后5位:17121)写的ResultWriter.java。
2.2交叉代码评审
我选择的代码评审对象是组长田诗园(学号后5位:17122)写的而后经组员沃锦文(学号后5位:17103)修改的CommandParser.java,按照开发规范,评审结果如下:
- 第9行,该类缺少@Author的注释信息,应添加作者的注释信息;
- 第10、49、91、104、114行,方法开头不应该用单行注释,应该用javadoc形式的注释;
- 第32、36、40行,未经定义的常量不应该直接出现在代码中,应该对常量进行定义;
- 第69、71、80、98、100、124行,不应该使用行尾注释,应在前一行单独作为注释行注释;
- 第97、99、106、123行,if没有大括号,应在if的判断条件后加大括号;
- 第74行,及时清理不再使用的代码段或配置信息。
2.3静态代码扫描
我使用的扫描工具是Alibaba Java Coding Guidelines插件,下载地址为 https://plugins.jetbrains.com/plugin/10046-alibaba-java-coding-guidelines ,我在IntelliJ IDEA 2017.2.5使用该工具进行静态代码扫描,按照 https://github.com/alibaba/p3c/tree/master/idea-plugin [4]的教程安装使用该插件对自己写的ResultWriter.java进行静态代码检查。
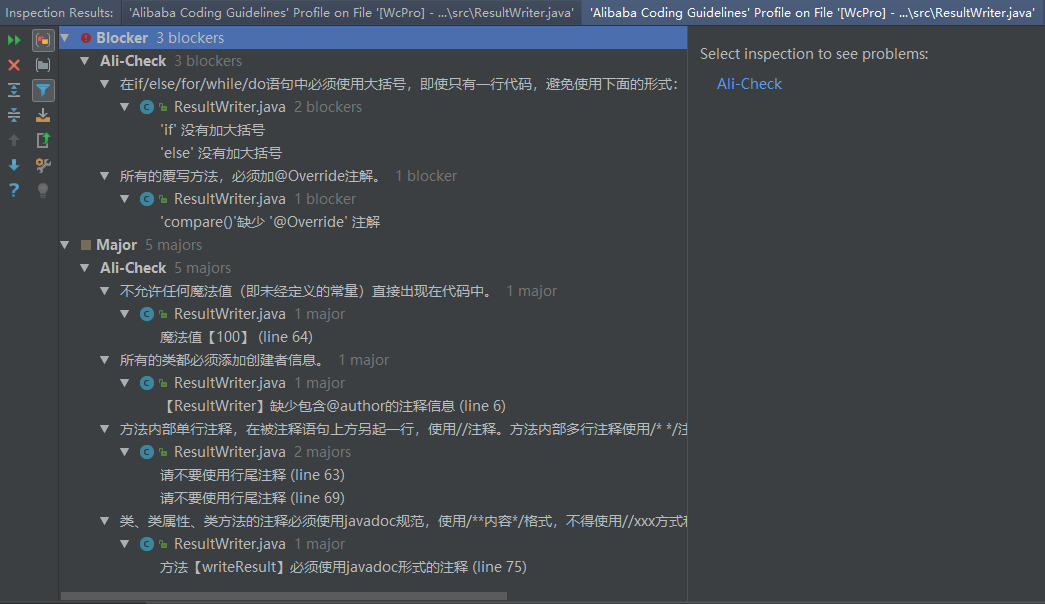
扫描结果:
-
在if/else/for/while/do语句中必须使用大括号,即使只有一行代码,避免使用下面的形式:if (condition) statements;
-
所有的覆写方法,必须加@Override注解。 反例:getObject()与get0bject()的问题。一个是字母的O,一个是数字的0,加@Override可以准确判断是否覆盖成功。另外,如果在抽象类中对方法签名进行修改,其实现类会马上编译报错。
-
不允许任何魔法值(即未经定义的常量)直接出现在代码中。
-
所有的类都必须添加创建者信息。 说明:在设置模板时,注意IDEA的@author为${USER},而eclipse的@author为${user},大小写有区别,而日期的设置统一为yyyy/MM/dd的格式。
-
方法内部单行注释,在被注释语句上方另起一行,使用//注释。方法内部多行注释使用/* */注释。注意与代码对齐。
-
类、类属性、类方法的注释必须使用javadoc规范,使用/**内容*/格式,不得使用//xxx方式和/*xxx*/方式。 说明:在IDE编辑窗口中,javadoc方式会提示相关注释,生成javadoc可以正确输出相应注释;在IDE中,工程调用方法时,不进入方法即可悬浮提示方法、参数、返回值的意义,提高阅读效率。
运行截图:
按照扫描结果并参考《阿里巴巴java开发手册》进行代码改进后的静态代码检查运行截图:

