Django之whoosh搜索引擎
一:搜索引擎简介
一:搜索引擎介绍
django是python语言后台web开发的一个框架,配合一些插件可为web网站实现很方便的搜索功能
django搜索引擎使用whoosh是一个纯python开发的全文搜索引擎,小巧简单
二:搜索引擎作用
搜索引擎可以在表中针对某些关键进行全文分析,根据关键词建立索引数据 mu
索引类似于新华字典的目录,可以快速搜索数据
# 例如 MacBook:商品1,商品2,商品3
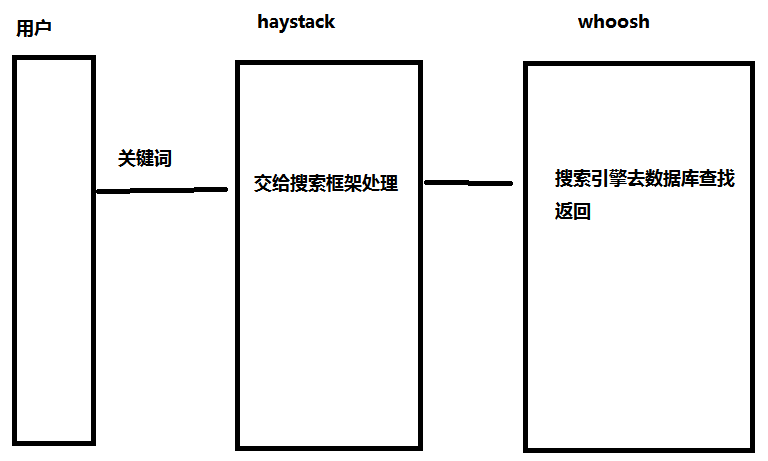
二:搜索引擎框架(haystack)
一:作用
直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立、搜索解析等细节问题。
haystack支持多种搜索引擎,whoosh,solr,elasticsearch等 虽然whoosh性能相比elasticsearch较低,但是其无二进制包程序不会莫名其妙崩溃,在中小型网站完全适用
二:图解
三:whoosh使用方式
一:安装依赖包
pip install django-haystack # 安装haystack框架 pip install whoosh # 安装whoosh搜索引擎
二:settings配置文件
一:注册haystack框架
INSTALLED_APPS = [ # 注册haystack框架 'haystack' ]
二:配置搜索引擎
HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine', 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), # whoosh_index 文件夹不需要自己手动创建 会自动创建 } } # 添加此项,当数据库改变时,会自动更新索引,非常方便 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
三:全局添加url路由
urlpatterns = [ ... url(r'^search/', include('haystack.urls')), ]
四:应用目录下创建search_indexes.py文件(固定名称)

search_indexes代码
from haystack import indexes # 导入索引 from . import models # 导入模型表 class GoodsIndex(indexes.SearchIndex,indexes.Indexable): text = indexes.CharField(document=True,use_template=True)
'''
document:使用文档建立索引字段
use_template:使用模板语法
'''
def get_model(self): # 为那个模型表建立索引 return models.GoodInfo def index_queryset(self, using=None): return self.get_model().objects.all()
五:模板文件夹创建如下文件
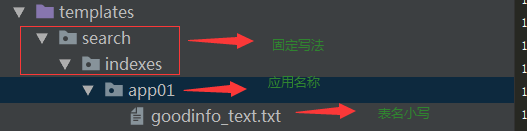
_text.txt指定模型表中那些字段建立索引
# 指定那些字段建立索引 {{object.name}} # 商品名称建立索引 {{object.desc}} # 商品简介建立索引
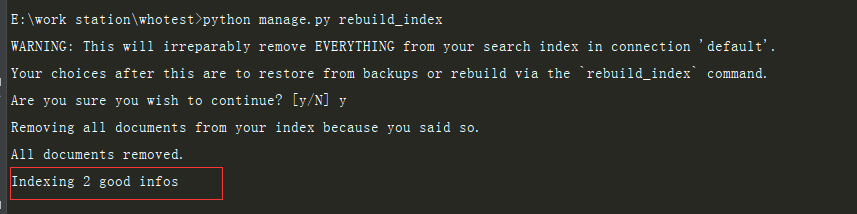
六:生成索引文件
python manage.py rebuild_index
七:在templates/search下建立search.html文件
搜索出结果后,haystack会把搜索出的结果传递给templates/search目录下的search.html,传递的上下文包括:
query:搜索关键字
page:当前页的page对象 –>遍历page对象,获取到的是SearchResult类的实例对象,对象的属性object才是模型类的对象。
paginator:分页paginator对象
<form action="/search" method="get"> <p>商品搜索:<input type="text" name="q"></p> <p>提交:<input type="submit"></p> </form> <p>搜索关键字:{{ query }}</p> <p>当前页page对象:{{ page }}</p> <p>分页对象:{{ paginator }}</p> <ul> {% for item in page %} <li> {{ item.object.name }}</li> <li> {{ item.object.desc }}</li> {% endfor %} </ul>

