
理解与学习深度卷积生成对抗网络
一.GAN
引言:生成对抗网络GAN,是当今的一大热门研究方向。在2014年,被Goodfellow大神提出来,当时的G神还是蒙特利尔大学的博士生。据有关媒体统计:CVPR2018的论文里,有三分之一的论文与GAN有关。由此可见,GAN在视觉领域的未来多年内,将是一片沃土。而我们入坑GAN,首先需要理由,GAN能做什么,为什么要学GAN。
》》GAN的初衷就是生成不存在于真实世界的数据,类似于使得 AI具有创造力或者想象力。应用场景如下:
》AI作家,AI画家等需要创造力的AI体;
》将模糊图变清晰(去雨,去雾,去抖动,等);
》进行数据增强,根据已有数据生成更多新数据供以feed,可以减缓模型过拟合现象。
接下来我们对GAN进行讨论:
(1)GAN的思想是是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数,比如两个人掰手腕,假设总的空间是一定的,你的力气大一点,那你就得到的空间多一点,相应的我的空间就少一点,相反我力气大我就得到的多一点,但有一点是确定的就是,我两的总空间是一定的,这就是二人博弈,但是呢总利益是一定的。
引申到GAN里面就是可以看成,GAN中有两个这样的博弈者,一个人名字是生成模型(G),另一个人名字是判别模型(D)。他们各自有各自的功能。比如,我们有一些真实数据,同时也有一把乱七八糟的假数据。(G)拼命地把随手拿过来的假数据模仿成真实数据,并揉进真实数据里。(D)则拼命地想把真实数据和假数据区分开。这里,(G)就是一个生成模型,类似于卖假货的,一个劲儿地学习如何骗过 (D)。而(D)则是一个判别模型,类似于警察叔叔,一个劲儿地学习如何分辨出(G)的骗人技巧。如此这般,随着(D)的鉴别技巧越来越牛,(G)的骗人技巧也越来越纯熟了。
相同点是:
这两个模型都可以看成是一个黑匣子,接受输入然后有一个输出,类似一个函数,一个输入输出映射。
不同点是:
生成模型(G)功能:比作是一个样本生成器,输入一个噪声/样本,然后把它包装成一个逼真的样本,也就是输出。
判别模型(D):比作一个二分类器(如同0-1分类器),来判断输入的样本是真是假。(就是输出值大于0.5还是小于0.5).
(2)训练这样的两个模型的大方法就是:单独交替迭代训练.
我们可以实现定义一个迭代次数,交替迭代到一定次数后停止即可。这个时候我们再去看一看噪声Z生成的假样本会发现,原来它已经很真了。看完了这个过程是不是感觉GAN的设计真的很巧妙,个人觉得最值得称赞的地方可能在于这种假样本在训练过程中的真假变换,这也是博弈得以进行的关键之处。

