

二、clickhouse的学习
借助官网的帮助文档进行学习,官方支持中文
OLTP(联机事务处理系统)
例如mysql等关系型数据库,在对于存储小数据量的时候,查询数据并分析速度很快,OLTP本身其实是一个逻辑上的概念,指的是某个数据库,主要是针对增删改操作的。
里面的数据会经常的发生变化。
OLAP(联机分析处理系统)
指的是数据库中的数据长期不变,有着大量的历史数据,并且可以随时的做分析,而增删改操作很少。
OLAP 种类数据库的特点

1、绝大多数是读请求
2、数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
3、已添加到数据库的数据不能修改。
4、对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
5、宽表,即每个表包含着大量的列
6、查询相对较少(通常每台服务器每秒查询数百次或更少)
7、对于简单查询,允许延迟大约50毫秒
8、列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
9、处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
10、事务不是必须的
11、对数据一致性要求低
12、每个查询有一个大表。除了他以外,其他的都很小。
13、查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
 ·
·
UInt8, UInt16, UInt32, UInt64, UInt128, UInt256, Int8, Int16, Int32, Int64, Int128, Int256
Int8 — [-128 : 127]
Int16 — [-32768 : 32767]
Int32 — [-2147483648 : 2147483647]
Int64 — [-9223372036854775808 : 9223372036854775807]
Int128 — [-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727]
Int256 — [-57896044618658097711785492504343953926634992332820282019728792003956564819968 : 57896044618658097711785492504343953926634992332820282019728792003956564819967]
UInt8 — [0 : 255]
UInt16 — [0 : 65535]
UInt32 — [0 : 4294967295]
UInt64 — [0 : 18446744073709551615]
UInt128 — [0 : 340282366920938463463374607431768211455]
UInt256 — [0 : 115792089237316195423570985008687907853269984665640564039457584007913129639935]
String:可变长字符串
FixedString(长度):固定长字符串,参数是字节数,执行效率比String要高
Date 年-月-日
Date32 年-月-日
DateTime 年-月-日 时-分-秒
DateTime64 年-月-日 时-分-秒.毫秒
案例:
# 建表语句:
create table date_test (date1 Date,date2 Date32,date3 DateTime,date4 DateTime64) ENGINE = TinyLog;
# 插入语句:
insert into date_test values ('2023-11-21','2023-11-21','2023-11-21','2023-11-21');
时间戳转换 insert into date_test values (1691825618123,1691825618123,1691825618123,1691825618123); //2023-08-12 15:33:38
clickhouse提供了一个函数:generateUUIDv4() 生成一个 00000000-0000-0000-0000-000000000000 的编号 编号的类型就是UUID类型
例如建表的时候,有一个id字段类型时Int32,如果当id不确定的时候,我们应该使用null进行填充,而不应该用默认值0,所以,我们这里应该添加的是null
Nullable(Int32)
insert into students_test values (null,'张玮2','男','特训营24期');
字段类型是数组,对于同一个数组,在建表的时候指定数据类型,注意:在MergeTree表引擎中是不允许出现数组嵌套的
注意:需要使用array()函数,将元素组成数组,将来还可以使用toTypeName()查看某一列的数据类型
# 举例:
create table t1 (col1 Array(Int8)) ENGINE = TinyLog;
insert into t1 values (array(11,12,13));
# Decimal(P,S),Decimal32(S),Decimal64(S),Decimal128(S)
有符号的定点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)
