并发编程之进程
一:进程基础概念
【1】什么是进程
(1)程序:就是自己定义的代码
(2)进程:就是运行的程序
PS:
(1)进程是一个实体 每一个进程都拥有自己的名称空间
(2)同一个程序可以被执行多次 即会拥有多个自己独立的名称空间 因为其独立的 数据不会冲突影响
【2】进程的调度方式
(1)先来先服务:其是最简单的调度算法,根据先来先调度 其对长进程比较有利 但是读短进程不利
例如:程序A调度使用CPU时间需要24小时 程序B调度CPU使用时间只需要1S 但是程序A先执行的 那么程序B必须等24小时才能开始执行
(2)短进程优先调度算法:其是指对短进程调度算法 对短进程有利 但是对长进程不利
例如:程序A调度使用CPU时间需要24小时 程序B调度CPU使用时间只需要1S 假设是程序A先执行 但是当使用该算法的时候 依旧是程序B先执行
(3)时间片轮转发:其是将CPU处理时间等分 每个程序平分这些时间片
例如:CPU执行时间为1S 现在有10个程序在执行 等分1S时间 即每个程序使用0.1S来处理程序调度
(4)多级反馈队列:其设置多个就绪队列 且为多个队列设置不同的优先级 第一队列优先级最高 从上到下优先级逐渐降低 导致程序处理时间在逐渐加长
例如:程序A的优先级最高 程序B优先级次高 程序C的优先级最低 那么处理时间程序A最先处理 其次是B 最后是C
二:同步/异步以及阻塞非阻塞
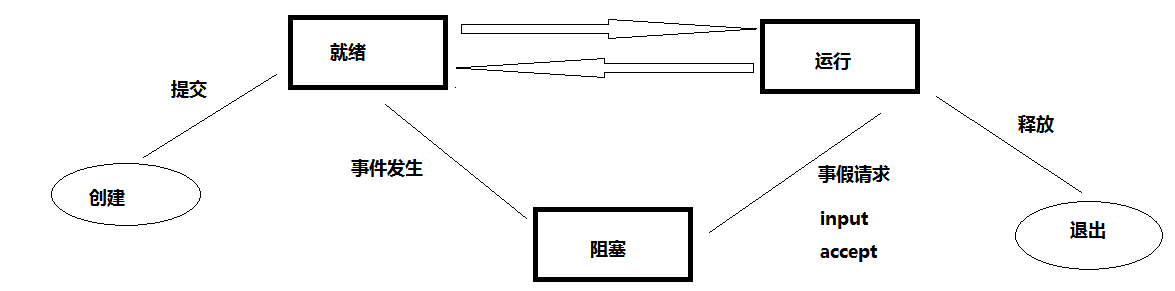
【1】程序运行状态
(1)定义:由于程序在运行的时候 受操作系统的调度算法控制 程序会进入几个状态
(2)程序运行状态
(1)就绪态:程序收到除CPU以外的所有调度资源
(2)运行态:进程已获得处理机处理 并且获得处理即可
(3)阻塞态:由于等待某个事情发生而无法执行 例如:input等待用户输入,accept等待接收对方对方传来的数据等
(3)程序运行状态图
【2】同步/异步
(1)同步/异步:指的是程序的提交方式
(1)同步:提交任务之后 等待任务的提交结果 期间不做任何事
(2)异步:提交任务之后 无需等待任务的提交结果 直接执行下一行代码
PS:结果获取使用异步回调机制---->即程序主动告诉我执行结果
(2)阻塞/非阻塞:描述的程序运行状态
(1)阻塞:阻塞状态
(2)非阻塞:就绪态/或者运行态
【3】multiprocess模块
(1)作用:
仔细说来,multiprocess不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块。由于提供的子模块非常多,为了方便大家归类记忆,我将这部分大致分为四个部分:创建进程部分,进程同步部分,进程池部分,进程之间数据共享
(2)multiprocess.process模块


1 p.start():启动进程,并调用该子进程中的p.run() 2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法 3 p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁 4 p.is_alive():如果p仍然运行,返回True 5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 2 p.name:进程的名称 3 p.pid:进程的pid 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了
(3)使用process创建进程
import time from multiprocessing import Process def f(name): print('hello', name) print('我是子进程') if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() time.sleep(1) print('执行主进程的内容了')
import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) print('我是子进程') if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() #p.join() print('我是父进程')
import os from multiprocessing import Process def f(x): print('子进程id :',os.getpid(),'父进程id :',os.getppid()) return x*x if __name__ == '__main__': print('主进程id :', os.getpid()) p_lst = [] for i in range(5): p = Process(target=f, args=(i,)) p.start()
import os from multiprocessing import Process class MyProcess(Process): def __init__(self,name): super().__init__() self.name=name def run(self): print(os.getpid()) print('%s 正在和女主播聊天' %self.name) p1=MyProcess('wupeiqi') p2=MyProcess('yuanhao') p3=MyProcess('nezha') p1.start() #start会自动调用run p2.start() # p2.run() p3.start() p1.join() p2.join() p3.join() print('主线程')
from multiprocessing import Process def work(): global n n=0 print('子进程内: ',n) if __name__ == '__main__': n = 100 p=Process(target=work) p.start() print('主进程内: ',n)
(4)守护进程
(1)作用:会随着主进程结束而结束
(2)主进程创建守护进程
1:守护进程会在主进程结束之后立马结束
2:守护进程内无法在创建子进程 否则会报错
import os import time from multiprocessing import Process class Myprocess(Process): def __init__(self,person): super().__init__() self.person = person def run(self): print(os.getpid(),self.name) print('%s正在和女主播聊天' %self.person) p=Myprocess('哪吒') p.daemon=True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() time.sleep(10) # 在sleep时查看进程id对应的进程ps -ef|grep id print('主')
from multiprocessing import Process def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") p1=Process(target=foo) p2=Process(target=bar) p1.daemon=True p1.start() p2.start() time.sleep(0.1) print("main-------")#打印该行则主进程代码结束,则守护进程p1应该被终止.#可能会有p1任务执行的打印信息123,因为主进程打印main----时,p1也执行了,但是随即被终止.