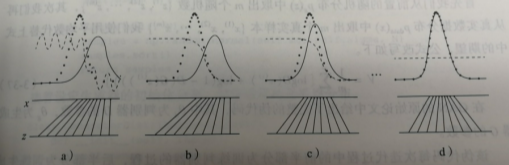
(3)生成对抗网络的运作过程:
》》》在a图中,初始状态生成数据与真实数据相比具有很大的差距,判别器具备初步划分是否是真实数据的能力,但是由于存在噪声,效果仍有缺陷;
》》》在b图中,通过对于判别器的训练,判别器D开始逐渐向一个比较完善的的方向收敛;
》》》在c图中,我们让生成数据向真实数据移动,使得生成数据更容易被判别器判别别为真实数据;
》》》在d图中,达到理想的p(生成)=p(真实),此时D与G都无法再更进一步优化!D(x)=1/2.我们的生成模型跟源数据拟合之后就没法再继续学习了(因为常数线 y = 1/2 求导永远为 0)。
(如下图a,b,c,d所示)
(4)GAN的特点:
● 相比较传统的模型,他存在两个不同的网络,而不是单一的网络,并且训练方式用的是对抗训练方式.
● GAN中G的梯度更新信息来自判别器D,而不是来自数据样本.
(5)GAN的优缺点:
》》》优点:
● GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了向传播,而不需要复杂的马尔科夫链;
● 相比其他所有模型, GAN可以产生更加清晰,真实的样本;
● GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域;
● 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAES生成的实例比GANs更模糊;
● 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的;
● GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练了。
》》》缺点:
● 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多
● GAN不适合处理离散形式的数据,比如文本
● GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
二.DCGAN(深度卷积对抗网络)
引言:
(1)DCGAN的创始论文发表于2015年,在GAN的基础上提出了DCGAN,其主要的改进是在网络结构上,在训练过程中状态稳定,并且可以有效实现高质量图片的生成以及相关的生成模型应用。DCGAN的生成器网络结构如下图:
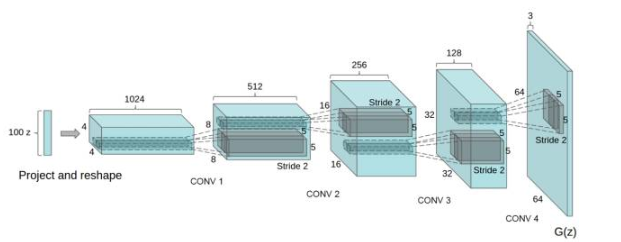
(2) DCGAN的改进:
● 使用步长卷积代替上采样层,卷积在提取图像特征上具有很好的作用,并且使用卷积代替全连接层;
● 生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm);
● 在判别器中使用leakrelu激活函数,而不是RELU,防止梯度稀疏,生成器中仍然采用relu,但是输出层采用tanh;
● 使用adam优化器训练,并且学习率最好是0.0002。(有的实验者也试过其他学习率,但不得不说0.0002是表现最好的了)
●生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)
(3) DCGAN的矢量计算:
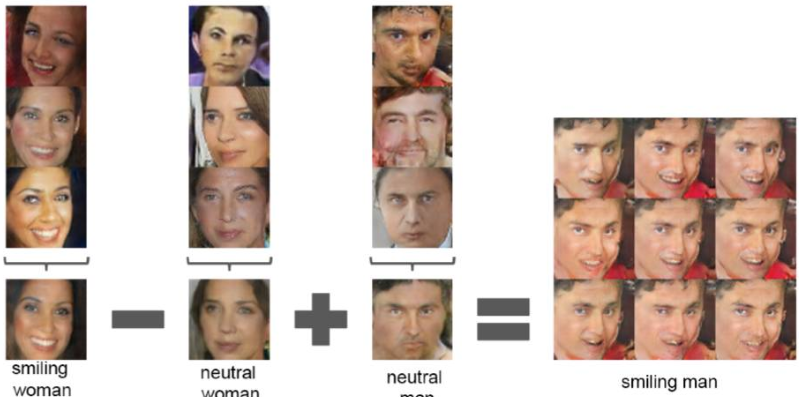
(smiling woman - neutral woman + neutral man = smiling man )
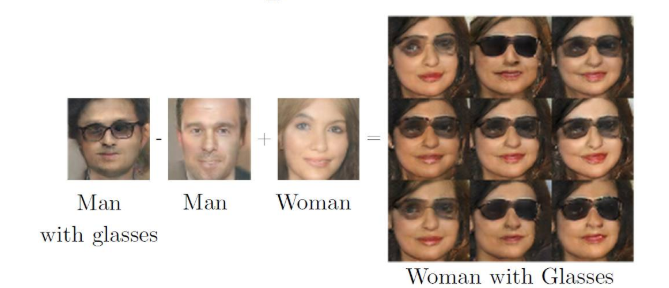
(man with glasses -man +woman = woman with glasses)
存在问题:DCGAN虽然有很好的架构,但是对GAN训练稳定性来说是治标不治本,没有从根本上解决问题,而且训练的时候仍需要小心的平衡G,D的训练进程,往往是训练一个多次,训练另一个一次。
(4)网上关于DCGAN的实现:
》》》DCGAN实现动漫头像生成:
》首先需要用爬虫爬取大量的动漫图片;
》我们的目标是生成动漫头像,所以需要进行人脸检测截取图像;
》搭建tensorflow框架
》训练,生成结果如以下图片:
Epoch0:

Epoch20:

Epoch300:

》结果:从以上图片可以看到,第300个Epoch的图片几乎可以以假乱真。
(5)我们对于人脸图片的生成:
》搭建并激活虚拟环境
》执行第一个.py文件,批量转换图片成统一格式文件,会生成一个设定好的文件夹,在该目录下生成符合要求的图片;
》开始训练,执行另一个.py文件,会生成设定好的文件夹,在该目录下找到训练好的图片。(若因某种原因导致训练终止,执行上述命令会在原有基础上继续训练)
》结果:
Epoch0:

Epoch25:

Epoch100:

》结果:我们使用的是6400张人脸图片数据集进行训练,train200-20000是我们通过DCGAN对人物头像的生成,可以看到第1个Epoch-train200很模糊,但是train-5000可以看到有人脸生成,而train-20000几乎可以看到清晰可辨的人脸!
》DCGAN的缺陷以及我的收获:
在实际实践中,生成数据和真实数据在空间中完美重合的概率是非常低的,大部分情况下我们可以找到一个完美的判别器加以划分。(一句话概括,在原始GAN中的问题在于:判别器越好,生成梯度消失越严重)导致在网络训练的反向传播中,梯度更新几乎为零,即网络很难在这过程中学到东西。
而对于DCGAN的训练1,10,25个epoch,生成器优化的梯度快速下降。但是修改梯度函数可以有效避免梯度消失的问题。但是呢,随着训练迭代次数的上升,梯度上升非常快,同时曲线的噪声也在变大,也就是说梯度的方差也在增加,这会导致样本质量低的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号