Python爬虫 从小白到高手 各种最新案例! Urllib Xpath JsonPath BeautifulSoup
Urllib
1.什么是互联网爬虫?
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
2.爬虫核心?
1.爬取网页:爬取整个网页 包含了网页中所有得内容
2.解析数据:将网页中你得到的数据 进行解析
3.难点:爬虫和反爬虫之间的博弈
3.爬虫的用途?
数据分析/人工数据集
社交软件冷启动
舆情监控
竞争对手监控
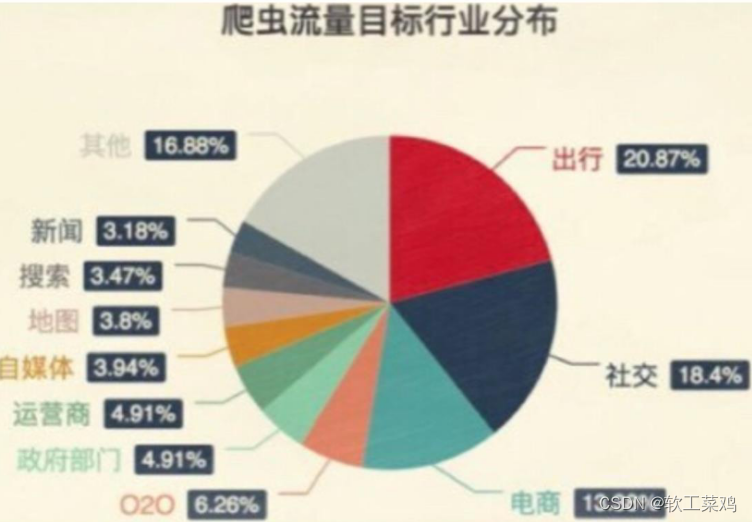
4.爬虫分类?

5.反爬手段?
1.User‐Agent:

6.urllib库使用
使用urllib来获取百度首页的源码
# 使用urllib来获取百度首页的源码
import urllib.request
# (1)定义一个url 就是你要访问的地址
url = 'http://www.baidu.com'
# (2)模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
# (3)获取响应中的页面的源码 content 内容的意思
# read方法 返回的是字节形式的二进制数据
# 我们要将二进制的数据转换为字符串
# 二进制--》字符串 解码 decode('编码的格式')
content = response.read().decode('utf-8')
# (4)打印数据
print(content)
一个类型 HTTPResponse
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
# print(type(response))六个方法 read readline readlines getcode geturl getheaders
# 按照一个字节一个字节的去读
# content = response.read()
# print(content)
# 返回多少个字节
# content = response.read(5)
# print(content)
# 读取一行
# content = response.readline()
# print(content)
#一行一行读,直到所有
# content = response.readlines()
# print(content)
# 返回状态码 如果是200了 那么就证明我们的逻辑没有错
# print(response.getcode())
# 返回的是 访问的url地址
# print(response.geturl())
# 获取是一个 请求头状态信息
print(response.getheaders())
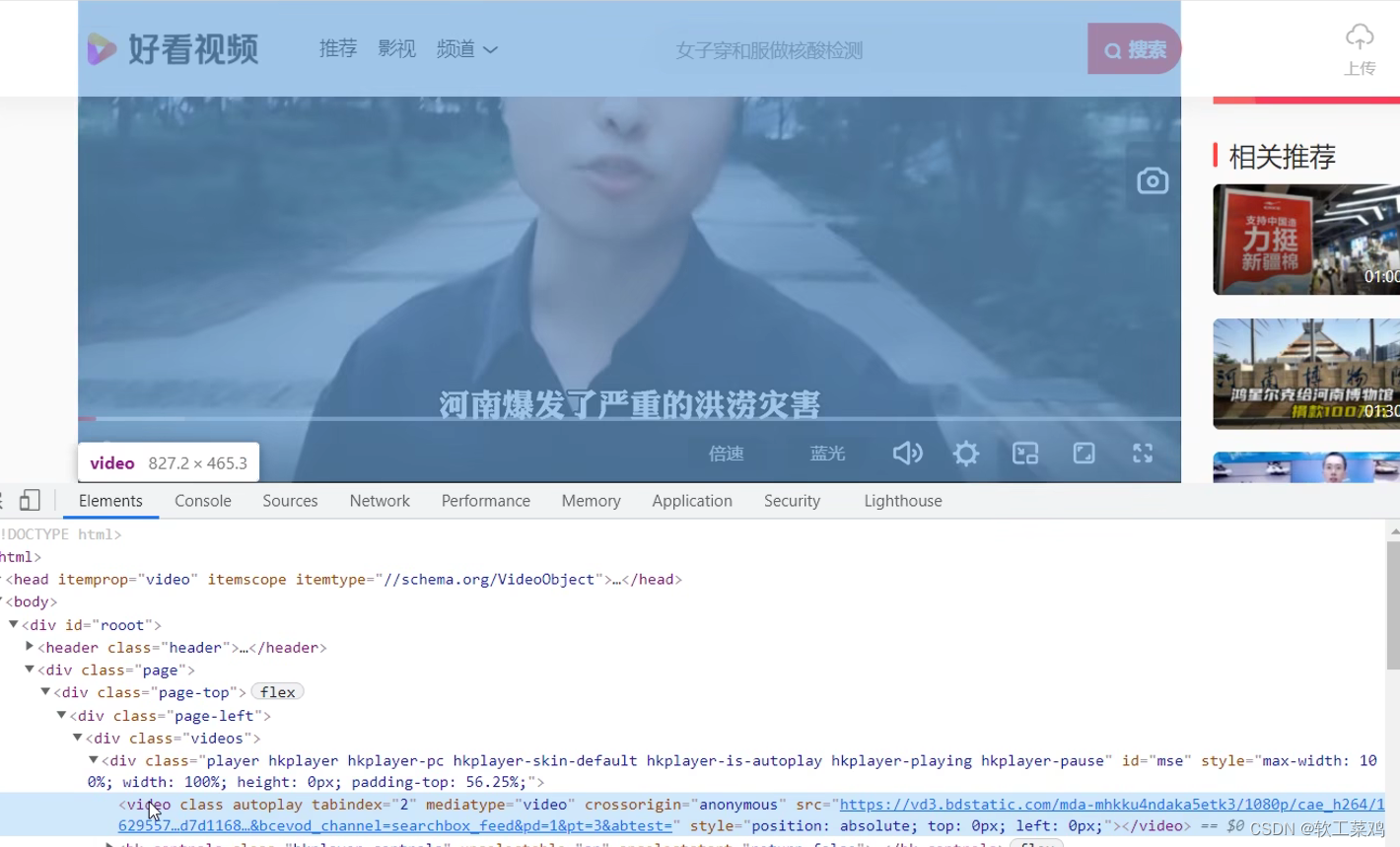
视频的地址;
下载爬取的东西
import urllib.request
# 下载网页
# url_page = 'http://www.baidu.com'
# url代表的是下载的路径 filename文件的名字
# 在python中 可以变量的名字 也可以直接写值
# urllib.request.urlretrieve(url_page,'baidu.html')
# 下载图片
# url_img = 'https://img1.baidu.com/it/u=3004965690,4089234593&fm=26&fmt=auto&gp=0.jpg'
#
# urllib.request.urlretrieve(url= url_img,filename='lisa.jpg')
# 下载视频
url_video = 'https://vd3.bdstatic.com/mda-mhkku4ndaka5etk3/1080p/cae_h264/1629557146541497769/mda-mhkku4ndaka5etk3.mp4?v_from_s=hkapp-haokan-tucheng&auth_key=1629687514-0-0-7ed57ed7d1168bb1f06d18a4ea214300&bcevod_channel=searchbox_feed&pd=1&pt=3&abtest='
urllib.request.urlretrieve(url_video,'hxekyyds.mp4')7.请求对象的定制
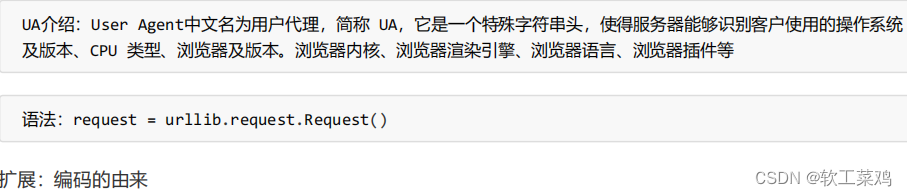

url的组成
https://www.baidu.com/s?wd=周杰伦
http/https www.baidu.com 80/443 s wd = 周杰伦 #
协议 主机 端口号 路径 参数 锚点
常见端口号: http 80 https 443
mysql 3306 oracle 1521 redis 6379 mongodb 27017
找ua

import urllib.request
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 因为urlopen方法中不能存储字典 所以headers不能传递进去
response = urllib.request.urlopen(url=url,headers=headers)
content = response.read().decode('utf8')
print(content)因为urlopen方法中不能存储字典 所以headers不能传递进去
import urllib.request
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
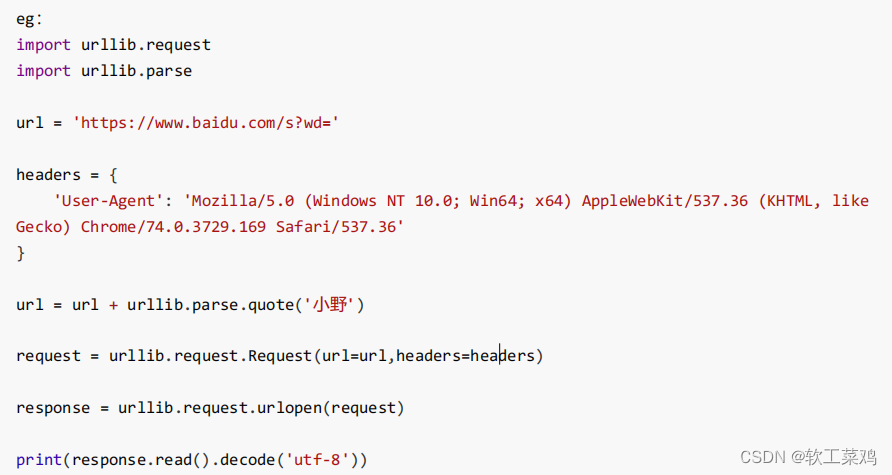
# 请求对象的定制
# 这种参数多的要加(url= ,headers= ),不然运行不了识别不了哪个是哪个参数
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
print(content)8.编解码
1.get请求:urllib.parse.quote()
获取 https://www.baidu.com/s?wd=周杰伦的网页源码
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
# 请求对象的定制为了解决反爬的第一种手段
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 将周杰伦三个字变成unicode编码的格式
# 我们需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦')
url = url + name
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode('utf-8')
# 打印数据
print(content)失败
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>百度安全验证</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="apple-mobile-web-app-capable" content="yes">
<meta name="apple-mobile-web-app-status-bar-style" content="black">
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0">
<meta name="format-detection" content="telephone=no, email=no">
<link rel="shortcut icon" href="https://www.baidu.com/favicon.ico" type="image/x-icon">
<link rel="icon" sizes="any" mask href="https://www.baidu.com/img/baidu.svg">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests">
<link rel="stylesheet" href="https://ppui-static-wap.cdn.bcebos.com/static/touch/css/api/mkdjump_aac6df1.css" />
</head>
<body>
<div class="timeout hide-callback">
<div class="timeout-img"></div>
<div class="timeout-title">网络不给力,请稍后重试</div>
<button type="button" class="timeout-button">返回首页</button>
</div>
<div class="timeout-feedback hide-callback">
<div class="timeout-feedback-icon"></div>
<p class="timeout-feedback-title">问题反馈</p>
</div>
<script src="https://ppui-static-wap.cdn.bcebos.com/static/touch/js/mkdjump_v2_21d1ae1.js"></script>
</body>
</html>
进程已结束,退出代码0加个Cookie成功!
【爬虫】如何解决爬虫爬取图片时遇到百度安全验证的问题?即页面上没有显示图片的源地址,没有img标签,只有div标签
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
# 需求 获取 https://www.baidu.com/s?wd=周杰伦的网页源码
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
# 请求对象的定制为了解决反爬的第一种手段
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.5162 SLBChan/105',
'Cookie':'',
#cookie你先自己登录百度帐号就有了
# 'Accept':'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
# 'Accept-Encoding':'gzip, deflate, br',
# 请求头使用了Accept-Encoding ,获取到的内容为压缩后的内容,使得后面解码utf错误
# 'Accept-Language':'zh-CN,zh;q=0.9'
}
# 将周杰伦三个字变成unicode编码的格式
# 我们需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦')
url = url + name
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode('utf-8')
# 打印数据
print(content)get:urllib.parse.urlencode() 多参数
urlencode应用场景:多个参数的时候
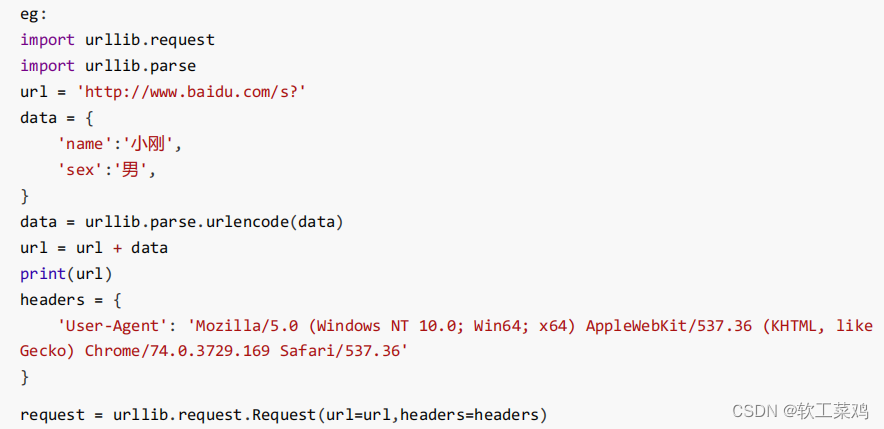