P - 精度。有效范围:[1:38],决定可以有多少个十进制数字(包括分数)。
S - 规模。有效范围:[0:P],决定数字的小数部分中包含的小数位数。
Decimal(4,2)
举例:12.12234
P: 7
S: 5
create table students_test(id Int64,name FixedString(12),gender Nullable(FixedString(3)),clazz String) ENGINE = TinyLog;
# 基本格式
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
# 举例
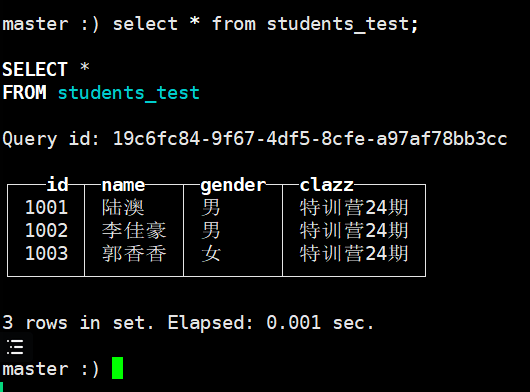
insert into students_test values (1001,'陆澳','男','特训营24期'),(1002,'李佳豪','男','特训营24期'),(1003,'郭香香','女','特训营24期');
insert into students_test values (1004,'王宇杰','男','特训营24期'),(1005,'张怀远','男','特训营24期'),(1006,'史俊超','女','特训营24期');
insert into students_test (name,gender,clazz) values ('张玮','男','特训营24期');
# 查看表结构
desc 表名;
MySQL数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,因此您可以执行诸如SHOW TABLES或SHOW CREATE TABLE之类的操作。
但您无法对其执行以下操作:
-
RENAME -
CREATE TABLE -
# 在clickhouse中创建数据库并指定远程的MySQL服务,将其中的某一个数据库映射过来(就将这新建的数据库看成一个远程客户端连接了mysql)
# 建库语句
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
# 举例
create database IF NOT EXISTS bigdata24_mysql ENGINE = MySQL('192.168.209.100:3306','bigdata24','root','123456');
# 参数理解:
host:port — MySQL服务地址,既可以是ip地址,也可以是主机名(如果是主机名,要配置hosts映射)
database — MySQL数据库名称
user — MySQL用户名
password — MySQL用户密码
2.1 日志引擎
a. Log
# 建表,指定表引擎为Log
create table students_log (id Int32,name String,gender FixedString(3),clazz String) ENGINE = Log;
# 添加数据
insert into students_log values (1001,'刘中义','男','特训营27期'),(1002,'吴小康','男','特训营27期'),(1003,'朱龙俊','男','特训营27期');
并发数据访问不受任何限制:
-
如果同时从表中读取并在不同的查询中写入,则读取操作将抛出异常
-
如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多1,000,000行)。如果您有许多小表,则使用此表引擎是适合的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,但在可能已经在其它 DBMS 时使用过,则您可能会发现切换使用 TinyLog 类型的表更容易。不支持索引
StripeLog 引擎将所有列存储在一个文件中。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。
ClickHouse 为每张表写入以下文件:
-
data.bin— 数据文件。 -
index.mrk— 带标记的文件。标记包含了已插入的每个数据块中每列的偏移量。
StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
读取数据:
带标记的文件使得 ClickHouse 可以并行的读取数据。这意味着 SELECT 请求返回行的顺序是不可预测的。使用 ORDER BY
CREATE TABLE stripe_log_table(timestamp DateTime,message_type String,message String) ENGINE = StripeLog
INSERT INTO stripe_log_table VALUES (now(),'REGULAR','The first regular message')
INSERT INTO stripe_log_table VALUES (now(),'REGULAR','The second regular message'),(now(),'WARNING','The first warning message')