(5)方法属性
from multiprocessing import Process import time import random class Myprocess(Process): def __init__(self,person): self.name=person super().__init__() def run(self): print('%s正在和网红脸聊天' %self.name) time.sleep(random.randrange(1,5)) print('%s还在和网红脸聊天' %self.name) p1=Myprocess('哪吒') p1.start() p1.terminate()#关闭进程,不会立即关闭,所以is_alive立刻查看的结果可能还是存活 print(p1.is_alive()) #结果为True print('开始') print(p1.is_alive()) #结果为False
1 class Myprocess(Process): 2 def __init__(self,person): 3 self.name=person # name属性是Process中的属性,标示进程的名字 4 super().__init__() # 执行父类的初始化方法会覆盖name属性 5 #self.name = person # 在这里设置就可以修改进程名字了 6 #self.person = person #如果不想覆盖进程名,就修改属性名称就可以了 7 def run(self): 8 print('%s正在和网红脸聊天' %self.name) 9 # print('%s正在和网红脸聊天' %self.person) 10 time.sleep(random.randrange(1,5)) 11 print('%s正在和网红脸聊天' %self.name) 12 # print('%s正在和网红脸聊天' %self.person) 13 14 15 p1=Myprocess('哪吒') 16 p1.start() 17 print(p1.pid) #可以查看子进程的进程id
(5)互斥锁
作用:当多个进程操作同一份数据的时候 会引发数据安全或者数据错乱等
PS:因为对于多个进程来说 内存空间是独立的 每个进程操作维护自己的数据 所以当操作同一份数据 容易导致数据错乱
import os import time import random from multiprocessing import Process def work(n): print('%s: %s is running' %(n,os.getpid())) time.sleep(random.random()) print('%s:%s is done' %(n,os.getpid())) if __name__ == '__main__': for i in range(3): p=Process(target=work,args=(i,)) p.start()
import os import time import random from multiprocessing import Process,Lock def work(lock,n): lock.acquire() print('%s: %s is running' % (n, os.getpid())) time.sleep(random.random()) print('%s: %s is done' % (n, os.getpid())) lock.release() if __name__ == '__main__': lock=Lock() for i in range(3): p=Process(target=work,args=(lock,i)) p.start()
#文件db的内容为:{"count":1} #注意一定要用双引号,不然json无法识别 #并发运行,效率高,但竞争写同一文件,数据写入错乱 from multiprocessing import Process,Lock import time,json,random def search(): dic=json.load(open('db')) print('\033[43m剩余票数%s\033[0m' %dic['count']) def get(): dic=json.load(open('db')) time.sleep(0.1) #模拟读数据的网络延迟 if dic['count'] >0: dic['count']-=1 time.sleep(0.2) #模拟写数据的网络延迟 json.dump(dic,open('db','w')) print('\033[43m购票成功\033[0m') def task(): search() get() if __name__ == '__main__': for i in range(100): #模拟并发100个客户端抢票 p=Process(target=task) p.start()
#文件db的内容为:{"count":5} #注意一定要用双引号,不然json无法识别 #并发运行,效率高,但竞争写同一文件,数据写入错乱 from multiprocessing import Process,Lock import time,json,random def search(): dic=json.load(open('db')) print('\033[43m剩余票数%s\033[0m' %dic['count']) def get(): dic=json.load(open('db')) time.sleep(random.random()) #模拟读数据的网络延迟 if dic['count'] >0: dic['count']-=1 time.sleep(random.random()) #模拟写数据的网络延迟 json.dump(dic,open('db','w')) print('\033[32m购票成功\033[0m') else: print('\033[31m购票失败\033[0m') def task(lock): search() lock.acquire() get() lock.release() if __name__ == '__main__': lock = Lock() for i in range(100): #模拟并发100个客户端抢票 p=Process(target=task,args=(lock,)) p.start()
PS:
(1)互斥锁将程序运行方式从并发变成串行
(2)降低了程序执行效率 提高了数据的安全性
三:进程之间的数据通信
(1)队列:创建共享进程队列 实现不同进程之间的数据共享
例如:
from multiprocessing import Queue queue = Queue(5) # 5 = maxsize最大传输队列 不写默认无穷大 # 队列中存放数据 queue.put(1) queue.put(2) queue.put(3) queue.put(4) queue.put(5) # queue.put(6) # 取数据 print(queue.get()) print(queue.get()) print(queue.get()) print(queue.get()) print(queue.get()) print(queue.get())
PS:
(1)当队列中数据存满之后 如果继续存放程序会一直处于阻塞状态 直到数据被取走
(2)当队列中的数据被取走完毕 如果继续取值 程序不会报错 会处于阻塞状态