#https://www.baidu.com/s?wd=周杰伦&sex=男
import urllib.parse
data = {
'wd':'周杰伦',
'sex':'男',
'location':'中国台湾省'
}
a = urllib.parse.urlencode(data)
print(a)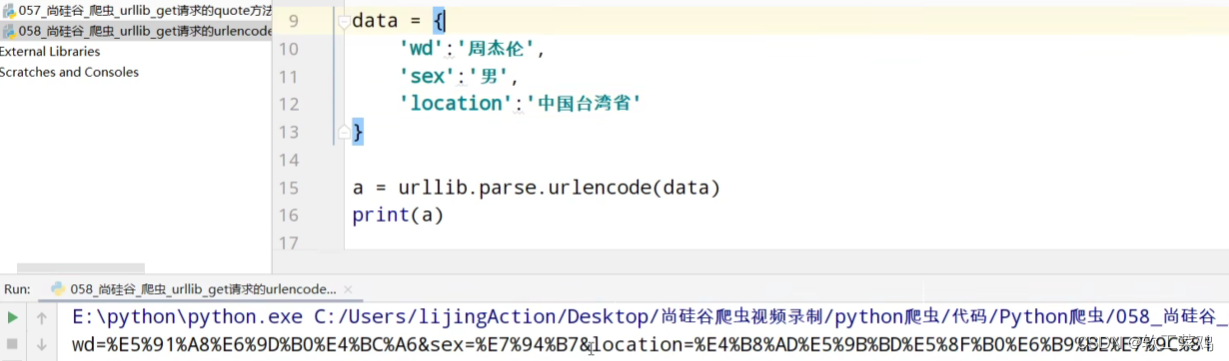
获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7的网页源码
加上Cookie成功!
import urllib.request
import urllib.parse
base_url = 'https://www.baidu.com/s?'
data = {
'wd':'周杰伦',
'sex':'男',
'location':'中国台湾省'
}
new_data = urllib.parse.urlencode(data)
# 请求资源路径
url = base_url + new_data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'Cookie':'',
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码的数据
content = response.read().decode('utf-8')
# 打印数据
print(content)post请求
百度翻译
翻译 发送了很多请求,找获取数据的 接口
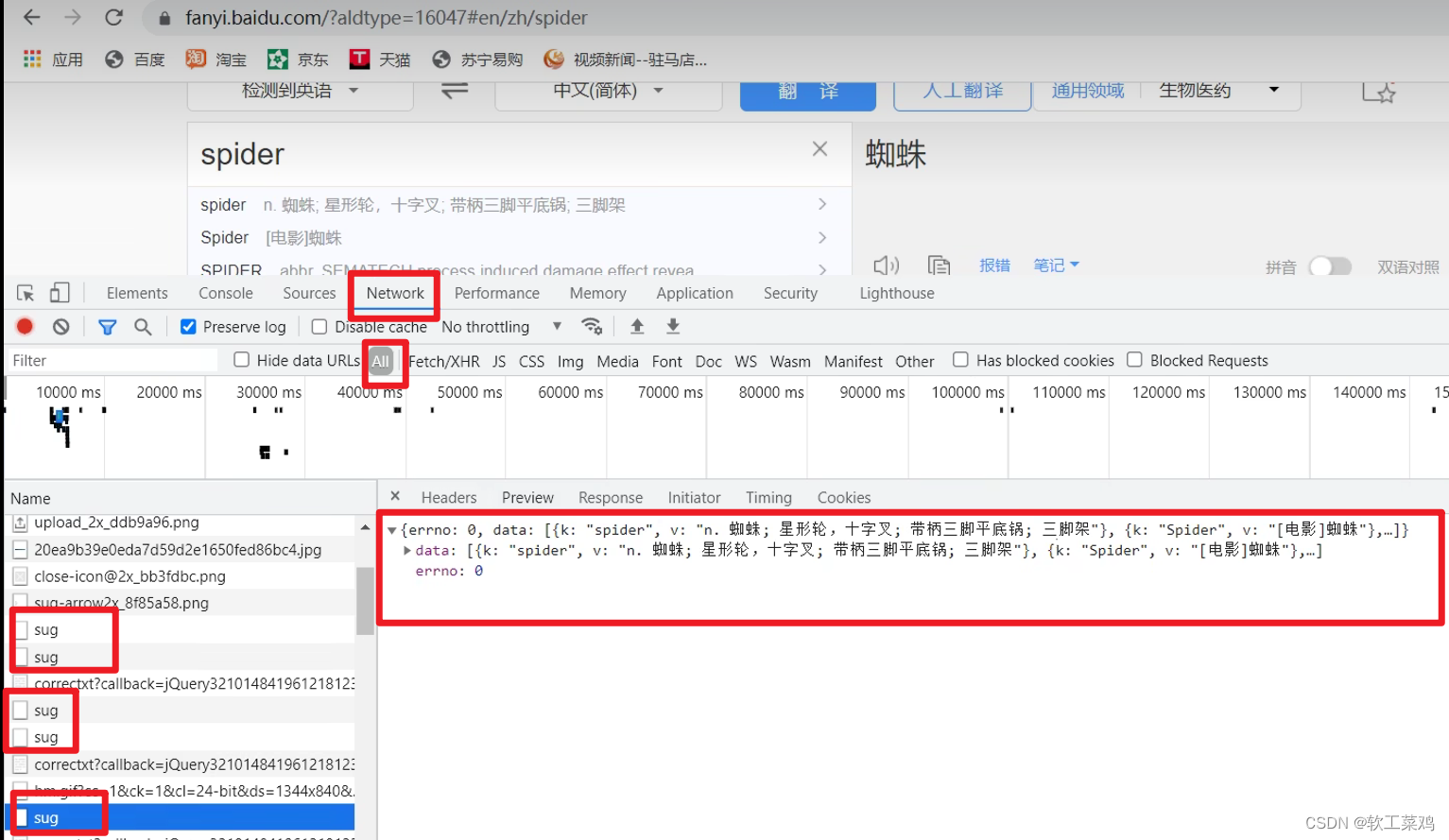
post请求方式的参数 必须编码 data = urllib.parse.urlencode(data)
编码之后 必须调用encode方法 data = urllib.parse.urlencode(data).encode('utf-8')
参数是放在请求对象定制的方法中
request = urllib.request.Request (url=url,data=data, headers=headers )
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'kw':'spider'
}
# post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
# post的请求的参数 是不会拼接在url的后面的 而是需要放在请求对象定制的参数中
# post请求的参数 必须要进行编码.encode('utf-8')
request = urllib.request.Request(url=url,data=data,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 字符串--》json对象
import json
obj = json.loads(content)
print(obj)
结果:
{'errno': 0, 'data': [{'k': 'spider', 'v': 'n. 蜘蛛; 星形轮,十字叉; 带柄三脚平底锅; 三脚架'}, {'k': 'Spider', 'v': '[电影]蜘蛛'}, {'k': 'SPIDER', 'v': 'abbr. SEMATECH process induced damage effect revea'}, {'k': 'spiders', 'v': 'n. 蜘蛛( spider的名词复数 )'}, {'k': 'spidery', 'v': 'adj. 像蜘蛛腿一般细长的; 象蜘蛛网的,十分精致的'}]}
post和get区别

