
MySQL的又一神器-锁,MySQL面试必备
原文链接:blog.ouyangsihai.cn >> MySQL的又一神器-锁,MySQL面试必备
1 什么是锁
1.1 锁的概述
在生活中锁的例子多的不能再多了,从古老的简单的门锁,到密码锁,再到现在的指纹解锁,人脸识别锁,这都是锁的鲜明的例子,所以,我们理解锁应该是非常简单的。
再到MySQL中的锁,对于MySQL来说,锁是一个很重要的特性,数据库的锁是为了支持对共享资源进行并发访问,提供数据的完整性和一致性,这样才能保证在高并发的情况下,访问数据库的时候,数据不会出现问题。
1.2 锁的两个概念
在数据库中,lock和latch都可以称为锁,但是意义却不同。
Latch一般称为闩锁(轻量级的锁),因为其要求锁定的时间必须非常短。若持续的时间长,则应用的性能会非常差,在InnoDB引擎中,Latch又可以分为mutex(互斥量)和rwlock(读写锁)。其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检测的机制。
Lock的对象是事务,用来锁定的是数据库中的对象,如表、页、行。并且一般lock的对象仅在事务commit或rollback后进行释放(不同事务隔离级别释放的时间可能不同)。
2 InnoDB存储引擎中的锁
2.1 锁的粒度
在数据库中,锁的粒度的不同可以分为表锁、页锁、行锁,这些锁的粒度之间也是会发生升级的,锁升级的意思就是讲当前锁的粒度降低,数据库可以把一个表的1000个行锁升级为一个页锁,或者将页锁升级为表锁,下面分别介绍一下这三种锁的粒度(参考自博客:https://blog.csdn.net/baolingye/article/details/102506072)。
表锁
表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并大度大打折扣。
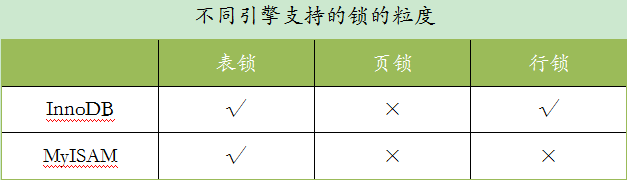
使用表级锁定的主要是MyISAM,MEMORY,CSV等一些非事务性存储引擎。
特点: 开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
页锁
页级锁定是MySQL中比较独特的一种锁定级别,在其他数据库管理软件中也并不是太常见。页级锁定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力也同样是介于上面二者之间。另外,页级锁定和行级锁定一样,会发生死锁。
在数据库实现资源锁定的过程中,随着锁定资源颗粒度的减小,锁定相同数据量的数据所需要消耗的内存数量是越来越多的,实现算法也会越来越复杂。不过,随着锁定资源 颗粒度的减小,应用程序的访问请求遇到锁等待的可能性也会随之降低,系统整体并发度也随之提升。