通过HAYSTACK_SEARCH_RESULTS_PER_PAGE 可以控制每页显示数量。
四:jieba
一:安装
pip install jieba
二:作用
whoosh不能很好的进行分词 而使用jieba可以很好的分词
二:使用方式
import jieba split_data = '很好吃的草莓' # 要被切割的数据 res = jieba.cut(split_data,cut_all=True) print(res) # <generator object Tokenizer.cut at 0x0000000009EA27D8> 拿到一个生成器 for value in res: print(value)
三:Haystack使用方式
一:在haystack的安装文件夹下,例如D:\Softwares\python3.6\Lib\site-packages\haystack\backends(每个人安装目录不一样 根据自己的安装目录创建)建立ChineseAnalyzer.py文件
import jieba from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer): def __call__(self, value, positions=False, chars=False, keeporiginal=False, removestops=True, start_pos=0, start_char=0, mode='', **kwargs): t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs) seglist = jieba.cut(value, cut_all=True) for w in seglist: t.original = t.text = w t.boost = 1.0 if positions: t.pos = start_pos + value.find(w) if chars: t.startchar = start_char + value.find(w) t.endchar = start_char + value.find(w) + len(w) yield t def ChineseAnalyzer(): return ChineseTokenizer()
二:将上面backends目录中的whoosh_backend.py文件,复制一份命名为whoosh_cn_backend.py,然后打开此文件进行替换:
# 顶部引入刚才添加的中文分词 from .ChineseAnalyzer import ChineseAnalyzer # 在整个py文件中,查找 替换 analyzer=StemmingAnalyzer()
analyzer=ChineseAnalyzer()
三: 修改settings.py文件中的配置项。
HAYSTACK_CONNECTIONS = { 'default': { # 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine', # 原来的默认的 'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine', # jieba搜索 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), # whoosh_index 文件夹不需要自己手动创建 会自动创建 } }
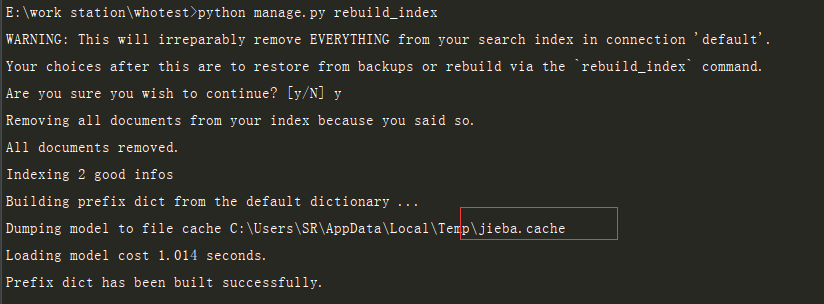
四:重新生成索引文件
python manage.py rebuild_index

 浙公网安备 33010602011771号
浙公网安备 33010602011771号