百度详细翻译
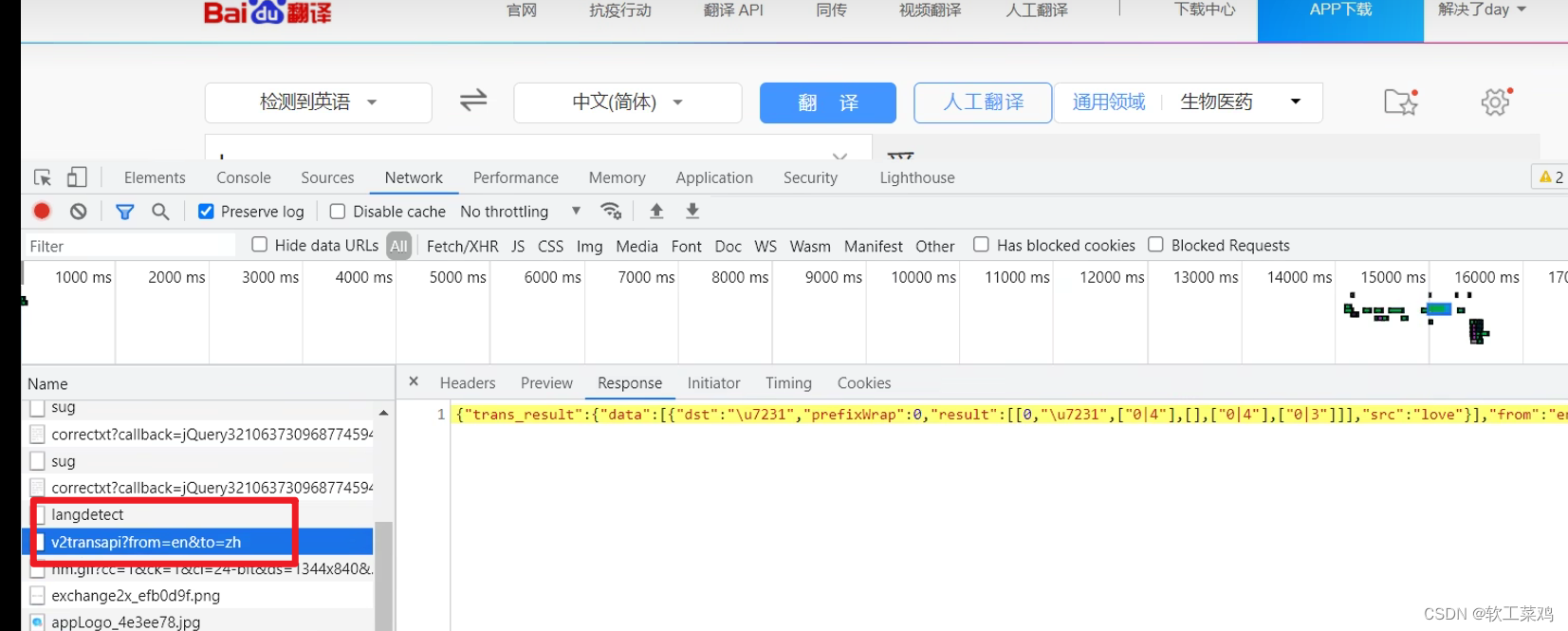
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
# 'Accept': '*/*',
# 'Accept-Encoding': 'gzip, deflate, br',
上面这行 接收的编码格式一定要注释掉
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Connection': 'keep-alive',
# 'Content-Length': '135',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
只要Cookie其实就行
'Cookie': 'BIDUPSID=DAA8F9F0BD801A2929D96D69CF7EBF50; PSTM=1597202227; BAIDUID=DAA8F9F0BD801A29B2813502000BF8E9:SL=0:NR=10:FG=1; __yjs_duid=1_c19765bd685fa6fa12c2853fc392f8db1618999058029; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=R2bEZvTjFCNHQxdUV-cTZ-MzZrSGxhbUYwSkRkUWk2SkxxS3E2M2lqaFRLUlJoRVFBQUFBJCQAAAAAAAAAAAEAAAA3e~BTveK-9sHLZGF5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFOc7GBTnOxgaW; BDUSS_BFESS=R2bEZvTjFCNHQxdUV-cTZ-MzZrSGxhbUYwSkRkUWk2SkxxS3E2M2lqaFRLUlJoRVFBQUFBJCQAAAAAAAAAAAEAAAA3e~BTveK-9sHLZGF5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFOc7GBTnOxgaW; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=DAA8F9F0BD801A29B2813502000BF8E9:SL=0:NR=10:FG=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=2; H_PS_PSSID=34435_31660_34405_34004_34073_34092_26350_34426_34323_22158_34390; delPer=1; BA_HECTOR=8185a12020018421b61gi6ka20q; BCLID=10943521300863382545; BDSFRCVID=boDOJexroG0YyvRHKn7hh7zlD_weG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK0mOTHv8F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tR3aQ5rtKRTffjrnhPF3-44vXP6-hnjy3bRkX4Q4Wpv_Mnndjn6SQh4Wbttf5q3RymJ42-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvD-ug3-7qqU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIE3-oJqC8hMIt43f; BCLID_BFESS=10943521300863382545; BDSFRCVID_BFESS=boDOJexroG0YyvRHKn7hh7zlD_weG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK0mOTHv8F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR3aQ5rtKRTffjrnhPF3-44vXP6-hnjy3bRkX4Q4Wpv_Mnndjn6SQh4Wbttf5q3RymJ42-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvD-ug3-7qqU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIE3-oJqC8hMIt43f; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1629701482,1629702031,1629702343,1629704515; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1629704515; __yjs_st=2_MDBkZDdkNzg4YzYyZGU2NTM5NzBjZmQ0OTZiMWRmZGUxM2QwYzkwZTc2NTZmMmIxNDJkYzk4NzU1ZDUzN2U3Yjc4ZTJmYjE1YTUzMTljYWFkMWUwYmVmZGEzNmZjN2FlY2M3NDAzOThhZTY5NzI0MjVkMmQ0NWU3MWE1YTJmNGE5NDBhYjVlOWY3MTFiMWNjYTVhYWI0YThlMDVjODBkNWU2NjMwMzY2MjFhZDNkMzVhNGMzMGZkMWY2NjU5YzkxMDk3NTEzODJiZWUyMjEyYTk5YzY4ODUyYzNjZTJjMGM5MzhhMWE5YjU3NTM3NWZiOWQxNmU3MDVkODExYzFjN183XzliY2RhYjgz; ab_sr=1.0.1_ZTc2ZDFkMTU5ZTM0ZTM4MWVlNDU2MGEzYTM4MzZiY2I2MDIxNzY1Nzc1OWZjZGNiZWRhYjU5ZjYwZmNjMTE2ZjIzNmQxMTdiMzIzYTgzZjVjMTY0ZjM1YjMwZTdjMjhiNDRmN2QzMjMwNWRhZmUxYTJjZjZhNTViMGM2ODFlYjE5YTlmMWRjZDAwZGFmMDY4ZTFlNGJiZjU5YzE1MGIxN2FiYTU3NDgzZmI4MDdhMDM5NTQ0MjQxNDBiNzdhMDdl',
# 'Host': 'fanyi.baidu.com',
# 'Origin': 'https://fanyi.baidu.com',
# 'Referer': 'https://fanyi.baidu.com/?aldtype=16047',
# 'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
# 'sec-ch-ua-mobile': '?0',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
}
data = {
'from': 'en',
'to': 'zh',
'query': 'love',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '198772.518981',
'token': '5483bfa652979b41f9c90d91f3de875d',
'domain': 'common',
}
# post请求的参数 必须进行编码 并且要调用encode方法
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求对象的定制
request = urllib.request.Request(url = url,data = data,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
import json
obj = json.loads(content)
print(obj)9.ajax的get请求
案例:爬取豆瓣电影前10页数据
获取豆瓣电影的第一页的数据 并且保存起来
找接口
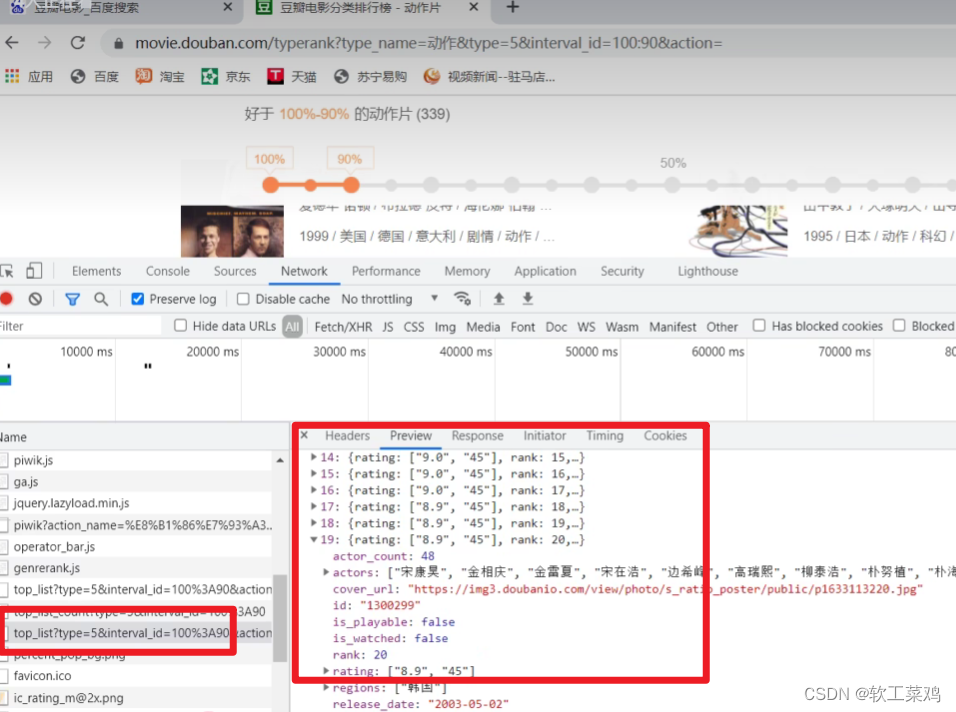
# get请求
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# (1) 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# (2)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# (3) 数据下载到本地
# open方法默认情况下使用的是gbk的编码
# 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8
# encoding = 'utf-8'
# 22 23行和 25 26行效果一样
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)下载豆瓣电影前10页的数据
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
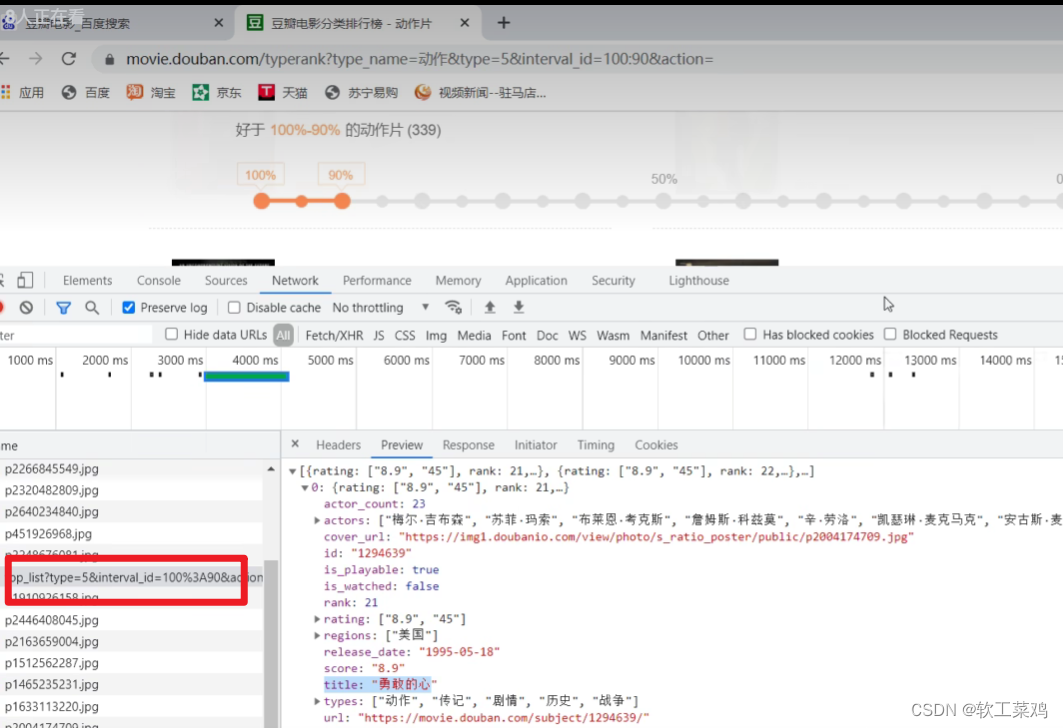
第二页接口
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=60&limit=20
page 1 2 3 4
start 0 20 40 60
规律: start数值其实= (page - 1)*20
# 下载豆瓣电影前10页的数据
# (1) 请求对象的定制
# (2) 获取响应的数据
# (3) 下载数据
import urllib.parse
import urllib.request
# 每一页都有自己的请求对象的定制
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start':(page - 1) * 20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
return request
# 获取响应的数据
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 下载
def down_load(page,content):
with open('douban_' + str(page) + '.json','w',encoding='utf-8')as fp:
fp.write(content)
# 程序的入口
if __name__ == '__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页面'))
for page in range(start_page,end_page+1):# 左闭右开
# 每一页都有自己的请求对象的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
down_load(page,content)10.ajax的post请求
案例:KFC官网 北京哪里有kfc&前十页数据
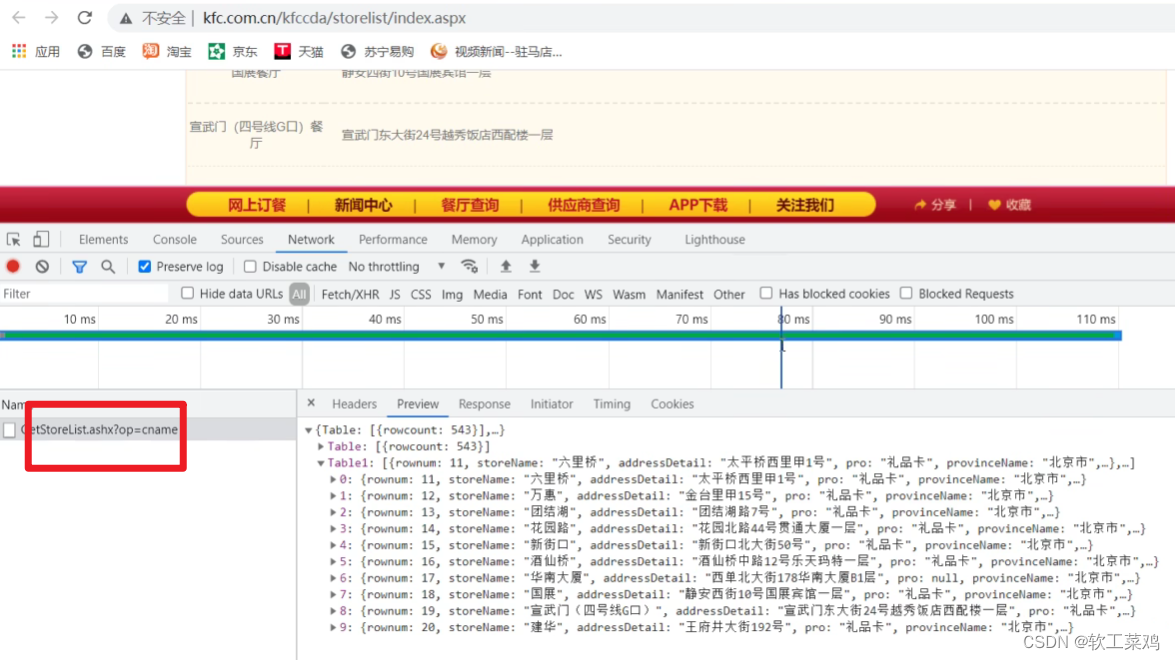
1页
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
post
cname: 北京
pid:
pageIndex: 1
pageSize: 10
2页
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
post
cname: 北京
pid:
pageIndex: 2
pageSize: 10
import urllib.request
import urllib.parse
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid':'',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_' + str(page) + '.json','w',encoding='utf-8')as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载
down_load(page,content)11.URLError\HTTPError