使用页级锁定的主要是BerkeleyDB存储引擎。
特点: 开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
行锁
行级锁定最大的特点就是锁定对象的粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力而提高一些需要高并发应用系统的整体性能。
虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
特点: 开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
比较表锁我们可以发现,这两种锁的特点基本都是相反的,而从锁的角度来说,表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
MySQL 不同引擎支持的锁的粒度
2.2 锁的类型
InnoDB存储引擎中存在着不同类型的锁,下面一一介绍一下。
S or X (共享锁、排他锁)
数据的操作其实只有两种,也就是读和写,而数据库在实现锁时,也会对这两种操作使用不同的锁;InnoDB 实现了标准的行级锁,也就是共享锁(Shared Lock)和互斥锁(Exclusive Lock)。
- 共享锁(读锁)(S Lock),允许事务读一行数据。
- 排他锁(写锁)(X Lock),允许事务删除或更新一行数据。
IS or IX (共享、排他)意向锁
为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB存储引擎支持一种额外的锁方式,就称为意向锁,意向锁在 InnoDB 中是表级锁,意向锁分为:
- 意向共享锁:表达一个事务想要获取一张表中某几行的共享锁。
- 意向排他锁:表达一个事务想要获取一张表中某几行的排他锁。
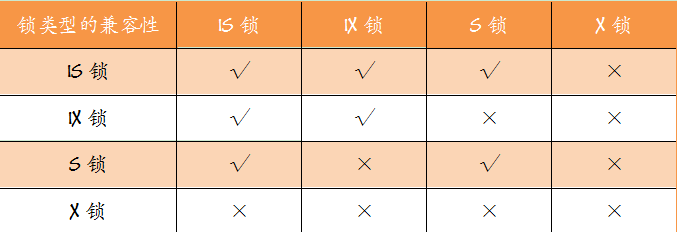
另外,这些锁之间的并不是一定可以共存的,有些锁之间是不兼容的,所谓兼容性就是指事务 A 获得一个某行某种锁之后,事务 B 同样的在这个行上尝试获取某种锁,如果能立即获取,则称锁兼容,反之叫冲突。
下面我们再看一下这两种锁的兼容性。
- S or X (共享锁、排他锁)的兼容性

- IS or IX (共享、排他)意向锁的兼容性
3 前面小结
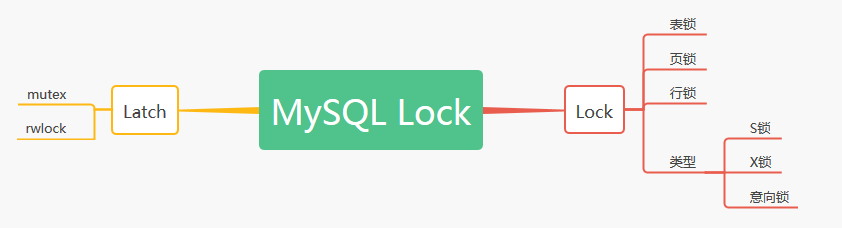
这里用一个思维导图把前面的概念做一个小结。
4 一致性非锁定读和一致性锁定读
一致性锁定读(Locking Reads)