(2)队列的属性方法
from multiprocessing import Queue queue = Queue(5) # 5 = maxsize最大传输队列 不写默认无穷大 # 队列中存放数据 queue.put(1) queue.put(2) # 查看队列是否处于饱和状态 # print(queue.full()) # False queue.put(3) queue.put(4) queue.put(5) # print(queue.full()) # True # 取数据 print(queue.get()) print(queue.get()) print(queue.get()) # 查看队列是否为空 # print(queue.empty()) # False print(queue.get()) print(queue.get()) print(queue.empty()) # True # 取值如果没有值 直接报错 停止等待 queue.get_nowait()
PS:
(1)full empty get_nowaite都不适用于多进程
(2)极限情况 当我上述代码刚好执行完毕的下一瞬间 队列中数据发生变化
例如:当队列为5个的时候 执行full代码此时为True 但是极限情况是 此时刚好那个从队列中被取出来一个值 此时队列不为满的
(3)IPC机制
作用:实现队列之间的通信
from multiprocessing import Process, Queue def producer(queue, name): queue.put('hello啊%s' % name) if __name__ == '__main__': queue = Queue() p = Process(target=producer, args=(queue, 'SR')) p.start() print(queue.get())
from multiprocessing import Process, Queue def producer(queue): queue.put('hello啊 我是进程producer') def consumer(queue): print(queue.get(queue)) # hello啊 我是进程producer if __name__ == '__main__': queue = Queue() p = Process(target=producer,args=(queue,)) c = Process(target=consumer,args=(queue,)) p.start() c.start()
(4)生产者/消费者模型
(1)生产者:生产/制造数据的
(2)消费者:消费/处理数据的
作用:解决队列中数据存取问题
(1)数据存放速度小于取出速度
(2)数据存放速度大于取出速度
例如:
from multiprocessing import Process, Queue import time import random def producer(name, food, q): for i in range(10): data = '%s制造了%s%s' % (name, food, i) # 模拟生产包子延时 time.sleep(random.random()) q.put(data) print(data) def consumer(name, q): while True: data = q.get(q) print('%s吃了%s '%(name,data)) # 模拟吃包子延时 time.sleep(random.random()) if __name__ == '__main__': q = Queue() p = Process(target=producer, args=('SR', '包子', q)) c = Process(target=consumer, args=('河马', q)) p.start() c.start()
PS:
产生问题:
(1)在此案例中当生产者不在生产数据 而消费者仍然在接收数据 但是此时无数据可以接收 导致进程一直处于阻塞状态
解决思路:
(1)首先我们要明确确定生产者的确不在生产数据
(2)消费者也将对队列中的数据读取完毕
(3)解决办法一
(1)可以让生产者在队列中生产一个数据None 当消费者受到该数据的时候 会直接结束循环
例如:
from multiprocessing import Process, Queue import time import random def producer(name, food, q): for i in range(10): data = '%s制造了%s%s' % (name, food, i) # 模拟生产包子延时 time.sleep(random.random()) q.put(data) print(data) def consumer(name, q): while True: data = q.get() if data == None: break print('%s吃了%s'%(name,data)) time.sleep(random.random()) if __name__ == '__main__': q = Queue() p = Process(target=producer, args=('SR', '包子', q)) c = Process(target=consumer, args=('河马', q)) c1 = Process(target=consumer, args=('河马', q)) p.start() c.start() q.put(None) q.put(None)
PS:此种方法虽然可以解决上述问题 但是每当添加一个消费者都需要往队列中上传一个None 扩展性很差
解决方法二:joinablequeue
from multiprocessing import Process,Queue,JoinableQueue import random import time # # def producer(name,food,q): for i in range(10): data = '%s生产了%s%s'%(name,food,i) time.sleep(random.random()) q.put(data) print(data) def consumer(name,q): while True: data = q.get() if data == None:break print('%s吃了%s'%(name,data)) time.sleep(random.random()) q.task_done() # 告诉队列你已经从队列中取出了一个数据 并且处理完毕了 if __name__ == '__main__': q = JoinableQueue() p = Process(target=producer,args=('SR','馒头',q)) c = Process(target=consumer,args=('河马',q)) c1 = Process(target=consumer,args=('憨子',q)) p.start() # 队列数据读取完毕 说明消费者没有值可以取 可以关闭消费者了 即主进程结束可以关闭子进程了 c.daemon = True c1.daemon = True c.start() c1.start() # 等待队列数据读取完毕 p.join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号