

iOS之@synchronized多线程递归锁的实现
@synchronized支持多线程递归调用,接下来我们来看一下@synchronized的底层实现。
一、@synchronized的源码入口
id _sync_obj = (id)obj1; objc_sync_enter(_sync_obj); struct _SYNC_EXIT { _SYNC_EXIT(id arg) : sync_exit(arg) {} ~_SYNC_EXIT() {objc_sync_exit(sync_exit);} id sync_exit; } _sync_exit(_sync_obj);
其中sync_exit()函数调用了_SYNC_EXIT的构造函数,而~_SYNC_EXIT是_SYNC_EXIT的析构函数,那么在@synchronized的底层就是通过调用objc_sync_enter 和 objc_sync_exit 实现的。
二、enter、exit函数
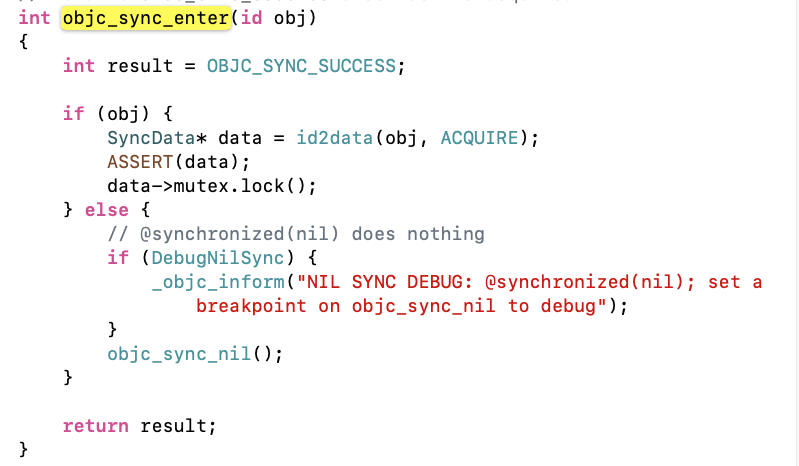

我们从两个函数的源码中可以发现,在这两次函数中通过data->mutex来实现加锁解锁操作,而data就是SyncData的实例化对象,所以接下来我们看下SyncData结构体。
二、SyncData
//alignas 关键字用来声明对齐字节的 typedef struct alignas(CacheLineSize) SyncData { //链表结构 struct SyncData* nextData; //@synchronized中传入的对象 DisguisedPtr<objc_object> object; // 多少个线程使用 int32_t threadCount; // number of THREADS using this block // 一把递归锁 recursive_mutex_t mutex; } SyncData;
我们可以看到SyncData的基本结构是一个存放了我们传入对象的单向链表、一把递归锁、以及使用的线程数量。我们先来看一下这个锁:
他是基于os_unfair_lock的封装:
using recursive_mutex_t = recursive_mutex_tt<LOCKDEBUG>; class recursive_mutex_tt : nocopy_t { os_unfair_recursive_lock mLock; //code ... } /*! * @typedef os_unfair_recursive_lock * * @abstract * Low-level lock that allows waiters to block efficiently on contention. * * @discussion * See os_unfair_lock. * */ OS_UNFAIR_RECURSIVE_LOCK_AVAILABILITY typedef struct os_unfair_recursive_lock_s { os_unfair_lock ourl_lock; uint32_t ourl_count; } os_unfair_recursive_lock, *os_unfair_recursive_lock_t;
接下来,我们重点关注一下id2data,在此之前,我们将一会分析id2data所遇到的一些数据结构先做一个整理分析。
2.1 SyncCache
typedef struct { SyncData *data; unsigned int lockCount; // number of times THIS THREAD locked this block } SyncCacheItem; typedef struct SyncCache { unsigned int allocated; unsigned int used; SyncCacheItem list[0]; } SyncCache;
在SyncCache中存放的是SyncData的缓存,可以得到他的结构体(https://juejin.cn/post/7105373573635637255#heading-4)


2.2 Fast Cache(快速缓存)
这个快速缓存与SyncCache类似,都是一种缓存机制,区别在于SyncCache是存了一个列表,而快速缓存只是存了单个的item。
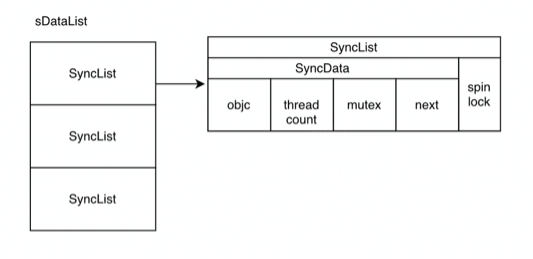
2.3 sDataLists
他是全局静态的,全局只有一张,是一个哈希表
// Use multiple parallel lists to decrease contention among unrelated objects. #define LOCK_FOR_OBJ(obj) sDataLists[obj].lock #define LIST_FOR_OBJ(obj) sDataLists[obj].data // 哈希表 static StripedMap<SyncList> sDataLists;