在一个事务中查询数据时,普通的SELECT语句不会对查询的数据进行加锁,其他事务仍可以对查询的数据执行更新和删除操作。因此,InnoDB提供了两种类型的锁定读来保证额外的安全性:
SELECT ... LOCK IN SHARE MODESELECT ... FOR UPDATE
SELECT ... LOCK IN SHARE MODE: 对读取的行添加S锁,其他事物可以对这些行添加S锁,若添加X锁,则会被阻塞。
SELECT ... FOR UPDATE: 会对查询的行及相关联的索引记录加X锁,其他事务请求的S锁或X锁都会被阻塞。 当事务提交或回滚后,通过这两个语句添加的锁都会被释放。 注意:只有在自动提交被禁用时,SELECT FOR UPDATE才可以锁定行,若开启自动提交,则匹配的行不会被锁定。
一致性非锁定读
一致性非锁定读(consistent nonlocking read) 是指InnoDB存储引擎通过多版本控制(MVVC)读取当前数据库中行数据的方式。如果读取的行正在执行DELETE或UPDATE操作,这时读取操作不会因此去等待行上锁的释放。相反地,InnoDB会去读取行的一个快照。所以,非锁定读机制大大提高了数据库的并发性。
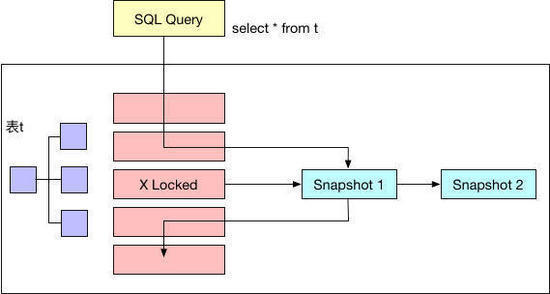
一致性非锁定读是InnoDB默认的读取方式,即读取不会占用和等待行上的锁。在事务隔离级别READ COMMITTED和REPEATABLE READ下,InnoDB使用一致性非锁定读。
然而,对于快照数据的定义却不同。在READ COMMITTED事务隔离级别下,一致性非锁定读总是读取被锁定行的最新一份快照数据。而在REPEATABLE READ事务隔离级别下,则读取事务开始时的行数据版本。
下面我们通过一个简单的例子来说明一下这两种方式的区别。
首先创建一张表;

插入一条数据;
insert into lock_test values(1);
查看隔离级别;
select @@tx_isolation;

下面分为两种事务进行操作。
在REPEATABLE READ事务隔离级别下;
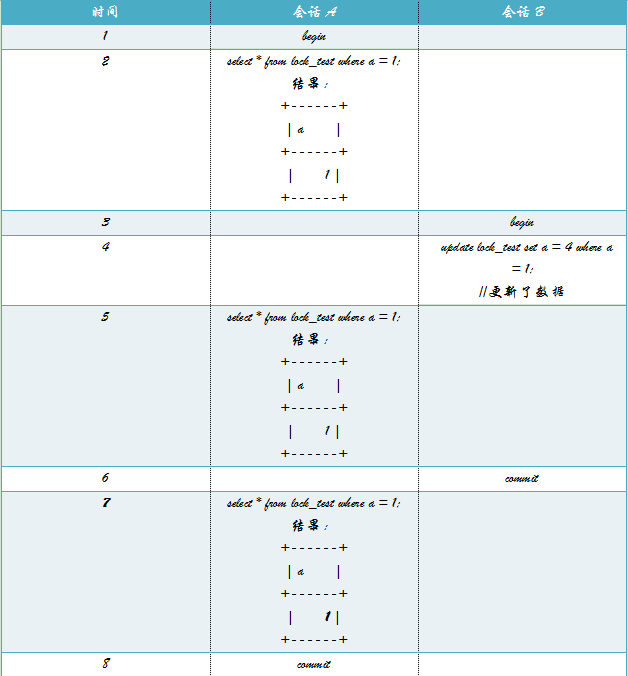
在REPEATABLE READ事务隔离级别下,读取事务开始时的行数据,所以当会话B修改了数据之后,通过以前的查询,还是可以查询到数据的。
在READ COMMITTED事务隔离级别下;
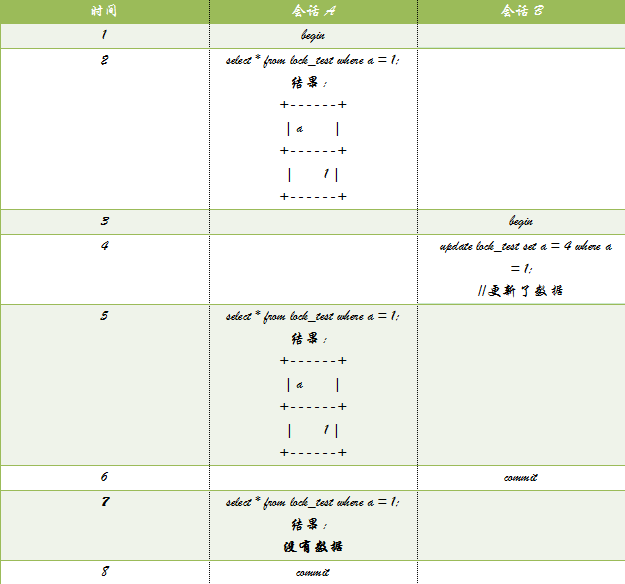
在READ COMMITTED事务隔离级别下,读取该行版本最新的一个快照数据,所以,由于B会话修改了数据,并且提交了事务,所以,A读取不到数据了。