import urllib.request
import urllib.error
#HTTPError
# url = 'https://blog.csdn.net/sulixu/article/details/1198189491'
#URLError
url = 'http://www.doudan1111.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
try:
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级。。。')
except urllib.error.URLError:
print('我都说了 系统正在升级。。。')12.cookie登录
适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面

个人信息页面是utf-8 但是还报错了编码错误
因为并没有进入到个人信息页面 而是跳转到了登陆页面,而登陆页面不是utf-8 所以报错
什么情况下访问不成功? 因为请求头的信息不够 所以访问不成功
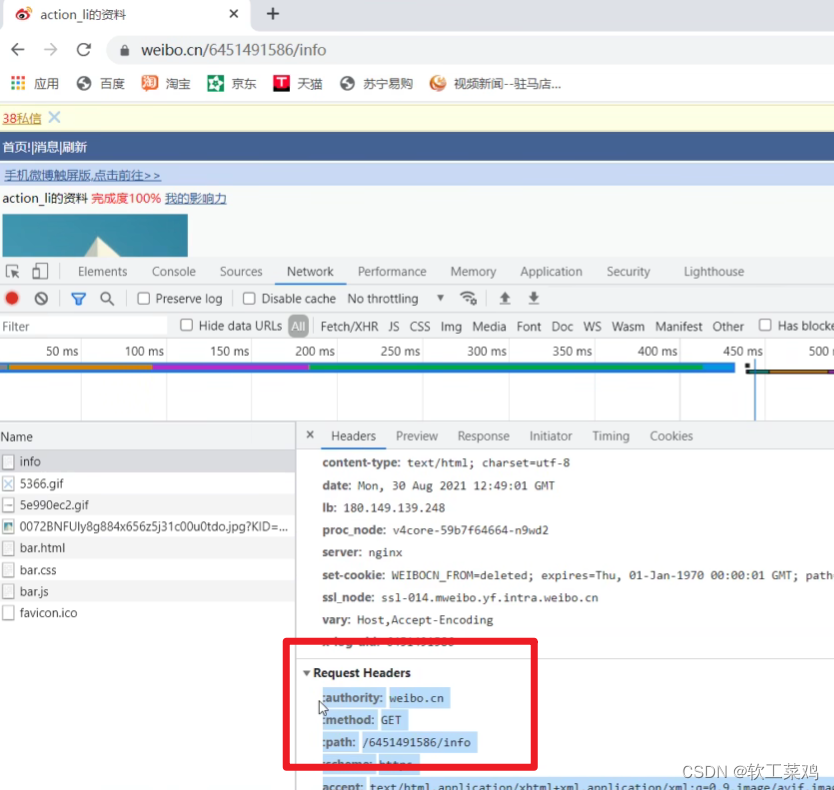
案例:weibo登陆
import urllib.request
url = 'https://weibo.cn/6451491586/info'
headers = {
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6451491586/info',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面
'cookie': '_T_WM=24c44910ba98d188fced94ba0da5960e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFxxfgNNUmXi4YiaYZKr_J_5NHD95QcSh-pSh.pSKncWs4DqcjiqgSXIgvVPcpD; SUB=_2A25MKKG_DeRhGeBK7lMV-S_JwzqIHXVv0s_3rDV6PUJbktCOLXL2kW1NR6e0UHkCGcyvxTYyKB2OV9aloJJ7mUNz; SSOLoginState=1630327279',
referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链
'referer': 'https://weibo.cn/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存到本地
with open('weibo.html','w',encoding='utf-8')as fp:
fp.write(content)失败

作业:qq空间的爬取
13.Handler处理器
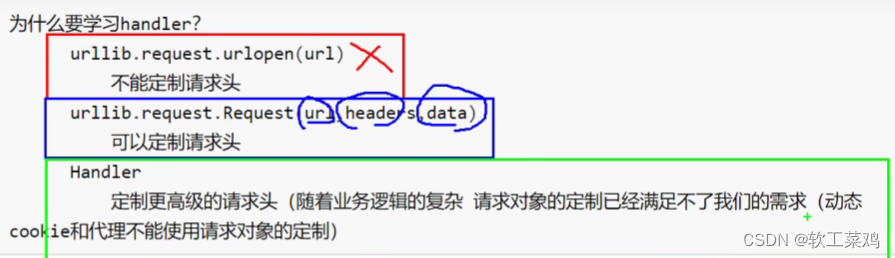
需求 使用handler来访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
# handler build_opener open
# (1)获取hanlder对象
handler = urllib.request.HTTPHandler()
# (2)获取opener对象
opener = urllib.request.build_opener(handler)
# (3) 调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)14. 代理服务器

免费的用不了,买一个
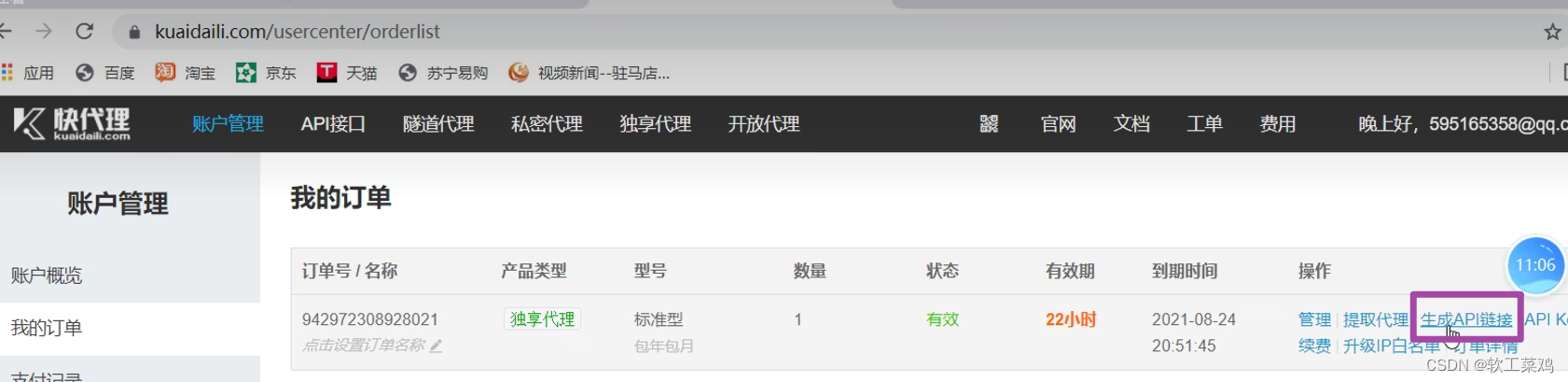
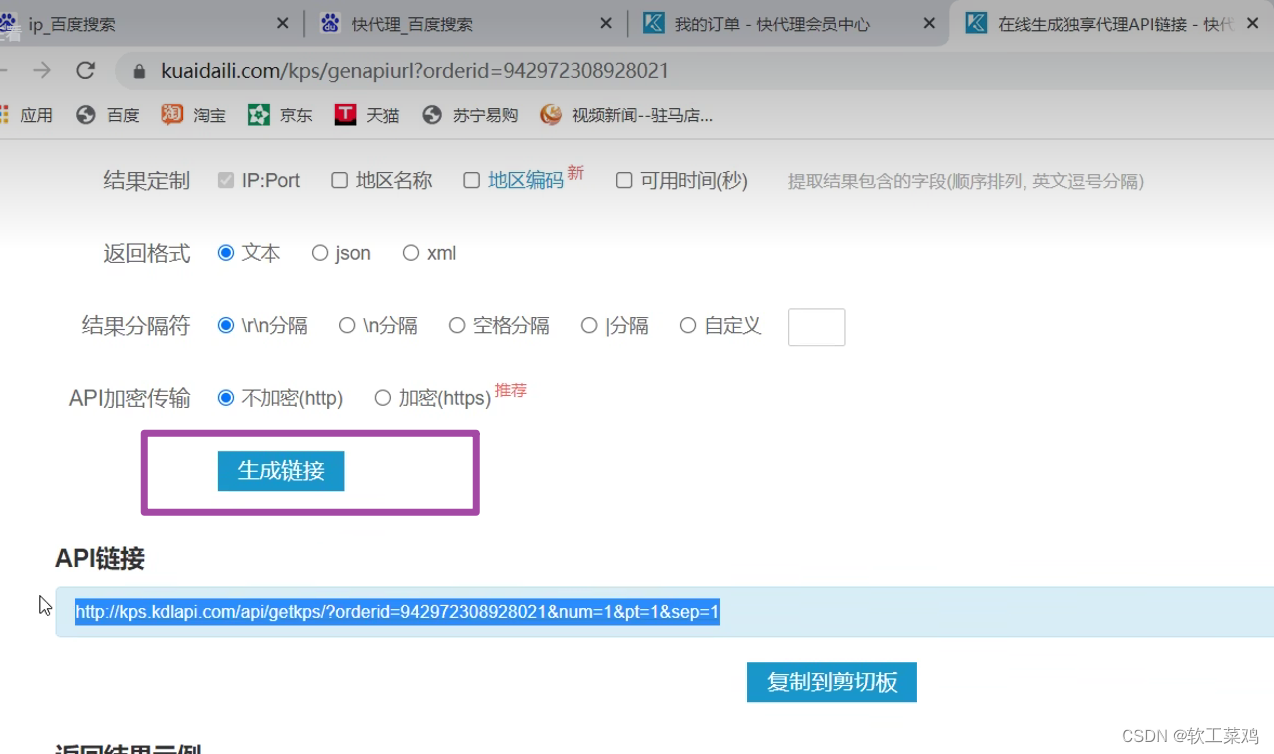