对于其中的SyncList,如下所示:

我们可以得到他的结构体(https://juejin.cn/post/7105373573635637255#heading-4)
2.4 TLS(Thread Local Storage)
TLS就是线程局部存储,是操作系统为线程单独提供的私有空间,能存储只属于当前线程的一些数据。
2.5 StripedMap
StripedMap 、的主要作用是用来缓存带spinlock锁能力的类或者结构体;苹果用StripedMap 来提前准备一定个数的 SyncList 放这里,然后在调用的时候均匀的进行分配。他的工作原理:如果说系统在全局只初始化一张 SyncList用来管理所有对象的加锁和解锁操作,会导致效率很慢,因为每个对象在操作这个表的时候,都需要等待其他对象操作完解锁之后才能进行,这样就会使得内存的消耗会非常大。
三、id2Data
我们将id2Data分成四个部分,分别解读一下:
3.1 在快速缓存里找;每个线程都会有一个这样的FastCache。
#if SUPPORT_DIRECT_THREAD_KEYS // 1⃣️去快速缓存里面找 // Check per-thread single-entry fast cache for matching object bool fastCacheOccupied = NO; //拿出快速缓存里面的SyncData SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY); if (data) { fastCacheOccupied = YES; // 如果是同一个 if (data->object == object) { // Found a match in fast cache. uintptr_t lockCount; result = data; lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY); //异常处理,判断 if (result->threadCount <= 0 || lockCount <= 0) { _objc_fatal("id2data fastcache is buggy"); } switch(why) { //加锁的时候(ENTER) case ACQUIRE: { lockCount++; //lockCount放入快速缓存 tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount); break; } //解锁的时候(EXIT) case RELEASE: lockCount--; //取出加锁的时候的lockCount tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount); if (lockCount == 0) { // remove from fast cache tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL); // atomic because may collide with concurrent ACQUIRE // SyncData中记录线程数量的-1 OSAtomicDecrement32Barrier(&result->threadCount); } break; case CHECK: // do nothing break; } //直接返回 return result; } } #endif
3.2 SyncCache缓存遍历查找(如果快速缓存找不到就来这个里面找)
{ // 2⃣️在线程的TLS中找objc对象,然后再维护2个count lockCount 和 threadCount // Check per-thread cache of already-owned locks for matching object // 每个线程都只有一份 SyncCache *cache = fetch_cache(NO); if (cache) { unsigned int i; //遍历查找 for (i = 0; i < cache->used; i++) { SyncCacheItem *item = &cache->list[i]; if (item->data->object != object) continue; // Found a match. result = item->data; if (result->threadCount <= 0 || item->lockCount <= 0) { _objc_fatal("id2data cache is buggy"); } switch(why) { case ACQUIRE: item->lockCount++; break; case RELEASE: item->lockCount--; //如果==0,该线程已经使用完了 if (item->lockCount == 0) { // remove from per-thread cache cache->list[i] = cache->list[--cache->used]; // atomic because may collide with concurrent ACQUIRE // threadCount -1。防止和加锁的时候通途 OSAtomicDecrement32Barrier(&result->threadCount); } break; case CHECK: // do nothing break; } //返回 return result; } } }