5 行锁的算法
InnoDB存储引擎有3种行锁的算法,其分别是:
- Record Lock:单个行记录上的锁。
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身。
- Next-Key Lock:Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身。
Record Lock:总是会去锁住索引记录,如果InnoDB存储引擎表在建立的时候没有设置任何一个索引,那么这时InnoDB存储引擎会使用隐式的主键来进行锁定。
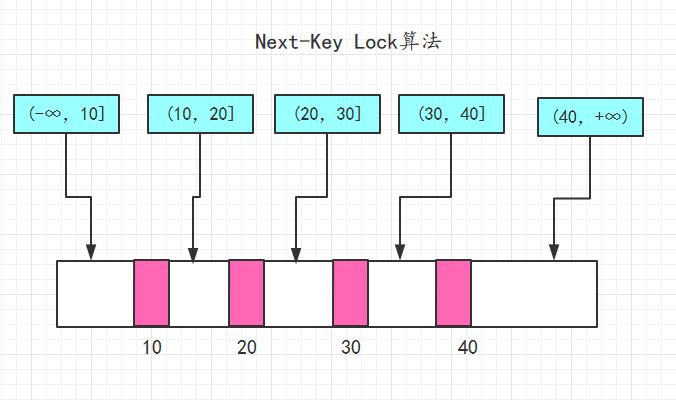
Next-Key Lock:结合了Gap Lock和Record Lock的一种锁定算法,在Next-Key Lock算法下,InnoDB对于行的查询都是采用这种锁定算法。举个例子10,20,30,那么该索引可能被Next-Key Locking的区间为:
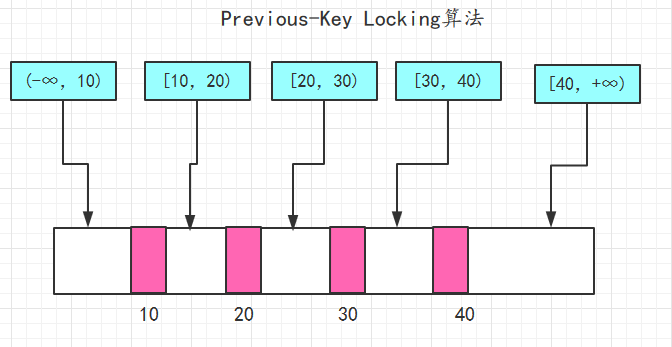
除了Next-Key Locking,还有Previous-Key Locking技术,这种技术跟Next-Key Lock正好相反,锁定的区间是区间范围和前一个值。同样上述的值,使用Previous-Key Locking技术,那么可锁定的区间为:
不是所有索引都会加上Next-key Lock的,这里有一种特殊的情况,在查询的列是唯一索引(包含主键索引)的情况下,Next-key Lock会降级为Record Lock。
接下来,我们来通过一个例子解释一下。
CREATE TABLE test (
x INT,
y INT,
PRIMARY KEY(x), // x是主键索引
KEY(y) // y是普通索引
);
INSERT INTO test select 3, 2;
INSERT INTO test select 5, 3;
INSERT INTO test select 7, 6;
INSERT INTO test select 10, 8;
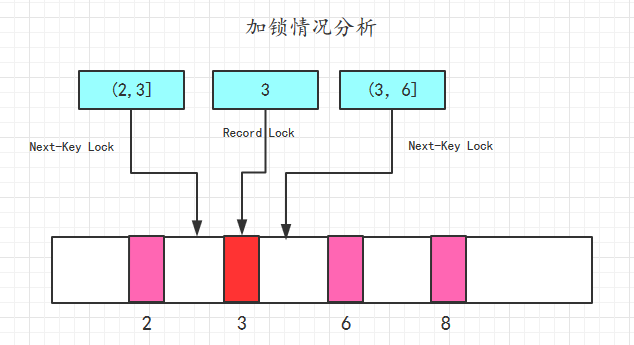
我们现在会话A中执行如下语句;
SELECT * FROM test WHERE y = 3 FOR UPDATE
我们分析一下这时候的加锁情况。
- 对于主键x

- 辅助索引y
用户可以通过以下两种方式来显示的关闭Gap Lock:
- 将事务的隔离级别设为 READ COMMITED。
- 将参数innodb_locks_unsafe_for_binlog设置为1。