查ip地址
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers= headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
# 代理ip
proxies = {
'http':'118.24.219.151:16817'
}
# handler build_opener open
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('utf-8')
# 保存
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)代理池
import urllib.request
proxies_pool = [
{'http':'118.24.219.151:16817'},
{'http':'118.24.219.151:16817'},
]
import random
# 随机从代理池选择
proxies = random.choice(proxies_pool)
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers=headers)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)解析
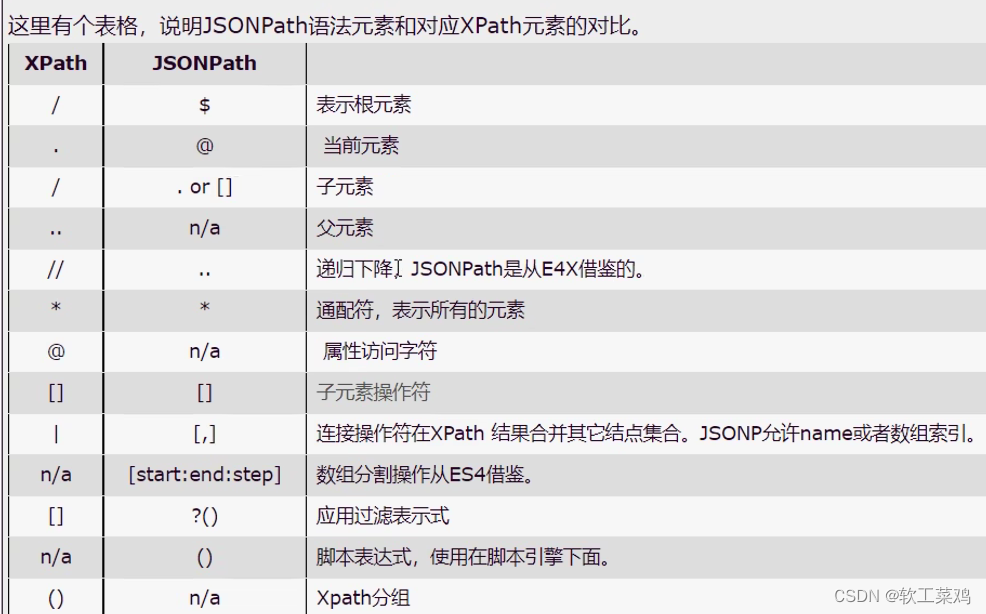
1.xpath(Ctrl+shift+x)
xpath使用:
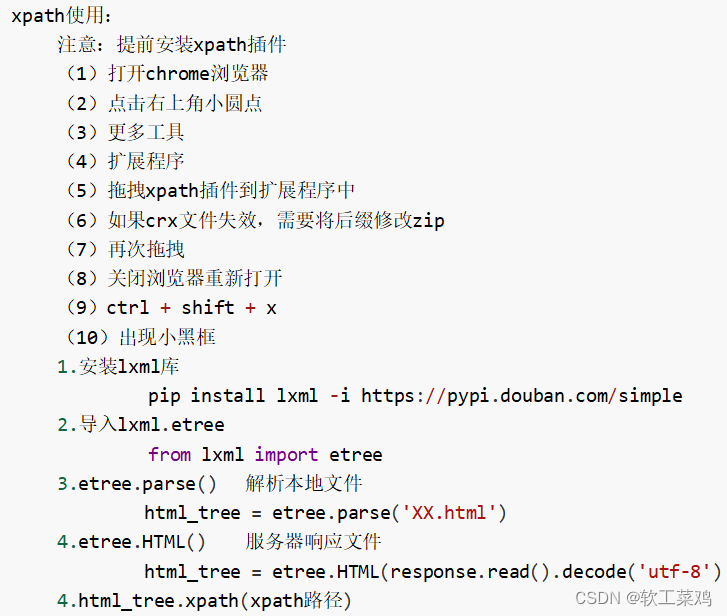
安装lxml库要到解释器的Scripts文件夹下面:

xpath基本语法:
调出xpath窗口后,shift按住,移动鼠标到指定目标,可以快速自动获取目标xpath路径

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="l2">上海</li>
<li id="c3">深圳</li>
<li id="c4">武汉</li>
</ul>
<!-- <ul>-->
<!-- <li>大连</li>-->
<!-- <li>锦州</li>-->
<!-- <li>沈阳</li>-->
<!-- </ul>-->
</body>
</html>xpath解析
(1)本地文件 etree.parse
(2)解析服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()
from lxml import etree
# xpath解析本地文件
tree = etree.parse('070_尚硅谷_爬虫_解析_xpath的基本使用.html')
#tree.xpath('xpath路径')
# 查找ul下面的li
# li_list = tree.xpath('//body/ul/li')
# 查找所有有id的属性的li标签
# text()获取标签中的内容
# li_list = tree.xpath('//ul/li[@id]/text()')
# ['北京', '上海', '深圳', '武汉']
# 找到id为l1的li标签 注意引号的问题
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# ['北京']
# 查找到id为l1的li标签的class的属性值
# li = tree.xpath('//ul/li[@id="l1"]/@class')
# ['c1']
# 查询id中包含l的li标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# ['北京', '上海']
# 查询id的值以l开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
#查询id为l1和class为c1的
# li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
# ['北京']
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
# ['北京', '上海']
# 判断列表的长度
print(li_list)
print(len(li_list))获取百度网站的 百度一下
xpath插件找 对应xpath路径 <input>类型,id=su;
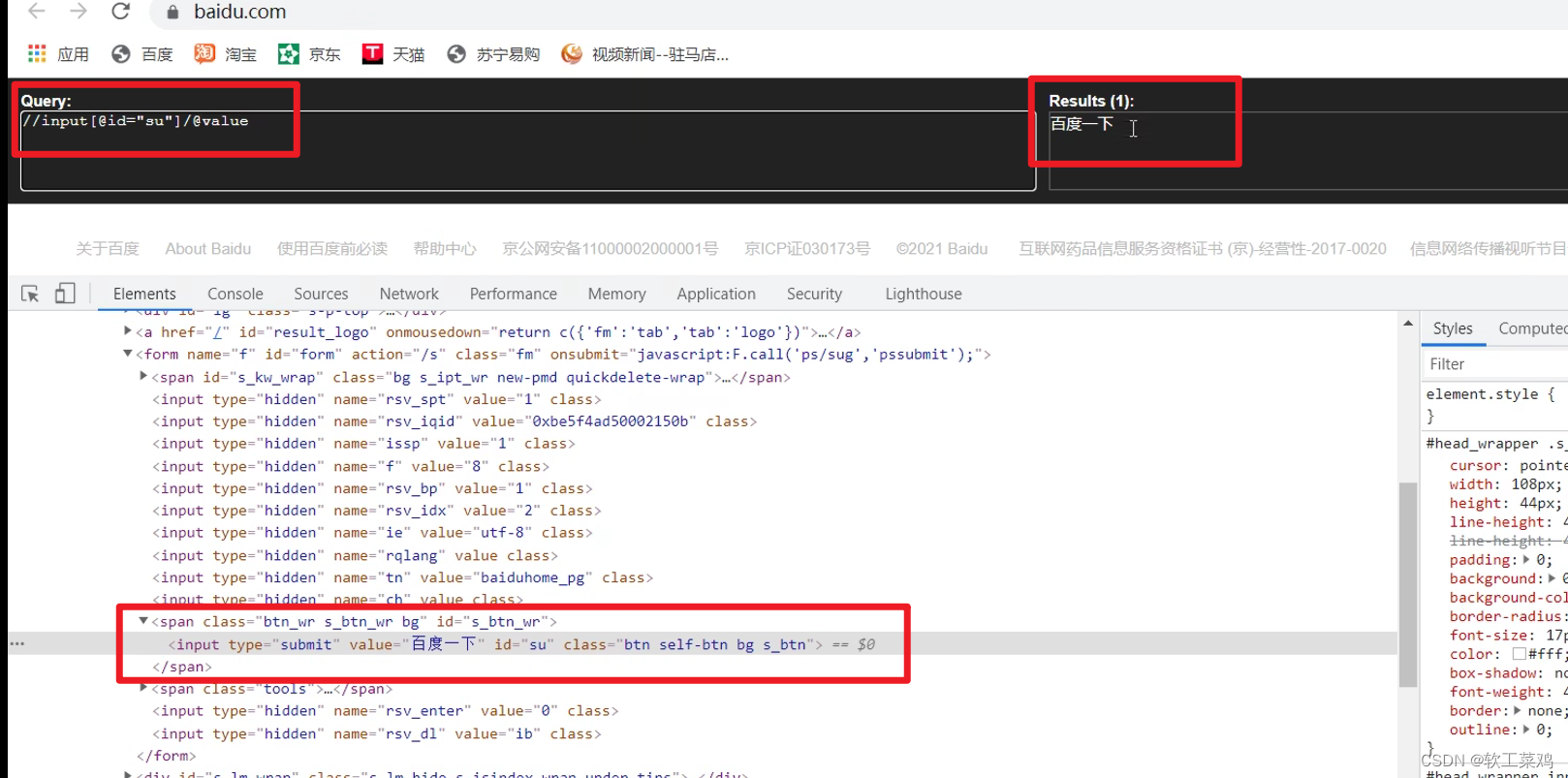
# (1) 获取网页的源码
# (2) 解析 解析的服务器响应的文件 etree.HTML
# (3) 打印
import urllib.request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers = headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析网页源码 来获取我们想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath的返回值是一个列表类型的数据
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)站长素材图片抓取并且下载(http://sc.chinaz.com/tupian/shuaigetupian.html)
--》懒加载 一般设计图片的网站都会进行懒加载 用@src2
需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 第一页
# https://sc.chinaz.com/tupian/qinglvtupian_2.html 第二页
# https://sc.chinaz.com/tupian/qinglvtupian_page.html 第n页
# (1) 请求对象的定制
# (2)获取网页的源码
# (3)下载
import urllib.request
from lxml import etree
# (1) 请求对象的定制
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url = url, headers = headers)
return request
# (2)获取网页的源码
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
# 图片名字
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# 一般设计图片的网站都会进行懒加载
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)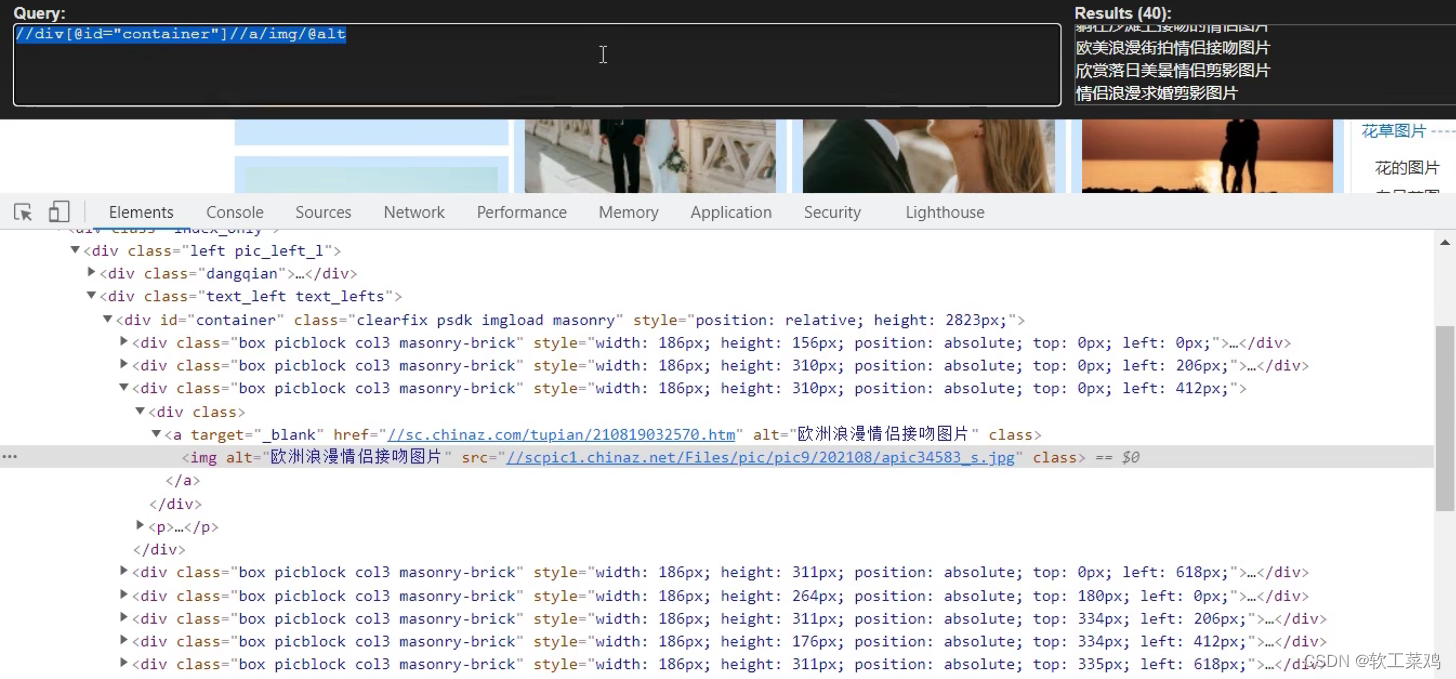
一直爬取失败,后来打印了content 发现爬取的源码和真实源码不同:
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
return content
失败了一个多小时捏! 但是xpath路径确实会找了
那爬的源码和实际源码不一样咋解决呢?
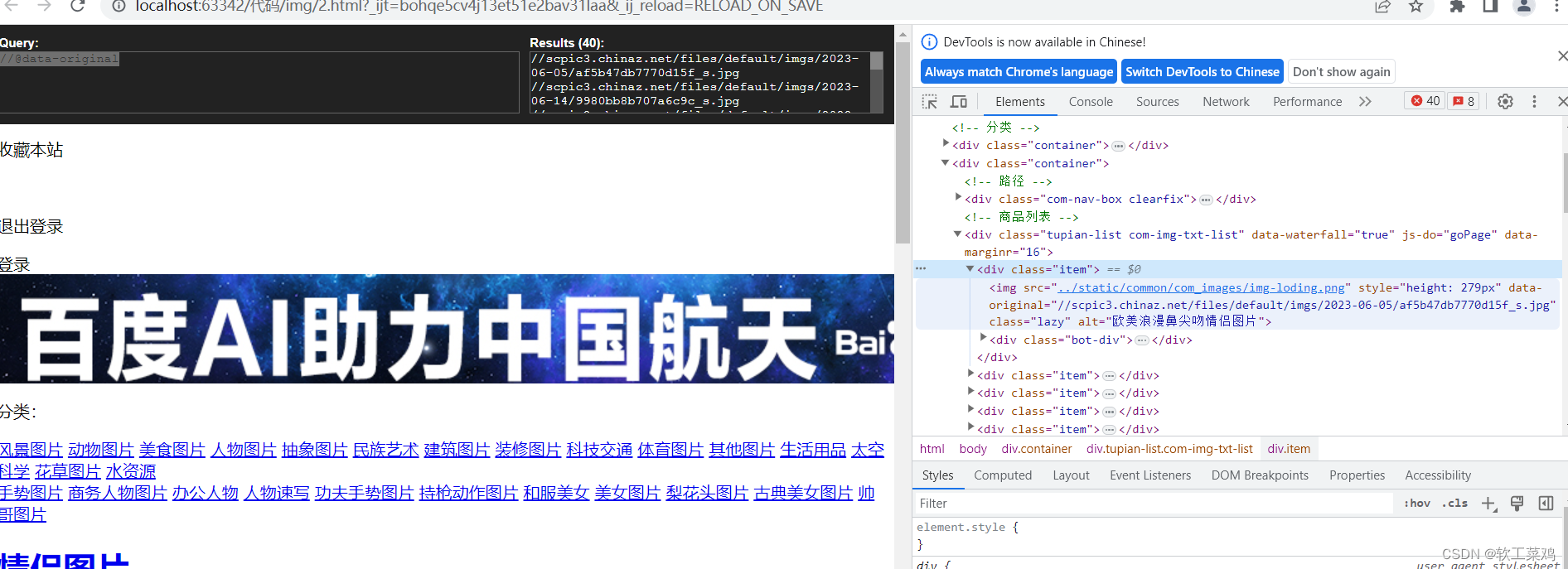
差点放弃,看弹幕里的//@data-original想起来,直接去爬到的源码里xpath不就得了?
import urllib.request
from lxml import etree
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url = url, headers = headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
return content
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
name_list = tree.xpath('/html/body/div[3]/div[2]/div/img/@alt')
# 一般设计图片的网站都会进行懒加载
src_list = tree.xpath('//@data-original')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
# print(url)
urllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)成功!!!
2.JsonPath 只能解析本地文件
jsonpath的安装及使用方式:
pip安装:pip install jsonpath
jsonpath的使用:
obj = json.load(open('json文件', 'r', encoding='utf‐8'))
ret = jsonpath.jsonpath(obj, 'jsonpath语法')
教程连接(JSONPath-简单入门)
import json
import jsonpath
obj = json.load(open('073_尚硅谷_爬虫_解析_jsonpath.json','r',encoding='utf-8'))
# 书店所有书的作者
# author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')
# print(author_list)
# 所有的作者
# author_list = jsonpath.jsonpath(obj,'$..author')
# print(author_list)
# store下面的所有的元素
# tag_list = jsonpath.jsonpath(obj,'$.store.*')
# print(tag_list)
# store里面所有东西的price
# price_list = jsonpath.jsonpath(obj,'$.store..price')
# print(price_list)
# 第三个书
# book = jsonpath.jsonpath(obj,'$..book[2]')
# print(book)
# 最后一本书
# book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
# print(book)
# 前面的两本书
# book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
# book_list = jsonpath.jsonpath(obj,'$..book[:2]')
# print(book_list)
# 条件过滤需要在()的前面添加一个?
# 过滤出所有的包含isbn的书。
# book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
# print(book_list)
# 哪本书超过了10块钱
book_list = jsonpath.jsonpath(obj,'$..book[?(@.price>10)]')