我们看看fetch_cache()获取data的函数:
static SyncCache *fetch_cache(bool create) { _objc_pthread_data *data; data = _objc_fetch_pthread_data(create); if (!data) return NULL; if (!data->syncCache) { if (!create) { return NULL; } else { int count = 4; data->syncCache = (SyncCache *) calloc(1, sizeof(SyncCache) + count*sizeof(SyncCacheItem)); data->syncCache->allocated = count; } } // Make sure there's at least one open slot in the list. if (data->syncCache->allocated == data->syncCache->used) { data->syncCache->allocated *= 2; data->syncCache = (SyncCache *) realloc(data->syncCache, sizeof(SyncCache) + data->syncCache->allocated * sizeof(SyncCacheItem)); } return data->syncCache; }
接着我们看看_objc_pthread_data的数据结构:
//每一个线程的存储 // objc per-thread storage typedef struct { struct _objc_initializing_classes *initializingClasses; // for +initialize // ⚠️注释!!! struct SyncCache *syncCache; // for @synchronize struct alt_handler_list *handlerList; // for exception alt handlers char *printableNames[4]; // temporary demangled names for logging const char **classNameLookups; // for objc_getClass() hooks unsigned classNameLookupsAllocated; unsigned classNameLookupsUsed; // If you add new fields here, don't forget to update // _objc_pthread_destroyspecific() } _objc_pthread_data;
3.3 sDataLists查找(在缓存里找不到 来这里找)
{ // Thread cache didn't find anything. // Walk in-use list looking for matching object // Spinlock prevents multiple threads from creating multiple // locks for the same new object. // We could keep the nodes in some hash table if we find that there are // more than 20 or so distinct locks active, but we don't do that now. // 这里加锁内容包括sDataLists查找,和创建SyncData,目的是为了防止创建重复的和创建SyncData lockp->lock(); { SyncData* p; SyncData* firstUnused = NULL; //遍历链表 for (p = *listp; p != NULL; p = p->nextData) { //找到SyncData if ( p->object == object ) { result = p; // atomic because may collide with concurrent RELEASE // threadCount + 1 OSAtomicIncrement32Barrier(&result->threadCount); // 跳转:done goto