# 建表,指定表引擎为Log
create table students_stripelog (id Int32,name String,gender FixedString(3),clazz String) ENGINE = StripeLog;
# 添加数据
insert into students_stripelog values (1001,'陆澳','男','特训营24期'),(1002,'李佳豪','男','特训营24期'),(1003,'郭香香','女','特训营24期');
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
主要特点:
-
存储的数据按主键排序。
这使得您能够创建一个小型的稀疏索引来加快数据检索。
-
如果指定了
在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
-
支持数据副本。
ReplicatedMergeTree系列的表提供了数据副本功能。更多信息,请参阅 -
支持数据采样。
# 建表语句规范:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
# 案例
# 建表语句
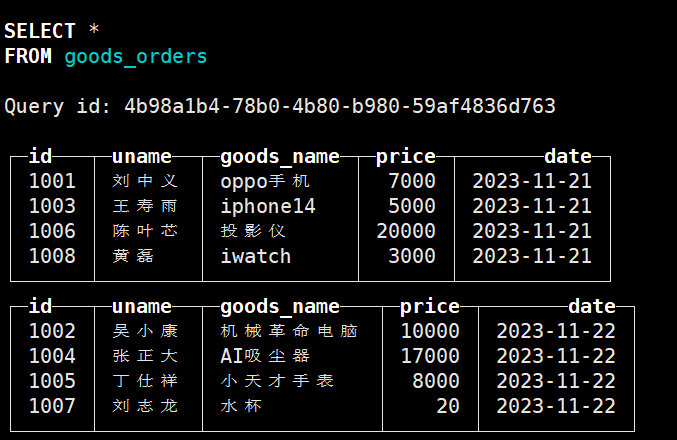
create table goods_orders (id String,uname String,goods_name String,price Int64,date Date32) ENGINE = MergeTree() order by date PARTITION BY date;
# 插入语句
insert into goods_orders values ('1001','刘中义','oppo手机',7000,'2023-11-21'),('1002','吴小康','机械革命电脑',10000,'2023-11-22'),('1003','王寿雨','iphone14',5000,'2023-11-21'),('1004','张正大','AI吸尘器',17000,'2023-11-22');
insert into goods_orders values ('1005','丁仕祥','小天才手表',8000,'2023-11-22'),('1006','陈叶芯','投影仪',20000,'2023-11-21'),('1007','刘志龙','水杯',20,'2023-11-22'),('1008','黄磊','iwatch',3000,'2023-11-21');
注意:默认是针对每一批数据按照分区字段的值进行分区
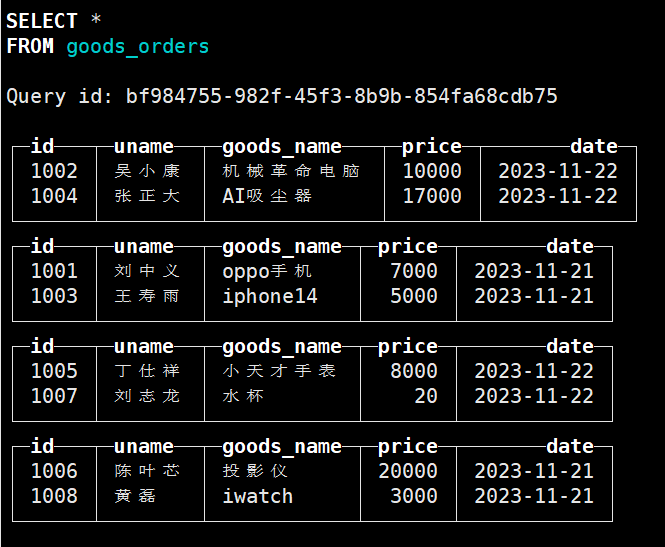
optimize table 表名 final;
optimize table goods_orders final;
手动合并后结果/或者是过一段时间自动合并结果
今后开发的时候,常用的表引擎:针对数据量小的表引擎用TinyLog, 数据量大表引擎就用MergeTree
四、常用函数
4.1 算术函数
对于所有算术函数,结果类型为结果适合的最小数值类型(如果存在这样的类型)。最小数值类型是根据数值的位数,是否有符号以及是否是浮点类型而同时进行的。如果没有足够的位,则采用最高位类型。简单理解:会自动的根据我们的数值大小,来选用最适合的数据类型存储。
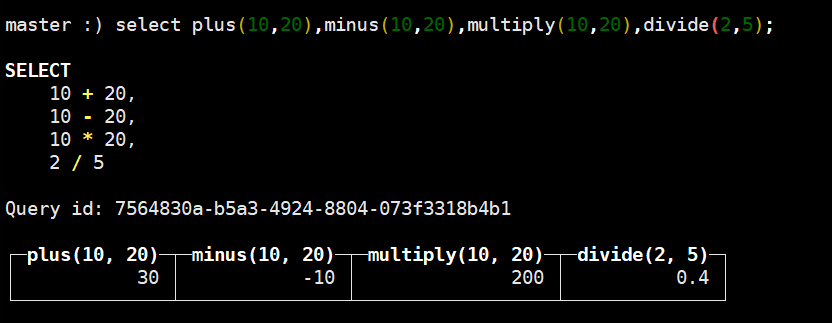
# plus(a, b), a + b operator
计算数值的总和。 您还可以将Date或DateTime与整数进行相加。在Date的情况下,和整数相加整数意味着添加相应的天数。对于DateTime,这意味着添加相应的秒数。
# minus(a, b), a - b operator
计算数值之间的差,结果总是有符号的。
您还可以将Date或DateTime与整数进行相减。见上面的’plus’。
# multiply(a, b), a * b operator
计算数值的乘积。
# divide(a, b), a / b operator
计算数值的商。结果类型始终是浮点类型。 它不是整数除法。对于整数除法,请使用’intDiv’函数。 当除以零时,你得到’inf’,‘- inf’或’nan’。
# intDiv(a,b)
计算数值的商,向下舍入取整(按绝对值)。 除以零或将最小负数除以-1时抛出异常。
# max2(a,b)
value1 — 第一个值,类型为Int/UInt或Float。
value2 — 第二个值,类型为Int/UInt或Float。
# max2(value1, value2)
value1 — 第一个值,类型为Int/UInt or Float。
value2 — 第二个值,类型为Int/UInt or Float。
可以比较以下类型:
-
数字
-
String 和 FixedString
-
日期
-
日期时间
以上每个组内的类型均可互相比较,但是对于不同组的类型间不能够进行比较。
例如,您无法将日期与字符串进行比较。您必须使用函数将字符串转换为日期,反之亦然。
等于,a=b和a==b 运算符
不等于,a!=b和a<>b 运算符
少, < 运算符
大于, > 运算符
小于等于, <= 运算符
大于等于, >= 运算符


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!