2.4组内代码分析
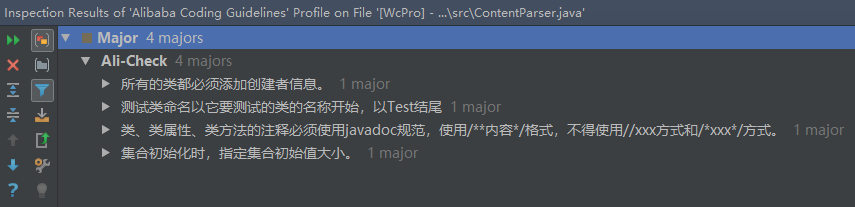
整个小组的代码存在一些共同的问题:
- 代码没加作者信息;
- 方法开头没使用javadoc形式的注释;
- 常量未定义直接在代码中使用;
- 大量使用行尾注释;
- 未及时清理不用的代码段;
- if判定条件后没写大括号。
下面贴出静态代码检查工具运行截图:

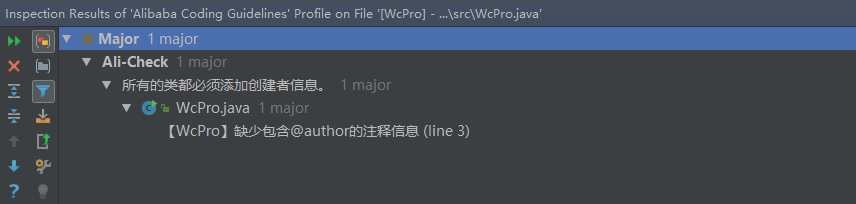
我们按照扫描的结果并参考《阿里巴巴java开发手册》改进代码,实现了比较好的代码规范。
3.高级任务
3.1测试数据集
经过试验,我们发现当txt文件的字符数达到千万级别时能给程序带来压力,故我们小组创建了jQuery.txt作为测试数据集,大小:22.9 MB (24,025,398 字节),占用空间:22.9 MB (24,027,136 字节),包含24,025,398个字符,307,981行。
我在自己的电脑(操作系统:64位 win10,处理器:Intel(R) Celeron(R) CPU N2920 @ 1.86GHz 1.86GHz,已安装的内存(RAM):8.00GB(7.87 GB 可用))的IntelliJ IDEA 2017.2.5对测试数据集进行测试,运行程序得到处理时长为4957ms。
3.2同行评审过程描述
- 角色分工:
- 主持人&记录员:田诗园
- 讲解员:邱利光 沃锦文 王启萌 田诗园
- 评审员:邱利光 沃锦文 王启萌 田诗园
- 作者:邱利光 沃锦文 王启萌 田诗园
- 评审目的:
- 评定代码对于性能需求的满足程度。
- 对程序进行性能优化。
- 评审意见收集:
- 代码并无明显缺陷。
- 代码性能可以继续优化。
- 评审结果
- 正则表达式效率较慢,可以用状态机来提取单词。
- 考虑到程序对查找的性能要求比较高,单词统计我们采用HashMap来存储。当数据容量较少时其内部实现为一个链表,当数据量较大时,自动改用二叉树进行存储,有效提高了查询效率。
- 输出单词时,改变原来的每个单词打开一次文件的做法,只打开一次文件,全部输出后关闭文件流,提高了IO速度。
3.3性能分析
- 正则表达式效率较慢,可以用状态机来提取单词。
- 考虑到程序对查找的性能要求比较高,单词统计我们采用HashMap来存储。当数据容量较少时其内部实现为一个链表,当数据量较大时,自动改用二叉树进行存储,有效提高了查询效率。
- 输出单词时,改变原来的每个单词打开一次文件的做法,只打开一次文件,全部输出后关闭文件流,提高了IO速度。
3.4性能优化
- 使用状态机代替正则式分词提高效率。
- 把多次输出改为一次输出提高IO速度。
3.5作业小结
在软件开发中,软件测试很重要,特别是在团队合作中,自己写的代码要交给他人使用,应保证代码质量,要对自己写的代码进行单元测试,确保没有缺陷,项目出现问题也不会出现在自己写的代码上,保证代码质量能加快项目开发进度。
参考文献链接
[1] https://blog.csdn.net/u012730840/article/details/19699179
[2] https://www.cnblogs.com/zhujiabin/p/6164826.html
[3] https://www.cnblogs.com/Simeonwu/p/7565005.html
[4] https://github.com/alibaba/p3c/tree/master/idea-plugin


 浙公网安备 33010602011771号
浙公网安备 33010602011771号