Gap Lock的作用:是为了阻止多个事务将记录插入到同一个范围内,设计它的目的是用来解决Phontom Problem(幻读问题)。在MySQL默认的隔离级别(Repeatable Read)下,InnoDB就是使用它来解决幻读问题。
幻读:是指在同一事务下,连续执行两次同样的SQL语句可能导致不同的结果,第二次的SQL可能会返回之前不存在的行,也就是第一次执行和第二次执行期间有其他事务往里插入了新的行。
6 锁带来的问题
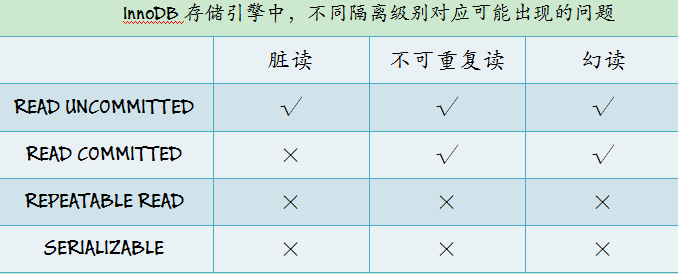
6.1 脏读
脏读: 在不同的事务下,当前事务可以读到另外事务未提交的数据。另外我们需要注意的是默认的MySQL隔离级别是REPEATABLE READ是不会发生脏读的,脏读发生的条件是需要事务的隔离级别为READ UNCOMMITTED,所以如果出现脏读,可能就是这种隔离级别导致的。
下面我们通过一个例子看一下。

从上面这个例子可以看出,当我们的事务的隔离级别为READ UNCOMMITTED的时候,在会话A还没有提交时,会话B就能够查询到会话A没有提交的数据。
6.2 不可重复读
不可重复读: 是指在一个事务内多次读取同一集合的数据,但是多次读到的数据是不一样的,这就违反了数据库事务的一致性的原则。但是,这跟脏读还是有区别的,脏读的数据是没有提交的,但是不可重复读的数据是已经提交的数据。
我们通过下面的例子来看一下这种问题的发生。

从上面的例子可以看出,在A的一次会话中,由于会话B插入了数据,导致两次查询的结果不一致,所以就出现了不可重复读的问题。
我们需要注意的是不可重复读读取的数据是已经提交的数据,事务的隔离级别为READ COMMITTED,这种问题我们是可以接受的。
如果我们需要避免不可重复读的问题的发生,那么我们可以使用Next-Key Lock算法(设置事务的隔离级别为READ REPEATABLE)来避免,在MySQL中,不可重复读问题就是Phantom Problem,也就是幻像问题。
6.3 丢失更新
丢失更新:指的是一个事务的更新操作会被另外一个事务的更新操作所覆盖,从而导致数据的不一致。在当前数据库的任何隔离级别下都不会导致丢失更新问题,要出现这个问题,在多用户计算机系统环境下有可能出现这种问题。
如何避免丢失更新的问题呢,我们只需要让事务的操作变成串行化,不要并行执行就可以。
我们一般使用SELECT ... FOR UPDATE语句,给操作加上一个排他X锁。
6.4 小结
这里我们做一个小结,主要是在不同的事务的隔离级别下出现的问题的对照,这样就更加清晰了。
文章有不当之处,欢迎指正,如果喜欢微信阅读,你也可以关注我的微信公众号:
好好学java,获取优质学习资源。
本文由博客一文多发平台 OpenWrite 发布!