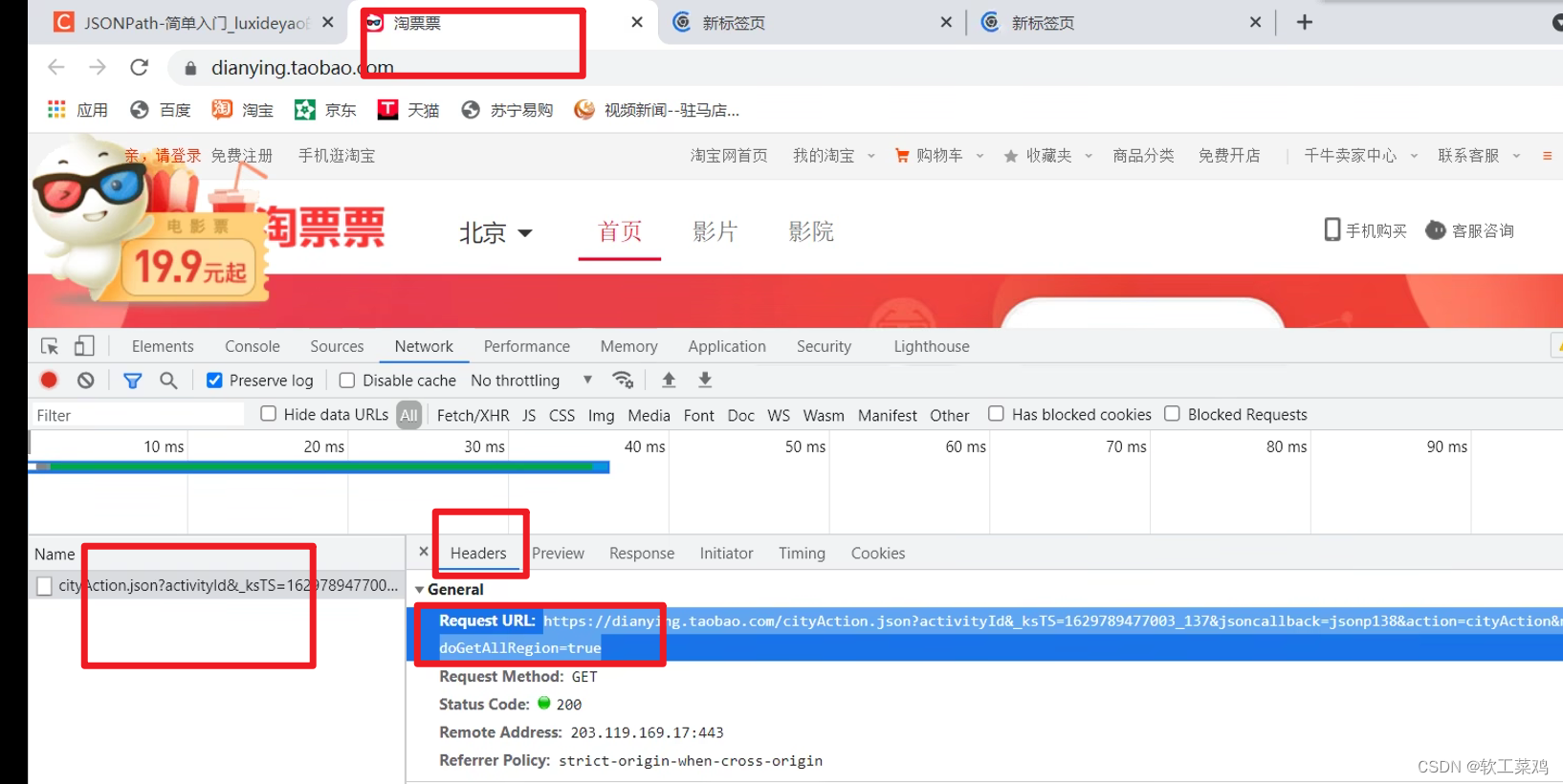
print(book_list)案例练习:淘票票
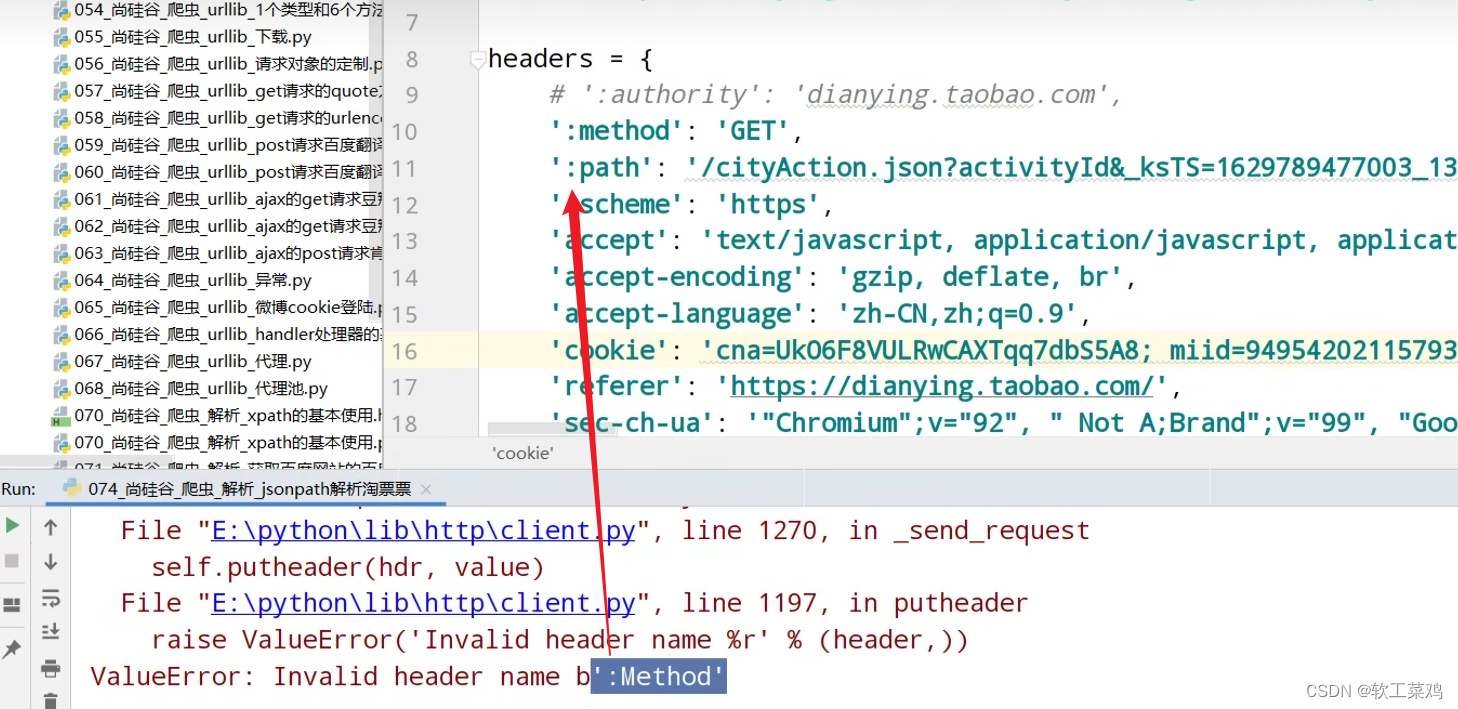
带冒号:的请求头一般 是 不好使的
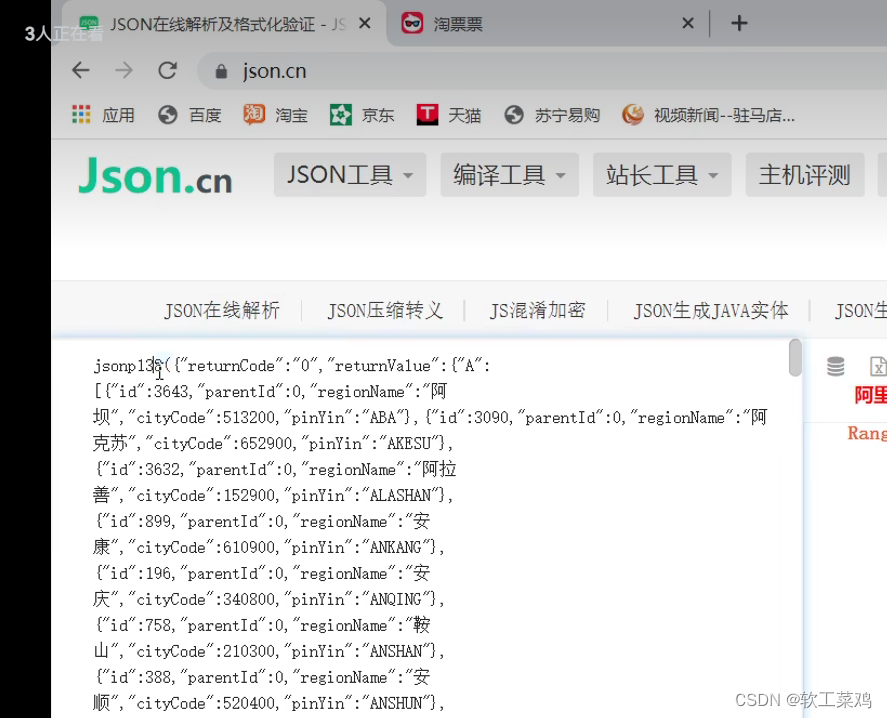
最开始jonsp和后面的)是不要的;split 切割
import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'cna=UkO6F8VULRwCAXTqq7dbS5A8; miid=949542021157939863; sgcookie=E100F01JK9XMmyoZRigjfmZKExNdRHQqPf4v9NIWIC1nnpnxyNgROLshAf0gz7lGnkKvwCnu1umyfirMSAWtubqc4g%3D%3D; tracknick=action_li; _cc_=UIHiLt3xSw%3D%3D; enc=dA18hg7jG1xapfVGPHoQCAkPQ4as1%2FEUqsG4M6AcAjHFFUM54HWpBv4AAm0MbQgqO%2BiZ5qkUeLIxljrHkOW%2BtQ%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; _m_h5_tk=3ca69de1b9ad7dce614840fcd015dcdb_1629776735568; _m_h5_tk_enc=ab56df54999d1d2cac2f82753ae29f82; t=874e6ce33295bf6b95cfcfaff0af0db6; xlly_s=1; cookie2=13acd8f4dafac4f7bd2177d6710d60fe; v=0; _tb_token_=e65ebbe536158; tfstk=cGhRB7mNpnxkDmUx7YpDAMNM2gTGZbWLxUZN9U4ulewe025didli6j5AFPI8MEC..; l=eBrgmF1cOsMXqSxaBO5aFurza77tzIRb8sPzaNbMiInca6OdtFt_rNCK2Ns9SdtjgtfFBetPVKlOcRCEF3apbgiMW_N-1NKDSxJ6-; isg=BBoas2yXLzHdGp3pCh7XVmpja8A8S54lyLj1RySTHq14l7vRDNufNAjpZ2MLRxa9',
'referer': 'https://dianying.taobao.com/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# split 切割
content = content.split('(')[1].split(')')[0]
with open('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','w',encoding='utf-8')as fp:
fp.write(content)
import json
import jsonpath
# 加载文件
obj = json.load(open('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','r',encoding='utf-8'))
city_list = jsonpath.jsonpath(obj,'$..regionName')
print(city_list)作业: 1.股票信息提取(http://quote.stockstar.com/)
2.boos直聘
3.中华英才
4.汽车之家
3.BeautifulSoup(跳过了)
看了这条评论:可以跳过 爬虫2年没用过这个
1.基本简介
1.BeautifulSoup简称: bs4
2.什么是BeatifulSoup?
BeautifulSoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
3.优缺点?
缺点:效率没有lxml的效率高
优点:接口设计人性化,使用方便
2.安装以及创建
1.安装
pip install bs4
2.导入
from bs4 import BeautifulSoup
3.创建对象
服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(), 'lxml')
本地文件生成对象
soup = BeautifulSoup(open('1.html'), 'lxml')
类似于xpath;
注意:默认打开文件的编码格式gbk所以需要指定打开编码格式
通过解析本地文件 来将bs4的基础语法进行讲解
默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码
from bs4 import BeautifulSoup
# 通过解析本地文件 来将bs4的基础语法进行讲解
# 默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码
soup = BeautifulSoup(open('075_尚硅谷_爬虫_解析_bs4的基本使用.html',encoding='utf-8'),'lxml')
# 根据标签名查找节点
# 找到的是第一个符合条件的数据
# print(soup.a)
# 获取标签的属性和属性值
# print(soup.a.attrs)
# bs4的一些函数
# (1)find
# 返回的是第一个符合条件的数据
# print(soup.find('a'))
# 根据title的值来找到对应的标签对象
# print(soup.find('a',title="a2"))
# 根据class的值来找到对应的标签对象 注意的是class需要添加下划线
# print(soup.find('a',class_="a1"))
# (2)find_all 返回的是一个列表 并且返回了所有的a标签
# print(soup.find_all('a'))
# 如果想获取的是多个标签的数据 那么需要在find_all的参数中添加的是列表的数据
# print(soup.find_all(['a','span']))
# limit的作用是查找前几个数据
# print(soup.find_all('li',limit=2))
# (3)select(推荐)
# select方法返回的是一个列表 并且会返回多个数据
# print(soup.select('a'))
# 可以通过.代表class 我们把这种操作叫做类选择器
# print(soup.select('.a1'))
# print(soup.select('#l1'))
# 属性选择器---通过属性来寻找对应的标签
# 查找到li标签中有id的标签
# print(soup.select('li[id]'))
# 查找到li标签中id为l2的标签
# print(soup.select('li[id="l2"]'))
# 层级选择器
# 后代选择器
# 找到的是div下面的li
# print(soup.select('div li'))
# 子代选择器
# 某标签的第一级子标签
# 注意:很多的计算机编程语言中 如果不加空格不会输出内容 但是在bs4中 不会报错 会显示内容
# print(soup.select('div > ul > li'))
# 找到a标签和li标签的所有的对象
# print(soup.select('a,li'))
# 节点信息
# 获取节点内容
# obj = soup.select('#d1')[0]
# 如果标签对象中 只有内容 那么string和get_text()都可以使用
# 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据
# 我们一般情况下 推荐使用get_text()
# print(obj.string)
# print(obj.get_text())
# 节点的属性
# obj = soup.select('#p1')[0]
# name是标签的名字
# print(obj.name)
# 将属性值左右一个字典返回
# print(obj.attrs)
# 获取节点的属性
obj = soup.select('#p1')[0]
print(obj.attrs.get('class'))
print(obj.get('class'))
print(obj['class'])3.节点定位