done; } if ( (firstUnused == NULL) && (p->threadCount == 0) ) firstUnused = p; } // no SyncData currently associated with object if ( (why == RELEASE) || (why == CHECK) ) goto done; //链表里面有无用节点,利用起来 // an unused one was found, use it if ( firstUnused != NULL ) { result = firstUnused; result->object = (objc_object *)object; result->threadCount = 1; goto done; } } }
3.4 sDataLists(sDataLists找不到,就需要新建SyncData,并添加到缓存中)
{ // 4⃣️再找不到,只能创建 // Allocate a new SyncData and add to list. // XXX allocating memory with a global lock held is bad practice, // might be worth releasing the lock, allocating, and searching again. // But since we never free these guys we won't be stuck in allocation very often. posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData)); result->object = (objc_object *)object; result->threadCount = 1; new (&result->mutex) recursive_mutex_t(fork_unsafe_lock); //放到头节点 result->nextData = *listp; *listp = result; }
// 5⃣️缓存 done: lockp->unlock(); if (result) { // Only new ACQUIRE should get here. // All RELEASE and CHECK and recursive ACQUIRE are // handled by the per-thread caches above. if (why == RELEASE) { // Probably some thread is incorrectly exiting // while the object is held by another thread. return nil; } if (why != ACQUIRE) _objc_fatal("id2data is buggy"); if (result->object != object) _objc_fatal("id2data is buggy"); #if SUPPORT_DIRECT_THREAD_KEYS // 支持线程快速缓存,并且快速缓存没有东西 if (!fastCacheOccupied) { //存储到快速缓存中 // Save in fast thread cache tls_set_direct(SYNC_DATA_DIRECT_KEY, result); tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1); } else #endif { //在线程缓存中存储 // Save in thread cache if (!cache) cache = fetch_cache(YES); cache->list[cache->used].data = result; cache->list[cache->used].lockCount = 1; cache->used++; } } return result; }
四、@synchronized的底层原理
我们总结一下@synchronized的底层原理:@synchronized根据我们传入的对象,为每个线程构建一把递归锁,同时记录每个线程加锁的次数,通过两点,对每条线程用不同的递归锁进行加锁和解锁的操作,从而达到多线程递归调用的目的。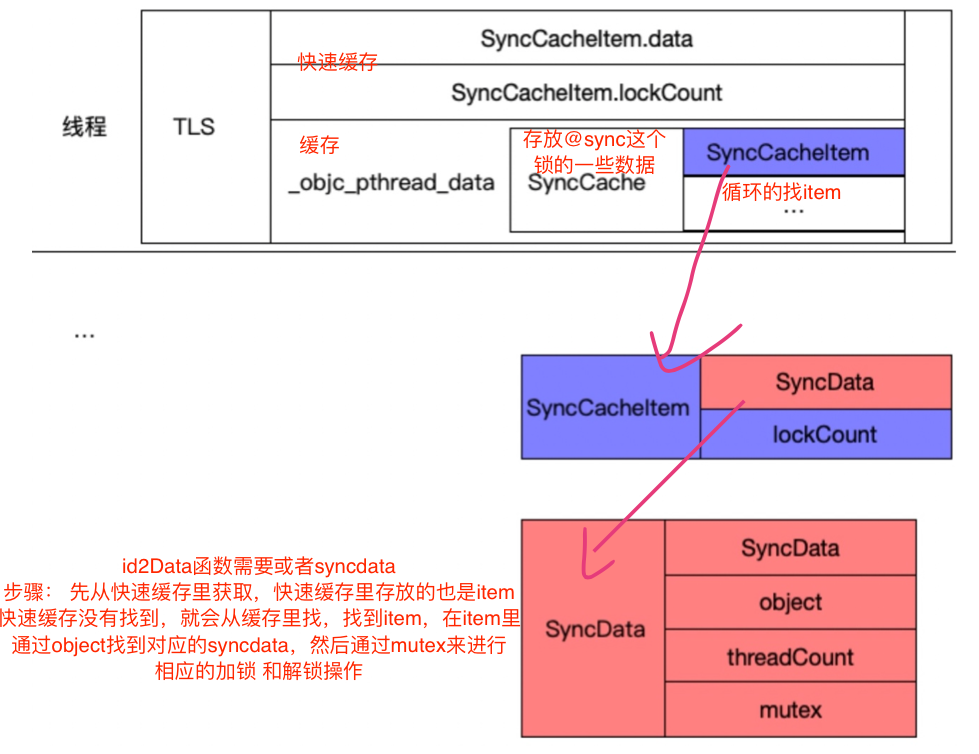
五、总结:
- @synchronized使用时如果传入nil,不能完成加锁,使用时应避免
- @synchronized使用了快速缓存,线程缓存,全局链表方式来使得线程可以更加快速的拿到锁,提升效率
- @synchronized内部是基于os_unfair_lock封装的递归互斥锁
- @synchronized在内部创建锁的时候为了唯一性,使用到spinlock_t(基于os_unfair_lock封装的)来保证线程安全

 浙公网安备 33010602011771号
浙公网安备 33010602011771号