4.节点信息

应用实例: 1.股票信息提取(http://quote.stockstar.com/)
2.中华英才网-旧版
3 .腾讯公司招聘需求抓取(https://hr.tencent.com/index.php)
bs4爬取星巴克数据.py
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class="grid padded-3 product"]//strong/text()
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())Selenium
1.Selenium (过程有点慢)
1.什么是selenium?
(1)Selenium是一个用于Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器测试
(4)selenium也是支持无界面浏览器操作的。
2.为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
3.如何安装selenium?
(1)操作谷歌浏览器驱动下载地址
http://chromedriver.storage.googleapis.com/index.html
(2)谷歌驱动和谷歌浏览器版本之间的映射表(没啥用了,现在版本已经停更映射表)
http://blog.csdn.net/huilan_same/article/details/51896672
(3)查看谷歌浏览器版本
谷歌浏览器右上角‐‐>帮助‐‐>关于
(4)pip install selenium
4.selenium的使用步骤?
(1)导入:from selenium import webdriver
(2)创建谷歌浏览器操作对象:
path = 谷歌浏览器驱动文件路径
browser = webdriver.Chrome(path)
(3)访问网址
url = 要访问的网址
browser.get(url)
常见使用报错原因
4.0+会自动装载path无需写入参数!但报错不会影响网页爬取
注意!如果你下载的seleninum是4.0+!path写了会报错
如果浏览器未安装在默认位置,会报cannot find Chrome binary错误,需要配置环境变量及代码指定浏览器位置
吐血了,闪退原因谷歌和谷歌驱动版本不兼容
闪退换成3.31版本就好:pip install selenium3.3.1
# (1)导入selenium
from selenium import webdriver
# (2) 创建浏览器操作对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# (3)访问网站
# url = 'https://www.baidu.com'
#
# browser.get(url)
url = 'https://www.jd.com/'
browser.get(url)
# page_source获取网页源码
content = browser.page_source
print(content)报错:感觉是版本问题 要不把chrome最新版卸了重新安装?
raceback (most recent call last):
File "D:\Python\爬虫\代码\078_尚硅谷_爬虫_selenium_基本使用.py", line 9, in <module>
browser = webdriver.Chrome(path).input()
File "D:\Python\Python3.10.4\lib\site-packages\selenium\webdriver\chrome\webdriver.py", line 49, in __init__
super().__init__(
File "D:\Python\Python3.10.4\lib\site-packages\selenium\webdriver\chromium\webdriver.py", line 60, in __init__
ignore_proxy=self.options._ignore_local_proxy,
AttributeError: 'str' object has no attribute '_ignore_local_proxy'重装了还是用不了;我估计是方法过时了;
https://www.chromedownloads.net/chrome64win/
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.jd.com/")
content = driver.page_source
print(content)新方法 爬取成功!
4‐1:selenium的元素定位?
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先
要找到它们,WebDriver提供很多定位元素的方法
方法:(这些方法应该都过时了)
参考最新源码:
def find_elements(self, by=By.ID, value: Optional[str] = None) -> List[WebElement]:
"""Find elements given a By strategy and locator.
:Usage:
::
elements = driver.find_elements(By.CLASS_NAME, 'foo')
:rtype: list of WebElement
"""
if isinstance(by, RelativeBy):
_pkg = ".".join(__name__.split(".")[:-1])
raw_function = pkgutil.get_data(_pkg, "findElements.js").decode("utf8")
find_element_js = f"/* findElements */return ({raw_function}).apply(null, arguments);"
return self.execute_script(find_element_js, by.to_dict())
if by == By.ID:
by = By.CSS_SELECTOR
value = f'[id="{value}"]'
elif by == By.CLASS_NAME:
by = By.CSS_SELECTOR
value = f".{value}"
elif by == By.NAME:
by = By.CSS_SELECTOR
value = f'[name="{value}"]'
# Return empty list if driver returns null
# See https://github.com/SeleniumHQ/selenium/issues/4555
return self.execute(Command.FIND_ELEMENTS, {"using": by, "value": value})["value"] or []class By:
"""Set of supported locator strategies."""
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"1.find_element_by_id
eg:button = browser.find_element_by_id('su')
Traceback (most recent call last):
File "D:\Python\爬虫\代码\079_尚硅谷_爬虫_selenium_元素定位.py", line 14, in <module>
button = driver.find_element_by_id('su')
AttributeError: 'WebDriver' object has no attribute 'find_element_by_id'
button = browser.find_element('id','su') 改成这样;
然后才能输入browser.find_element(By.ID,'su');然后才能输入browser.find_element(By.ID,'su')
2.find_elements_by_name
eg:name = browser.find_element_by_name('wd')
3.find_elements_by_xpath
eg:xpath1 = browser.find_elements_by_xpath('//input[@id="su"]')
4.find_elements_by_tag_name
eg:names = browser.find_elements_by_tag_name('input')
5.find_elements_by_css_selector
eg:my_input = browser.find_elements_by_css_selector('#kw')[0]
6.find_elements_by_link_text
eg:browser.find_element_by_link_text("新闻")
from selenium import webdriver
# path = 'chromedriver.exe'
# browser = webdriver.Chrome(path)
driver = webdriver.Chrome()
url = 'https://www.baidu.com'
driver.get(url)
# 元素定位
# 根据id来找到对象
# button = driver.find_element('id','su')
# print(button)
# <selenium.webdriver.remote.webelement.WebElement (session="4a3108f55869fdd968308cca8c755ceb", element="9c0cb14b-6b13-4df0-bd9c-f037b5e698b7")>
# 根据标签属性的属性值来获取对象的
# button = driver.find_element('name','wd')
# print(button)
#<selenium.webdriver.remote.webelement.WebElement (session="9ce8bcbd316bd3833196d27b35bc3ee0", element="5b60bd16-8ddd-4d1e-91b5-419ca56df7c1")>
# 根据xpath语句来获取对象
# button = driver.find_elements_by_xpath('//input[@id="su"]')
# AttributeError: 'WebDriver' object has no attribute 'find_elements_by_xpath'
# buttons = driver.find_elements('xpath','//input[@id="su"]')
# button = driver.find_element('xpath','//input[@id="su"]')
# print(buttons)
# # [<selenium.webdriver.remote.webelement.WebElement (session="88c5e8b10c200d2d01c6b60c1b4a10d0", element="737a0208-c72f-4413-a910-d637af304c07")>]
# print(button)
# <selenium.webdriver.remote.webelement.WebElement (session="460bc537d3c06f4863f0500bf8bd8778", element="05e6b8ac-7028-47de-92bf-740c8ebb4e3a")>
# 根据标签的名字来获取对象
# button = driver.find_elements(by='tag name',value='input')
# print(button)
# [<selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="dd075d84-cec1-4f9a-b917-74658dc7d0ce")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="818e0cbb-29a1-4110-a149-8dce242bd835")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="47557002-f224-4331-a611-188db0de0ac5")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="7829b3a3-8b16-4d23-9561-65f3c935dec6")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="c052ffcf-a485-480d-aa46-31d98a8836a9")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="a59d68d0-cb5a-4770-9ea6-05a0720974b5")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="9c1bc881-d835-43ad-a859-4a9eed5f2d7b")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="409da760-913d-4e26-bcd2-0d984cc920fe")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="eade7f40-2207-44ed-8dfe-e6fa5c45a32e")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="b1fb9f45-56e4-4a77-bfab-e8c34daaf7ae")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="3bcb8f3f-c5b6-4546-a7c6-f577981dd975")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="d5c92328-43d7-4d85-9f24-d112d4a60535")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="0eec8b4f-e999-47e0-b2eb-8d3fac1f9e21")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="e8680897-274c-4485-86be-8795e826d5ca")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="4b16bf17-7915-4203-a558-b6dad4695d64")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="c2ceb712-e117-4323-bfe2-f0f63c753387")>, <selenium.webdriver.remote.webelement.WebElement (session="7ee88b514bbfd8dc09fee89186847dab", element="0905fc95-4a89-46c2-bd55-fa120174693f")>]
# 使用的bs4的语法来获取对象
# button = driver.find_elements(by='css selector',value='#su')
# print(button)
# [<selenium.webdriver.remote.webelement.WebElement (session="8d7e7230bc7c180aaf19d0ffe6f14444", element="bea4de33-57ab-4578-b8f7-98a6fa68b734")>]
#获取当前页面的链接文本
button = driver.find_element(by='link text',value='地图')
print(button)
# <selenium.webdriver.remote.webelement.WebElement (session="3fd11e699abe32acaaebc12b2d76a812", element="7c7f54b2-dd76-4076-a582-c3f0a8352ca3")>4‐2:访问元素信息
获取元素属性
.get_attribute('class')
获取元素文本
.text
获取标签名
.tag_name
from selenium import webdriver
driver = webdriver.Chrome()
url = 'https://www.baidu.com'
driver.get(url)
input = driver.find_element('id','su')
# 获取标签的属性
print(input.get_attribute('class'))
# bg s_btn
# 获取标签的名字
print(input.tag_name)
# input
# 获取元素文本
a = driver.find_element('link text','地图')
print(a.text)
# 地图4‐3:交互
点击:click()
输入:send_keys()
后退操作:browser.back()
前进操作:browser.forword()
模拟JS滚动:
js='document.documentElement.scrollTop=100000'
browser.execute_script(js) 执行js代码
获取网页代码:page_source
退出:browser.quit()
from selenium import webdriver
# 创建浏览器对象
# path = 'chromedriver.exe'
# browser = webdriver.Chrome(path)
driver = webdriver.Chrome()
url = 'https://www.baidu.com'
driver.get(url)
import time
time.sleep(2)#睡2秒
# 获取文本框的对象
input = driver.find_element('id','kw')
# 在文本框中输入周杰伦
input.send_keys('周杰伦')
time.sleep(2)
# 获取百度一下的按钮
button = driver.find_element('id','su')
# 点击按钮
button.click()
time.sleep(2)
# 滑到底部 scrollTop=100000距离顶部十万差不多就能到底
js_bottom = 'document.documentElement.scrollTop=100000'
driver.execute_script(js_bottom)
time.sleep(2)
# 获取下一页的按钮
next = driver.find_element('xpath','//a[@class="n"]')
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
driver.back()
time.sleep(2)
# 回去
driver.forward()
time.sleep(3)
# 退出
driver.quit()2.Phantomjs(公司破产,基本淘汰)
1.什么是Phantomjs?
(1)是一个无界面的浏览器
(2)支持页面元素查找,js的执行等
(3)由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多
2.如何使用Phantomjs?
(1)获取PhantomJS.exe文件路径path
(2)browser = webdriver.PhantomJS(path)
(3)browser.get(url)
扩展:保存屏幕快照:browser.save_screenshot('baidu.png')
3.Chrome handless
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。
1.系统要求:
Chrome
Unix\Linux 系统需要 chrome >= 59
Windows 系统需要 chrome >= 60
Python3.6
Selenium==3.4.*
ChromeDriver==2.31
2.配置:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('‐‐headless')
chrome_options.add_argument('‐‐disable‐gpu')
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('http://www.baidu.com/')
3.配置封装:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path是你自己的chrome浏览器的文件路径
path = r'C:\Users\6\AppData\Local\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
driver = webdriver.Chrome()
url = 'https://www.baidu.com'
driver.get(url)
driver.save_screenshot('baidu.png')我的还是会弹出来界面,我估计是driver的原因;
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def share_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path是你自己的chrome浏览器的文件路径
path = r'C:\Users\王睿\AppData\Local\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
driver = webdriver.Chrome()
return driver
driver = share_browser()
url = 'https://www.baidu.com'
driver.get(url)作业:京东
本文来自博客园,作者:软工菜鸡,转载请注明原文链接:https://www.cnblogs.com/SElearner/p/17676646.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号